
Abstract
Duty cycling is an efficient design approach to achieve energy efficiency in wireless sensor networks. However, it may aggravate congestion due to long access delay and amplified hidden/exposed terminal problems. This paper first investigates some key facts that impact congestion and deteriorate packet transmission. With above observations, we propose a queue length based contention window adjustment approach, which allows congested nodes having high priority to access the channel. Then, a batch transmission scheme is introduced to drain accumulated packets rapidly. Finally, a random preamble mechanism is designed, so that congested nodes have more chances to get channel when other transmission is happening. Through the experiments on TelosB nodes test-bed using TinyOS, evaluation results show that our proposed schemes can mitigate congestion efficiently and have better performance than traditional approaches.
1. Introduction
In the past several years, wireless sensor networks (WSNs) have attracted many research interests in network protocols and algorithms design. One crucial design consideration in WSNs is energy efficiency due to sensor nodes need to operate from several months to several years without the necessity of replacing the batteries. Duty cycling is an effective method for energy-efficient wireless sensor network design, which lets sensor nodes periodically switch between active and dormant states and thus the energy of sensor nodes can be conserved by reducing idle listening and overhearing. There are several important duty cycling MAC protocols which have been proposed, such as synchronous protocols [1–3] and asynchronous protocols [4–7]. Since synchronization is a difficult design challenge in real test-bed based multihop wireless sensor networks, asynchronous protocols seem more practical and attractive.
The traffic patterns in wireless sensor networks usually show temporal and spatial diversiform characteristics. Packets are delivered to sink or cluster head nodes from source nodes via a multihop and funneling style, so the links near sink or cluster head node are more easy to get congested. Furthermore, when events are detected, a large number of packets are generated and injected to networks causing temporary local congestion. Congestion usually leads to serious network performance deteriorations such as packet drop, long delay, low throughput, and more energy consumption.
Congestion problem seems more serious in duty cycling operated wireless sensor networks. In asynchronous duty cycling protocols, each sensor node wakes up and operates independently according to its own schedule, and the sender does not exactly know the wake up time of the receiver. A long preamble needs to be transmitted by a sender to guarantee that the intended node could have a chance to receive data when it wakes up. Such long waiting delay intensifies network congestion, in which the longer the duty cycle length is, the worse congestion networks will suffer. Furthermore, when two nodes can not hear each other and transmit packets to a common receiver, the receiver will detect a long conflicting preamble and can not distinguish it successfully, so packets in senders cannot be sent out timely which causes extra delay and energy consumption. Although several congestion control schemes in WSNs have been proposed [8–10], they mainly focus on source rate adjustment or reliable transmission. The important impact of duty cycling on network still has not been studied and resolved well.
Currently off-the-shelf MicaZ sensor nodes (with ATmega128 Microcontroller) have 4 k SRAM and TelosB nodes (with MSP430 mixed signal microcontroller) have 10k RAM available. A part of RAM spaces are used for running operation system and allocating variables, that is, a classic program occupies 1-2 k bytes RAM footprint. The maximal packet size defined in IEEE 802.15.4 standard [11] is 128 bytes and the packet size in sensor network application usually contains several tens of bytes. So the remainder of spaces are available for protocol design.
Considering problems and sensor nodes features mentioned above, in this paper we propose DCMM (distributed congestion mitigation MAC), a new protocol that combines congestion detection, buffer operation, and medium access to mitigate congestion in duty cycling WSNs. We firstly study some important factors that deteriorate network performance in duty cycling WSNs and then propose three important design schemes to mitigate congestion and enhance packets transmission efficiency. (1) Nonuniform and congestion priority based preamble transmission letting the congested node have high priority to send preambles. (2) Randomized preamble packet interval scheme making congested node has a chance to access channel when the other node is transmitting preambles. (3) Batch transmission scheme, which makes a node transmits consecutive packets series when it seizes the channel and detects packets accumulated in its buffer.
The rest of this paper is organized as follows. Section 2 discusses some key related research works in wireless sensor networks. Section 3 describes the proposed DCMM protocol in detail. Some key implementation issues are discussed in Section 4. In Section 5 we evaluate the performance of the proposed protocol. Finally, Section 6 concludes this paper.
