
Abstract
Cooperative communication has emerged as a new wireless network communication concept, in which parameter optimization such as cross-layer cooperation plays an important role. Heuristic evaluation postdecision state learning algorithm (HE-PDS) is proposed in cross-layer cooperation. The proposed algorithm exploits the determinate state information and jointly considers the transmitting power and channel state condition at the physical layer and the buffer congestion control at the media access control layer. The experimental results show that the cumulative average total costs of HE-PDS algorithm decrease about ten times and 8% under the maximum delay and throughput constraints and the power costs decrease about 50% and 28% under various delay limits and about 100% and 56% under the different throughput constraints than the traditional Q algorithm and PDS algorithm, demonstrating that the proposed algorithm has much better energy-efficient performance and faster convergence speed and outperforms the traditional Q learning algorithm and PDS learning algorithm.
1. Introduction
Recently, the merits of cooperative communication in the physical layer have been explored. However, the impact of cooperative communication on the design of the higher layers has not been well understood yet. As wireless devices often rely on battery power sources in wireless communication, how to minimize the energy consumption under the constraints on both delay and throughput has posed a great challenge and attracted lots of research attention in recent years [1]. Besides, affected by the fading channel state, time-varying buffer state, and dynamic traffic characteristics, this problem becomes more sophisticated [2]. Since the unknown environment can be modeled as a Markov decision process (MDP), it is reasonable to build the cross-layer transmission strategy based on this property [3, 4]. The state of the art of research on the energy-efficient problem in wireless communication can be mainly divided into two categories: the cross-layer design and approximate algorithm design. Related research is as follows.
From the view of energy-efficient design, the authors in [5] analysed the throughput performance. However, the feature of limited buffer has not been taken into account during the performance analysis. References [6–8] considered energy-efficient packet transmission under packet delay constraint. In [9, 10], the authors investigated the balance between throughput and the energy consumption. Although all these works obtained good energy-efficient performance, the trade-off among delay, throughput, and energy consumption is not fully considered. Aiming at the characteristics of MDP model, [6, 9–11] formulated the optimal packet transmission as a control policy which was solved by reinforcement learning (RL) algorithm. However, most of these works performed the computation offline which resulted in restricted application. In [7], the authors introduced the postdecision state (PDS) learning to raise the convergence rate. Unfortunately, the state of the transmission power of the model has not been taken into account. Although [11] took the power state into consideration, the effect of trade-off between exploration and exploitation is not been fully considered. Therefore, the convergence performance of the algorithm is needed to be further improved.
To address the aforementioned challenge, this paper extends our prior work [8] by considering the constraints of both delay and throughput simultaneously. We propose a heuristic evaluation postdecision state (HE-PDS) algorithm for packet transmission, which has not only low computation complexity but also faster convergence speed. The specific contributions of this paper include the following.
A literature survey about various existing energy-efficient policy, analyzing their advantages and disadvantages.
An effective energy-efficient optimization models for decreasing the energy consumption is proposed in wireless communication.
A unified framework to realize a scheduling mechanism is proposed by jointly considering the transmit power and channel state at the physical layer and the buffer congestion control at the media access control layer.
An online RL algorithm is proposed that fully exploits the known state information about the system's dynamics to improve learning performance.
Performance analysis of the proposed algorithm and an evaluation of the algorithm with respect to other existing algorithms.
The rest of this paper is organized as follows. A brief overview of the related works is presented in Section 2. The formulation of the problem within the structure of CMDP is presented in Section 3. Section 4 presents an online HE-PDS algorithm for cross-layer optimization. Experiments are given in Section 5. Finally, Section 6 summarizes the anticipated results and discusses some future research directions.
2. Cross-Layer Cooperation Model
Cooperative communication will improve network performance in certain circumstances. However, if the cooperative communication is not necessary, it will make the system more complex, increase the transmission delay, and reduce the efficiency of the system. As illustrated in Figure 1, we consider a point to point system where one single user (a transmitter and receiver pair) transmits data from the finite buffer queue over a time-varying channel. Meanwhile, we divide the transmission time into equal slots of length

Wireless transmission system.
2.1. Physical Layer Model
We consider a discrete time block Rayleigh fading channel model with additive white Gauss noise (AWGN) [12, 13], where its power spectrum density is

