
Abstract
This paper addresses the problem that multiple DSP system does not support OpenCL programming. With the compiler, runtime, and the kernel scheduler proposed, an OpenCL application becomes portable not only between multiple CPU and GPU, but also between embedded multiple DSP systems. Firstly, the LLVM compiler was imported for source-to-source translation in which the translated source was supported by CCS. Secondly, two-level schedulers were proposed to support efficient OpenCL kernel execution. The DSP/BIOS is used to schedule system level tasks such as interrupts and drivers; however, the synchronization mechanism resulted in heavy overhead during task switching. So we designed an efficient second level scheduler especially for OpenCL kernel work-item scheduling. The context switch process utilizes the 8 functional units and cross path links which was superior to DSP/BIOS in the aspect of task switching. Finally, dynamic loading and software managed CACHE were redesigned for OpenCL running on multiple DSP system. We evaluated the performance using some common OpenCL kernels from NVIDIA, AMD, NAS, and Parboil benchmarks. Experimental results show that the DSP OpenCL can efficiently exploit the computing resource of multiple cores.
1. Introduction
OpenCL (open computing language) has been defined as a standard by the Khronos group which focuses on programming a possibly heterogeneous [1] set of processors with many cores such as CPU cores, GPUs, DSP processors, and FPGA. Although designed as a cross-platform parallel programming model, OpenCL remains mainly used for CPU and GPU programming [2, 3].
Compared with a single core, multicore architecture obtained higher throughput with the same clock frequency which reduced the power consumption. Multicore processor technology provides new levels of performance and energy efficiency. Multiple DSP architecture is pervasive in massive data processing occasions such as communication and image processing. However, multicore architecture challenges programmers to write code that scales over so many cores to exploit the full computational power. The software architecture needs a special design for application on specific hardware in multiple DSP system. It needs considerable efforts for software restructuring between different processors and hardware architectures during hardware change or upgrade. It definitely will consume a great deal of energy for migration between different hardware and software architectures.
OpenMP (open multiprocessing) [4] is one of the most popular frameworks used to program multicore architectures which are aimed at shared memory parallel machines. In OpenMP, programmers enable parallel execution by annotating sequential C, C++, or FORTRAN code with #PRAGMA. Also, we can easily set up our OpenCL application using the SDK and drivers from AMD, NVIDIA, and INTEL. It needs an effort of compiler and runtime support for specific platforms. Fortunately, processor manufactures have provided this support.
OpenMP is supported on TI's multicore DSP, but it is not available to use OpenCL programming language on multicore DSP systems. It is a challenging task to support OpenCL program model on multicore DSP for embedded application. We address this problem by firstly utilizing the LLVM (low level virtual machine) [5] and Clang [6] open source compiler to support kernel compilation and further optimization for the DSP platform; then we designed a second level RTOS (real time operating system) [7, 8] scheduler that aimed to schedule work-item in a work group to decrease the task switching overhead. Finally, we proposed a kind of software managed CACHE method to efficiently administrate the distributed global memory which was combined through interconnections such as PCIE, SRIO (serial rapid IO), Hyperlink, and SGMII.
This DSP OpenCL support breaks through the limitation of OpenMP, which was restricted to the number of cores integrated in a single chip. We make it possible to utilize distributed multiple DSP cores for parallel processing using OpenCL.
The major contributions of this paper are as follows.
A more efficient DSP RTOS scheduler was proposed for the OpenCL kernel task. It is beyond the capability of DSP/BIOS RTOS to manually schedule between multiple tasks without using the synchronization module such as semaphores. The second level scheduler utilized the 8 functional units in C66 core and special instructions like LMBD to accelerate the switch process. The optimized scheduler can efficiently schedule work-item tasks within a workgroup directly.
A kind of software managed CACHE method suitable for DSP implementation was designed to manage global memory distributed in multiple DSP and optimized transfer driver for SRIO interconnections.
LLVM and Clang were utilized to analyze the OpenCL kernel code for a work-item address translation and memory access. The kernel information obtained from compiler provides useful information in kernel execution.
2. OpenCL Kernel Scheduler
2.1. OpenCL Platform
Component Mapping between OpenCL platform and the DSP system target architecture is shown in Table 1.
Mapping OpenCL platform to DSP target.