2. Related Work
Asynchronous MAC protocols are well implemented in wireless sensor networks test-bed. The advantage is that both sender and receiver can adopt their own listen/sleep scheduling, which makes protocol design simple and effective. To ensure the receiver can receive packets from the sender successfully in duty cycling operation, a preamble transmission operation before a data transmission is important.
B-MAC [4] is the earliest asynchronous MAC protocol in WSNs. The sender transmits a long and consecutive preamble before each data packet. The preamble length should be long enough to cover a whole operation cycle to ensure that the receiver can detect the transmission whenever it wakes up. After sending the preamble, the sender begins to transmit data packets to the receiver. The receiver keeps an awake state when it detects channel activity and awaits packets from the sender. After receiving the data packet, the receiver replies an ACK packet to the sender to confirm current transmission. Since the long preamble transmission in B-MAC causes a lot of negative effects, such as, the receiver needing to keep awake to listen to the whole preamble before receiving a data packet, which waste extra energy; nodes who are not the receiver still need to keep awake and listen to the whole preamble. X-MAC [5] integrates some improved designs to enhance transmission efficiency, especially in preamble transmission. The long preamble is broken down into a series of short preamble packets. Each preamble packet contains the destination address information. The interval of two consecutive preambles is long enough to accommodate an ACK packet. After receiving the preamble packet and getting the address information, nodes who are not the receiver can go to sleep early to conserve energy. The receiver also can end the preamble early by sending ACK packet.
RI-MAC [6] is a receiver based asynchronous MAC protocol. Each node periodically wakes up based on its own schedule to check if there are any incoming packets intended for this node. The sender with pending packet waits for the beacon from the intended receiver and starts the data transmission quickly after receiving the beacon from receiver. If there is no incoming data packet after broadcasting a beacon, the node goes to sleep. EM-MAC [12] is a multichannel asynchronous duty-cycling MAC protocol. A sender rendezvous with a receiver by predicting the receiver's wake-up channel and wake-up time based on the sender's knowledge of the state of the receiver, which can reduce interference and enhance network performance well.
Some researches also consider both the congestion and MAC layer problems in wireless networks. Zhai and Fang [13] reveal the close coupling between medium contention and network congestion and propose a framework that utilizes the MAC layer control frames to efficiently conduct the network layer's flow control function. Yi and Shakkottai [14] research the impact of MAC layer with congestion and model the multihop wireless network by using a Lyapunov function based optimization framework and then propose distributed end-to-end algorithm and distributed hop-by-hop algorithm. Hull et al. [15] also propose a hop-by-hop flow control scheme. When a node overhears a packet from its parent with the congestion bit set, it stops forwarding data, allowing the parent to drain its queues. Nodes use a token bucket scheme to regulate each sensor's send rate, which limits the sensor to sending packets to its descendants at the same rate. The authors also take notice of the impact of window size and channel access probability. However they do not make an intensive study on congestion and channel access in duty cycling wireless networks.
3. The Design of DCMM
DCMM protocol design includes the congestion detection, buffer operation, and medium access. The basic intention lies in nodes trying to adjust the contention window according to congestion level to ensure that nodes with high congestion level have high priority to access the channel. So packets in buffer can be drained quickly to mitigate congestion. We use the terms sender and receiver to denote one-hop transmissions and source and destination to denote the endpoints of a flow.
The state transition diagram of DCMM operation can be seen in Figure 1. In basic transmission, a sender contends to access the channel for packets transmission. Before each transmission attempt, the sender will measure buffer queue length to estimate congestion. If packet accumulation is detected, the sender adjusts the initial contention window size according to congestion level, which makes the congested sender have more chances to get the channel. Before transmitting data packets, a sender will transmit preamble packets with randomized interval, so that the congested node could have a chance to access channel when noncongested node is transmitting preambles. When the sender gets channel and detects packets in buffer exceed a threshold, it launches batch transmission to drain packets as soon as possible.

