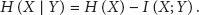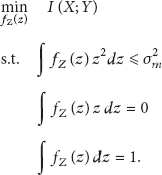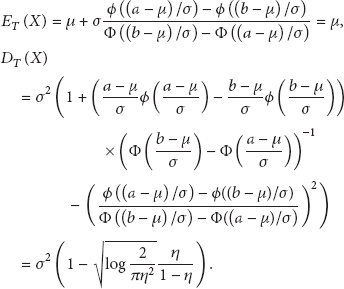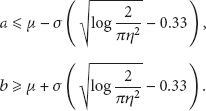In emerging mobile aggregation applications (e.g., large-scale mobile survey), individual privacy is a crucial factor to determine the effectiveness, for which the noise-addition method (i.e., a random noise value is added to the true value) is a simple yet powerful approach. However, improper additive noise could result in bias for the aggregate result. It demands an optimal noise distribution to reduce the deviation. In this paper, we develop a mathematical framework to derive the optimal noise distribution that provides privacy protection under the constraint of a limited value deviation. Specifically, we first derive a generic system dynamic function that the optimal noise distribution must satisfy and further investigate two special cases for the distribution of the original value (i.e., Gaussian and truncated Gaussian distribution). Our theoretical and numerical analysis suggests that the Gaussian distribution is the optimal solution for the Gaussian input and the asymptotically optimal solution for the truncated Gaussian input.
1. Introduction
With the advance of information age, data aggregation has been widely used in daily life and commercial applications. Even some companies such as Canalys make a living from providing all kinds of statistics. In aggregation applications the server wishes to distill valuable aggregate statistics from a mass of individual data. For example, CarTel [1] learns the traffic condition from the road information collected by mobile phones. BikeNet [2] measures air and road condition to guide cyclists, where all the data is contributed by users' devices.
However, the individual privacy may be violated during the aggregation. The server is able to obtain the individual data of participants from inputs. Nevertheless, much of this information is private for individuals, such as health condition and income, especially in the presence of curious server or data abuse. Actually the server only needs to know the aggregate result without knowing the individual data. Thus, in aggregation applications, calculating the aggregate statistics without compromising individual privacy is an important challenge.
Secure Multiparty Computation (SMC) is a good choice to solve this problem. It usually uses cryptographic methods, doing operations on ciphertext domain. However, it also has many limitations. Firstly, because of the huge overhead, SMC is not suitable for large-scale systems. Secondly, most of SMC methods need collaboration of parties, which is not suitable for some circumstances where collaboration is not easy (e.g., in wireless network, the node may not connect with others at all times). Thirdly, both encryption/decryption and communication are high-power consumption operations, which limit SMC deployed in energy-sensitive devices (e.g., sensor or phone). Therefore, SMC is not suitable for the large-scale energy-constraint environments such as large-scale mobile survey applications. Furthermore, brute force attack is powerful to cryptographic methods if the plaintext space is small. Some of the methods such as [3] get the aggregate result based on this property. On the contrary, noise addition, which prevents the adversary from getting the accurate individual data values, is a simple but effective method. Compared to SMC, it is much simpler and efficient, especially in this environment. Without collaboration with others, each participant only adds noise into his data independently before updating. However, in this method, how to choose the noise distribution is a headache. Improper additive noise could result in bias for the aggregate result. It demands an optimal noise distribution which provides the best protection to individual privacy while the aggregate result has tolerable bias. However, the optimal noise distribution is not evident. Usually the noise distribution is proposed directly (usually homogeneous noise or Gaussian noise) without any explanation.
In aggregation applications the accuracy of result and the privacy of individuals are two main concerned issues. Our goal is to find out the optimal noise distribution in noise addition method, where the individual privacy is protected best under the given accuracy requirement. The main contributions of this paper are as follows.
We formulate the accuracy and privacy metrics by mean and variance and mutual information, respectively, which are the foundations for choosing proper noise distribution.
Based on the accuracy and privacy metrics, we develop a mathematical framework to derive the optimal noise distribution.
We get the generic system dynamic function that the optimal noise distribution must satisfy, where the input is the distribution of original individual data.
We solve the problem for two input cases. For the Gaussian input, we get the theoretical optimal solution. For the truncated Gaussian distribution input, firstly we point out when it can be approximated by Gaussian distribution, so that the solution of the Gaussian distribution input can be employed directly. Then for the arbitrary truncated Gaussian input, we point out Gaussian distribution is the asymptotically optimal solution.
The rest of the paper is organized as follows. Related work is introduced in Section 2. We formulate the problem in Section 3. In Section 4 we give the general solution and investigate the Gaussian input. In Section 5 the truncated Gaussian input is analyzed in the details. In Section 6 we numerically verify the conclusions and compare the privacy-preserving capability of three proposed noise distributions. At last the paper is concluded in Section 7.
