
Abstract
Due to the limited energy of sensor nodes, it is a research goal that the lifetime of sensor networks is prolonged by transmitting the sensed data to the base station in an energy-saving way. Previous algorithms aim at reducing the average energy consumption rate to extend the network lifetime. However, some nodes sometimes may be served as the cluster-head too many times to conserve their energy, resulting in reduced network lifetime. Thus, the large deviation of network lifetime makes these algorithms impractical. This paper proposes a new clustering algorithm which not only reduces the average energy consumption rate, but also converges the residual energies of all nodes on a small interval. Based on the two-region cluster-heads selection mechanism, the coordinator adaptively adjusts the far-near regions to converge the energies of all nodes on a small interval. With the exclusion-circle of cluster-heads, cluster-heads can be distributed evenly in a spatial respect for each round, resulting in reduced energy consumption. The simulation results show that the proposed algorithm not only makes cluster-heads distribute evenly in a spatial respect but also converges the residual energies of all nodes on a small interval, resulting in extending the network lifetime significantly and stably.
1. Introduction
The technological advances in microelectronics, wireless communications, and embedded systems make the development and deployment of wireless sensor networks feasible [1–3]. In 2000, the professors in UCLA proposed a wireless sensor network, called Smart Dust, for military applications. Recently, its applications have been expanded on many fields, such as industrial control, environmental monitoring, medical care, and daily living facilities [4–8].
A lot of sensor nodes are distributed in the sensing field. All the sensor nodes conduct environmental sensing periodically and send the sensed data to the sink [9]. The sink collects and analyzes all the sensed data and then transmits the results to the user terminal. It is hard to recharge the sensor nodes after they are deployed. Hence, it becomes an important research issue that the sensed data are collected in an energy-saving way to prolong the network lifetime [10].
The approaches for data collection can be categorized into a clustering scheme [11] and a multihop scheme [12]. The clustering scheme is an easier and more efficient way to save energy in wireless sensor networks. In each round, cluster-heads are elected and each cluster-head collects the sensed data from its corresponding member nodes and then transfers the collected data to the sink. The energy consumption for data transmission is proportional to the square (or quadruplicate) of the distance between the sender and receiver. It is expected that the elected cluster-heads are uniformly distributed in the sensing area such that all the transmission distances are shorter, resulting in reducing energy consumption. If some particular nodes are elected as cluster-heads too often, these nodes will use up their energy earlier and the network lifetime is reduced significantly. Hence, the energy-balanced cluster-heads selection becomes a key point in designing a wireless sensor network.
Taking the above considerations, this paper proposes the two-region cluster-heads selection mechanism. The sensing area is partitioned into the far and near regions. In the first phase, the selected coordinator picks the node with the highest residual energy in the far region as the unique cluster-head for the far region. In the second phase, all the nodes in the near region calculate their priorities to compete for several cluster-heads by the nodes’ energy distribution window, which is estimated from the residual energies of cluster-heads of the last round. Finally, the coordinator unifies the cluster-heads by broadcasting to solve the collision problem. With the residual energies of cluster-heads of previous rounds, the coordinator adaptively adjusts the partition-state to make the system stay on two stable states back and forth after a short time period. With the exclusion-circle of cluster-heads, cluster-heads can be distributed evenly in a spatial respect for each round, resulting in reducing the energy consumption.
This paper is organized as follows. Section 2 reviews related clustering approaches for wireless sensor networks. Section 3 gives our proposed cluster-heads selection algorithm EnBaCH. Experimental performance comparison between EnBaCH and LEACH is given in Section 4. Section 5 concludes the paper.
2. Related Works
In LEACH [13], cluster-heads are randomly selected based on the probability by which each node will be elected as a cluster-head once in the fixed number of rounds. Probably, there is no cluster-head elected in one round and each node needs to send the sensed data to the base station by itself, resulting in wasting energy. Sometimes, cluster-heads are unevenly distributed and some member nodes employ larger energies to transmit the sensed data to their corresponding cluster-heads with the larger distance.
