
Abstract
Aimed at the Top-k query problems in the wireless sensor networks (WSN) where enquirers try to seek the k highest or shortest reported values of the source nodes, using privacy protection technology, we present an exact Top-k query algorithm based on filter and data distribution table (shorted for ETQFD). The algorithm does the query exactly and meanwhile uses conic section privacy function to prevent the disclosure of the real data and then to promise the security of nodes in network. In this proposal, each node in WSN uses data distribution table to reflect the distribution of its own data and keeps exact filter to just return data which is possibly to be the result of the query, so as to reduce the energy cost of network and prolong network lifetime. In addition, data of node is packaged with a privacy protection function based on conic section. The algorithm's performance is examined with respect to a number of parameters using synthetic datasets. Performance analysis and simulation results illustrate that, compared to existing algorithms, ETQFD is energy-efficient and the network lifetime in our algorithm is longer. At the same time, privacy of data in this algorithm is also guaranteed.
1. Introduction
Wireless sensor networks are widely used in a variety of monitoring applications, including habitat monitoring and environmental observation. In many of these monitoring applications, measurements from sensors are periodically collected at the base station to answer monitoring queries submitted by users. There exist many situations where one is interested in a monitoring extreme and a typical behavior, for example, finding the highest pressure points in a pipeline, the largest temperature values in a building or patch of forest, the points of the most intense vibration in a bridge, and so forth. Oftentimes, one may be interested only in the Top-k observations. Top-k query, as a basic aggregate query, continuously returns the k nodes with the highest (or lowest) sensor readings. This type of queries is often used in practice since they give compact but useful information about the monitored environment. Hence, how to execute Top-k query in data-centric wireless sensor networks is a research hot spot. While the sensor nodes in the network have limited availability of recourses like energy and computational power, we must take energy consumption into consideration when doing queries. At the same time, the sensor network could be easily undermined by adversaries and thus they will obtain privacy information of sensor nodes. Many scholars and experts are dedicated to the research of Top-k query algorithm with highly efficient and low energy consumption. However, we should also execute Top-k query with privacy protection strategy.
Some representative Top-k query algorithms are as follows: an in-network aggregation technique, known as TAG [1], an algorithm called PROSPECTOR-PROOF [2], and a novel filter-based monitoring approach called FILA [3] The algorithm FILA, which firstly introduced the concept of filter, used a query revaluation algorithm and a filter setting algorithm to ensure correctness and validity. However, it costs a lot in the process of filer setting. Recently, Thanh et al. [4] proposed a distributed query revaluation algorithm and a filter setting algorithm based on linear regression model. Liao and Huang [5] proposed an energy efficient monitoring scheme, in which the network is divided into several grids, to decentralize network traffic. Liang et al. [6] took query response time into consideration for the first time and proposed a union query optimization framework to find the optimal query tree, but it has some limitations. Zhu et al. [7] processed Top-k in k-nearest neighbor network and reduced energy consumption by shutting or waking up nodes, yet it is not applicative in updated network. Malhotra et al. [8] advanced an exact filter algorithm to ensure accuracy of query results. All in all, we need to explore a Top-k query algorithm with low energy consumption and high accuracy.
As WSN is a data-centric network, privacy of location and data appears important. The traditional network data is encrypted by key; however, it is not feasible for WSN for high energy consumption. Chen and Lou [9] proposed four models to protect privacy of nodes and sink: Forward Random Walk, Bidirectional Tree, Dynamic Bidirectional Tree, and Zigzag Bidirectional Tree. Jayashree and Sathish Babu [10] raised a privacy protection mechanism STDMA based on topology tree and dispersion mechanism, in order to protect privacy and conserve energy by minimizing the number of intermediate nodes from one given node to the sink. Dimitriou and Sabouri [11] put forward a privacy protection model based on random location and random orientation. Groat et al. [12] concealed sensitive data into a group of fake tables to protect real data, but the process is too complex.
In this paper, we propose a Top-k query algorithm based on data distribution table and filter which can obtain balance between energy consumption and accurate query results. We aim to execute accurate query with lower energy consumption and longer network lifetime. In most Top-k query algorithms, all nodes in the network need to send their sensing data to the sink node in the initial stage, while nodes in our algorithm only send their data distribution tables which occupy just several bits to their father nodes, and then only those nodes determined by the sink node after the distribution phase will send their data. In our algorithm, the number of nodes sending data to the sink node in the initial phase is much smaller than that of all nodes in the network. To reduce energy consumption, we set more restricted filters. We use several sets to reflect different data ranges and then, according to the sets, each node maintains a threshold value which is more restricted. This will avoid many unnecessary update messages. To obtain accurate query results, nodes in the set “Top-k” will always send their new sensing data to the sink node to ensure that sensing data in the set is always real time and accurate. Although the k nodes may cost more energy to some extent, k is so small compared with the number of all nodes, and nodes in the “Top-k” set are changeable, so this kind of cost is acceptable in order to obtain accurate results. To deal with hidden trouble in security, we propose a privacy protection strategy based on the conic section to protect real data.
2. Top-k Query Algorithm Based on Data Distribution Table and Filter
While doing query, if all sensor nodes in the network participate in comparing or returning, a large amount of redundant information will be generated and that will also lead to great query delay. While that will be much better if the sink node can accurately locate the area of interest and directly obtain data from those regions, in this paper, we try to exactly locate the nodes having influence on query results and then only send query request message (QRM) to those nodes. To realize that, every node in network maintains a copy of DDT, which reflects the distribution information of sensor data. When receiving QRM, every node sends the request to the influential nodes according to query parameter k and the DDT. Furthermore, we use exact filter to avoid unnecessary data transmission and provide real-time and accurate query results.
2.1. Description of DDT
Every sensor node maintains a copy of DDT; the first row of that DDT expresses the distribution information of itself and other rows show the distribution information of its child nodes. The structure of DDT is shown in Figure 1. For instance, assume that DDT is comprised of M rows and R columns, we divide the range of sensing data into R nonoverlapping intervals and Column L means the Lth interval. If the sensing data is in the Lth interval, then value of Column L, Row 1 of the DDT is set to 1 and other columns of Row 1 is set to 0. Intervals can be divided according to data intensive degree and the higher the degree is, the more the intervals are.

