
Abstract
Advancement in wireless sensor networks gave birth to applications that can provide friendly and intelligent services based on the recognition of human activities. Although the technology supports monitoring activity patterns, enabling applications to recognize activities user-independently is still a main concern. Achieving this goal is tough for two reasons: firstly, different people exhibit different physical patterns for the same activity due to their different behavior. Secondly, different activities performed by the same person could have different underlying models. Therefore, it is unwise to recognize different activities using the same features. This work presents a solution to this problem. The proposed system uses simple time domain features with a single neural network and a three-stage genetic algorithm-based feature selection method for accurate user-independent activity recognition. System evaluation is carried out for six activities in a user-independent setting using 27 subjects. Recognition performance is also compared with well-known existing methods. Average accuracy of 93% in these experiments shows the feasibility of using our method for subject-independent human activity recognition.
1. Introduction
The advancement in technology and the widespread of smart devices, such as smart phone, over the past few years provided a computational model that makes it possible to recognize human user's context anywhere and anytime. One area under the umbrella of automatic context recognition, which has been extensively studied over the past decade, is human activity recognition (HAR). HAR deals with the automatic recognition of activities of daily living using computers. These activities include both high-level activities, such as cooking and taking a shower, and low-level physical ones, such as walking and running. Physical activity patterns can provide significant support in various system (e.g., health care system).
In order to gather the information about physical activities, various sensing technologies have been introduced. One such technology is an accelerometer sensor. Due to high improvement in their sensing technology, it is now possible to use accelerometers to gather acceleration information about physical movement to recognize physical activities of a person in a more pervasive fashion. Although the technology supports the monitoring of activity patterns using accelerometers, the effectiveness of the recognition algorithm is still the main concern to interpret the accelerometer data based on different subjects and different activities as HAR requires an objective and reliable technique that can be used under the condition of daily living [1].
Even though there exist a number of research studies that have investigated the area of HAR via accelerometer (a-HAR) at length [2–5], there are two important aspects that have stayed unobserved. The first aspect is the fact that different people exhibit different physical activities for the same activity pattern due to their different behavior. For example, some people walk fast, whereas others walk at a slower pace. This phenomenon could result in misclassification of walking as running activity. The second aspect is that different activities performed by the same person could have different underlying models which makes it unwise to recognize them using the same feature. For example, walking is very different than cycling because in walking activity the whole body plays its role, whereas in cycling its mainly the legs that are involved. In order to overcome this problem, the stronger analytical method must be carried out to understand the behavior of different subjects regarding their physical activities for selecting any features. Therefore, this work proposes a feature selection method that is able to extract the most appropriate features of accelerometer data by analyzing a vast set of features based on subject and activity behavior.
This work makes several contributions in the area of a-HAR. Firstly, we have collected a significant amount of activity data from a large number of subjects using accelerometer-enabled smart phones. We have analyzed these data to demonstrate for the fist time that different people perform the same activities with different behaviors, and different activities performed by the same subject could follow different models. Secondly, based on our findings, we implemented a three-stage genetic algorithm-based feature selection method. This method produces a feature set that is both subject-independent and is capable of representing multiple activities effectively in the feature space. Thirdly, we used the selected features set with neural network, as the classifier, and compared its performance with seven existing works to show the feasibility of using our method for a-HAR via smart phone accelerometers.
The rest of the paper is organized into the following sections. In Section 2, we explain the background and related work of this research in the area of HAR (in general) and HAR (in particular). Section 3 explains in detail the proposed approach for subject-independent activity recognition. Section 4 talks about experiments and presents the experimental and comparison results for our approach and some existing a-HAR algorithms. Finally, in Section 5, we conclude our work and briefly talk about the future directions.
2. Background and Related Work
In this section, we briefly discuss the related work. Firstly, we explain the motivation behind context aware system. Next, we talk about one of the examples of context aware systems, that is, activity recognition and the existing activity recognition research. Lastly, this section discusses accelerometer, a low-cost wearable sensor, along with some related work in the field of a-HAR.