Figure 1 shows the runtime organization. The OpenCL platform consists of a host processor connected to one or more compute devices, each of which contains one or more CU (compute unit). The computing unit could be a CPU, GPU, DSP, FPGA, or ASIC. The host thread and the command scheduler share a queue. The ORT (OpenCL Run Time) has a ready queue. Whenever the host thread enqueued a command in a command queue, an event object was created that encapsulates the command status.
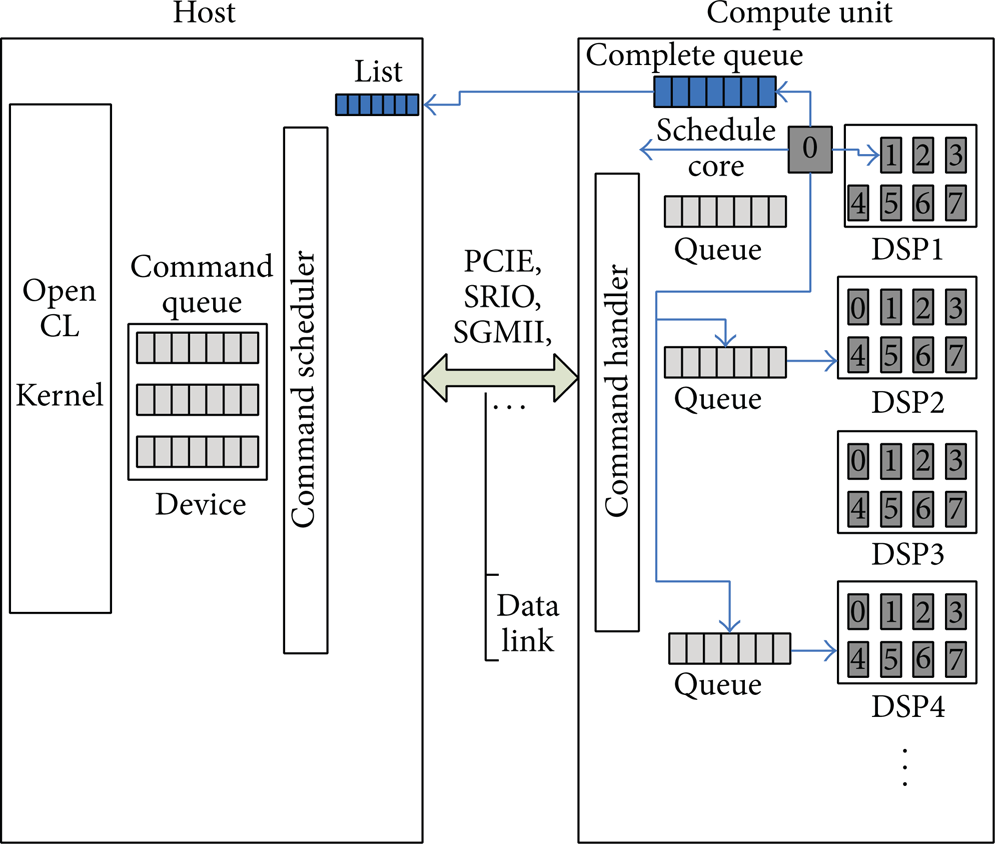
OpenCL command queue.
The ORT checks the status if the event queue is empty. When the event queue is not empty, the ORT invokes the command scheduler. The command scheduler determines the execution ordering between queued commands and issues them to the ready queue. It maintains a data structure called DAG (directed acyclic graph [9]) which is shared between the command scheduler and handler. Each node in the DAG is an event object. The execution ordering is obtained from the command queue type (in-order or out-of-order) and the ordering is enforced by barrier and event synchronization.
DSP 0 Core 0 schedules other CU cores with command messages through the ICC (intercore communication) and other interconnections, such as SRIO doorbell and PCIE MSI interrupt. Work-items in a workgroup can communicate with each other and can synchronize execution among work-items in a group to coordinate memory access. The schedule core is responsible for checking the command and sending an event to host when the command is completed.
Figure 2 shows the software architecture of multicore DSP systems that supports OpenCL kernel execution. Multiple DSPs were connected using PCIE, SRIO, SGMII, and Hyperlink connections, while multiple cores within a DSP were tied together with shared memory and intercore communication.

Software architecture.
The traditional RTOS is incapable of scheduling OpenCL kernel work-items, so we designed a two-level scheduling mechanism for OpenCL kernel. The second scheduler was on top of DSP/BIOS only for OpenCL kernel scheduling. Using DSP/BIOS, various RTSCs (real time software component) run concurrently for easier use of peripherals on a chip.
2.2. First Level RTOS Scheduler
Compared with commercial RTOS such as OSE and QNX, the DSP/BIOS from TI is totally free and has perfect support for its own DSP processors. DSP/BIOS kernel is a priority based preemptive [10] scheduler. It is designed to be used by applications that require real-time scheduling and synchronization. There are four kinds of threads in DSP/BIOS, that is, HWI, SWI, TASK, and IDLE.
With various RTSC (real time software component) modules provided by TI such as IPC (interprocessor communication), MCSDK (multicore software Development Kit), and PDK (platform development kit), the application program can easily utilize these modules to fully take advantage of the DSP core and hardware accelerators on chip such as SRIO, PCIE, and FFT.
DSP/BIOS is a priority based preemptive scheduling kernel. The process of task preemption is shown in Figure 3. Currently the high priority task “Tsk2” was waiting for “semaphore b” and low priority “Tsk1” occupies the CPU; when interrupt happens the OS kernel enters into ISR (interrupt service routine) routine where semaphore “b” was released and task “Tsk2” changed into ready state. When the ISR returns, the OS kernel schedules task “Tsk2” instead of returning to the previously executed task “Tsk1.”

