
Abstract
A packet loss concealment (PLC) algorithm is proposed to improve the quality of decoded speech when packet losses occur in a wireless sensor network. The proposed algorithm is mainly based on artificial bandwidth extension (ABE) from narrowband to wideband. It consists of three main functions: packet loss concealment in the narrowband, ABE in the modified discrete cosine transform (MDCT) domain, and smoothing of wideband MDCT coefficients with those of the last good frame. The performance of the proposed PLC algorithm is implemented by replacing the PLC algorithm employed in the ITU-T Recommendation G.729.1. The experimental results show that the proposed PLC algorithm provides significantly better speech quality than the PLC in the ITU-T G.729.1.
1. Introduction
There have been rapid developments in wireless sensor networks (WSNs) owing to recent advances in devices such as ultralow-power microcontrollers and short-range transceivers [1]. WSN technology is used in a wide range of applications like environmental monitoring, human tracking, biomedical research, military surveillance, and multimedia transmission [2, 3]. This paper addresses the issues regarding sensors used for multimedia transmission, called wireless multimedia sensors (WMSs) [4, 5]. These sensors deal with multimedia data like image, video, speech, and audio. Multimedia sensor nodes have resource constraints such as low energy capacity of battery, low storage space, and limited computing power. Many multimedia sensor nodes focus on speech data transmission suitable for speech transmission over WSNs. In such cases, each sensor node is linked by wireless local area network (WLAN) links and real-time transport protocol/user datagram protocols (RTP/UDPs). Packet loss rate increases in this type of transmission because of increased network congestion [6, 7]. In addition, depending on the network resources, the possibility of burst packet losses also increases, which potentially results in severe quality degradation of the reconstructed speech [8].
Most speech coders in use today are based on telephone-bandwidth narrowband speech, nominally limited to about 300–3,400 Hz at a sampling rate of 8 kHz. In order to improve speech quality in voice services, wideband speech coders have been developed for smoothly migrating from narrowband to wideband quality. They operate with a bandwidth 50–7,000 Hz at a sampling rate of 16 kHz. For example, ITU-T Recommendation G.729.1, a scalable wideband speech coder, improves the quality of speech by encoding the frequency bands ignored by the narrowband speech coder, ITU-T Recommendation G.729. Encoding wideband speech using ITU-T Recommendation G.729.1 is performed by two different operations on the low band and high band in the time and frequency domain, respectively. When a frame loss occurs, the low-band and high-band packet loss concealment (PLC) algorithms work separately. The low-band PLC algorithm reconstructs the excitation and spectral parameters of the lost frame from the last good frame, and the high-band PLC algorithm reconstructs the spectral parameters such as modified discrete cosine transform (MDCT) coefficients of the lost frame from the last good frame [9].
Several packet loss concealment (PLC) methods have been proposed to reduce the speech quality degradation due to a packet loss [7, 10]. The PLC algorithm proposed in [7] was developed to improve the narrowband speech quality by estimating the excitation using comfort noise and multiple codebooks. A technique based on the resynchronization of the glottal pulses in the low band was also proposed in [10], which was subsequently embedded into ITU-T Recommendation G.729.1 as the low-band PLC algorithm [10]. However, the high-band PLC algorithm for ITU-T Recommendation G.729.1 replaced spectral parameters in the modified discrete cosine transform (MDCT) domain with those of the previous frame [10, 11]. In this case, the high-band signal was reconstructed without regard to the low-band signal for the lost frames. The speech quality would have been better if the PLC algorithm estimated the high-band signal by taking into account the reconstructed low-band signal for the lost frames.