2.1. Context Awareness System
Ubiquitous computing, a computing paradigm that emerged about two decades ago, introduced the idea of making computing devices available everywhere in the physical world, while keeping these devices effectively invisible to the user at the same time. With the use of ubiquitous computing people can receive and process information anytime and anywhere through a device which can connect to the internet. This would result in reducing complexity of using devices and making people live easier and more efficiently [6].
Ubiquitous computing uses context as its core resource to provide proper service and information. Context is any information that can be used to characterize the situation of entities that are considered relevant to the interaction between users and application themselves [7]. One of the recent applications of ubiquitous computing is context aware system.
A context aware system is one that actively and autonomously adapts and provides the appropriate service or context to users, using the advantages of contextual information [8]. Though context comes in different types, one such type is the activity being performed by a user at any given time.
2.2. Human Activity Recognition (HAR)
HAR requires an objective and reliable technique that can be used under the condition of daily living [1]. In order to achieve this goal, HAR system should be equipped with sensing ability. Two approaches have been mainly used for this purpose [9]. The first approach is external sensor, fixedly placed in a particular location at the predetermined point of interest. On the other hand, the second approach, which is a wearable sensor approach, is a dynamic device attached to a user. Based on [9], wearable sensor is better than external sensor because the external sensor is only able to capture human activity when users are in the coverage range of the sensor which makes it lacking of pervasiveness. Due to its capability to capture human activity without position boundary, the wearable sensor approach became the most accepted approach. One of widely used wearable sensors for HAR is the triaxial accelerometer. First research in the area of a-HAR was conducted in the late 90's yet convincing challenge still exists within this field [3].
In [5] they conducted an activity recognition using single triaxial accelerometer worn near the pelvic area. They focused on eight activities including standing, walking, running, climbing upstairs, climbing downstairs, sit-ups, vacuuming, and brushing teeth. In order to recognize those activities, a particular algorithm is used to recognize the accelerometer signal pattern corresponding to each activity. Using a set of simple time domain features, which include mean, standard deviation, energy and correlation, they evaluated the performance of several classifiers such as Decision Tree, K-Nearest Neighbors, SVM, and Naïve Bayes.
In [2], the authors compared accuracy for different features across a number of different lower limb placements. In this research they investigated eight different dynamic activities including walking, walking up stairs and down stairs, jogging, running, hopping, on the left and right leg, and jumping. Seven sets with different number of features were evaluated using K-Nearest Neighbor classifier. This research found that it reaches a good level of classification accuracy when using simple time domain features.
In [4] three features were extracted from each axis of the accelerometer including peak-to-peak amplitude, standard deviation, and correlation between axes. In order to preserve the accuracy, they selected the significant features and eliminated the ineffective ones. Fuzzy inference system was used to classify four activities including moving forward, going down stairs, going up stairs, and jumping.
Researchers in [10] recognized a group of daily activities using evolutionary fuzzy models. Seven common dynamic activities were selected as the basic activities of daily life to be recognized, that is, walking, jogging, running, cycling, going up stairs, going down stairs, and hopping. Their evolutionary fuzzy model was able to estimate the membership functions through a statistical method and fuzzy rules using genetic algorithm optimization.
In [11] the research focused on five daily activities including walking, cycling, running, idling (sitting or standing), and driving a car. The research aimed at providing real-time activity recognition. In this research, 21 features including standard deviation, mean, and percentile were extracted from the accelerometer. Those features were used to classify selected activities using k-nearest neighbor and quadratic discriminant analysis classifiers. This research was able to show both classifiers are reliable for real-time activity recognition.
Those previous researches show a remarkable result in the activity recognition area. Various activities have been classified using several classifier algorithms based on numerous selected features. The previous studies achieved a good performance for recognizing the human activity. However, they failed to achieve good performance for subject-independent activity recognition, as we show in the Section 4.2. The previous research overlooked two important aspects, that is, different people perform the same activity differently and different activities performed by the same person could have different models. In other words, every person has a different behavior such as gesture to perform a certain activity. And, it is important to understand these different behaviors, as by understanding this behavior we will able to provide a more reliable activity recognizer. In order to overcome this matter, we analyze influential features from different subjects for different activities using a three-staged genetic algorithm based feature selection method. Those selected features are then used to classify activities using neural networks. Our proposed model is able to understand dynamic activities from different subjects using their accelerometer data and is capable of providing high accuracy for subject-independent activity recognition.
