
Abstract
Energy efficiency and energy balance are two important issues for wireless sensor networks. In previous clustering routing algorithms, multihop transmission, sleep scheduling, and unequal clustering are always used to improve energy efficiency and energy balance. In these algorithms, only the cluster heads share the burden of data forwarding in each round. In this paper, we propose a flow-partitioned unequal clustering routing (FPUC) algorithm to achieve better energy efficiency and energy balance. FPUC consists of two phases: clustering and routing. In the clustering phase, the competition radius is computed according to the node density and the distance from sensor nodes to the sink. The sensor nodes that have more residual energy and larger overlapping degree have higher probability to be selected as cluster heads. In the routing phase, each cluster head first finds the gateway nodes and then distributes the data flow to each of its gateway nodes depending on residual energy. After that, each gateway node forwards the data to the next hop with minimum cost. Two metrics called network lifetime and coverage lifetime are used to compare the performance of FPUC with that of the existing ones. Simulation results show that FPUC can achieve longer network lifetime and coverage lifetime than previous algorithms.
1. Introduction
With recent advancement in techniques such as microelectromechanical, embedded, and low-power design, wireless sensor networks (WSNs) have achieved great developments, which have been widely used in areas such as environmental monitoring, health care, and battlefield surveillance [1]. WSNs are collections of some sensor nodes that have integrated wireless communication, sensing, data storage, and data processing capabilities. These sensor nodes transmit sensed data to the sink via single-hop or multihop routing to accomplish specific tasks. Generally speaking, each sensor node has limited energy because it is often powered by nonrechargeable batteries. So with time elapsing, some sensor nodes may run out of energy, thus leading to the phenomenon that other sensor nodes cannot send data to the sink, called energy hole [2–4]. Therefore, designing energy-efficient routing algorithm to prolong the lifetime is very important to wireless sensor networks.
Researchers have done a lot of related work, among which clustering, multihop transmission, and sleep scheduling are the most widely used techniques to improve energy efficiency. In clustering algorithms, each cluster consists of one cluster head (CH) and some cluster members (CM). CH aggregates the data received from CMs and then conveys the aggregated data to the sink. For the reason that data aggregation is applied, the amount of the whole network's data to be transmitted is significantly reduced, thus prolonging the lifetime [5–7].
Studies in [6–11] have shown that multihop transmission can effectively help reduce the energy consumed in communication and extend the lifetime. However, CHs closer to the sink would consume more energy because they are loaded with more relaying traffic than the other CHs. Therefore, the energy hole problem will arise around the sink much easier. To solve the problem, unequal clustering is proposed. In unequal clustering algorithms, the clusters closer to the sink have smaller cluster size. Actually node density around the CH will also have effects on its energy consumption, especially under the nonuniform distribution. As Figure 1 shows, areas a and b have approximately equal distance to the sink, but node density of area a is obviously larger than that of area b which will lead to those CHs in area a having heavier burden than CHs in area b, and thus CHs in area a will consume more energy and then the energy hole may occur.