Therefore, this paper proposes an artificial bandwidth extension-(ABE-) based PLC algorithm for high-band signal reconstruction in order to improve the quality of decoded speech under packet loss conditions in a WSN. The proposed PLC algorithm is mainly composed of three functions: PLC in the narrowband, ABE in the MDCT domain, and smoothing of the wideband MDCT coefficients using those of the last good frame. The ABE algorithm performs different operations for the 4–4.6 kHz and 4.6–7 kHz bands. It reconstructs the MDCT coefficients of the 4–4.6 kHz band from the harmonic spectral band replication and correlation-based replication approaches. On the other hand, the MDCT coefficients for the 4.6–7 kHz band are obtained by spectral folding [12]. The performance of the proposed PLC algorithm is evaluated by implementing it in the G.729.1 decoder, and it is compared with that of the PLC algorithm employed in the ITU-T Recommendation G.729.1 decoder.
The remainder of this paper is organized as follows. Following this introduction, Section 2 discusses the PLC algorithm currently employed in the G.729.1 decoder. Section 3 proposes an ABE-based PLC algorithm that can also be applied to the ITU-T Recommendation G.729.1 decoder. Section 4 evaluates the performance of the proposed ABE-based PLC algorithm. Finally, this paper is concluded in Section 5.
2. Conventional PLC Algorithm
PLC algorithms can be classified into a sender-based and a receiver-based algorithm, depending on the position where the PLC algorithm works [13, 14]. The sender-based algorithms try to prevent packet errors by using error-robust transmission methods or by including error correction data. The lost speech packets are retransmitted or the sequential speech packets are interleaved to avoid burst losses. Moreover, the speech packets are transmitted with forward error correction (FEC) code or redundant data, which are used to recover the lost speech signals at the receiver. In addition, robust header compression (ROHC) provides a robust speech streaming method at the transmission protocol layer by reducing the overhead due to protocol headers [15]. On the other hand, the receiver-based algorithms conceal lost speech signals by using the speech signal characteristics. The lost speech signals are replaced with silence, noise, or previously reconstructed speech signals. In other words, lost speech signals can be reconstructed by interpolating previous and next good speech signals [16]. In practice, the parameters of a lost frame should be estimated by extrapolating the parameters of a previous good frame.
Figure 1 shows a block diagram of the PLC algorithm employed in the ITU-T Recommendation G.729.1 decoder [17]. The PLC algorithm is composed of low-band and high-band PLC modules. The PLC algorithm reconstructs speech signals of a lost frame based on the speech parameters correctly received from the last good frame, where the speech parameters are excitations in the low band and the MDCT coefficients in the high band. In the low-band PLC module, the excitation of the lost frame is replaced with that obtained from the last good frame, and the energy of the reconstructed excitation is gradually decayed. In addition, a synthesis filter for the lost frame is reconstructed using the linear predictive coding (LPC) coefficients from the last good frame, and the pitch period of the lost frame is estimated as the integer part of the pitch period of the last good frame.
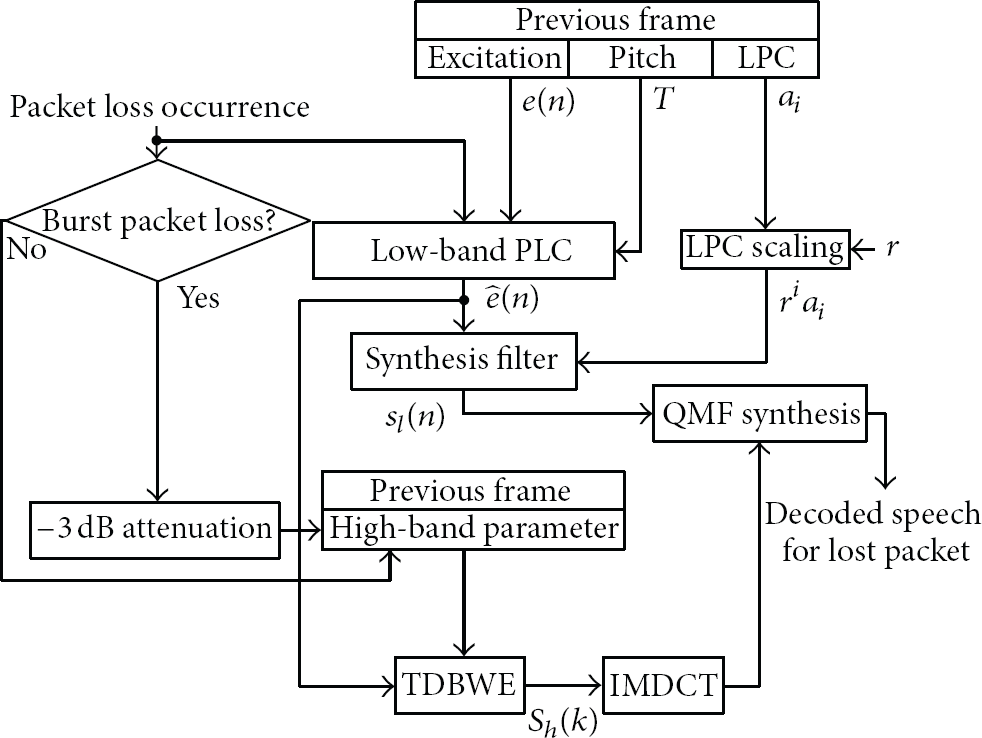
Block diagram of the PLC algorithm employed in the ITU-T Recommendation G.729.1 decoder.
In the high-band PLC module, the high-band signal is reconstructed by time-domain bandwidth extension (TDBWE) that convolves the excitation generated from the low-band PLC module with a spectral envelope estimated from the high-band energy parameters of the last good frame. Then, an MDCT is applied to the high-band signal, and subsequently, the MDCT coefficients corresponding to 7-8 kHz are set to zero. Next, an inverse MDCT (IMDCT) is applied to the modified MDCT coefficients in order to obtain the high-band signal. Finally, the reconstructed wideband signal of the lost frame is obtained by quadrature mirror filter (QMF) synthesis using both the low-band signal and the high-band signal that are reconstructed by the low-band PLC and high-band PLC modules, respectively.
3. Proposed ABE-Based PLC Algorithm
Figure 2 shows a block diagram of the proposed ABE-based PLC algorithm. When a frame loss occurs, the low-band PLC module reconstructs the low-band speech signal of the lost frame,

