
Abstract
A social network service (SNS) is a platform to build social networks or social relations among people. Many users enjoy SNS with their smart devices, which are mostly equipped with sensory devices. The sensitive information produced by these sensory devices is uploaded to SNS, which may raise many potential risks. In order to share one's sensitive data with random people without security and privacy concerns, this paper proposes a shared interest discovery model for coauthor relationship in SNS, named as coauthor topic (coAT) model, to identify the users with similar interests from social networks, and collapsed Gibbs sampling method is utilized for inferring model parameters. Thus, one can reduce the possibility that recommended users are not friends but attackers. Finally, extensive experimental results on NIPS dataset indicate that our coAT model is feasible and efficient.
1. Introduction
A social network service (SNS) [1] is a platform to build social networks or social relations among people who, for example, share interests, activities, backgrounds, or real-life connections. A SNS consists of a representation of each user (often a profile), his/her social links, and a variety of additional services, such as potential friend recommendation service. Most social network services, such as Facebook, LinkedIn, and Twitter, are web based and provide means for users to interact over the Internet.
Recently, people enjoy SNS with their smart devices including phones and tablets, which are mostly equipped with sensory devices such as global positioning system (GPS) and camera. As we all know, the information produced from the sensory devices is often sensitive to people's privacy. However, many users like to upload such sensitive information to SNS for some reasons, which raises many potential risks [2]. For example, some attackers usually pretend to originate from a trusted SNS and post a comment containing a malicious URL. If one follows the instructions, he/she may disclose sensitive information or compromise the security of his/her system.
This paper focuses on dealing with the following problem: how to share one's sensitive data with random people without security and privacy concerns. Our main idea is to identify the users with similar interests from social networks, so that recommended friends are not attackers, but indeed friends. This idea is motivated by the following fact. In order not to be recognized as an attacker, he/she often posts a comment related to your posted article. As we all know, he/she does not care about your posted article but entices you to click the malicious URL hiding in the comment. If we are able to analyze in advance whether there are some shared interests, SNS may directly filter the comments.
In the paper, academic social network is taken as research object, which are about interests of academic persons. For example, given coauthors with Koch_C in Figure 1 and coauthored papers in Table 1, our model described in the article can easily discover the shared interest from this social network.
Papers coauthored by Bair_W, Horiuchi_T, Luo_T, Douglas_T, and Manwani_T with Koch_C in NIPS dataset.


Coauthor social network of Koch_C in NIPS dataset.
The organization of the rest of this work is as follows. In Section 2, we firstly discuss briefly the author topic (AT) model and then introduce in detail our proposed coauthor Topic (coAT) model. Section 3 describes the collapse Gibbs sampling methods used for inferring the model parameters. In Section 4, extensive experimental evaluations are conducted, and Section 5 concludes this work.
2. Generative Models for Documents
Before presenting our coauthor topic model (coAT), author topic (AT) model is described firstly. The notations are summarized in Table 2.
Notations used in the Generative Models.

2.1. Author Topic (AT) Model
Rosen-Zvi et al. [3–5] propose an author topic (AT) model for extracting information about authors and topics from large text collections. Rosen-Zvi et al. model documents as if they were generated by a two-stage stochastic process. An author is represented by a probability distribution over topics, and each topic is represented as a probability distribution over words. The probability distribution over topics in a multiauthor paper is a mixture of the distributions associated with the authors.
The graphical model representations for AT model are shown in Figure 2. The AT model can be viewed as a generative process, which can be described as follows.
For each topic
(2) for each author
(3) for each word

