
Abstract
RFID is a practical technology that supports extensive applications such as warehouse management, asset tracking, and transportation and logistics. Identifying the missing tags in categorized RFID systems is of practical importance for a variety of applications but is not yet thoroughly investigated. Traditional missing tag identification approaches can not solve the problem efficiently because they do not distinguish categories, leading to long scanning time and high energy consumption. To achieve time and energy efficiency, this paper proposes three protocols. First, we formally formulate the problem of missing tag identification in categorized RFID systems. And then a compact structure is proposed to active tags in protocols which carries a large volume aggregated tag ID information. To further improve the utilization rate of a frame, we design a rehash scheme to change empty slots and collision slots into singleton slots. We evaluate the performance of our protocols with extensive simulations. Compared with the physical-layer missing tag identification protocol (P-MTI), which is the state-of-the-art missing tag identification technology, our best protocol reduces the execution time up to 99.8%.
1. Introduction
Radio frequency identification (RFID) [1] has been widely employed in extensive applications such as warehouse management [2], transportation and logistics [3–5], and asset tracking [6, 7]. Compared with the existing barcode, RFID tags can be read wirelessly over a number of feet (passive RFID tags) or even hundreds of feet (active RFID tags). Meanwhile, a RFID tag has storage and computation capabilities. The data can be automatically read, eliminating the trouble of manual scanning. Their new functions have advantage over the barcode system that they extend the operational range and improve its reading accuracy in a variety of applications.
There are two major features in most of the current RFID systems. First, they are categorized systems. It is because each RFID tag not only has an inherent ID but also belongs to a category according to the product which it is attached to [8]. Such feature can be easily found in RFID system such as the systems in Walmart [9] and Hong Kong International Airport [10]. Hence, the methods in RFID systems should be able to distinguish the different categories. Second, RFID systems are large-scale systems. The quantity of the tags may scale up to millions in practical RFID systems. Many large-scale RFID systems can be seen in [11–13]. For this reason, the methods in RFID systems should be able to adapt to the increasing quantities of the tags.
The problem of missing tag identification has attracted wide attention due to its practical importance. Recently, many novel protocols have been proposed to identify the missing tags [13–15]. Typically, those approaches identify the missing tags for monitoring range of all RFID tags and do not distinguish categories. This will lead to time and energy inefficiency. However, the categorized system is very common in our daily life. For example, in the airport luggage management, considering the huge traffic every day, tens of thousands of pieces of luggage have to be dealt with. Luggage losses often happen due to theft or other reasons. Thus, passengers cannot timely access their luggage after they arrive which leads to tremendous financial losses for customers and industries. As we know, passengers check in the luggage according to different airlines and each piece of luggage is sorted to different categories according to different flights. Administrators want to know whether the luggage of a specific flight is complete or not.
The problem also exists in other applications such as warehouses, mega factories, hospitals, and military bases. In a large warehouse, there are different categories of merchandise such as clothes, shoes, watch, and jewelry. Managers want to know whether the merchandise of a specific category especially valuable categories is missing or not. Hence, an efficient categorized missing tag identification procedure will be greatly helpful.
There are two main challenges for identifying the missing tags in categorized RFID system. First, many applications may frequently run the protocol and need to receive a timely report of the missing tags. Thus, we need an efficient method to identify the missing tags as quickly as possible. Traditional missing tag identification approaches are not suitable because those approaches do not distinguish categories, leading to long scanning time. Meanwhile, in the process of previous missing tag identification, we find that some slots of a frame are wasted. Thus, the utilization rate of a frame still has room to improve. Second, how to solve the problem of energy consumption is another challenge. We only want to know the information of a specific category. All tags in RFID systems participating in will lead to energy wasting.
To address the above challenges, we propose three protocols for identifying the missing tags in categorized RFID systems. Our protocol design follows two guidelines to achieve time efficiency. One is to keep RFID tags which are not in the wanted category from participating in protocol. The other is to reduce radio collision that makes the information which is reported from the tags not be wasted. To achieve these goals, our three protocols add on top of one another, to improve the system performance. More specifically, the baseline protocol eliminates the transmission collision among the tags and avoids RFID tags which are not in the wanted category participating in protocol. The second protocol utilizes the Bloom filter as a tool to activate all tags in the wanted category. The protocol uses a compact structure to activate the tags and does not require any tag ID to be transmitted. Our last protocol further improves the second protocol by changing empty slots and collision slots into singleton slots. Here, empty slot means no response from tags in the slot; singleton slot means only one tag responds in the slot; collision slot means more than one tag responds in the slot. To achieve time efficiency, much prior work concentrates on how to turn the collision slots into singleton slots. And we found empty slots also account for a proportion of a frame. Hence, our protocol utilizes the empty slots and reduces collision slots that greatly improve the time efficiency. We analyze the protocol performance to obtain optimal parameter settings which are able to significantly reduce the time and energy overhead according to particular accuracy requirement.