In TB-LEACH [14], all the nodes broadcast ADV (advertisement) packets to compete for cluster-heads only if the number of elected cluster-heads is less than the prescribed threshold. Hence, there are a fixed number of cluster-heads in each round. It only solves the problem of a few cluster-heads in one round.
LEACH-B [15] is a two-stage cluster-heads selection approach. The first stage is the same as LEACH except for broadcasting with its own residual energy. If the number of cluster-heads of the first stage is less than the prescribed threshold, in the second stage, the other nodes broadcast ADV packets to compete for cluster-heads according to time priority which is proportional to their own residual energy. It also solves the problem of a few cluster-heads in one round. Cluster-heads elected in the second stage can be with the higher residual energy while cluster-heads elected in the first stage are not.
C-LEACH [16] adjusts the number of cluster members for each cluster within the specified interval by a two-stage method. The first stage is the same as LEACH. It reforms the clusters in the second stage. However, some members may be far away from their corresponding cluster-heads, resulting in wasting energy.
N-LEACH [17] improves LEACH by giving some nodes more chances to compete for cluster-heads. For the nodes having served as a cluster-head in the fixed number of rounds, if the total number of their own member nodes is less than the prescribed number, they are allowed to compete for cluster-heads. It is assured that the number of its member nodes of each node in the fixed number of rounds is no less than the prescribed number. However, energy consumption of each node is not affected only by the number of its corresponding member nodes.
LEACH-IMP [18] partitions the sensing area into the prescribed number of regions in which there are the same number of nodes. In each round, exactly one node near the center of each region is elected as the cluster-head. The member nodes consume less energy because of the shorter transmission distance. However, the nodes near the center of each region consume more energy because of being served as cluster-heads frequently and will use up their energies earlier, resulting in reducing the network lifetime significantly.
EDL [19] enhances LEACH by considering energy and distance. The nodes within the specified distance from the elected cluster-heads are prohibited from competing for cluster-heads such that cluster-heads can be distributed uniformly in the spatial aspects. The nodes with higher residual energy are giving more chances to compete for cluster-heads. Hence, all the nodes are balanced with respect to energy, resulting in extending the network lifetime. However, it causes very high overhead to collect total energies for each round.
3. Energy-Balanced Cluster-Heads Selection Mechanism (EnBaCH)
Because all sensor nodes are distributed in the sensing area randomly, the location of all sensor nodes and distances between the base station and all sensor nodes is unknown in the beginning of the sensor network. Therefore, it is necessary to initialize the system with coordinator selection and set-up of far-near region.
After the system initialization, the system begins collecting sensed data. Each round composes two parts: set-up and data-collection, as shown in Figure 1. The set-up part consists of CH selection, coordinator broadcasting, member joining, and schedule broadcasting. The data-collection part consists of five frames, in which one sensed data from every sensor node is collected to the base station per frame. In each frame, member nodes transmit the sensed data to their corresponding cluster-heads in the scheduled slots while they are sleeping in the other slots for energy-saving. The cluster-heads collect the sensed data from their corresponding member nodes and then send all the collected data to the base station.

The schedule of each round.
With transmitting the same amount of data to the base station, the farther nodes from the base station will consume more energy than the nearer nodes. The sensing area is partitioned into two regions (far and near regions) according to the distance from the base station. In the first phase, exactly one cluster head will be elected in the far region, and then others are elected in the near region, resulting in reducing energy consumption.
For competing for cluster-heads with broadcasting, it is possible to collide with each other. The nodes with collision may perceive themselves as cluster-heads and send their data to the base station solely, resulting in wasting energy. By choosing a suitable node as the coordinator, it broadcasts the received cluster-heads information to unify the cluster-heads information of all nodes, resulting in solving the collision problem.
In addition to unifying the cluster-heads information, the coordinator must adjust far-near region to achieve the balance of energy consumptions. With the energy information of cluster-heads of previous rounds, the coordinator adaptively adjusts the far-near regions to converge the residual energies of all the nodes to a small interval.
3.1. System Initialization
Initially, the base station broadcasts the request to all sensor nodes and all sensor nodes send their own distances from the base station back to the base station, which are estimated by the received signal strength indication (RSSI). In order to partition the sensing area into far and near regions by the estimated distances, it is necessary that each sensor node has a unique (distance, node-id) tuple. The operation < on (distance, node-id) tuples is defined in the following, which possesses the property of total ordering.
