
Abstract
With the increasing growth of media cloud technologies, web service technologies, and smartphones equipped sensors, a number of collaborative media services are being built for ubiquitous user access. Currently, collaborative services are being used in several areas like healthcare, defense, education, and so forth. However, due to the challenge of providing such service to users in terms of computations, communications, processing, and storage, there is a growing need for an infrastructure to have on-demand access to a shared pool of configurable computing resources (e.g., networks, storages, servers, applications, and services). Cloud computing is such a paradigm or infrastructure to provide configurable platform to support the collaborative service. In this paper, we present the corresponding framework of collaborative media service for efficient collaboration between caregivers and healthcare professionals. The experimental results not only showed our solution is more efficient than the similar system but also proved that our solution can work well for web service-based collaborative environment.
1. Introduction
Current end systems include a wide diversity of devices that are heterogeneous in terms of sensor processing capacity and capability [1]. Devices vary from full multimedia workstation, to smartphones, to PDAs. A major problem is to create and deliver content that is rendered properly by these handheld devices ubiquitously. The challenge is to deliver the collaborative service to diversity of users who accessed media contents (e.g., video, image, audio, voice, and other documents) through resource limited devices as media (e.g., video, image, audio, and other documents) sharing in the form of video conferencing, web conferencing, discussion service, and so on. Collaborative service can be defined as a service through which interactive information (e.g., audio-visual content, voice, SMS, text, etc.) is interchanged or exchanged between two or more participating users.
Collaborative service for distributed user clients over an overlay network (WSN) is challenging due to its heterogeneity in terms of limited capability, user preferences, communication technologies, sensing features, and strict demand for sensor as well as media processing service at the client side that is equipped with different handheld devices. These current handheld devices (e.g., iPhone, Samsung's Android Phones, Google's HTC Android, etc.) are equipped with a rich set of sensors such as camera, audio, accelerometer, and microphone for accessing the media (e.g., image, video, and audio/voice) content ubiquitously through web or networks. However, due to (a) intensive requirements in resources and infrastructure, (b) adaptation or transcoding requirements with regard to changing the configurations of the handheld devices, (c) real time processing and storing of the sensors as well as healthcare data, and (d) finally the limitations of resource-hungry client side processing, it is difficult to provide seamless collaboration for quality patient care. Therefore, there is a need for new adaptability and scalable techniques for media collaborative service on cloud, where collaborative server or service manager can add or utilize media service for seamless collaboration using metadata, media technology, web service technology, and finally cloud as a service for storing, delivering, and customization.
Currently, cloud service allows healthcare professionals to maintain heath records, collaborate with fellow healthcare professionals, analyse patient health record (PHR), and monitor patients for quality care [3]. The user or system can use cloud services [4] as Infrastructure as a Service (IaaS), Software as a Service (SaaS), and Sensing as a Service (S 2 aaS) [1] to provide storage, processing, and sensing services for supporting collaborative applications without physical storage devices being installed with none or minimal user intervention and without interruption to the service that is accessed through web interfaces. These cloud-enabled collaborative applications enable communications between healthcare professionals in terms of live discussions, recommendations, multiparty conferencing, and so on for quality patient care. Several cloud hosting providers such as Amazon, Google, and Microsoft offer the cloud service at a very low cost at anytime from anywhere on the basis of pay per use services.
In this paper, we propose a framework of collaborative media service for efficient collaboration between doctors and healthcare professionals. Specifically, the framework is designed for the rehabilitation of the patients having voice pathologies. A patient can give his or her voice through a smartphone, which is used as a media sensor. Media content server (MCS) receives and transmits it to the cloud manager (CM). The CM sends the voice data to a collaborative service manager (CSM), and the CSM uploads the information to the web for the use of a family doctor. In the CSM, there are servers dedicated to the extraction of features from the voice, to modelling normal or pathological samples, and to classifying the samples. After analyzing the information, the doctor prepares a report or feedback and sends it to the CSM. If the family doctor needs to check the report by an external doctor, the report can be accessed by the doctor through proper authentication. The doctor can analyze the report and upload his feedback. It is then processed in the CSM and stored in the CM. The patient can get the feedback from the doctor from the CM. One of the main problems of this collaboration between the patients and the doctors is to maintain the quality of the voice during transmission, because pathological voice is already noisy. In this paper, we propose a new feature set, which is less affected by the transmission, for voice pathology detection, and evaluate it using a commercially available voice database.
