
Abstract
Accurate detection of driver's eye state by computer vision is critical to driver drowsiness monitoring. The histogram of oriented gradients (HOG) is commonly used as descriptive feature of eye image for state classification. However, HOG often suffers from the limit of local gradient information. This paper proposes a new HOG-like feature of eye image, called cooccurrence matrix of oriented gradients (CMOG), for the purpose of more effectively classifying the eye state. By introducing the cooccurrence matrix, the CMOG enhances the ability of describing global gradient information of eye images. The ZJU eye blink database is used as the baseline images for performance comparison. The classification results show that the accuracy of CMOG reaches up to 95.9% in comparison with 91.9% by HOG under this database.
1. Introduction
The driver eye state, that is, opening and closing, is the most salient facial expression related to driver drowsiness. Eye state classification based on computer vision plays an important role in the field of drowsiness monitoring. It is a challenging task to detect drowsiness from eye images owing to variable facial expression, random illumination, and head pose changing.
The ideas of existing methods related to eye state classification can be categorized into two types, that is, shape-based method and appearance-based method. In the first method, the eye state is evaluated by the distance of upper and lower eyelids. The elliptical shaped eyelids can be detected by deformable templates [1–3], which use optimization methods to solve cost functions to get the best shape. For convergence efficiency and accuracy of optimization methods, this kind of methods needs correct initial position as much as possible and sharp contrast of eye image. In the driving condition, it is hard to supply correct initial position and high-contrast eye image because of the influence of head pose and random illumination, and it makes this kind of methods unsatisfactory in real application.
The second method uses appearance of eye image to extract features for classification. Feature is the most important factor in this kind of methods. Many types of features from eye images have been proposed by nowadays researchers, such as HOG (Histograms of Oriented Gradients) [4], LBP (Local Binary Patterns) [5], Gabor wavelets [6], Eigeneye [7], and ASEF (Average of Synthetic Exact Filters) [8]. Taking LBP, for example, it uses the difference between pixels in a local scale to represent the image which is insensitive to illumination changing. Appearance-based method is more efficient and robust comparing to eye shape detection and it is more suitable in driving condition. In this paper, we choose extracting feature from the appearance of eye image to classify the eye state.
Gradient is more stable comparing to other descriptors and is highly related to eye state in the eye image, so we want to capture gradient information to detect the eye state. HOG feature is widely used in object detection using gradient information. HOG feature is a histogram of adjacent pixel gradients of brightness from local regions, which only can get gradient information in a local scale using cells, blocks, and blocks overlapping techniques. Many modifications of HOG were proposed for different applications, such as RS-HOG [9], CS-HOG [10], MSC-HOG [11], LPP-HOG [12], and CoHOG [13]. In these modifications, Watanabe et al. [13] used cooccurrence matrix [14] to describe gradient orientation distributions in local and global scale at the same time, and this strategy makes this method more robust than HOG. In their work, only gradient orientation was taken into consideration ignoring the gradient magnitude information, and it is time-consuming to use 31 different parameters of cooccurrence matrixes to gather gradient orientation information.
In this paper, the advantages of HOG and cooccurrence matrix are integrated by a novel gradient feature extraction scheme called Cooccurrence Matrix of Oriented Gradients (CMOG). The local gradient structure and the global gradient information are described by HOG and cooccurrence matrix, respectively. Gradient orientation and magnitude are used at the same time to make CMOG robust and effective for eye state classification.
The rest of this paper is organized as follows. Section 2 explains the outline of eye state detection by CMOG. Section 3 describes the detailed definition of CMOG. The optimization of CMOG parameters and its performance validation are illustrated in Section 4. Finally, Section 5 concludes this paper.
2. Outline of CMOG
The performance of eye state classification depends on the effectiveness of feature descriptor extracted from the eye image. The feature should be informative enough. The schematic of eye state classification by CMOG is shown in Figure 1.

