
Abstract
In accordance with the problem that the traditional trilateral or multilateral estimation localization method is highly dependent on the proportion of beacon nodes and the measurement accuracy, an algorithm based on kernel sparse preserve projection (KSPP) is proposed in this dissertation. The Gaussian kernel function is used to evaluate the similarity between nodes, and the location of the unknown nodes will be commonly decided by all the nodes within communication radius through selection of sparse preserve projection self-adaptation and maintaining of the topological structure between adjacent nodes. Therefore, the algorithm can effectively solve the nonlinear problem while ranging, and it becomes less affected by the measuring error and beacon nodes quantity.
1. Introduction
For most wireless sensor network (WSN) applications, it is essential to know the location of sensor nodes. Related researches show that, in the information related to the context of monitoring deployment area provided to the users, more than 80% is related to the information of location [1].
The self-localization algorithm of nodes can be divided into the two major categories: range-based and range-free [2, 3]. Range-based approaches have a relatively higher accuracy, but this final location estimation accuracy depends on the measuring accuracy. The most common measuring technologies include Radio Signal Strength (RSSI) [4], Time of Arrival (ToA) [5], Time Difference of Arrival (TDoA) [6], and Angle of Arrival (AoA) [7]. The measurement data of RSSI can be achieved during each data communication between nodes, and it does not occupy additional bandwidth and energy, so the hardware expense is relatively simple and cheap. These turn it into a hotspot research direction to use the RSSI measurement data to conduct localization. However, in a complicated monitoring environment, the measurement of RSSI signal is also affected by multiple factors; for example [8–10], the communication between nodes generally uses free common channel, which is inevitably interfered by other devices in the monitoring area; RSSI signal itself has multipath feature; the hardware of sensor node is relatively cheap, simple, and with poor operational capability, and in addition, the unstable production technique has also caused unstable quality of certain node products, blockage by static or moving obstacles in the monitoring area, and so forth. All these will provoke a large amount of uncertain factors in the collected signals and make the signal present nonlinearity.
Figure 1 shows the cause of nonlinearity in a complex environment. When the part between node