Our contributions of this paper are briefly summarized as follows.
We formally introduce the problem of missing tag identification in categorized RFID systems.
We propose three protocols that utilize a compact structure and reduce collision slots of a frame which significantly improve the time and energy efficiency.
Compared with the physical-layer missing tag identification protocol (P-MTI) [15], which is the state-of-the-art missing tag identification technology, our best protocol reduces the execution time up to 99.8%.
The rest of the paper is organized as follows. The related work is presented in Section 2. In Section 3, we present the preliminaries of this paper. We give detailed description on our protocol and analyze system parameters in Section 4. The performance evaluation is illustrated in Section 5. Finally, we conclude this paper in Section 6.
2. Related Work
One closely related problem is RFID identification which aims at identifying the tags through collision arbitration [11, 16]. Existing RFID identification protocols can be generally classified into two categories: Aloha-based [17–23] and Tree-based [24–28] protocols. In Aloha-based identification protocols, the reader first broadcasts the query request to tags. Upon receiving such a request, each tag randomly chooses a time slot to transmit its ID. If a time slot happens to be selected by only one tag, then the tag can be successfully identified and will keep silent for the rest of the identification process. If more than one tag selects a time slot simultaneously, the responses are garbled due to tag-tag collision and the tags cannot be identified. Therefore, the tags need to retransmit and the process continues until all the tags are identified successfully. In Tree-based identification protocols, the reader queries the tags to detect whether any transmission collision occurs. If there are any tag-tag collisions, the reader continuously splits signal-collided tags into two subsets until all tags can be successfully identified. While the RFID identification protocols cannot be directly borrowed to address the missing tag identification problem in categorized RFID systems, the execution time increases with the number of tags and the communication overhead could be excessively high in categorized RFID systems.
Rather than identifying the RFID tags, the cardinality estimation protocols estimate the number of tags [12, 29–31], which may serve as primary inputs for tag identification. However, such approaches cannot be directly borrowed to address the categorized missing tag identification problem because they only provide an approximate estimation of tag number.
Recently, many efforts study the problem of tag monitoring and missing tag identification [2, 13–15]. Tan et al. [2] design a missing tag monitoring protocol (trust reader protocol: TRP) which can detect the missing tag events with probability α when the number of missing tags exceeds m. α and m are system parameters. However, TRP cannot detect the missing tag events with certainty and it cannot identify which tags are missing. In [13], Li et al. propose a missing tag identification protocol. Their optimal protocol (iterative ID-free protocol: IIP) can detect the missing tag events with certainty and identify the missing tags. In [14], Zhang et al. propose more efficient protocols and utilize multiple readers that can reduce the execution time. In [15], Zheng and Li look into the aggregated responses instead of focusing on individual tag responses and extract useful information from physical-layer symbols. They leverage the sparsity of missing tag events and identify the missing tags through compressive sensing. Opposite to the purpose of identifying the missing tags of all RFID tags in the monitoring region, in this work we focus on identifying the missing tags in categorized RFID systems.
3. Preliminaries
In this section, we will first introduce the system model which helps to understand the working process of the RFID system and then present the problem formulation of identifying the missing tags in categorized RFID systems.
3.1. System Model
In our model, the RFID system consists of three main components: a large number of RFID tags attached to items, a number of RFID readers that monitor the tags, and a backend server that has powerful computation capability. The backend server connects to the RFID readers through high speed and reliable wireless network such as Gigabit Ethernet. We focus on the communication between RFID readers and tags rather than the backend server. The RFID readers transmit commands of the backend server and later report responses back to the backend server. When multiple readers are synchronized, we logically treat them as one.
The RFID system may use battery-powered active tags that have larger transmission ranges or use passive tags that are energized by radio waves transmitted by the reader. The EPC global Class-1 Gen-2 standard [32] specifies several mandatory commands to regulate the RFID tags. It provides flexibility for RFID manufacturers to implement value-added features. Such an open design motivates researchers to explore new features of RFID tags for practical needs with currently available components (e.g., random number generator [32], lightweight hash function [33], etc.). We note that such routine components are widely implemented in current RFID tags. In this paper, the tag needs lightweight hash function.
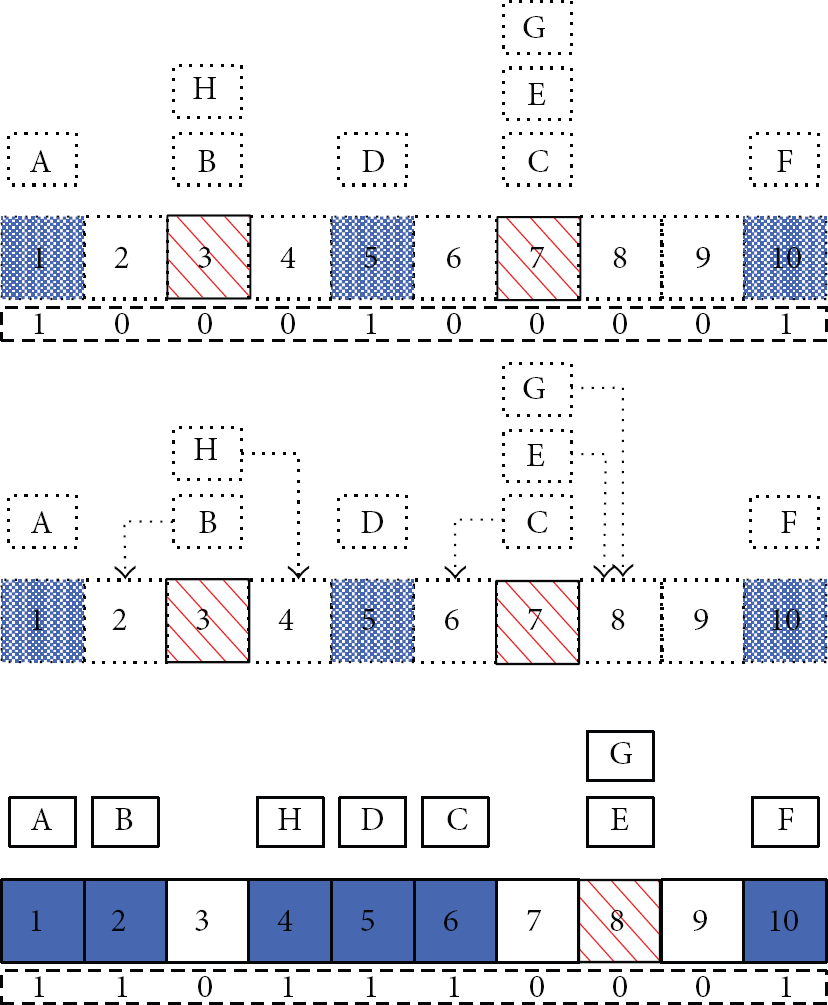
In this paper, the RFID system works on a slotted Aloha model. According to the EPC global Class-1 Gen-2 standard [32], the reader communicates with the tags with the framed slotted Aloha protocol. In this standard, each tag contains a unique 96-bit ID. The communication between the reader and tags is composed of frames and each frame is further divided into time slots. The reader initiates communication by broadcasting commands and parameters to tags, for example, random number for hash function and number of time slots in one frame. Upon receiving the command, each tag will randomly select one slot to respond to the reader. If there is no response from tags in a slot, the slot is called an empty slot. If only one tag responds in a slot, the slot is called a singleton slot. In this case, the reader can decode the response successfully. If more than one tag responds in a slot, the reader cannot decode those responses because the signals collided; the slot is called a collision slot. Figure 1 illustrates an instance where 8 tags (A~H) contend for 10 time slots.

