
Abstract
Automatic video annotation has become an important issue in visual sensor networks, due to the existence of a semantic gap. Although it has been studied extensively, semantic representation of visual information is not well understood. To address the problem of pattern classification in video annotation, this paper proposes a discriminative constraint to find a solution to approach the sparse representative coefficients with discrimination. We study a general method of discriminative dictionary learning which is independent of the specific dictionary and classifier learning algorithms. Furthermore, a tightly coupled discriminative sparse coding model is introduced. Ultimately, the experimental results show that the provided method offers a better video annotation method that cannot be achieved with existing schemes.
1. Introduction
The notion of visual sensor networks is frequently reported as the convergence between the concepts of sensor networks and distributed smart cameras. As a result, the explosive growth of massive video data is afforded by both individuals and organizations users. Accordingly for the sake of the users to search the target video fast and accurately, in information retrieval realm there is a critical need for resolving the problem of how to organize, manage, and index these video data efficiently, thus video semantic annotation is the significant issue of the video indexing. Video semantic annotation, based on the video context, is giving the video the accurately semantic or conceptual “tag,” which leads to the mapping from the underlying characteristics to high-level semantic concept of the video and narrowing the “semantic gap”; also by employing these tags the video data managers are feasible to efficiently run the operations as accession, contractions, and so forth; moreover, to individual users it makes an approach to search and share videos; besides existing network video search engines like Google, YouTube, and Yahoo! Video mostly use the retrieval technology based on text as it shows its advantage at high speed and relatively maturity, and that the “tags” is an important part to constitute the video text information. However, manual tagging video losses in enormous workload and cost also fail in efficiency, with the drawback of high subjectivity. Hence it is necessary to bring the machine learning methods to approach automatic video semantic annotation based on the analysis of the video content and also to support collaborative annotations and create a shared structured knowledge [1].
Commonly video annotation and retrieval ask for considerable relevance between the videos and the given concept, also called as correlation; nevertheless, that also emphasizes the “topicality” and “uniqueness” of the retrieval results [2]. To boost the efficiency of retrieval and browse for the users, the search engine submitting results call for the “concept” with correlation, and the “sub-concepts” with the quality of diversity as well. Somehow nowadays in the context of enormous explosive growth video data, there exist substantial homologous videos (the various versions edited from one same original video) in the data base; hence, the diversification of “nonredundancy” video retrieval displays its significant. Ideally, the top videos of the submitted results should cover all the “subconcepts” in the “concept” entirely meanwhile exclude “subconcepts” repetition. According to that, as fuzzy as the users input, one side for the video retrieval results is that it conveys more broad and diverse video semantics which leads to further catering for the requirement of the users [3–5]; on the other side the “topicality” of these “unique” videos also obtains the decent flux as encounter with magnanimous data, and thanks to the “nonredundant” retrieval results it enhances the users’ browsing efficiency as well.
Because of the above, when semantically annotate them, we attempt to separate diverse “sub-concepts” videos from each other and discriminatively annotate, which may make feasible to diversify objects during the indexing process. Also, discriminatively preannotate the “subconcepts,” which compared to diversified study accelerates real-time processing speed of the search engines or systems and consequently shortens the costing time the retrieval users wait on line. By taking advantage of sparse code, we aim to give a solution to adopt diversity restraint as the discriminative constraint, and add constraint item in the objective sparse coding function, that approaches to the discrimination for the sparse representative coefficients and dictionary boost, finally map the sparse coding to the kernel space, that attempts to obtain the better video retrieval results.