The schematic of eye state classification by CMOG. SVM is used to classify the eye state, that is, opening and closing, for its high accuracy.
This paper focuses on the feature descriptor. Eye images can be gotten using algorithms [15–18] from the driver's face image. All of the eye images used in this paper are resized into 64 × 32 pixels.
The feature of Cooccurrence Matrix of Oriented Gradients (CMOG) consists of two parts. The first part is HOG descriptor, and the second part is cooccurrence matrix encoded with gradient information. The main goal of CMOG is to capture gradient information comprehensively. The first part (HOG feature) describes edge or gradient structure in a local scale. However, the second part of CMOG gets gradient structure in a large or global scale. These two parts of descriptors are then concatenated into the final CMOG feature.
Song et al. [19] proved that “HOG + SVM” is the best combination to detect the eye state comparing to other feature and classifier combinations. In this paper, we also adopt the SVM (Support Vector Machine) as the classifier to test our new feature.
3. Cooccurrence Matrix of Oriented Gradients (CMOG)
The first part of CMOG is HOG. HOG calculates gradient in a local scale; therefore, it is robust to illumination and deformations [13]. We directly use HOG following the guidance of Dalal and Triggs [4].
The main work of this paper concentrates on the second part of CMOG. Many advantages of HOG are adopted in the second part of CMOG to make it more robust.
3.1. Smoothing
HOG feature uses blocks overlapping and normalizing method in local scale to reduce the influence of noises instead of image smoothing, because smoothing can dramatically weaken gradient information in small scale. The cells, blocks, and blocks striding techniques used in HOG are also used in the second part of CMOG.
Blocks overlapping and normalizing are used in a large scale in the second part of CMOG. This method can reduce noise in local scale not in large scale; we need to know whether smoothing is needed or not before blocks overlapping and normalizing. Therefore, three kinds of eye images are compared: original grayscale image, isotropic smoothing image, and edge-preserving smoothing [20] image; these three kinds of eye images are illustrated in Figure 2.

Smoothing results. (a) Original grayscale image. (b) Isotropic smoothing. (c) Edge-preserving smoothing.
Gaussian filter is chosen as the isotropic smoothing filter

here σ
x
should equal σ
y
, and
Guided Image Filter [20] is chosen as the edge-preserving smoothing filter. Based on the local linear assumption,

where

where

where
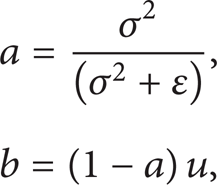
where u and σ2 are the mean and variance of the guidance image
In order to contrast, we set the same size of filtering window for these two filters. Table 1 gives the comparative performance of these three kinds of eye images based on ZJU eye blink dataset [22].
Comparative performance of three kinds of eye images.

From this result, we can find that edge-preserving smoothing achieves the highest identification accuracy. There are some heavy noises in the original eye image which will cause inaccurate feature description. Isotropic smoothing can reduce the level of noise and remove the details at the same time. Therefore the gradient information will get lost dramatically after isotropic smoothing. In contrast, the details are preserved while the noises are reduced by the edge-preserving smoothing. As a result, edge-preserving smoothing is conducted before blocks overlapping and normalizing.
3.2. Gradient Information Capturing
The cooccurrence matrix can be used to express the distribution of gradient information over an image. Every element (i, j) in cooccurrence matrix corresponds to the number of pairs of property levels i and j with offsets a and b in the original image [23]. This matrix can take the property values and positions into consideration at the same time.
The cooccurrence matrix is used as the second part of CMOG to capture the gradient information in a large scale. This paper tries to use constant offset instead of different horizontal and vertical offsets to capture the gradient information of eye image for computation efficiency. The cooccurrence matrix calculation procedure is illustrated as follows.
Parameters
N: dimension of cooccurrence matrix;
a: horizontal offset;
b: vertical offset.
Input. Intensity image {I(x, y)} x ∈ 1: N x , y ∈ 1: N y , I(x, y) ∈ 1: 256.
Step 1. The gradient magnitude of pixel (x, y) is
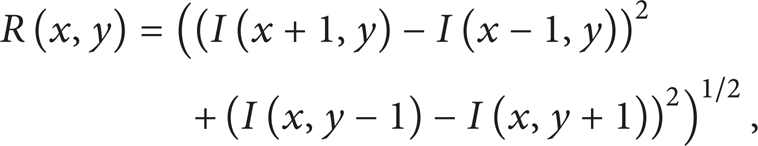
where I(x, y) is the intensity of pixel (x, y). The corresponding gradient orientation is
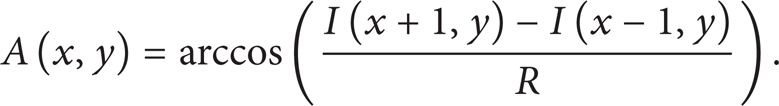
Step 2. Discretize the magnitude and orientation into N stages.
Step 3. Suppose the gradient magnitude of pixel (x, y) is R1 and its gradient orientation is A1. The corresponding values of pixel (x + a, y + b) are R2 and A2. Then, the pixel (A1, A2) in cooccurrence matrix accumulates abs(R2 − R1), just as