Framed slotted Aloha: 8 tags contend for 10 time slots.
A singleton slot or a collision slot is also called a nonempty slot. If the RFID reader only needs to know whether one slot is empty slot or nonempty slot, each tag can transmit one-bit short response in the selected slot. If the reader receives response in the slot, it indicates there has been a tag (tags) that selects the slot. Therefore, the slot is nonempty slot and it can be encoded as “1.” The empty slot can be encoded as “0.” The length of a short response can be denoted by
3.2. Problem Formulation
We consider a large-scale RFID system with
Key notations.


Categorized missing tag identification.
The database alters according to the changing conditions. When new items are moved into the system, the tag IDs will be read into the database. When the items are moved out the system, they will be removed from the database. Even if a failure incurs such database information loss, we can recover it by executing an ID-collection protocol [21–23] that reads the IDs from the tags. In this case, we will not identify the missing tags that have already been lost. However, now that we have a database of the remaining tags, we can identify the missing tags after this point of time.
4. Protocol Design and Analysis
In this section, we propose three new protocols for identifying the missing tags in categorized RFID systems. We first give a baseline protocol which eliminates the transmission collision among the tags. We further propose a categorized missing tag identification protocol to avert any tag ID transmission. On top of it, we propose an enhanced categorized missing tag identification protocol to achieve time efficiency. In addition, we analyze system parameters of the protocols.
4.1. Baseline Protocol
We know that directly implementing the aforementioned missing tags identification protocols in set