Structure of DDT.
In Figure 1, there are 6 intervals, respectively,
2.2. Establishment and Maintenance of DDT
Before query execution, each node in the network needs to initialize its DDT and after the initialization DDTs are aggregated from the leaf nodes to the sink node along the query tree.
2.2.1. Initialization of DDT
The structure of the network is hierarchical cluster-layer topology architecture and nodes in the network not only sense data but also forward data. After sensing data, each node determines its DDT. For example, if a node's sensing data is in interval
2.2.2. Establishment of DDT
Each node sends its DDT to its father node starting from the leaf node finally to the sink node. There are two kinds of child node; one is the leaf node and another is nonleaf node. The leaf nodes send the one-row DDT to their father nodes. While other nodes firstly accumulate values of the same column in different rows of the DDT and thus new DDT with single row is generated, then they send the new DDT to their father nodes. In the new DDT, the value of Columnkmeans the number of nodes whose data is in the kth interval among the tree rooted by the nonleaf node.
Figure 2 describes the establishment of DDT.

Aggregation process of DDT.
2.2.3. Update of DDT
Since WSN is a network continuously sensing data with dynamic topology, updating DDT with appropriate frequency is necessary to exactly reflect real situation of the network. Update of DDT plays an important role in query algorithm.
Update of DDT is described as follows.
A node continuously senses X records. Only if the X records are in the same interval but not in the previous interval whose value is 1 in the first row of the node's DDT, value of the previous interval should be set to 0 and that of current interval should be set to 1. If DDT is changed, the node will send the new information to its father node.
2.3. QRM Distribution of Query Algorithm
Each node in the network maintains a copy of DDT which reflects the data distribution information of itself and its child nodes. Take node number of nodes in different intervals in the query tree rooted by node the distribution information of the subtree rooted by node
QRM dispatches the query from the sink node to the source node by top-down way. Assume that
2.4. Update of Query Algorithm
After distributing QRM for the first time, there are sum records sent to the sink. We generate a set Sum containing the sum records. Then we select the k highest records in set Sum into the set Top-k, and others into another set nTop-k. We use set nSum to describe records not in set Sum and it is not the real set saved in the sink node. We use min to reflect the minimum value in set Top-k and low to reflect the boundary value between set Sum and set nSum. Figure 3 shows data distribution of the sets.
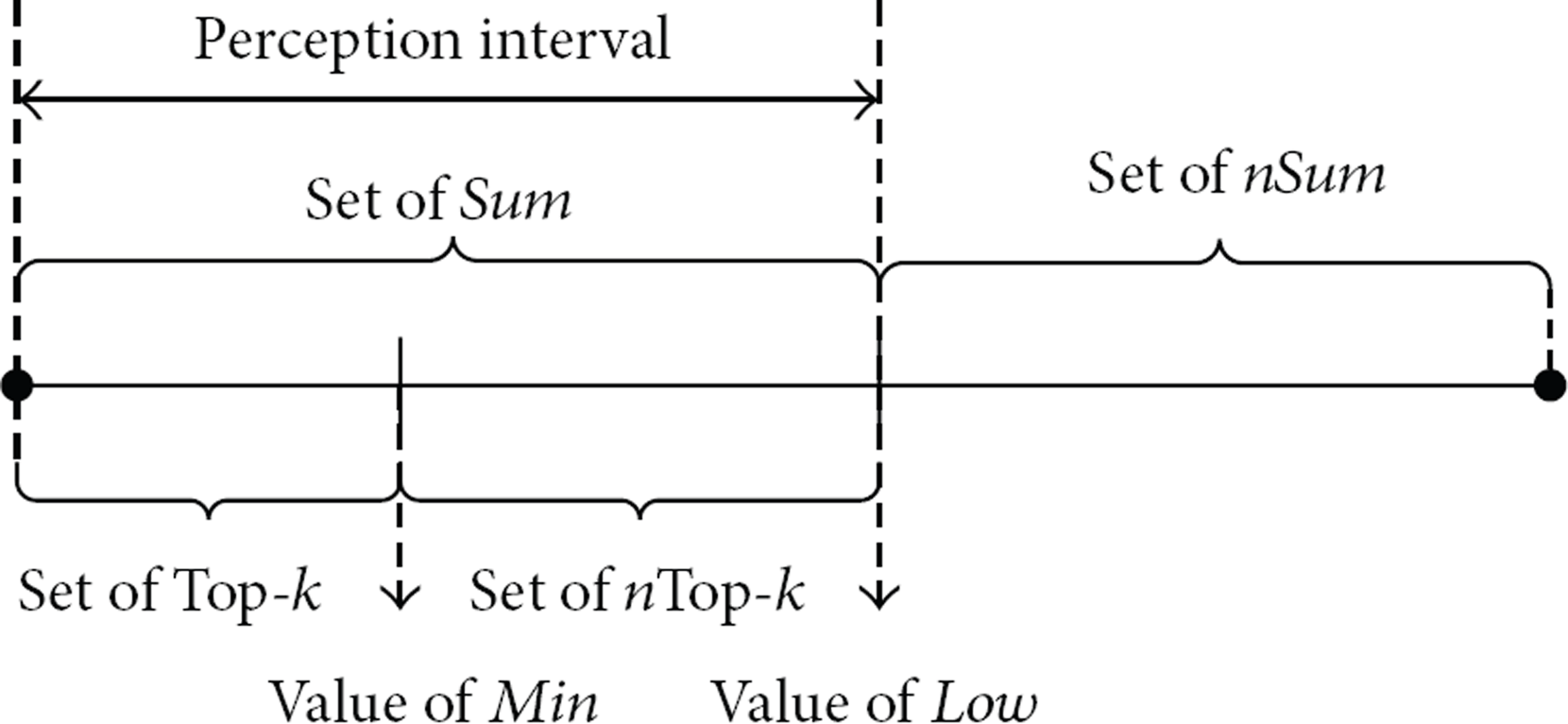
Description of sets that sink keeps.
As sensing data changes with the environment, it is necessary for nodes to send update information periodically to obtain exact records. On one hand, there are so many nodes in the network and it is obviously inadvisable for all nodes having effect on query results to send update information. On the other hand, recently even if filters are used in nodes, the sink node can only obtain approximate data. In this paper, each node has a threshold τ, and only when the sensing data is higher than the threshold, the node will send update information to the sink node. In addition, we generate different thresholds for different nodes; thus, we can protect the minimum and maximal value and prevent attacker from analyzing characteristic of the whole network. We set threshold τ as follows.
For Nodes in Set Top-k, For Nodes in Set nTop-k, For Nodes in Set nSum,
When receiving data from nodes, the sink node can identify the nodes and type of messages. There are five situations.