Distance measurement in complex environment.
The rest of the paper is structured as follows. In Section 2, we address the related work in the area of range-based localization schemes. In Section 3, we give a brief review of related concepts. And Section 4 presents our localization method. Section 5 shows simulated results, and Section 6 gives the conclusions.
2. Related Work
Related literature [11] generally divides the localization algorithm based on signal strength ranging into two types: one type uses empirical formula transformation to obtain the distance after obtaining the signal strength between nodes and then uses the trilateration method or multilateral method to obtain the location of unknown node; another type directly uses the signal strength information between nodes to obtain the similarity between nodes through the machine learning method, and then, the relation between nodes is mined in accordance with the similarity and the location of beacon node. The former depends on the empirical model, and classic methods include the RADAR system [12] and SpotON system [13]. They only can be applied to some scenarios with relatively unchanging environment, and in order to obtain the localization result with high accuracy, training calibration should be conducted to different environments, which might cost a large amount of manpower and material resources. If the fitting model is not accurate or the deployment scenario is modified, then the original model cannot reflect the relation between the Euclidean distances and RSSI values, the distance measurement accuracy is low, and it will result in undesirable localization effects. The latter regards the nodes in network as independently distributed devices, uses the RSSI measurement values between adjacent nodes, refers to the machine learning algorithm, trains and learns a prediction model in the deployment area, and further estimates the location information of unknown nodes in the area, such as the LANDMARC localization system based on k nearest neighboring (k-nn) [14], kernel principal component analysis (KPCA) localization algorithm [15], kernel canonical correlation analysis (KCCA) location estimation method [16, 17], and localization algorithm based on kernel locality preserving projection (KLPP) [18]. The range-based localization technology based on machine learning method is not sensitive to RSSI measurement error and it has the characteristics of low requirement for measurement technology and high self-adoption degree; therefore, it has attracted considerable attention.
The k-nn method [18] relies on the “nearest adjacent distance criteria” weighted idea to obtain the information of unknown nodes, its algorithm is a kind of linear algorithm, the k value is generally artificially set, and it has high randomness. In addition, when the nodes are assigned to a complicated environment, the RSSI measured values have a high nonlinearity, which would lead to poor localization result. For nonlinear data, the researchers find that it is a practical and effective solution to use the kernel method to build the mapping model. The kernel method [19, 20] maps the original data into an appropriate high-dimensional feature space through a certain suitable kernel function, which transfers the nonlinear problem difficult to solve in the original space into a linear problem in the feature space. By referring to the characteristics of the kernel method, this paper uses it to solve the nonlinear problem in the RSSI measured data.
A large number of related researches show that after kernel function and training set are given, the kernel matrix (or Gram matrix) can be built, and the real internal structure of data can be disclosed in accordance with the similarity provided by the kernel matrix. The KPCA and KCCA localization algorithms taking into account this theory have been proposed successively.
KPCA is an extension of principal component analysis (PCA) [21] using techniques of the kernel method. Using kernel method, the nonlinear data is mapped into a high-dimensional feature space and then PCA is employed in feature space. The linear PCA in the high-dimensional feature space can best represent the projection of original data in order to realize dimensionality reduction and denoising of data. KCCA is also a kind of dimensionality reduction method similar to KPCA, and different from KPCA; by building the mapping of signal space and physical space in the feature space, the localization method based on KCCA makes it possible for the nodes to use RSSI values to deduce back the relative topological structure of their physical space and then calculate the location of these nodes. However, both of the KPCA and KCCA computations have adopted a global nonlinear mapping algorithm, which is simple and highly efficient, and although it can obtain good results under some situations, it has ignored the data distribution and failed to consider that the data have the local distribution feature. In addition, the KCCA algorithm is only applicable to fingerprint-based database for indoor localization, and it requires artificially collecting the training datum and building the distribution diagram of the relation between RSSI and Euclidean distances beforehand. During localization, in accordance with the distribution diagram obtained during previous training, k nearest access points (APs) will be found, and their center of mass will be used as the estimated location, and if the APs density is not high enough, it requires further iterative operation. Therefore, the KCCA estimation algorithm does not apply to the random deployment environment or any scenarios that cannot be reached by human.
Based on that, Wang et al. [18] used the KLPP algorithm and proposed the KLPP-based localization algorithm. The KLPP localization method uses the kernel function to measure the similarity between nodes, and after the RSSI values are mapped into the feature space, it uses the LPP algorithm [22] to construct the adjacency graph between nodes, which formulates the localization problem as a graph embedding problem and allows us to consider the topological structure of the networks. The KLPP-based localization method uses the kernel method to solve the nonlinear problem of RSSI values; by using the adjacency graph, the location of unknown nodes is commonly decided by their adjacent nodes, so the measurement error caused by remote beacons during the process of traditional multilateral or trilateral method is avoided, and the impact by the number of beacon nodes is small.
However, the KLPP algorithm is overly dependent on the adjacency graph, while the construction of the adjacency graph mainly use k-nn and ε-ball approaches [23]. The k-nn and ε-ball methods are the two most popular ones for graph construction in the literature. The k-nn graph method chooses k nearest adjacent samples, while the ε-ball method chooses the samples which falling into its ε-ball neighborhoods are linked to it. In addition, the weight of side in the graph is generally obtained through methods like binary, Gaussian kernel, or
Figure 2(a) shows traditional multilateration or trilateration localization, whose measurements are made only between an unknown location sensor and known location sensors. When the location of beacon nodes is relatively far, the measurement error will definitely be bigger; in addition, the algorithm does not consider the impact of other nodes surrounding this node, so the location obtained through traditional method has a low location estimation accuracy. Figure 2(b) shows the LE-KLPP method; if its k-nn graph only chooses three pairs of sensors, then this algorithm has obviously ignored the impact of some other nodes in the adjacent area, so the location estimation result is not ideal. Figure 2(c) shows the LE-KSPP method, because each node can automatically obtain the neighbors with information through SP. The information of neighbors can be utilized to aid in the location estimation and enhances the accuracy and robustness of the localization system.

