
Abstract
This paper proposes and describes a trust model for distributed systems based on groups of peers. A group is defined as a collection of entities with particular affinities and capabilities. All entities may have a trust and a reputation value of each other in the system. In many cases it may be necessary to trust the whole system instead of one particular entity. In such cases group trust represents the trust of their particular members. To achieve this, this paper presents a group trust calculation model. We implemented the proposed model in a P2P simulation tool and presented main results for group trust calculation.
1. Introduction
Nowadays, distributed systems have become very complex environments in that hundreds of nodes have to collaborate in order to provide large-scale services. Some examples can be P2P networks, multiagent systems, grid systems, cloud systems, and so on. In these scenarios, trust between entities becomes a crucial factor as a way of determining the reliability of the different nodes in the system and to detect and predict misbehaviors and security threats. In these environments, trust can also help in the veracity of the system.
Considering that the Internet nowadays has so many different types of things connected to it, there is no known way of dealing with the amount of information or data that is necessary to verify if systems are fully reliable. This amount of connected elements and its functions are commonly named Internet of things [1]. Once that so many possibilities of information and systems are connected and a lot of them interoperable, the amount of security threats also increases significantly because of the complexity, distribution, channels, data, and networks, which make the traditional security approaches inefficient. This also leads the technology and researches towards new manageability challenges.
It has become clear that new trust management systems are necessary in order to accomplish security related to distributed system [2] considering the amount and variety of systems connected. The management of trust relationships between different peers belonging to a distributed system can be done using different approaches. The trust relationships can be manually established by each node in the network around the rest of the nodes. This manual approach does not scale when the number of nodes becomes bigger and bigger, so other approaches based on a trust model are used to automatically calculate how much a node can trust other nodes. Usually, a given node follows a trust model to determine if a node is trustworthy or not depending on two different aspects: (i) trust values are locally calculated and (ii) trust values are provided by the rest of the nodes in the network (reputation).
Current trust models are generally used to calculate one-to-one relationships between nodes. This means that an entity A needs to determine the trust value for all the other entities available in the distributed system, which has to communicate with A. In large-scale scenarios, this fact is an important lack of scalability in distributed systems due to the fact that A needs to calculate and maintain as many trust relations as the number of nodes necessary to accomplish A's work. Other scenarios consider several entities as a single node for trust purposes. For example, a distributed file system could be seen as a single entity even though it is composed of several subentities and a security threat in any of them may compromise the complete file system. This kind of simplifications may cause a lack of the accuracy of the current models.
When A needs to communicate with a group of nodes having the guarantee that the group itself is trustworthy, A wants to independently form an opinion about the whole group. If this is the case, it may be necessary to establish communication with every group member. This makes entity A start an exhaustive process of discovering every member of the group. In most practical situations this is not a good idea because it will make entity A try to find maybe thousands of nodes in a network. This consumes time and resources for entity A and may not be the best approach to achieving its objectives.
To address these problems, the main contribution of this paper offers a novel extension to conventional trust models that enables the support for calculating the trust values for groups of nodes. A group is defined as a collection of entities with particular affinities and capabilities. Then, the entities which need to interact with a given group are able to find a trust value for the whole group directly, thus avoiding the necessity of discovering the whole group members and providing more accurate information about the group than approaches which consider the group members as a single entity. The extension provided has been implemented and validated by means of a set of statistics.
In order to describe the proposal, this paper is organized as follows. Section 2 reviews some aspects and definitions about trust and reputation. Section 3 discusses some related work of different trust models for distributed systems. Section 4 presents the proposed group trust model. Section 5 shows implementation results and Section 6 ends this paper with the conclusions and future works.
2. Definitions
The concept of trust and its definitions has been studied by many authors and is part of many research projects. Trust is recognized as an important aspect for decision-making in distributed systems [3–6], but there is no general consensus in the literature on the definition of trust and what trust management comprehends. For example, Patel [7] considers that trust in computational relations may be focused on the optimized selection of a communication partner and on the decision of agreements between two or more members of the network. That is particularly true in distributed environments where there is no certainty about the destination and the communication process can be easily deceived. Gambetta [8] considers trust as a particular level of subjective probability and Marsh [9] says that trust involves probability and this permits a representation of trust in values between zero and one.