Our proposed framework has some important features. Firstly, it provides seamless audio-visual collaboration among participants such as caregivers, physicians, and patients for potential health monitoring, quality care, and decision. During collaborations, we make use of Extensible Messaging and Presence Protocol- (XMPP-) driven client along with smartphones’ sensing [5] (e.g., video cameras, and microphones) service as well as their built-in collaboration features (e.g., SMS, Telephony, email, and conferencing) for possible handling of communication, storing, and retrieving data based on users’ requests. Secondly, it provides service-based architecture to support agility, flexibility, and scalability of service by exploiting the cloud infrastructure system. With the said service-based architecture, the collaborative server or service manager can add or utilize or share media service for seamless collaboration using Web service technologies (SOAP, XML, WSDL, and XMPP) [5, 6] and smartphones’ built-in communication features. Thirdly, we show how this proposed framework facilitates collaboration between the caregivers by considering a voice pathology assessment scenario, where doctors, caregivers, and patient collaborate with each other to assess the voice pathology.
The rest of the paper is organized as follows: Section 2 describes related work regarding collaborative service. Section 3 presents the system architecture of the proposed collaborative media service framework in detail. Section 4 reports the results and discussion of the framework which facilitates collaboration between the doctors and a patient by considering a voice pathology assessment scenario. Section 5 concludes the paper.
2. Related Studies
Today the proliferation smartphones, cloud computing, and heterogeneous high speed networks (WSN, WBAN, and Wi-Fi) have been directed towards the development of collaborative service, systems, tools, and frameworks in healthcare, education, industry, and so forth. Collaborative service is being used in a wide range of areas like healthcare [4], government, and environmental services like natural disaster relief [5], mobile learning [7], and smart city [8]. Currently, there exist some frameworks and tools for collaboration such as Virtual Campfire [9], SonART [10], Microsoft SharePoint [11], Microsoft Research ConferenceXP, and Alfresco [12]. Microsoft Research ConferenceXP enables connecting different parties through multicasting by using a customized service for collaborations. Virtual Campfire [9] considers multimedia as image and signal processing, which supports multimedia processing such as image display and signal processing to support some sort of collaboration. SonART [10] provides networked collaborative interaction for art, science, and industry applications.
Currently, the combination of collaborative service with sensing service is used to collect patient's health relevant data for monitoring and detecting sleep activity pattern, voice disorder, respiratory, and blood sugar through sensors, camera, and voice sensors. These sensor devices have the ability for streaming of sensed data, which are connected wirelessly to any smartphone. In [13], Eisenman et al. developed a mobile sensor network framework for collecting and processing sensory data from a human body and then delivering and visualizing it in remote locations in real time. However, sensor networks have been facing many issues and challenges [14] regarding their collaborative communications and sensing processing. In this regard, web service-based communication [6, 15, 16] is used, which is offered by sensor-cloud platform (SCI). In this platform, sensor related information is accessed by using the combination of Web Service Description Language (WSDL) and XML-based SOAP message to be transported over the Internet protocols like SMTP, FTP, and HTTP.
To this end, sensor-cloud infrastructure (SCI) [17, 18] has been evolved and is the combination of cloud technology with the WSN or WBAN. It is the extended form of cloud computing to manage the sensors [19], which are scattered throughout the heterogeneous networks (WSN, WBAN, Wi-Fi, etc.). As cloud computing provides a vast storage capacity and processing capabilities, it allows collecting the huge amount of sensor or sensed data by combining the WSN and cloud through the gateways on both sides, that is, sensor gateway and cloud gateway. Sensor gateway collects information from the sensor nodes, transcodes it, and sends it back to the cloud gateway, which in turn decompresses and stores it in the cloud storage server [18].