3. Approach
The adopted methodology of this research for dynamic activity recognition is illustrated in Figure 1. The first step in our proposed model is data collection using accelerometer enabled smart phones. The second step is feature extraction and analysis based on time domain feature analysis. The third step is the feature selection method for subject-independent human activity recognition using genetic algorithm. The learning process for activity classification is done in the fourth step using neural network, based on selected influential features.

The adopted methodology for subject-independent activity recognition on accelerometer data using neural network classifier with genetic algorithm feature selection.
3.1. Data Collection
As we can see in Figure 1, there are four major steps in our research methodology. The first step is data collection, that is, a collection of raw signals from accelerometer sensor, as people perform daily activities. In this research, we are focusing on recognizing dynamic activities. These activities include walking, jogging, running, going upstairs, going downstairs, and hopping. Those activities are selected based on the conducted research [10]. In order to get common position, subjects were asked to place their smart phone at front right pocket of a pant. This location is designed to capture user activity based on their leg movement due to our focus on dynamic activities. The accelerometer captures the activity by measuring the orientation of the device. Therefore, it could result in different patterns when the device is put in the different positions. The work of [12] shows that the accelerometer that is put on the thigh gives a powerful performance to differentiate the activities.
The android smartphone accelerometer is used to collect the activity data set. Each subject was asked to collect the data activity using our custom build application that can be seen in Figure 2. As we know, different devices have different sampling rates based on the smart phone model, so in order to control the data collection process, we did not use the highest number of sampling rate because it may differ for various android devices making the method less device model dependent. Based on [10] it shows that 50 Hz is a suitable sampling rate for recognizing dynamic activities with acceptable accuracy, which is used in this work as well.

Accelerometer-enabled activity data collector application before the user starts recording their activities (a) and while the user is recording their activities (b).
In this study, the data sets were collected from 27 healthy subjects (12 females and 15 males) between the ages of 18 and 29 years old. The criteria of selecting the subjects are based on their gender and age. We considered the gender and age because we assumed that different age and gender could perform different behaviors for the same activity. Those subjects were asked to perform more than one activity each day and each activity should be performed more than twice. We collected those data for more than one month. Therefore, we are able to collect data from the same subject and the same activity but performed on different days.
3.2. Feature Extraction
In order to recognize the activity, each behavior of activity should be represented with simple and general features [13]. The second step in our methodology is feature extraction which extracts the representative feature to recognize the activities. An accelerometer sensor generates time series signals that are highly fluctuating and oscillatory in nature [10]. Those accelerometer signal characteristics make activity recognition more difficult if we directly use raw signal data. Therefore, feature extraction is needed to gather the nontrivial data from such signals.
In order to extract information from those data, we divided signal data in several equal-sized windows. The windowing process reduces the flow rate and sends less data to system to recognize the activity performed by a certain subject [14]. Given a sampling rate of 50 Hz, we chose a window size of 100 samples, meaning two seconds, as such a window provides enough data for quality feature extraction while ensuring a fast response at the same time. Each window contains 100 numbers of samples as shown in Figure 3.

Representative raw signals of going downstairs (a), hopping (b) and running (c) activities which have different signal patterns.
As for the feature extraction, there are several types of features that can be extracted from raw signal data such as time domain features and frequency domain features. The work done in [9] showed that time domain features are able to effectively represent the data that can be used for activity recognition. The research found simple statistical feature and coefficient of time series analysis to be highly suitable for smartphone based activity recognition, as these features are capable of providing high recognition rates at lower sampling rates. Based on this finding, we chose the same features for our work.
As for simple time domain features, several features including mean, root mean square, variance, correlation, and standard deviation were used. The mean feature helps to characterize each window. The root mean square feature measures the tendency of data [15]. Also, variance feature is used to measure the data spread among different activities. Meanwhile, correlations between axes are also considered as a feature to represent the interrelationship of among triaxial accelerometer data. Standard deviation helps in capturing the range of acceleration.