Traditional multilateration localization methods, LE-KLPP localization method, and LE-KSPP localization method.
3. Related Concepts
3.1. Kernel Method
The kernel method is one of the current hot topics in the field of artificial intelligence and machine learning, and it is based on statistical learning theories and kernel technology. As early as 1964, during research of potential function, Aizerman et al. [30] introduced the idea of kernel function as the inner product of feature space into learning field. However, it was until 1992 when this idea attracted the attention of Boser et al. [31]; they combined it with large margin hyperplane to generate support vector machine (SVM), and since then, the concept of kernel method has become one of the mainstream directions of machine learning literatures. Kernel method using the feature function ϕ embeds data into the feature space, so that the nonlinear data are presented linear model in such space, as showed in Figure 3.

Principle of kernel method.
In accordance with Figure 3, we can see that the basic idea of kernel method is to map the random vector datum in the input space into a higher feature space by using nonlinear function, and then, the linear learning algorithms are designed in this higher-dimensional feature space. The kernel method generally uses a kernel function to pack the nonlinear relation between input space and output space, and generally speaking, the solutions of any kernel methods consist of two parts, that is, a module and a learning algorithm. The module executes the process of mapping into the embedding or feature space, while the learning algorithm is used to find out the linear patterns in that space. The modularity of kernel methods proves its reusability as the learning algorithm. The matching algorithm can be combined with any kernel function, so it can be used in any data domain. The kernel component is for specific data, but it can be set with different algorithms to solve the task within the full range that we consider. Figure 4 shows the stages involved in the application of the kernel method.

The stages involved in the application of kernel methods.
The kernel function is a potential nonlinear and parametric equation of input variable. The kernel function relies on the input and output variables to realize control of parameters, and for the localization algorithm, the input variable is the input RSSI values matrix, and the output variable is relative coordinate of nodes. Therefore, the key of machine learning is estimation of parameter based on known input and output data. Consider there exists such a mapping, and assume a training sample set
Definition 1.

The purpose of the map ϕ aims to transform the nonlinear relation into a linear relation. This kind of change to the input space can generally increase the learning efficiency, but in addition to enriching the function expressive ability, a higher-dimensional feature space can also increase the amount of computation, which correspondingly reduces the generalization ability of learning algorithm. Therefore, we need an implicit way to complete the data change process, and in the kernel method, this kind of direct computation process is called kernel function.
Definition 2.
A kernel is a function κ that for all


Kernel function can use the inner product as the direct function of the input space, it can calculate the inner product more efficiently, which makes the feature space with index dimension or even infinite dimension possible, and it does not need to explicitly calculate the mapping ϕ. In other words, the kernel method uses a predefined kernel function to express the inner product of two sample vectors in the feature space, and it does not need to directly realize nonlinear mapping of the sample, so during use, it does not need to know the specific form of nonlinear mapping.
During actual application, there are three kinds of common kernel functions: polynomial kernel function, sigmoid kernel function, and Gaussian kernel function (also called radial basis kernel function) [19]. Of these, the Gaussian kernel function has the characteristic of maintaining the distance similarity of input function; this paper chooses the Gaussian kernel function to calculate the similarity between nodes, and its definition is as follows:
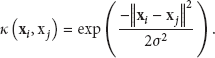
3.2. Kernel Sparsity Preserving Projections
First of all, KSPP uses the kernel method to map the data into a higher feature space, which makes it linearly separable in the higher feature space; then, it uses the SPP method to construct the adjacent matrix of sample data in the higher-dimensional feature space; finally, the adjacent matrix is used to conduct feature extraction through the graph embedding method.
Assume there is a set of training sample

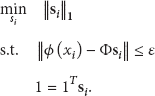

At this moment, the formula can be solved to obtain the estimated vector of SP coefficient,