Block diagram of the proposed ABE-based PLC algorithm.
3.1. Artificial Bandwidth Extension (ABE)
ABE is used to generate the high-band MDCT coefficients,

Block diagram of the ABE method employed in the proposed PLC algorithm.
First, for the frequency band of 4.6–7 kHz, the MDCT coefficients are initially generated by a spectral folding operation, which is defined as

For the frequency band of 5.5–7 kHz,



For a voice frame, the harmonic characteristics of the low-band should be maintained in the high band [18]. The harmonic spectral band replication approach determines the harmonic period as

On the other hand, for an unvoiced frame, a correlation-based replication approach is used to patch the high-band MDCT coefficients. Thus, the optimal shift,

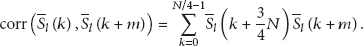

It is important to avoid an abrupt change in the boundary between the low band and the high band. This is achieved by adjusting


Finally, the extended MDCT coefficients,

The extended MDCT coefficients in (11) provide an excessively fine structure at high frequencies, which results in musical noise. Therefore, it should be smoothened. This is done by applying a shaping function to

3.2. Reconstruction of High-Band MDCT Coefficients for a Lost Frame
As mentioned earlier, the proposed ABE-based PLC algorithm reconstructs the high-band signal from the low-band signal, which is mainly composed of three modules: low-band PLC, ABE in the MDCT domain, and smoothing of the wideband MDCT coefficients using those of the last good frame. The high-band PLC module in the ITU-T Recommendation G.729.1 decoder utilizes the high-band energy of the last good frame regardless of the signal class characteristics such as voiced, unvoiced, and transition period. In contrast, in the proposed ABE-based PLC algorithm, the high-band MDCT coefficient,