Definition 1.
(dis 1 , id 1 ) < (dis 2 , id 2 ) if and only if dis 1 < dis 2 or (dis 1 = dis 2 and id 1 < id 2 ).
With the property of total ordering, the base station sorts all the (distance, node-id) tuples in decreasing order into Distance-Id List (DIL) and then broadcasts DIL to all sensor nodes. The partition-state of the sensing area can be defined with DIL.
Definition 2.
Let DIL
k
be the kth tuple in DIL. The partition-state
From Definition 2, each sensor node can determine its belonging region with DIL and
The coordinator is responsive for collecting the residual energies of all the nodes in the far region and selecting the node with the highest residual energy as the cluster-head of the far region. The nodes nearby the center of the sensing area are suitable for the candidates of the coordinator. A feasible candidate can reduce energy consumption due to short distances.
Initially, all the sensor nodes calculate their own broadcast waiting time which is in inverse proportion to their own distances from the base station. When each node has run out of its waiting time, it determines whether it broadcasts a Co_ADV packet or not. If a node is within the exclusion-circle of some coordinator candidates or there are three or more coordinator candidates, it will cancel broadcasting; otherwise, it will broadcast a Co_ADV packet, which includes other candidates’ information to claim itself as a coordinator candidate.
Each candidate has three distances among these three candidates through broadcasting messages. Each candidate has two related distances. The candidate with the minimum sum of its related distance should be in the middle of three. In order to let the coordinator be nearby the center of the sensing area, only the middle candidate with less distance (< threshold α) from the base station can be elected as the coordinator. If the distance between the middle candidate and the base station is greater than threshold α, the middle candidate broadcasts a Co_NAK packet to cancel its candidacy. When other nodes receive the Co_NAK packet, they will remove the middle candidate from the candidate list and then compete for being the coordinator candidate. If the distance between the middle candidate and the base station is not greater than threshold α, the middle candidate broadcasts a Co_ACK packet to assume its coordinator-ship. When other nodes receive Co_ACK message, they will record the middle candidate as the coordinator.
3.2. The Cluster-Head Selection in the Far Region
Because the nodes in the far region consume more energy than the nodes in the near region, only one cluster-head is elected in the far region and others are elected in the near region. In the first phase, the coordinator is expected to select the node in the far region with the highest residual energy as the cluster-head, resulting in the residual energies of all the nodes in the far region being converged on a small interval.
At first, the coordinator collects the quantities of the residual energies of all the nodes in the far region. All the nodes in the far region will broadcast their own quantity of the residual energy to the coordinator at a time slot randomly. The coordinator then selects the node with the highest residual energy and notifies it. The notified node will broadcast a CH_ADV packet to assume its cluster-headship. Due to collision, it is possible that the notified node is not the node with the highest residual energy.
3.3. The Cluster-Heads Selection in the Near Region
In the second phase, it is expected that the nodes in the near region with the highest residual energy are elected as the cluster-heads, resulting in the residual energies of all the nodes in the near region being converged on a small interval. As described before, in order to achieve the spatial balance, the nodes within the exclusion-circle of cluster-heads are prohibited from being cluster-heads. It is useless that the coordinator collects the quantities of residual energies of all the nodes in the near region. Therefore, we propose an estimation method to estimate the residual energy distribution of all the nodes in the near region. Based on the estimated energy distribution, it allows the nodes with the higher residual energy to compete for being cluster-heads with less collision.