Through deduction similar to SPP, we obtain the optimization criteria for KSPP; that is,
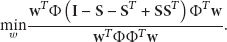
Then, the criterion is transformed to a solution of the generalized characteristic equation:

Left-multiply
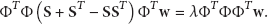
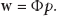
The generalized characteristic equation can be simplified to

Solve the eigenvectors of the first d corresponding maximum eigenvalues
K is the inner product of data in the feature space calculated by kernel function; that is,
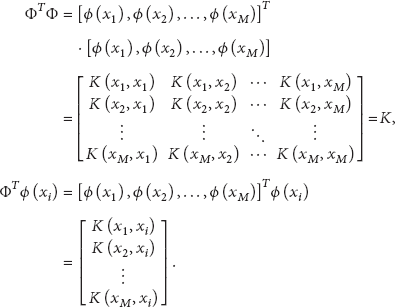
After KSPP projection, the ith new eigenvector is
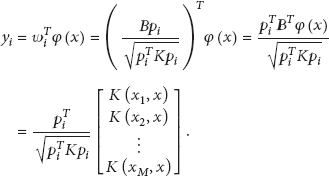
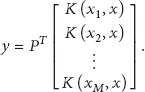
4. Localization Algorithm with KSPP
4.1. The Connection between Kernel Function and Localization
The localization algorithm based on kernel method uses a kernel function to map the RSSI vector between nodes into corresponding feature space. In this space, after a linear algorithm is used to calculate the relation between nodes, it is projected into the coordinate space; that is, through the kernel function, the RSSI vector
In accordance with Figure 5, we can see that when the communication radiuses of two nodes have intersection, then direct communication can be conducted between these two nodes; the weaker the formed RSSI vector is when two nodes have received the RSSI signal of other nodes in the network, the farther the actual distance between them is, which means the less similar they are; the closer the distance between two nodes, the stronger the RSSI vector between them formed by other nodes in the area.
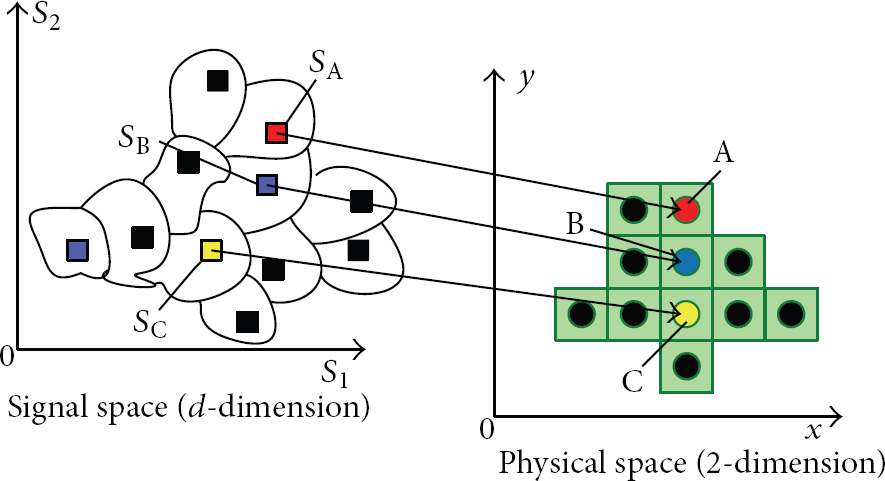
Correlation between the signal and physical location spaces.
In addition, in the literature [16], Pan proved that when the nodes are deployed in an idyllic environment, the RSSI matrix is positive semidefinite, so we can believe that the RSSI matrix itself is a kernel function matrix. Therefore, we can use the kernel method to measure the similarity between samples, which means the kernel function implicitly embeds the RSSI data into the feature space, and the linear algorithm is used in the feature space to solve the nonlinear relation of RSSI in the Euclidean space.
Assume in the monitoring area, n nodes generate n samples
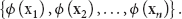
Furthermore, the closer the nodes in the area are, the more similar the signal strength that they have received from other nodes is; therefore, we can believe the signal strength space and feature space H are related, and