2. Related Work
SMC enables parties to calculate the result by collaboration based on their own data without compromising others' privacy. However it has lots of limitations. In [4] a secure sum protocol was depicted, where the summation is calculated serially which would spend too much time in large-scale systems. Another protocol [3] was proposed, which allows the untrusted server to calculate the summation. It requires that the sum of the keys of parties is . If one of the partiez leaves in the process, which is a common case in large-scale systems, the summation cannot be calculated. Jung et al. [5] proposed a linear time protocol without secure channel, but it still needs lots of communications among parties. Meanwhile, in these methods each party has to communicate with others and do lots of mathematical operations, both of which are high-power consumption operations. Although CPDA [6] reduces the communication overhead of SMC for wireless sensor networks, it is still much more complex than other methods. So SMC is not suitable for energy-constrained devices.
In ad hoc network, some other methods are exploited to protect the privacy during data aggregation while trying to reduce the energy cost. A cryptology-based aggregation approach is proposed in [7], which leverages a simple secure additively homomorphic stream cipher, but it requires that all the nodes must share their keys to the sink node, so that the sink node could decrypt the encrypted aggregate result. In SMART [6], the original data is sliced into several pieces and recombined randomly. This method calculates the summation securely, but the communication cost rises several times. GP2S [8] is based on the data generation. It replaces the original data by an integer range, by which the data collector plots the histogram without the accurate original value. However, the summation calculated by the histogram is not accurate.
Noise addition has been studied for many years in secure data mining [9]. It prevents the adversary from getting the accurate individual data values. Plenty of schemes are proposed to preserve the privacy of individual records. Most of them such as [10, 11] are not claimed whether their methods are optimal. Furthermore, they utilize the covariance of data in the database, which needs the party who adds the noise to know the global information of data. In some schemes the noise is added without concerning the covariance of the data, but the uniform distribution or Gaussian distribution is directly declared [12, 13]. In [14] the authors considered the optimal randomization given the bias of results, but they did not solve it. Meanwhile, some researchers [12, 15] found the original data distribution can be restructured by perturbed values, but the individual privacy is not violated yet. To the best of our knowledge, there is no work completely focusing on the optimization of the noise addition scheme.
There are several different measures of privacy. In [12] the privacy is measured by “confidence interval.” If the data concerned x is in the interval with at least certain probability , the length of interval is treated as a privacy measure. However, this measure is not accurate. Mutual information or differential entropy in Shannon's information theory is another much more popular privacy metric [15]. It indicates the average privacy supporting by mathematical theory. Renyi entropy (an extension of Shannon entropy) is also used to measure privacy [16], but it is too complex and does not have obvious physical meaning.
In recent years differential privacy [17] is a hot noise addition technology protecting the individual privacy in data mining. It guarantees the accuracy of statistical result while avoiding individual record disclosure. Ghosh et al. [18] found out the optimized noise distribution that provides most accurate result under the given privacy requirement. However, differential privacy is against the adversary that obtains individual record from different statistic results. In our situation, the adversary can get the individual records directly, and we only focus on one aggregation process.
3. Problem Formulation
In this section, firstly we introduce some aggregation applications where the violation of individual privacy potentially exists and noise addition method is appropriate. Then we quantify the accuracy and privacy requirements. Finally, based on the measurements the optimization problem is presented.
3.1. Applications
The individual privacy is potentially threatened in statistics aggregation applications. There are many examples, including
sensor network aggregation; in sensor network applications, many energy-constrained sensors are widely deployed to monitor the surrounding environment and send data to the central server for aggregation. However, the data from individual sensor may contain privacy-sensitive information, especially if the sensors are deployed in personal space, confidential institution, or across multiple companies. So energy-efficient privacy protection in aggregation is an important issue;
mobile survey applications; in these applications, tens of thousands of participants exist and the phones are energy-constrained. The overall results are distilled from a large amount of individual information collected by mobile phones. However, the individual privacy may be violated during information collection.
In these large-scale energy-constrained applications, the server should know the aggregate results, which are distilled from the information of individuals. However, the individual privacy may be violated during the collection. Noise addition technology, which protects the individual privacy by adding noise into the individual data, is a simple but efficient method in these applications, where it can be employed independently by individual devices without collaboration and the operations are energy-efficient compared with SMC. To describe the problem more accurately, in the following we formulate the problem in mathematical way.
3.2. Accuracy and Privacy Measurement
Suppose that there are n users with values , , and a server calculating aggregate statistics. In this paper, we mainly focus on a simple but common statistic problem called summation. The server processes the aggregation function . Of course there are several other aggregation types. Besides summation, Popa et al. [19] list other classes such as average, standard deviation, and count. All of them can be constructed by summation, as outlined in Table 1.
Aggregation function list.
Aggregation function
Construction with summation
Count:
The value of each individual is
Average:
Standard deviation:
There are two parties threatening the individual privacy. One is the server, who would get the individual data by aggregation. The other is the eavesdropper, who could capture the packets from the participants to the server. Both of them (named attacker) can get the individual value, which is regarded as the individual privacy.
