
Abstract
We consider the soil moisture monitoring problem and propose a WSN associated clustering strategy based on spatiotemporal data correlation, which ensures that the nodes within each cluster can share a good data correlation and consequently makes the cluster head do the data fusion more efficiently. As a result, the energy of each node will be saved and the lifetime of the whole sensor network will be extended. In the associated clustering strategy, the different clusters can be divided by the correlation characteristics of nodes data, which is based on a dynamic model and a correlation characteristics model after the correlation coefficient analysis. Simulation results show that our proposed associated clustering strategy works very well in soil moisture measurement. Moreover, as compared with the traditional random clustering, the associated clustering strategy based on data correlation achieves better performance for each cluster, and will be more efficient in data fusion at the cluster heads.
1. Introduction
The improvement of embedded system design, sensor node design, and low power wireless communication techniques has made the large-scale wireless sensor networks (WSN) become an attractive solution for many applications [1]. WSN has features such as large-scale and high-density, independence from infrastructure, self-organizing, and adaptive network topology, making it exhibit a distinct advantage in many applications. When used in industrial or agricultural fields [2], WSN can provide cost-effective data monitoring and meanwhile bring several remarkable superiorities, such as concealment, ease of deployment, timeliness of data, reliability, and high coverage density.
Clustering [3] is a network management method, which divides the network nodes into several separated subsets according to some certain rules. Cluster head is responsible for collecting the data within its cluster and forwarding it to the base station. Data integration in cluster head can reduce the redundant data in networks and, consequently, save the energy consumption and prolong the network lifetime. Existing clustering strategy, such as LEACH, GAF, TEEN, and PEGASIS, is mostly cluster by the distribution of cluster head, distance between nodes, remaining energy, and network topology. Data correlation within one cluster is rarely a major consideration in clustering. In practical applications, data between nodes are generally correlated [4]. However, traditional random clustering strategy has poor data correlation within cluster, which leads to low data integration and thus generate massive data redundancy in network. Therefore, WSN clustering strategy based on data correlation has become a hot spot. In clustering process, partitioning the associated nodes into one cluster can get efficient data integration in cluster head. Accordingly, reducing the traffic in network greatly saves network resource and energy.
The main contribution of this work is to exploit the spatiotemporal correlation to divide the WSN clusters. The inherent correlation of a specific application is taken to be the basis of clustering. Take soil moisture measurement application as an example and establish a universal associated clustering strategy, which is also suitable for industrial applications when the soil moisture model is replaced by the particular industrial model. Based on Rodríguez-Iturbe soil moisture model, establish a dynamic model of soil moisture in greenhouse. Provide a clustering strategy based on spatiotemporal data correlation, which makes nodes in a cluster share a good correlation so as to do more efficient data integration, consequently, saving energy and extending the network lifetime.
2. Related Works
Several methods have been developed to analyze the spatial and temporal correlation characteristics in WSN. In [5], variograms are used to analyze spatial correlation. In [6], spatial correlation is used for schedule so as to achieve energy efficient data aggregation. In [7], an error-bounded data compression using data spatial-temporal correlation is provided. However, in the above studies, they mostly get data correlations from a single dimensional relation, spatial or temporal; besides, associated correlation is also nonqualitative. Particularly, spatial correlation is still just equivalent to physical location correlation, but not the data spatial correlation. In [8, 9], linear correlation between n-dimensional random variable and the definition of linear correlation coefficient of multiple variables are studied.
In [10], temporal and distance correlation are both used as clustering basis to reduce traffic in network to achieve the goal of energy saving. Similar clustering method is also mentioned in [11], which only takes the spatial correlation into account. In [12], a novel clustering algorithm based on correlation of sensor data is proposed. Its key is to express the data redundancy of WSN as formalized data correlation, thereby considering clustering from the perspective of data dependency. In [13], Yang et al. studied to define the correlation of soil moisture between different vertical depths by correlation analysis and R-type hierarchical clustering analysis.
