
Abstract
In a wireless visual sensor network consisting of wireless, battery-powered, and field-of-view (FoV) overlapping and stationary visual sensors, trade-offs exist between extending network lifetime and enhancing its sensing accuracy. Moreover, aggregating individual inferences from each sensor is essential to generate a globally consistent inference, because these individual inferences can be biased by noise or other unexpected conditions. Those challenges can be addressed by reducing the amount of data transmission among the sensors and by activating, in a timely manner, only a desirable camera subset for given targets. In this paper, we initialize an optimal data transmission path among visual sensors using the inference tree method, which is vital for collecting individual inferences and building a global inference. Based on the optimal data transmission path, we model the camera selection problem in a cooperative bargaining game. In this game, based on the serial dictatorial rule, camera sensors cooperatively attempt to raise the overall sensing accuracy by sequentially deciding their own mode between “sleep” and “active” in descending order of their bargaining power. Simulated results demonstrate that our proposed approach outperforms other alternatives, resulting in reduced resource overhead and improved network lifetime and sensing accuracy.
1. Introduction
There has been an increasing necessity to extract relevant information for multiple targets moving around inside wide areas for surveillance purposes. Moreover, these requirements must be fulfilled in a cost-efficient manner. A visual sensor is primarily equipped with an image sensing device, several processing units, communication facilities, and a set of batteries. This composition is very suitable for surveillance, because of the advantageous characteristics such as a wide monitoring area, rich visual information, and human-friendly data. Following the development of these inexpensive, powerful, and easily-deployable visual sensors, wireless visual sensor networks (WVSN) consisting of wireless, battery-powered, and field-of-view (FoV) overlapping and stationary visual sensors have been widely employed for surveillance in public places [1, 2]. Compared with other types of wireless sensors, visual sensors are impacted more by their limited bandwidth, lifespan, computation, and storage capabilities, because they contend with high-dimension data sets containing rich information generated from images [3]. Thus, it will be necessary to initialize an optimal data transmission path to reduce the amount of data transmission among the sensors for a global inference and to efficiently activate only selected cameras, which optimizes their collective coverage of given targets in a timely manner. The latter is referred to as Camera Selection (CS).
In this paper, we initialize an optimal data transmission path among visual sensors utilizing the inference tree method, which is a key component in aggregating individual inferences and building a global inference with minimized transmissions [2]. Based on the optimal transmission path, every visual sensor can exchange data with other sensors. Additionally each sensor can autonomously switch its mode between “sleep” (in sleep mode, the sensor stops capturing data; it will continue to transmit data) and “active” only with local knowledge, during advanced target analysis beyond basic tracking. This local rationale can be feasible under the practical assumption that FoV overlapping cameras can directly communicate with each other; additionally, the view of a target is shared only between neighboring cameras. Thus, the camera's local knowledge is sufficient to measure its sensing contribution towards the global sensing accuracy, considering its neighbors’ contributions. As discussed in [4, 5], each of the multiple cameras can cooperatively bargain for an optimal collective coverage. Our proposed approach utilizes the serial dictatorial rule, in which preferred cameras are prioritized to select their mode in earlier steps to achieve efficient computation.
The remainder of this paper is organized as follows. Section 2 introduces and discusses several advanced CS solutions; Section 3 describes the inference tree method used to initialize the data transmission path; Section 4 models a CS problem in a cooperative game; Section 5 describes our proposed serial dictatorial rule-based solution to force every camera to select its optimal mode using its local knowledge; Section 6 simulates and analyzes our approach in several network performance metrics and resource overhead; Section 7 compares our solution with its representative alternatives employing our concerned metrics; and Section 8 concludes the paper.
2. Related Work
Because of the lack of CS-related studies at this time, we note that several considerable research efforts have proposed comparable solutions, mainly based on greedy selection (GS) or potential game (PG).
The GS-based approaches select a camera best satisfying the criteria of interest at the time until l cameras are selected for a certain l that has been heuristically determined in advance. For example, a candidate camera may be selected based on the extent to which it improves the current visual hull and thus reduces occlusion [6, 7]; candidate cameras may also be selected based on the degree to which their images are different from images of already-selected cameras, with a goal of producing varied images that reduce redundancies [8]. Although this selection process may provide richer information about targets, it does not adaptively cope with the dynamics in the targets’ locations because of the stationary l.
For seamless tracking, the PG studies assign a camera to every target based on the maximum utility between the camera and the associated target. A camera's utility for a target is quantified by how large the camera records the target and its face in stationary camera networks [4] or the degree to which the camera can closely observe the target in active camera networks [5]. Until a set of probabilities describing how effectively a target is tracked by a camera for every camera and every target is converged, a set of these utilities and the probability set are alternatingly updated; additionally, they both influence each other. This one-for-one selection could efficiently produce results for tracking or locating given targets; however, it may be insufficient to produce advanced target information, such as multitarget interaction analysis.
All of the discussed techniques have approached a CS solution in a centralized manner, with global knowledge of every camera and every target. To obtain such global knowledge, high bandwidth consumption will necessarily occur at a central operator in centrally controlled networks or at every camera sensor in distributed controlled networks. To avoid such dissipation, our approach employs only limited knowledge; however, it aims to perform similarly to, or improve, the previously mentioned alternatives.
3. Inference Tree Method for Initializing Transmission Path
A WVSN can be described as displayed in Figure 1. Figure 1(a) displays the configuration of a WVSN, Figure 1(b) illustrates a physical topology based on wireless connection reachability (or geometric proximity), and Figure 1(c) represents a logical topology based on the FoV overlapping constraint. In this paper, however, we assume that FoV overlapping cameras can directly communicate with each other. Thus, the physical topology graph can be ignored. This assumption is feasible in practical applications and enables us to focus on the data transmission and camera selection challenges.

