
Abstract
This paper presents a lightweight data compression method for wireless sensor networks monitoring environmental parameters with low resolution sensors. Instead of attempting to devise novel ad hoc algorithms, we show that, given general knowledge of the parameters that must be monitored, it is possible to efficiently employ conventional Huffman coding to represent the same parameter when measured at different locations and time periods. When the data collected by the sensor nodes consists of integer measurements, the Huffman dictionary computed using statistics inferred from public datasets often approaches the entropy of the data. Results using temperature and relative humidity measurements show that even when the proposed method does not approach the theoretical limit, it outperforms popular compression mechanisms designed specifically for wireless sensor networks.
1. Introduction
One of the greatest challenges to the construction of large scale wireless sensor networks (WSNs) with practical applicability is the development of mechanisms that allow the network to operate for prolonged periods of time relying solely on the limited amounts of energy that can be stored in or harvested by wireless sensor nodes. Since data communication is generally the main factor responsible for draining the energy reserves of the network, techniques to reduce the amount of information transmitted by the sensor nodes are of great interest. One effective approach to reduce data communication in the network is to compress the information locally before it is transmitted.
Although data compression is a well-established research area, despite the extraordinary advances in the computational capability of embedded devices, most existing algorithms still cannot be directly ported to wireless sensor nodes because of the limited hardware resources available, particularly program and data memory [1]. Even though many of the time-honored compression algorithms could be executed in modern wireless sensor nodes, they would leave few resources available for the nodes to carry out other tasks such as sensing and communication. More importantly, these nodes would have significantly fewer opportunities to enter deep sleep modes and attain the energy efficiency that motivated the use of a compression algorithm in the first place. Therefore, a number of data compression methods specifically designed for WSNs have been proposed in the past few years [2–11]. What many of these methods have in common is the fact that they make use of the correlation of the data acquired by the sensor nodes in order to achieve high compression ratios while employing computationally inexpensive algorithms.
However, WSNs are generally deployed with the purpose of monitoring a particular phenomenon of interest [12]. Therefore, we show that, if the statistics of this phenomenon are known beforehand from general datasets, and if the data collected by the sensor nodes presents relatively low resolution, by employing simple Huffman encoding, it is possible to achieve compression ratios higher than those obtained by state-of-the-art algorithms such as those presented in [2–4]. More specifically, we show that by constructing a fixed Huffman dictionary to encode the differences between two consecutive samples from a large general dataset, the compression ratio obtained on test datasets of the same phenomenon at different locations and periods is very close to what would be achieved if a specific dictionary was constructed for each test dataset.
The rest of this paper is organized as follows. In Section 2, we briefly explain some of the recent contributions on data compression for WSNs. We then describe the proposed lightweight compression method in Section 3. In Section 4, we show the results obtained with our approach and compare them with those obtained when employing the methods in [2–4]. Finally, Section 5 concludes the paper.
2. Related Work
In the literature on compression methods for WSNs both lossy and lossless approaches that exploit the high temporal correlation of the sensor node data can be found. One of the first lossy methods for data compression in WSN, lightweight temporal compression (LTC) [5], approximates the data collected by each sensor node in a WSN by a set of lines. In [6] a variation of the run length encoding (RLE) method for data compression in WSN known as K-RLE approximates a string of N measurements with values in the range
Although lossy compression methods can generally achieve high compression ratios at the expense of moderate accuracy losses, in many WSN applications it may not be clear before data collection how much information can be disregarded without compromising the overall purpose of the system. Event-based communication approaches attempt to resolve this problem by limiting the transmission of sensor data to responses to user queries [13]. However, in many cases, the user may not be able to formulate queries without observing the raw sensor data beforehand. As a consequence, a number of lossless compression methods for WSNs have been proposed. S-LZW [7] is an adaptation of the celebrated Lempel-Ziv-Welch (LZW) algorithm [14] for resource-constrained wireless sensor nodes. Alternatively, in [8] sensor measurements are coded using adaptive Huffman [15], but in order to save memory the number of symbols present in the Huffman tree is limited to the measurements that happen most frequently. In an interesting attempt to facilitate the application of data compression algorithms in real WSN deployments, a middleware layer is proposed in [9] in which only the dissimilarity between the packet to be transmitted and a previously transmitted reference (or index) packet is compressed using variable length coding.
While a number of additional works on data compression for WSNs such as [10, 11] attempt to employ distributed source coding techniques [19] to exploit the spatial correlation in the data acquired by the sensor nodes, we are particularly interested in methods that do not make any assumptions about the spatial structure of the WSN. Furthermore, in the context of data aggregation, that is, when nodes along routing paths collaborate to reduce the dimensionality of the data collected by multiple nodes, one recent and extremely promising technique is compressed sensing [20]. In this work, however, we consider approaches that attempt to achieve efficient lossless data compression by leveraging solely on the temporal correlation of the data collected by each sensor node and performing all the computations locally, without relying on information from other nodes. Two of the most recent and effective approaches in this category are Marcelloni and Vecchio's lossless entropy compression (LEC) [2, 3] and Kiely et al.'s adaptive linear filtering compression (ALFC) [4].
LEC computes the differences of consecutive sensor measurements and divides them into groups whose sizes increase exponentially. Each group corresponds to the number of bits required to represent the measurement differences. These groups are then entropy coded using a fixed compression table based on the baseline JPEG algorithm to compress the DC coefficients of an image. The compressed symbols are formed by concatenating the group number and the index of the element within the group. The authors reported high compression ratios for actual environmental data collected by WSNs.
In ALFC, an adaptive linear filter is used to predict the future M samples of the dataset and the prediction errors are compressed using an entropy encoder. In order to account for the limited computational capabilities of wireless sensor nodes, the method employs a quantization mechanism. Adaptive prediction avoids the requirement of defining the filtering coefficients a priori while still allowing the system to adjust to dynamic changes in the source. The authors showed that ALFC achieves higher compression ratios than previous methods while requiring significantly fewer hardware resources.
Although essentially all of the methods described above rely on the temporal correlation of the data collected by WSNs to achieve high compression ratios, they do not take into consideration the fact that the statistics of the phenomena to be monitored by a particular WSN are usually relatively easy to estimate before the deployment of the sensors. Furthermore, the state-of-the-art algorithms perform well when the resolution of the data collected by the sensor nodes is very high, but when the data resolution is limited to integer measurements they suffer significant performance penalties. In this work, we leverage on these facts to achieve even higher compression ratios while resorting only to traditional entropy-based compression methods with extremely modest computational requirements.
3. Lightweight Compression of Environmental Data
In this section, we define the problem of data compression in WSNs and present a simple compression approach, which takes into consideration the characteristics of the measurements acquired by the sensor nodes so that algorithmic complexity can be reduced without sacrificing compression ratios.
3.1. Problem Definition
We consider a sensor node monitoring environmental data. Let the data acquired by the sensor at time instant t be represented, after analog to digital conversion, by