There has been extensive research about designing and developing framework or prototype collaboration environments. However, a very few, [3] and [20], have attempted to develop a collaborative framework as well as prototyping by considering sensor and cloud. In [3], Fox et al. describe a cloud computing infrastructure for collaboration sensor-centric applications on the FutureGrid. They attempted to study the characteristics of cloud computing infrastructure for message-based collaboration applications, where media based collaboration has not been addressed. In [20] Han et al. described a content-centric cloud-based collaboration platform. They considered implementing the collaborative medical application on their system, where computation intensive application like a volume rendering is used for MRI analysis.
As cloud computing provides a vast storage capacity and processing capabilities, it allows collecting, storing, and processing huge amount of sensor data by leveraging the use of WSN and sensing tasks of smartphones through web interface or sensor. Sensor device or sensing smartphones can be connected to the web via XMPP for delivering the required data stream (e.g., sensed or audio-visual) to the cloud service. In this case, deployed application on smartphones needs to perform sensing as well as collaborative actions request, collect the data, and send them to different kinds of servers such as sensing server, streaming server, and collaboration service manager for further action. Our proposed framework is an attempt to fulfill this goal of collaborations among doctors by leveraging the sensing feature of smartphones as well as the built-in communication features.
3. Proposed Cloud-Based Collaborative Service Framework
The proposed collaborative service framework (as shown in Figure 1) is composed of several components that are described in detail below. An overview of the overall framework and how each component communicates with each other is described in the following sections.

Cloud-based collaborative media service framework.
The request to initiate a medical consultation or collaboration is made by the doctors or patients through the collaboration session web service after the authentication is accomplished by the Authentication Management web service. The initial request is managed by the Cloud Manager upon receiving the request from the collaborative users through the network and delivering it to the responsible web service for further processing. Then, the Resource Allocation Manager allocates various VM resources for running the collaboration session and web services while the cloud manager provides the participating user with the identification data of the VM. The VM can be regarded as media content server to communicate directly with the doctors in collaboration. In addition, it configures VM capacities based on load balancing capacity. The user sends his or her inputs and data over the network. It may be mentioned that, in addition to the session initiation, Cloud Manager also terminates the session when the collaboration is finished.
As far as the context extraction is concerned, the context data is collected on the user's device and transmitted to the server over the network. The webserver or Sensing Server of the user's device may push the sensed data to the DB and Context Server using AJAX. As it can be seen from Figure 1, the relevant sensed data is transmitted, analyzed, processed, and stored in DB and Context Server through Context Extraction and Management web service. During the execution of the collaboration session, the audio-visual output (e.g., report and voice mail) is sent to the participating users. In order to get customized audio-visual output by the user's device, the output (e.g., audio/voice and video) needs to be transcoded via Transcoding Server and then it is sent through Streaming Server through the overlay network. The communication with Streaming Service is being conducted through SOAP message and XML. The key components of the proposed framework are briefly described below.
Collaborative Users. The main users of the framework are doctors, patients, and caregivers.
Patients: patients are equipped with various body sensors to communicate with doctors in the cloud environment through the network using different smart devices. Physicians or caregivers: doctors are responsible for monitoring the patient performance in detecting voice disorder by using various collaborative media services such as conferencing, discussion board, and live chat.
Cloud Manager. It is responsible for overall management of the proposed framework and consists of various web services. They are as follows.
User, device, and collaborative service profile management: this web service is liable for managing the users’ (doctors, patients, and caregivers) device information and storing in the database. Authentication and registration management: it is responsible for registering and authenticating the users in the system. In order to initiate a collaborative session or to access medical consultation or analyze report, authentication is required. Collaborative session management: it is responsible for managing and controlling the sessions in addition to recommending, tracking, and evaluating the activities. This web service is responsible for collaboration session initiation as well as session completion. Context extraction (e.g., WSN, WBAN, and sensed data) and management: it is responsible for extracting sensed data and other relevant data from the patient through smartphones and storing them in the DB and context server. The context extraction and management service has been implemented using an XAMPP server that stores the sensed data in a MySQL database. Statistics and communication service management: this web service generates and tracks the performance reports as well as the history of collaboration and medical consultations to know about the patients’ well-being.