To protect the individual privacy in the process of aggregating statistics, user adds random noise into his/her true value. Instead of , contributes the perturbed value to the server. The information that the attacker knows most is all the perturbed values and the scheme by which the noise is generated. So we suppose the attacker knows and the distributions of and . He tries to get based on the information he knows. The aim of the noise is to prevent the attacker from getting the accurate true value.
Obviously different noise distributions have different privacy protection capability. To protect the true value, how to choose a good noise distribution is the key issue. Noise is a random variable with the probability density function (pdf) . To meet the requirements of accuracy and privacy, should satisfy
accuracy requirement; the difference of and is small;
privacy requirement; the confusion of the true value is evident.
The first requirement guarantees that the aggregate result does not deviate from the true result too much. The second one guarantees the individual privacy is not violated. If the attacker gets the user's value, he still doubts it because of the existence of noise.
3.2.1. Accuracy Measurement
For accuracy requirement, we define the difference
where n is the number of participants. Ideally is constantly equal to zero, but it is impossible. Due to the fact that are random variables, also is a random variable, with the expectation and the variance . are independent, where has the expectation and the variance , respectively. If they satisfy Lindeberg's condition [20], obeys Gaussian distribution regardless of the distributions of individual noise. It is only decided by the expectation and the variance; that is, and . We try to keep small with high probability. It requires and is small. Therefore, we quantify the accuracy requirement as
with an additional condition . It measures the average deviation tolerance of the perturbed result from the true result. Suppose that are independent and identically distributed random variables with the expectation and the variance . The accuracy requirement U is simplified as
with .
U measures the average deviation tolerance of the perturbed result from the true result by the variance of the noise distribution. If two zero-mean noise distribution and satisfy , it means that guarantees the accuracy of result better.
3.2.2. Privacy Measurement
Consider
where Y, X, and Z are random variables which delegate perturbed value, true value, and noise, respectively. Z is independent of X. Suppose that the adversary knows the distribution of Z. It is reasonable that any user including malicious user knows it to generate noise. Because of the perturbation of noise z, the adversary is uncertain about x when he gets y. We use Shannon's information entropy to measure the uncertainty. Suppose that the adversary gets , the uncertainty of X is measured by . The larger is, the better the privacy protection is provided at .
For different y, is different. We use the average to quantify the privacy protection strength (denoted by V) of the noise; that is,
denotes the average uncertainty of the true value when the perturbed value is captured. The larger V is, the higher the average uncertainty is.
Generally speaking, for noise addition technology, the accuracy and the privacy are in contradiction. High accuracy leads to low privacy protection strength, and vice versa. However, for a given accuracy level, different usually has different privacy protection capability. Thus how to optimize the noise distribution that provides the best privacy protection under the accuracy constraint is the key problem.
3.3. Optimization Problem Formulation
For convenience, in the following we consider the continuous distributions. The discrete distribution can be regarded as the approximation of the corresponding continuous distribution. Consider the formulation , where X and Z are random variables with pdf and pdf , respectively. We will find the optimal providing the best privacy protection while guaranteeing that the result has an acceptable deviation; that is, . Consider the optimization problem
where is the accuracy requirement bound required by applications.
Consider
Since is deterministic, is a constant. Thus the optimization problem is translated to
4. Problem Solution
To solve the problem proposed in the above section, firstly we investigate the general solution. Then for the special case that the original data obeys Gaussian distribution, the further result is shown.
4.1. General Solution
To solve problem (8), firstly we consider a more general problem
where . If Z is independent of X, we have
The constraints become
This problem is translated to problem (8). In other words, the problem (8) is a special case of problem (9).
The mutual information is
where .
We use the method of Lagrange multipliers to find the solution. Set up the functional
Differentiating with respect to , we have
Setting and ,
Thus
Here we get the expression of . In problem (8), and Z is independent of X. From (16),
Z and X are independent; for any x, is unchangeable. can be calculated by fixing x (e.g., ). So is simplified as , where λ, , and are constants for fixed . For convenience, and are abbreviated as ω and C. Therefore, we have the following theorem.
Theorem 1.
Given the accuracy requirement , the noise providing the best privacy protection has the pdf
where , and λ, ω, and C are related to the constraints , , and , respectively.