In study of soil moisture model, Rodríguez-Iturbe et al. in [14] proposed several typical dynamic stochastic models of soil moisture and the corresponding probability density function of soil moisture. Rodríguez-Iturbe model is the one which considered more completely the dependence of random input and output of soil moisture. Main factors of soil moisture such as rainfall, vegetation, and soil are expressed as quantified model. Further discussions of spatial and temporal variability of soil moisture are proposed in [15]. However, in this model, rainfall was proposed as the main factor of soil moisture, which is difficult to achieve fine-grained soil moisture analysis model. As for the detection of soil moisture in greenhouse, irrigation replaced rainfall to be the main entry of soil moisture. In [16, 17], sprinkling irrigation is analyzed, which is an irrigation method widely used in greenhouse. However, its model only depends on some parameter coefficient.
In this paper, consider the main affect factors of soil moisture in greenhouse; a dynamic soil moisture model is established. Meanwhile, a spatiotemporal correlation characteristics model is proposed after the soil moisture model. Associated clustering strategy based on data correlation is finally raised, which can implement efficient data integration within each cluster and reduce traffic in network, so as to achieve energy balanced efficient WSN.
The remaining of the paper is organized as follows: soil moisture correlation characteristics model is established in Section 3, which is based on a dynamic soil moisture model and an irrigation model. Section 4 proposes an associated clustering strategy using the idea of correlation clustering pedigree chart. Simulation results of clustering algorithm and verification of correlation are deployed in Section 5. Finally, conclusions and further works are mentioned in Section 6.
3. Data Correlation Characteristics
3.1. Soil Moisture Model
Soil moisture is affected by many factors like climate, rainfall, irrigation, soil structure, and so forth. So, it is difficult to establish an accurate soil moisture model by taking all the factors into account. Based on the classic Rodríguez-Iturbe soil moisture dynamic model, we established a soil moisture model specifically for greenhouse, which takes irrigation as a major factor of soil moisture entry. The model gives a complete expression of soil moisture input and output items. Ignoring the effects of terrain, it proposed a quantitative simulation for several major factors such as irrigation, vegetation, evaporation, and leakage; meanwhile, take the upper and lower bounds of soil water capacity into consideration. Soil moisture model can be described by the following water balance equation:
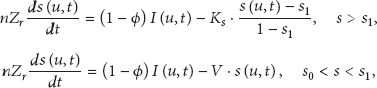