Next,
4. Performance Evaluation
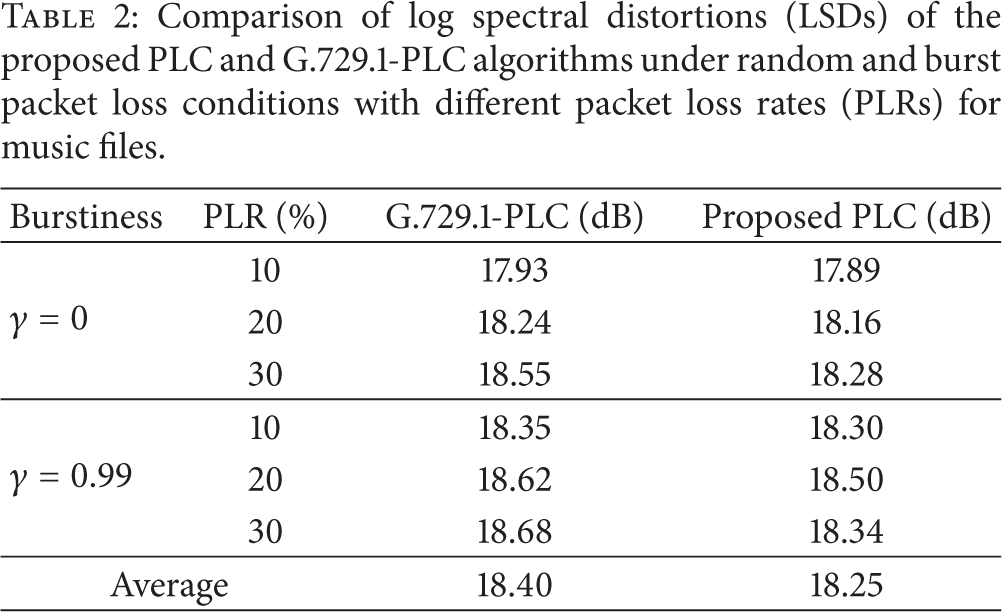
The effectiveness of the proposed ABE-based PLC algorithm is demonstrated by comparing its performance with that of the PLC algorithm employed in the ITU-T Recommendation G.729.1 decoder, which is referred to as G.729.1-PLC. For comparison, eight audio files (three male voice files, three female voice files, and two music files) were excerpted from the sound quality assessment material (SQAM) database [23]. Since the files were originally recorded in stereo at a sampling rate of 44.1 kHz, the right channel signal of each file was downsampled to 16 kHz. In addition, two different packet loss conditions such as random and burst packet losses were simulated. Packet loss rates of 10, 20, and 30% were generated by the Gilbert-Elliot model defined in ITU-T Recommendation G.191 [24]. To simulate burst packet loss conditions, the burstiness of the packet losses was set to 0.99, where the mean and maximum consecutive packet losses were measured as 1.9 and 5.6 frames, respectively.
First, the log spectral distortion (LSD) [25] was measured between the original and decoded signal. It is defined as

Comparison of log spectral distortions (LSDs) of the proposed PLC and G.729.1-PLC algorithms under random and burst packet loss conditions with different packet loss rates (PLRs) for speech files.