where Ca, b(A1, A2) is the value of element (A1, A2) in cooccurrence matrix.
Step 4. Calculate the horizontal direction (a, 0); repeat Step 3.
Step 5. Calculate the vertical direction (0, b); repeat Step 3.
Step 6. Calculate the diagonal direction (a, b); repeat Step 3.
Output. Cooccurrence matrix {Ca, b(x, y)} x ∈ 1: N, y ∈ 1: N.
The cooccurrence matrix calculation of one region of eye image is illustrated as Figure 3.
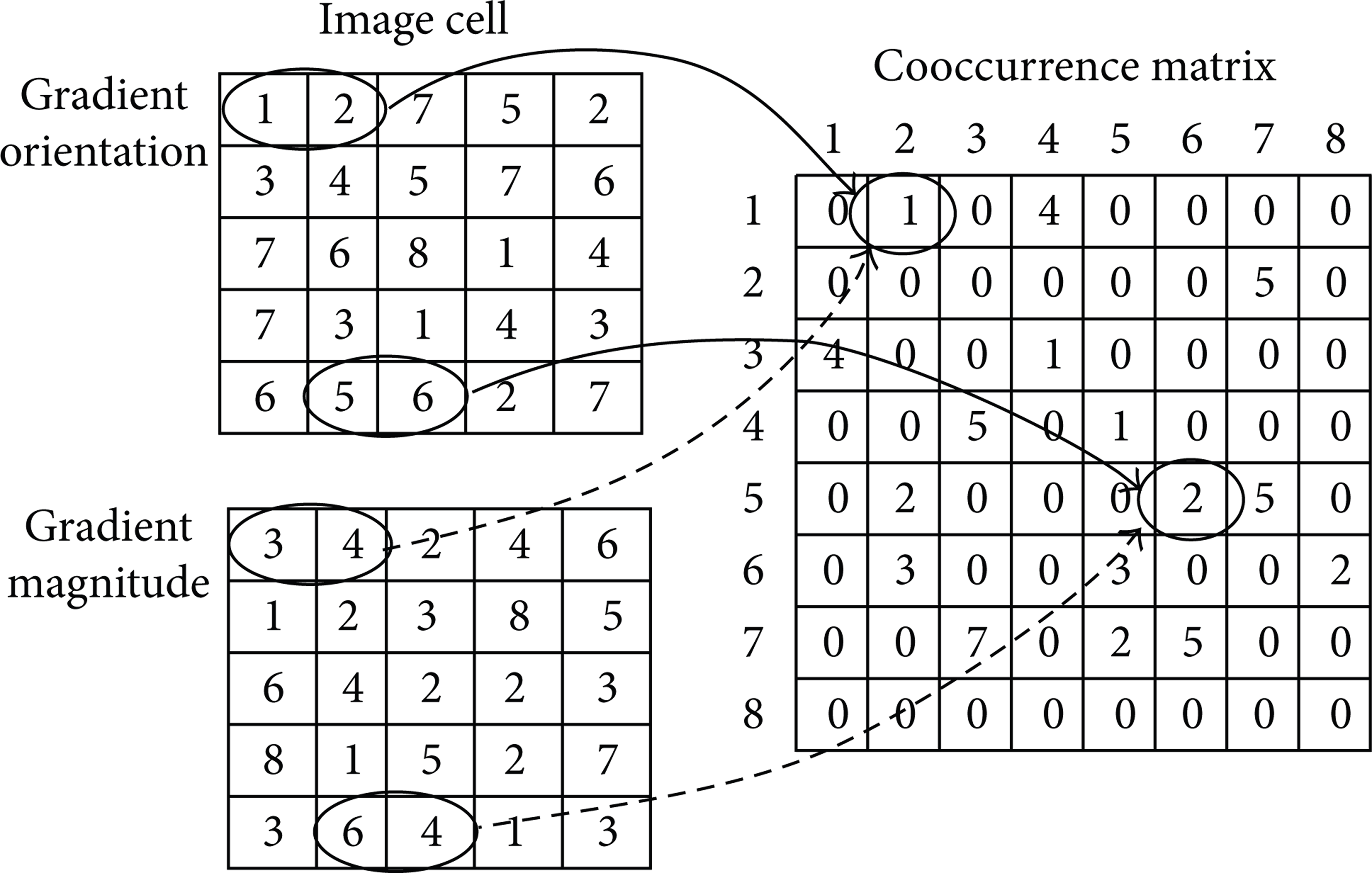
The cooccurrence matrix calculation of one region. The value of N equals 8, a equals 1, and b equals 0 in this figure.
HOG uses bilinear interpolation method between different cells in one block to improve the performance. We also take this strategy that is mixing the cooccurrence matrixes of different cells in one block into one matrix. In this paper, we use the following four kinds of cells and blocks as illustrated in Figure 4. The red rectangles are cells and the green rectangles are blocks.

