
Abstract
An adaptive noise sensing method is proposed to improve the speech sensing performance of speech-based applications operated over wireless sensor networks. The proposed method is based on nonnegative matrix factorization (NMF), which consists of adaptive noise sensing and noise reduction. In other words, adaptive noise sensing is performed by adapting a priori noise basis matrix of the NMF, which is estimated from the noise signal, resulting in an adapted noise basis matrix. Subsequently, the adapted noise basis matrix is used for the NMF decomposition of noisy speech into clean speech and background noise. The estimated clean speech signal is then applied to a front-end of the speech-based applications. The performance of the proposed NMF-based noise sensing and reduction method is first evaluated by measuring the source to distortion ratio (SDR), the source to interferences ratio (SIR), and the source to artifacts ratio (SAR). In addition, the proposed method is applied to an automatic speech recognition (ASR) system, which is a typical speech-based application, and then the average word error rate (WER) of the ASR is compared with that employing either a Wiener filter, or a conventional NMF-based noise reduction method using only a priori noise basis matrix.
1. Introduction
Speech-based user applications operated over wireless sensor networks are increasingly being utilized in various environments, for example, smart home, smart TV, and cars, since they have become a key feature of smart user interfaces [1–4]. However, as the number of the speech-based application fields has increased, the various types of background noise could negatively affect the speech sensing performance of the applications deployed over wireless sensor networks. These background noises can be classified into two types—stationary and nonstationary—depending on the variability of their characteristics over time. Many conventional methods, including spectral subtraction [5], minimum mean square error log-spectral amplitude (MMSE-LSA) [6, 7], and Wiener filtering [8], have been reported to effectively reduce stationary noise that was recorded with speech signals. Consequently, they were successfully applied to a front-end of an automatic speech recognition (ASR) system, that is, a typical speech-based application over wireless sensor networks [9]. However, since these conventional methods were developed based on the stationary noise assumption, their performance could degrade under nonstationary noise conditions [10, 11]. Thus, the reduction of nonstationary noise is important for reliable noise-robust speech-based applications over wireless sensor networks under various kinds of environmental noise conditions.
As an alternative, nonnegative matrix factorization (NMF)-based noise reduction methods have been proposed to estimate the noise spectrum effectively under nonstationary noise conditions [12–16]. In particular, recent research works have reported that NMF-based noise reduction methods have been successfully applied to a front-end of an ASR system under various nonstationary noise environments [14–16]. However, the performance of NMF-based noise reduction methods degraded substantially when