The graphical model representation of the AT model.
2.2. Coauthor Topic (coAT) Model
The graphical model representations of the coAT model are shown in Figure 3(a). The coAT model can be viewed as a generative process, which can be described as follows.
For each topic
draw a multinomial for each author pair
draw a multinomial for each word
draw an author draw another author if draw a topic assignment draw a word
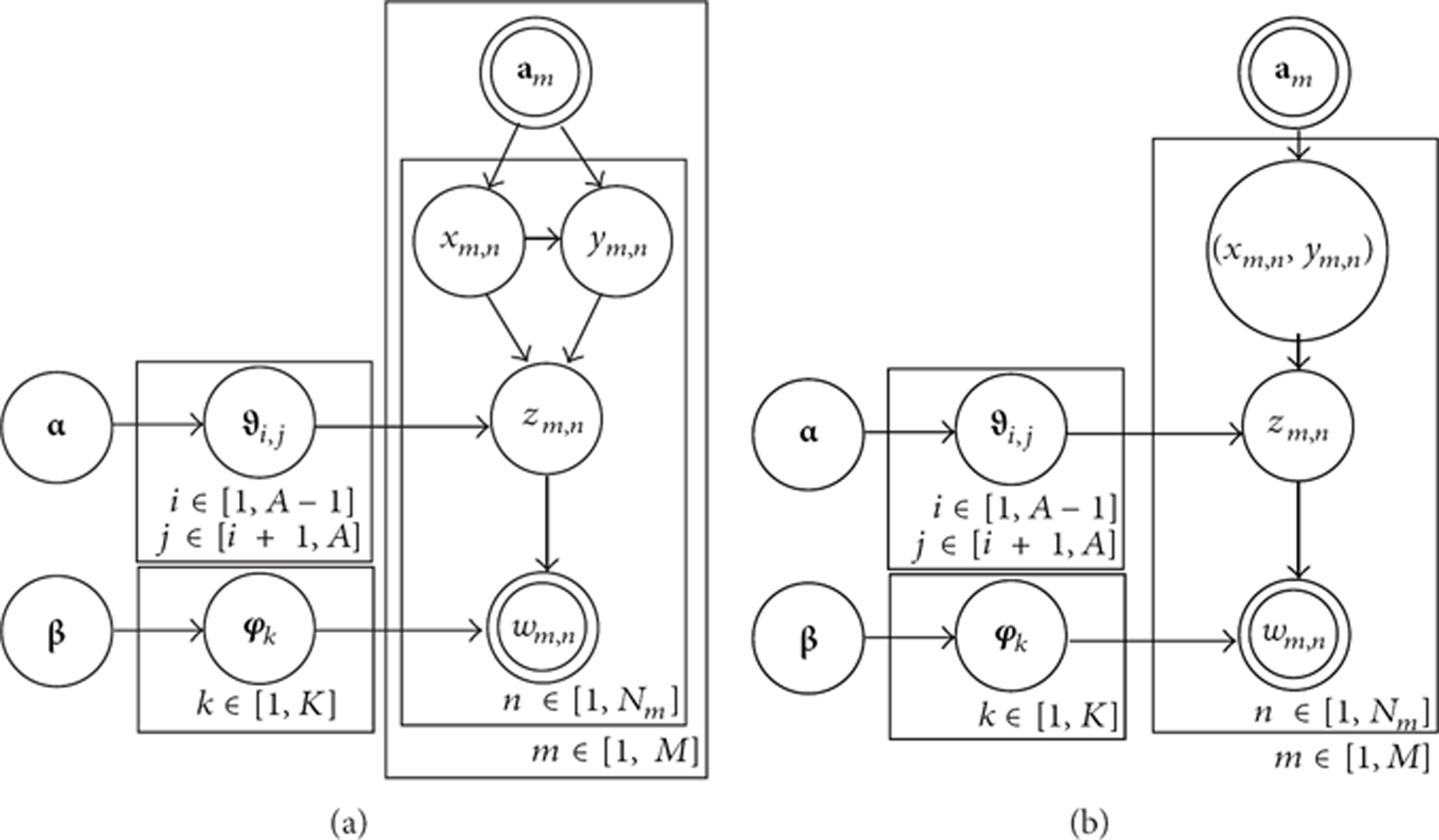
The graphical model representation of the coAT Model.
As shown in the above process, the posterior distribution of topics depends on the information from the text and authors. The parameterization of the coAT model is