The LE-KSPP algorithm can be utilized to obtain the relative location between nodes, but in most applications, the absolute coordinate of nodes should be obtained; therefore, the obtained relative coordinate should be transformed to absolute coordinate. If the system has provided adequate beacon nodes (in 2-dimensional space, at least three beacon nodes are required, and in 3-dimensional space, at least four beacon nodes are required), the relative coordinate of nodes can be transformed to absolute coordinate from relative to absolute. Assume the estimated absolute coordinate

Through deduction, we can obtain the estimated coordinate of unknown node is



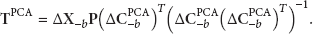
At this moment, the absolute coordinate of unknown nodes can be obtained through the following formula:
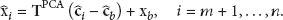
Consider there are n sensor nodes
About the LE-KSPP localization algorithm, see Algorithm 1, in which Steps (1) to (3) use the RSSI values between nodes to conduct training and learning; in Step (4), each node uses its adjacency relation with other nodes and estimates the relative coordinate of node through the training and learning model; by referring to the absolute location of beacon node, Step (5) transforms the node location of relative coordinate obtained in the area to absolute coordinate.
Input: Beacon node coordinate: RSSI vector between nodes Output: Estimated coordinate of unknown nodes (1) By using the collected RSSI vector between nodes between nodes is calculated through Gaussian kernel function to form the kernel matrix K; (2) By solving the constrained optimization problem (See (6)), we obtain the kernel sparse representation coefficient combination to obtain the kernel sparse reconstructed adjacent matrix; (3) Solve the optimal projection vector generalized characteristic equation and their corresponding eigenvectors (4) Through (20), obtain the relative coordinate matrix; (5) Use the beacon nodes in the monitoring area, and transfer the relative coordinate into absolute coordinate; if the beacon nodes have a collinear or near collinear relation, adopt (26); if not, obtain the absolute coordinate of unknown node through (22).
5. Simulation and Experiment
Consider a WSN which is comprised of n nodes
Related literature [20] points out that the received signal strength s between nodes has a certain proportional relation with their distance d. In an ideal environment, node i is within the communication radius of node j, and the signal strength and distance have the following relation:

This section analyzes and assesses the performance of LE-KSPP localization method through experiment and simulation. In the experiment, the nodes were assigned in a two-dimensional space, and measurement of the distance between nodes adopted the range model-based simulation experiment and actual measurement-based data set, respectively. The parameters involved in the range model are fit with the values collected by Patwari [32], and the actual measurement data set is the RSSI data collected by Patwari experiment team [33] in a
Because it is difficult to evaluate performance by using relative coordinate, we adopted absolute coordinate to express location of nodes in this experiment. We also compare our LE-KSPP algorithm, which is built on one kind of graph embedding localization, with the same kind of algorithms such as MDS-MAP [34], Isomap [35], and LE-KLPP [18]. In addition, the location accuracy of ours and KLPP are both related to kernel function, which is called Gauss kernel function in our selection. We also found there is a certain relationship between kernel parameter σ and the distance between training samples, so in the experiment we assume the average distance between sample nodes of σ (4) as 50 times, and the cumulative variance contribution rate of PCA as 90%.
The paper utilizes Average Localization Error (ALE) performance index to evaluate the performance of the algorithm. The formula is shown as follows:
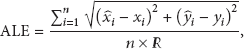
5.1. Localization Results with Range Model-Based
In order to compare the impartiality of the experimental results, when the measurement information is based on signal strength model, in this section, the signal model in literature [32, 33] is used to simulate the signal strength between the nodes:

Among these,
5.1.1. Regular Deployment
In this group of experiments, the nodes were regularly deployed in a
Before analyzing performance of LE-KSPP algorithm, let us first investigate the two final localization results under different deployment. In Figure 6, the circles denote the unknown node and the squares are the beacon, the line connects the actual coordinate and estimated coordinate of unknown nodes, and the longer the line is, the more the estimated value deviates from the actual location. Figure 6 indicates the localization results for each node under regular deployment with 10 beacons. The LE-KSPP algorithm of ALE for this uniformly deployed network is about 14.9% (Figure 6(a)) and 19.9% (Figure 6(b)).