Resource Allocation Manager. It manages VM resources and web services.
Media Content Server. This server is responsible for maintaining the database and holds all the necessary information for the physicians or patients along with their context information during the medical consultation or collaboration.
Sensing Server. It is responsible for sensing and synchronizing media related data from the sensor through web interface or participating users’ devices. We have used smartphones for this sensing activity. Cloud manager (CM) manages the storage pool for that data. Through XMPP, CM may allow data exchange with an external database such as Massachusetts Eye and Ear Infirmary (MEEI) database. In this case, web server within the smartphone can communicate with the external server or database.
Monitoring and Metering. It is responsible for performance monitoring and usage tracking of VM resources.
Figure 1 facilitates establishing the user's initial communication for collaboration between the participants; however, the detail of the communications for collaborations is described in Figure 2. As it can been seen from Figure 2, the client of each collaborative service user first queries the registry or cloud manager to find out a streaming service. Then, it sends a request to the streaming service with specific load balancing parameters along with user preferences, device profile, and network profile for establishing collaborative session. Upon receiving all information from the proxies, the streaming service originates or creates the media stream (e.g., audio/voice, video, and simple SMS or Text). The originated stream can be captured in real time by using a camera, sensors, microphone, and so forth. The transcoding service in proxy servers transforms or converts the media stream from one media format to another, according to the capacity and capability of users’ handheld devices in order to produce the final content as a reply to the client request.

Communication in service collaboration.
When the client requires a media stream, it first searches a streaming service from the registry or cloud. The request returns the Web Service Description Language (WSDL) file. Using the WSDL file, the client generates a request to the streaming service with Simple Object Access Protocol (SOAP) and sends it to the service. The request consists of a call to the streaming service, with parameters such as jitter, shimmer, HNR, image or video quality, the format of the stream, and the user location of the respective collaborative service users. Upon receiving all information, media stream, and the selected features, the server creates customized media stream using feature extraction and selection algorithm running on transcoding proxies. Finally, the transcoding service directly sends its output stream to the clients’ devices. The high-level message flows of the above can be seen in Figure 2.
4. Experiments and Evaluation
To evaluate the prototype realizations and justify the feasibility of our proposed approach, we first discuss the background of a service collaboration to detect voice pathology and its rehabilitation process, in Section 4.1. Then as a realization of media service collaboration, we show the detailed collaboration task flow between the doctors and patients by considering a voice pathology assessment scenario in Section 4.2. In Section 4.3, we describe the database used in the experiments and rational behind it. After that, we highlight some selected features used in the experiment in Section 4.4. Finally, we present some selected performance issues and their comparisons in Section 4.5.
4.1. Background
For voice pathology detection and classification, some traditional features such as shimmer, jitter, and harmonic-to-noise ratio (HNR) are used. The voice frequency perturbation and the voice amplitude perturbation are called jitter and shimmer, respectively [21]. HNR is a measurement of the ratio between the periodic (harmonic) components and the noise components. However, the impact of these measures on voice pathology assessment varies from one research to another research [22–24]. Many techniques are utilized to detect voice pathology in recent times, for example, empirical mode decomposition [25], filter bank analysis [26], multidirectional regression [27], and so forth. One of the shortcomings of this research is that these techniques were not fully tested in remote collaboration between the patients and the healthcare professionals.
With the increase in aged population and shortage of healthcare professionals, it is feared that the level of patient care may decline in the near future. Wireless body area network (WBAN) is therefore introduced to have an impact on several aspects of healthcare. The WBAN needs some types of medical sensors that can be deployed inside or outside of a human body. Some examples of medical sensors are hearing sensor that can substitute auditory function, visual sensor, and olfaction sensor to replace smelling function. However, most of these sensors need to be connected with the body, and many people do not feel comfortable with these connected sensors. Transmission of voice is an invasive way that can be utilized to overcome the problem of connectivity issue. In this paper, we introduce the idea of using smart mobile phones for the rehabilitation of the patients having voice disorders. Figure 3 shows the rehabilitation and collaboration process in a cloud environment. A patient, while sitting at his or her home during rehabilitation, can use smart mobile phone to give his or her voice. In the cloud, features are extracted from the voice in a processor, modeled in the server, and classified in an engine. The load distributor distributes the load to different components and also controls the data flow to a requested physician or a patient. The physician can use the voice and automatically detected result to assess the rehabilitation.