where
The efficiency of a compression algorithm can be measured by comparing the average symbol length after compression to the source entropy. For instance, consider the case of a set of integer temperature measurements denoted as Set 1 in Table 1. As the measured integer temperature values range between −16∘C and +37∘C, without compression we have to use
Main characteristics of the temperature datasets, including location, temperature range, number of samples, date range when the measurements were taken, and sampling interval.

One can do much better by considering the differences of consecutive temperature measurements, so that the data to be transmitted is
By applying the method in [2] to the temperatures in Set 1 we obtain
3.2. Proposed Scheme
Our objective is to devise a simple compression method which approaches the performance of optimal entropy coding while relying on a fixed dictionary. After comparing the probability distribution of the temperatures and of the differences of consecutive temperatures for many datasets of measurements carried out at different locations, we noticed that the distributions of the differences are quite similar for all datasets, even though the distributions of the temperature values vary significantly. This can be observed in Figure 1, which shows the probability distribution of the differences between consecutive measurements for each of the datasets in Table 1. As the figure shows, all the distributions are approximately Laplacian with zero mean [22]. Since the temperature differences only assume integer values, the distributions are actually discrete and the continuous approximations are shown simply to facilitate the visualization. More importantly, note that for all datasets, if we list the differences from the most likely to the least likely, the result is