2. Related Works
2.1. Video Annotation
There are two methods in automatic annotating video: one is based on machine learning [6, 7] and the other is based on searching [8]. The former method based on machine learning adopts the tagged training sets, emulate the classification models such as artificial neural network (ANN) [9], kernel density estimation (KDE), Gaussian mixture model (GMM), support vector machine (SVM) [10], hidden Markov model (HMM) [11], graph model [12], optimized multigraph-based semisupervised learning (OMG-SSL) [13], incremental learning model [14], support tensor machine (STM) [15], cross media relevance model (CMRM) [16], multicorrelation learning [17], probabilistic latent semantic analysis (PLSA) [18], and fusing semantic topics (PLSA-Fusion) [19], and predict the tags of the new video data by referring to the classification model. The annotation based on searching, on the other hand, is to search the videos similar to the target video; besides, it explores the local sample and label distributions to search neighborhood similarity measure [20] and then annotates the target video by label propagation. An open platform VATIC (Video Annotation Tool from Irvine, California) is the released tool for crowd source video labeling, which contributes to providing a video annotation user interface; it has annotated various complicated massive datasets [21]. However, no matter what the approach is to automatically annotate the video, the first step of it is to extract video content from the raw data then effectively represent or further extract the features on them. Information extraction (IE) is a topic in semantic processing, which includes entities, relations, and events in natural language texts [22]. Mainly the feature extraction rules the three functions as (1) removal of the noise interference on the annotation and retrieval, which contains in the low-level features of high complex image, (2) the high dimension as the low-level visual features which are required to feature selection and dimension reduction by feature extraction which results in simplifying subsequent learning and classification, and (3) narrowing the “semantic gap” to extract semantic feature and then bridging from low-level feature to high-level “concept”; with the background of nowadays developed divers classification models, based on its considerable maturity, the video content representation plays a particularly important role in video annotation.
Video annotation usually takes the shot as the basic unit; the video content feature on the other hand is extracted from the key frames. Thus, the image feature is the major feature of the video. Traditional global feature such as color and texture generally encounter the complex difficulty expressing semantic information. But recently the booming technologies based on local features including scale-invariant feature transform (SIFT), rotation-invariant feature transform (RIFT), bag-of-words (BoW), and bag-of-features (BoF) represent enormous potential to convey semanteme. Take BoW as an example; it is a mainstream image representation method, and efficiently adopted for image content representation and categorizing visual objects and feature by a histogram of the visual words [23], as well applied for texture representation by accurately combining different features to construct vocabulary. In [24], it achieves the texture representation grounded on BoW framework, and represent colour-texture image content by the attributes of image blobs. BoF, as another efficient image representation model, describes the image as the statistics or the distribution of local characteristics and also performs invariance in scale, rotation, or illumination, compared to global feature which has enhanced the ability of expressing video semantic [25]; then spatial pyramid matching (SPM) is proposed based on the BoF model that is capable of expressing the spatial relationship among the objects shown in the scene. In a word, all the superiority ensures that BoF model acquires the ability for better visual representation. Also already perform well in video annotation.
2.2. Diverse Video Annotation and Representation