In order to understand the individual behavior in subjects’ physical pattern, we also analyzed each activity data using time series modeling techniques, as time series analysis can reveal the unusual observation and particular patterns of data [16]. There are several models that are commonly used to perform time series analysis, such as a moving average model, autoregressive model, and combination of both models. Autoregressive model is useful for describing situations in which the present value of time depends on its preceding value and its random shock which represents the phenomena of data behavior [17]. While moving average is useful in describing phenomena in which event produce and immediate effect that only last for a short period of time [18].
In order to identify the model in our data, partial autocorrelation function (PACF) and autocorrelation function (ACF) coefficients were used as the characteristics of those models. Those coefficients reveal the pattern of each datum and indicate the possible model of the data. Determination of the model for the data is done based on the characteristic of theoretical ACF and PACF that can be seen in Table 1 [16] and sample of PACF and ACF of the activity, which can be seen in Figure 4.
Characteristic of theoretical ACF and PACF for determining process model.


Sample of ACF and PACF from a certain activity that can be used to determine the time series model of the activity data.
The fitting process of time series model to any data means estimating the parameter values for that model based on a selected model order. The parameter estimation process of autoregressive and moving average requires an iteration procedure [19]. Among other iteration procedures, we adopt Box-Jenkins model estimation due to its flexibility to the inclusion of both autoregressive and moving average model [20]. Determined model and parameter have to be verified to ensure that estimated parameters are statistically significant [21]. In this research, we used likelihood ratio to test model specification [22].
After the feature extraction, the selected features were analyzed. Figure 5 shows running activity and walking activity from the same subject, and it can be seen that they have different process models. For example, based on the characteristic of the model presented in Table 1, we are able to see that x-axis data of walking activity is an autoregressive (AR) model. On the other hand x-axis data of running activity is autoregressive moving average (ARMA) model. Same phenomena were witnessed for many other activities. Based on this difference, we can conclude that different activities could exhibit different data behaviors.

ACF and PACF graph of running (a) and walking (b) activities from the same subject showing different patterns.
That phenomenon does not only happen in different activities; even the same activity could exhibit different behaviors. This phenomenon could happen when an activity is performed by different subjects. This is very distinguishable because every person shows a different behavior while performing different activities. Figure 6 shows that different subjects (a), (b), (c), and (d) show different behaviors while performing the same activity, which is the running activity in this case. As we can see, the subjects (a) and (b) have ARMA model in every axis of their data but in different order. Compared to them, subject (c) has an AR model for every axis of their data. On the other hand, subject (d) has different models for every axis of their data. Due to these differences, we can see that every subject has different behavior, even performing the same activity. Therefore, it is important to understand those behaviors in order to get common features for every subject to support subject independent activity recognition.

ACF and PACF graphs of running activity gathered from different subjects show that every subject has a different behavior in performing a certain activity.
As we can see in Figures 5 and 6, every activity performed by different subject could fall in the different underlying models. Those differences also result in different features for each activity. Therefore, a single feature is not able to represent the entire activity. In order to solve this problem, we decided to create a big set of features and implement feature selection method.
3.3. Feature Selection
The third process is feature selection which is the selection of features that have high impact on the intended activities. Ladha and Deepa [23] define feature selection as a process commonly used in machine learning wherein subsets of the features available from the data are selected for application of learning algorithm. There are several advantages of feature selection. Feature selection is able to reduce dimensionality of feature space which can avoid the curse of dimensionality [23]. The main purpose of feature selection is to increase the accuracy of the resulting model. Feature selection also helps to reduce the abundant, irrelevant, misleading, and noisy features. Also, the use of feature selection is able to reduce the cost of the system in most applications [24]. As we showed in the previous section, there is no single feature set that is able to consistently perform better for all activities. Therefore, it is important to determine the features which have high impact.
Several algorithms have been presented as a computational solution for the feature selection problem [23]. The first approach is filter method which selects the feature based on discriminating criteria that are relatively independent of classification. The method uses minimum redundancy-maximum relevance feature selection. This method is fast and scalable. This method also provides good computational complexity. Unfortunately, it ignores the interaction with the classifiers. Some examples of algorithms for this method are Euclidean Distance and Correlation-based Feature Selection. The second method is the wrapper method which is a feature selection method that utilizes the classifier as a black box to score the subset feature based on their predictive power. The wrapper method uses simple and less computational feature selection. This method also interacts with the classifier to optimize the feature subset. The disadvantage of this method is its dependency on the classifier that makes classifier selection become an important process in this method. The algorithms that use this method are sequential forward selection, simulated annealing, and genetic algorithm.
