
Abstract
Social networking has been used widely by millions of people over the world. It has become the most popular way for people who want to connect and interact online with their friends. Currently, there are many social networking sites, for instance, Facebook, My Space, and Twitter, with a huge number of active users. Therefore, they are also good places for spammers or cheaters who want to steal the personal information of users or advertise their products. Recently, many proposed methods are applied to detect spam comments on social networks with different techniques. In this paper, we propose a similarity-based method that combines fingerprinting technique with trie-tree data structure and meet-in-the-middle approach in order to achieve a higher accuracy in spam comments detection. Using our proposed approach, we are able to detect around 98% spam comments in our dataset.
1. Introduction
In the last few years, social networking has been known as an Internet phenomenon. It has become the main way for people to connect and keep track with their friends online. The most popular social networking sites such as Facebook, Twitter, and My Space are consistently among the top 20 most viewed websites on the Internet. Many people spend more and more time for enjoying the virtual lives on the social networks rather than their real lives. Moreover, their personal information that is stored and shared on such sites is usually under loose security. Hence, social networking is also a potential target for spammers and cheaters who want to advertise their products or more dangerously steal the users' information. There are many simple tricks, for example, posting fake updates that contain malicious links, abusing the comment function to post unsolicited messages to users, images trick, and social engineering, with which spammers can achieve their purposes easily.
Spam comments usually have duplicate or near-duplicate contents. Therefore, they can be detected by several common methods that are used to detect duplicate and near-duplicate documents in the web mining field.
Duplicate and mirror web pages are seen in plenty in the World Wide Web [1]. Besides that, near-duplicate documents are mostly identical to the original ones but differ in several small portions of document such as advertisements, timestamps, or counters.
Recently, duplicate and near-duplicate documents detection is important in various computer science fields, specifically data mining, information retrieval, and web mining. Its advantage is saving storage for necessary data instead of those duplicated. A sizeable percentage of web pages are found to be near duplicate by several studies [2–4]. These studies suggested that approximately 1.7% to 7% of the web pages visited by crawlers are near-duplicate pages. Although the problem due to mirroring and plagiarism is detected simply by applying several techniques such as machine learning and document clustering, near-duplicate documents are more difficult to identify.
In this paper, we propose a method using trie-tree data structure to store a set of 64-bit strings, each of which is the fingerprint of a web document. After that, we use meet-in-the-middle approach in order to detect near-duplicate documents. In social spam detection issue, we believe our method described in this paper is capable of identifying spam comments as well as near-duplicate documents with high accuracy level.
The rest of the paper is structured as follows: Section 2 reviews the related works; Section 3 describes the proposed methods that we utilize to identify duplicate and near-duplicate documents; Section 4 reveals our datasets and evaluation. Finally, we offer some concluding thoughts in Section 5.
2. Related Works
Many researchers were early to realize the difficulty and importance of near-duplicate web pages detection in web mining field. The proposed methods in such previous works are either similarity-based or signature-based [5].
As for similarity-based methods, they usually require that all documents are compared with each other. Specifically, every document is compared to all others in the dataset and the similarity between each pair is calculated [5].
In 1997, Broder et al. [6] analyzed the fraction of web pages which are near-duplicates of others. In that study, they implemented a technique called shingling. The basic idea of their method is to choose a contiguous subsequences set of every document's tokens. The set of these tokens is used to represent each document. In their experiment, they compared the representative of two documents for overlap to provide an approximation to similarity. Higher similarity would be assigned in two documents that have substantial overlap in their tokens.
Narayana et al. [7] had presented a method for near-duplicate detection of web pages in web crawling. After obtaining a new web page from web crawler, the system extracts the content of that page into many tokens and calculates its similarity score with many various existing documents. A document would be considered a near-duplicate web page if its similarity score was greater than the threshold that had been predefined.
By applying the similarity-based method, the runtime performance is
In another paper, we proposed a method to detect spam SMS on mobile devices and smart phones. That approach was based on improving a graph-based algorithm and utilizing the KNN algorithm—one of the simplest and most effective classification algorithms in order to improve the accuracy and performance of detection system on mobile devices [9].
In one example in the fingerprinting context, some frequently occurring shingles are eliminated [5]. In this study, the shingles technique considers a document as a stream of tokens, which is broken into overlapping or nonoverlapping segments referred to as shingles. Instead of using the complete set of tokens from each document to compute the similarity between two of them, they chose a small subset of tokens that contained the most frequent ones as the representative of that document. With such simplification, however, the detection accuracy is improved sufficiently.
Another example was based on the fingerprinting to detect near-duplicate documents, which was recently proposed by Kumar and Govindarajulu [1]. The fingerprint of document, which is a 64-bit string, is generated by a fingerprinting algorithm called sim-hash [10]. In computer science, a fingerprinting algorithm is a procedure that maps an arbitrarily large data item (in this paper, the data item is a web document) to a much shorter bit string that is likely to identify the original data. The sim-hash algorithm can hash similar documents to similar fingerprints and each document can be represented by only 64 bits. Then, K-Means clustering, sentence feature, and fingerprint comparison would be applied in order to detect near-duplicate web page document. Pugh, who worked at Google, surmised that two documents can be detected as duplicate or near-duplicate documents if any of their fingerprints match [11].
Following the fingerprinting context, we propose a new social spam comments detection method that utilizes trie-tree data structure for fingerprints and meet-in-the-middle approach in the detection phase, which can be applied to the spam comments detection process. The experimental result shows how our method achieves high detection accuracy and efficient performance.
3. Proposed Method
3.1. Workflow
This section describes an overview of our proposed method. A new document has to be processed through many steps such as parsing, tokenization, stop words removal, and stemming in the preprocessing phase. After that, the most frequent tokens set is chosen and used to generate the 64-bit fingerprint by sim-hash algorithm. Furthermore, from a primary fingerprint of document, we continue to invert the value of one or two positions among 64 bits sequentially for generating many 64-bit strings as near-similar fingerprints. Finally, the primary fingerprint and its corresponding near-similar fingerprints will be stored in the trie-tree. Generally, our workflow is illustrated in Figure 1.

