
Abstract
As a resource-saving technique, data aggregation has been intensively studied in wireless sensor networks (WSNs). However, existing methods of secure data aggregation in WSNs either (1) cause high communication overhead or (2) cannot defend against compromised member nodes and aggregator nodes at the same time. In this paper, we propose a mutual defense scheme for secure data aggregation, which includes two components, that is, secure sort-group-filter data aggregation algorithm (SSGF) and lightweight TDMA-based monitoring mechanism. The SSGF is to defend against injecting false readings by compromised member nodes, and the monitoring mechanism is to defend against altering the aggregation results by aggregator nodes. In addition, a secure data packet transmission scheme is also presented. Considering that the readings sensed by neighbor nodes exhibit temporal and spatial correlation, a constraint parameter, called maximum tolerant difference (MTD), is introduced and the quantitative criteria for abnormal readings evaluation are given. Both the theoretical analysis and comparative experiments show the feasibility and efficiency of the proposed method.
1. Introduction
The data aggregation technique is considered as one of the resource-saving strategies in wireless sensor networks (WSNs) to save the energy and minimize the medium access layer contention. However, in reality, WSNs are likely to be deployed in unattended areas, which make them vulnerable against attacks. When some nodes are compromised by attackers, they can launch a wide variety of attacks, such as injecting, altering, and selective forwarding. In this paper, we focus on the security issues of secure data aggregation, especially, on preventing the stealthy attack. In a stealthy attack, a compromised node may inject bogus raw readings or produce forge aggregation values with the aim of causing the base station to accept false aggregation values while not being detected by the user. In critical applications, using incorrect or maliciously modified aggregation results can have disastrous consequences.
Due to the importance of the secure data aggregation in WSNs, many innovative and intuitive methods have been proposed [1, 2]. These existing secure data aggregation methods can be classified into two main categories: cryptography-based schemes [3–13] and monitoring-based schemes [14–21]. In the first category, the methods mainly rely on pure cryptography techniques to provide end-to-end security, that is, to ensure the confidentiality, authentication, and integrity of data. But, these approaches cannot defend against all attacks and they especially cannot prevent attacks from compromised nodes, which can send false raw readings. In the second category, monitoring-based methods have been proposed as an attractive complement to cryptography in securing WSNs. These methods rely on monitoring mechanisms to monitor the behaviors of nodes and then filter out the untrusted nodes and the bogus readings. However, most of these solutions either (1) cause high communication overhead or (2) only consider the member nodes or the aggregator nodes to be the compromised nodes.
In this paper, to overcome the aforementioned drawbacks, a lightweight mutual defense scheme is proposed for secure data aggregation in WSNs. It includes a secure sort-group-filter (SSGF) data aggregation algorithm and a TDMA-based listening mechanism, which defend against compromised sensor nodes injecting false readings and aggregators sending incorrect aggregation results, respectively. It also provides security services including the integrity, freshness, and authentication via a secure data packet transmission scheme. Considering that the readings sensed by neighbor nodes exhibit temporal and spatial correlation, we define a constraint parameter, maximum tolerant difference (MTD), and give the quantitative criteria for abnormal readings evaluation. At the same time, we analyze and prove the feasibility of our method and present the worst aggregation results that compromised nodes can produce. Extensive experiments are conducted and the results show that the proposed mechanism can effectively and efficiently defend against and detect the malcompromised nodes. Compared with existing methods, our method can ensure higher accuracy of the aggregation results but with lower monitoring overhead.
The rest of this paper is organized as follows. Section 2 gives a summary of related work. Section 3 provides network model, attack model, and assumptions. Section 4 gives the details of our mutual defense scheme for secure data aggregation. The analysis of aggregation results affected by compromised nodes is introduced in Section 5 and simulation results are provided in Section 6. Finally, Section 7 concludes this paper.
2. Related Work
The secure data aggregation problem in WSNs has been investigated extensively during the past few years. Several surveys of these works are presented in [1, 2]. Wagner has studied the security of aggregation and proposed a mathematical framework for formally evaluating secure aggregation [22].
In [3, 4], a secure information aggregation (SIA) scheme was proposed to prevent the users from accepting incorrect aggregation results. By constructing efficient random sampling mechanisms and interactive proofs, SIA can let the home server verify the correctness of the aggregated data. However, as the aggregator not only needs to construct a Merkle hash tree-based commitment but also needs to deal with the check tasks from the home server, the computation and communication overhead of the aggregator is very high.