The state transition diagram of DCMM operation.
3.1. Contention Window Adjustment
DCMM is a distributed based protocol, in which the current contention window
When
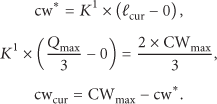
So we get

When
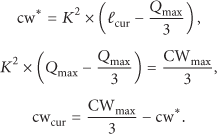
We have
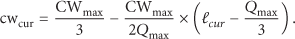
In DCMM protocol, backoff time is randomly chosen from
3.2. Randomized Preamble Packet Interval
Preamble transmitting is an efficient approach in asynchronous duty cycling MAC protocols to ensure a successful communication between a sender and a receiver. Currently the efficient preamble transmitting approach is shown in X-MAC. The preamble consists of a series of short packets embedded with destination address information, which let the receiver get packet early and put the nodes to sleep if they are not the receiver. However, it also has disadvantages when network congestion occurs. Assume the wake up time of receiver C is
The hidden and exposed terminal problems are also amplified in preamble based data communication. As can be seen from Figure 2, node A and node B cannot hear each other and begin transmitting preamble to a common receiver C; the collision period may last to the end of current cycle. On the other hand, if a sender begins to transmit preamble, the transmission of neighboring node is also restrained. Since the preamble may also last to a whole cycle length

The simple many-to-one communications patten.
In our DCMM design, we randomize the preamble packets interval and make the interval longer enough to allow other nodes' preamble packet to have a chance to access the channel. Figure 3 describes the scheme, here PP stand for preamble packets, while A1 and A2 are two type of ACK packets. Take the simple network topology shown in Figure 2, if node A has packets in its buffer, it will send a series of short preambles. The backoff timer value in preambles transmission is also based on functions described in Section 3.1. Due to the fact that preamble may last a long period, the heavy congested node (assuming buffer length of node B is larger than node A) should have a chance to beat light congested node or no congested node. The minimal interval between two consecutive PPs during preamble transmission should be long enough to accomodate a PP transmitting time and an ACK transmitting time. When there are packets arriving at node B, it transmits preamble packets with small interval. After receiving PP from node B, node C replies ACK1 with corresponding destination address. Therefore, node A overhears the ACK1 and goes to sleep immediately. In this way, congested node could gain a chance to send DATA when other transmission is happening. It is worth noticing that the maximum backoff interval should not be too long since sensor nodes have to be awake for possible packet reception.

Randomized preamble packets interval.
3.3. Batch Transmission
As discussed above, in asynchronous communication with preamble transmission, nodes may need to wait a long period before data packet transmission. A sender may not get the transmission priority again after current transmission, even though there are a lot of packets still accumulated in node's buffer. So in our protocol, we also propose a batch transmission scheme, which lets the nodes with buffer accumulation continuously transmit a batch of packets to drain packets quickly, while without contending to access the channel for each individual packet transmission, which also can reduce the control packet overhead.
When a sender contends to access medium and wins transmission priority, it then detects current buffered packets number

Batch transmission operation (a) node operation during batch transmission, (b) buffer limitation for batch transmission.
After receiving the preamble packet, the receiver node C replies an ACK0 packet to notify the sender to finish preamble transmitting. The ACK0 also contains the information about current available buffer space in the receiver, which is used for sender's batch number calculation. After getting current buffer status information from ACK0, the sender calculates the batch transmission number and then transmits a batch of DATA packets to the receiver. Each DATA packet is embedded a batch sequence number. When node C receives the last packet of current batch transmission, it replies a group ACK (ACK1) to confirm current batch transmission. Considering the imperfect channel conditions due to channel fading and shadowing, some of the packets in the batch packets may not be received successfully. DCMM adopts a selective acknowledgment scheme to enhance reliability; namely, the receiver fills ACK1 with information about which packets are not received successfully, letting the sender knows lost packets during batch transmission. The sender can schedule these packets in the buffer head and retransmit these packets in the next transmission for reliability considerations.
The preamble packet is stamped an extra bit (batch bit) in the packet head before transmission. When the receiver receives the preamble packet and gets the batch bit, it will log the available buffer information in the ACK0 and reply the sender. All the DATA packets and ACK packets are embedded with the NAV (Network Allocation Vector) about the time for now to the end of current batch transmission. The neighboring nodes that have no packets to send and overhead these packets can go to sleep for energy conserve consideration.
The packet number in a batch is an important parameter that needs to be considered carefully. Assume
The batch transmission number should not exceed current available space in the receiver, or else buffer overflow may occur in the receiver. Figure 4(b) shows such situation. Assume all the nodes have same maximal packet capacity, so we can get the batch number allowed by the receiver (
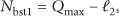