The learning algorithm that we are going to use for feature selection is genetic algorithm. This algorithm gained a lot of attention due to its ability to reduce the likelihood of getting trapped in local optimum which inevitably is present in many practical optimization problems [25]. Genetic algorithm is parallel, iterative, optimized, and has been successfully applied to a broad spectrum of optimization problems [26]. The genetic algorithm evaluates the features by finding the maximum fitness of population by selecting feasible individuals from the population and uses its genetic information to produce the new optimal population of solution.
There are two basic operations in a genetic algorithm to produce new generation: crossover and mutation [27] process from the chromosomes. This chromosome which represents the set of selected feature is composed of several genes. Each feature is treated as a single gene. This gene is mapped into a chromosome by given a certain index, which is as follows:


Chromosome encodes of features.
Since our aim is to find feature set which is both appropriate for different activities for single person and effective in representing these activities across multiple subjects, therefore, we have devised a three-staged genetic algorithm-based feature selection method as seen in Figure 8. Therefore, different number of x is used based on the number of selected features in each stage.

The feature selection process based on the extracted features using a three-stage genetic algorithm. The selected feature (represented as triangles) as the result of each stage is used as the input of the next stages (represented as arrows).
The first stage of our proposed method analyzes the feature from each activity of each user. Based on this step we are able to determine which features have high impact in every user physical activity. As we can see in Figure 8, every A activity from m number of subjects is evaluated. This stage is aimed to analyze the behavior of the same activity performed by the same subject in different time frames. For example, subject m performs
The first stage result is
The second stage of feature selection step is aimed to analyze the feature based on each subject. In this stage genetic algorithm is run based on the number of subjects using their entire sample. The input for this stage is the selected feature of each activity from every subject. This stage is aimed to determine the different behavior of each activity performed by the same subject. Using the second stage we can determine the important features for each subject. As we can see in Figure 8, each subject gives a different set of features. Therefore, set of feature from each subject is combined using the same rule used in the first stage. The second stage feature set is structured from the sets of each subject based on its counter. For example mean feature appears on set of subject 1 and set of subject 2 then its counter is 2. In order to be selected in second stage features each feature should have more than 50% of number of subjects. In order to get global feature selection, the third stage genetic algorithm is used.
The selected features from each subject as the result from the second stage are used as the input for the third stage of feature selection. The third stage analyzes every feature from each subject. This process is used to determine the common features of physical activity for every subject and every activity. Those common features are the features that are used as the set of features for activity recognition step.
3.4. Activity Classification
After we get the common important feature from the feature selection process, the next process that should be done is activity learner and recognizer. The learning activities during the training process and recognizing the activity in the testing process will be done using artificial neural network (ANN) classifier. This classifier is chosen due to its adaptive characteristic and able to provide accurate classification result. ANN is able to classify a certain pattern in which data have not been trained. The characteristics of ANN are inspired by the work performance of a biological brain system which has nonlinear characteristic, robustness, fault tolerance, and fuzzy information [28].
There are several algorithms that can be used as a classifier in human activity recognition area, for example, Bayesian rule, decision tree, regression, and neural network. One of the widely known algorithms for activity recognition is decision tree. The decision tree is a classification algorithm based on a hierarchical data structure that is composed of internal decision nodes and terminal leaves [29]. In [30], decision tree was trained based on mean acceleration to recognize the activity. Based on the accuracy, decision tree is able to provide good performance to recognize the posture such as sitting and lying down. Unfortunately, it gave lower accuracy for activities such as stretching. The other algorithm is Bayesian rule. This algorithm classifies the activity by calculating the probability of each class [29]. The result in [30] shows that in order to provide accurate classification process using bayesian rule tends to need more data. It also shows that bayesian rule shows weaker performance due to its characteristic that is unable to precisely model the independence of features.