there was a mismatch in noise type for noise basis training and estimation using NMF [17, 18]. There have been several approaches proposed to improve the noise reduction performance of NMF when there was a mismatch between the training and estimation of speech and/or the noise basis [19–21]. In particular, real-time semisupervised source separation methods in [19, 20] assumed that the noise basis was prepared at the training stage, while the speech basis was learned online under nonstationary noisy conditions. The methods dealt with the mismatch in speech basis training and estimation, but there was no consideration on the mismatch between the noise basis training and estimation. In [21], a universal model was introduced to overcome the mismatch between the noise basis training and estimation, where each noise basis was trained to represent a certain type of noise source. Consequently, the performance of the universal model would be limited because noise could be represented by multiple overlapping sources in a real world environment [18].
In this paper, an NMF-based adaptive noise sensing and reduction method is proposed to improve the performance of an ASR system under the mismatch in a noise type between the noise basis training and estimation. The proposed method adaptively updates a priori noise basis matrix of the NMF on the fly by estimating the noise signal prior to the actual speech signal. Next, NMF decomposition is carried out with the adapted noise basis matrix in order to estimate clean speech and background noise from noisy speech. Finally, the estimated clean speech signal is applied to a front-end of an ASR system in order to improve the performance of ASR under various noise types.
The rest of this paper is organized as follows. Following this introduction, Section 2 briefly reviews a conventional NMF-based noise reduction method. Section 3 proposes an NMF-based noise sensing and reduction method. Section 4 evaluates the performance of the proposed method and compares it with those of conventional methods. Finally, the paper is concluded in Section 5.
2. Conventional NMF-Based Noise Reduction Method
Figure 1 shows the procedure of a conventional NMF-based noise reduction method applied for an ASR. As shown in the figure, noisy speech is captured by a microphone; then a block of speech signal, called a speech frame, is transformed into a frequency domain by applying a short-time Fourier transform (STFT). Next, an NMF technique is applied to estimate the clean speech spectrum by reducing the noise spectrum. Consequently, the estimated clean spectrum is transformed back into the time domain by applying an inverse STFT. Finally, an ASR system, which is typically based on hidden Markov models [22], is constructed from the feature parameters extracted from this estimated clean speech.
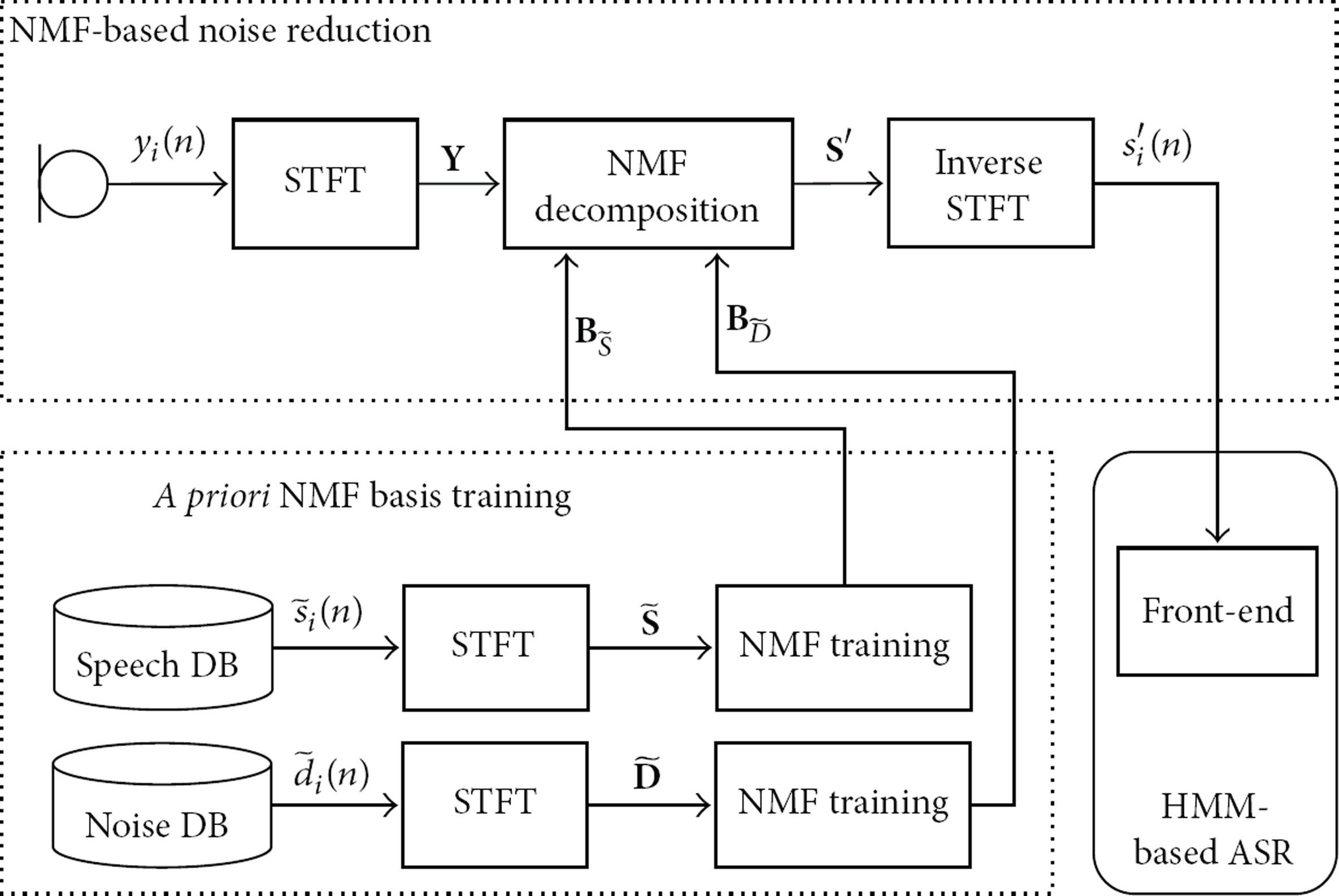
Procedure of a conventional NMF-based noise reduction method.
As mentioned in Figure 1, an NMF-based noise reduction method attempts to decompose a noisy speech signal into separate speech and noise signals by exploring the sparseness of the noisy speech [18]. To explain how to estimate speech and noise with NMF, noisy speech at the ith speech frame,