Task preemption.
2.3. Second Level RTOS Scheduler
The DSP/BIOS operating system is incapable of efficiently scheduling OpenCL kernel work-items. It does not support manual task switching through any system calls. It will considerably increase the overhead by changing work-item task priority or through synchronization module such as semaphore [8] to allow expected execution sequence. Task schedule overhead is heavy when using DSP/BIOS kernel, and it involves task stack change and context switch.
The SETJMP [11] and LONGJMP method for barrier handling restricted that the work-item switching among a workgroup can only execute sequentially because of shared stack usage.
The process can be illustrated in Figure 4. It uses SETJMP to save CPU register context into a jump buffer and then switches to another work-item. CPU register was restored from the jump buffer when work-items switched back. When it comes to barrier, the SETJMP is incapable of out-of-order execution.
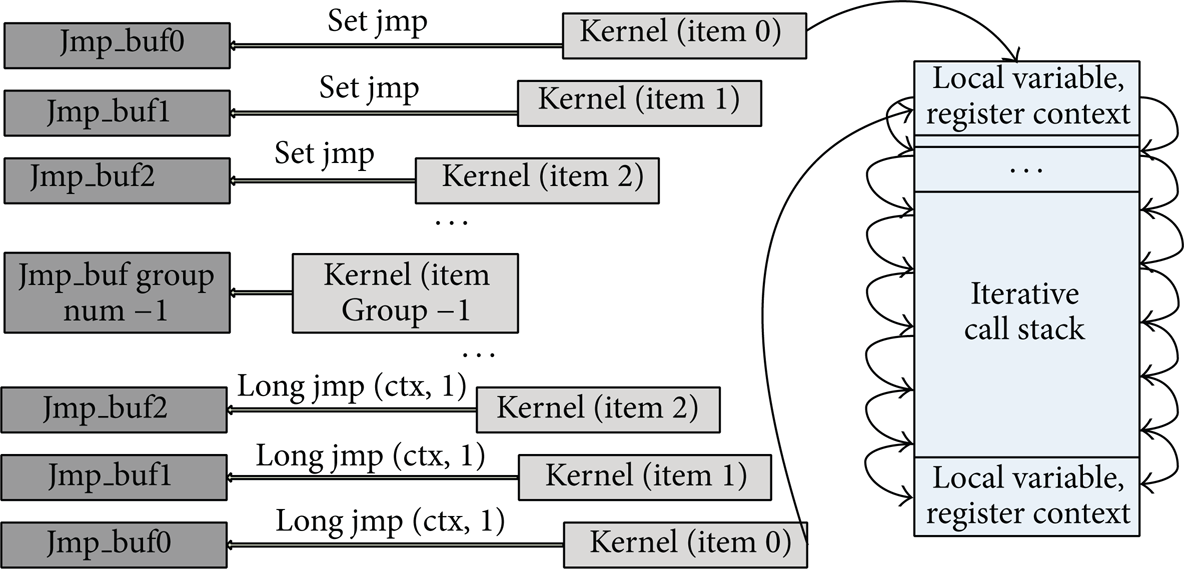
Work-item switch using SETJMP and LONGJMP.
So we designed a new scheduler on top of DSP/BIOS to minimize the switching overhead and compensate the data acquisition latency in OpenCL kernel execution within a workgroup. The second level scheduler optimized the register context saving and restoring process to achieve arbitrary OpenCL work-item task switching.
An OS that supports multitasking can be roughly classified as two kinds which are preemptive and nonpreemptive. Nonpreemptive scheduler kernel does not provide any guarantee of response to a high priority task. In contrast preemptive kernel can be triggered by external events to reschedule all of the tasks and switch to highest priority task to guarantee real time response. When dealing with hybrid task sets, the main objective of the kernel is to guarantee the schedulability of all critical tasks in the worst case conditions and provide good average response times.
2.3.1. Task Switching
The C66 DSP core integrated 8 functional units, a C64 + fixed point and C67 floating point kernel, which enhanced the data path capacity. It is shown in Figure 5.

C66 data path.
We utilize the cross data path to accelerate the register context backup and restore process by accessing 4 registers per cycle. The register context saving process is displayed in Table 2.
Register context saving.

The register context restoring process is displayed in Table 3.
Register context restoring.