In [5–9], several homomorphic encryption-based end-to-end secure data aggregation schemes were proposed. The advantage of these approaches is that the ciphertexts can be directly aggregated. In [10], a pattern-based end-to-end secure data aggregation scheme was presented. In [11], a watermark-based end-to-end secure data aggregation approach was proposed. In [12], to provide end-to-end data confidentiality, a secure data aggregation scheme was proposed. It achieves data privacy through the secure channel. In [13], a signature-based data security technique was proposed to protect sensitive data aggregation. It makes use of the additive property of complex numbers. However, those approaches can only defend against external attacks and cannot prevent attacks from compromised nodes by injecting bogus raw readings.
In [23], to defend against the falsified subaggregate attack, in which a compromised node relays a false subaggregate to the parent node, a verification algorithm was presented. The base station can use it to determine if the computed aggregate includes any false contribution. However, it would fail to compute the aggregate in the presence of the attack. To address this problem, an attack-resilient computation algorithm was designed in [24]. In [25], a random sample consensus paradigm-based technique, called RANBAR, was designed to filter out outlier elements from a sample before an aggregation procedure. However, RANBAR does not consider the situation where the aggregator nodes are compromised.
In [14], a trust management scheme was presented to identify trustworthiness of sensor nodes. As the strategy of this method is to collect multiple and redundant readings and to crosscheck them for consistency, the communication overhead is also high.
In [15], a secure aggregation tree (SAT) was proposed to detect and prevent cheating. In SAT, as every child node needs to gather all the messages from their sibling nodes to the father node, the communication overhead is relatively high. At the same time, they do not consider the situation where the leaf nodes may also be compromised. In [16], a secure and reliable data aggregation protocol, called SELDA, was proposed. The basic idea of SELDA is that each sensor node updates trust levels for environment by monitoring actions of its neighboring nodes using Beta distribution function. However, SELDA ignores the situation where the aggregator nodes are compromised. In [17], a reputation-based secure data aggregation (RSDA) was proposed. In RSDA, as each node in a cell needs to compare its readings with the readings of its neighbors and perform redundant operations to monitor the actions of the cell representative, the communication and computation overhead is high. In [18], a RSDA-based representative aggregation tree (RAT) scheme was presented to reduce the data transmission overhead. However, this scheme is just mentioned to adopt the monitoring mechanism to prevent the injection of bogus information and forged aggregation values. In [19], a solution to detect the false readings during the data aggregation and recognize the attacking nodes was proposed. The main idea is to be monitored by children and judged by majority. However, it requires the dedicated external nodes to monitor the internal nodes, which wastes a lot of external nodes. In [20], a monitoring-based secure data aggregation method was proposed to prevent on-off attacks. In [21], a monitoring mechanism with two hierarchical levels was designed to ensure the integrity and the accuracy of aggregate result. In the first level monitoring, a principal supervisor node PSUP_L1 monitors the behavior of clusterhead, whereas, in the second level monitoring, the rest of nodes in the cluster monitor the behavior of both PSUP_L1 and clusterhead. However, since each node participates in aggregation function and gathers the data through passive listening, this scheme incurs a very high monitoring overhead.
3. System Model
We consider a static WSN with one sink node and N sensor nodes. The sink node is a powerful node and secure. We assume that the network is densely deployed and readings sensed by nodes exhibit temporal and spatial correlation, which is reasonable because all the nodes can sense similar physical phenomena at a specific time and area, such as applications to monitor the temperature, humidity, and lighting of an area.
Similar to other works in the literature, we consider the cluster-based network architecture for data aggregation; for instance, the network can be organized into a clustered structure through some secure clustering algorithms such as the protocol proposed in [26] or be divided into grids as [17, 18]. However, such preestablished network architecture is not suitable for data aggregation in some event detection applications such as intruder detection. Because it is very likely that in a cluster some nodes detect an event while others do not. Hence, for this kind of applications, it is very important to organize the collaboration of sensor nodes dynamically to generate reports once events are detected. In this paper, we do not consider this kind of applications. Figure 1 presents the logical architecture of the WSN considered. The clusterhead nodes, also called aggregator nodes in this paper, are responsible for aggregation of readings sent by their member nodes. They form a structure tree to transmit aggregation readings by multihopping through other clusterhead nodes. In this paper, we just consider the average aggregation operation. We assume that the effective key-based mechanisms are adopted, such as [27–29]. And the secure communications between member nodes and their clusterhead nodes are based on the symmetric keys. Each cluster has a group key, which is used by the clusterhead node to send aggregation results to the sink node or the next hop clusterhead node.