Illustration of a voice pathology collaboration and rehabilitation process using smart mobile phones in a cloud environment.
Voice disorder or voice pathology occurs due to some abnormal functionality in the vocal fold. Due to this abnormality, the vocal folds cannot open and close in a periodic manner and thereby cause problems while producing voiced sounds. The types of voice disorders include vocal fold cyst, polyp, nodule, and sulcus, among others. Various types of disorders affect the vocal folds differently. The output voice also depends on the severity of the disorder. When a person notices some difficulty in his or her voicing, he or she consults with a specialist physician, who in turn assesses the disorder. If there is need for some surgical operation, the patient goes through a treatment. It is very important for the patients to have a postoperative management in the form of rehabilitation. The rehabilitation is normally in the form of visiting the physician and checking the voice. However, it is found that most of the patients do not show up to the physicians for postoperative management. Therefore, if there is a way to collaborate between the patients and the physicians for the rehabilitation while staying at their own places, it will be beneficial for both the parties. The smartphone can be a solution to this problem. A patient can give his or her voice through the smartphone staying at home, and the physician can receive and assess the voice and give some instructions to the patient through mobile. The major concern of this approach is the quality of voice degradation due to the mobile channel. Pathological voice is already having some sort of noises, and if the mobile channel introduces more noise, then the whole rehabilitation process will be meaningless. In this paper, we utilize some MPEG-7 audio features that are robust against mobile channel distortion for voice disorder assessment.
4.2. Collaboration Task Flow
Here, we will discuss the detailed collaboration between the healthcare professionals by considering a voice pathology assessment scenario, where doctors, caregivers, and patient collaborate with each other to assess the voice pathology. The workflow of the scenario is depicted in Figure 4. The three persons can be the patient, the internal doctor (or family doctor) in the nearby clinic, who the patient regularly visits, and the external doctor from another clinic anywhere in the world. As shown in Figure 4, the collaboration flow has 18 steps. These steps are described in Table 1 in detail.
Description of each arrow in voice pathology assessment scenario.


Collaboration task flow of a medical scenario-voice pathology assessment scenario.
At first, the patient sends his/her voice through mobile. Media content server (MCS) receives it (step 1) and then sends it to the cloud manager (CM) (step 2). The CM sends the voice data to collaborative service manager (CSM) (step 3), and the CSM uploads the information (voice and features) to the web (step 4) with proper authentication protocol. The internal doctor receives the voice data (step 5) from the web by using his/her credentials. The doctor may also receive the information directly from the CSM using the mobile (step 6). After analyzing the information, the doctor prepares a report or feedback (step 7) and uploads it to the web (step 8) or sends it to the CSM (step 10). The web sends the report to the CSM (step 9), which uploads the report or feedback to the CM (step 11). If the doctor needs to check the report by an external doctor, the report can be accessed by the doctor through proper identification using the web (steps 12 and 13). The doctor can analyze the report (step 14) and upload his feedback on the web (step 15). It is then processed in the CSM (step 16) and stored in the CM (step 11). The CM sends the report and feedback from the doctors to the MCS (step 17), and they can be accessed by the patient (step 18).
4.3. Database
The database used in the experiments is the one developed by the Massachusetts Eye and Ear Infirmary (MEEI) Voice and Speech Labs [28]. The MEEI database contains the sustained vowel/AH/recordings by 53 normal speakers with duration of around 3 seconds and by 657 pathological speakers, with a wide variety of diseases, with duration of around 1 second. It also contains voice recordings with duration of around 12 seconds of a reading text from “Rainbow passage.” Since we are interested in vocal pathologies, we used sustained vowel recordings only to ensure that the vocal folds remain in motion during the entire utterance [2]. We used the same subset of the MEEI database which was used in [2], denoted by MEEI subset; this subset has sustained vowel/AH/recordings for 53 normal and 173 pathological speakers. /AH/samples are chosen because they have clearly distinguished formants, have high amplitudes, and are easier than other vowels to pronounce by the patients. The criteria in selecting this subset considered a wide variety of voice disorders and a uniformly distributed gender and age between both normal and pathological classes [29]; statistical description of the MEEI subset is shown in Table 2. The MEEI database has been thoroughly tested in numerous research works since its development, and it is the most widespread and available of all the voice quality databases.