In the NMF framework,
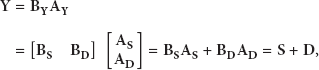

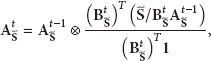


In the NMF training,
As described above, the conventional noise reduction methods are performed using

However, the main drawback of the conventional NMF-based noise reduction methods is that the noise reduction performance is not reliable when there is a mismatch in noise types between the noise basis training and estimation using NMF. In other words, the basis matrices,
3. Proposed NMF-Based Adaptive Noise Sensing and Reduction
In this section, an NMF-based adaptive noise sensing and reduction method is proposed to mitigate the degradation of noise reduction when there is a mismatch in noise types between noise basis training and estimation using NMF. Figure 2 shows the procedure of the proposed NMF-based adaptive noise sensing and reduction method. As shown in the figure, the procedure is divided into three different processing stages: a priori NMF basis modeling, NMF-based adaptive noise sensing, and noise reduction. The first processing stage of the proposed method is the same as that of the conventional method described in Section 2. In other words, clean speech signals and noise signals are separately applied to the NMF training in order to obtain the a priori basis matrices. In the second processing stage, the adaptive noise sensing is performed to decompose the noisy input spectrum into speech and noise spectrum using a priori speech basis matrix estimated by the first processing stage. That is, the noise basis and activation matrices are obtained by adapting a priori noise basis from the instantaneous noise frames of the noisy input signal. Finally, the third processing stage of the proposed method estimates the noise-reduced speech signal by constructing a Wiener filter [8] using the adaptively estimated noise spectrum. The following subsections describe a priori NMF basis acquisition, NMF-based adaptive noise sensing, and noise reduction in detail.
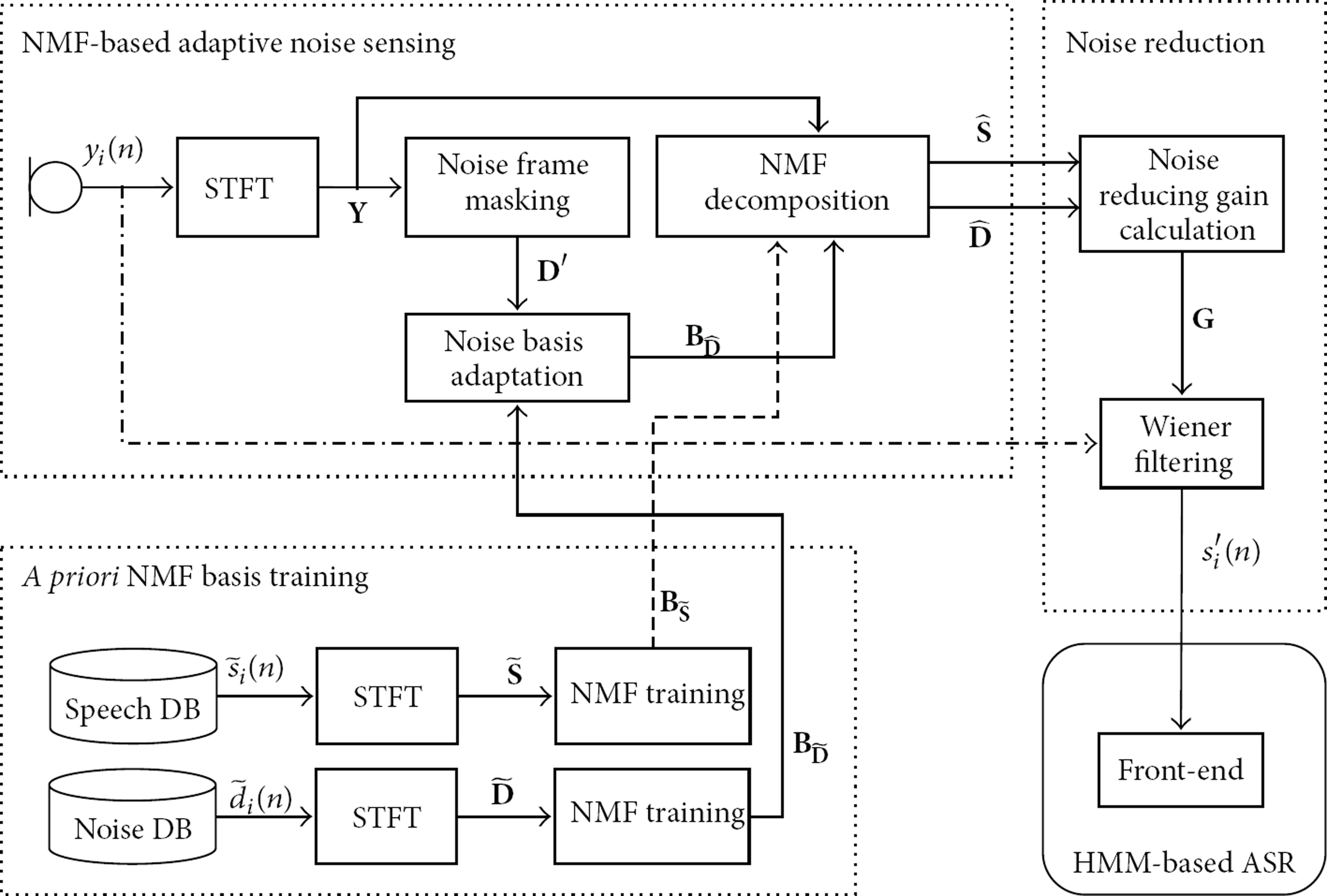
Procedure of the proposed NMF-based adaptive noise sensing and reduction method.
3.1. Modeling of A Priori NMF Basis Matrix
This subsection describes how to obtain the NMF basis matrices of speech and noise signals. As mentioned in Section 2, for given speech and noise database,

