
Abstract
We proposed the automatic sound scene control system using the image sensor network for preserving the constant sound scene without respect to the users' movement. In the proposed system, the image sensor network detects the human location in the multichannel playback environment and the SSC (sound scene control) module automatically controls the sound scene of the multichannel audio signals according to the estimated human location which is the angle information. To estimate the direction of the human face, we used the normalized RGB (red, green, and blue) and the HSV (hue, saturation, and value) calculated from the images obtained by the image sensor network. The direction of the human face can be easily decided as the image sensor to capture the image with the highest number of pixels to satisfy the thresholds of the normalized RGB and the HSV. The estimated direction of the human face is directly fed to the SSC module, and the controlled sound scene can be simply generated. Experimental results show that the image sensor network successfully detected the human location with the accuracy of about 98% and the controlled sound scene by the SSC according to the detected human location was perceived as the original sound scene with the accuracy of 95%.
1. Introduction
With increase in multichannel audio sources such as DVD and consumer's demand on more realistic audio service, multichannel audio signals are getting more important in the audio coding and the audio service. In addition, as the multichannel audio signals need very high bit-rate to be transmitted, there have been many efforts to efficiently handle the multichannel audio signals with respect to the bit-rate, and the sound quality and spatial cue based multichannel audio coding schemes such as binaural cue coding (BCC), MPEG Surround, and sound source location coefficient coding have been introduced and developed [1–6]. These multichannel audio coding schemes do not attempt to provide an approximate reconstruction of the original multichannel signals' waveforms and instead focus on delivering perceptually satisfying replica of the original sound scene by exploiting knowledge about human perception [7–9]. In the spatial cue based multichannel audio coding, the spatial image of the multichannel audio signals is captured by a compact set of parameters, that is, the spatial cues, and a down-mix signal. In other words, the multichannel audio signals are represented as a down-mix signal and small amount of side information while successfully preserving the sound image of the multichannel audio signals. Accordingly, the spatial cue based multichannel audio coding can dramatically reduce the bit-rate and provide an extremely efficient representation of the multichannel audio signals.
Apart from the coding efficiency and the sound quality of the spatial cue based multichannel audio coding determined by the spatial cues, there is another merit to create valuable functionality in the multichannel audio coding through the usage of spatial cues. Since the spatial image of the multichannel audio signals can be preserved by the spatial cues, we can control the sound scene by the modification of the spatial cues. In other words, the spatial cues can be utilized not only to keep the sound quality of the multichannel audio signals but also to change the sound scene of the multichannel audio signals. We call this sound scene control (SSC) based on the spatial cues and this functionality can provide users with interactivity [10]. Moreover, the SSC can be implemented in the frequency domain and it only needs a few multiplications and additions; the complexity of the spatial cue based multichannel audio coding is rarely affected by the SSC [10]. One of the possible applications of the SSC is to combine sound scene controller with multiview video. In the case of multiview broadcasting, which will be advent in near coming days, it is expected that multichannel sound scene control can provide interactive audio playback systems and realistic audio sound by synchronizing sound scene with moving video scene.
Meanwhile, users can perceive the original sound scene of the multichannel audio signals produced by contents providers when they locate at the center of the multichannel speaker layout. If users change their position, especially their heads' direction, they feel the different sound scene from the original one due to the binaural effect [3, 11]. In other words, when the users' position has changed, the original sound scene should be controlled according to the users' new position so that the users can perceive the constant sound scene without respect to their movement. To achieve this goal, we proposed an automatic sound scene control system using image sensor network.
In the proposed system, the human location (or the direction of the human face) is detected by the image sensor network and the sound scene of the multichannel audio signals is automatically controlled by the previously mentioned SSC module according to the estimated human location which is the angle information. The image sensor network consists of twelve image sensors to be uniformly arranged in the multichannel playback environment and it has 30-degree resolution for detecting the direction of the human face. To estimate the direction of the human face, we used the normalized RGB (red, green, and blue) and the HSV (hue, saturation, and value) calculated from the images obtained by the image sensor network [12–14]. It is because the normalized RGB and the HSV are useful for detecting the human skin region in the images. In addition, as the image obtained by the image sensor to be located at the direction of the human face includes many pixels with the normalized RGB and the HSV values to satisfy thresholds for detecting the human skin, the direction of the human face can be easily decided as the image sensor to capture the image with the highest number of pixels to satisfy the thresholds of the normalized RGB and the HSV. The estimated direction of the human face is directly fed to the SSC module, and the controlled sound scene can be simply generated.
The paper is organized as follows. In Section 2, the sound scene control method in MPEG Surround which is representative of the multichannel audio coders is presented. In Section 3, the estimation of the direction of the human face using the image sensor network and the proposed automatic sound scene control system are described. In Sections 4 and 5, experimental results and conclusion are drawn, respectively.
2. Sound Scene Control in MPEG Surround
MPEG Surround is a technology to represent multichannel audio signals as the down-mix signal and spatial cues [1–3]. The MPEG Surround only uses the down-mix signal and the additional side information, that is, spatial cues, for the transmission of the multichannel audio signals through wired/wireless network system. Therefore, users can enjoy a realistic audio sound by the multichannel audio signals through multichannel audio services such as digital audio broadcasting and digital multimedia broadcasting in wired/wireless network environment.
The MPEG Surround uses channel level difference (CLD) and interchannel correlation (ICC) as spatial cues. The CLD is a main parameter in the MPEG Surround because it determines the spectral power of the reconstructed multichannel audio signals and occupies a considerable amount of the side information [4]. However, the ICC is an ancillary parameter in the MPEG Surround because it reflects the spatial diffuseness of the recovered multichannel audio signals and takes a small portion of side information. As the multichannel audio sound is compressed and recovered using the down-mix signal and the spatial parameters, the performance of the MPEG Surround in the aspects of the coding efficiency and the sound quality is determined by the spatial parameters. In other words, the sound image formed by the multichannel audio signals is captured and recovered by the CLD and the ICC. Under this knowledge, we can control the sound scene of the multichannel audio signals by the modification of the spatial parameters, alternatively. The SSC is a new tool to reproduce a new sound scene of the multichannel audio signals according to the global panning position which is freely inputted by a user or another system. By the given panning angle, denoted by