Update Message (UM) of Nodes in Set Top-k. The sink node receives message and finds out whether the value of the sending node is lower than min. If the value is lower than min, then the sink node deletes the node from set Top-k, puts it into set nTop-k, and then informs the node to change its threshold τ into min. UM of Nodes in Set nTop-k. The sink node receives message, deletes the node from set nTop-k, puts it into set Top-k, and then informs the node to modify its threshold UM of Nodes Not in Set Sum. The sink node receives message, records the node, and then compares its value with min. If the value is higher than min, then the sink node puts the node into set Top-k and informs the node to update the threshold Query Feedback Message (QFM). We will discuss it later in this section. Inspection Feedback Message (IFM). We will discuss it later in this section.
After a period of time, there may be less or more than k nodes in set Top-k (a set maintaining query results) or less than k nodes in set Sum. Assume that there are If If
Consider Consider
With the execution of the algorithm, nodes in set Top-kmay jump into set nTop-k, or contrarily, and nodes in set nSum may jump into set Sum. So the values of some nodes in set nTop-k may be less than low; thus there exists some useless nodes in set Sum which leads to false decision by the sink node. To solve this problem, the sink node periodically sends inspection message to nodes in set nTop-k with a parameter “low”. The nodes which receive the message will set the threshold
3. Privacy Protection Strategy Based on Conic Section
Unlike traditional network, WSN is a network with limited energy, so that traditional key management is difficult to use in WSN. In this paper, the proposed privacy protection strategy based on conic section abandons key encryption method and simplifies the problem to protect the real data.
3.1. Description of Privacy Protection
Before sending sensing data, the nodes repackage the sensing data using privacy protection strategy to prevent attacker from stealing and analyzing real data. Assume that
To find privacy protection function is extremely significant. On one hand, the privacy protection function should be difficult to recover real data from it. On the other hand, sometimes the sink node does not need to know the values of the real data but the ordering relationship among them. For an instance, users may just want to know the k highest regions rather than the concrete data from those regions and so that there is no need for sink node to obtain real data but just their relationship of sequence. Therefore, the privacy protection function should be monotonically increasing.
The ordering relationship of data after using privacy protection function is the same as that of real data, and if attackers obtain data in network, they will know the relationship of real data. To solve this problem, each node in the network has a value of ID (
In this paper, we present a normalization method on real data; for example, data
The specific procedure of a node (take Node Node Node Node
The sink node keeps a conic volume table, which is composed of all kinds of different volumes obtained from, respectively, cutting the cone by all kinds of different straight lines whose vertical distances to conical bottom center are distinguished from each other. When the sink node receives data from nodes, it firstly computes the privacy protection value using the corresponding ID saved in it and then calculates the normalized data via simulating the straight line cutting the cone; finally it concludes real data through reverse normalization.
3.2. Privacy Protection Function
Assume that
On the basis of that, we propose a privacy function based on conic section. If we use a straight line to cut a cone, the larger the vertical distance between the line and the center of conic bottom is, the smaller the subvolume will be (as shown in Figure 4). That is, along the arrow in Figure 4, the larger the vertical distance between the line and point A, the bigger the volume of the rest part after the line cutting the cone. We assume that the radius of this conic bottom is 1 unit.