Reference Energy (RE) is defined as the estimation of the highest residual energy in the near region for the current round. Let

From the definition, it is obvious that RE should be equal to
Recall that the nodes with higher residual energy are expected to be elected as cluster-heads. Let us introduce the concept of contention window. It is expected that the contention window covers most of the nodes with higher residual energy. Hence, let the beginning of contention window (WB) be RE + 0.1 and the width of the contention window be 0.7 Joules. Because the broadcasting interval is limited, the nodes with a residual energy less than RE + 0.6 do not join the competition for cluster-heads. Due to estimation error, maybe there exist some nodes with a residual energy greater than WB, namely, priority group, and it is necessary to give these nodes higher priority, as shown in Figure 2. ADVtime1 time slots are allocated for priority group. The nodes within the contention window are partitioned into usual group and backup group according to the energy threshold WB − 0.3. ADVtime2 and ADVtime3 time slots are allocated for usual group and backup group, respectively. Because usual group must have higher priority, ADVtime2 is set to be two times that of ADVtime3. Thus, the broadcast waiting time of priority group (

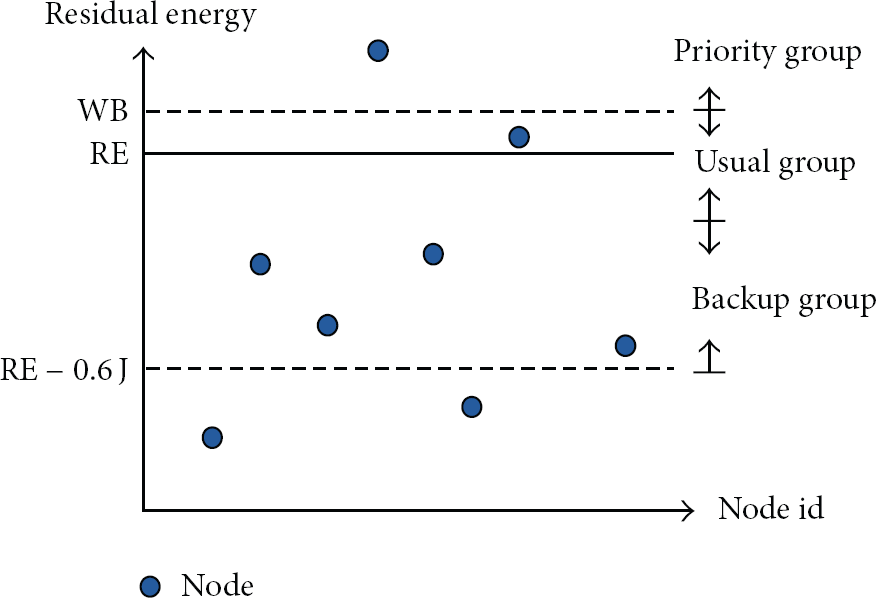
The contention window.
3.4. Adaptive Adjustment of Far-Near Regions
For transmitting the same amount of data to the base station, the farther nodes from the base station will consume more energy than the nearer nodes. The sensing area is partitioned into two regions (far and near regions) according to the distance from the base station. In the first phase, exactly one cluster head will be elected in the far region, and then others are elected in the near region, resulting in reducing energy consumption. If the partition-state is not in energy-balanced state and one of far-near regions will run out of energy earlier, the network lifetime is reduced significantly. However, the balanced state is affected by many factors and it is very difficult to derive the balanced state in advance. In this paper, we propose a partition-state adjustment scheme which adaptively adjusts partition-state by the energy information of cluster-heads such that average energy consumption per node is almost equal. Thus, it can extend the network lifetime significantly and stably.
Recall that there are k nodes in the far region for partition-state
Recall that the coordinator selects the node with the highest residual energy in the far region as the cluster-head. One turn is defined as a number of rounds in which every node in the far region has been the cluster-head once. That is, one turn consists of k rounds for partition-state
The partition-state adjusting scheme consists of two stages: initialization stage and adjusting stage. For the case of the current partition-state being at the left-hand side of the balance point,

The adjusting stage for partition-state adjustment.
In the adjusting stage, it is not assured that the current partition-state is in the left-hand (or right-hand) side of the balance point if
The partition-state is changed only if the system is in Cases 1 or 4. Due to the estimation error, it is possible that an incorrect state changing is made. To prevent the incorrect state changing, two small amounts of thresholds TH1 and TH2 are introduced. The conditions of state changing for Cases 1 and 4 become
For Cases 2 and 3, the system stays on one of two stable states to let
4. Simulations and Results
The simulations are conducted with NS2 [20]. There are 100 sensor nodes randomly distributed in the 100 m × 100 m area. The base station is located at the top of the sensing area with the distance of 75 m, as shown in Figure 4. The base station and all the sensor nodes are assumed to be fixed. All the sensor nodes are not equipped with the devices for detecting their own locations and their own location may be estimated with some localization algorithms. All the sensor nodes are homogeneous with limited energy.