3.2. NMF-Based Adaptive Noise Sensing
This subsection describes how the noise spectrum is adapted into the NMF framework. First, noise frames are detected from noisy input speech. Then, the detected noise frames are concatenated to construct a noise matrix,

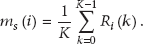
Using (11), a set of noise frames,

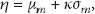
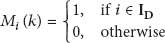
Next,
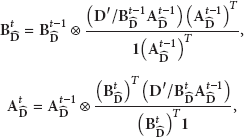
As a final processing step for the adaptation, NMF decomposition is performed in order to calculate

3.3. Noise Reduction
This subsection describes how to reduce noise from noisy input speech using the adapted noise basis of NMF, which is the third processing stage of Figure 2. First, a

4. Performance Evaluation
The performance of the proposed method was first evaluated by measuring the source to distortion ratio (SDR), source to interferences ratio (SIR), and source to artifacts ratio (SAR) [26]. Next, the average word error rate (WER) of an ASR system employing the proposed method was measured. Finally, the performance of the proposed method was compared with those of the two-stage mel-warped Wiener filter method (Mel-WF) [8] and the NMF-based noise reduction method without noise basis adaptation (NMF-Conv) [14].
For the evaluation, 10 males and 10 females spoke 20 sentences each, resulting in 400 sentences. This recording was performed in a quiet room without any reverberation. Next, each sentence was mixed with four different kinds of background noise recorded at bus stops, restaurants, subways, and a living room with a TV on, where signal-to-noise ratio (SNR) was changed from 0 to 20 dB with a step of 5 dB. The bus stop, restaurant, and subway noises were used to simulate high stationary noise environments, while the living room noise was used in order to simulate a high nonstationary noisy environment in which a person was speaking while watching different genres of TV programs such as drama, news, sports, and movies. It should be noted that the restaurant and living room noise signals were recorded in a nonreverberant room. The speech and noise signals used in the evaluation were sampled at 16 kHz with a 16-bit resolution. A priori basis matrices for the evaluation were prepared as follows. First, a priori basis matrix for speech,
4.1. Noise Reduction Performance
In this subsection, the noise reduction performance of the proposed method was evaluated under both nonstationary and stationary noise conditions by measuring the SDR, SIR, and SAR. As shown in (1), a noisy speech signal was composed of clean speech and noise as

First, Table 1 compares the SDRs, SIRs, and SARs of the proposed method and those of the conventional methods under a nonstationary noise condition such as the living room condition. As shown in the table, the proposed method significantly increased the average SDR, SIR, and SAR values, compared to both the Mel-WF and the NMF-Conv. In particular, the proposed method achieved a dramatically higher average SIR than Mel-WF and NMF-Conv, by 15.01 dB and 8.60 dB, respectively, under the living room noise condition. This implies that the proposed method could provide a speech signal with significantly lower interference than the conventional methods under the nonstationary noise condition.
Comparison of the average SDRs, SIRs, and SARs (in dB) of the proposed method and the conventional methods under a living room noise condition.