Statistics of MEEI subset (♂ for male, ♀ for female).

To simulate voice pathology detection using smart mobile phone, all the samples in the MEEI subset are transmitted through an iPhone4S mobile and received at a Samsung Galaxy III mobile. The samples recorded at the Samsung Galaxy III mobile are used as the input to a voice pathology detection engine. In this process, the sampling rate of the recorded voice becomes 11.025 kHz. It can be mentioned that, in the MEEI subset, the sampling rate for the normal voices is 50 kHz and that for pathological voices is 25 kHz. To see the effect of mobile transmission, Figure 5 demonstrates examples of waveforms of normal (Figures 5(a) and 5(c)) and pathological samples (Figures 5(b) and 5(d)) in the original recording and mobile recording, respectively. From Figure 5, we can see a significant loss of data while transmitting through mobile phones.

Waveforms and spectrograms of a sustained vowel/AH/from a normal person without voice pathology (first column) and from a person with voice pathology (second column). The first row shows example of MEEI recorded data, while the second row shows example of mobile phone transmitted data. In the spectrograms, red dots indicate formant values, and the blue dots indicate pitch values.
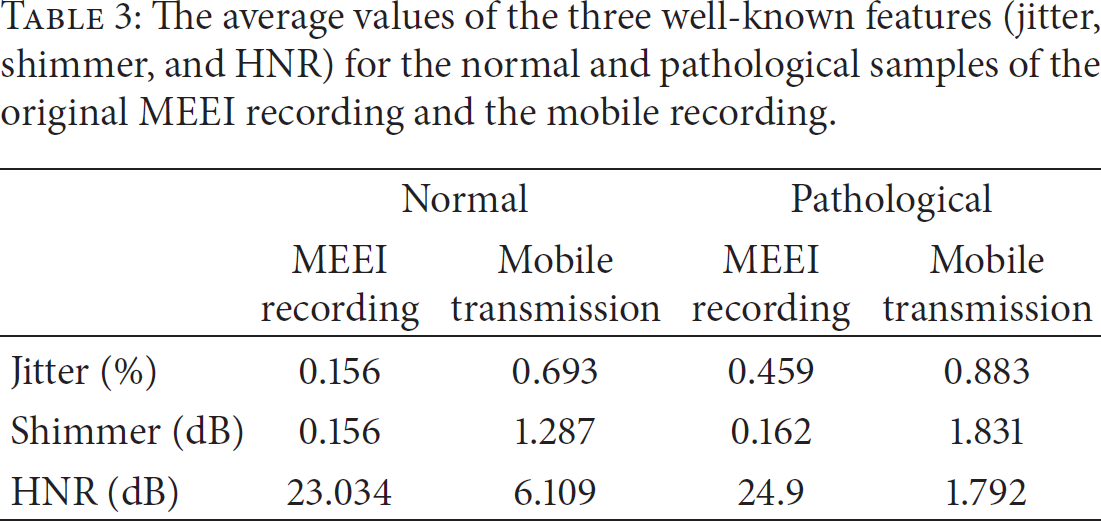
Table 3 gives the average values of the three well-known features, jitter, shimmer, and HNR, for normal and pathological voice samples of the original recording of MEEI subset and the mobile recording. The table shows a significant difference, especially in HNR, between the original recording and the mobile recording. In the mobile recording, some channel noises are convolved with the signal and thereby reduce the value of HNR. From Figure 5 and Table 3, it is clear that the conventional features (jitter, shimmer, and HNR) cannot detect the voice pathology precisely if the voice is transmitted through mobile phones.
The average values of the three well-known features (jitter, shimmer, and HNR) for the normal and pathological samples of the original MEEI recording and the mobile recording.