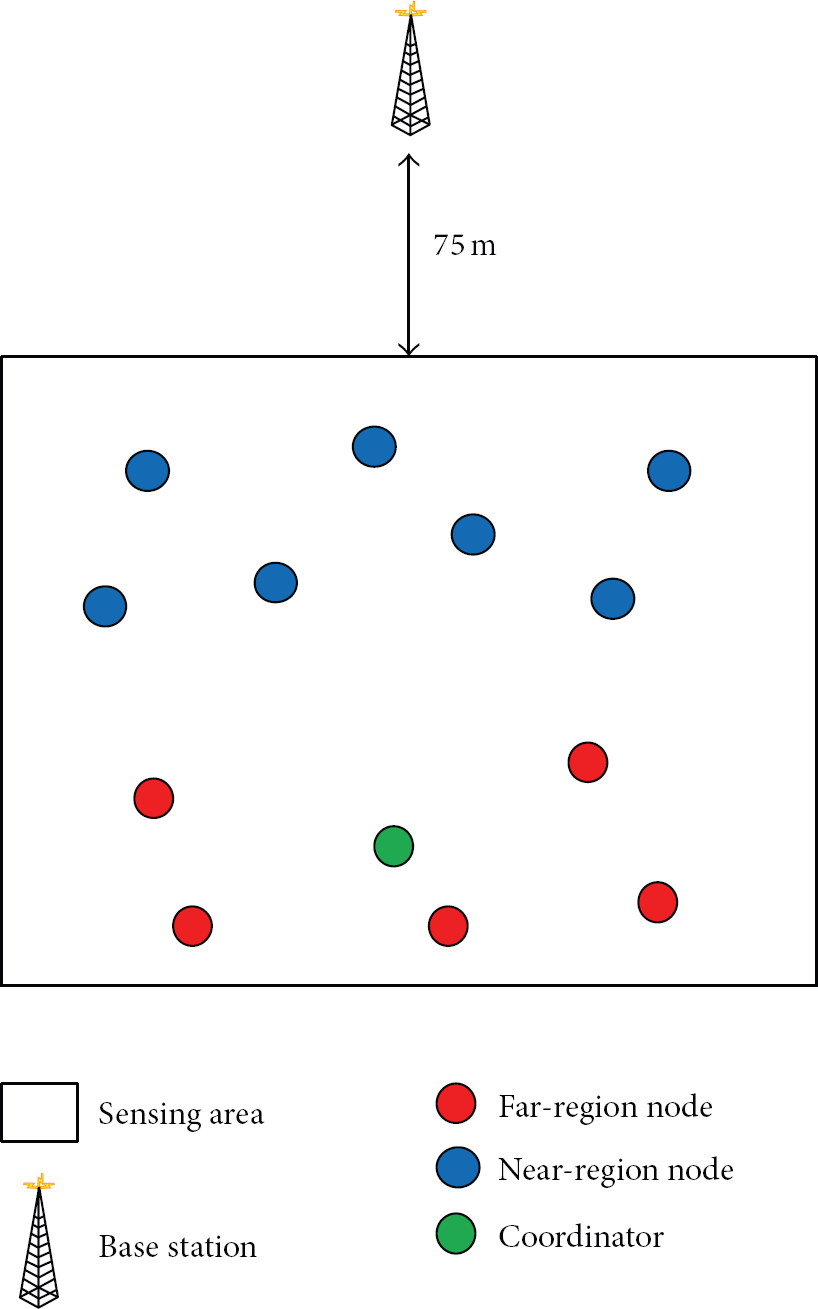
The simulation environment.