Comparison of log spectral distortions (LSDs) of the proposed PLC and G.729.1-PLC algorithms under random and burst packet loss conditions with different packet loss rates (PLRs) for music files.
Second, the waveforms decoded by different PLC algorithms were compared, as shown in Figure 4. It was seen that the decoded signal obtained by the proposed PLC algorithm (Figure 4(e)) is closer in fidelity to the decoded signal without any loss (Figure 4(b)) than the decoded signals obtained by G.729.1-PLC (Figure 4(d)) for a given packet error pattern (Figure 4(c)). Additionally, Figure 5 compares the spectrograms of the signals decoded by different PLC algorithms. As shown in Figure 5, the spectrogram of decoded signal obtained by the proposed PLC algorithm (Figure 5(d)) was more similar to the decoded signal without any loss (Figure 5(b)) than the spectrogram of the decoded signals obtained by G.729.1-PLC (Figure 5(c)) in the high band.
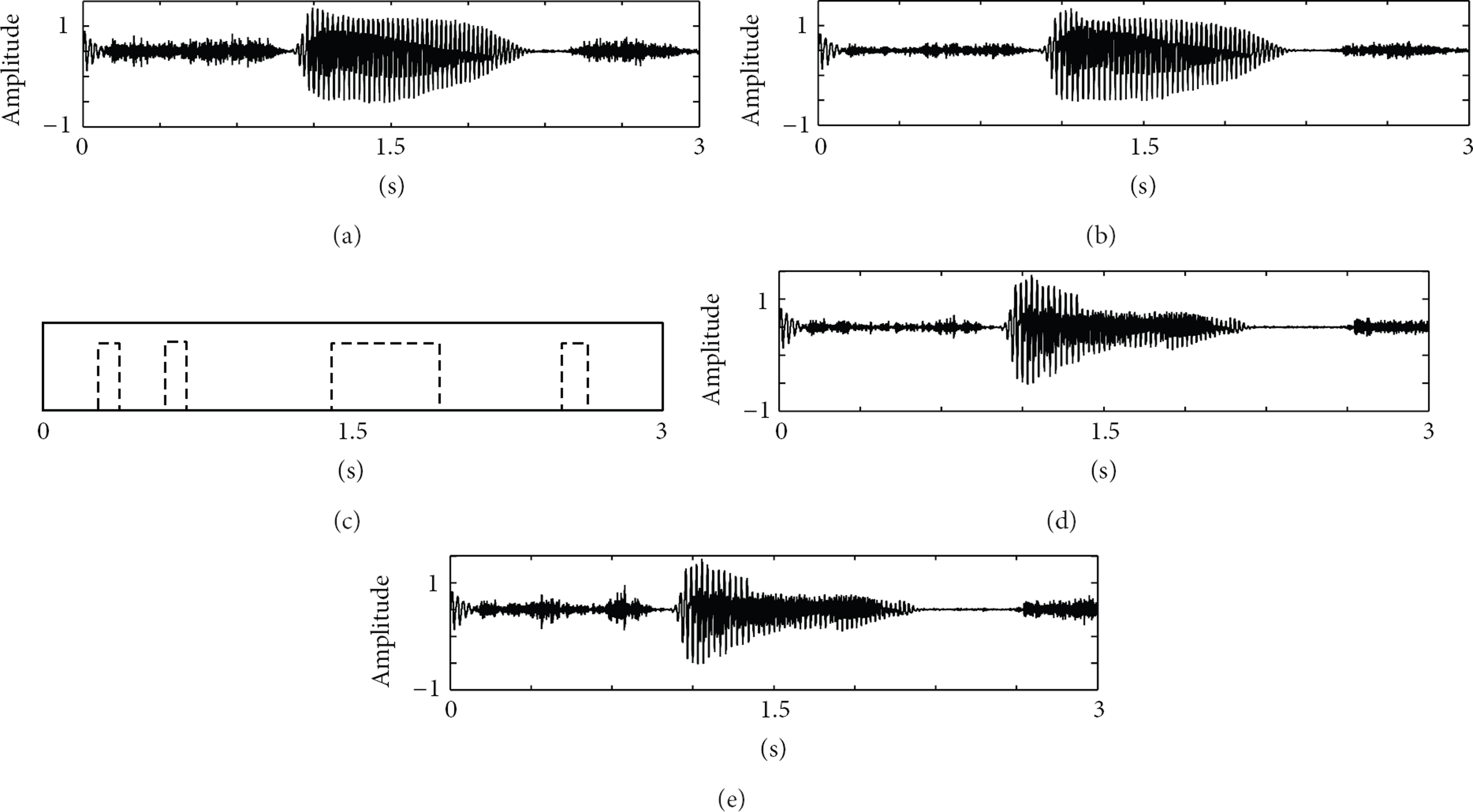
Waveform comparison of (a) original signal, (b) decoded signal without packet loss, (c) packet error pattern, (d) decoded signal by the G.729.1-PLC algorithm, and (e) decoded signal by the proposed PLC algorithm.

