
Abstract
Processing top-k query in an energy-efficient manner is an important topic in wireless sensor networks. Redundant data transmitting between base station and sink node is avoided by installing filters on sensor nodes; thus, communication overhead between base station and sensor nodes is decreased. However, existing algorithms such as FILA, and DAFM consume much energy when updating the filter window. In this paper, we propose a new top-k algorithm named PreFU which is based on prediction models to update window parameters of filters. PreFU can predict the next s step sensor values based on time series predicting models which can be built by historical data. By estimating the cost of updating window parameters based on predicted sensor values, updates of filter window parameters can be reduced. Thus, the cost of updating window parameters is decreased. Experimental results show that our PreFU algorithm is more energy-efficient than existing algorithms while guaranteeing the accuracy of top-k query results.
1. Introduction
Despite all progress within research, energy consumption is still a major issue for wireless sensor networks [1, 2]. In addition, the quantity of generated data is large and dense. However, users are always interested in max or min k objects among them. Thus, top-k query processing is in high demand for many applications in uncertain databases and relational databases [3–5]. The top-k query in wireless sensor networks is different from general queries that data itself on sensor node could not determine whether it would be in final results. An intuitive way is that top-k query results will be determined by base station after collecting data from all sensor nodes. For our top-k queries, k is not restricted and the query determines the k highest observed values. The query also determines the full set of nodes that report the k highest values and is executed periodically starting at some point in time and reporting values for a number of subsequent rounds. The centralized query processing produces a large amount of communication cost and wastes lots of energy. So, how to process query in an energy-efficient manner is an important topic in wireless sensor networks, which can supply top-k results to users by minimizing the energy consumption. Generally speaking, query processing in wireless sensor networks is essentially different from that in traditional databases. A wireless sensor network containing N sensor nodes can be viewed as a distributed system, while this special distributed system is different from the general distributed system for there is not any single powerful node serving as the collection center to collect data from all the sensors. Each sensor transmits its data to the base station through multihop relays, which consumes energy for each data transmission. From another aspect, as the major optimization objective for query processing in wireless sensor networks, the network lifetime is determined not only by the total energy consumption of all sensors but also by the maximum energy consumption among the sensors. The sensors near to the base station consume more energy than the others, because they relay the data for the others and they will exhaust their batteries first. Once they run out of energy, the rest of the sensors will be disconnected from the base station, no matter how much residual energy left the rest of the sensors. Consequently, the network is no longer functioning even if the total energy consumption per query is reasonably small. Hence, how to evaluate queries effectively and efficiently in wireless sensor networks poses great challenges.
A typical solution for answering top-k queries in wireless sensor networks is by making the use of filters. Filters are broadcasted into the network and used by individual sensor node to decide whether its value is relevant to compute the query result. FILA (filter-based monitoring approach) [6] is an energy-efficient approach among these algorithms. The basic idea is to install a filter at each child sensor node, which avoids redundant data from transmitting to parent nodes or base station. However, the approach consumes much energy on updating filters. Mai et al. [7, 8] proposed DAFM algorithm according to FILA. The algorithm predicts the next sensed values of sensor nodes by linear regression model. Then, base station decides whether to update filtering windows based on predicted benefits. When data is in complicated distributions and varies widely over time, the predicted performance of linear regression is unsatisfactory such that the performance of DAFM algorithm gets worse. The contributions of this paper are summarized as follows.
We adopt a powerful time series model ARIMA to predict next s steps sensor values based on historical sensor data. The ARIMA time series model is suitable for sensor data due to the temporal correlations. Our proposed PreFU approach focuses on reevaluation when filters need updating. PreFU introduces prediction mechanism to achieve less energy consumption compared to eager filter update and lazy update policies in FILA approach. Also, compared to DAFM approach, our PreFU approach guarantees smaller mean squared error and thus can perform effectively (Algorithm 1). Instead of one-step-forward prediction of DAFM approach, we adopt adaptive s step prediction based on prediction errors. To select suitable s values based on specified sensor data, PreFU outperforms existing approaches. Extensive experiments are conducted to evaluate proposed PreFU approach by using real data traces. The results show that our PreFu approach outperforms DAFM, FILE-e, and FILA-l in terms of both energy consumption and network lifetime under single hop and multihop network configurations.
(1) top-k← Query (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) Calculate (12) (13) (14) Update-Window (15)
The rest of this paper is organized as follows. In Section 2, we discuss related work. Typical filtering methods for top-k query processing are introduced in Section 3 and our proposed PrePU algorithm is provided in Section 4. In Section 5, extensive simulations are conducted to show the efficiency and accuracy of the proposed method. Finally, we conclude this paper in Section 6.
2. Related Work