Near-duplicate document detection in the training phase.
For the detection phase, we generate fingerprints from the new document, including their primary and near-similar ones. Then, we check whether the fingerprints of new document exist on the trie-tree. If any item exists on the tree, it can be concluded that at least one document in the collections is near-duplicate or duplicate with this.
3.2. Preprocessing
Preprocessing needs to be done prior to fingerprints generation and trie-tree representation. It consists of HTML parsing, tokenization, stop words removal, and stemming [1]. In parsing, a web document is analyzed to a linear representation according to a given grammar. After parsing HTML, the parsed web content is broken up into many words through tokenization process and then they are filtered by removing several connecting words such as “is,” “a,” and “an” in the stop words removal procedure. Finally, a process called stemming condenses these filtered words into their basis form before passing them to the fingerprint generating process for further processing.
3.2.1. Parsing
A web page is a mixed textual content that includes text, HTML tags, and JavaScript code. Parsing process is the procedure of analyzing the document into a linear representation according to a given grammar [12]. It helps to tidy up the HTML tags and JavaScript code to make the content cleaner and more useful before extracting information from the content of document.
3.2.2. Tokenization
This process breaks a stream text up into many words, phrases, or other meaningful elements called tokens. After tidying up HTML content by parsing process, the extracted content is tokenized to many words. The amount of those words can be reduced without losing the document meaning by filtering and removing many popular linking words in the process called stop words removal.
3.2.3. Stop Words Removal
In computing, stop words are such words that are filtered out prior to, or after, processing of natural language data (text) [13]. They are usually the common words such as “the,” “a,” “an,” and “of” as in Table 1 that appear many times in document's content. Stop words removal is the process that filters and removes out such kind of words in order to improve the algorithm performance.
Example of stop words.