Spectrogram comparison of (a) original signal, (b) decoded signal without packet loss, (c) decoded signal by the G.729.1-PLC algorithm, and (d) decoded signal by the proposed PLC algorithm in the packet loss.
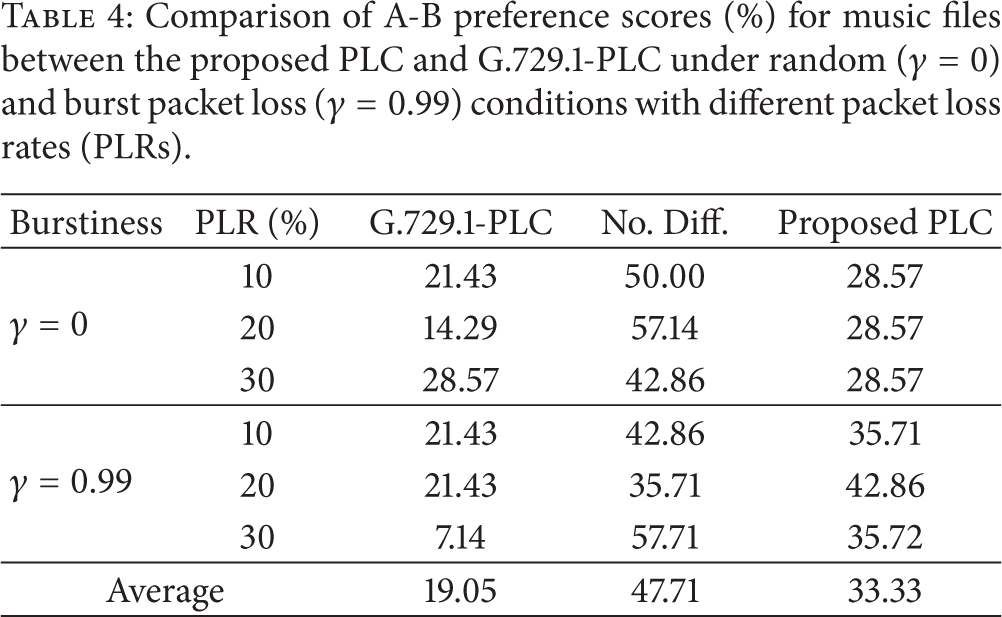
Third, an A-B preference listening test was performed to evaluate the subjective quality. The audio data used for the test consisted of six speech files (three male and three female voices) and two music files. All the files were processed under random and burst packet loss conditions by G.729.1-PLC and the proposed PLC algorithm, respectively. In this paper, seven people with no auditory diseases participated. Audio files processed by the G.729.1-PLC and proposed PLC algorithm were presented to the participants, and they were asked to choose their preference. Tables 3 and 4 show the test results for the speech and music data, respectively. Note that if a participant could not distinguish the difference between the file processed by the proposed PLC and G.729.1-PLC, then “No. Diff.” was selected. It was shown from Tables 3 and 4 that the speech and music signals decoded by the proposed PLC algorithm were preferred to those by the G.729.1-PLC algorithm.
Comparison of A-B preference scores (%) for speech files between the proposed PLC and G.729.1-PLC under random (

Comparison of A-B preference scores (%) for music files between the proposed PLC and G.729.1-PLC under random (
Next, in order to demonstrate the effectiveness of the proposed PLC algorithm, the stimuli with a hidden reference and an anchor (MUSHRA) test [26] were performed as a subjective listening test. For the MUSHRA test, two anchors with cut-off frequencies of 7 and 3.4 kHz were prepared. Seven people with no auditory diseases also participated in this test. Each participant was presented with the eight stimuli and was asked to rate the audio quality from 0 to 100. Figure 6 compares the MUSHRA scores, where each column corresponds to the opinion score averaged over seven listeners and eight audio files. Note that the vertical line on the top of each bar denotes the standard deviation of the opinion score. As shown in Figure 6, the proposed PLC algorithm achieved an average score of 39, which was higher than that by the G.729.1-PLC algorithm.

Comparison of MUSHRA scores.
Finally, in order to show how much more effective the proposed PLC algorithm was in comparison to the G.729.1-PLC algorithm, a paired t-test [27] was performed using their MUSHRA scores. Assuming that the differences in MUSHRA scores followed a normal distribution, the test statistic had a t-distribution based on
For the paired t-test, the test statistic must be greater than
5. Conclusion
In this paper, a packet loss concealment (PLC) algorithm has been proposed to improve the performance of decoded signal quality when frame erasures or packet losses occurred in wireless sensor networks. The proposed PLC algorithm was based on artificial bandwidth extension (ABE) from the low band to the high band in the MDCT domain. The performance of the proposed PLC algorithm was evaluated by replacing the PLC algorithm currently employed in the ITU-T Recommendation G.729.1 decoder, G.729.1-PLC under random and burst packet loss rates of 10, 20, and 30%. The comparisons were made based on log spectral distortion (LSD), waveform/spectrogram comparison, an A-B preference test, MUSHRA test, and the paired t-test. It was shown from the comparisons that the proposed PLC algorithm provided better quality of decoded speech and music signals than G.729.1-PLC for all the simulated packet loss conditions.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Research Foundation of Korea (NRF) Grant funded by the government of Korea (MSIP) (no. 2012-010636), by the MSIP (Ministry of Science, ICT and Future Planning), Korea, under the ITRC (Information Technology Research Center) Support Program (NIPA-2013-H0301-13-4005) supervised by the NIPA (National IT Industry Promotion Agency), and by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2009-0093828).