This approach creates a concept where a trust value ranges from 0, which means complete distrust, to 1 which means complete trust. This value may suffer interference of nodes, betrayal, and so forth. Moreover, complete trust is not desirable in most scenarios because it eliminates any possibilities to suspect any particular node. Figure 1 illustrates this consideration.
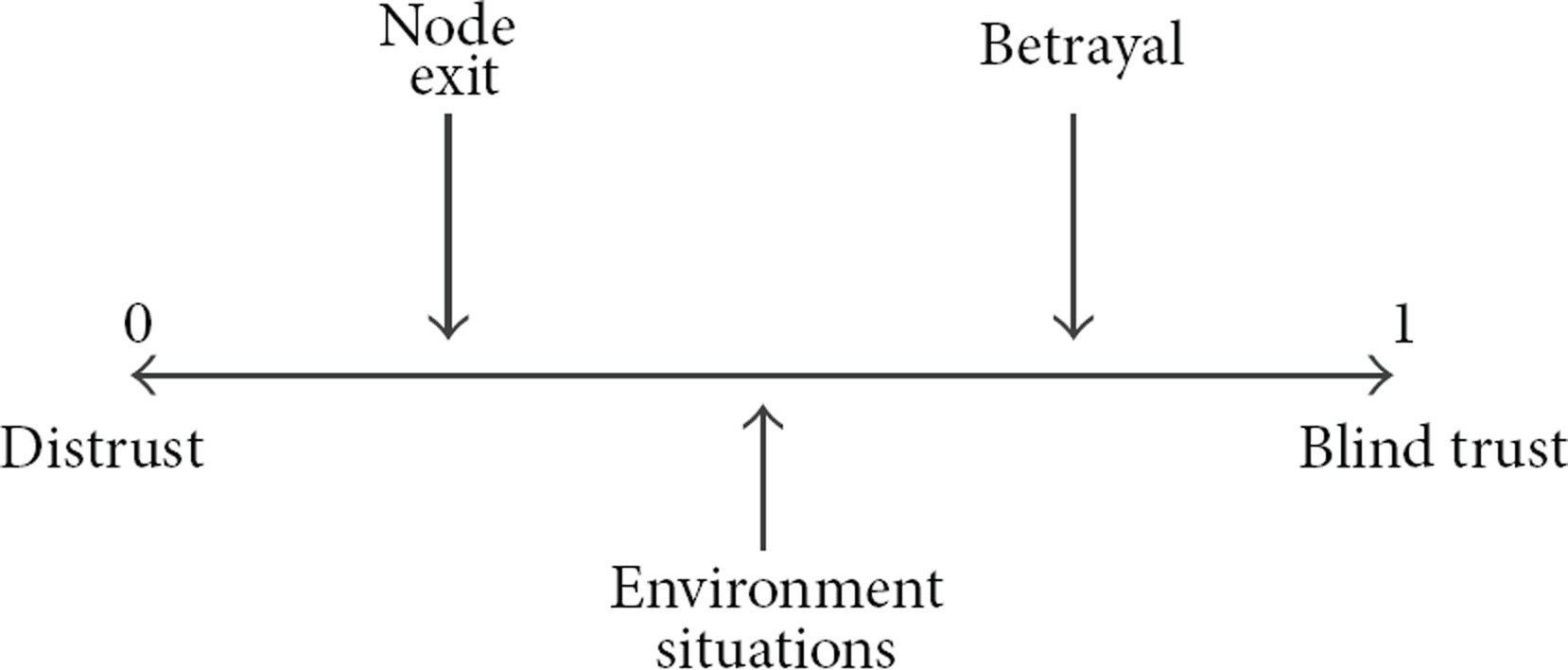
Trust or distrust and influences.
There are common aspects in almost all the references about trust models that make us determine a common set of features related to trust. These features can be summarized in Table 1.
Summary of common set of trust characteristics.