3.2. Irrigation Model
Assume a greenhouse environment using sprinkler irrigation technology, with sprayers uniformly distributed in the crop area. As shown in Figure 1, distance between sprayers is D; each sprayer uniformly watered a circle whose radius is R. Consider that no area is irrigated by 3 sprayers at the same time, and thus we have
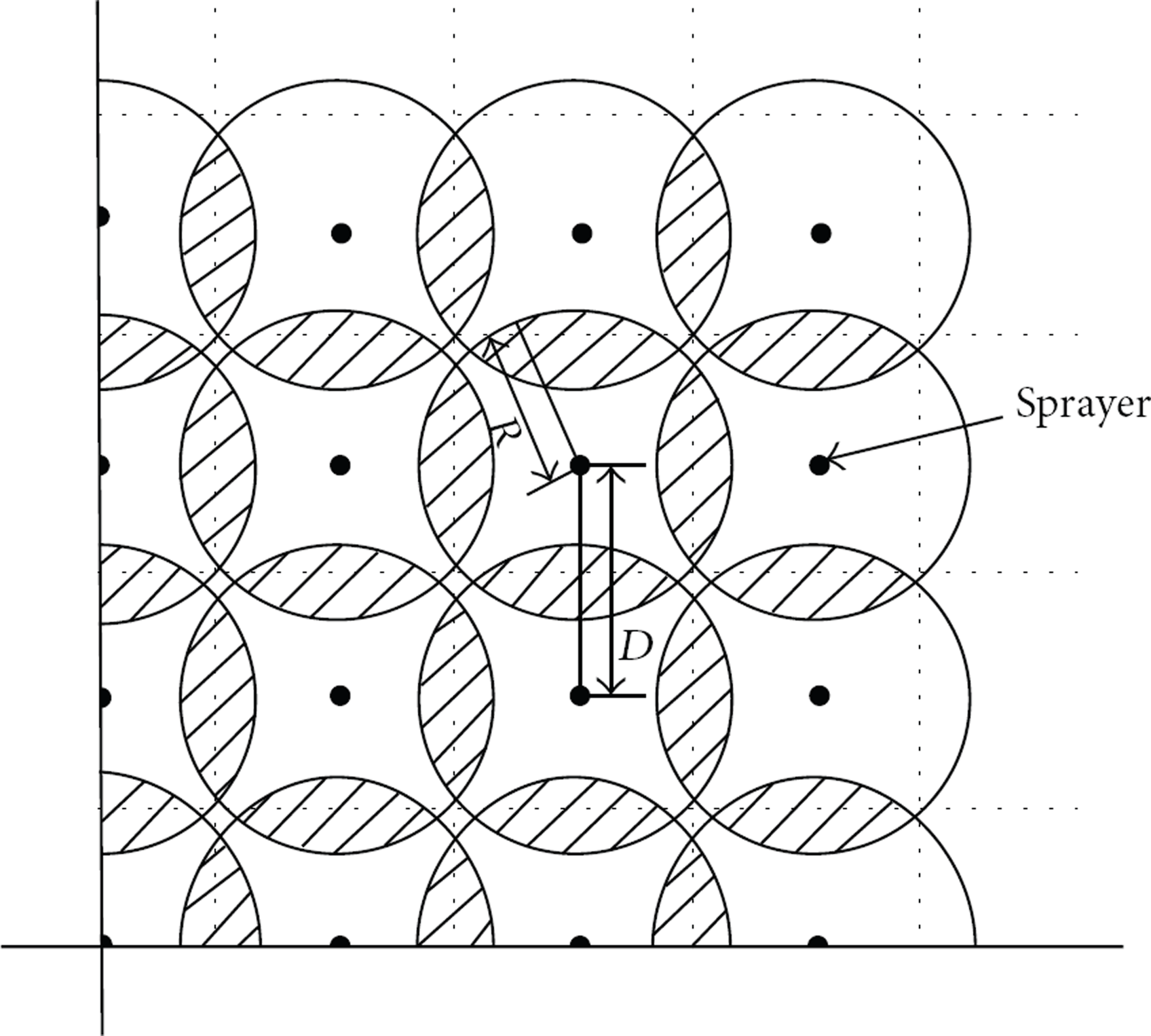
Greenhouse irrigation environment.
In Figure 1, take the lower left point of the monitoring area as the coordinate origin, with sprayers located at
Therefore, irrigation model of point
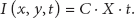
3.3. Correlation Characteristics Model
Based on the soil moisture model and the irrigation model, we can get spatiotemporal correlation characteristics model of soil moisture, which indicate the relation between each influence factor and the correlation characteristics. Accordingly, it can better guide our clustering strategy when network is deployed.
The correlation coefficient is used to define the linear correlation of two variables. Corresponding, we use it to describe the correlation of soil moisture at two different points. The correlation coefficients
The correlation coefficient is defined as
The soil moisture model in (1) can be normalized as

Accordingly, the soil moisture of point A is represented as

The expectation of soil moisture at point A is calculated as
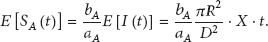

According to the calculation of correlation coefficient, the spatiotemporal correlation characteristics model of soil moisture is proposed as follows:

This correlation characteristics model can be used to approximate the real data correlation to describe the correlation characteristics of soil moisture.
4. Associated Clustering Strategy
According to the correlation characteristics calculated in (7), the associated clustering strategy uses cluster analysis to divide associated sets into clusters.
Clustering is process to partition data into different clusters or classes. Objects within one cluster share a great similarity, while objects between different clusters have a great dissimilarity. Clustering is a statistical analysis technique that divides objects into relatively homogeneous groups (clusters). The clustering analysis process is shown in Figure 2. Data correlation is the basis of clustering process in this paper.

Clustering analysis process.
The initialization process of associated set partition algorithm is described as each node is initialed as a single associated set
Algorithm 1 describes the process of our associated clustering strategy. Comparing with random clustering strategy, associated clustering strategy guarantees that the nodes divided into the same cluster have a greater data correlation. Thus, more efficient data aggregation can be done at the cluster head.