Cells and blocks used in the second part of CMOG.
Figure 5 shows the final cooccurrence matrixes of different state of eyes corresponding to Figure 4(d). The difference of gradient distribution between these two eye images is obvious.

The distributions of gradient in cooccurrence matrix corresponding to Figure 4(d).
4. Experiments and Parameters Determination
4.1. Data
ZJU eye blink dataset [22] contains 20 individuals with and without glasses which was collected from frontal and upward views. Various transformations such as rotation, blurring, contrast modification, and addition of Gaussian white noise were applied to this dataset by Song et al. [19], and finally 1574 closed eye images and 5770 open eye images in the training set and 410 closed eyes and 1230 open eyes in the test set were obtained. The appearance of eye images is largely changed by these transformations, hence posing great challenge to eye state classification. Some samples of ZJU eye blink dataset are illustrated in Figure 6.

Illustration of some open (a) and closed eyes (b) of ZJU eye blink dataset.
The training set of ZJU eye blink dataset is used to extract CMOG feature and train the SVM classifier, and the identification accuracy of the test set is used as the reference standard to optimize the parameters.
4.2. Parameters of Cooccurrence Matrix Optimization
There are two important parameters in cooccurrence matrix: the dimension of matrix N and the horizontal and vertical offsets a and b (we set a equal to b for the purpose of simplification). The classification results are illustrated as Figure 7. The best dimension of cooccurrence matrix is 10 achieving 95.9% in identification accuracy, and the best offset is 4 in both horizontal and vertical direction.
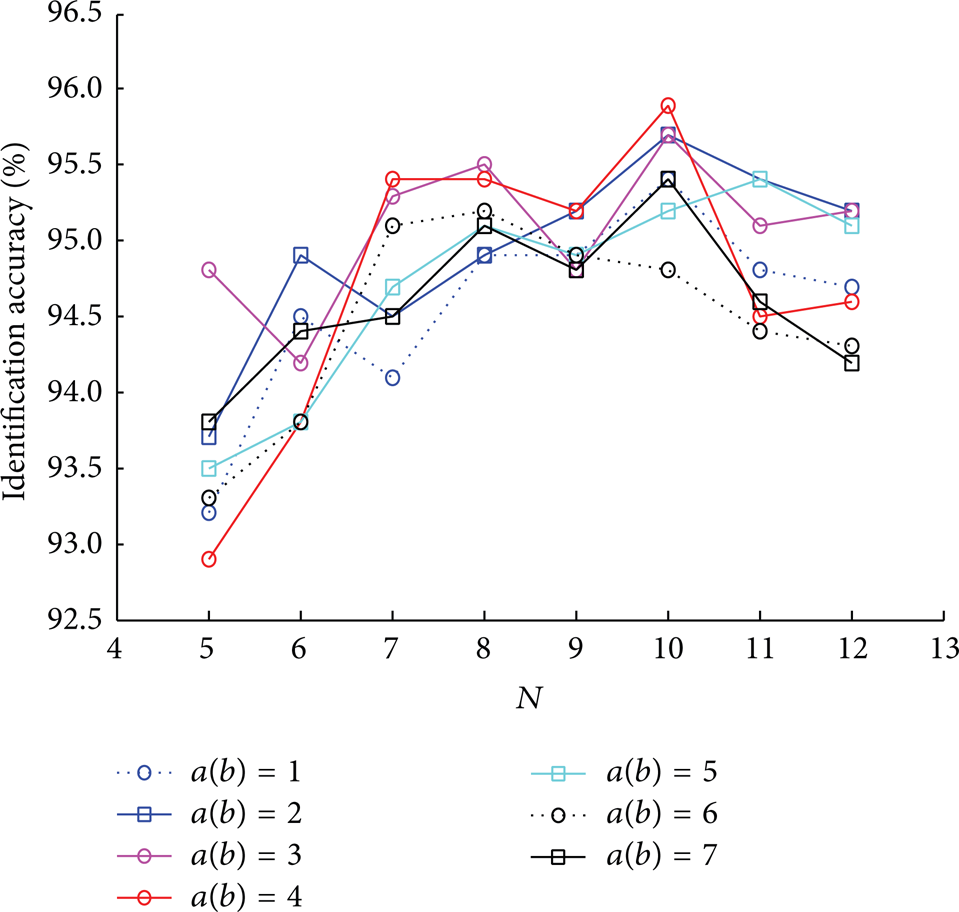
Cooccurrence matrix parameters optimization. a and b are the horizontal and vertical offsets of cooccurrence matrix, respectively, and N is the dimension of cooccurrence matrix.
The gradient orientation is used to determine the corresponding coordinate of a pair of gradient pixels in cooccurrence matrix, and the experimental results show that the unsigned gradient (0°–180°) performed better than the signed gradient (0°–360°), achieving 95.9% comparing to 94.3% in identification accuracy.
4.3. Parameters of Cooccurrence Matrix Normalization
The normalization of cooccurrence matrix is essential before comparison. Four types of normalization methods were compared by Dalal and Triggs [4] to get HOG feature, and these methods are also adopted to normalize cooccurrence matrix. Let
Comparative performance of five kinds of normalization methods.