FSMC model.
In Rayleigh fading channel, the received instantaneous signal-to-noise ratio (SNR) φ is exponentially distributed with probability density function:

where
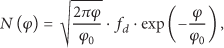
where

where the steady state probability (SSP)

2.2. MAC Layer Model
As shown in Figure 3, let the transmission buffer be the first in first out queue. In the nth time slot, the transmitter receives


Buffer timing diagram.
Afterwards, we define that the backlog at the transmitter buffer is denoted by
Let

where PER is the packet error ratio, which meets

2.3. Dynamic Power Management Model
To reduce power consumption, we assume that the wireless card can turn to low power state similar to [8, 11, 16]. Specifically, the card may be one of the two power management states; that is,
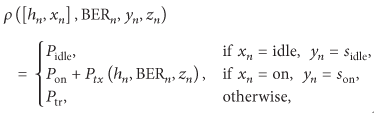
where

In the implementation of power management action, we assume that the delay of the power state switching from one state to another is negligibly small. Let

State diagram of the power model.
3. Problem Formulation
As discussed in the second section, in a given channel state, since the energy consumption function is a convex function when z packets are transmitted, there must exist an optimal solution to this problem [17]. Given the buffer state b, channel state h, and power management state x, we define a joint vector state

where the holding cost at the start of each slot stands for the number of packets that still remain in the buffer. We use parameter η to fully analyse the effect of the holding cost and overflow cost on wireless transmission. Thus, the buffer cost can be evaluated as
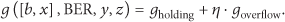
For the average packet arrival rate λ, the system throughput can be calculated by

where PER is packet error rate and
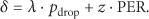
In summary, we can reformulate the cross-layer energy-efficient transmission optimization as a problem of minimizing the long-term average power consumption under transmission delay and throughput constraints. Therefore, the optimization problem can be expressed as
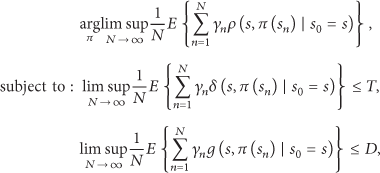
where

4. Heuristic Evaluation PDS Learning Algorithm
4.1. Algorithm Description
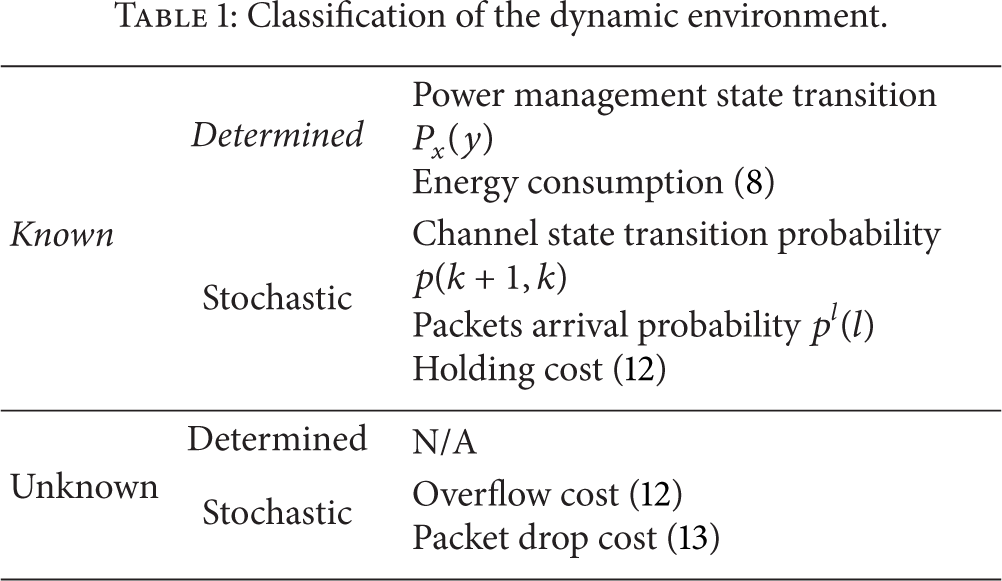
The state information of the environment is often assumed uncertain when the state-action pairs are learned in the traditional Q learning algorithm. Therefore, the known state information can not be fully utilized in the learning process which will inevitably result in poor convergence performance. However, the known information may be determined in most communication systems. Table 1 gives an example of what is known and what is unknown. In Figure 4, when
Classification of the dynamic environment.
In order to use the known state information, we introduce postdecision state (PDS) and PDS value function as in [7]. In PDS learning algorithm, the search of optimal strategy is mainly performed by PDS. Specifically, as shown in Figure 5, the PDS is a virtual state of the system after performing a selected action. In addition, we further assume that the buffer state changes from the current state to the PDS, and, afterwards, the channel state and power management state change from the PDS to the next state.