Picture of cone cutting.
We firstly compute the value of the subvolume. Assume that

Picture of computing subvolume.
According to geometry and calculus, we can deduce

We may set

We set

Furthermore, we can obtain
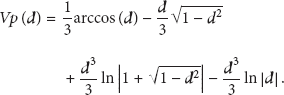
Then, the privacy protection function
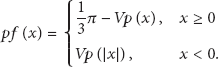
4. Analysis and Experiment Simulation Results
4.1. Simulation Initialization
We evaluate the performance of our approach through MATLAB simulations and compare our approach with EXTOK algorithm and FILA algorithm.
In the simulation, all nodes are evenly distributed in a grid area (
4.1.1. Energy Consumption of Query Algorithm
Assume that a node may send c bits data in its cycle and transmission distance is d; then energy consumption of sending data is

And energy consumption of receiving data is

The simulation parameters are set as follows: (1) original energy of father nodes: 1.5 J; (2) original energy of leaf nodes: 1 J; (3) operational cycle: 10 s; (4) simulation time: 200 s;
To evaluate performance of the proposed algorithm in many aspects, we change total number of nodes in network (defined as N) and the probability of data variety (defined as P) and we, respectively, execute Top-k(

Energy cost in network of different algorithms.

Energy cost of algorithms with different parameters.
Figures 6(a) and 6(b) show that the Top-k query algorithm in this paper consumes less energy than FILA and EXTOL in the same circumstance. Figure 7(a) displays that, when data of nodes changes frequently, the average remaining energy in our algorithm declines more slowly, which indicates that our proposal performs better than FILA and EXTOK even in the network with frequent update. Figure 7(b) reveals that our algorithm consumes less energy than FILA and EXTOK when executing Top-k with different values of k. Figure 7(c) shows average energy cost of nodes in different algorithms when changing total number of nodes. Our algorithm also performs better than FILA and EXTOK in large-scale network. Those results indicate that our algorithm performs well in energy consumption.
4.1.2. Network Lifetime of Query Algorithm
The simulation parameters in this section are the same as those in above experiments except for the simulation time. If the remaining energy of a node is less than 0.1% of its original energy, we mark the node as death node. We define the network lifetime as the time when half the number of nodes in the network have died and we define the network size as the total number of sensor nodes. Average results of experiments for 200 times are shown in Figures 8 and 9.

Network lifetime of different algorithms,

Number of residual nodes in different algorithms under the same conditions.