A wireless visual sensor network.
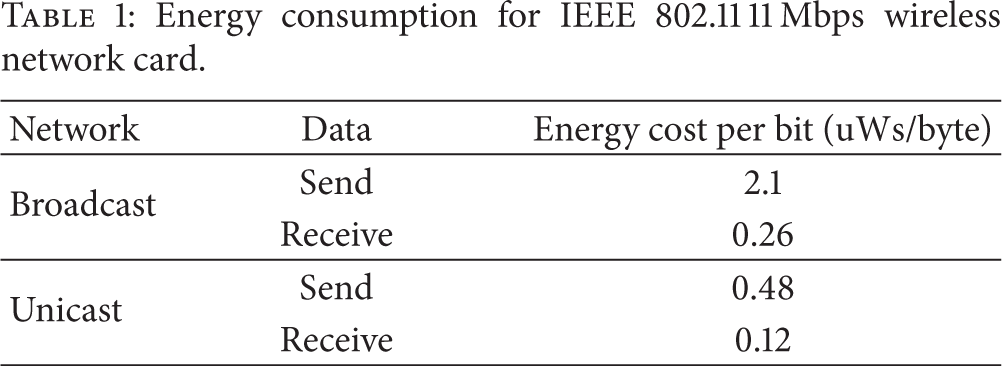
As displayed in Table 1 [9], power consumption costs are higher for a broadcasting network compared with a unicasting network. In order to minimize data transmissions for building a global inference in a WVSN, we need to convert the logical topology from a broadcasting/multicasting network to a unicasting network. To initialize a transmission path as a unicasting network, we use the inference tree method [2]; the process is illustrated in Figure 2. When a logical topology is provided as an input, a weight value is calculated for each edge based on the amount of FoV overlapping between two visual sensors. The result of this initial step is a weighted graph. From the weighted graph, a maximum spanning tree is produced, and the center node of the maximum length path is selected as a root node. Utilizing the root node selected in the second step, the weighted graph is converted into a minimum depth tree employing a breadth-first search algorithm. The result of this step is an initial inference tree. Lastly, it is optimized with up and down actions necessary to build a balanced tree. We utilized the final resulting tree as an optimal data transmission path for the WVSN.
Energy consumption for IEEE 802.11 11 Mbps wireless network card.

The process of inference tree method.
The results from our implementation are displayed in Figure 3. Figure 3(a) illustrates that there is a significant reduction in the number of data transmissions for both the leaf and internal nodes. Figure 3(b) illustrates that energy consumption for data transmissions has decreased for all nodes. Figures 3(a) and 3(b) successfully support that the inference tree method is effective for initializing an optimal data transmission path in WVSN.