In fact, if we do not draw one author
3. Inference Algorithm
For inference, the task is to estimate the sets of thefollowing unknown parameters in the coAT model: (1)
In the Gibbs sampling procedure, we need to calculate the full conditional distribution 
If one further manipulates the above equation (2), one can turn it into separated update equations for the topic and author of each token, suitable for random or systematic scan updates:


During parameter estimation, the algorithm keeps track of two large data structures: an 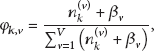

With (3)–(6), Gibbs sampling algorithm for coAT model is summarized in Algorithm 1. The procedure itself uses only seven larger data structures, the count variables
multinomial parameters zero all count variables: sample topic index sample one author index sample another author index swap sample an author pair index sample a topic index read out parameter set read out parameter set
4. Experimental Results and Discussions
NIPS proceeding dataset is utilized to evaluate the performance of our model, which consists of the full text of the 13 years of proceedings from 1987 to 1999 Neural Information Processing Systems (NIPS) Conferences. The dataset contains 1,740 research papers and 2,037 unique authors. The distribution of the number of papers over the number of authors is shown in Table 3, which indicates that the percentages of papers with 3, 4, and 5 authors at most are 87.8736%, 95.8046%, and 97.9885%, respectively.
Distribution of #papers over #authors in NIPS dataset.