Concerning OS support, the C66 kernel inherited TSR, ITST, and NTSR from C64 +. The GIE, CXM, PGIE, and SGI were backed up and restored when a task switch happened, and B IRP, B NRP, and CALLP instruction were utilized to switch between ISRs and tasks. The register status bit transformation process is shown in Figure 6.
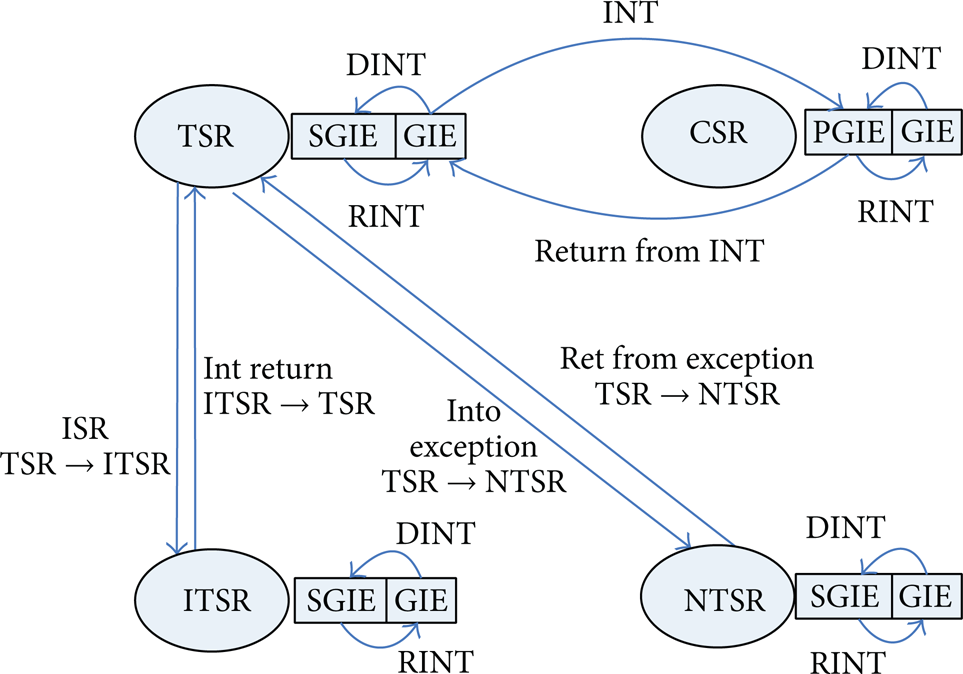
Register status transfer.
2.3.2. Separate Task Stacks
In single stack kernels [12], all tasks use the same stack; the scheduler does not change stack pointer during task switching. This kind of kernel is tightly coupled, which is difficult to debug when any error occurred. Dual stack mechanisms only separate task stack with interrupt stack. The separate stack OS provides flexibility and fault tolerance. It is described in Figure 7. Separated stacks were used to store the call relation, C language runtime environment, local variables, and register context for each task.
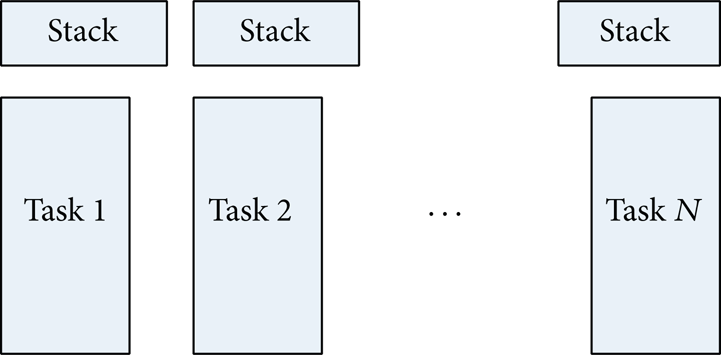
Separate stack.
If a work-item is halted, but not finished, then the stack cannot be destroyed by another work-item. So each work-item must have a separate stack. A “while loop” is used to execute the work-items sequentially where “barrier” is never called. This reduces the switching overhead between work-items. The situation is different when there is a barrier in the kernel. When the first call to barrier is made, it begins to allocate memories for the stacks.
2.3.3. Task Queue