As opinion, it has many subjective evaluations depending on several factors like situation observed (context), own trust value inference, information received by others in a social relationship, and so forth. The reputation value evolves with time and directly depends on the behavior of the entity being observed. Reputation may also represent indirect trust. It includes asking for the opinion of other parties with whom the entity has previously interacted in the past about a third entity. Reputation can also be defined as the common opinion of others regarding an entity [7], which may be used in the absence of trust formed from personal opinions. Reputation values take time to be acquired, but it can be easily lost in social aspects. Calculation of reputation values is done using past information that has been obtained during time and based in the information that was received from trusted parties. These variables enable an entity to form an idea about an unknown entity. It could be considered as a social evaluation of an individual or group of individuals.
3. Related Work
There is an important number of research works providing trust models for different distributed scenarios such as grid computing, P2P, multiagents, ad hoc networks, wireless sensor networks, and cloud computing. This section provides a review of trust and reputation models in order to motivate our new trust model in context with the other works. Regarding trust models for Zhao and Dong [10] present a trust model multidomain grids scenarios and consider that trust can be used to evaluate the relationship between grid resource providers and grid consumers. Jingshan et al. [3] present a trust model for grids based on the information provided by the last service used. According to the authors, their proposed model achieved less resources occupied, increased flexibility, and prevention of threat of malicious evaluation and cooperative cheating in the grid. GridTrust [11] security framework is able to provide trust management in vertical and horizontal approach in the grid. GSF is based on layers and policies that control and monitor users activities in such a way that security and trust are guaranteed by their model.
Regarding trust models for P2P, the novelty and strong point of the model proposed in DWTrust [12] is that all the factors that have influence on the trust value for a particular node are represented as dynamic weights that adapt themselves depending on the trust policy of each node. AntRep [13] is another trust model where reputation evidence is distributed over a P2P network based on the swarm intelligence paradigm [14]. In AntRep each peer has a reputation table (RT) which is very similar to the distance-vector routing table [15] but differs in the following aspects: (i) each peer in the RT corresponds to one reputation content; (ii) the metric is the probability of choosing each neighbor as the next hop instead of the hop count to destinations. EigenTrust [16] has become one of the most cited trust models for P2P networks. It achieves a decrease in the number of downloads of inauthentic files in a P2P file-sharing network by assigning each peer a unique global trust value, based on the peer's history of uploads.
Regarding trust model for mobile ad hoc networks (MANETs), Chang et al. [17] propose a Markov chain-based trust model to determine the trust value for each one-hop neighbors in multicast MANET and the results indicate that the convergence speed is independent of the trust classes and of the initial values of the proposed model. Liu et al. [4] present a reputation model able to use subjective opinions with familiar values in order to prevent selfish behaviors in MANET. Nodes accumulate reputation information and create a familiarity value used to compute impact of reputation recommendation. RRS for P2P and MANETs [18] present an enhancement of CONFIDANT [19], which is a robust reputation system for P2P and mobile ad hoc networks where everyone maintains a reputation rating and a trust rating about everyone else they care about. PTM [20] is a decentralized trust model which expressed trust relationships with fuzzy logic. These relationships can be established as direct or indirect. In the former, A will trust B without intervention of third parties. In the latter, the indirect trust relationships are given by recommendations from TTPs. A TTP is a peer who has a trust value higher than a certain threshold. Such recommendations are distributed using a pervasive recommendation protocol (PRP) among close entities.
Regarding trust models for multiagents systems, TRAVOS [7] consists of a trust and reputation model for virtual organizations based in agents, in which trust is measured using probability. The evaluation of the amount of trust is based on past interactions and reputation obtained by other nodes. Sporas [21] is another reputation mechanism in agent systems where the reputation is computed recursively and where the more recent a rating is, the more weight it has. MTrust [22] uses a Bayesian network to calculate the trust value among entities in the network. It is focused on a mobile agent system, where the cooperative interactions among these agents and their respective visited hosts are ensured. Regret [23] (one of the most representative trust and reputation models in multiagent systems) manages reputation from three different dimensions: the individual one, given from direct interactions with the agent; the social one, from previous experiences of group members with the agent and its acquaintances; and the ontological one, given by the combination of multiple aspects in order to build a reputation about complex concepts. AFRAS [24] proposes a reputation mechanism in multiagent systems whose main characteristic is the modeling of an agent reputation and the interaction rating as fuzzy sets. In case the reader is more interested in how many of the previous models are being calculated, Gómez Mármol and Martínez Pérez [5] provide a very complete and comprehensible survey of trust models for distributed systems.