ANN is more robust and has better performance compared with other computational tools. One of the widely known learning algorithms in the neural network is back propagation neural network. Back propagation learns by iteratively processing a data set of training tuples by comparing the predicted value and actual target value (also called a class label) [31]. The network structure used in this research showed in Figure 9 consists of three stages which are input stage, hidden stage, and output stage.

Neural network classifier structure for subject-independent activity recognition using selected feature (
The input for input stage that will be used in this network is the features gathered from the feature selection process. Therefore the x number of nodes in input stage is based on the length of the selected features. The z number of the output stage is calculated based on the number of activities as the target class. Activation of each node in hidden stage and the output stage is done using the log sigmoid function. A sigmoid is the frequently used activation function. This function is easy to distinguish, so it can minimize the computational capacity of the training process [32]. The network learns about the process by adjusting weight based on the error value. Adjusting the weight is done based on the error and learning rate. In order to evaluate the entire method, some scenarios which are sample based activity recognition and subject based activity recognition will be executed.
4. Performance Evaluation and Comparison
In this section, we present the experimental design to evaluate our proposed method. Case study designed methodology which has been explained in [33] is used to validate the effectiveness of our method. We also present our evaluation process and the results in this section.
4.1. Experimental Design
In [33] Lee and Rine explained that it is necessary to have an empirical research methodology that is able to validate the effectiveness of a particular method. It provides a conceptual framework to support the collection of evidence as a set of conclusions to support our research hypothesis. Based on that study, the following components were defined.
4.1.1. Study Question
In order to validate the stated hypothesis, study questions need to be clarified precisely [33]. The “how and why” type questions are derived from research goal. Generated study questions for this study are as follows.
Why is subject-independent activity recognition difficult to perform? How can feature selection improve the accuracy of subject-independent activity recognition? How does the proposed activity recognition approach perform in contrast to the previous approaches for subject-independent activity recognition?
4.1.2. Study Proposition
The study proposition is derived from study questions [33]. It is composed of a set of facts related to a research hypothesis that should be examined thought a certain measurement. Using study propositions, we are able to point out the goal of study, give a certain scope of experiments, and suggest possible links between phenomena (e.g., different behaviors of same activity performed by different subjects) during the evidence collection process. The derived study propositions related to our study question are as follows.
Why is subject-independent activity recognition difficult to perform?
Every subject has different statistical process models from other subject to perform the same activity. Every activity has different statistical process models from other activity. How can feature selection improve the accuracy of subject-independent activity recognition?
The feature selection process is able to reduce the number of features. Feature selection learns characteristic of each activity behavior. Feature selection provides common features for every subject. How does the proposed activity recognition approach perform in contrast to the previous approaches for subject-independent activity recognition?
When applied as a three-stage process analyzing the performance of different activities for each subject, it can help us identify the most suitable feature set for subject-independent activity recognition.
4.1.3. Unit of Analysis
A set of selected resources to be examined during the experiment process. This unit of analysis is used as the evidence to support our research hypothesis. Unit of analysis is the actual source of information that measures the achievement of study proposition. The units of analysis that we use in this study are as follows:
process model of activity; number of feature; the accuracy rate for subject independent activity recognition without feature selection; the accuracy rate for subject independent activity recognition using feature selection; the accuracy rate of the existing activity recognition approaches for subject-independent activity recognition under the exact same setting.
4.1.4. Linking Data
In order to connect the generated unit of analysis and study proportion, linking both of those entities is important. Table 2 shows the relation of unit analysis used as the validity evidence of study proposition.
Evidence Collection.

4.1.5. Criteria to Interpret the Finding
This process corresponds to the measures used in evaluating the result of the experiments. This process is the iteration between propositions and data. Therefore, these criteria could help to support the study proposition. This criteria is also used as the proof of our research hypothesis. Using this criteria, we are able to determine whether our research hypothesis is accepted or not. The interpretation of our experiments is explained in detail in the following section.
4.2. Experiment Result
In order to gather mentioned evidences from the experimental design process, several experiment settings are conducted. For every experiment, the same set of data is used. The sample data from all the subjects was divided into training data and testing data, based on subjects. As we mentioned in the data collection section, we have sample data from 27 subjects. For the set of training data, we used the entire data from 20 subjects. The data from the rest of the 7 subjects were used as the testing data.