MPEG Surround with sound scene control module.
The procedure of the SSC in the MPEG Surround is shown in Figure 2. At first, the spatial parameters such as the CLD and the ICC are parsed from the transmitted spatial parameter bit-stream. And then they are modified according to

Procedure of sound scene control.
To modify the CLD, it is processed by gain factor converter, constant power panning (CPP), and CLD converter, sequentially. In the gain factor converter, the CLD is converted to each channel level gain per each subband. The gain factors are simply calculated from the CLD as the following formula:

In CPP module, the CPP law is applied to manipulate the position of each channel according to desired sound scene [15, 16]. Let us assume that if the channel gain
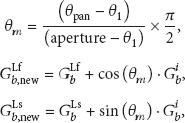
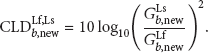
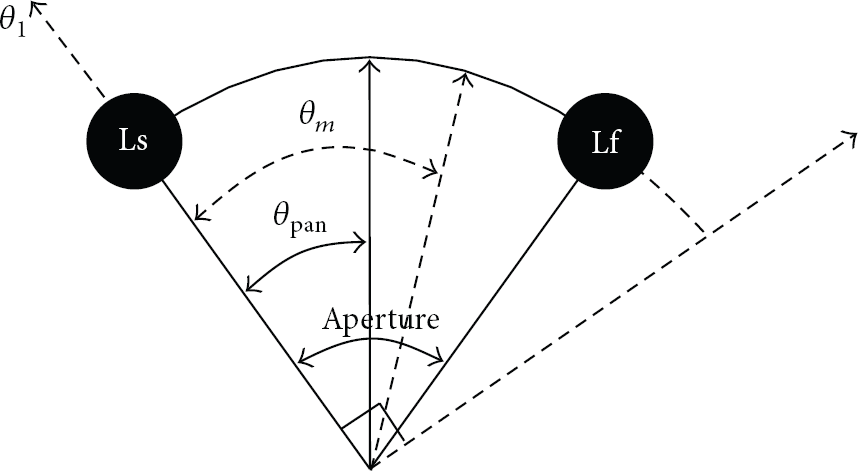
An example of constant power panning law between two channels.
To perfectly modify the ICC, the ICC must be reestimated according to the controlled sound scene. But, different from the CLD, the ICC cannot be reestimated in parameter domain since the degree of correlation between the channels is only able to be estimated in signal domain. Due to this problem, the ICC cannot be perfectly controlled and it could result in the degradation of overall sound quality after changing the sound scene. In spite of this restriction, two kinds of ICC parameter could be modified in the case of sound scene rotation:


These equations mean that left and right half plane ICC parameters are totally cross-changed if the degree of scene rotation is equal to the 180 degrees. In the case that rotation angle is increased greater than 180 degrees to 360 degrees, the reverse cross-changed is ocurred and the modified ICC parameters are equal to the original ones at 360 degrees. This concept of modification originated from common smoothing technique used in the MPEG Surround [3, 4].
3. The Proposed Automatic Sound Scene Control System Using Image Sensor Network
As the human perception of the sound scene is decided by the human localization in the multichannel playback environment, the image sensors are located around the multichannel speaker layout as shown in Figure 4. Figure 4 shows that the twelve image sensors are uniformly distributed in the multichannel playback environment and the resolution of the human localization is 30 degrees.

Image sensor network in the multichannel playback environment.
Although the direction of the human face is an important factor for the perception of the sound scene, the precise recognition of the human face is not necessary in our proposed system. As the image obtained by the image sensor to be located at the direction of the human face includes many pixels with the normalized RGB and the HSV values to satisfy thresholds for detecting the human skin, the direction of the human face can be easily decided as the image sensor to capture the image with the highest number of pixels to satisfy the thresholds of the normalized RGB and the HSV.
From the past research results, it has been confirmed that human skin colors cluster in a small region in RGB color space and human skin colors differ more in brightness than in colors [12–14]. Therefore, the normalized RGB value can be used to detect the human faces with less variance in color.
Generally, colors of each pixel in image are represented by the combination of R, G, and B components and the brightness value is calculated as


In addition to the normalized RGB value, we use the HSV (hue, saturation, and value) as additional parameter for the direction recognition of the human face [12]. It is because the HSV is more similar to the human perception of color. At first, the hue (H) indicates a measure of the spectral composition and it is represented as an angle which varies from 0 to 360 degrees. Second, the saturation (S) is the purity of colors and it varies from 0 to 1. At last, the value (V) is defined as the darkness of a color and it ranges also from 0 to 1. The HSV values can be simply calculated from the RGB values using the following equations:

We used the following threshold values of the normalized RGB and the HSV for the decision of the human skin-like pixels [12]:
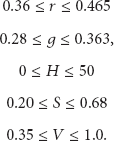
A pixel of the obtained image by sensor is judged as the human skin-like pixel only if its normalized RGB and HSV values satisfy all thresholds of (9). Under this knowledge, all skin-like pixels in the captured image by sensor are counted and the location of the image sensor with the highest number of skin-like pixels is determined as the direction of the human face. Figure 5 shows the whole procedure for the human localization using image sensor network.