The cluster-based logical architecture for data aggregation.
We assume that both the clusterhead nodes and their member nodes are possibly compromised by attackers. When an attacker compromises a node, he or she can obtain its cryptographic keys and completely control it. Hence, the attacker may use the compromised node to launch a variety of active or passive attacks. However, in this paper, we focus on a passive attack. In such attack, a compromised node follows the normal network protocols and does not perform attacks, such as jamming and DoS attacks, to block the normal operations of the network. Using the compromised keys, it can inject forged or malmodified readings, which deviate from the normal readings. The purpose of attackers is to try to produce incorrect aggregation results without being detected. Note that, in this paper, we do not consider attacks based on colluding clusterhead nodes. In this attack, multiple compromised clusterhead nodes work in collusion to modify messages. When a colluding clusterhead node receives a message generated from its distant colleagues, it modifies this message to avoid being detected. Dealing with this attack is beyond the scope of this paper, and we will seek solutions to this issue in the future.
We classify the nodes in a cluster from two points of view: the cluster and the individual node. From the view of the cluster, we classify the nodes in a cluster as invalid cluster nodes and valid cluster nodes. The invalid cluster nodes are those nodes which have been excluded from the cluster while the valid cluster nodes are on the opposite. The number of the valid cluster nodes will be decreased if the majority of the valid cluster nodes mark some node as invalid. From the view of the individual node, we classify the nodes in a cluster as invalid cooperative nodes and valid cooperative nodes. For a specific node in a cluster, its invalid cooperative nodes are those nodes which have been marked as the malicious node by itself, while valid cooperative nodes are on the opposite. The number of the valid cooperative nodes of x will be decreased if x marks some node as invalid.
We assume that the number of compromised nodes is less than the number of well-behaving nodes in any cluster. We also classify the compromised nodes as invalid compromised nodes and valid compromised nodes. The invalid compromised nodes are those compromised nodes which have been excluded from the network while the valid compromised nodes are on the opposite. Notations summary lists some major notations and their specific meanings in this paper.
4. The Mutual Defense Scheme for Secure Data Aggregation
Our mutual defense scheme for secure data aggregation contains two aspects: the clusterhead nodes defending against their member nodes and the member nodes listening to their clusterhead nodes. It is based on a constraint parameter, called MTD, representing the maximum tolerant difference among the valid readings in a cluster. As mentioned earlier, the readings exhibit temporal and spatial correlation. For a specific application, we can predefine the MTD. The MTD is denoted by
4.1. Solution Outline
To defend against compromised member nodes injecting bogus raw readings, clusterhead nodes aggregate the collected data using the secure sort-group-filter (SSGF) aggregation algorithm proposed in this paper, which will be presented in detail in the following subsection. At the same time, clusterhead nodes update the normal or abnormal information of each member node separately according to the aggregation results, the MTD, and the received data from each member node. Then clusterhead nodes send their aggregation results to their next hop clusterhead nodes or the sink node.
To defend against clusterhead nodes sending forged aggregation results, a listening mechanism based on the TDMA scheme is designed for member nodes monitoring their clusterhead nodes, which can conserve the energy of nodes effectively. Based on its readings and the MTD, each member node will update the normal or abnormal information of its clusterhead node.
4.2. Secure Data Packet Transmission Scheme
In this subsection, we introduce the packet formats in data packet transmission phase. They can provide security services including the integrity, freshness, and authentication.
The data packet sent from a member node u to its clusterhead node v is described as the following format:

where
The clusterhead node v sends the data aggregation packet to its next-hop node
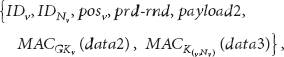



where
4.3. SSGF: Secure Sort-Group-Filter Aggregation
In this subsection, we focus on the SSGF. The SSGF algorithm consists of five steps, including sorting, grouping, filtering, aggregating, and updating.
4.3.1. Sorting Phase
In this step, a clusterhead node firstly sorts the collected data sent by its valid cooperative nodes. Assume that, after sorting, a clusterhead node v obtains an ascending data sequence
For instance, considering that in a cluster with v as the clusterhead a set of data received by v from its valid cooperative nodes is {11.7, 10.5, 9.6, 10.1, 7.2, 11.5, 9.4, 11.0, 11.9, 11.1}. Then the sorted ascending data sequence
4.3.2. Grouping Phase
In this step, based on the obtained difference sequence
Extending the example at sorting phase, we assume that the MTD
4.3.3. Filtering Phase
In this step, based on the MTD
For the above example,
4.3.4. Aggregating Phase
In this step, according to the aggregation function, the clusterhead node v aggregates the group
Continuing our example, considering the average aggregation function, we can get the aggregation result
4.3.5. Updating Phase
In this step, based on the result
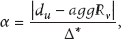


In formula (8), λ is a punishment base and
The value of
Note that, in order to defend against the bad-mouthing attack, in which a compromised clusterhead node libels a normal node as an invalid compromised node, when a member node receives an alarm message from its clusterhead node, it only marks the corresponding node as a suspicious compromised node. A node x is viewed as an invalid compromised node by a node y only in two cases: the direct case mentioned above or the indirect case, in which node y receives alarm messages about node x from the majority of valid cluster nodes in the cluster. Note that in the indirect case the number of the valid cluster nodes will be decreased.
Going on our example at aggregation phase, the cluster node updates the
4.4. TDMA-Based Listening Defense Mechanism
The motivation behind the TDMA-based listening mechanism is to save the monitoring overhead per node. Since energy is a scarce resource in WSNs, if a node keeps the listening state all the time, a significant amount of energy will be consumed. Adopting the TDMA-based method can reduce the energy consumption caused by listening.
A TDMA-based mechanism contains two phases: assigning slots and sending messages in corresponding slots. For the TDMA-based listening defense mechanism, a clusterhead node v firstly assigns the slots to its valid cooperative nodes and itself. Secondly, each node sends messages to its clusterhead node in corresponding slot. A valid cooperative node will enter hibernation after it sends a data message, while it will wake up at the slot when its clusterhead node sends the aggregation result.
Based on the sensed reading

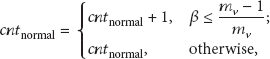

Theorem 1.
The upper bound of the β for the normal member nodes’ estimation is
Proof.
Without loss of generality, considering a normal cooperative node u and its reading
If we assume that

Similarly, if we assume that

Hence, combining formulae (12) and (13), formula (9) becomes

or

That is, we can obtain
Therefore, if
Note that our method can alleviate or restrict a compromised clusterhead node to send incorrect aggregation results even if the number of compromised nodes becomes more than half of the number of its valid cooperative nodes via repeatedly excluding normal node(s) from the cluster by the compromised clusterhead. On the one hand, if the number of normal nodes excluded by the clusterhead node is above
As nodes just need to listen at the slots of their clusterhead nodes, compared with other mechanisms, this mechanism can conserve plenty of energy at nodes, as shown in Table 1.
Comparison of different listening mechanisms.

5. Analysis for Aggregation Results under Attack
Without loss of generality, considering that a cluster has one clusterhead node v and

Assume that, after sorting the readings sensed by the normal member nodes, we can obtain an ascending data sequence normalSenData
5.1. Only Member Nodes Compromised
Considering a node w in the set W of the valid compromised member nodes and its reading
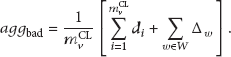
Combining (16), then (17) becomes

From (18), we know that, in order to try to let the aggregation result deviate the ideal aggregation result, it needs
Theorem 2.
The upper bound of the
Proof.
As mentioned earlier, the maximum and the minimum values sensed by normal member nodes are
From Figure 2, we know that
Consider the worst case, when

Therefore, in the worst case, if

The maximum
Based on formulae (18) and (19), we have derived the theoretical upper bound of
Theorem 3.
The upper bound of the
Proof.
Similarly, in Theorem 2, in the worst case, each of the compromised member nodes modifies a maximum deviated value as shown in formula (19). Then formula (18) can be transformed to