The performance evaluation was then repeated under three different stationary noise conditions such as bus stop, restaurant, and subway noises. Table 2 shows the SDRs, SIRs, and SARs of the noise-reduced signals processed by the proposed and conventional methods under the stationary noise conditions. Similar to the results under the living room noise condition, the proposed method achieved a substantially higher average of SDR, SIR, and SAR than either the Mel-WF or the NMF-Conv under all stationary noise conditions. It could be concluded that the NMF method employing the proposed noise basis adaptation method performed noise reduction more effectively than the conventional methods under both the stationary and nonstationary noise conditions.
Comparison of the average SDRs, SIRs, and SARs (in dB) between the proposed method and the conventional methods under stationary noise conditions such as (a) bus stop, (b) restaurant, and (c) subway noise condition.

Next, the spectrograms obtained by the proposed method were compared with those by the conventional methods. Figure 3 shows the spectrograms of the noise signals, noisy speech signals at 5 dB SNR, and the estimated noise signals obtained by different noise reduction methods under four different background noise conditions. It was shown by pairwise comparison between Figures 3(e)–3(h) and Figures 3(m)–3(p) that the noise reduction performance of the proposed method was comparable to that of the Mel-WF under stationary noise conditions including bus stop and restaurant noise. On the other hand, the proposed method successfully reduced nonstationary noise under the living room noise condition, whereas the Mel-WF failed to handle the nonstationary noise. Furthermore, it was demonstrated by comparing Figures 3(i)–3(l) and Figures 3(m)–3(p) that the proposed method provided more distinctive speech signals than the NMF-Conv under all the noise conditions.
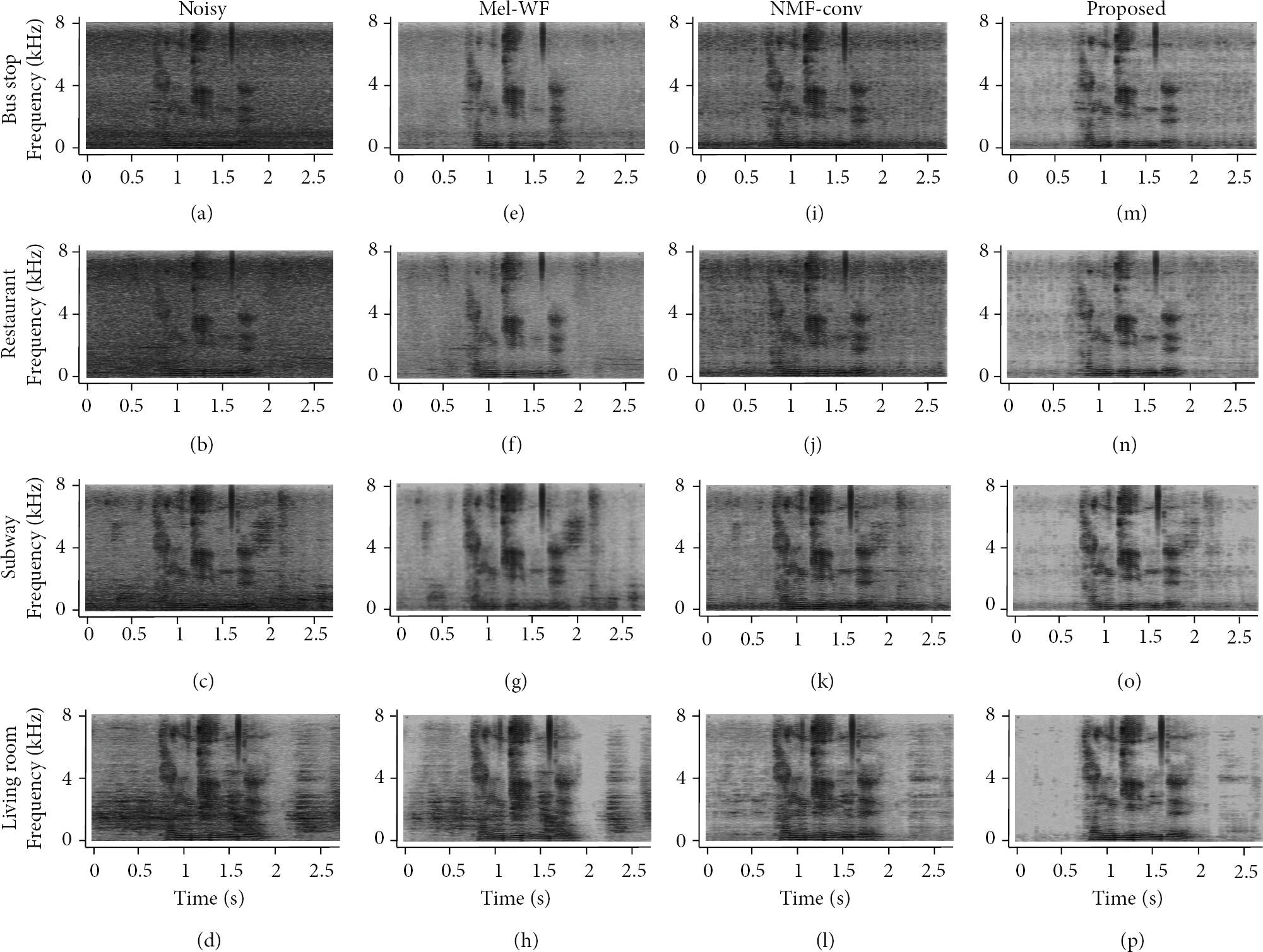
Spectrograms of signals: (a)–(d) noisy speech signals at 5 dB SNR, (e)–(h) noise-reduced speech signals from Mel-WF, (i)–(l) those of NMF-Conv, and (m)–(p) those by the proposed method under four different noise conditions.
4.2. ASR Performance
To evaluate the recognition performance of the proposed noise reduction method in an ASR system, a hidden Markov model (HMM)-based speech recognition system was constructed. To this end, acoustic models based on three-state left-to-right HMMs were first built from 170,000 phonetically balanced words, which were recorded in quiet rooms by 1,800 speakers. Every recorded speech signal was also sampled at 16 kHz at a 16-bit resolution. As a speech recognition feature, 12 mel-frequency cepstral coefficients (MFCCs) with logarithmic energy were extracted and their delta and acceleration coefficients were concatenated, resulting in a 39-dimensional feature vector [27].
Table 3 compares average WERs of an ASR system employing the proposed method as a front-end with those of ASR systems employing the conventional methods under the nonstationary noise condition. As shown in the table, the proposed method significantly reduced average WER than the conventional methods. Specifically, the proposed method relatively reduced average WER by 65.22% and 24.21% compared to the Mel-WF and the NMF-Conv, respectively.
Comparison of average word error rates (WERs) (%) of an ASR system employing the proposed method and the conventional methods under a living room noise condition.