Procedure of the human localization using image sensor network.
The proposed automatic sound scene control system using image sensor network is shown in Figure 6. Compared to Figure 1, the input angle to the sound scene control module is only replaced by the estimated direction of human face according to the human movement. Therefore, the explained sound scene control module in Section 2 can be directly used for the proposed automatic sound scene control system without any changes in the operation. The proposed system has the sound scene control error as maximum 15 degrees since the image sensor network has 30-degree resolution for the estimation of the direction of the human face.
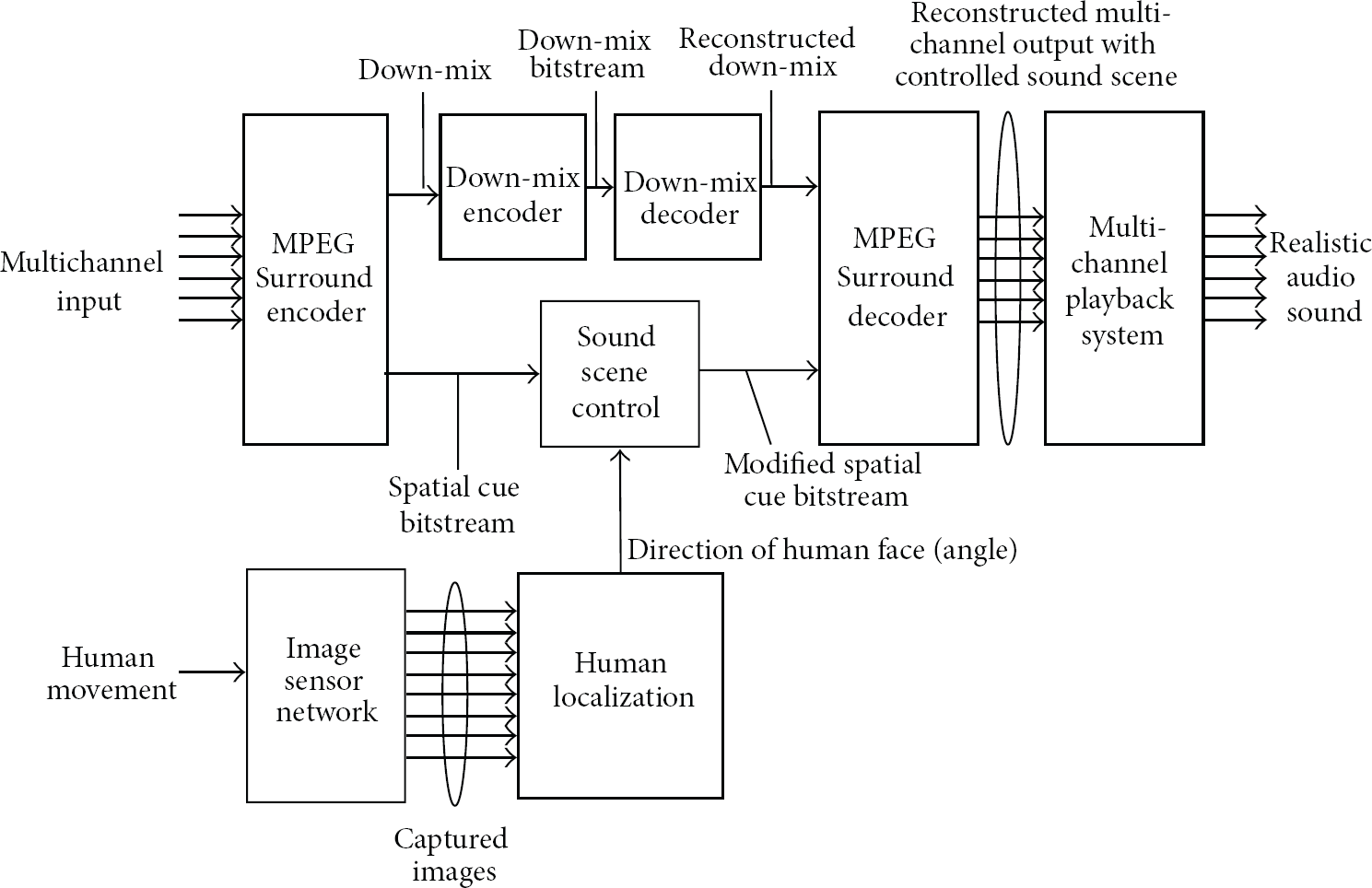
The proposed automatic sound scene control system using image sensor network.
4. Experimental Results
To validate the performance of the proposed automatic sound scene control system using the image sensor network, we performed a subjective listening test which focused on the sensing ability of the image sensor network and the controllability of the SSC according to the result of the image sensor network. For the listening test, the five test items offered by MPEG audio subgroup were used and are listed in Table 1 [17]. The items were sampled at 44.1 kHz with 16-bit resolution and were all shorter than 20 seconds. Eight listeners participated in the listening test.
Test items.
To check the sensing ability of the image sensor network, the estimated result by the image sensor network was compared to the listeners' position, that is, the direction of their face, when they moved. Here, for the clarification of the test, 30, 60, 90, 120, 150, 180, 210, 240, 270, 300, and 330 degrees are only allowed as the listeners' position. All listeners changed their position into the given angles 3 times and the total number of trials was 264. Table 2 and Figure 7 show the recognition result by the image sensor network. The recognition rate of the image sensor network is about 98.1% and only 5 trials were recognized as the wrong position. Here, a main reason for the false recognition was the listeners' wrong head direction.
Recognition rate of the image sensor network.