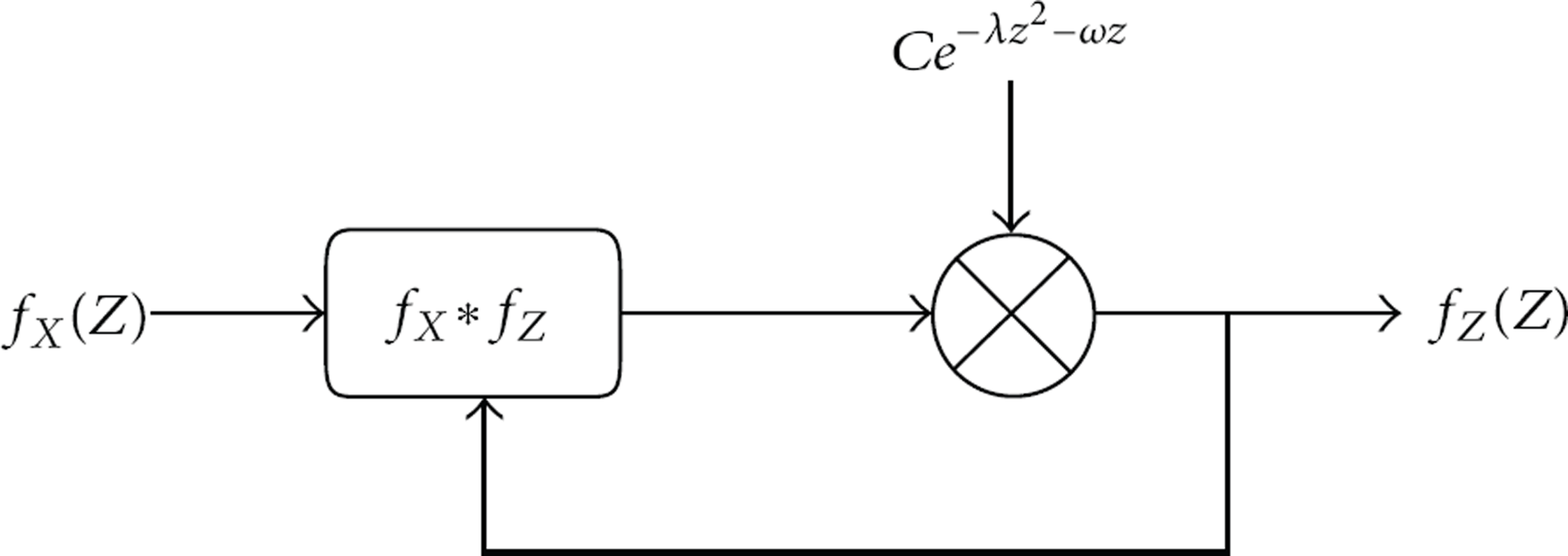
Based on the theorem the corresponding system diagram is constructed in Figure 1, where is the input and is the output. The system contains two operations. One is convolution of the input and the output. The other is multiplication of the convolution result and the factor “.”
The system diagram.
From the theorem and system diagram, the optimal noise distribution is determined by the distribution of the original value. Therefore, for different aggregation application, the optimal noise distribution may be different.
is a convex function of in problem (9) [21], so problem (8) also is a convex optimization problem. The constraints satisfy the sufficient conditions of KKT approach (inequality constraint is a continuously differentiable convex function; the equality constraints are affine functions [22]). If we find one satisfying (18), it is the global optimal solution. So given the distribution of original value , we only try to find a solution for (18), that is, the optimal noise distribution.
4.2. Gaussian Distribution Input
Generally for different input , the output is different. We consider a special but popular case that X follows Gaussian distribution.
When , it is easy to check that is a solution of (18), where
Thus is the solution of problem (8), where . Therefore we have the following theorem.
Theorem 2.
When X obeys Gaussian distribution, the noise which obeys Gaussian distribution with the expectation and the variance protects the individual privacy best.
5. Truncated Gaussian Distribution Input
In practice, X usually has maximum and minimum bounds. For example, the person's height has a maximum bound and is not less than . The examination score usually is in . So we consider the truncated Gaussian distribution in the range . In Section 5.1 we investigate the condition that the truncated Gaussian distribution can be approximated by Gaussian distribution, so that Theorem 2 can be applied directly. In Section 5.2 we revise the condition, making it much more accurate. However, not all the truncated Gaussian distribution can be approximated by Gaussian distribution. In Section 5.3, for the arbitrary truncated Gaussian distribution we find Gaussian distribution still is a nearly optimal noise distribution.
5.1. Approximation Condition
We use the metric [15] to measure the difference of two distributions, where
This difference metric measures the overlap of the two distributions, which lies in the interval . The smaller is, the more overlap the two distributions have, and the more similar they are. implies that the two distributions are exactly the same, while means there is no overlap between them.
Suppose . is a pdf of the truncated Gaussian distribution over ; that is,
where is the cumulative distribution function of the standard normal distribution.
When , can be approximated by , where
This metric is equivalent to Kullback-Leibler divergence , where
is the increasing function of , so the two metrics are the same.
Since , we have and . So satisfies
Given , there is lower and upper bounds for , that is, < . When , . Thus
When , . So
Therefore, given the bound of the difference metric , . For (24) and (26), the range satisfies
If , the length of is
For a fixed η, from , we get the minimum as
where
In this case . The expectation and the variance of are
Since , .
Therefore, given the difference bound , if the range of follows the condition (27), can be approximated by . The corresponding optimal noise distribution is Gaussian distribution. In particular, if , the condition can be simplified as (30).
By the analysis in this section, for an aggregation application where the original value obeys the truncated Gaussian distribution, if the distribution satisfies condition (27) or (30), it can be approximated by Gaussian distribution, where Theorem 2 can be used directly.