If
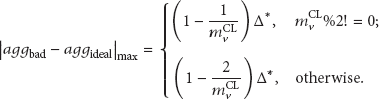
From formula (21), we know that if
However, as mentioned earlier, as the communication between each member node with its clusterhead node adopts symmetric key mechanism, the compromised member node w cannot decrypt the data sent by normal member nodes. In order to stealthily modify its sensed data
According to the SSGF, affected by node w, the
Theorem 4.
The average upper bound of the
Proof.
Without loss of generality, considering a node w in the set Wof the valid compromised member nodes, assume that its
Considering the worst case when the number of compromised member nodes is

5.2. Clusterhead Node Compromised
To decide the compromised clusterhead node v as a malicious compromised node in a cluster, the number of the alarm nodes at least is equal to
Note that although the compromised clusterhead node v may mark normal, uncompromised nodes as invalid, from the view of v, it does not introduce benefit to it by the following reasons. First, those removed normal nodes will report alarm messages against it if they are framed by v. Second,
If
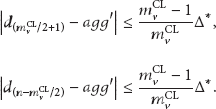
Because
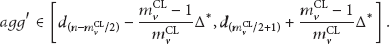
Similarly, if
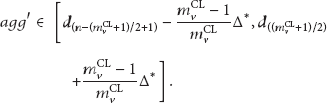
From the range of

Based on the range of
Theorem 5.
The upper bound of
Proof.
The ideal aggregation can be calculated by formula (27) or (28), where

Consider the worst case when
However, the upper bound in Theorem 5 can hardly happen, because it can only happen when one node obtains the maximum or minimum value and the other nodes obtain
6. Simulation Results
We present the simulation results of SSGF, including the detection ratio, false positive ratio, the accuracy of aggregation results, the communication overhead for monitoring, and aggregation results for a slow poisoning attack. For comparison with SSGF, we also implemented SELDA in [16], RSDA+, which is based on RSDA in [17] and is used for clusterhead nodes monitoring their member nodes, and SAT+, which is based on SAT in [15] and is used for clusterhead nodes monitoring their member nodes only considering the temporal correlation as [15]. All the experiments are simulated with the Castalia simulator [30], which is a simulator for WSNs and other low power embedded devices networks and is based on the OMNeT++ [31] platform.
We consider a WSN with 50 member nodes and a clusterhead node. The locations of the member nodes are generated randomly within a 40-by-40 area, with a uniform distribution for their coordinates. The clusterhead node lies in the centre of the deployment area. For each member node u, a random value
6.1. The Detection Ratio and False Positive Ratio in a Detection Period
In this subsection, we will present the experimental results of the detection ratio and the false positive ratio in one detection period with different numbers of compromised member nodes

The detection ratio when
The detection ratio when

The detection ratio when

The detection ratio when

The false positive ratio when
Figures 3 and 4 show the results of the detection ratio when
Figures 5 and 6 show the results for another attack behavior, in which the readings sent by compromised nodes are between 6.0 and 12.0. It can be seen that in both cases when the fraction of compromised nodes is 30% and 40%, respectively, our method is faster than both SELDA and RSDA+ methods in detecting all compromised nodes. This is because both SELDA and RSDA+ methods adopt the same punishment strategy for all abnormal readings. That is, if a reading sent from a node is detected as an abnormal reading, then its
Figure 7 shows the false positive ratio when

The detection ratio when
In conclusion, compared with SELDA and RSDA+, our method outperforms them in terms of detection speed and/or detection ratio for different cases. At the same time, the false positive ratio can remain zero by setting an appropriate
6.2. Aggregation Results
In this subsection, we will present the aggregation results of the above experiments. The results are shown in Figures 9, 10, 11, and 12, in which “all” means that the clusterhead node takes all the data for aggregation and “good” is the result by aggregating the data only from normal member nodes.
Aggregation results when