So the batch transmission number allowed by the sender (

Assume the current packet number in the sender's buffer as

4. Prototype Implementation
In this section, we discuss some key implementations of DCMM protocol. DCMM is designed in nesC [16] for TinyOS2.x [17], and we use TelosB motes [18] that consist of CC2420 Radio [19] and MSP430 microcontroller [20], with the data rate of 250 Kbit/s. TelosB motes also have 10 K bytes RAM space available. A typical sensor application usually cost 1 K-2 K bytes RAM space. So there is nearly 8 K bytes RAM space available for packet buffer design. Considering the MAC packet size defined in IEEE 802.15.4 standard is 128 bytes, a node's buffer size could be more than 60 packets (8 K/128). In our protocol, the buffer size is set up to 30 packets.
In our design, we insert the Queue component between Routing layer module and MAC layer module, as shown in Figure 5(a). When Routing layer dispenses a new packet to Queue component, Queue component firstly checks current queue length and declines current packet if queue length reaches the maximal value, or else it will allocate a new RAM space and copy current packet to the RAM space and then puts the allocated packet to the tail of current queue. When MAC layer component sends out a packet and triggers the sendDone event, the event will be captured by Queue component firstly. Since the sendDone event in MAC layer may be generated by successfully transmitting a packet, timeout, or canceling current packet, Queue component checks the error status for further actions. If the error status is success, Queue component pops up current packet in queue head, then reclaims the RAM space for further use, and pushes the second packet to queue head and transmits it. The Queue component also contains a GetQueueLen interface, which provides other components with the ability to get current queue size. In DCMM protocol design, this interface is also wired to software ACK component and CSMA low power listening component.

Implementation under TinyOS (a) Queue scheme implementation; (b) software ACK scheme implementation.
CC2420 Radio Support Hardware Acknowledgement. In normal operation, when the receiver receives a data packet, CC2420 Radio generates ACK packet after 12 symbol period (192
However, in DCMM design, nodes need to record some important information to ACK packet such as available buffer space for efficient communication. Current ACK scheme can not meet our design requirement, so we have designed a software ACK scheme. As can be seen in Figure 5(b), we design the software ACK component and wire it to Receiver component. When packets are received by CC2420 radio, a FIFOP Interrupt is triggered, Receiver component knows that at least one packet is received by CC2420 Radio. The Receiver component then reads the packet from RXFIFO through SPI bus. To reply to data packets as soon as possible, Receiver component will reply to the ACK packet after the FCF (frame control field) field and address field are received, since such information is enough to distinguish whether the ACK is needed and who the sender is. Receiver component calls the SendAck interface to notify software ACK component to generate a software ACK packet. The software ACK component then constructs an ACK packet and fills it with basic address information as well as some important design information, that is, available buffer space in the receiver, the lost packet in a batch transmission. The ACK packet will be loaded to TXFIFO of CC2420 radio through SPI bus and then issues STXON to transmit the ACK packet. After the transmission of the software ACK packet, Receiver component signals the received data packet to upper layer.
The transmission operation also can be seen in Figure 6. Each time when a node gets a data packet from the upper layer, it needs to load the packets to TXFIFO first. Since the software ACK is also written to TXFIFO, and it may overwrite the data packet in TXFIFO. In our protocol design, we setup a global variable to maintain current state and assign software ACK with high priority. After writing an ACK to TXFIFO, which is the time

Transmission operation of the radio part.
5. Performance Evaluation
5.1. Experimental Setup
We use TelosB motes testbed to evaluate our proposed DCMM protocol. The DCMM protocol has been implemented in TinyOS-2.1 [17]. The experiments are conducted over a network with 30 nodes deployed in the floor of a large building. Figure 7 shows the topology, where nodes 0–15 are selected as the source nodes, which generate packets during the experiments, and node 29 is the sink node. Packets are delivered to sink node via other relay nodes.