Probability distributions of the differences between consecutive measurements for each of the temperature datasets.
Thus, in this paper we propose to construct a fixed alphabet obtained by the application of the Huffman algorithm to a large dataset of temperature measurements. We consider Set 1 as our reference dataset, without any particular reason other than the fact that both the number of samples and the measured temperature range are quite large. Unlike LEC, which always uses the same alphabet, our approach uses a reference dataset to generate a dictionary for a particular parameter under observation (e.g., temperature). We compute the frequencies of each of the symbols available in the reference dataset and use them to construct the Huffman tree that represents the compression alphabet [23]. This alphabet, shown in Table 2, is then used to compress different temperature datasets. As the alphabet is fixed, the complexity of the proposed approach is rather low, being no more complex than that in [2]. For instance, an implementation of the Huffman encoding and decoding for AVR microcontrollers, widely used in sensor nodes, utilizes only 468 bytes of program memory [24]. In this work, we utilize Huffman coding due to its utmost simplicity; however, other entropy coding approaches such as arithmetic coding would likely produce similar results [25].
Proposed fixed Huffman dictionary for temperature datasets.

In the proposed compression scheme, as in any dictionary-based differential compression approach, two special cases must be considered: (i) in the beginning of data collection, the first sample,
4. Results
In this section we investigate the performance of the proposed scheme when the fixed Huffman alphabet in Table 2 is used to compress different datasets. First we consider the temperature datasets in Table 1. It is important to note that the test datasets, Set 2 to Set 9, were collected at different locations and times than those of the reference dataset Set 1, which was used to construct the alphabet in Table 2. The performance of the proposed scheme is compared to the theoretical limit given by the source entropy (considering both the temperatures and the differences of the temperatures) and to the performance of the LEC [2] and ALFC [4] algorithms. In order to meet the assumptions of the proposed method, whenever a dataset contains measurements with resolutions higher than 1°C, the data is rounded before being processed by any of the algorithms under consideration. To further validate our approach, we also carry out experiments using six datasets of relative humidity measurements. Again, a resolution of
4.1. Comparison with Lossless Entropy Compression
Figure 2 shows the average uncompressed symbol length (

while the code efficiency with respect to the theoretical limit is given by

As the results demonstrate, the proposed fixed dictionary method outperforms LEC, always achieving a larger compression ratio. Moreover, the code efficiency η for the proposed scheme approaches

Average symbol length (

Average symbol length after compression (L), compression ratio (
4.2. Comparison with Adaptive Linear Filtering Compression
ALFC assumes that the measurements are transmitted in fixed-length packets which contain enough information so that the measurements within the packet can be decoded regardless of communication failures that may have caused previous packet losses. In order to achieve comparable results, we modify our approach so that measurements are also assumed to be contained in fixed-length packets, and the first measurement in each packet is not compressed. That allows every measurement within a packet to be decoded independently of the information contained in previous packets and adds robustness to packet losses similar to that obtained by ALFC.
We compare the performance of our approach to that of ALFC using the same set of parameters employed in the experimental evaluation presented in [4]. That is, we used the quantization parameters
Figure 4 shows the average symbol length