Until now, academic research on diversified retrieval tends to be more than diverse video or image annotation. During the process of diversifying retrieval, trained sets generally afford images with “concept” tags instead of “subconcept” tags; hence, the diversified studding is an unsupervised process. Mostly diversified retrieval technology on the basis of the completed correlation searching achieves reranking the correlation retrieval results by using some unsupervised learning algorithm, and it results in the goal that advanced in diversity. The reranking method is mainly focused on “Greed” selection method and clustering: the “Greedy” selection method, usually according to maximal marginal relevance (MMR) index, selects and reranks the correlated retrieval results and plenty indexes like MMR evaluation index lead to large scale use in diversified retrieval as well [26, 27]; yet considering the drawback of the “Greedy” selection method, the previous unhealthy selection will possibly extend a great influence on the subsequent selection process, thus worsening the whole sorted result. And the diversified searching method based on clustering is based on correlating retrieval results, choosing a certain scale of top-ranked sample set to cluster, and then advancing the samples close to the cluster center, to attain the diversified retrieval results.
Nevertheless, basically all the reranking technologies are based on the searching methods, to study the diversified learning problem from the feature extraction level; no matter if it is annotation or retrieval, whether adopting any reranking methods or not, as mentioned previously, the visual presentation of the video acts as the “bridge” and “bond” mapping from low-level feature to high-level “concept,” and that the visual presentation with excellent performance not only excludes the distraction on the diversified studies caused by the noise underlying the complicated low-level feature but also decreases the dimension of the high dimension feature; hence, it plays a significant role both in classification and retrieval. The pity is that, at present in view of the diversified learning visual representation or feature extraction, the research works still retain in scarceness, not satisfying the requirement for the diversified study to distinguish the “subconcept.”
2.3. Sparse Coding
In recent years, sparse coding has the potential to rapidly advance to further research in machine learning field; for example, the application rage of sparse coding has already extended to blind sources separation [28], voice signal processing [29], image and video feature extraction, signal and image denoting [30], pattern recognition and classification [31, 32], video retrieval, visual tracking, fault diagnosis based on the adaptive feature extraction [33], event detection, image compression, image restoration, reconstruction, imaging, and so forth, and at same time making a remarkable progress on some solving algorithms for sparse coding factors such as basis pursuit (BP) [34], BPDN homotopy, feature sign search (FSS), and “dictionary” learning algorithm such as maximum likelihood estimate (MLE), method of optimal direction (MOD), conjugate gradient method, K-SVD [35], Lagrange dual method [36], and K-LMS.
Sparse coding is widely and successfully employed in the machine vision, which originates from the research finding on neuroscience. Brain primary visual cortex V1 expresses the received visual signals as the restructurings with a few interpretable “basis” [37], in order to employ sparse signal to represent image signal [38]. Accordingly, it has the superiority to apply the sparse coding to the video representation in the video annotation; yet compared to low-level feature, it shows more advantages to analyze the “redundancy” of visual patterns through the semantic layer, which has been confirmed by the applied research of the video thumbnail [39]. Therefore, it is viable to adopt sparse coding for the video representation and extend it to diversify annotation which is the aim to eliminate the “redundancy” of the retrieval results besides enhancing its “topicality.”
3. Method Description
For a general classification problem, the training sample points can be represented as a matrix
3.1. Introduction to Sparse Coding
Sparse coding is a way that selects the least possible basis from an over-complete dictionary to represent the images signal under certain reconstruction error constraints. Intuitively, the sparsity of the coding coefficients can be measured by l0-norm, which determines the number of nonzero entries in a vector or matrix. Since l0-norm regularization is a NP-hard problem, l1-norm regularization is widely employed in sparse coding, as it is shown that l0-norm and l1-norm regularization are equivalent under certain conditions [41].
In detail, let