4.4. The Features
Four types of features, which are relatively less affected by mobile transmission, are utilized in this paper. The features are audio spectrum centroid (ASC), audio spectrum spread (ASS), harmonic spectrum spread (HSS), and audio spectrum flatness (ASF). These features were basically included in the low-level descriptors of audio in MPEG-7 [30]. ASC describes the center of gravity of the log-frequency power spectrum and is calculated as shown in (1), where
The reason behind choosing these features is that they are less affected by noise, have powerful discrimination capability in the field of environment recognition [31], musical onset detection [32], and even in voice pathology detection [33], and are computationally not expensive:



4.5. Experiments
To validate the usage of the proposed features for voice pathology detection through mobile transmission, we use Gaussian mixture model (GMM) and support vector machine (SVM), separately, for classification. 10-fold cross-validation approach is utilized. In the 10-fold cross-validation, the normal files and the pathological files are randomly divided into ten equal groups each. In each iteration, nine groups, each from the normal and the pathological samples, are used for training, while the remaining samples are for testing. Therefore, at the end of ten iterations, all the ten groups are tested. There is no overlapping between the training set and the testing set in one iteration. The final accuracy is obtained by averaging ten accuracies of the folds.
The number of mixtures in GMM is varied to 2, 4, and 8. The optimization of the SVM parameters is done with the training set. Two types of kernel, which are polynomial and radial basis function (RBF) of SVM, are tested. Grid search is conducted to obtain the optimal parameter values for “C” and “gamma” in the SVM. “C” is the optimization parameter of the SVM, and “gamma” is the kernel parameter of RBF.
Figure 6 shows the voice pathology detection accuracy of originally recorded MEEI subset using the proposed features of dimension five with SVM and GMM. The results are compared with traditional mel frequency cepstral coefficients (MFCC) features with 12 dimensions and 24 dimensions (12 MFCC plus their delta) [34]. The highest accuracy (99.4%) is obtained with the proposed features and SVM (RBF kernel). In general, SVM performs better than GMM.

Voice pathology detection accuracy (%) using the three different types of features with SVM and GMM. The voice samples are original recorded MEEI subset.
Figure 7 shows the detection accuracy of the mobile transmitted MEEI subset. The highest accuracy (98.1%) is achieved with the same combination as before. From Figures 6 and 7, we can observe that the performance of the mobile transmitted samples is not too much degraded with the proposed method, while, with the other methods, the performance is significantly degraded. A performance comparison between the proposed features and SVM (RBF) and the method in [2] is shown in Figure 8. As can be seen from Figure 8, the proposed features outperform the method in [2] in both MEEI recording and mobile transmitting cases. Therefore, we can conclude that the proposed features can effectively be used to assess the voice for rehabilitation using mobile phone sensor.

Voice pathology detection accuracy (%) using the three different types of features with SVM and GMM. The voice samples are mobile transmitted MEEI subset.

Performance comparison between the proposed features + SVM (RBF) and method in [2] in case of MEEI recording and mobile transmitting.
5. Conclusion and Future Work
In this paper, we present a cloud-based collaborative media service framework. The framework uses collaborative service for voice pathology detection, where doctors, caregivers, and patients collaborate with each other through emerging multimedia communication technologies such as video conferencing, web conferencing, voice mail, and discussion board. During the session, collaborative users (caregivers and patients) need to use different handheld devices equipped with a rich set of sensors such as camera, audio, Wi-Fi/3G/4G radios, accelerometer, and microphone to access the media (image, video, and audio/voice) content ubiquitously. To have this access, the proposed system being able to provide adaptive collaborative services is based on user's preferences, device's sensing capability, and processing. Currently, we have not deployed the database on the Amazon Cloud; we have used external database (MEEI subset) for experimenting suitability and realizations of our approach. As for the future work, we will do the deployment so that user can enjoy the full scalability, flexibility, agility, and ubiquity of the proposed media service collaboration.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported by the Research Center of College of Computer and Information Sciences (CCIS), King Saud University, by the research Project RC121259. The authors are grateful for this support.