Largillier and Vassileva [25] argue that group formation is a difficult task. It has many different contexts and groups can be formed based on users criteria or using methods that matches what users desire. In most cases it does not take into account previous successful or unsuccessful collaborations to forge new ones. Considering this, their work proposes a model of collaborative trust to help select the criteria that is the best fitted group for a task. Al-Oufi et al. [26] explain that in order to protect users it is important to identify trustworthy people. Their work extends the Advogato trust metric [27] so trustworthy users can be identified. The authors [26] claim that their model has advantages over existing representative methods because it is able to discover reliable users and prevent unreliable users. Easa et al. [28] say trust is used in soft security and proposes a group-based trust method to propagate information among peers. They also consider two factors called intermediate group confidence and group confidence used between two groups.
Related to trust and the Internet of things, Saieda et al. [2] propose a new trust management system and design a context-aware and multiservice trust management system fitting the new requirements that the authors consider important in their model. Schulz and Tjstheim [29] point out that, when there are interactions with objects and services in the Internet of things, usually the users need to trust that their data is safe and that things will fulfill their promise. Wang et al. [30] consider trust management as a way of providing a potential solution for the security issues of distributed networks and propose a new distributed trust management mechanism for the Internet of things. They propose a model using sensor, core, and application layers which provide a general framework for the study of trust management for the Internet of things.
All this preview work shows that trust is used in many different distributed technologies. Very few works consider the group aspect of distributed system as an important characteristic to help provide security and reliability in distributed systems. It is also important to remember that trust and reputation have increased significantly in recent years and nowadays they are being considered as important factors to help extend the functionalities in distributed systems.
4. Group Trust Model
This section describes the extension for supporting groups in trust models. This extension enables the definition of trust values over both groups and single entities. A group is defined as a collection of entities connected together with common goals or even common contexts. Thus the entities are able to perform specific works in a common context like service offering. Moreover, the entities are also able to perform trust and reputation calculation of other entities in the system that considers any interaction. This group extension can be deployed over a system in which entities use any trust and reputation model that attends to the system needs. This work just considers that there is a trust and a reputation algorithm that can perform trust and reputation calculations and is considered as an extension over such algorithm. The trust added value is a consequence of the individual trust values of the group members. The added value represents a point of information for external entities so they can use it to infer the whole group trust value.
To perform a trust calculation over a group, it is a requisite of our model that there should be a leader in the formation of the group. It is not easy to determine a leader for holding trust information and thus a method by consensus is adopted to determine the leadership of the group. Entities in a group may be able to agree to a minimum level of trust (trust threshold) in order to make a common analysis and commonly choose a leader based on trust. The problem is that not every entity has the same trust value about any other entity. This is because trust is calculated by every entity using its own ability and making use of its own inferences.
Entities may agree in an ordinary value of trust and also agree that this value is enough to assume that one specific entity can represent the whole group. This assumption transforms the chosen entity to the leader of the group. In real distributed system scenarios where every node can perform its own decision, such agreement is very difficult because entities must exchange trust and reputation information that should have been defined previously considering, for example, security aspects as availability and integrity. However, if it is assumed that an entity should not trust other entity if its trust value is not inside a specific range, this entity could avoid exchanging information with another in the system thus leading to a complete failure of acquiring enough trust information to create trust consensus. Besides, this should consider that some basic factors are commonly known and used by every entity in the system and that may not be true in most distributed systems. If it is considered just voting schemas for a leadership choosing process, this may not represent consensus because what an entity does is just to vote. In other words, it is to choose one among many options. Voting schemas, in general, do not consider consensus in a distributed manner, which contradicts the trust aspects. It is not the objective of this work to develop a trust consensus algorithm or a trust consensus model in order to choose a leader.