Aggregation results when

Aggregation results when

Aggregation results when
From Figures 9–12, we know that the results of both our method and the comparison methods have a higher accuracy than the “all” situation. However, the results from our scheme are gradually consistent with the “good” situation with the increasing of the roundfor the four cases in Figures 9–12, while this happens for two comparison methods (i.e., SELADA and RSDA+) only when the distortion of the data sent by compromised nodes is high as shown in Figures 11 and 12. At the same time, the speed of our method to be consistent with the “good” situation is faster than SELADA and RSDA+. This is because our method can gradually detect and filter out all compromised nodes for the four cases in Figures 9–12, while SELADA and RSDA+ methods can only do this with a slower speed for the two cases in Figures 11 and 12, as described in Section 6.1. In conclusion, compared with SELADA and RSDA+, our method outperforms them in terms of the accuracy of the aggregation results for different cases on the whole.
At the same time, we have compared the resilient aggregation methods suggested by Wagner in [22] (i.e., trimming and median) and RANBAR in [25] with SSGF. The idea of trimming is that if there are some bogus readings, then we should ignore the highest 5% and the lowest 5% of the readings (5% trimming) and calculate the average of the remaining readings as the estimation of the real average. In other words, it only works well if the proportion of compromised readings stays below 5%. In our experiments, there are 30% and 40% of compromised nodes in the cluster for two situations, respectively. So, some bogus readings are considered as valid during the aggregation procedure; thus, the distortion of the aggregation results of trimming is relatively high. The median is defined as the middle element(s) of the sorted readings. In fact, it is the extreme case of the trimming method (i.e., 49% trimming). Although the median method excludes all the compromised readings, it also excludes the majority of the real readings. Hence, the accuracy of the results also declines. The idea of RANBAR is to construct the consensus set for aggregation by filtering out the readings which are not satisfied with some distribution model randomly established based on the raw readings. The size of the initial set is 1, the maximum permitted number of iterations is 15, and the error tolerance is 0.1. Since the method to construct the consensus set is random and the set is considered as valid if the majority of readings are included in it, some real readings may be not included in the set while some bogus reading may be included. Thus, the accuracy of the results also declines. In conclusion, compared with trimming, median, and RANBAR, SSGF also outperforms them on the whole.
6.3. The Communication Overhead for Monitoring
In this subsection, we will present the experimental results of the communication overhead for monitoring. The results are shown in Figures 13 and 14, in which “cmp-