Localization result with 10 beacons under regular deployment.
Figure 7 describes the impact of the beacon nodes number (from 5 to 15) on the ALE of the two localization algorithms of four localization algorithms in a regularly deployed network. They are regularly deployed in two blocked and unblocked environments, respectively. We can note that our algorithm always obtains the best results. Different with the MDS-MAP, Isomap and LE-KLPP, the localization accuracy of our algorithm raises with the increase of beacon nodes. This is because LE-KSPP method can reconstruct the relation between nodes through SP, and opposed to other methods, it can more self-adaptively choose and decide the node number and weight around its location.

ALE with different number of beacons.
5.1.2. Random Deployment
In this group of experiments, 200 nodes were randomly deployed in a
Similarly, the two definitive localization results were analyzed first. As showed in Figure 8, in these two experiments, the number of beacon nodes is still 10. Under the unblocked situation, LE-KSPP is about 17.5%; the corresponding ALE is 24.6% under the blocked situation.
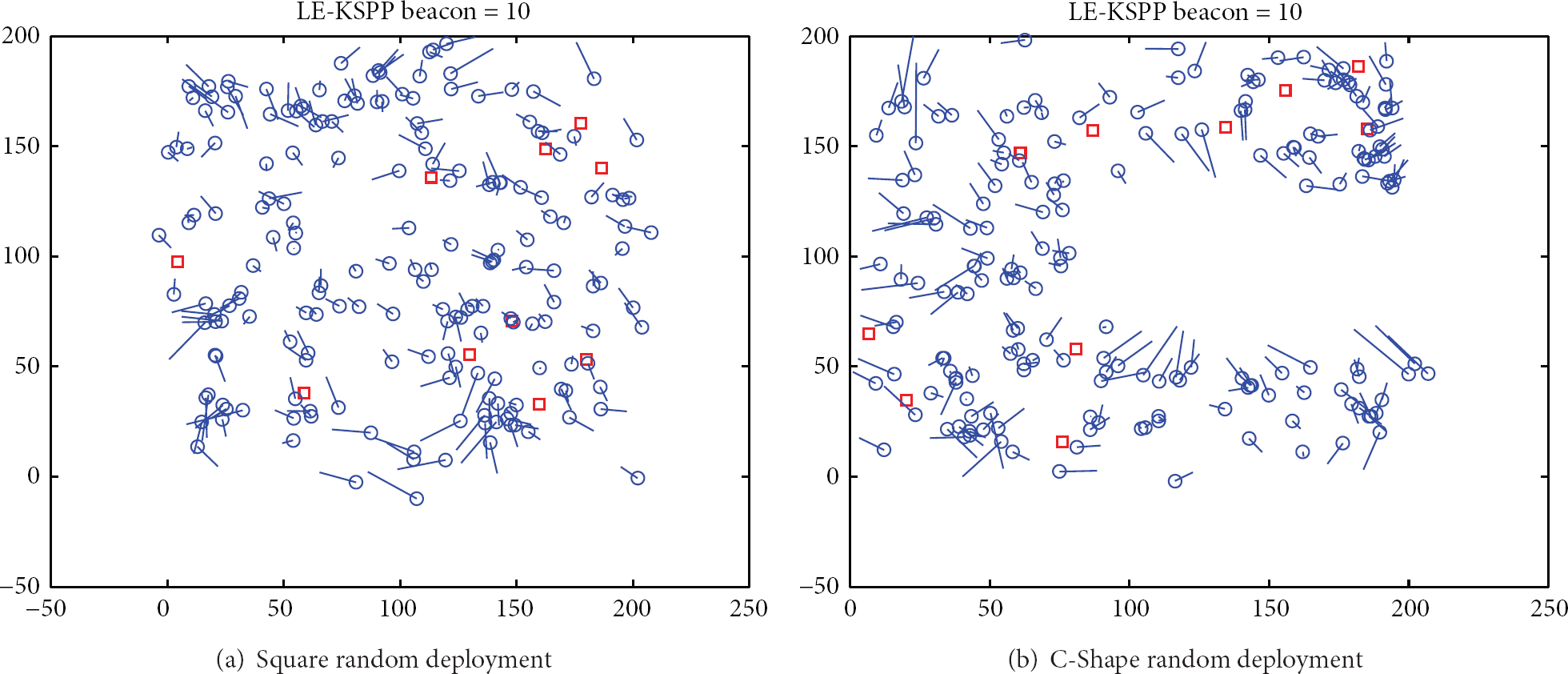
Localization result with 10 beacons under random deployment.
In Figure 9, for the randomly placed sensor network, we also compare it with the other algorithms (i.e., MDS-MAP, Isomap, and LE-KLPP) under different number of beacons. We can see that our algorithm always achieves the minimal average location error. When the number of beacons is 5 and 7, the ALE of value of MDS-MAP and LE-KLPP is even bigger than 40%, respectively.