Network topology for experiment.
The packet payload is set to 80 bytes in our experiments, and total message size is 112 bytes including the message head. Duty cycle length is set to 2 s. We let the source nodes send 400 packets then stop the traffic. We measure the throughput, latency, and energy consumption to evaluate the performance of our protocol and compare the performance of DCMM protocol with X-MAC and RI-MAC, which are the two representative asynchronous MAC protocols in wireless sensor networks. In our experiments, energy consumption is the total energy cost to deliver a certain number of packets from source to sink; latency is the average end to end delay to deliver a packet, and throughput is the total bits received per unit time by sink node.
5.2. Experiment Results
Latency. We first measure the latency of the flow from source nodes to sink, since the source nodes may have different hops towards sink node. We choose the traffic from node 0, 1, 2, and 3 for latency measurement, because these flows have the same hop count towards the sink node. In the experiment, the latency of each flow is measured and we calculate the average latency of these four flows. Here each flow may contain 400 packets during the experiments. When a node receives a packet and sends it to others after a while, we calculate the dwell time on a node, plus the transmission time to get one hop delay. Then we add all the one hop delay to get the latency.
Figure 8 shows the latency results. From the figure, we can see that with the packet interval increasing, the latency of the protocols decrease. Since the larger the packet interval is, the lighter traffic load will be, in heavy traffic load, many packets are injected to the network that cause buffer accumulation and even congestion. Packets can not be delivered to sink node quickly, so the packet latency increases as well. When packets interval increases, traffic load gets low and the packets in network may not occupy all the link capacities, so packets may easily be passed to sink and the latency is low. We also see that when the packet interval is less than 3.5, the latency becomes large, since from this time the network begin to be crowded.

Latency under different packet interval.
The latency of RI-MAC is lower than X-MAC during all the packet intervals, as RI-MAC utilizes invitation based transmission that can reduce collision and makes packets go fast that reduces latency. When traffic load gets heavy, RI-MAC may cause collisions at the receiver and still needs to back off for retransmit packets if several senders are transmitting the packets. For all the traffic loads, DCMM shows the lowest latency compared to other protocols, since DCMM can transmit several packets when buffers accumulated, which can reduce control packet overhead and send out packets as soon as possible. Therefore, the receiver can get more packets from other senders. The congestion window adjustment scheme can let the high congested node have high priority to transmit packet, which will alleviate network congestion and reduce latency. During the transmission, the sender can continuously transmit packets without any backoff operations, which can reduce the collision and increase the transmission ability. So we can find that the latency of DCMM is better than other protocols.
Throughput. We then compare the throughput performance of all these protocols. We measure the number of packets received by sink node in a unite time to calculate throughput. Figure 9 shows the throughput of these protocols. What can be seen from this figure is that when packet interval decreases, the traffic load increases and throughput also increases as well. Since in low traffic load conditions, the number of packets generated by source nodes is also small so that the receiver just gets small number of packets, this results in low throughput. When traffic load increases, more packets are injected into the networks and the sink node can get more packets in a unit time, which achieve high throughput. We can also see that when packet interval gets larger, all the protocols achieve nearly the same throughput since in low traffic load, the network does not get congestion and the packets generated from source node can be delivered to sink node fluently. So in a certain time, the packets received by sink node are nearly the same that lead to similar throughout.