Clustering under nonuniform distribution.
In [12–15], researchers have proposed some algorithms which aim to conserve energy by turning off as many as possible sensor nodes while achieving the application's coverage goal at the same time. Tao et al. first propose the flow-balanced routing protocol (FBR) [16], which is very different from traditional routing algorithms. In FBR, a graph topology is constructed instead of tree structure and each CH may have multiple parents. When CH relays data, it computes the amount of flow from itself to each of its parent according to parent's current residual energy to balance relaying node's energy consumption. However, each cluster has the same cluster size in FBR; thus sensor nodes closer to the sink will die faster.
In this paper, we propose a flow-partitioned unequal clustering routing algorithm (FPUC) aiming to achieve longer network lifetime and coverage lifetime. Network lifetime is defined as the duration from the beginning to the time when any or a given percentage of sensor nodes die. Coverage lifetime measures the period from the network setup time to the time that network coverage drops below a predefined threshold or application's demanding value [16–18]. Compared with the existing clustering routing algorithms, FPUC mainly has the following differences.
FPUC considers not only sensor node's residual energy but also sensor node's overlapping degree in the process of cluster heads selection. The sensor node which has more residual energy and larger overlapping degree has higher probability to be a cluster head. FPUC computes the competition radius according to sensor node's distance to the sink and sensor node's surrounding node density. After aggregating the data received from CMs, CH sends data to its CMs by the way of partitioning flow. When a CM receives data from its CH, it will transmit the flow to the next hop with the minimum cost. Thus the CH and CMs bear the burden of data relaying together.
The remainder of this paper is organized as follows. Section 2 introduces the related work. The network model and some definitions are described in Section 3. In Section 4, we propose the FPUC algorithm. Section 5 provides performance analysis about FPUC. In Section 6, we present the simulation results to show the validity of FPUC. The last section gives the conclusions.
2. Related Work
A lot of clustering routing algorithms have been proposed in recent years. Low-energy adaptive clustering hierarchy (LEACH) [5] is the first clustering routing protocol proposed. In LEACH, each sensor node has a certain probability to become a cluster head per round and the CHs send the aggregated data to the sink directly. Obviously, LEACH is very simple and can effectively extend the lifetime. However, LEACH does not take the residual energy of sensor node into consideration which will result in that the sensor node with little residual energy may become a cluster head. Moreover, because of transmitting data to the sink via single hop, sensor nodes closer to the sink will die faster, respectively. To solve the problems of LEACH, Younis and Fahmy proposed HEED in which the sensor node having more residual energy has higher probability of becoming cluster head [6]. As a result, HEED can generate a more reasonable network topology. In HEED, it adopts multihop routing. Consequently, sensor nodes closer to the sink would deplete their energy faster. The unbalanced energy consumption among different CHs may cause the network to be partitioned.
For solving hot spots problems in multihop WSNs, Soro and Heinzelman first proposed unequal clustering algorithm [19]. In [19], the network topology is a two-level concentric circle around the sink and the inner ring has smaller cluster size than the outer ring. However, the work in the literature [19] focuses on a heterogeneous network where CHs are deployed at determined locations. In [7], Li et al. proposed an energy-efficient unequal clustering algorithm (EEUC). In EEUC, the cluster closer to the sink has smaller size so that the cluster head can have more energy to relay data. Other unequal clustering algorithms, for example, [20, 21], are, respectively, based on the core idea of EEUC. These existing algorithms compute competition radius only according to sensor node's distance to the sink so that the cluster in an area where the node density is very high may have too many CMs. As a result, the cluster head may be loaded with too heavy burden and then would die faster. It is much worse in the case that the sensor nodes are deployed nonuniformly.
Research works in the literature [12–15] concentrate on how to switch off as many as possible sensor nodes for saving energy consumption while satisfying application's requirements for coverage. In [12], the authors proposed a sleep scheduling mechanism that puts sensor nodes into sleeping mode based on coverage information. In [13], the authors proposed a sleep scheduling scheme, where the probability of a sensor node's entering sleeping state is proportional to its distance to its cluster head. However, achieving the expected coverage ratio does not ensure that it can provide persistent coverage of the monitored area. Obviously, sensor nodes do not equally contribute to the whole network coverage. Comparing with the loss of a sensor node in scarcely populated regions, the death of a sensor node in a densely populated area is not so important. In other words, if some parts of a sensor node's sensing area are not covered by any other sensor nodes, the loss of this sensor node would leave the network inefficient. Such a sensor node can be called the coverage-critical node. These algorithms select cluster heads according to residual energy or previous activity of the sensor node as cluster head, ignoring sensor node's overlapping degree. So in these algorithms, the coverage-critical nodes may become cluster heads. Thus, these cluster heads would run out of energy very fast so that the coverage lifetime would be affected. This paper proposes a new cluster head selection algorithm that takes sensor node's residual energy and overlapping degree into consideration at the same time.
Existing clustering routing algorithms [2–10, 19–21] perform the cluster construction operation periodically to balance the energy consumption between cluster head and cluster members. However, these approaches cannot improve energy balance of relaying nodes significantly. In FBR [16], it assigns the transferred data over multiple paths from sensor nodes to the sink in order to equalize the energy consumption of sensor nodes. But the cluster formation is performed only once in FBR, which will result in that the sensor nodes as cluster heads would deplete energy very fast. And in FBR, each cluster has the same cluster size; thus the energy hole will occur around the sink easier. In this paper, we propose a novel algorithm where flow-partitioned routing is applied. At the same time, it adopts unequal clustering mechanism that will help avoid the hot spots problem around the sink, thus prolonging network lifetime.
3. Network Model and Definitions
3.1. Network Model
In this paper, we adopt the same network model as in [7, 8, 20], considering
The sensor nodes in the range R of sensor node i are called the neighbor nodes of sensor node i, denoted by