In addition to downcasing and removing stopwords and numbers, we also remove the words appearing less than five times in the corpus. After the preprocessing, the dataset contains 13,649 unique words and 2,301,375 word tokens in total. Each document's timestamp is determined by the year of the proceedings. In our experiments, K is fixed at 100, and the symmetric Dirichlet priors α and β are set at 0.5 and 0.1, respectively. Gibbs sampling is run for 2000 iterations.
4.1. Examples of Topic, Coauthor Relationship Distributions
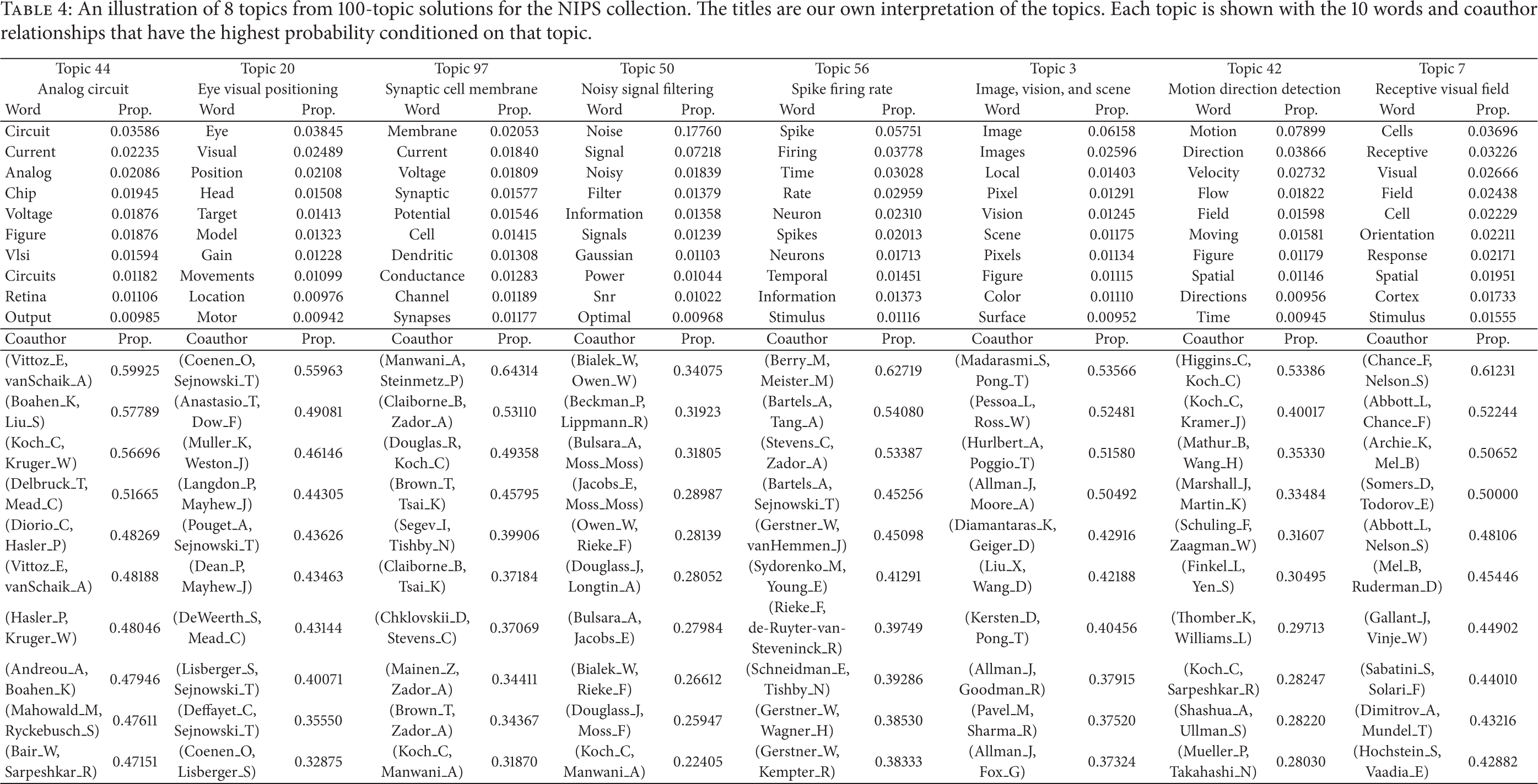
Table 4 illustrates examples of 8 topics learned by coAT model. The topics are extracted from a single sample at the 2000th iteration of the Gibbs sampler. Each topic is illustrated with (a) the top 10 words most likely to be generated conditioned on the topic; (b) the top 10 coauthor relationships which have the highest probability conditioned on the topic.
An illustration of 8 topics from 100-topic solutions for the NIPS collection. The titles are our own interpretation of the topics. Each topic is shown with the 10 words and coauthor relationships that have the highest probability conditioned on that topic.
4.2. Shared Interest Discovery
In order to analyze further shared interest by an author pair, one can see Table 4 from the viewpoint of author pairs. Table 5 shows the shared interests with Koch_C in NIPS dataset. In Table 5, the meaning of each topic is given in Table 4, and × means that the resulting strength is very low. From Table 5, one can see that shared interests by Koch_C and Manwani_A include Topic 97, Topic 50, and Topic 56 with the strengths of 0.31870, 0.22405, and 0.10003, respectively. By comparing Table 5 with Table 1, it is not difficult to see that our discovered shared interests make sense.
Shared interests with Koch_C in NIPS dataset.

4.3. Predictive Power Analysis
In order to compare the performance of AT and coAT models, we further divide the NIPS papers into a training set 