5.2. Approximation Amendment
From the analysis of Section 5.1, when reaches the minimum, . Thus the exact (calculated by (24)) is
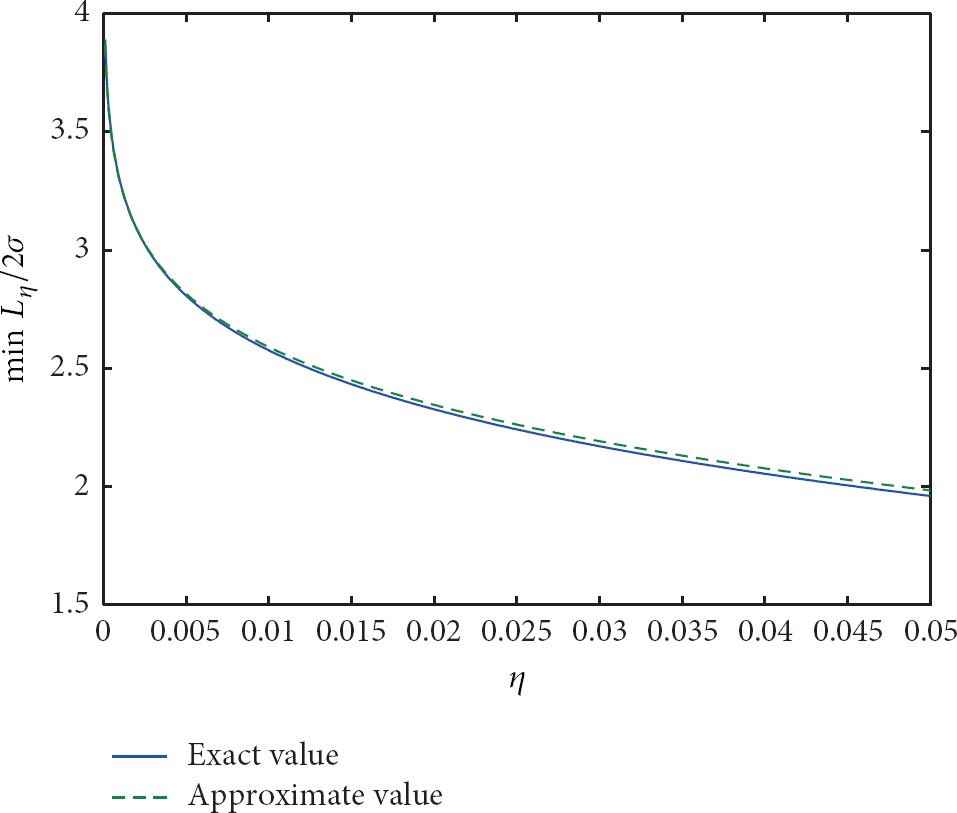
Equation (29) is the approximate , from which . Figure 2 shows the relationship between minimum length of and η. The smaller η is, the larger is. However, from the figure biases exist between the approximate method and the exact one. The reason is that (29) is based on (26), which contains the approximation that . However, in practice the difference is not large enough, so the bias exists.
The ratio of minimum length of to for difference bound η before amendment.
In order to reduce the bias, we revise the condition. Based on (32) without the above approximation, from (25) we have
Here, and are exact value and approximate value, respectively. Consider (which is reasonable that if η is too large, the approximation using normal distribution is useless, while if η is too small, it is hard to find out such a in practice), is in the range . Thus is in the range . Thus (29) can be revised as
The effect of revision is illustrated in Figure 3, where approximate result is almost the same as the exact one.
The ratio of minimum length of to for difference bound η after amendment.
5.3. Arbitrary Truncated Gaussian Distribution Input
In the above analysis, when the truncated Gaussian distribution can be approximated by Gaussian distribution, Theorem 2 can be used directly. However, not all the truncated Gaussian distribution can be approximated by Gaussian distribution. The truncated Gaussian distributions with the variance and the expectation are in quite a variety of shapes, which are decided by the range , where . Specially, when converges to infinity, the truncated Gaussian distribution becomes Gaussian distribution. When equals , the truncated Gaussian distribution becomes homogeneous distribution. If the truncated Gaussian distribution cannot be approximated by Gaussian distribution, does remain the optimal noise? Unfortunately, Gaussian distribution is not the solution of (18); that is, Gaussian distribution is not the optimal noise distribution. However, if makes so small that the difference to the minimum is small enough, it is still a good choice.
Theorem 3.
Suppose that X obeys the truncated Gaussian distribution over with the variance and the expectation . in problem (8) is only determined by and .
Proof.
Suppose that two random variables and follow the truncated Gaussian distributions and , respectively, where is over with the variance and the expectation , is over with the variance and the expectation , and . The expectation only decides the position of the function in coordinate system. It has no effect on entropy and mutual information. For convenience, we suppose that the expectations of two functions are 0 (i.e., ), so . Next, we will prove , where and are random variables with the variances and (k is a positive number)
Set . On one hand, for any , there is . On the other hand, for any , there is . Thus a one-to-one mapping exists between and .