4.2.1. First Experiment
The first experiment in our research is aimed to evaluate the performance of subject independent activity recognition without feature selection. The features used in this experiment were gathered from the feature extraction process. The feature extraction process results in 66 numbers of features gathered from 20 numbers of subjects.
The result of first experiment which is based on sample data dividing by activity using all extracted feature is shown in Table 3. Based on this result, we can see that using entire 61 features for classification is not effective to understand each different behavior from the same activity performed by different subject. Due to a big number of features it is possible that some features are against each other. From Table 3, we can see that different subjects could have different behaviors to perform the same activity. This difference has been analyzed in Section 3.2 to prove that same activity could fall in different models as the evidences of study Propositions (1.1) and (1.2). Therefore, some activities are misclassified into different activities. For example, due to its different behavior of subject, running activity from 30% subjects was classified as jogging activity.
Result of classification process based on activity using all extracted features.

Same with previous analyses, the first experiment which is based on the entire activities divided by each subject using the entire features of the feature extraction process gives the lower amount of accuracy as seen in Table 4. From this table we can conclude that even performed by same subject, each activity could have different types of statistical model that should be determined.
Result of classification process based on subject using all extracted features.

4.2.2. Second Experiment
In this experiment, we studied the effectiveness of using selected features for subject-independent activity recognition process. From this experiment we would like to see the influence of using the selected features to understand different behavior from the same activity performed by different subject. Compared to the previous experiment, in this experiment we also want to figure out the effectiveness of the selected features.
As we mentioned in Section 3.3, three-stage feature selection process was run to get the influential features for every activity from each subject. By evaluating each feature based on subject and activity in the first stage, 61 numbers of features are selected for the next step of feature selection. Those features are the features that influence every subject for each activity. By gathering entire selected features, second stage of feature selection which is feature selection based on each subject was run. Every subject that appears in more than ten subjects is selected. That number is chosen based on the number of evaluated subjects which is 50% of the total number of subjects. From second stage of the feature selection process, 35 numbers of features are selected for the next process. The third stage of the feature selection process results in 21 numbers of features including mean, correlation, and process model. Based on the last stage of the feature selection process, not all of the axes are selected. for example from standard deviation features only (standard deviation feature) x-axis is selected. From this result, we are able to get the evidence of study Proposition (2.1) which means that our feature selection process is able to reduce the number of features for activity recognition.
In order to evaluate those selected features, the second experiment was conducted. The selected features based on three-stage feature selection process are used for the second experiment. The result of second experiment which is based on sample data dividing by activity using the selected features from the feature selection process is shown in Table 5. Compared to the result in Table 3, we can see that there is a big improvement of accuracy when we used selected features. From this table we can see that the feature selection process is able to determine the common feature from each activity based on different subjects which can improve the performance of a neural network classifier. From this result, we are able to get the evidence of study Propositions (2.2) and (2.3) which means that the proposed feature selection approach is able to learn about the characteristic of each activity behavior by providing common features for the entire activity of each subject.
Result of classification process based on activity using selected features.