The results of the inference tree method.
4. Cooperative Game for CS
Consider c cameras, indexed by i, statically deployed, and t targets, indexed by j, randomly moving inside a geographical area. As previously stated, we also assume that any two neighboring cameras are able to communicate with each other if their FoVs overlap. The locations of cameras are initially calibrated and stationarily fixed. The locations of targets are updated based on any object localization algorithm of [10], utilizing the most recently recorded images at each time instant, provided to their associated cameras. Whenever new locations are provided, the expected target locations at the next time instant are also estimated by the extended Kalman filter as in [11]. At this point, every camera i is aware of the set of its observable targets to move into its FoV, termed
Illustration of parameter notations in camera i's FoV with targets j and

Illustration of parameter notations in camera i's FoV with targets j and
Declaring that

For

such that


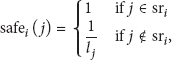
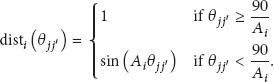
The target utility of target j by camera i represents the smallest likelihood that j is sufficiently observed without any occlusion in i's FoV according to i's mode. This likelihood is determined utilizing three values:
Forthwith, we discuss the extent to which an individual camera contributes to a certain global utility. Camera utility of camera i evaluates its contribution degree to observe the set of its observable targets

The equations from (4) to (7) reflect the following characteristics that only camera sensors can possess.
Every camera can be assumed to have, in its FoV, its own safe region where any target is observable in sufficient detail to give desirable information with minimal distortion.
Owing to the 3D-to-2D projection of imaging, the occlusion among multiple targets in a camera's FoV obstructs the extraction of the targets’ information [3, 4].
The interaction analysis among multiple targets provides more relevant information about the targets beyond their locations [15].
While (i) and (ii) are, respectively, represented by (5) and (6) for (4), more relevant information is provided by cameras with a higher camera utility, which becomes greater as it observes more targets or its associated target utilities are greater, as in (7).
Subsequently, every camera selects its mode to cooperatively maximize their payoff and the global utility
5. Serial Dictatorial Rule-Based Bargaining Solution
According to [13], the serial dictatorial rule is a sequence of dictatorial rules conducted by individual players whose exercising order is statically arranged by their bargaining powers. By evaluating camera utilities provided in (7), we consider that a camera has greater bargaining power if it observes a greater number of targets, in a less occluded manner, in the corresponding safe region. Given that all cameras possessing greater bargaining power have already determined their modes and a camera must presently select a mode, it will select the mode maximizing its payoff,
5.1. Order Cameras by Their Camera Utilities
Given estimated locations of
5.2. Select the Current Mode
Prior to mode selection, every i waits for all the modes of its more bargaining-powerful neighbors to be announced while updating

A camera i will decide to be active only if it can improve the total of the global target utilities for every target of
This local reasoning with limited knowledge soundly and completely extends maximizing
Theorem 1.
For every camera i with its mode

where
Proof.
The following equation (10) holds by the global utility definition and (11) is derived because the change of camera i's mode affects only the global target utilities of every j in



To more easily understand the claim, we restate the target argument as the following if-then rule.
By the nature of our bargaining process,
Subsequently, we verify this claim for both its soundness and completeness.
Soundness. We demonstrate that (12) and
case of When i decides its mode as active while assuming that every mode for the less bargaining-powerful neighboring cameras is sleep, it is believed that it can improve the global target utility of any in
Because any of less bargaining-powerful neighbors could be active to contribute to the improvement of the concerned global target utilities, Case of When i determines its mode as sleep, it believes that every j in
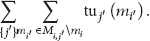
Completeness. We demonstrate that
Consider any
Therefore, the selected mode by (8) with limited knowledge for every camera optimizes the global utility by Theorem 1.
6. Simulations and Analyses of Our Approach
In this section, we evaluate our proposed serial dictatorial rule-based game for CS utilizing several network performance metrics in different simulations and quantitatively analyze the complexity required to achieve each step of our approach's design.
6.1. Simulated Performance Analysis
Our proposed approach has been simulated in the following multicamera and multitarget environment.
16 stationary cameras of different FoVs, labeled 1 through 16, are deployed and calibrated in a square-shape area of 230 × 230 cells as in Figure 5.
Every camera is provided with its own safe region and FoV center point in advance.
The scaling factor
Every camera is initially charged with 1000 power bars and only dissipates a bar per time instance if it is active.
The maximum neighboring density for every camera, d, is set to 7 as in Figure 5(a) or 3 as in Figure 5(b).
In a scenario, 10 or 20 targets freely move inside the area, under a speed of 15 cells per time instance, until the network lifetime has expired.
The target locations at the previous time instance obtained by any image-based localization of [10] are always announced to their associated cameras. After receiving this location information, every camera computes the expected locations of its observable targets at the current time instance by the extended Kalman filter as in [11]. To add authenticity to the simulation, we implement imperfect localization by adding a small amount of noise to our target localization.