Consider the two functions (37) and (38). Denominators are equal to each other denoted by M. For any in and ,
Thus ,
So .
For any , the pdf of which is with the expectation and the variance , we can find with pdf which satisfies . has the expectation and the variance . There is a one-to-one mapping between and . Thus for any for , we have corresponding for .
The entropy satisfies
Supposing that with pdf and with pdf ,
Similarly,
Since Z and X are independent,
Suppose that minimizes ; the corresponding minimizes too; otherwise we can find another that makes smaller. In the above analysis, we only have the constraint that . In problem (8) actually is the variance of optimal . In this proof we have an implied condition that when satisfies the variance condition for (), satisfies it too for (). Since , . Therefore when and are fixed, the minimum of is a constant.
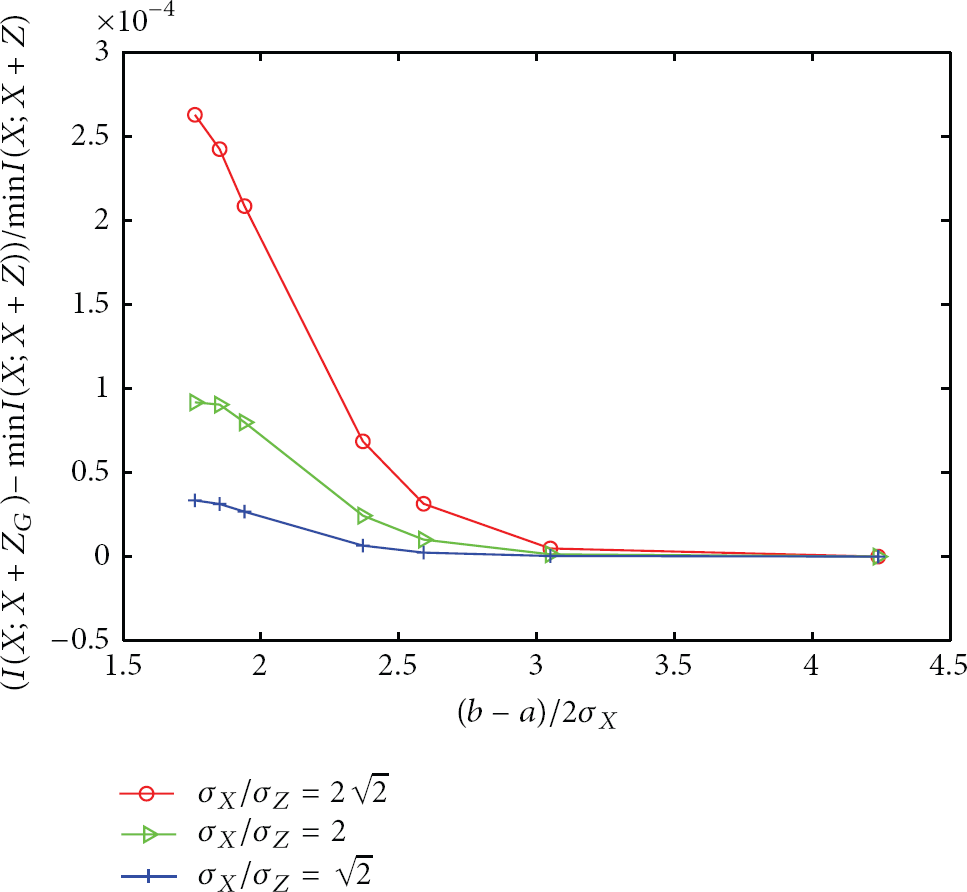
From Theorem 3 the optimal solution is only determined by , , and . To see the performance that noise obeys Gaussian distribution, the difference between and is shown in Figure 4, where obeys Gaussian distribution. From the figure, we find that although Gaussian distribution is not the optimal noise distribution, the deviation to the optimal solution is small. In particular, when is larger than , the bias is very close to . For example, when is , and are and , and , and and . That is because in this case is much like Gaussian distribution. When is close to , is approximated to homogeneous distribution. The results remain good. For example, when is , and are and , and , and and . Thus although Gaussian distribution is not the optimal noise distribution when X follows the truncated Gaussian distribution, it is a nearly optimal noise distribution.
The difference between and where obeys Gaussian distribution. and are the variances of X and Z, respectively.