3.2. Diversification Video Retrieval and Representation
Adopt diversity restraint as a discriminant constraint among different categories. For diversity constraint item between different categories it already has succeeded in the applications of subspace learning method, enables advancement in the criteria for feature mapping, and also increases the separating capacity among various categories; applied to sparse coding modality it could be expressed as
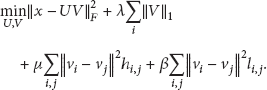
Here, U is the complete “dictionary,”
(1) Defined template feature set: when the scale of the local feature tends to be larger, to raise the efficiency, the approach is to randomly collect some features as a template feature set
(2) Solving constrained sparse representation coefficient: for a feature x, first we figure out the corresponding vectors

Obviously, when the local feature and template feature tends to be larger, because of the neighborhood region or the smaller defined K value, the new additional Laplacian constraint items are sparse in the objective function (2), due to the more local feature, which leads to more discriminant constraint items represented as nonsparse. For BP method, the more constraint items are, the more difficulty in the linear programming of convergence there will be, but for the FSS method, if the discriminant constraint items are nonsparse, this will highly increase the calculation of the gradient and the complexity of the matrix in the quadratic programming directly. Thus, in order to decrease the complexity of the calculation, adopt the following objective function:

(3) Discriminant “dictionary” learning: assume the “dictionary” as

(a) Represent V as

(b) Represent Vas row vector
(c) It can be figured out that to split row in different positions leads to acquiring different
3.3. Diversify Video Key Frame Representation Based on Local Structure Constraint Sparse Coding
Usually, there is shortage of “subconcept” tags in the training video samples; hence diversified annotation and retrieval are the process of unsupervised learning and classification, while, during the sparse coding, it will have an effect on maintaining positive local topology structure that constrains the negative local topology structure of the “concept,” thus decreasing the distinctiveness of the “subconcept” in the positive category. So it is available to adopt “neglect” negative local constraint to strengthen the maintaining local topology structure of the “subconcept” and also to be more similar between neighborhood sparse coding coefficients as diversifying nonneighborhood coding coefficients, which leads to improving the separability of the “subconcept” and reducing the noises sensitive that underlies in the sparse coding of the “subconcept” neighborhood. The concrete implement is that, only constrain the neighborhood relation between the samples and positive templates:


As mentioned above,
3.4. Sparse Coding in Kernel Space
To solve the sparse coding mapping in kernel space, it aims to obtain better performance at video retrieval results. Assume the function φ satisfies

Similarly, it can be solved by the alternative optimized method for the above function (functions (3) and (7) refer to the similar relevant method in the kernel space). When fixing U to work out v, the objective function can be translated into
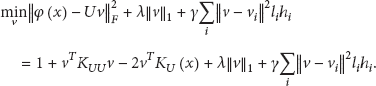
In which,

In the formulation
4. Experiments and Results
4.1. Experimental Datasets
In this section, we compare the proposed method with other methods, such as the CMRM [16], PLSA [18], and PLSA-fusion [19]. We select experimental datasets from CC_WEB_VIDEO [43] which include the video from five semantic concepts; each concept has many subconcepts, as shown in Table 1. Each concept represents the set of objects sharing the same values for a certain set of properties; each subconcept contains a subset of the objects in the concepts above it.
Test sample videos.

4.2. Automatic Annotation Comparison
We achieved the video annotation performance by comparing the test set automatically and then labelling the original label for evaluation. The recall was calculated based on how many correct words we extracted compared to the Total words detected 
Table 2 shows the recall rate from the tracking performance after the processing step. In addition, Table 3 shows the precision rate of the same processing step.
Mean per-word recall.

Mean per-word precision.

The Precision was calculated based on how many correct regions we extracted against the Total number of actual active regions that our system should have detect
4.3. Comparison of Semantic Search Results
A problem that arises is that the diversified annotation is usually achieved by clustering algorithm; therefore, cross validation or result estimation could refer to the clustering index such as Davies-Bould or Dunn Index, but the clustering index excludes the relevant valuation, which fails in reflecting the influence that the diversified learning affects the correlation. Thus this project combines correlation and diversification valuations, then propose Maximal Scatter Relevance (MSR) estimation index to choose coefficients, as
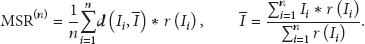
Comparison of ranked retrieval results.

4.4. Discussion
From the above results, we can conclude that our method has good performance and surpasses the other competing methods. The experimental results showed that the proposed method was able to improve the performance at the video annotation and retrieval task, especially in mean per-word precision.
5. Conclusion
In summary, the paper describes the methods of a solution of the sparse representative coefficients with discrimination, the learning of the sparse representative coefficients, and dictionary boost of each other for discrimination and forms a tightly coupled discriminative sparse coding model. For a future work, we will extend our sparse coding into the kernel space, to obtain the accurate expressions of spatial orders and video sequences which are associated with concepts and subconcepts.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Nature Science Foundation of China (41101432, 41201378), the Natural Science Foundation Project of Chongqing (cstc2012jjA40014), and the Scientific and Technological Research Program of Chongqing Municipal Education Commission (KJ120526).