3.2.4. Stemming
In information retrieval, stemming is the process of reducing inflected words to their stems, base, or original form of word. Stemming programs are commonly referred to as stemming algorithms or stemmers. Ingason et al. [14] attempt to convert a word to its linguistically correct root which ultimately facilitates the reduction of all words that possess an identical root to a single one. This is obtained by removing each word of its derivational and inflectional suffixes [4]. For example, “went,” “goes,” and “gone” are all condensed to “go”—their base form.
3.3. Fingerprints Extraction
3.3.1. Primary Fingerprint of Document
A fingerprint of document is a hash value of its features. It is the 64-bit string that is generated by sim-hash algorithm [15]—a special hash function.
Hash function is an algorithm or program that maps data from a variable to a fixed length. The values returned by hash function are called hash values, hash codes, hash sums, checksums, or simply hashes. Most hash functions usually generate totally different hash values even for similar inputs.
For similarities detection purpose, sim-hash was proposed. This is a special hash function which was developed by Charikar [15]. This hash function is utilized to hash similar inputs to similar hash values.
Initially, a document is preprocessed to extract a set of keywords (tokens) from its content. We initialize an f-dimensional vector V with each dimension as zero. Each keyword is tagged with its frequency (the number of times it appears in the contained document). Here, for each keyword of document, it is hashed to f-bit hash value. The increase or decrease in the f components from these f bits depends on the weight of that word. In the next step, the components' sign determines the corresponding bits of the final fingerprint of document. The working procedure that applies sim-hash to generate a document to a 64-bit fingerprint is illustrated in Figure 2 and the pseudocode of the sim-hash algorithm is given in Algorithm 1 [1].
(1) (2) { (3) Init vector Sim (4) (5) { (6) Kw is hahsed into f bit Hash value X; (7) (8) { (9) (10) { (11) Sim[i] = Sim[i] + weight(Kw); (12) } (13) Sim[i] = Sim[i] − weight(Kw); (14) } //end if (15) } //end for (16) }//end for (17) (18) { (19) (20) (21) } //end for (22) }

Working procedure of the sim-hash algorithm.
3.3.2. Near-Similar Fingerprints Extraction
A document is represented by a unique fingerprint and the fingerprints of near-duplicate documents are usually different from each other in a few bits. To enrich the number of fingerprints, we extract near-similar fingerprints based on the primary one of a document. These fingerprints have a few bits of difference from the primary one.
The k positions in the 64 bits whose values are inverted in order to extract the near-similar ones are computed by calculating the combinations of k. The combinations can be taken from a set of size 64 using the following formula:
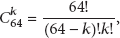
In this paper, the number of different bits is at most 2. In other words, k values used in this algorithm are 1 and 2. Finally, a document has
S64(1) = ( S64(2) = (
Main fingerprint is: 1101001011110010011010000110000100111000111001001010100011010100 Near-similar fingerprints: 1 1
(1) (2) { (3) Array Subset = Integer Array [NumberChangedBit]; (4) //init subset array (5) (6) { (7) Subset (8) } //end for (9) (10) { (11) Result.add (Clone of Subset); (12) i = NumberChangedBit − 1; (13) (14) { (15) i − −; (16) }//end while (17) (18) { (19) Subset[i] = Subset[i] + 1; (20) (21) { (22) Subset[j] = Subset[ (23) } //end for (24) } //end if (25) } (26) (27)}
3.4. Near-Duplicate Detection
A trie-tree data structure and meet-in-the-middle approach are utilized for near-duplicate detection. Whilst trie-tree is used to represent all the generated fingerprints of documents in the training phase, meet-in-the-middle strategy has an important role in detection procedure.
Trie-tree is an ordered data structure that is used to store a dynamic set or associate array, in which the keys are usually strings. Furthermore, it allows many strings with similar character prefixes to use the same prefix data and store the tails only as separating data.
Firstly, a trie-tree is initially created. After extracting the fingerprints of each document, they are inserted into the tree sequentially if they do not exist there. A complete tree is illustrated in Figure 3.

The fingerprints trie-tree.
After building the trie-tree in the training phase, it is used in near-duplicate detection phase. When a new crawled document is added, we apply meet-in-the-middle approach to detect near-duplicate documents. It means that a newly crawled web page is also analyzed and

Meet-in-the-middle example (1).

Meet-in-the-middle example when
4. Dataset and Evaluation
4.1. Data Set
As for checking the result of our proposed approach, we customize a part of the public dataset that is available on [16]. The whole of this dataset contains a subset of the WWW-pages that is collected from computer science departments of various universities in January 1997 by World Wide Knowledge Base (Web→Kb) project of the CMU text learning group [17]. From this dataset, we randomly pick up more than 1000 web documents and use these as the training dataset. Here, a subset contains 176 files and their contents are chosen and modified to create the training dataset including both duplicate and near-duplicate documents.
4.2. Evaluation
The following experiments are designed and carried out to check the performance and accuracy of our proposed method. Even though our experiment is done with a web pages dataset, it can also work well and achieve a good result in spam comments detection. In order to detect social spam, we will apply this method on a given spam comments dataset. In the other words, we will use spam comments dataset instead of using web pages collection to build trie-tree with the same processes.
First of all, we build the trie-tree from the training dataset. Each document is sequentially preprocessed by HTML parsing, tokenization, stop words removal, and stemming before generating many fingerprints from the set of most frequent tokens. Then, the trie-tree is built from those fingerprints and its structure as in Figure 3.
From a training dataset with more than 1000 web pages, the trie-tree's size is approximately 22 million nodes including the root node when the number of different bits between two fingerprints

Trie-tree size.