The neighbor nodes and close nodes of sensor node i.
Then,

The overlapping degree of a sensor node is the ratio of the overlapping area of the sensor node with its close nodes to its sensing area. For example, the overlapping degree of sensor node i, denoted by

As Figure 3 illustrates, assuming the sensing area of sensor node i is

Illustration of overlapping area.
First of all, we consider a simple case. As Figure 4 shows, sensor node i has one close node and the sensing area of i, denoted by


Sensor node i with one close node.
So, when sensor node i has multiple close nodes,

3.2. Energy Model
This paper only considers the energy consumed in data transmitting and receiving as the energy model used in [2, 5–10, 20, 21]. The energy consumed for data transmitting comes from transmitter electronics and amplifier, and the energy consumed for data receiving comes from receiver electronics. Then, when transmitting one l-bit packet with distance d, the radio expends:

As well, when receiving one l-bit packet, the radio expends:
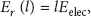
4. The Proposed Algorithm
FPUC consists of two phases: clustering and flow-partitioned routing. In the clustering phase, it first selects candidate cluster heads based on sensor node's residual energy ratio. Then it calculates competition radius according to sensor node's distance to the sink and surrounding node density. After that, CHs are generated on the basis of sensor node's residual energy and overlapping degree. In the routing phase, CH aggregates data received from CMs and then distributes the data flow to gateway nodes which will relay the received data to the next hop with minimum cost.
4.1. Cluster Formation Algorithm
At the time of network setup, the sink broadcasts a message named “Initial (
At the beginning of cluster formation phase, each sensor node broadcasts a “Compete_Head_Msg” message that includes its ID, residual energy, and distance to the sink with max competition radius

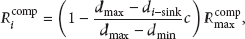

Once finishing computing competition radius, all candidate cluster heads start to compete to be cluster head. In FPUC, it adopts timing broadcast mechanism. The time that a candidate cluster head declares to become a cluster head is defined as follows:

When the cluster head selection phase ends, ordinary sensor nodes wake up. To inform the ordinary sensor nodes to join cluster, each cluster head broadcasts a message named “Construct_Cluster_Msg.” After that, each ordinary node joins the closest cluster according to signal strength and returns a “Join_Cluster_Msg” to notice the corresponding cluster head.
Algorithm 1 is the pseudocode of cluster head selection algorithm.
(0) (1) broadcast a Compete_Head_Msg (2) (3) (4) compute distance between node i and node j (5) (6) (7) find (9) compute (10) (11) (13) (14) sleep (15) (16) (17) compute (18) (19) (20) (21) (22) give up the competition (23) (24) (25) (26) broadcast a Final_Head_Msg (27) (28)
4.2. Flow-Partitioned Routing Algorithm
In this phase, each cluster member first sends data to its cluster head. The cluster head aggregates the data gathered from its cluster members into a single packet, which is assumed L-bit, and then transmits the data to the sink by the way of flow partitioning, which can significantly balance energy consumption among sensor nodes. Figure 5 illustrates an example; to explain the advantages of flow-partitioned routing more clearly and briefly, we make the following assumptions: (1) sensor node i has a Y-bit data packet, denoted by P, to be conveyed and the residual energy of sensor nodes z, v, and g is 0.4 J; (2) the energy consumption for transmitting Y-bit data from sensor nodes z, v, and g to the sink is 0.3 J and the energy consumption for receiving Y-bit of sensor nodes z, v, and g from sensor node i is 0.12 J, 0.1 J, and 0.12 J. So if sensor node i sends packet P to the sink via sensor node v, sensor node i will run out of its energy. If the data packet P is partitioned into three equal packets, denoted by
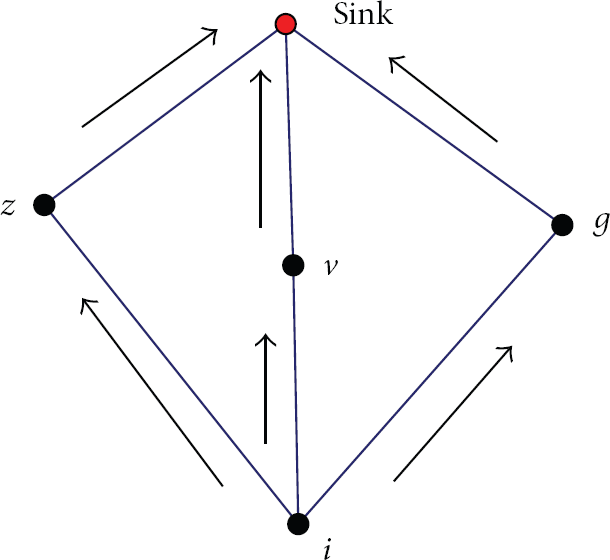
Flow-partitioned transmission.
The flow-partitioned routing algorithm is composed of two phases: data flow partitioning phase and relaying phase. In the data flow partitioning phase, the cluster head partitions data flow into several small packets and then distributes these packets to its gateway nodes. In the relaying phase, each gateway node transmits received data to the next hop with minimum cost. If a sensor node, say j, receives data from a gateway node, sensor node j will send the data to its cluster head.
Figure 6 shows the entire process intuitively. In the data flow partitioning phase, each cluster head, say j, first finds its gateway nodes
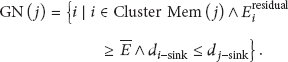

The gateway nodes of a cluster.
Assuming sensor node j has H-bit data to be transmitted, the amount of data to be distributed to each of its gateway nodes, say i, is given as follows:

When a gateway node, say i, receives data sent by its cluster head, it needs to find the next hop to forward data. In order to reduce energy consumption for communication, a distributed strategy is adopted where gateway nodes choose an optimal path for transmission. At the beginning, gateway node i should decide whether to send data to the sink directly or broadcast a message which includes its ID, its cluster head ID, and its distance to the sink depending on whether its distance to the sink The first term in the cost function aims to select the sensor node with more residual energy as relaying node to forward data. Because data transmission will consume energy, the residual energy of a sensor node is a very important factor. The second term in the cost function takes the residual energy of candidate relaying node's cluster head into consideration because when a relaying node receives data, it will send the data to its cluster head. The third term in the cost function aims to select the route that uses minimum energy to transmit data from sensor node i to the sink.

In the data flow partitioning phase, it may occur that some cluster heads, say j, may fail to get their gateway nodes, called “Gateway Hole.” As Figure 7 shows, each of the cluster members that are closer to the sink of cluster head j does not have more residual energy than the cluster's average residual energy. If the problem arises, cluster head j will broadcast a message that contains its distance to the sink with


The phenomenon of gateway hole.
5. Performance Analysis
Lemma 1.
In the cluster formation phase, the message complexity is
Proof.
At the beginning of the cluster selection phase, each of the sensor nodes broadcasts a “Compete_Head_Msg” message, so the total number of “Compete_Head_Msg” messages is N. Assuming that in the cluster head selection phase, Q cluster heads are generated. Thus these Q cluster heads will broadcast Q “Final_Head_Msg” messages. To construct cluster, each cluster head should broadcast a “Construct_Cluster_Msg” message and each ordinary sensor node should send a “Join_Cluster_Msg” message. The number of these two types of messages is N. So the total messages add up to
Thus the message complexity is
Lemma 2.
In cluster formation phase, the upper bound for the number of cluster heads is
Proof.
For each cluster head, there are no other cluster heads in the range of its competition radius. In [22], it has been proved that the maximum overlapping angle between three adjacent disconnected sensor nodes is

Illustration of minimum area of cluster.