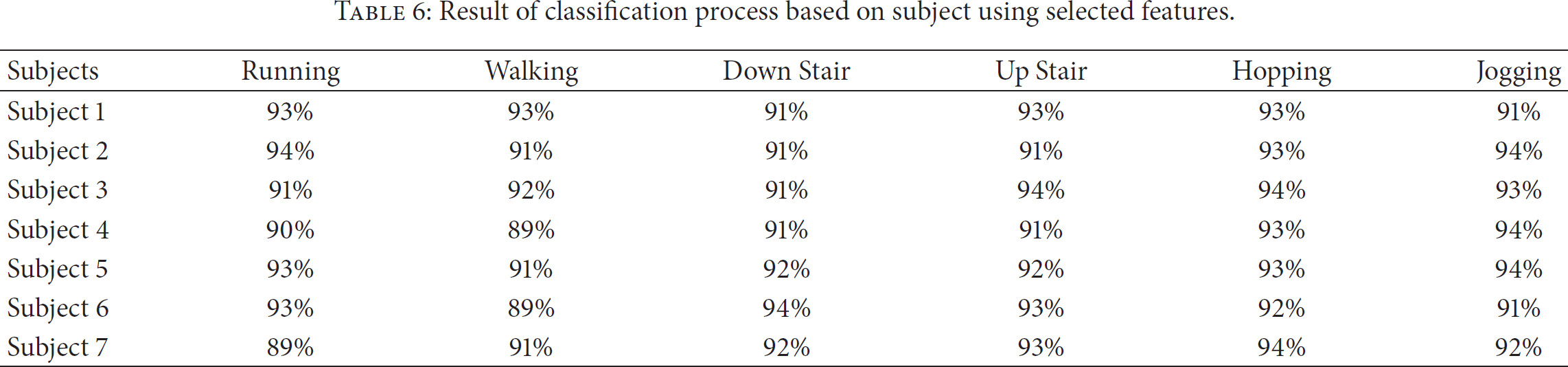
The result presented subject-wise, shown in Table 6, shows the same results. From Tables 5 and 6, we can conclude that three-stage feature selection process is able to learn behavior from each sample. Also, the feature selection process is able to give common feature for every subject and activity. This finding supports the fact that understanding each activity behavior from each subject is able to improve the learning process of activity recognition.
Result of classification process based on subject using selected features.
4.2.3. Third Experiment
The third experiment is aimed to evaluate the effectiveness of our adopted methodology compared to other previous works. In this experiment, different sets of features and classifier are used based on their own proposed methodology [3, 5]. Different numbers and types of features are used under the same setting used in those related works. In order to compare our approach to the existing approach, we used the same setting for our approach which is subject-independent activity recognition with three-stage feature selection as we mentioned in the second scenario. This experiment setting is conducted to evaluate whether our proposed approach using a certain set of features from feature selection is able to give better performance in subject-independent activity recognition. The comparison result for classification using different classifier is shown in Table 7.
Accuracy rate of the existing activity recognition approaches and proposed approach for subject-independent activity recognition.

From this result, we can see that our adopted methodology used neural network classifier with 21 numbers of features is able to represent the behavior of each activity from each subject. Table 7 also shows that our proposed approach for subject-independent activity recognition outperforms the existing works. Based on this result, we can conclude that our proposed recognition scheme is able to classify the activity accurately. It shows that our proposed approach is able to learn the data from the subject even though we do not include those subjects not only in the training process of classification but also in feature selection process. This result came out due to the ability of our proposed recognition scheme to learn from new data and its ability to handle the noise of the data. From this result, we are also able to conclude that our adopted methodology is able to perform subject-independent activity recognition. As we can see in Table 7, the previous methods failed to perform subject-independent activity due to its lack of capability to represent the behavior of the entire activity. Moreover, using a big number of features does not mean a wise decision. Using the smallest number of features does not make the classification process give worse performance. Therefore, the problem related to features in subject-independent activity recognition is not only about the number of features but also the effectiveness of the selected features to represent each behavior of entire activities.
Finally, based on the gathered evidence that we need to evaluate the study proposition as we mentioned in Section 4.1, we can conclude that our adopted methodology is able to provide better performance for recognizing subject-independent activity. This goal has been achieved by determining particular model for each activity and understanding different behavior of activity performed by different subjects through analysing the extracted feature and three-stage feature selection process, respectively.
5. Conclusion
Our proposed method uses accelerometer to capture dynamic activity from each subject. Android accelerometer is chosen due to its effective ability to capture movement. Gathered data of activity are performed on raw signal data. In order to classify activity, time-domain features are extracted from those raw signal data. The classification process of dynamic activity is not a trivial problem. It is because every subject has different behavior to perform activity. Our proposed method is able to overcome this problem using three-stage feature selection process using genetic algorithm. Demonstrated experiment shows that feature selection process is able to increase the overall accuracy of activity classification process. The experiment result shows that our proposed approach for subject-independent activity recognition outperforms the existing works.
In this study, we run the entire process of our method using Matlab. Our aim for handling subject-independent activity recognition has been achieved successfully using offline process. Therefore, our future plan includes online activity recognition by using the proposed method.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported by the National Research Foundation of Korea (NRF), Grant funded by the Korea government (MSIP) (no. 2010-0028631).