To have a consensus process enables entities to express their opinions about the leadership election process. It is important to observe that any entity in the group may be the potential leader of the group. One prerequisite is that the candidate entity has trust and reputation values expressed by the members of the group. Extending this view, any entity may announce its preferred candidate also depending on the context. That makes the leadership choosing process more complicated than just voting. For example, an entity could be responsible for taking other entities opinion and announcing in the network who has the most elevated trust value among
So, once a leader already exists in the groups, entities in the group have agreed that this leader is the representation of the group for new members and for the outside world. It is normal that entities may not be able to be actuated in every context available in the system. For example, one entity may be able to upload files but may not be able to perform matrix calculation. So it is a requisite to the model that the leader in the group knows every context in order to be able to calculate the trust information of the group for all such contexts available within the group. Thus, let's define how to calculate the trust value of the groups. Firstly, the reputation that entity B has for entity A in a particular context C is represented in the following equation by notation 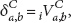


In our model, we consider that what best represents the trust value of a group is the reputation that every entity within the group has about all entities of the group that it is part of. Then, the trust value can be calculated as an average reputation of all members inside the group. Considering this, the leader of the group receives and organizes the reputation values of the rest of the entities and computes the trust value of the group. For example, let's consider an example group of 5 members
It is important to remember that there is no common trust communication protocol for exchanging information in distributed systems. We assume in our model that the protocol to exchange information with the leader can be proactive, reactive, and hybrid depending on the scenario in which the protocol is deployed. Note that in some scenarios the members of groups already know who is the leader and then can proactively send such information. A new member can always ask for the leader of the group, so we assume that the node is able to find and communicate with the leader. Once this process is defined, the leader computes the final reputation of each entity as the average of the reputation values provided by the rest of entities within the group:

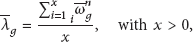
In the case where there are many groups (N), every group leader can perform its own trust value calculation and inform its trust value to other group leaders. Every group leader has the responsibility to store group trust information, send it when asked, and distribute this value to new members, new leaders, and group outside requests as well. As seen the group role is very important, so the leader must be chosen carefully.
In order to create a common process to perform group calculation the algorithm represented in Figure 2 can be used.

Algorithm for group trust calculation.
5. Implementation and Analysis
The proposed model has been implemented and some statistics results have been obtained in order to validate it. In essence, a testbed has been set up by means of a P2P simulation tool [31] to create a basic group and to develop all calculation processes. The simulation tool uses asynchronous interactions between machines and different scenarios were simulated according to specific policies in the network. Some assumptions were defined in the test environment in order to organize the tests. For simplicity, the testbed is accomplished assuming that peers do not lie about trust and reputation values in the network. However this behavior can also be detected using the underline trust model used in the proposal. All participants are doing the same number of interactions in the testbed. The objective is to find standards and verify certain behaviors about trust and reputation values in the system.
When interactions between entities correspond (or not) to the expected behavior, it can be determined if the peer is trustworthy (or not). Some behavior patterns have been delimited as desirable in the system. Firstly, there are no errors in the communication transmission; secondly, the time for transmitting a file is determined by the quality level of the transmission. These parameters have been chosen in order to simplify the P2P environment, thus permitting the focus of the analysis on trust and reputation values considered in the interactions of peers and performing the calculation of the group trust value.
The testbed is executed in machines with JXTA Shell [31] installed and configured. The simulated environment was composed of 500 nodes. These were defined as 5 different groups with a hundred nodes in each group. Each node only performs interactions within its group. Also, each peer performs at least 20 interactions in the network. The network topology is simple and uses 2 common layer switches. The purpose of this topology is to represent a P2P network connected directly to a LAN. The peers are configured in the same network segment with no additional hops. Each peer uses a different TCP port. This characteristic is to permit the P2P network to establish connections on different ports.
The simulation testbed considered that the transmission delay and the integrity of the file are the parameters used to decide whether a peer is malicious or not. This means that the peer can send a corrupted file, delay its sending to another peer, or perform both. The interval of time values for the transmission is defined after some file transfer tests were executed. Several interactions have been fulfilled for a file with fixed size (100 Kbytes), and a standard time could be defined for a successful interaction.