Illustration of maximum area of cluster.
Lemma 3.
The total number of messages in the cluster formation phase is smaller than
Proof.
It can be concluded from Lemma 1 that the total number of messages in the cluster formation phase is
6. Simulation Results
In this section, we provide simulation results to validate the effectiveness of FPUC and compare the performance with existing algorithms: LEACH [5], EEUC [7], and FBR [16]. Firstly, we show two performance metrics of the four algorithms: network lifetime and coverage lifetime. Then we analyze the energy balance and overall energy consumption of each algorithm. Besides, to observe the effects of parameters on performance, we also change the network parameters to see the difference. At last, we compare the performance of the four algorithms under uniform and nonuniform deployment situations. The network environment and experimental default parameters are given in Table 1.
Network environment and experimental default parameters.
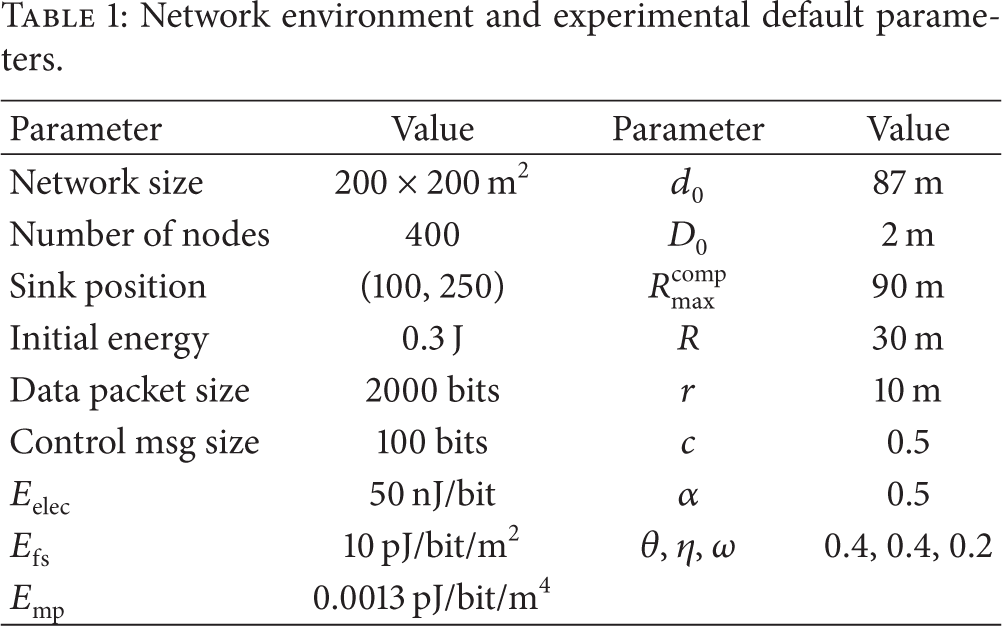
6.1. Comparison of Network Lifetime
In this paper, we use two metrics: network lifetime and coverage lifetime to evaluate the performance of LEACH [5], EEUC [7], FBR [16], and FPUC. Network lifetime is defined as the duration from the beginning to the time when any or a given percentage of sensor nodes die. Coverage lifetime measures the period from the network setup time to the time that network coverage drops below a predefined threshold or application's requirement.
Figure 10 compares the network lifetime of FPUC with that of LEACH, EEUC, and FBR. From the results shown in the picture, we can see that FBR outperforms other approaches and FPUC yields a much longer network lifetime than FBR.
Comparison of network lifetime.
Figure 11 compares the coverage lifetime of FPUC along with LEACH, EEUC, and FBR. Respectively, FPUC can achieve better coverage lifetime than the other three protocols and when the first sensor node runs out of energy, the network coverage ratio is still kept at 100%.