Figure 8 summarizes the lifetime performance of different algorithms. Each point in Figure 8 represents an average network lifetime with different network size. In general, the network lifetime increases linearly as a function of the network size. Figure 8 shows that our algorithm has longer network lifetime than FILA and EXTOK when executing Top-k query in the same network. In addition, the larger the network size is, the better our algorithm performs. The results imply that our algorithm can efficiently prolong network lifetime.
We calculate the number of nodes remaining in network to illustrate the network lifetime in another way. Average results of experiments for 200 times are shown in Figures 9 and 10. From the figures, we can judge the network lifetime from the downward trend of residual nodes to some degree.
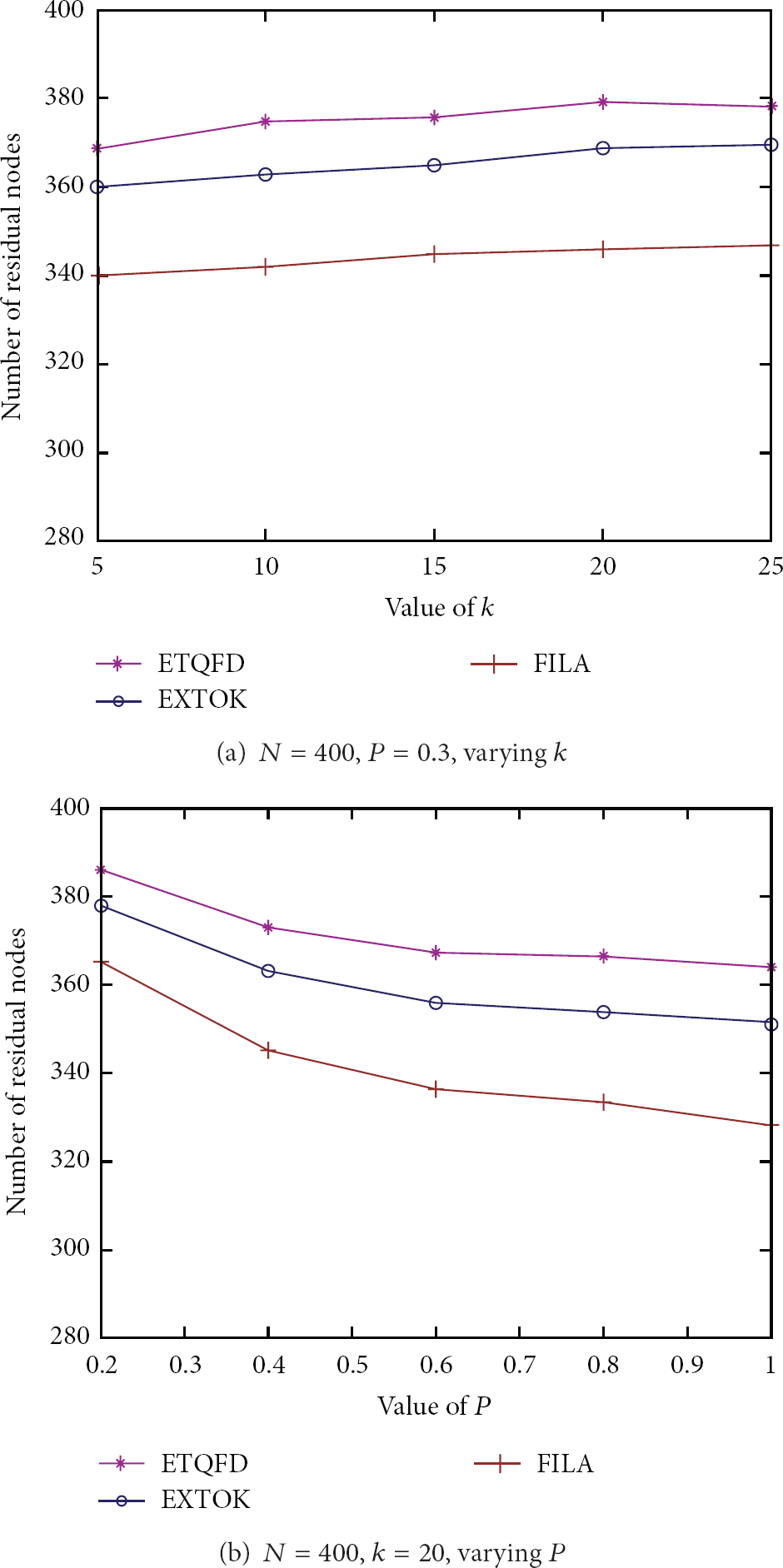
Number of residual nodes in different algorithms with different parameters.
Figure 9 proves that, at the beginning, nodes have enough energy to execute queries, and then more and more nodes become death nodes, while the rate of death of our algorithm is slower than that of FILA and EXTOK. Figure 10(a) shows that our algorithm performs better than FILA and EXTOK when executing Top-k with different values of k. Figure 10(b) displays that our algorithm is also superior to FILA and EXTOK in the network with frequent update.
4.2. Security Analysis of the Privacy Protection Strategy Based on Conic Section
The security of our strategy can be concluded as follows.
Even if attackers obtain data transmitting in network, it is difficult for them to compute the real data. The difficulty to decipher the privacy protection function to get real data relies on the complexity of the function. However, the privacy protection function based on conic section is complicated as its formula contains logarithmic function and antitrigonometric function. The privacy protection function is monotonically increasing and attackers may get the ordering relationship of the real data even if they do not gain them. To solve the problem, ID is used and every node only keeps ID of itself, so the attackers may encounter obstacle by analyzing data packaged with ID value to achieve the sorting sequence.
Energy consumption produced by privacy calculation is negligible compared with that caused by data transmission. In order to analyze the performance of our Top-k query algorithm with privacy protection, we take the quantities of data into consideration. We assume that there are two types of data: the first is simple data that occupy 1 data unit and the second is sensing data that occupy x data units. We assume that there are row child nodes of each nonleaf node in the query tree and so there are
Comparison of data amount in network between our algorithm and EXTOK.