The second level scheduler organizes task by priority. It uses a 32-bit register to indicate 32 priority levels, and each bit corresponds to a task queue with status being set or cleared. Task queue contains the TCB (task control block) linked list. It was the task scheduler's responsibility to find out the task from the corresponding queue by the bit indication. It is shown in Figure 8.
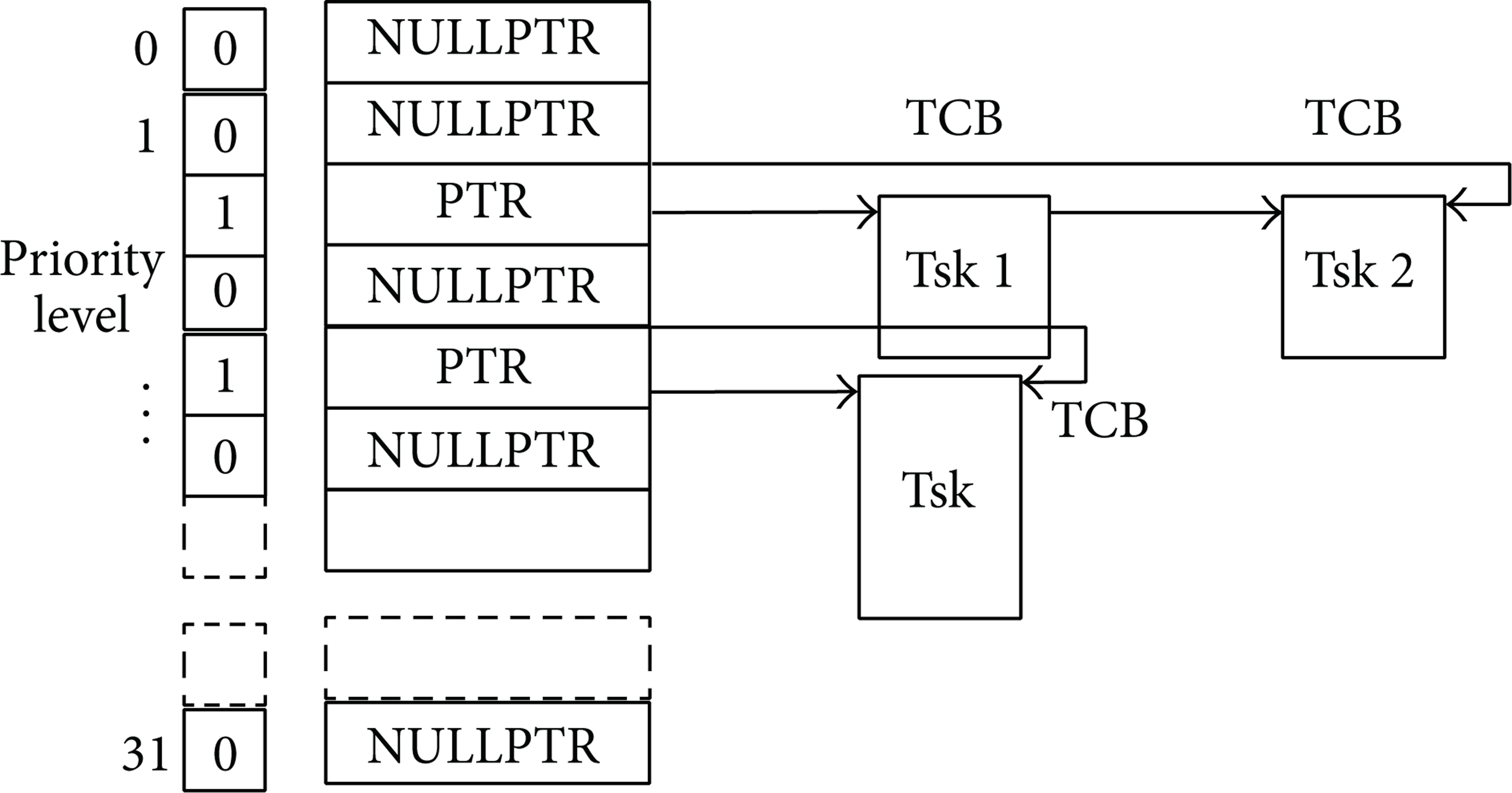
Task queue.
Each time the status of task changes, the corresponding bit must be modified. The DSP special instruction such as LMBD (left most bit detection) is used to accelerate the task switch process. The dispatcher adopts FCFS [7] (first come first served) strategy to deal with the same priority task.
3. Compiler and Runtime
Supporting OpenCL in embedded systems such as DSP is a challenging task. The DSP compiler does not support OpenCL C, and the keyword such as “__kernel” qualifier is not recognized by CCS. The memory usage, such as variable and stack allocation, needs to be translated. The RTOS does not support dynamic linking library and dynamic loading. It needs special design and optimization to support OpenCL programming on DSP systems.
3.1. Compiler
The compiler front-end [5] involves lexical analyzing AST parsing, syntax analyzing, address qualifier parsing, vector parsing, CGIR expansion, and WHIRL lowering optimization passes. The compile process of character stream is shown in Figure 9.
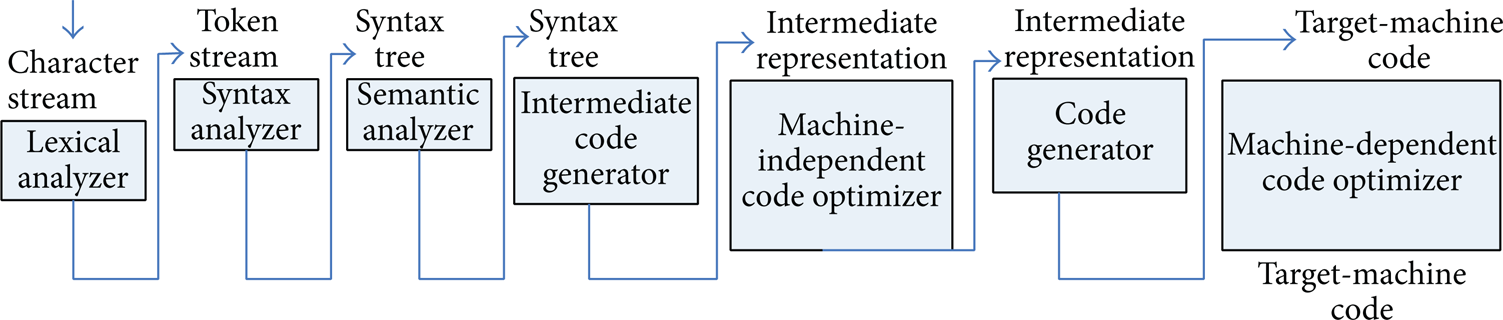
Source-to-source translation.
LLVM and Clang provide support for C99 code. They translate the kernel into C code with calls to the runtime library embedded. The source-to-source code translation is shown in Algorithm 1.