Comparison of coverage lifetime.
6.2. Energy Consumption
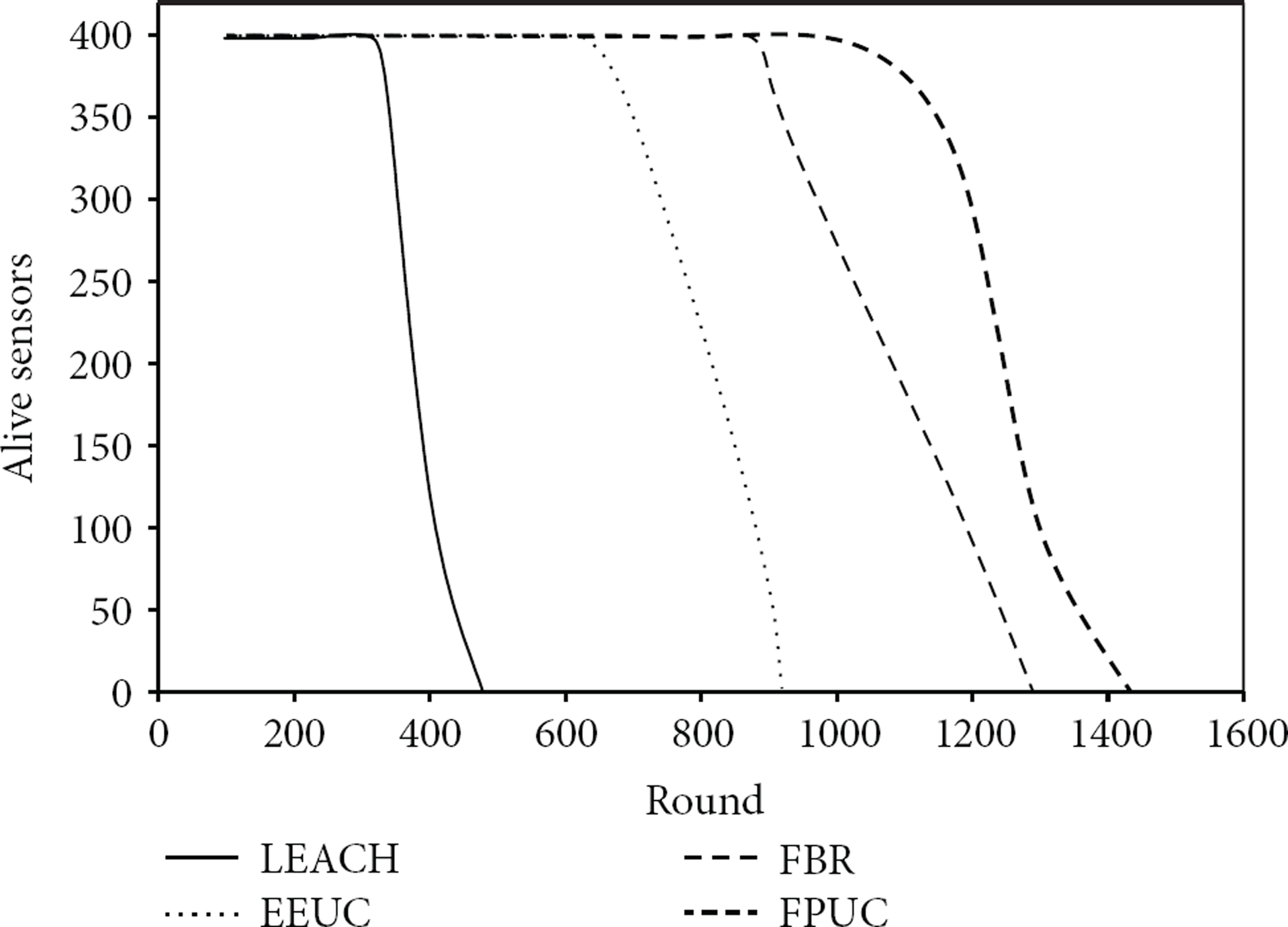
For wireless sensor networks, the algorithms that aim to improve the lifetime need to have the following two features: (1) minimum total energy usage; (2) balanced energy consumption. Figure 12 shows the energy consumption over time of the four algorithms. Figure 13 represents each sensor node's residual energy at the 100th round of LEACH, EEUC, FBR, and FPUC.
Energy consumption of the four algorithms over time.