In Table 1, we can deduce

and we multiply (8) with row
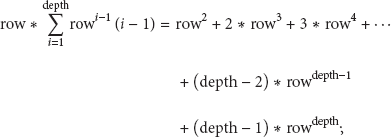
then we conclude

At the beginning, each node creates its DDT and sends DDT to its father node, where it only sends col (
according to (10), so data amount of initialization in our algorithm is much less than that in EXTOK. In the update phase, in our algorithm not all nodes need to send update message. And meanwhile, each node has a filter so that only k nodes have to send data all the time, thus reducing network traffic. Even in the worst situation, only
5. Conclusions
In this paper, we propose a Top-k query algorithm based on DDT and filter with privacy protection. The sink node distributes QRM according to DDT and only sends the request to nodes having effect to the results. Each node has a filter to avoid unnecessary transmission. In addition, we use privacy protection function to conceal real data. In the future work, we are absorbed on improving the security of privacy protection scheme while satisfactory efficiency guaranteed.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The authors would like to thank the anonymous reviewers of this paper for their objective comments and helpful suggestions. And meanwhile, the subject was sponsored by the National Natural Science Foundation of China (nos. 61170065, 61003039, 61202355, 61201163, 61373138, 61300240, and 61100199), Natural Science Foundation of Jiangsu Province (no. BK2011072), Scientific and Technological Support Project (Industry) of Jiangsu Province (no. BE2012183), Natural Science Key Fund for Colleges and Universities in Jiangsu Province (no. 12KJA520002), Postdoctoral Foundation (nos. 1101011B, 2012M511753, and 2013T60536), Science and Technology Innovation Fund for Higher Education Institutions of Jiangsu Province (nos. CXLX12_0486, CXLX13_467), Fund of Nanjing University of Posts and Telecommunications (no. NY212047), and the Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions (no. yx002001).