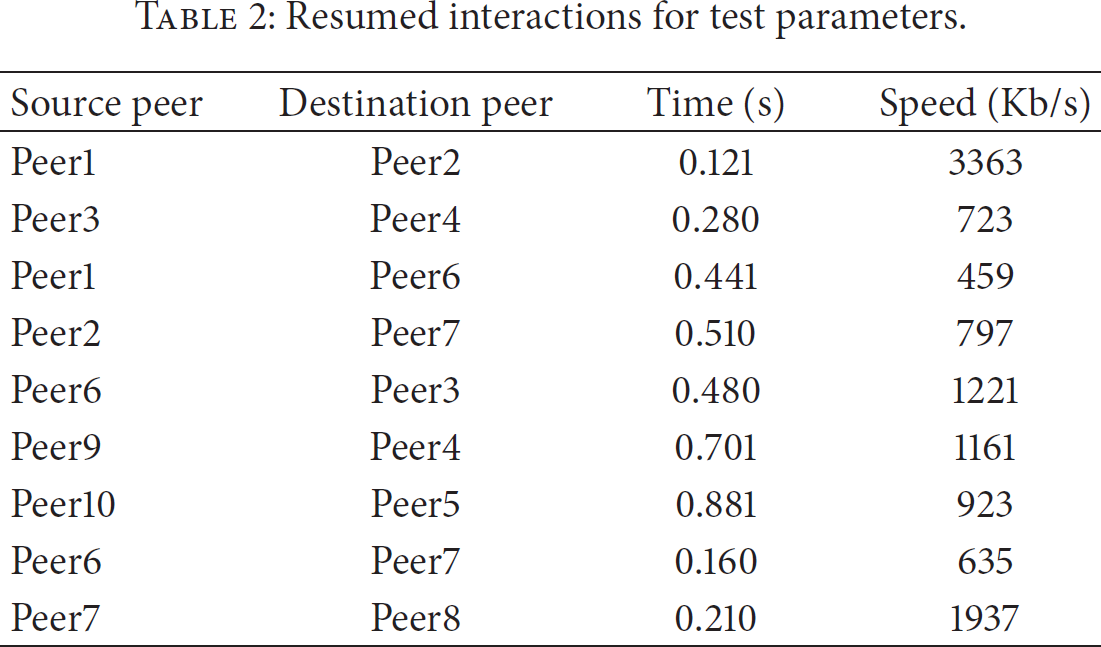
Table 2 has some summarized definitions of the test interactions to limit the values expected. Based on this information it has been determined that the expected transference time of a file is up to 1 s, a short delay would be between 1 s and 2 s, and a completely delayed is above 2 s. The other parameter defined is the integrity of the received file. A hash calculation is used to verify this condition.
Resumed interactions for test parameters.
Once this parameter is defined, the file load times are parametrically determined by the variable a, the file integrity check times are determined by the variable b, and the variable c determines the reputation feedback for the trust model associated with the given interaction. Table 3 shows the parameters used in our testbed to define how to infer some reputation for a peer.
Probable situations considered.

The reputation value c is determined by the following equation, where the parameter P represents the weight (importance) that the network administrator allocates to the integrity of the file:
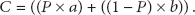
Related to peers behavior, peers only accomplished interactions with appropriate parameters to verify the convergence of trust and reputation values. The underlying trust model used in the testbed is TRAVOS [7], which allows peers to realize that some members of the network changed their behavior. The testbed has been set up in order to have peer1 as leader of each group. Once all these parameters were set up, we defined different scenarios for our tests. Direct trust of the peers and reputation values based on context of the groups are calculated in the simulations in order to calculate group trust. The tested scenarios, its results, and analysis are presented in the following subtopics. In all graphs the x-axis is the number of interactions and the y-axis is the correspondent trust value in each round.