Recognition rate of the image sensor network.
To check the controllability of the SSC, we used two kinds of audio sounds—the original and controlled ones. The original sound scene was given as the reference signal and the listeners decided whether the controlled sound scene according to their position was equal to the original sound scene or not when they moved. For the simplification of the test, 60, 120, 180, 240, and 300 degrees were used as the listeners' position. All listeners changed their position into the given angles per each test item and the total number of trials was 200. Here, if the estimated listeners' position was wrong, it was deleted and the listeners tried again at the same position. Table 3 and Figure 8 show the result for checking the controllability of the SCC. The ratio that the controlled sound scene by the SCC was perceived as the original sound scene was 95%. Because the SCC has a problem about the ICC modification as previously described, the newly generated audio sound by the SCC showed the different sound scene in some trials.
Controllability result of the proposed system using the image sensor network.

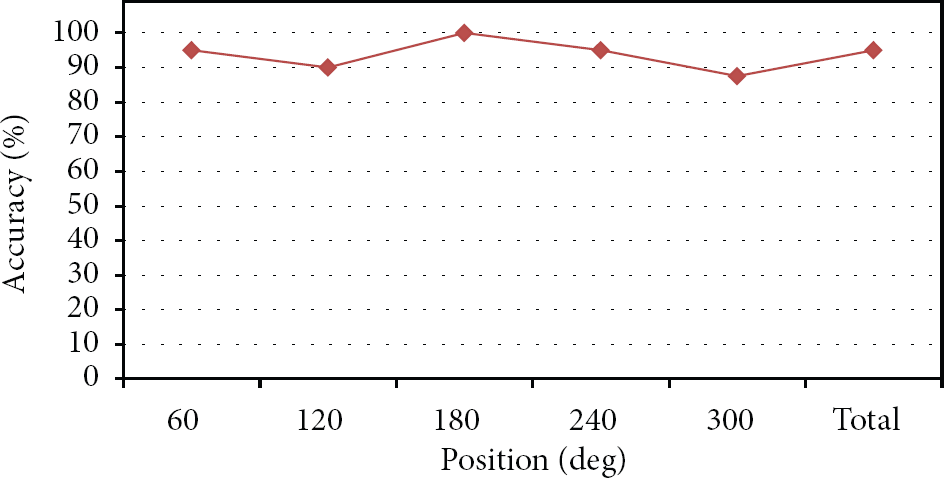
Controllability result of the proposed system using the image sensor network.
5. Conclusion
In this paper, we proposed the automatic sound scene control system using the image sensor network for preserving the constant sound scene without respect to the users' movement. In the proposed system, the image sensor network detects the human location in the multichannel playback environment and the SSC module automatically controls the sound scene of the multichannel audio signals according to the estimated human location which is the angle information. To estimate the direction of the human face, we used the normalized RGB and the HSV calculated from the images obtained by the image sensor network. The direction of the human face can be easily decided as the image sensor to capture the image with the highest number of pixels to satisfy the thresholds of the normalized RGB and the HSV. The estimated direction of the human face is directly fed to the SSC module, and the controlled sound scene can be simply generated.
Experimental results show that the image sensor network can successfully detect the human location with the accuracy of about 98%. Moreover, the controlled sound scene by the SSC according to the detected human location was perceived as the original sound scene with the accuracy of 95%. To enhance the performance of the image sensor network and the SCC, more precise human localization using the eye detection in the image remains as a future work.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This study was funded by the research fund of Korea Nazarene University in 2014 (Kwangki Kim) and supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science, and Technology (Grant no. 2012R1A1A4A01004195).