A naive implementation of monitoring top-k query is to use a centralized approach in which all sensor readings are periodically collected by the base station, which then computes the top-k results set directly. However, a wireless sensor network can be viewed as a distributed network which consists of lots of energy-limited sensor nodes, and communication cost is the main energy consumption. Therefore, there is no doubt that the centralized approach will consume extra energy because of the transmission of massive data. In order to reduce the communication cost in data collection, Madden et al. proposed an in-network aggregation technique, known as TAG [9], which keeps unavailable data from transmission compared with centralized algorithms. However, this approach incurs unnecessary updates in the network and is not really energy-efficient.
Wu et al. [6] propose FILA approach for top-k monitoring, which is to install a filter on each sensor node to filter out unnecessary data that are not contributed to final results. Reevaluation and filter setting are two critical aspects that ensure the correctness and effectiveness. When the new filters are different from the old ones maintained by sensor nodes themselves, base station needs to update them. But, when sensing values on nodes vary widely, base station needs updating filters to related nodes frequently which leads to large scales of updating cost and makes the performance of algorithm worse. Mai et al. [8] propose DAFM approach which aims to reduce the communication cost of sending probe messages in reevaluation aspect as well as the transmission cost in filter updating in FILA. DAFM approach predicts the next value of sensor nodes whose values are whether or not out of filtering windows by linear regression model. To some extent, this approach decreases the cost of filter updating. However, the sensed values are affected by various factors; the performance is worse when linear regression model was used to complicate data.
Besides these, filter-based and aggregation are two main strategies at present that they cope with each other to process top-k query in wireless sensor networks. Chen et al. propose QF (quantile filter, QF) [10] approach which treats sensing values and its sensor as a point. A top-k query is to return k points with highest sensing values. The goal of algorithm is to decrease energy consumption and prolong the lifetime of network which is not only minimizing the total energy consumption but also consuming less energy on each node. Liu et al. [11] propose a new cross pruning (XP) aggregation framework for top-k query in wireless sensor networks. There is a cluster-tree routing structure to aggregate more objects locally and a broadcast-then-filter approach in the framework. In addition, it provides an in-network aggregation technique to filter out redundant values which enhance in-network filtering effectiveness. Abbasi et al. [12] proposed MOTE (model-based optimization technique) approach based on assigning filters on nodes by model-based optimization. Nevertheless, it is an NP-hard problem on how to get optimal filter settings for top-k set.
In addition, there are other related works about how to process top-k query in wireless sensor networks. Yeo et al. propose a novel technology called PRIM (priority-based top-k monitoring) which relied on the semantic of top-k query [13]. Its basic idea is to gather data according to priority; that is to say, the higher readings are collected earlier. Cho et al. propose POT algorithm (partial ordered tree) which considers the space correlation to maintain k sensor nodes with highest sensing values [14]. Michel et al. propose a framework KLEE to process top-k query [15] which allows for trade-off efficiency against result quality and bandwidth saving against communications. Different from the above, Silberstein et al. propose a sampling-based approach to evaluate approximate top-k queries in wireless sensor networks [16].
Energy-efficiency is a critical issue in wireless sensor networks and also an important indicator to evaluate the effectiveness and practicality of algorithm. In recent years, some researchers introduced time series models to wireless sensor networks. Tulone and Madden [17] apply autoregressive models to data collection in wireless sensor networks. The basic idea is to build a model on base station and each sensor node. When base station predicts the values of nodes until outlier readings produced, the nodes send sensing readings to base. When a reading is not properly predicted by the model, models are relearned to adapt changes. They are approximate readings collected by the approach. [18] is similar to [17]; both of them are approaches based on time series predicting in wireless sensor networks. The main difference is that the previous one is based on ARIMA. Although time series have been applied to wireless sensor networks, they just utilize to minimize energy consumption on data collection, not applied to top-k query processing. In this paper, we propose a novel top-k monitoring algorithm PreFU that combined the time series model ARIMA with FILA approach which avoids unnecessary filter updating cost and minimizes sensor node energy consumption.
3. Filtering Method for Top-k Query Processing
A typical system architecture of a wireless sensor network includes a base station and a number of sensor nodes. The base station has enough energy while sensor nodes are powered by batteries and energy-limited. When the base station is beyond a sensor node's radio coverage, data are sent to base station via other sensor nodes through multiple jumps. Otherwise, sensed data are sent to base station directly.
Sensor nodes sense the physical phenomenon at a fixed sampling rate, such as temperature, humidity and light. When receiving the top-k query request, base station starts query and returns the results set to users at regular intervals. Assume that the sensed value on node
Initially, after collecting the readings from all sensor nodes, the base station sorts the readings and gets the initial top-k result set. The base station computes a filtering window
In order to ensure the correctness of the algorithm, the space which is formed by all filtering windows should be continuous; that is, we set
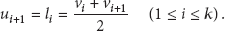