Average symbol length
4.3. Impact of Encoding Symbols Not Present in the Dictionary
To evaluate the impact of transmitting uncompressed symbols not present in the dictionary, we augmented each of the measurement datasets in Table 1 by inserting pairs of uncompressed symbols along with the corresponding special marker and computed the corresponding compression ratio
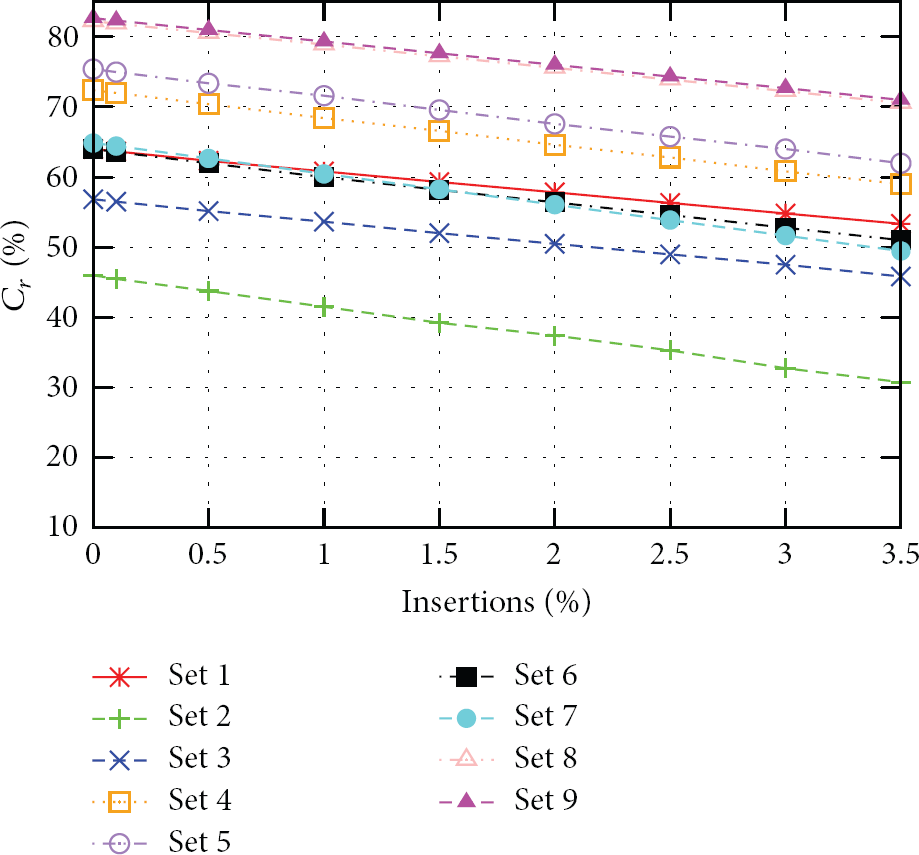
Impact of the insertion of symbols not present in the dictionary in the compression ratio
As Figure 5 shows, even for a relatively high percentage of uncompressed symbols, the compression ratio difference is below
4.4. Validation of the Method Using Alternative Dictionaries
With the purpose of demonstrating the generality of the proposed approach, we evaluated the performance of our method when datasets other than Set 1 were used to generate the dictionary. Table 3 shows the results of this evaluation. In the table, each row shows the average symbol length
Average symbol length

Despite the longer symbol lengths obtained when Set 3 is used, the proposed method performed better that LEC in all the cases presented in Table 4. It also outperformed ALFC's best case compression in every scenario, except when the dictionary generated by Set 3 is used to compress the symbols in sets with very low entropy. Again, one must take into consideration the simplicity of the proposed method.
Percentage of symbols not present in the dictionaries generated by the different datasets.

Table 4 shows the percentage of symbols present in each dataset which cannot be represented by the dictionary generated using the dataset on the top row. The results show that the percentage of symbols not present in the dictionary is very close to zero in most cases. The percentage of symbols outside the dictionary is at most
4.5. Evaluation Using Relative Humidity Measurements
The proposed approach can be applied to other environmental datasets. In order to demonstrate that, we consider a set of relative humidity measurements, whose characteristics are listed in Table 5. Figure 6 shows the probability distribution of the differences between consecutive relative humidity measurements for each of the datasets. Figure 7 shows the average symbol length for the uncompressed case (
Main characteristics of the relative humidity datasets.


Probability distributions of the differences between consecutive measurements for each of the relative humidity datasets.

Average symbol length (
The results concerning the utilization of the proposed scheme and of LEC are shown in Figure 8. In this case, a Huffman dictionary (Table 6) was generated based on the measurements in Set 10 and used to compress the measurements in Sets 11 to 15 (if a temperature dataset, such as Set 1, is used to generate the dictionary, a degradation of up to
Proposed fixed Huffman dictionary for relative humidity datasets.