Each sensor node's residual energy of various algorithms at the 100th round.
We can have the following conclusions from Figures 12 and 13. The energy consumption in each round of LEACH and EEUC is much more than that of FBR. And FPUC consumes relatively less energy than FBR. In Figure 13, we can clearly know each sensor node's residual energy at the 100th round of the four algorithms. Figure 13(a) is the distribution of each sensor node's residual energy of LEACH. It can be easily seen that the sensor nodes closer to the sink have much more energy than those sensor nodes far away from the sink. Figure 13(b) is the distribution of each sensor node's residual energy of EEUC. Obviously, the sensor nodes far away from the sink have much more energy than those sensor nodes closer to the sink. Figure 13(c) is the distribution of each sensor node's residual energy of FBR. Respectively, the energy consumption of FBR is relatively more balanced than LEACH and EEUC. Figure 13(d) is the distribution of each sensor node's residual energy of FPUC. Compared to LEACH, EEUC, and FBR, the total energy consumption among all sensor nodes of FPUC is more balanced. However, the sensor nodes closer to the sink still consume more energy.
The reasons for the above results can be summarized as follows. In LEACH, the data is transmitted to the sink directly; that is to say, the farther the sensor node is, the more energy the sensor node will consume when forwarding data. Thus, the sensor nodes far away from the sink will consume more energy. In EEUC, it adopts multihop data transmission, so the sensor nodes closer to the sink will be loaded with more data forwarding traffic, thus consuming more energy. In FBR, because the flow-balanced routing is used, the energy consumption is balanced in a degree. However, because only the cluster heads convey data and the cluster formation is performed only once, the cluster heads will run out of energy faster. In FPUC, the cluster heads and cluster members share the burden of data traffic at the same time and unequal clustering is adopted, thus leading to more balanced energy consumption.
Figure 14 shows the distribution of dead sensor nodes when 10% sensor nodes die. We can see that the distribution of FPUC is more uniform in comparison with the other three algorithms.