The simple first-order radio model is adopted to calculate the energy consumption for transmitting and receiving data packets. Let

The simulations with initial partition-states from

The state transition diagram for initial state

The state transition diagram for initial state

The state transition diagram for initial state
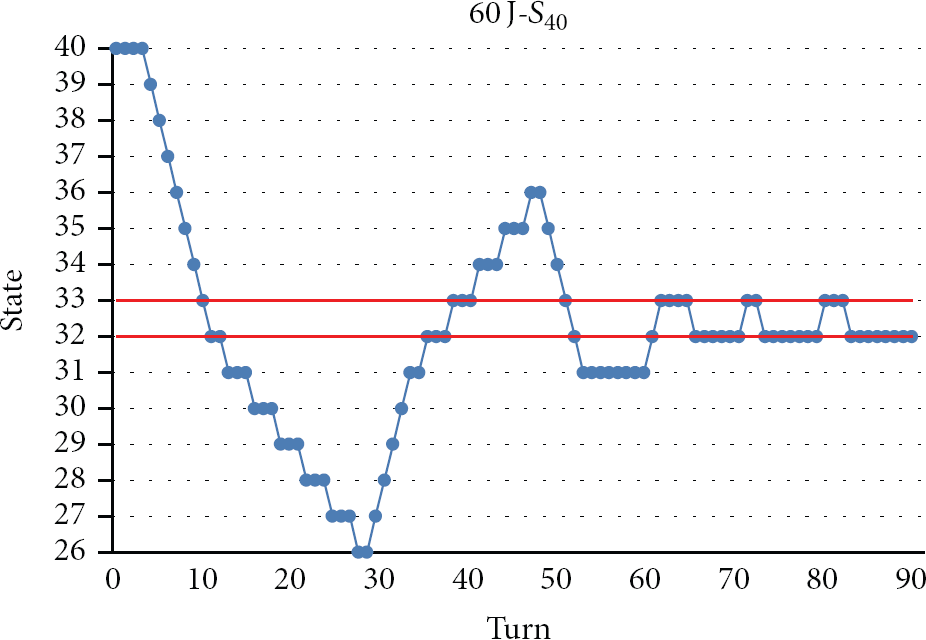
The state transition diagram for initial state
For the cases of initial partition-state being far away from stable states, the system stays on two stable states back and forth after turns 45 and 60 for initial states
Recall that the coordinator is expected to select the node in the far region with the highest residual energy as the cluster head. The residual energies of all the nodes in the far region are converged on a small interval (0.3 J), because the cluster-heads consume about 0.3 J per round. Due to collision and exclusion-circle, the node in the near region with the highest residual energy may not be elected as the cluster head. Hence, the residual energies of all the nodes in the near region are converged on a small interval (0.6 J). The simulation results show that the residual energies of all the nodes are distributed on a small interval (0.6 J), as shown in Figure 9 (blue dots denote near-region nodes, while red dots represent far-region nodes). Therefore, at the end of network lifetime, the total residual energy of 100 nodes is around 30 J, as shown in Table 1. In Table 2, the standard deviation of residual energy for EnBaCH is only 2.3308. This confirms that the residual energies of all the nodes are always distributed on a small interval. The standard deviation of average energy consumption per round for EnBaCH is very small too. This shows that our proposed algorithm is stable.
The network lifetime for LEACH and EnBaCH.
The standard deviation for LEACH and EnBaCH.