Kernel function translation.
We added the barrier detection in LLVM compiler to generate information which will be used by the second level scheduler. The information includes the following:
if OpenCL kernel contains barrier,
if it is in a branch where the barrier was called,
if the memory access needs intercept and translation.
The global memory access statement in the translated C function was translated into a function call which conducts address translation, memory fetching, and context switching.
3.2. Dynamic Linking and Loading
The kernel was dynamically loaded into the code memory space of DSP. With regard to dynamic linking and loading, it is impossible for the COFF (common object file format) object format to dynamically load a program to the target memory. The ELF (executable and linkable format) [13] makes it possible. The open source project RIDL [14] (reference implementation of dynamic loading) from TI solves the problem. Figure 10 shows the loading process.
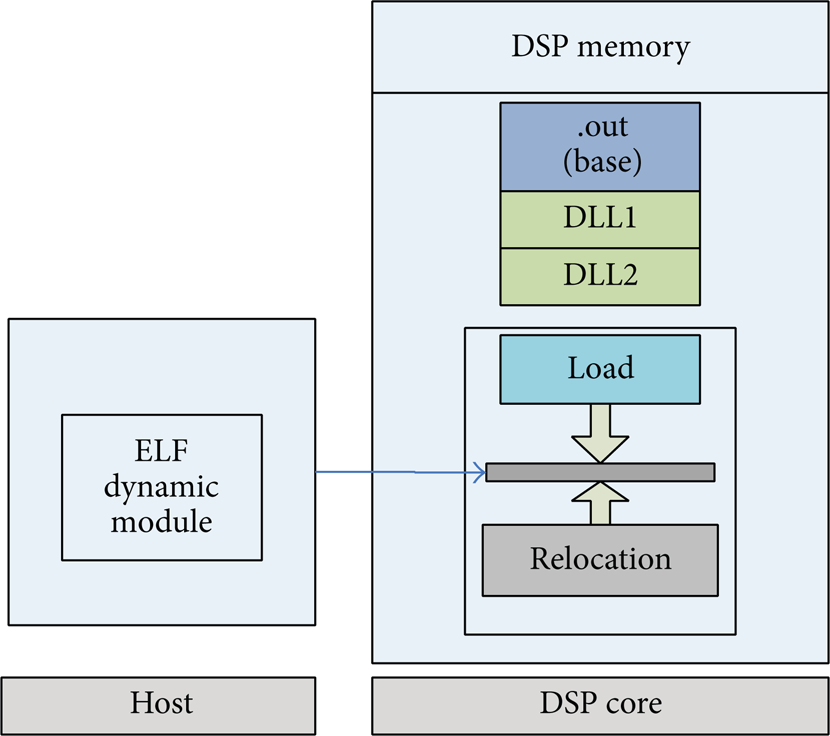
Dynamic loading on DSP (RTOS).
The RIDL uses a target memory pool called “blob” section to handle dynamic section. This section was split from DDR with R + W + X (read, write, execution) permission where both data and program CACHE path exist between the CPU and DLL. The dynamic linking procedure cannot be accomplished in one step without interruption. After copying all the dynamic sections to the target memory, the relocation process will resolve all the dynamic symbols. The assembly line with “!” indicates that it needs relocation and the exclamatory mark means symbols defined in another module (see Algorithm 2).