To maximize the filtering capability, the upper bound of top-1 is set to
To some extent, FILA avoids redundant data from transmission and saves energy. However, there is massive unnecessary energy consumption. Assume that, after sampling in epoch t, the filtering windows are shown in Figure 2.

Fluctuation of
In Figure 2(a), at epoch
In addition, from Figure 2, the values on the nontop-k vary in a small range, their filtering windows are useful to filter out irrelevant sensor nodes. However, the upper bound of nontop-k nodes is determined by the values of kth and
Inherent defects of FILA and DAFM need better mechanisms to avoid too much communications while updating windows. So, we propose a new updating algorithm PreFU based on prediction by autoregressive integrated moving average (ARIMA) models. The algorithm evaluates the possible communication cost based on the s-step-ahead predicted values; usually s is smaller than 10. Then, the base station decides whether or not to update relevant filtering windows.
4. PreFU Approach
In FILA, when setting of the new filtering windows for nodes is changed after reevaluating the top-k results, the filters on the nontop-k nodes are affected, and the frequent fluctuation of data will lead to unnecessary communication cost on updating windows. Considering two aspects above, by updating approach based on prediction, the algorithm decides whether to send the new filtering window parameters to corresponding nodes. In fact, we could not get the exact future values for each sensor node, but it can be obtained by prediction. In this paper, our PreFU approach predicts the next value(s) by ARIMA models.
4.1. ARIMA Model
ARIMA is a time series predicted model which predicts the next value(s) according to historical data. A typical ARIMA model consists of three components: AR (auto regressive), I (the integrated), and MA (moving average). AR is a linear regression of the current value of the time series against one or more prior values of the series, which captures the relationship between current value and the latest p historical values. If there is a time series

Equation (2) is an autoregressive model and p is the order of the model. The parameters of the model are
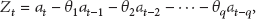

4.2. Time Series Model-Driven Prediction
Prediction by ARIMA model usually consists of two steps. The first step is model identification and parameter estimation. The second is prediction.
4.2.1. Model Identification and Parameter Estimation
Each parent node builds an ARIMA model to predict the next threshold
In order to get p and q, we introduce function of self-correlation (ACF) and partial autocorrelation (PACF). Self-correlation describes the simple correlation between values in time series. If

T is the number of samples; l is the distance of interval; in general,
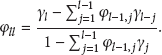
We can get the estimated values of p and q according to PACF and ACF. That is, the sample PACF cuts off at lag p. As for q, we can get it by ACF. For a time series


After order determination of the ARMA model, we estimate parameters
4.2.2. Predicting
As illustrated by (1) in Section 4.2, suppose that we are at time epoch h; Z is a time series formed by previous epoches just before h; one-step-ahead predicted value
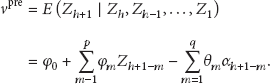
4.3. Evaluation of the Cost
Predicting the next s values for each node in
Let