The best normalization method for cooccurrence matrix is the L2-Hys based on the results of Table 2, which is also the best normalization method for HOG.
4.4. Parameters of CMOG
Up to now, we have determined all parameters of CMOG. In summary, the parameters to calculate the second part of CMOG are as follows: edge-preserving smoothing; 10 discrete stages of gradient magnitude and orientation; 10 × 10 cooccurrence matrix; 4 pixels offset in both horizontal and vertical direction; unsigned gradient (0°–180°); L2-Hys cooccurrence normalization; block spacing stride of 16 pixels corresponding to Figures 4(a), 4(b), and 4(c).
4.5. Result
The performances of HOG and CMOG in eye state classification are illustrated in Figure 8. The performance of HOG is better on condition that the number of training images is small; and the identification accuracy of CMOG becomes better when the number of training images is large.

Identification effects between CMOG and HOG.
In order to obtain high identification accuracy, the training set should contain nearly all kinds of variations, such as rotation, blurring, and noise, just as the work of Song et al. [19]. If the number of training images is small, these variations become a sense of noise of training images, which influence the performance of classifier. This influence can be weakened by local-scale based descriptors, because slight deformations make small histogram value changes [13]. In this situation, it is better to use local-scale based descriptors to capture the gradient structure of images, while the recognition accuracy is relatively low. If the number of training images is large enough, these variations become a sense of property of training images, which can be covered by large-scale based descriptors. Therefore, local-scale based descriptors are more robust than large-scale based descriptors for slight deformations, while large-scale based descriptors are more suitable to cover the property of training set comparing to local-scale based descriptors. As a result, it is better to combine local and global descriptors to capture gradient information of training images, and relatively high identification accuracy can be achieved.
The comparison of eye state classification between CMOG and HOG is illustrated in Figure 9. Since the top-left curve of ROC diagram means better performance, the results show that our method achieves better detection rate comparing to HOG. Finally, the identification accuracy reaches 95.9% using “CMOG + SVM” comparing to 91.9% using “HOG + SVM.”

ROC curves of CMOG and HOG [4].
5. Conclusion
This paper proposes a new feature called Cooccurrence Matrix of Oriented Gradients (CMOG) for the classification of eye state. In CMOG, the HOG is used to describe the gradient structure of eye images in a local scale and the cooccurrence matrix is used to describe the gradient information in a large or global scale. The ZJU eye blink dataset is used for performance validation, which has a broad range of transformations and adding noises. The test indicates that the proposed CMOG feature significantly improves the performance of eye state classification, reaching 95.9% comparing to 91.9% by only using HOG features. The proposed CMOG feature can also be extended to other kinds of image classification, for example, satellite images, medical images, and so forth.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Footnotes
Acknowledgments
The research described in this paper was supported by the Information Technology Project of Ministry of Transport of China (2012-364-835-110) and the National Natural Science Foundation of China (51205228).