6. Numerical Simulation
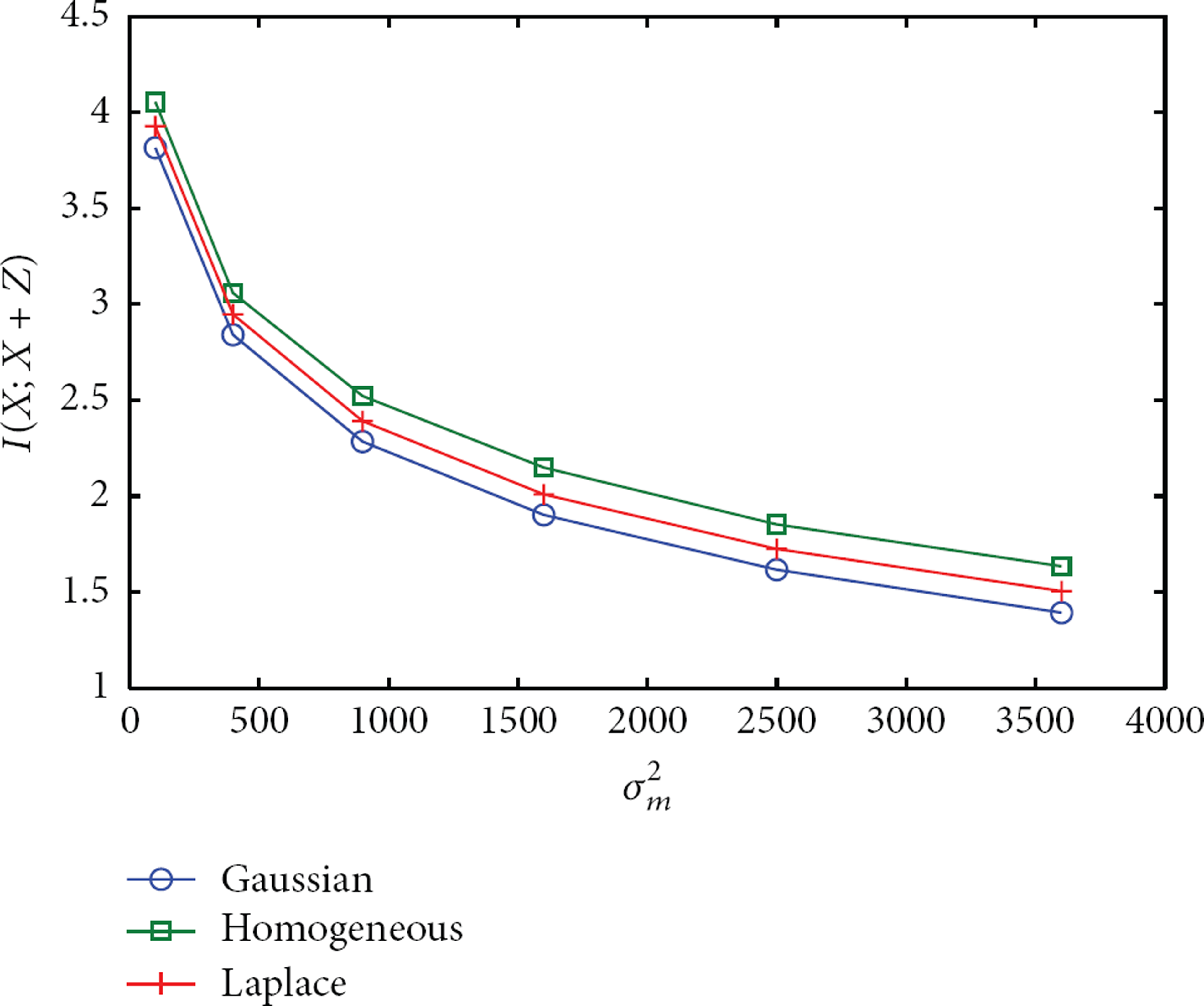
From Theorem 2, when the original value obeys Gaussian distribution, the optimal noise distribution is Gaussian distribution too. Besides Gaussian distribution, homogeneous distribution (e.g., [12]) and Laplace distribution (e.g., [17]) are also used in noise addition method. Figure 5 shows the privacy-preserving capabilities of these three noise distributions, where is a Gaussian distribution. From the figure, we could find that the mutual information, which measures the privacy protection strength, is the smallest with the Gaussian noise. It means that by adding Gaussian noise, the attacker gets the least information of the true value from the perturbed value. Meanwhile, from the figure, the information leaks less with the increase of the accuracy requirement bound .
Compare the privacy-preserving capabilities of Gaussian distribution, homogeneous distribution, and Laplace distribution, where is Gaussian distribution with the variance .
Figure 6 illustrates the privacy-preserving capabilities of Gaussian distribution, homogeneous distribution, and Laplace distribution when is a truncated Gaussian distribution. Here we choose as an example, which is in the range of . From the figure, Gaussian noise is still the best one to protect the individual privacy. The difference to the optimal noise distribution has been shown in Figure 4, from which we find when the original value obeys the truncated Gaussian distribution, Gaussian distribution is still a good noise distribution.
Compare the privacy-preserving capabilities of Gaussian distribution, homogeneous distribution, and Laplace distribution, where is the truncated Gaussian distribution .