Second, Table 4 compares average WERs of an ASR system employing the proposed method as a front-end with those of ASR systems employing the conventional methods under stationary noise conditions. As shown in the table, the proposed method relatively reduced average WER under bus stop, restaurant, and subway noise conditions by 0.93%, 11.34%, and 6.56% compared to the Mel-WF and 12.13%, 13.10%, and 11.50% compared to the NMF-Conv, respectively. Consequently, it was concluded that the proposed method provided a better ASR performance than the conventional methods under the stationary and nonstationary noise conditions.
Comparison of average word error rates (WERs) (%) of an ASR system employing the proposed method and the conventional methods under stationary noise conditions such as (a) bus stop, (b) restaurant, and (c) subway noise condition.

5. Conclusion
In this paper, an NMF-based noise sensing method has been proposed to reduce stationary and nonstationary noises for speech-based applications over wireless sensor networks. The proposed method adapted the initially estimated noise basis matrix on the fly when the noisy input spectrum was applied to a front-end of a speech-based application. After constructing a Wiener filter using the estimated clean speech and noise spectra in the NMF frame, a clean speech signal was estimated and used for speech recognition. The performance of the proposed method was evaluated by measuring the SDR, SIR, and SAR. In addition, the proposed method was applied to an ASR system and then average WER of the ASR system was evaluated. The performance of the proposed method was also compared with those of conventional methods such as the two-stage mel-warped Wiener filter method and the NMF-based noise reduction method without noise basis adaptation. As a result, it was shown that the proposed method provided better performance in terms of the SDR, SIR, SAR, and WER than the conventional methods under both nonstationary and stationary noise conditions.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the IT R&D Program of MSIP/KEIT [10035252, development of dialog-based spontaneous speech interface technology on mobile platform] and the National Research Foundation of Korea (NRF) Grant funded by the Government of Korea (MSIP) (no. 2012-010636).