Input: N is the number of sensor nodes, K is the expected number of clusters, data nodes. Output: (1) /* Initialization: initialize associated set and initial correlation between these sets */ (2) FOR i IN (3) {/* Initialize associated set (4) InitGroup( (5) FORj IN (6) /* Initialize the correlation (7) InitCor( node (8) } (9) (10) /* Clustering process: combine the associated sets until its number is no larger than K*/ (11) WHILE ( (12) { (13) FindMaxCor( sets */ (14) Merge( (15) Delete( (16) /* update the correlation between newly generated (17) FOR k IN (1 : 1 : N) (18) IF (Exist( (19) UpdateCor( (20) } //end of while
5. Simulation Results
In order to verify the effectiveness and performance of associated clustering strategy, simulation was taken in experimental environment with a monitor area 4 m × 6 m. 50 sensor nodes were deployed randomly in the area, with location known. For the soil moisture application, sprayers in the greenhouse are distributed with irrigation radius
Object distribution in the monitoring area.
5.1. Effectiveness of Soil Moisture Correlation Characteristics
An ideal data correlation characteristics model should be able to approximately describe the real data correlation. Model with such character can effectively illustrate the spatiotemporal correlation of soil moisture. Figure 4 is verification of the soil moisture correlation characteristics model.

Effectiveness verification of correlation model.
In Figure 4, take the correlations between node 1 and node
5.2. Associated Clustering
According to Algorithm 1 and the soil moisture correlation characteristics calculated by (7), Use the randomly generated coordination data of sensor nodes data[N] [2] and expected cluster number K as input data, executing associated clustering on the experimental environment in Figure 3. The result of clustering is in Figure 5.
Associated clustering based on data correlation.
As known from (7), the main factor of data soil moisture correlation characteristics contains soil and vegetation coefficient a and b and irrigation coverage degree C. According to the experimental environment settings, coefficients a, b, C can be got from the coordination data. The expected cluster number K helps to determine the grain of cluster. Therefore, the result of clustering is associated with node location and expectation cluster number.
5.3. Comparison with Random Clustering
In order to verify the associated clustering strategy based on spatiotemporal data correlation can make nodes within each cluster share a greater data correlation and select the random clustering protocol: LEACH clustering algorithm as comparison. Figure 6 is the result of LEACH clustering. In LEACH, cluster head is randomly generated and the other nodes decide to join a cluster according to the distance between it and the cluster head. As a result, LEACH clustering is more likely to cluster the nodes closer.
Result of LEACH clustering.
In order to compare the data correlation within a cluster, use multivariate linear relationship
Take each node data as random variables
Correlation comparison between associated clustering and LEACH.
As shown in Figure 7, compared with LEACH clustering, associated clustering strategy can get generally higher data correlation within each cluster. In this experimental environment, the average intracluster data correlation gained by associated clustering strategy is 0.6760, which is higher than the average data correlation 0.4331 gained by LEACH clustering. Therefore, associated clustering strategy can divide nodes with higher data correlation into the same cluster. Thereby enabling efficient data integration at cluster head achieves the goal of energy saving and network lifetime extending.
6. Conclusions and Further Work
In this paper, the clustering problem of WSN is studied. In the application of soil moisture measurement, we established a dynamic soil moisture model, and after correlation coefficient analysis of the model, proposed a soil moisture correlation characteristics model, which is used to represent the correlation of sensor data, also used as the basis of clustering. Finally, an associated clustering strategy based on spatiotemporal correlation characteristics is proposed. As a result, the associated clustering strategy divides nodes with high correlation into a cluster, makes the cluster head do the data fusion more efficiently. Thus the energy of each node will be saved and the lifetime of the whole sensor network will be extended. This associated clustering strategy is also suitable for other industrial or agriculture applications when using a particular industrial model to replace the soil moisture model.
In practical scenarios, the distance between nodes affects the energy consumption in WSN. During the process of data transmission, the longer is the distance, the more energy is consumed. So, in the further works, we can take both associated clustering strategy and distance factor into consideration, in order to optimize clustering strategy of WSN.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant No. 61170245 and the National Natural Science Foundation of China under Grant No. 61103242.