If the value of the sensor node
In our PreFU algorithm, if the base station updates the filters to nodes, the cost is composed of two aspects: the cost of updating the new filters and the cost of sending the updated values violating the filters at the next s step sampling to base station, denoted as
5. Experiments
5.1. Experiment Settings
We evaluate the performance of the proposed algorithm PreFU by MATLAB simulations. The experimental data is from Intel Lab [19]. We adopt temperature, humidity and light data on March 1st, 2004, as experimental data. The data were collected from 54 sensor nodes, and data are collected every 31 seconds. In the paper, we treat the average of every two sample values as one.
We compare our proposed PreFU algorithm with FILA-E, FILA-L, and DAFM under uniform filter setting [6] for each window. We view the times of communication for a top-k query as the measurement with different k. Considering that the energy consumption of sending is different from receiving, we simulate Mica2Dot sensor node which the energy consumption of sending is 0.37 times of receiving in this paper. The network lifetime is defined as time duration before the first sensor node runs out of power [6]. We adopt 2 AAA batteries with 15120 J for total energy capacity while the energy to establish a connection is 0.645 J and sending a byte data consumes 0.0144 J.
5.2. Experiment Results
5.2.1. Comparison of Prediction Performance in Different Models
We learn the ARIMA(2,0,2) utilizing historical data in the experiment. The parameters on different nodes are maintained by the base station dynamically. Figure 3 shows the predicted performance comparison of two models for s-step-ahead predicting. The prediction performance of ARIMA models is prior to linear regression model. Using ARIMA model to predict, the error rate is much smaller than linear regression model when

Error comparison of LR and ARIMA models.
5.2.2. Comparison of Four Algorithms in Different Network Structures and Data Distributions
First, the different network structures may affect the performance of algorithm. We evaluate the effectiveness of algorithm based on single-hop and multihop networks as shown in Figure 4 (the hop number is 2). Second, the different data distributions have affected the performance of algorithm. We evaluate the algorithm using following sensor attributes temperature, humidity, and light in different network structures to illustrate the efficiency of the proposed algorithm. Figures 5 and 6 show the results of our proposed algorithm and existing algorithms in different network structures and data distributions.

2-hop structure for Intel Lab sensors.

Comparison of different approaches for top-k query processing on Intel Lab data (single hop).