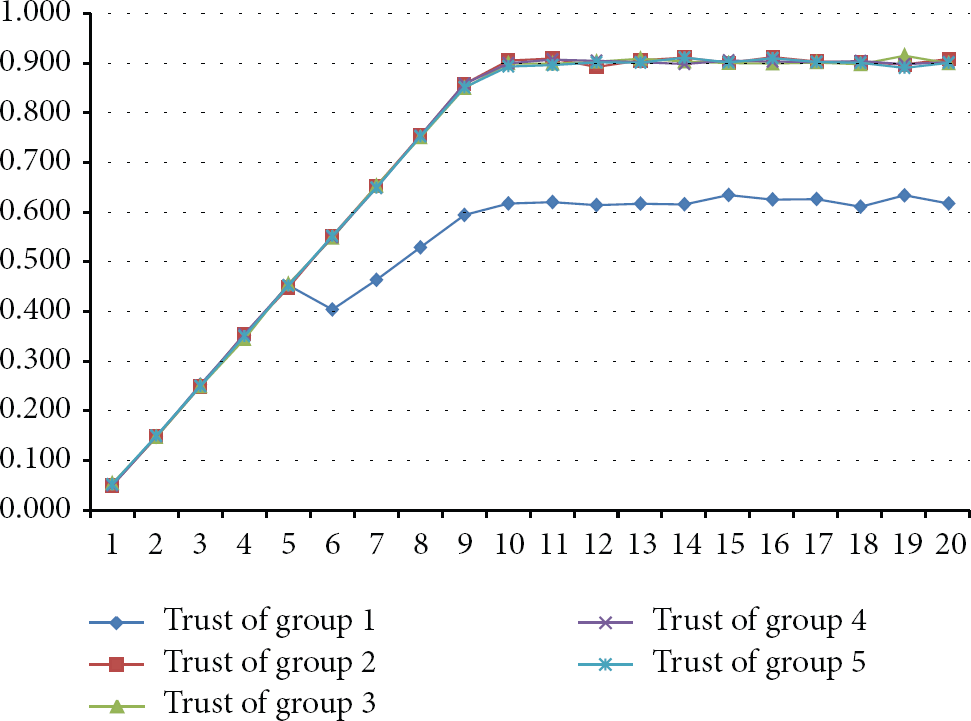
5.1. Scenario 1: All Peers Behave Accordingly
In this test all the peers in all groups behave as expected. This means that they fulfill their requirements and perform their defined context correctly. Note that the entire peer acts following the same behavior, without changing any aspect of its functional context. In this case, the trust value of the group is considered extremely trustworthy and it tends to stabilize in a value near 1, thus avoiding blind trust. When there is no malicious peer in the network, the trust value of the group reflects the individual behavior of the peers in the group. This is considered the ideal world. Figure 3 shows this result.

Group trust of an ideal environment.
5.2. Scenario 2: Random Behavior of Peers
In this test all peers in all groups behave randomly after round 4. This means that it is not known for certain by the other group members whether a particular peer behaved accordingly or not. This test was set up in order to verify the results when nodes behave in a proper manner sometimes and then change their behavior with no particular reason. This can be considered the worst environment imaginable because it cannot be possible to predict if a node will or will not behave accordingly. This scenario is represented in Figure 4.
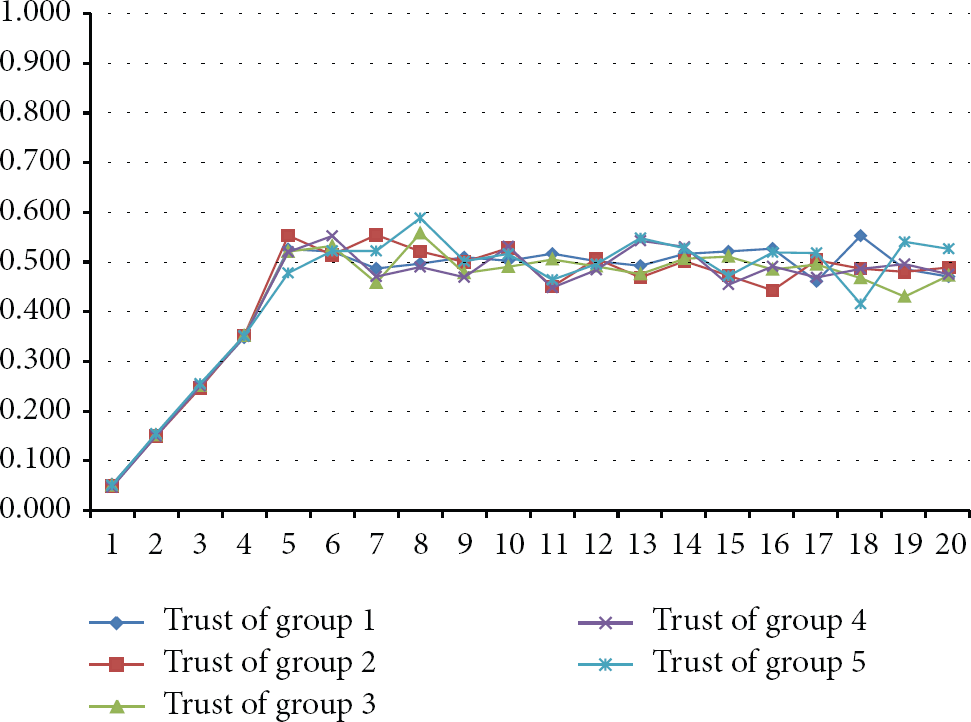
Group trust of the worst environment.