Dynamic symbol reference in assembly.
First, the dynamic loading module copies the sections into the code memory space. Then the loader modifies the instruction code by substitution with the external dynamic symbol address resolved.
3.3. Software Managed CACHE
The three levels of memory hierarchy in the typical multicore system were shown in Figure 11, where level 2 was bigger but slower; level 0 was smaller but faster; and level 1 was in between.

3 level memory hierarchies.
Accesses to the global or constant memory on the same chip may be prefetched in the CPU data CACHE. When it comes to the distributed global memory, the CU cannot access the global memory directly but only through interconnect links such as PCIE, SRIO, and Hyperlink. To accelerate the data access from the remote device memory, we propose a new static mapping software managed CACHE (SMC) [15–17] which is designed for global memory and we use the DSP special instruction LMBD to accelerate the tag search process. The diagram of static mapped software CACHE mechanism is shown in Figure 12.

Static mapped CACHE.
3.4. Utilization of Data Latency
The global memory may be distributed in a different processor of a multiple processor system which aimed at supporting the memory intensive application. So there could be a large number of cycles that are waiting for memory prefetch using SRIO, PCIE, Hyperlink, or other interconnection links. We make use of this kind of idled CPU by switching to another work-item and make the execution shift to an earlier stage instead of waiting. Figure 13 shows the work-item scheduling before and after optimization.

Work-item schedule optimization.
The time in direct schedule method in the left column of Figure 13 is described in

where “num” is the number of work-items and “T
a
”, “
So the time spent after optimization is shown in
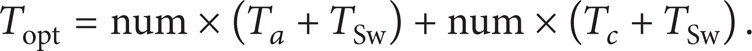
If Topt > Tall, it is unnecessary for optimization. The criterion is shown in
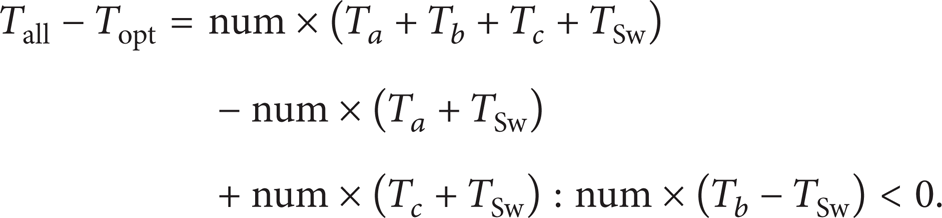
It means that if the waiting time for memory is larger than the task switching time, it is worth dynamically switching to the rest of the work-items.
3.5. Barrier Handling
The schedule flowchart of the whole system is shown in Figure 14.