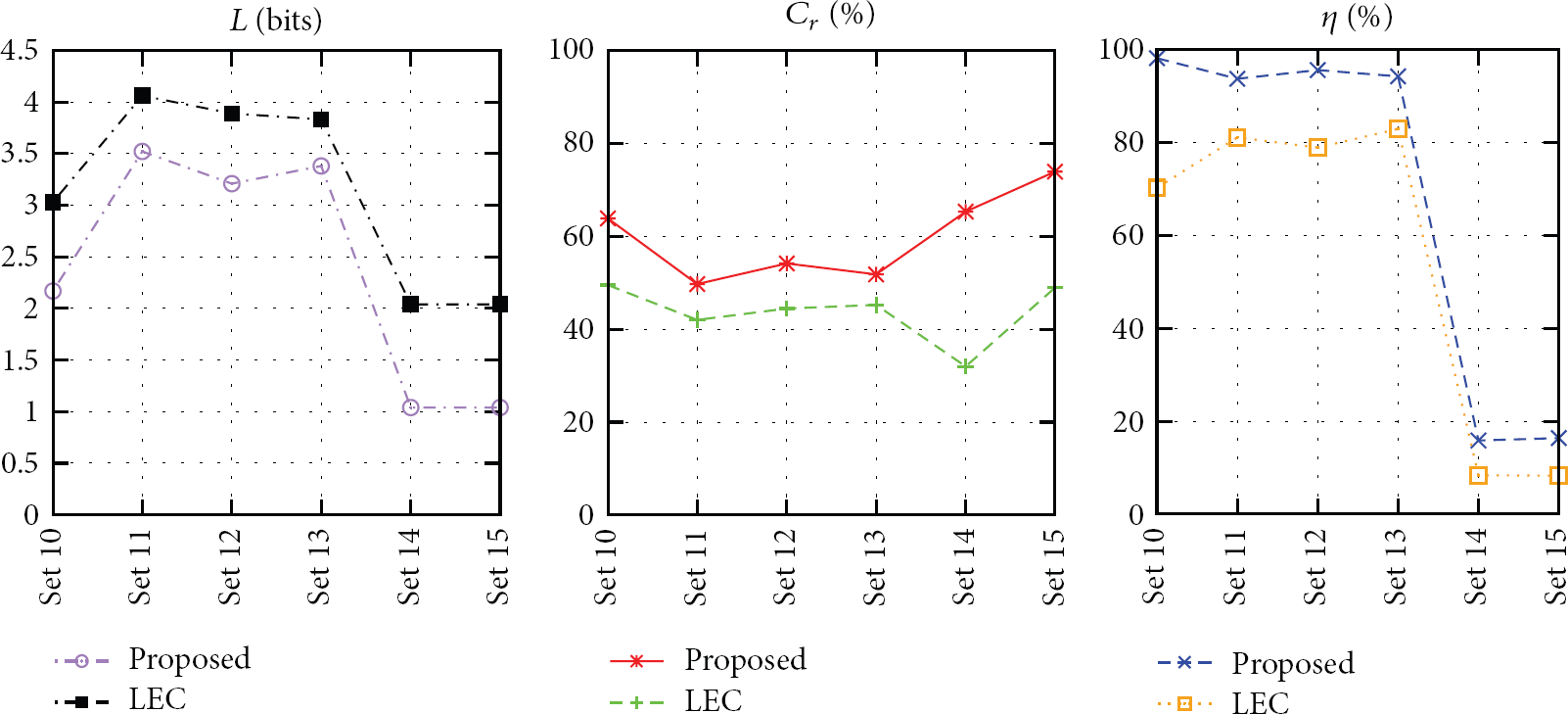
Average symbol length after compression (L), compression ratio (
As we did for the temperature datasets, we also compared the performance of our approach to that of ALFC using the same set of parameters used in Section 4.2. Figure 9 shows the average symbol length

Average symbol length
5. Conclusions
This paper presents a lightweight compression mechanism for low resolution sensor nodes based on fixed Huffman dictionaries. Since the proposed scheme presents very modest computational and memory requirements, it can be easily employed in practical wireless sensor nodes. In order to evaluate the method, we computed the compression ratio obtained in several real datasets containing temperature and relative humidity measurements collected at different locations and during distinct periods of time. The compression ratios obtained using our approach vary between
The most promising direction we envision for the future is to improve our ability of understanding the reference measurement datasets so that we can compensate for deficiencies in the dataset during dictionary generation. That is, we would like, for example, to analyze the relationship between measurement range and sample rate in order to adjust for any discrepancies before generating the dictionary. This would mitigate the impact in the performance of the method seen, for example, when Set 3 was used to generate the dictionary. In fact, taking one step further, this approach might allow us to establish synthetic measurement distributions for different environmental variables (e.g., temperature or relative humidity) which would allow sensor nodes to generate measurement dictionaries on-the-fly without the necessity of referring to reference datasets. For example, the experiments with temperature measurements in Section 4 showed that very high compression ratios are achieved when Set 1 is used to generate the Huffman dictionary. As Figure 1 shows, the distribution of the measurement differences in Set 1 can be obtained by sampling a Laplacian distribution with mean 0 and scale 1 at integer points. The dictionary in Table 2 can then be generated by constructing a Huffman tree based on the probabilities of the points
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was partially supported by CNPq, CAPES, and FAPEAM (Brazil). Part of this work was presented (in Portuguese) in the 31st Brazilian Telecommunications Symposium.