ALE with different number of beacons.
5.2. Localization Results with the Actually Measured Data Sets
The literature and experiment of Section 5.1 show that the LE-KLPP has a better performance than the MDS-MAP and Isomap algorithm; therefore, only LE-KSPP algorithm and LE-KLPP algorithm are compared in this group experiment. The experimental data come from the SPAN lab, and the experimental scenario is as shown in Figure 10.

Actual collection area.
By using the data set mentioned above, this paper has compared the localization performance of the LE-KLPP and LE-KSPP algorithms, and see Table 1 for the experiment results. In accordance with Table 1, we can see that under separate communication radius (CR), the localization accuracies of LE-KSPP are all higher than the LE-KLPP algorithm, and the ALE has an increase of more than 10%.
The ALE of LE-KLPP and LE-KSPP with actual RSSI-based ranging.

Figure 11 shows the localization result under the communication radius of 7.5 m. In the figure, we can see that the closer these two algorithms are to the beacon node point, the smaller the estimated error is, which means, because the beacon node has an accurate location, it is more accurate to use it to determine the location of unknown node; in Figure 11, the LE-KLPP algorithm is used, because it artificially sets parameter k and it causes that an optimal solution (short line) can be obtained in certain area (far from the beacon node), while in some area, it does not apply (long line); in Figure 11, the LE-KSPP algorithm is chosen, because SP is used to self-adaptively obtain the number of adjacent points and the obtained estimation value is relatively stable (the length of line does not have big change).

Location estimates with actual RSSI-based ranging.
6. Conclusion
This paper studies the localization problem of sensor network nodes built on signal strength, and the LE-KSPP algorithm is proposed. This LE-KSPP utilizes the kernel method to map the signal strength to a higher-dimensional feature space and conducts SP, and then, the SP coefficient of the obtained signal set is obtained through SP. Because the data in a higher-dimensional feature space have better linear separability, the SP can self-adaptively capture the “local” structure of data, and different sample points are automatically endowed with different “adjacency” number and parameter selection is avoided, which makes the algorithm more applicable to different environments.
The experiments in this paper show that the proposed LE-KSPP algorithm can obtain relatively satisfying localization results on both range model and actually measured data, the impact of the beacon nodes number and blockage on this algorithm is small, and it can self-adapt to various network topology environments, which has a high robustness.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The paper is sponsored by Natural Science Foundation of China (61272379), Prospective and Innovative Project of Jiangsu Province (BY2012201); Provincial University Natural Science Research Foundation of Jiangsu Education Department (12KJD510006, 13KJD520004); Doctoral Scientific Research Startup Foundation of Jinling Institute of Technology (JIT-B-201411).