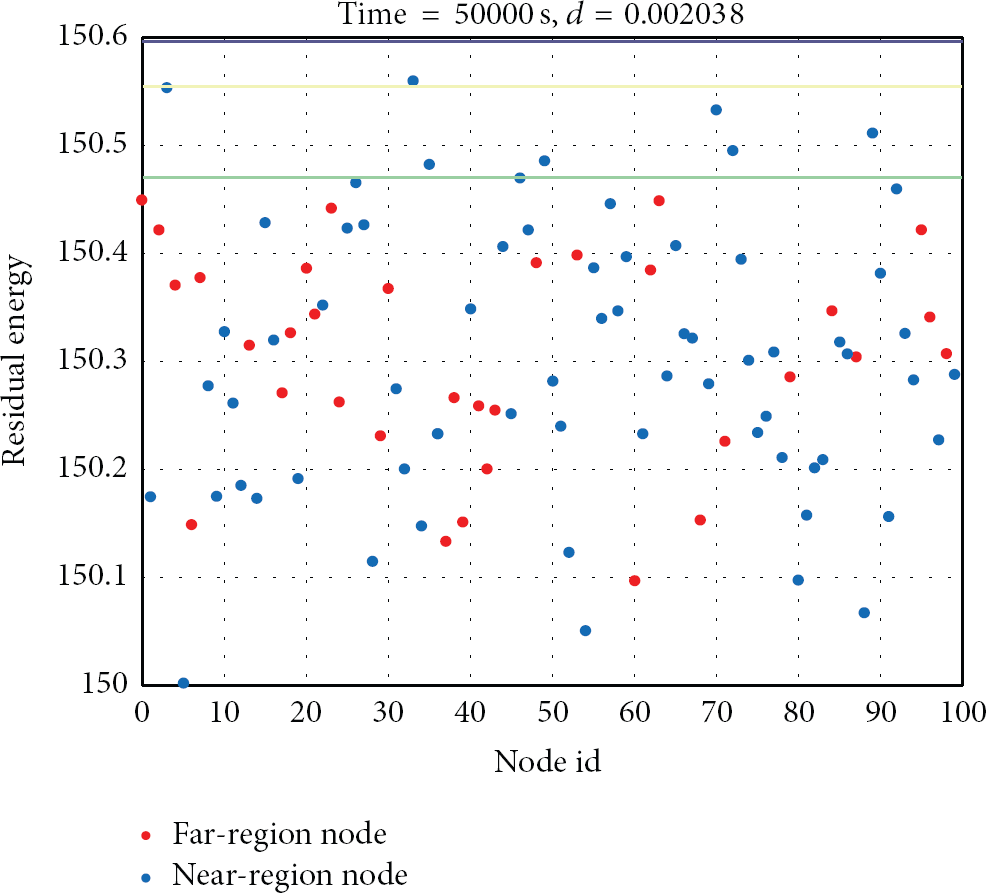
Residual energy distribution for all the nodes at time 50000 second.
Consider the average case in the following. From Table 1, because the energy utility of EnBaCH is 99.67% and the energy utility of LEACH is 92.96%, EnBaCH gets 7.22% improvements in the energy utility over LEACH. For average energy consumption per round, EnBaCH obtains 39.43% improvements over LEACH. Totally, EnBaCH obtains 49.40% improvements in the network lifetime over LEACH. In the worst case, EnBaCH obtains 55.35% improvements in the network lifetime over LEACH. Table 3 shows that EnBaCH obtains much more improvements in the network lifetime than other cluster-head selection algorithms.
The performance comparisons for cluster-head selection algorithms.

5. Conclusions
This paper proposes a two-region cluster-heads selection mechanism. The sensing area is partitioned into the far and near regions. In the first phase, the selected coordinator picks the node with the highest energy in the far region as the unique cluster-head of the far region. In the second phase, all the nodes in the near region calculate their priorities to compete for several cluster-heads by the estimation band of nodes’ energies. Finally, the coordinator unifies the cluster-heads by broadcasting to solve the collision problem. With the energy information of cluster-heads of previous rounds, the coordinator adaptively adjusts the partition-state to make the system stay on two stable states back and forth after a short time period. With the exclusion-circle of cluster-heads, cluster-heads can be distributed evenly in spatial respect for each round, resulting in reducing the energy consumption. The simulation results show that EnBaCH not only distributes cluster-heads evenly in spatial respect but also converges the energies of all the nodes on a small interval, resulting in extending the network lifetime significantly and stably.
The simulation results show that EnBaCH obtains 39.43% improvements in the average energy consumption per round over LEACH, because of cluster-heads unification by the coordinator and even distribution of cluster-heads in space. EnBaCH also gets 7.22% improvements in the energy utility over LEACH by adaptive partition-state adjustment. Totally, EnBaCH obtains 49.40% improvements in the network lifetime over LEACH.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported in part by the National Science Council, Republic of China, under Grant no. NSC 102-2221-E-011-067.