Two different camera deployment environments with
To permit greater focus on the network performance of our interest achieved by our approach, we vary only the simulation situations with different neighboring densities and different target cardinalities, whereas the energy and scaling specifications of the cameras are not changed. In this environment, our approach is evaluated by observing the number of cameras that are active on average, #Active, the number of cameras that are redundantly active, #RActive, the number of targets that are missed, #Missing, at a time instance, and the amount of time that a camera network survives, Lifetime. To assist in understanding the three metrics, #Active, #RActive, and #Missing, we present two successful and a single-failed examples of

Two successful and a single-failed examples of
Table 2 illustrates the average simulated values of our four primary performance metrics (in two or more significant figures) over 100 random scenario tests. The following claims can be derived from the results.
Simulation results in the four cases of two densities and two target cardinalities.

Claim 1.
On average, six cameras for 10 targets and nine cameras for 20 targets are active. Accordingly, Lifetime for 10 targets is longer than that for 20 targets.
Claim 2.
As d is larger, #RActive and #Missing are smaller. It would be more advantageous for more neighboring cameras to synthesize more accurate target locations by exchanging different information and the full network coverage of
Claim 3.
A smaller numbers of active cameras in all cases somewhat extend the network lifetime from 1000 to 1481.
Claim 4.
Because of the low #RActives and #Missings in all cases, our approach might be able to work over some localization errors, which necessarily occur in any existing localization techniques.
6.2. Complexity Analysis
Because we consider wireless cameras, we must discuss the resource overhead required by our proposed method. For each time instance in our design, energy consumption occurs according to the operations listed in Table 3.
Analyzed complexity by each operation.

The complexities for (1) and (5) depend on the models or algorithms camera sensors employ, and we leave them as α and β. We strongly emphasize that the two operations are conducted only by active cameras, and our proposed approach, on average, activates 0.57 (=9.1/16) times fewer cameras, including the worst case. The computational complexity for (2) is referred to as
The energy consumption of camera sensors is dominated by (1) and (5) because of the significant size of image data [3, 17]. This supports our simple assumption about power consumption that only active cameras can monotonously consume a single power bar per time instance and indicates that our approach can be considered as fairly competitive if targets are not highly crowded in any of the FoVs.
7. Comparison Work
Utilizing the same environments employed in our simulations, we simulated the representative alternatives, PG of [8] and GS of [5], while measuring the four network performance metrics, #Active, #RActive, #Missing, and Lifetime. For GS in particular, we have heuristically assumed that the optimal number of active cameras for 10 targets and 20 targets are, respectively, 6 and 9 by #Actives of Table 2. Because the numbers are not consistently optimal, we examined three GS tests for the two different target sets as {5-GS, 6-GS, 7-GS} for 10 targets and {8-GS, 9-GS, 10-GS} for 20 targets. Table 4 lists each of the network performance results for the five different approaches, on average, after 100 tests. A smaller number of active cameras typically result in longer network lifetime; correspondingly, the GSes with smaller numbers of active cameras provided the network with longer life. However, their performance observed for #RActive and #Missing was lower than analogous results from our approach and PG. Compared with our approach, PG produces similar results for every factor. However, PG requires each camera to compute required utilities for every camera and to communicate with every other camera. This consumes greater resources compared with our approach. Therefore, we emphasize that our approach generally provides more advantageous trade-offs between {#Active, Lifetime} and #Missing and between Lifetime and resource overheads compared with the alternate approaches.
Simulation results of the five approaches.

As representative instances of this comparison process, we provide five simulation screenshots for each approach in one simulation of

Screen shots of the five approaches in the simulation of
8. Conclusion
In this paper, we addressed trade-offs between extending network lifetime and enhancing its sensing accuracy. To minimize the energy consumption necessary for data transmission while aggregating individual inferences to build a global inference, we utilized the inference tree method to initialize an optimal data transmission path, and we demonstrated that it is very effective for reducing the number of data transmissions and energy consumption. We modeled a CS in the context of a cooperative bargaining game, where every participating camera serially optimizes the global utility, employing only local knowledge based on the serial dictatorial rule. The simulated results demonstrated that our approach extends network lifetime and performs accurately over limitedly accurate target locations. Moreover, our approach is energy-efficient for uncrowded targets, compared with the alternative representative conventional studies.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research was supported by the Basic Science Research Program (2013R1A1A2064233) and by the Converging Research Center Program (2013K000358) through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT and Future Planning, Korea. This work was partly supported by the IT R&D Program of MSIP/KEIT, (Development of personalized and creative learning tutoring system based on participational interactive contents and collaborative learning technology).