Throughput under different packet interval.
We can also see that RI-MAC outperforms X-MAC since it puts senders in listening state and does not send the preamble. In this way, interference can be reduces and thus more packets can be delivered to sink quickly. As for our DCMM, when traffic load is small, the throughput is not larger than other protocols. While when traffic load increases, the throughput is obviously larger than other protocols. Since it utilizes the randomized preamble scheme, the collision can be reduced well and packet also can be passed to next hop node more freely. Furthermore, the DCMM adopts the batch transmission, as soon as a sensor node seizes the channel and is aware that there are multiple packets in the buffer, it tries its best to transmit several packets to the next nodes. So the node does not need to contend the channel for each packet transmission. The sender can get high transmission efficiency and large throughput. This is more obvious in high traffic load, where the packet accumulation is large so that batch transmission scheme can work well.
When traffic load increases further, the network may get saturated so that the throughput of all the protocols does not increase further. For different protocols, the throughput in saturated state is also different. Such DCMM utilizes contention window adjustment and batch transmission, which can increase the transmission capacity in saturated state, while X-MAC may get low saturated throughout since the long preamble transmission reduce the transmission efficiency.
Energy Consumption. We also measure the average energy consumption of all the nodes. Firstly, we record the time in which the node stays in sleep and idle time through the power control interface in TinyOS and a timer, and log the time in which the node stays in transmitting and receiving state through the hardware interrupt of CC2420. Since we add a 2.7 voltage supply in TelosB node and the current parameters are also shown in the CC2420 datasheet. After the sink node gets the last sequence number packet, it initiates a command to notify all the nodes to stop logging the time. The sink then notifies the source nodes to send several energy trace packets so that all the nodes along the path add their energy consumption information into the energy trace packets, until the sink node gets enough energy consumption information. We calculate the total energy consumption through these parameters and average the energy consumption.
The average energy consumption of all the protocols is shown in Figure 10. We can see that the energy consumption increases with packet interval increasing. When traffic load decreases, energy consumption also increases. This is because in the experiment, we calculate the average energy consumption for sending a certain number of packets, and nodes need more time to deliver all the packets. Control packet overhead and idle listening waste a lot of energy. When packet interval is small, the time for each source node to send all the packets is also small and the energy consumption spent on waiting for the receiver and keeping idle state is also reduced as well.

Average energy consumption under different packet interval.
With packet interval increasing, energy consumption of X-MAC increases greatly, especially when packet interval is greater than 4.5 s, since X-MAC needs to transmit a long preamble to ensure the communication between the sender and the receiver, which increase the energy consumption on idle listening. As for RI-MAC, the energy consumption increase is not as obvious as X-MAC, since it utilizes the receiver based communication that can reduce the energy in transmitting state. When the number of senders increases, RI-MAC can save a lot of energy.
DCMM protocol can achieve lowest power consumption. In data gathering network, there may exist many many-to-one communications, and the packets are easily accumulated in the node attached in the bottleneck. DCMM adopts batch transmission, which can drain buffered packets more quickly than RI-MAC and the nodes cost less time to deliver all the packets to the receiver. So the nodes cost less time on delivering all the packets to sink. The control packer overhead is also reduced. So the energy consumption is also reduced well.
Last but not least, the funneling effect is one of important issues in wireless sensor networks. Nodes closing to the sink node have excessive traffic load. As a result, the energy depletion for these nodes is much faster than nodes away from the sink. Node 28 in the proposed scenario consumed much more energy than other nodes in all MAC protocols. In the future work, we will pay greater attention to the funneling effect.
6. Conclusion
In this paper, a MAC protocol named DCMM (distributed congestion mitigation MAC) is proposed to alleviate congestion in wireless sensor networks. Considering the data gathering communication in wireless sensor networks, there exist lots of many-to-one communications and the receiver is easily accumulated because of large packet injection for multiple source nodes. The duty cycling operation causes long packet delay and low throughput. We dwell on some important problems that influence network performance and propose some schemes to alleviate the problems.
In DCMM, we proposed a contention window adjustment that can let the node with more packets buffered have high priority to transmit packets. Thus it can alleviate congestion for avoiding buffer overflow due to unbalanced traffic load. Then the randomized preamble packet interval scheme is also proposed, which can reduce the long preamble collision at the receiver. It also makes the nodes that have high buffer occupancy have chance to grab the channel resource to balance packet accumulation. We adopt the batch transmission scheme that lets the nodes with packet accumulation have right to transmit multiple packets to the next-hop node and do not need to contend the channel for each packet transmission. It can obviously reduce the congestion problem and also reduce the control packet overhead well.
We have implemented the proposed protocol under TinyOS system and TelosB sensor nodes and built the test-bed in a building for performance evaluation. We compared the performance of DCMM with traditional protocols and the experiment results show that our proposed DCMM can achieve better performance than other approaches.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The authors would like to thank the editor and the anonymous reviewer, whose insightful comments helped us to improve the quality of the paper. This work was partly supported by the National Science Foundation of China (Grant no. 61176031), Natural Science Foundation of Jiangsu (Grant no. BK2011018), and Graduate Research and Innovation Projects of Universities in Jiangsu Province (KYLX_ 0130).