Comparison of different approaches for top-k query processing on Intel Lab data (multihop).
As shown in Figures 5 and 6, under two possible network structures single-hop and multihop and three different data temperature, humidity, and light, the proposed PreFU algorithm is prior to existing algorithms. Take Figure 5(b) as an example, when
5.2.3. Comparison of Lifetime under Different Approaches
We now consider the lifetime of DAFM, FILA-E, FILA-L, and our PreFU approaches under single-hop (Figure 7) and multihop (Figure 8) network distributions. In Figure 7, our PreFU approach is prior to other three approaches under temperature and humidity data. When k is small, our approach performs much better. However, under light data, when k is small, our PreFU approach is worse than DAFM approach. The reason is that light changes rapidly in real world and one-step-prediction will be better under small k values. When k increases, we should consider more sensor nodes as top-k results, our proposed PreFU approach performs better. In Figure 8, the same situation occurs and the reason is the same as above.
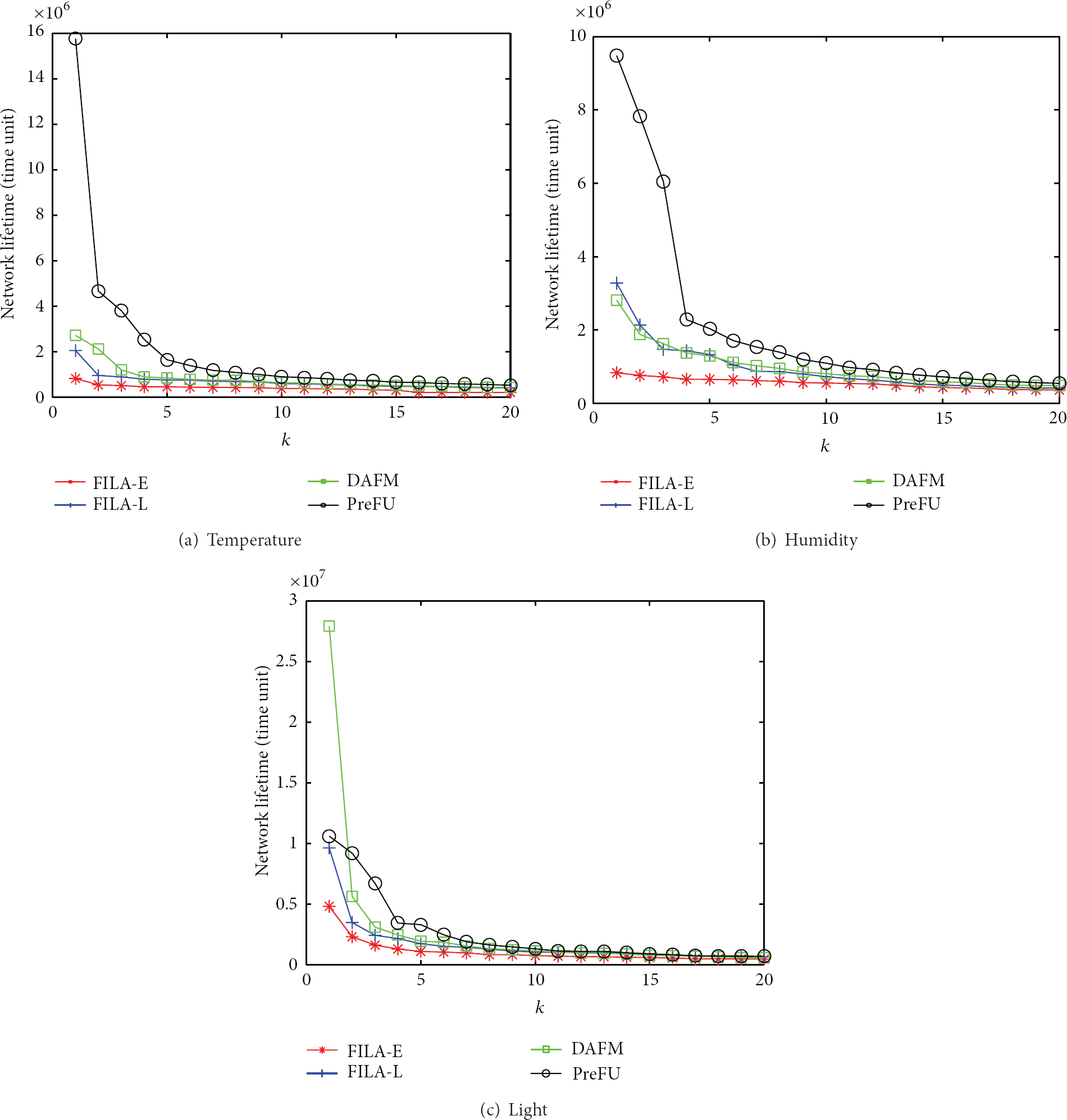
Comparison of lifetime for top-k query processing on Intel Lab data (single hop).

Comparison of lifetime for top-k query processing on Intel Lab data (multihop).
6. Conclusion
In order to cope with the problem that there is unnecessary updating cost in top-k query processing, we propose a new top-k query algorithm called PreFU which is based on time series prediction models. The algorithm evaluates the cost of updating the filters based on ARIMA prediction models which is built on the historical sensor data. Our PreFU reduces the energy consumption and prolongs the life of network by avoiding unnecessary updating of filtering windows. The extensive experiments demonstrate the correctness and effectiveness of the proposed PreFU approach compared with FILA-E, FILA-E, and DAFM approaches.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by National Program on Key Basic Research Project of China (973 Program) under Grant no. 2014CB744900, the Fundamental Research Funds for the Central Universities of China under Grant no. NZ2013306, the Ph.D. Programs Foundation of Ministry of Education of China under Grant no. 20103218110017, Aeronautical Science Foundation of China under Grant no. 20115552030, and NUAA Research Funding of China under Grant NS2013089. The authors would also thank the reviewers for their helpful comments and advices to improve the presentation of the paper.