Flow of kernel scheduling.
The central thread and CU threads run on the host and the device executor runs on the device. Once the memory is allocated, barrier can proceed normally. It first tries to take the next context and checks if it is initialized; that is to say, its work-item has already begun and is currently halted somewhere in its execution. If the work-item has not yet been initialized, it is created and initialized to point to the kernel function, with the correct arguments.
After the context creation, we should firstly save the current context in the memory location and then jump to the next. If this is the first time that barrier is called, the current context is simply the MAIN CONTEXT of the thread, and it gets saved like any other context. Barrier works even when a dummy context is used. The context being swapped, then the execution can begin or continue into the next work-item. When a work-item finishes, the execution flow will return to where it has left, which is at the swap context call. It allows the scheduler to simply terminate all the work-items.
When a barrier has been encountered and a work-item finishes, we cannot just launch the next, as it has already begun before. The second level scheduler backs up the context and switches to the next.
4. Results and Discussion
4.1. Hardware Platform
We tested our OpenCL scheduler and runtime with OpenCL kernel programs on DSPC-8681E [18] evaluation module from TI with 4 DSPs onboard. The architecture of DSPC-8681E is shown in Figure 15.
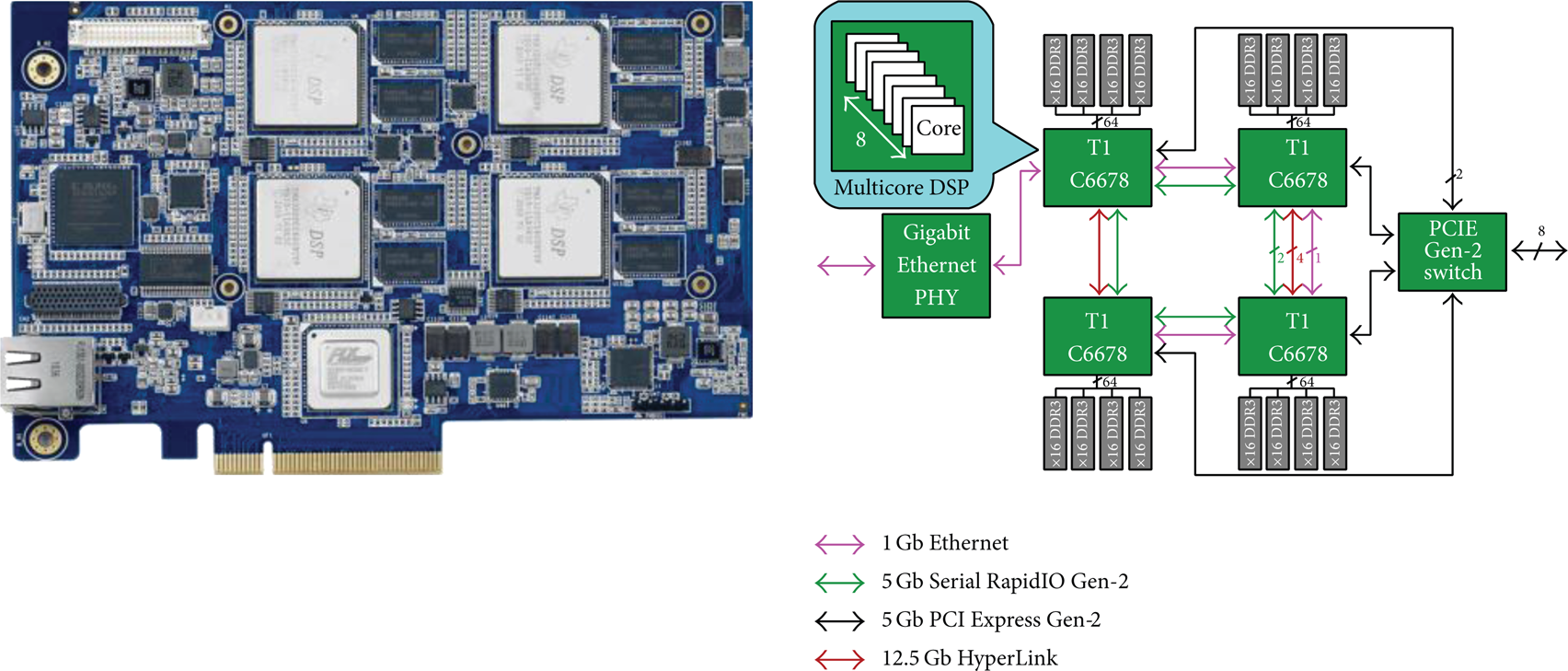
DSPC-8681E architecture.
Each TMS320C6678 DSP is equipped with 64-bit data width and 2 GB capacity memory. Each TMS320C6678 DSP is connected to PEX8624 switch by 2 lanes of PCIE Gen2. The PEX8624 PCIE switch connects the board to the host PC through an 8-lane interface. Each pair of TMS320C6678 DSP devices is connected by four lanes of Hyperlink interface with the 50 Gbps in between. The board contains a two-lane SRIO chaining through lane 0 and lane 1 at 5 Gbps.
4.2. Evaluation Algorithm
It can be classified as 3 kinds of tests to the heterogeneous high performance platform which were computationally intensive, memory intensive, and communication intensive. The NPB [19, 20] consists of five kernels including IS, EP, CG, MG, and FT and three pseudo applications including SP, BT, and LU. The OpenCL version of NPB was created by SNU [16]. We downloaded and tested the benchmark in our DSP platform. We also select some typical kernels from NVIDIA [21], AMD [22], and Parboil benchmark [23]. The parameters for each kernel are shown in Table 4.
Algorithm evaluation parameter.

The comparison was conducted among serial C, OpenMP, and OpenCL. The results are shown in Figure 16.

Speedup comparison.
From the speedup we know that the runtime can efficiently utilize multiple cores in a single DSP and other distributed DSP. With regard to OpenMP, the barriers significantly impact the speedup. OpenCL runtime overcomes OpenMP in BS, CP, CG, EP, IS, and LU. The kernels in BO, BT, MM, NB, and MG make the DSP core suffer from nonsequential memory access. OpenCL gains remarkable speedup over OpenMP in that the former takes advantage of multiple DSP while the latter only supports multi-core on a single DSP.
5. Conclusion
We address the problem that embedded DSP system does not support OpenCL parallel programming model. Manually task partition, customized task communication, and fixed data processing procedure were still challenges for programmers without using OpenCL. Firstly, the LLVM compiler was imported for source-to-source translation for compilation support on DSP. Secondly, two-level schedulers were proposed to support efficient OpenCL kernel execution. The DSP/BIOS is used to schedule system level tasks such as interrupts and device drivers. However, DSP/BIOS scheduler is unsuitable for OpenCL kernel work-item scheduling. So we designed an efficient second level scheduler especially for OpenCL work-item scheduling. The second level scheduler, which utilizes 8 functional units and cross path links, was superior to DSP/BIOS in task switching efficiency. Finally, dynamic loading and software controlled CACHE modules were redesigned. Some common OpenCL kernels from NVIDIA, AMD, NAS, and Parboil benchmarks were evaluated and the experimental results show that the DSP OpenCL can efficiently exploit the computing resource of multiple cores.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Footnotes
Acknowledgments
This work was funded by the China “863” projects with Grant nos. 2011AA0641 and 2013AA041201-7.