Time performance of training phase.

Time performance of testing phase.
In terms of evaluating the performance and accuracy of the proposed method, the experiment is done with the training dataset which includes 176 duplicate and near-duplicate documents. In this experiment, we choose the input data and the constant used in the proposed method as in Table 2.
The experimental input.

In the experiments we have chosen k to be 2, which means that the number of different bits is at most 2. Specifically, the set of fingerprints in this case includes not only 2-bit difference fingerprints but also 1-bit difference ones when comparing with the primary fingerprint. We can detect almost all of the duplicate documents and achieve high accuracy of near-duplicate detection, summarized in Table 3.
The experimental result.

Moreover, the time performance of our proposed method is definitely better than the previous work. Because they compare with all other documents, although the result is impressive, the time performance is
Near-duplicate detection is a vital issue in data mining. Many existing methods have been proposed to resolve this issue and achieved many different results [18]. Generally, we have compared several evaluation metrics of our result to the previous work [1] such as, precision, recall, and F-measure. These values are calculated by the following formulas:

The computed values in our paper are presented in Figures 9 and 10 with blue bars, whilst those of the previous work are shown with red bars.

Comparison of duplicate detection result.
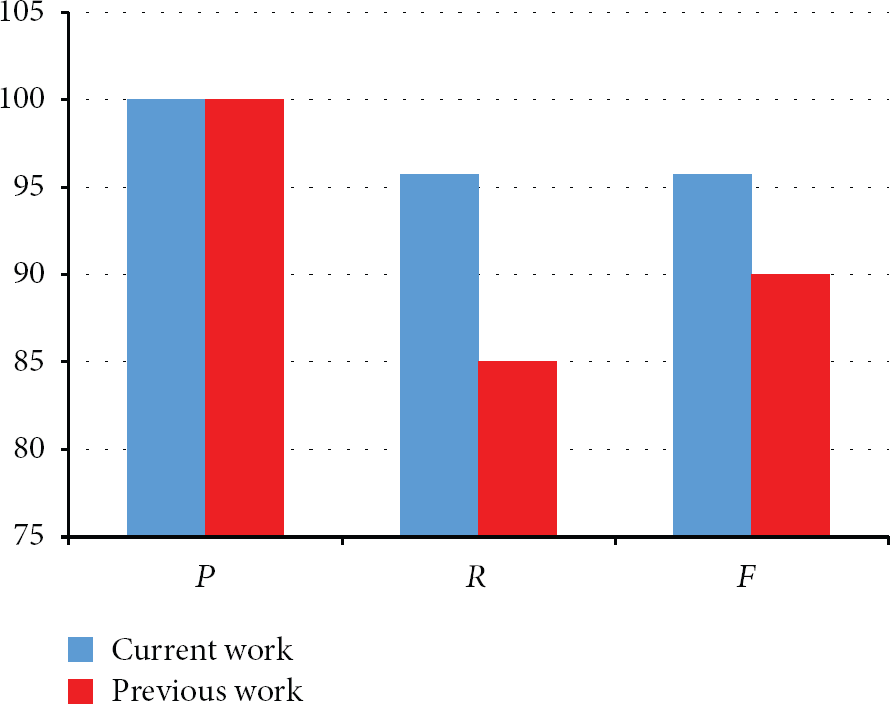
Comparison of near-duplicate detection result.
5. Conclusion
Social spam issue is one of important and serious threats in the social networking field. It is obvious that the social and security risks are increasing rapidly because of this issue. Recently, there have been plenty of algorithms that are proposed to resolve it based upon many different techniques. In this paper, we propose an effective method for detecting spam comments on the current social networking sites. By applying trie-tree data structure and meet-in-the-middle approach, our method can easily detect comments which have near-duplicate contents with the given spam collection. The experimental results have proved the effectiveness of our method in both accuracy and time performance.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research was supported by Next-Generation Information Computing Development Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT and Future Planning (2011-0029924) and MSIP (Ministry of Science, ICT and Future Planning), Korea, under the ITRC (Information Technology Research Center) support program (NIPA-2013-H0301-13-3006) supervised by the NIPA (National IT Industry Promotion Agency).