Figure 4 shows the results for the AT model and coAT model on the test set
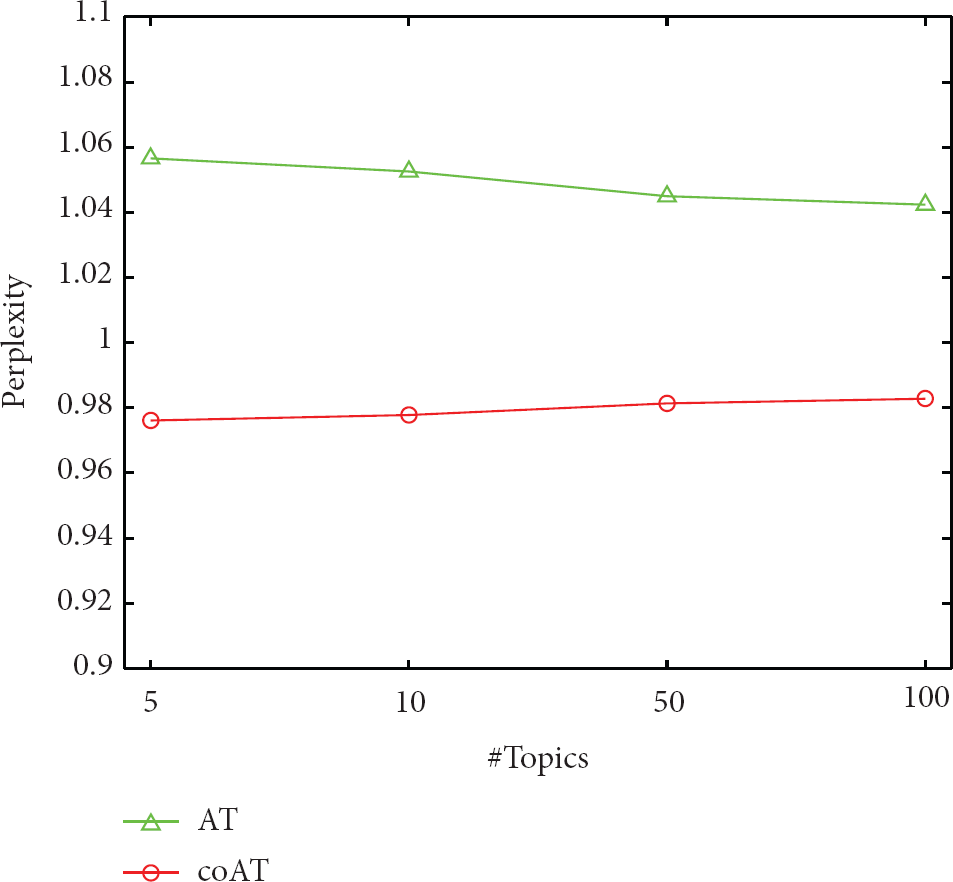
Perplexity of the test set
5. Conclusions
Social network service (SNS) is a way for people to connect and share information with each other online. However, these sensitive pieces of information are often sensitive to people's privacy and raise security concerns. Some pieces of information are even more used for providing users with user-customized or context-aware services by commercial companies.
In order to solve this problem, a shared interest discovery model for coauthor relationship in SNS, named as coauthor topic (coAT) model, to identify the users with similar interests from social networks, and collapsed Gibbs sampling method is utilized for inferring model parameters. Thus, one can reduce the possibility that recommended users are not friends but attackers. The results on NIPS dataset show that discovered shared interests make sense.
The relative simplicity of the approach in the work provides advantages for injecting these ideas into other topic models. For example, in ongoing work, we are finding dynamic shared interest patterns in SNS over time, with a coAT model over time, similar to our previous work on AT over time (AToT) [13, 14]. Additionally, the collapsed Gibbs sampling method following the main idea of MapReduce [15, 17] is also utilized for inferring the coAT model parameters. Many other extensions are possible.
Footnotes
Appendix
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was funded partially by Fundamental Research Funds for the Central Universities: Research on Forest Property Circulation Mechanism in Collective Forest Area under Grant no. JGTD2014-04, Beijing Forestry University Young Scientist Fund: Research on Econometric Methods of Auction with their Applications in the Circulation of Collective Forest Right under Grant no. BLX2011028, and Key Technologies R&D Program of Chinese 12th Five-Year Plan (2011–2015): Key Technologies Researcher on Large Scale Semantic Computation for Foreign Scientific & Technical Knowledge Organization System, and Key Technologies Research on Data Mining from the Multiple Electric Vehicle Information Sources under Grant no. 2011BAH10B04 and 2013BAG06B01, respectively.