PDS model.
Defining the PDS set
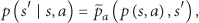
where


where
The optimal scheme can be calculated by the following formula in traditional Q learning [19]:

where
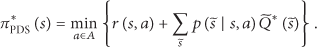
Although the PDS learning can reduce action exploration by using the determined information, the action does not balance the trade-off between the exploration and exploitation. To overcome the problem, we propose an HE-PDS learning algorithm that uses heuristic function and evaluation function to improve the algorithm performance. Specifically, the heuristic function stands for the importance when executing an action and the evaluation function for the feasibility. Thus, the optimal scheme can be written as follows:
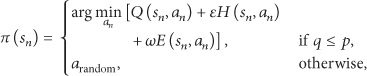
where

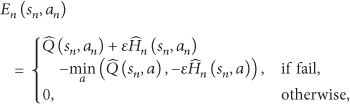
where σ is a small real value and
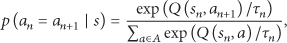
where
In summary, the solving process of energy-efficient problem is as follows. In the nth slot, The HE-PDS first observes the current state

where
4.2. The Procedure of the HE-PDS Learning Algorithm
According to the analysis stated above, the working procedure of HE-PDS learning algorithm is summarized in Algorithm 1.
( ( ( ( ( ( ( (
5. Numerical Results and Discussion
In this section, we will compare the performance of the proposed algorithm with that of the traditional Q learning and PDS learning algorithm. In the numerical computation, we assume that the bits can be mapped into QAM symbols by Gray code in physical layer similar to [8, 11]. The buffer length is
Channel states and transition probabilities.

In the typical 802.11
5.1. Performance Comparison under the Fixed Delay and Throughput Constraints
Figure 6 compares the cumulative average costs for 80000 time slots under the maximum delay (

Performance comparison under the constraint of fixed delay and throughput. (a) Cumulative average total cost. (b) Cumulative average delay overhead. (c) Cumulative average throughput cost. (d) Cumulative average energy consumption.
5.2. Performance Comparison under Various Delay Limits
To validate the performance of the HE-PDS algorithm for different delay limits, taking values of

Delay-energy trade-off for different algorithms.
5.3. Performance Comparison under Various Throughput Limits
To verify the performance under various throughput limits, Figure 8 shows the performance comparison under the throughput limits

Throughput-energy trade-off for different algorithms.
5.4. Algorithm Convergence Analysis
In this section, we evaluate how the parameter γ will affect the convergence of the HE-PDS energy-efficient algorithm. γ will be set to 0.98 and 0.85, respectively. We also set T to

Algorithm convergence with different discount factor γ. (a) Energy consumption convergence speed of the three strategies with
6. Conclusion
In this paper, we investigated the impacts of the cooperative communications and designed cooperative cross-layer algorithm on energy-efficient policy in wireless networks while subjected to both transmission delay and throughput constraints. Given the dynamic buffer, time-varying channel states, and system-level power consumption in a point to point transmission environment, the problem is formulated as a CMDP and further converted into an UMDP by Lagrange multiplier. We propose an HE-PDS learning algorithm based on the determinate state information to achieve an optimal energy-efficient strategy by using the heuristic function and evaluation function. Furthermore, the performance of different energy-efficient strategies is compared and the proposed scheme is verified through simulations. Through the discussions, we highlight that the proposed algorithm has much better energy-efficient performance and faster convergence speed than the other typical state-of-the-art schemes.
Footnotes
Appendices
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Natural Science Foundation of China (no. 61072138 and no. 61379005) and Southwest University of Science and Technology (12zx7127).