The distribution of dead sensor nodes (10% sensor nodes die).
6.3. The Effects of Network Parameters on Performance
6.3.1. Varying the Number of Sensor Nodes
First we evaluate how the number of sensor nodes affects the performance. From Figure 15, we can draw the conclusion that the number of sensor nodes has a little effect on the performance of LEACH. When the number of sensor nodes increases, EEUC, FBR, and FPUC can achieve longer network lifetime in some degree. In EEUC, increasing the number of sensor nodes can contribute to select a more optimal relaying node when forwarding data. In FBR and FPUC, there will be more sensor nodes to share the burden of data transmission if the number of sensor nodes increases and the energy consumption will be more balanced.
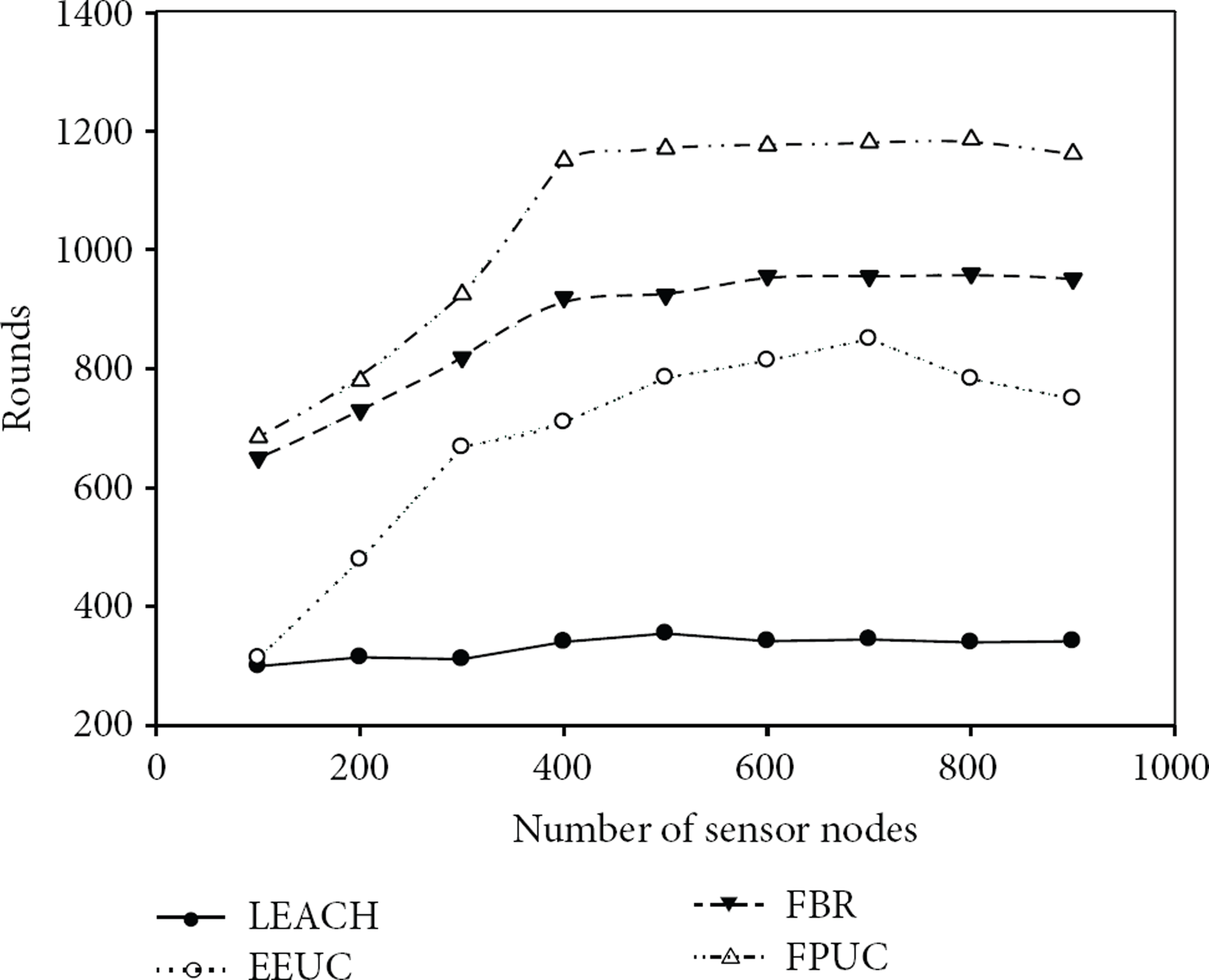
Network lifetime under different node density.
6.3.2. Varying the Value of Parameter α
Figure 16 shows how the parameter α affects the network lifetime of FPUC and Figure 17 shows the effects of parameter α on the coverage lifetime. It can be seen that the performance is the best when α is 0.5.

The effects of parameter α on network lifetime (when first sensor node dies).

The effects of parameter α on network coverage (when first sensor node dies).
6.3.3. Varying the Node Distribution
From the results in Figure 18, we can see that the network lifetime of LEACH, EEUC, and FBR under the uniform distribution is longer than that under the nonuniform distribution. But the distribution has a little effect on the performance of FPUC because it can also generate a reasonable topology under the nonuniform distribution.

The effects of node distribution on network lifetime.
7. Summary
In this paper, we have proposed a new flow-partitioned unequal clustering routing algorithm. In the clustering formation phase, it first computes the competition radius according to the node density and the distance from a sensor node to the sink. Then it selects the sensor nodes with more residual energy and larger overlapping degree as cluster heads. In the data transmitting phase, flow-partitioned routing is adopted, where cluster heads and cluster members share the burden of data forwarding together. Comprehensive simulation results demonstrate that FPUC can significantly improve network lifetime and coverage lifetime comparing with LEACH, EEUC, and FBR.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (61303204, U1333113), the Sichuan Province Science and Technology Support Plan (2012GZX0088-1, 2011GZ0188), and the Scientific Research Fund of Sichuan Normal University (13KYL06).