5.3. Scenario 3: Random Behavior of 20 Peers in Group 1
In this test 20% of group 1 behaves randomly. This test simulates a coalition of peers in order to modify the group trust. Such behavior is considered as if the nodes suffer some kind of attack or there are peers acting as black holes in the P2P environment. When 20% of the peers start behaving in a malicious manner, the trust value of the group decreases and tends to stabilize in a value near 0.8. The analysis shows that the increase of the trust coefficients provided by the good peers overcomes the decrease of the coefficient of the malicious peers. In this case the group is still considered trustworthy (

Group trust of G1 when 20 nodes change their behavior.
5.4. Scenario 4: Random Behavior of 40 Peers in Group 1
In this test 40% of group 1 behaves randomly. This test simulates a situation where the P2P network is compromised and there is no guarantee that the peers in this group are trustworthy or not. When 40% of the group members are malicious, the trust coefficient of the group tends to stabilize in a value near 0.6 which represents that the peers in the group are not trustworthy, and thus the group is not considered trustworthy because of the threshold. Figure 6 shows this result.
Group trust of G1 when 40 nodes change their behavior.
5.5. Scenario 5: Random Behavior of 60 Peers in Group 1
In this test 60% of group 1 behaves randomly; then the trust coefficient tends to stabilize in a value near 0.5, also making the group untrustworthy because of the threshold, as seen in Figure 7.

Group trust of G1 when 60 nodes change their behavior.
5.6. Group 1 Analysis
This test was performed to analyze group 1, compiled in one graph, as seen in Figure 8. When peers change their behavior, the trust value of the group decreases, thus making a group with constant behavior change to be untrustworthy considering a defined threshold of

Group 1 synthesis.
The reader may realize that the individual behavior of each member in the group influences the trust value of the group as a whole. The results can also be considered satisfactory because all the peers are initiated at the same time in the network and interact with each other the same number of times.
These results also show that the trust value of group 1 in the first scenario is originally high (moment in which all the peers have good behavior). After that, it starts to decrease in the moment the peers in the group change their behavior or acts forming a coalition. As a result, the group trust model can be used as a parameter to interact or not with a specific group.
6. Conclusion
This work has reviewed different trust and reputation models in distributed systems. We developed a model as an extension to support the calculation of trust values of groups of entities. The proposed model has been validated in a P2P simulation tool. Our results show that it is possible to generate and to calculate group trust behavior in distributed systems.
We consider that it is important that a trust leadership based algorithm or a trust consensus algorithm should be better studied in order to create leaders in groups in a distributed manner. It is also important to define a trust protocol as a platform to support trust based communications. We consider that as research areas that can be deeply studied.
Using the concept of group trust, the proposed model in this paper can be used in bigger and more complex distributed systems architectures. As future work we will implement our group trust model in software agents, grid platforms, or cloud environments in order to evaluate its behavior in bigger systems.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
Part of the computations of this work was performed in EOLO, the HPC of Climate Change of the International Campus of Excellence of Moncloa, funded by MECD and MICINN. The first author acknowledges the Laboratory for Decision Technologies at the University of Brasilia (LATITUDE/UnB) for its support to this work.