7. Conclusion
In this paper, we quantify the accuracy of result and the privacy of individuals. Based on the metrics, we propose the optimization problem, finding out the optimal noise distribution that provides the best privacy protection while maintaining the acceptable deviation from the accurate result. For the special cases that the original data of individuals follows Gaussian distribution and the truncated Gaussian distribution, Gaussian distribution is the optimal distribution and the asymptotically optimal one, respectively.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by National Natural Science Foundation of China under Grant no. 61371192, National Natural Science Foundation of China under Grant no. 61271271, 100 Talents Program of Chinese Academy of Science, the Strategic Priority Research Program of the Chinese Academy of Sciences under Grant XDA06030601, and the Funding of Science and Technology on Information Assurance Laboratory under Grant KJ-13-003.
References
1.
HullB.BychkovskyV.ZhangY.Cartel: a distributed mobile sensor computing systemProceedings of the 4th ACM International Conference on Embedded Networked Sensor SystemsNovember 2006
2.
EisenmanS. B.MiluzzoE.LaneN. D.PetersonR. A.AhnG.-S.CampbellA. T.BikeNet: a mobile sensing system for cyclist experience mappingACM Transactions on Sensor Networks200961, article 62-s2.0-7514916567710.1145/1653760.1653766
3.
ShiE.ChanT.-H. H.RieffelE.ChowR.SongD.Privacy-preserving aggregation of time-series dataProceedings of the Network and Distributed System Security Symposium (NDSS '11)February 2011
4.
CliftonC.KantarciogluM.VaidyaJ.LinX.ZhuM. Y.Tools for privacy preserving distributed data miningACM SIGKDD Explorations Newsletter2002422834
5.
JungT.MaoX.LiX.-Y.TangS.-J.GongW.ZhangL.Privacy-preserving data aggregation without secure channel: multivariate polynomial evaluationProceedings of the IEEE Conference on Computer Communications (INFOCOM '13)April 201326342642
6.
HeW.LiuX.NguyenH.NahrstedtK.AbdelzaherT.PDA: privacy-preserving data aggregation in wireless sensor networksProceedings of the 26th IEEE International Conference on Computer Communications (INFOCOM '07)May 2007204520532-s2.0-3454830195310.1109/INFCOM.2007.237
7.
CastellucciaC.MykletunE.TsudikG.Efficient aggregation of encrypted data in wireless sensor networksProceedings of the 2nd Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services (MobiQuitous '05)July 20051091172-s2.0-3374952520910.1109/MOBIQUITOUS.2005.25
8.
ZhangW.WangC.FengT.GP2S: generic privacy-preservation solutions for approximate aggregation of sensor dataProceedings of the 6th IEEE Annual International Conference on Pervasive Computing and Communications (PerCom '08)March 20081791842-s2.0-4914912569310.1109/PERCOM.2008.60
9.
AdamN. R.WortmannJ. C.Security-control methods for statistical databases. A comparative studyACM Computing Surveys19892145155562-s2.0-0024914229
10.
OliveiraS. R. M.ZaianeO. R.Privacy preserving clustering by data transformationProceedings of the 18th Brazilian Symposium on Databases2003
11.
SuC.BaoF.ZhouJ.TakagiT.SakuraiK.A new scheme for distributed density estimation based privacy-preserving clusteringProceedings of the 3rd International Conference on Availability, Reliability and Security (ARES '08)March 20081121192-s2.0-4904909637410.1109/ARES.2008.129
12.
AgrawalR.SrikantR.Privacy-preserving data miningProceedings of the ACM International Conference on Management of Data (SIGMOD '00)20004394502-s2.0-0041783510
13.
Domingo-FerrerJ.SebéF.Castellà-RocaJ.On the security of noise addition for privacy in statistical databasesPrivacy in Statistical Databases20043050Berlin, GermanySpringer149161Lecture Notes in Computer Science2-s2.0-35048834229
14.
ZhuY.LiuL.Optimal randomization for privacy preserving data miningProceedings of the International Conference on Knowledge Discovery and Data Mining (KDD '04)August 2004
15.
AgrawalD.AggarwalC. C.On the design and quantification of privacy preserving data mining algorithmsProceedings of the 20th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database SystemsMay 20012472552-s2.0-0034827009
16.
RachlinY.ProbstK.GhaniR.Maximizing privacy under data distortion constraints in noise perturbation methodsPrivacy, Security, and Trust in KDD20095456Berlin, GermanySpringer92110Lecture Notes in Computer Science2-s2.0-6765028992910.1007/978-3-642-01718-6_7
17.
DworkC.Differential privacy2Proceedings of the 33rd International Conference on Automata, Languages and Programming (ICALP '06)2006112
18.
GhoshA.RoughgardenT.SundararajanM.Universally utility-maximizing privacy mechanismsProceedings of the 41st ACM Annual Symposium on Theory of Computing (STOC '09)June 20093513592-s2.0-7035068377010.1145/1536414.1536464
19.
PopaR. A.BlumbergA. J.BalakrishnanH.LiF. H.Privacy and accountability for location-based aggregate statisticsProceedings of the 18th ACM Conference on Computer and Communications Security (CCS '11)October 20116536652-s2.0-8075516944810.1145/2046707.2046781