The communication overhead with different
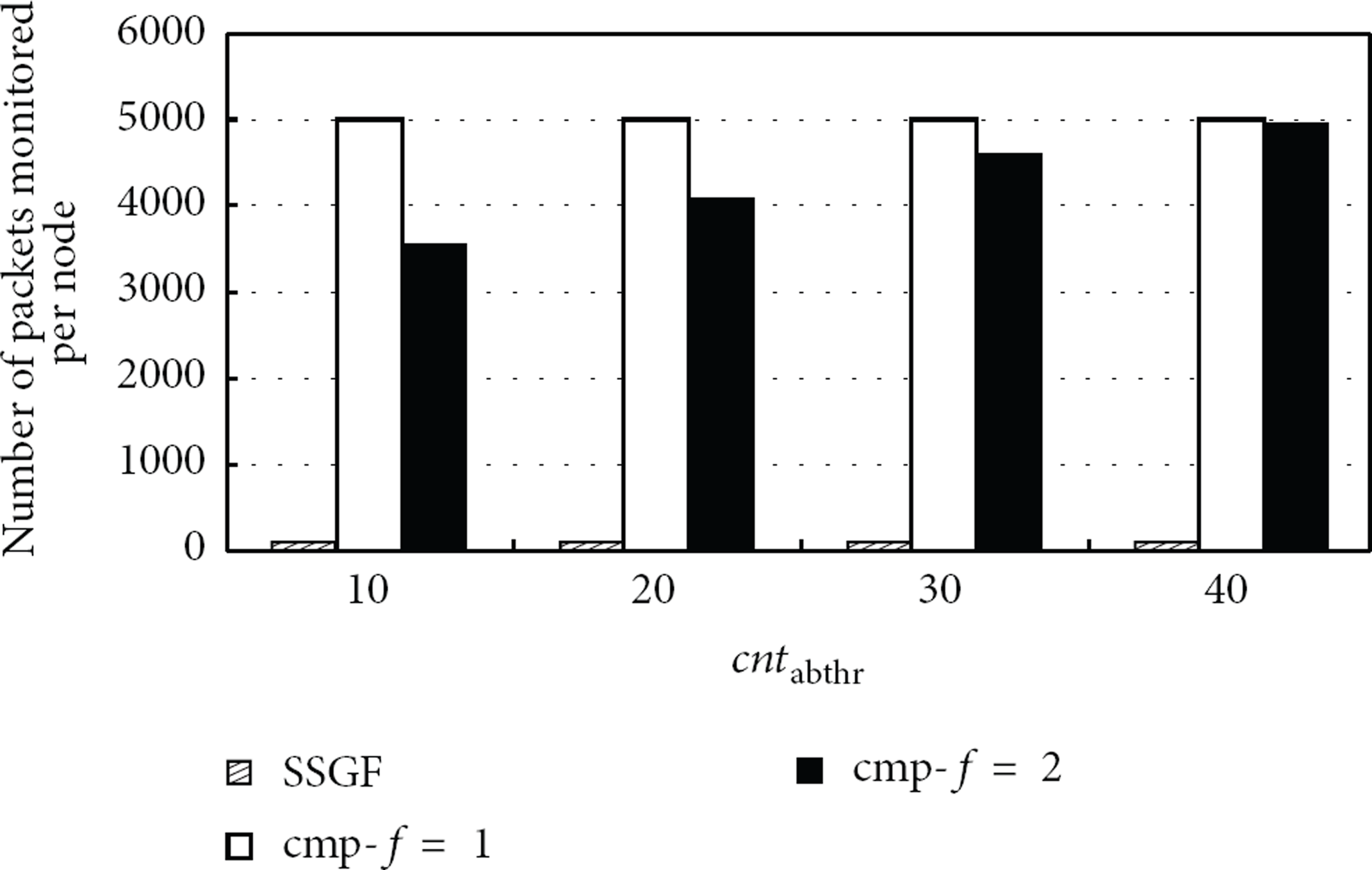
The communication overhead with different
Figures 13 and 14 show the results with 30% and 40% compromised nodes, respectively. From the results, we can see that, according to our monitoring mechanism, the communication overhead for monitoring by each node is obviously less than that of the SELDA and RSDA+ methods for all cases. This is because in our method each member node only needs to monitor its clusterhead node to send aggregation results, while for the SELDA and RSDA+ methods each node needs to monitor other nodes in the same cluster.
6.4. Aggregation Results for a Slow Poisoning Attack
In this subsection, we will present the comparison experimental results with SAT+ about the accuracy of the aggregation results against a slow poisoning attack, in which the compromised nodes slowly change readings sent to the clusterhead node. The reading sent by a compromised node w at r round
Figure 15 shows the comparison results of our method with SAT+ when 40% of the nodes are compromised,

Aggregation results for a slow poisoning attack when
7. Conclusions
In order to defend against compromised member nodes and aggregator nodes simultaneously during data aggregation in WSNs with low communication overhead, we proposed a mutual defense scheme for secure data aggregation. It contains a secure aggregation and defense mechanism SSGF for clusterhead nodes to defend against their member nodes injecting forged readings and a TDMA-based listening mechanism for member nodes to defend against their clusterhead nodes generating incorrect aggregation results. It also provides security services including the integrity, freshness, and authentication via a secure data packet transmission scheme. Considering that the readings sent by neighbor nodes exhibit temporal and spatial correlation, we defined the maximum tolerant difference (MTD) constraint parameter. Based on the MTD, we gave the quantitative criteria for abnormal readings evaluation. Moreover, we analyzed and proved the worst aggregation results that compromised nodes can produce. The extensive simulation results also indicated the feasibility and efficiency of our scheme. Compared with existing methods, our method can achieve higher accuracy of the aggregation results while being with lower communication overhead for monitoring.
There are a number of directions that are worth studying in the future. First, in this paper, we do not consider the colluding attacks launched by compromised clusterhead nodes. However, in practice, multiple compromised clusterhead nodes may be able to work in collusion to modify messages. This presents interesting challenges to our approach. Second, in this paper, it only covers the average aggregation operation and it is not suitable for event detection applications where the event happens contingently and can only be detected by a small number of nodes each time. Studying the average aggregation operation and other aggregation operations such as minimum, maximum, and counting for more broad applications will be an interesting research direction.
Footnotes
Notation Summary
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant no. 60873199. The authors are grateful to the anonymous reviewers for their insightful comments.