In practical large-scale RFID systems, the number of tags can scale to millions, while the number of tags in the wanted category is usually much smaller. Since the aforementioned missing tags identification protocols do not distinguish the categories, therefore the baseline protocol significantly reduces the time. We compare the execution time of P-MTI (with

Execution time: baseline versus P-MTI.
Although the baseline protocol demonstrates a promising performance improvement, it suffers from some limitations. In the baseline protocol, the transmission of query message takes a large portion of the execution time. Moreover, unique tag IDs are explicitly transmitted and acknowledged on the air which leads to potential privacy leaks. Therefore, it motivates us to design a more efficient and secure categorized missing tag identification protocol.
4.2. Categorized Missing Tag Identification Protocol (CMTI)
Based on the baseline protocol, we propose a categorized missing tag identification protocol (CMTI) to further reduce transmission overhead. In particular, we use the Bloom filter as a tool to carry aggregated tag ID information which is capable of encoding itemized information in a hashed Boolean vector. We transmit the vector instead of explicit tag IDs to activate the tags in wanted category
4.2.1. First Phase
We activate the wanted tags by using a Bloom filter produced by the tags in
At the beginning of the phase, the backend server constructs a Bloom filter vector by mapping the tags in the wanted set
4.2.2. Second Phase
We identify the missing tags in the wanted category. At the beginning of this phase, the RFID reader transmits a request with two parameters f and r, where f is the frame size and r is a random number. The frame that consists of f short-response time slots follows the request. Upon receiving the request, each tag is pseudorandomly mapped to a slot at index
After receiving responses, the RFID reader measures the state of the slots. Since the one-bit short response can only successfully verify the tags which is mapped to a singleton slot, the RFID reader constructs a vector that consists of f bits, representing the actual state of the slots. In the vector, “0” indicates empty slots or collision slots and “1” indicates singleton slots. The RFID reader transmits the vector; each tag checks it at corresponding position according to its responding slot. If a tag sees that its bit in vector is “1,” it means that its slot is a singleton slot and the tag will not participate in the following protocol execution. The unverified tags execute the same second phase until they are all verified. The frame size f will change on the basis of the number of unverified tags.
If the size of a vector is too long, the RFID reader divides it into segments of 96 bits which are equivalent to the length of the tag ID. Each segment is transmitted in a time slot of size
4.2.3. Analysis
In the following, we determine an appropriate size of the two phases.
In the first phase, the execution time is
So the total execution time is
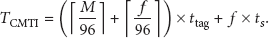
Under our protocol, if a slot is a singleton slot, the corresponding tag can be verified. The probability for singleton slots is
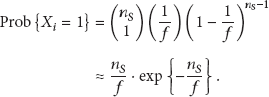
Let

Thus, we can have the average time for verifying the presence of one tag as follows:

We let

Average time of CMTI for verifying the presence of one tag with respect to the load factor ρ.
In (5), we can see that the average time depends on ρ which is determined by
In CMTI, we use the Bloom filter as a tool to activate the tags in the wanted category
4.3. Enhanced Categorized Missing Tag Identification Protocol (ECMTI)
Based on the CMTI, we propose an enhanced categorized missing tag identification protocol (ECMTI) to improve the utilization rate of the frame. Our final protocol consists of two phases. We also use a Bloom filter produced with the tags in
4.3.1. Second Phase
When a slot is a singleton slot, the corresponding tag can be verified. We know the probability of a slot turning to be a singleton slot from (3). Hence, we have

where the probability reaches its maximum value when
Since the RFID reader knows the wanted tags’ IDs, it knows in which slot each tag is supposed to respond. At the beginning of the second phase, the RFID reader transmits a request with parameters f,
After receiving responses, the RFID reader measures the state of the slots in the same way as CMTI does. Each tag checks the vector to determine whether it participates in the following protocol execution. The unverified tags execute the same second phase until they are all verified. Figure 5 shows the process of the second phase.
The process of ECMTI in the second phase: (1) transmission of a request with parameters f,
4.3.2. Analysis
In the following, we determine an appropriate size of the two phases.
In the first phase, the execution time is the same as the CMTI protocol:
So the total execution time is

Under the ECMTI protocol, the probability for singleton slots is

We define
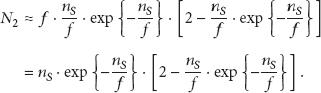
Thus, we can have the average time for verifying the presence of one tag as follows:

And
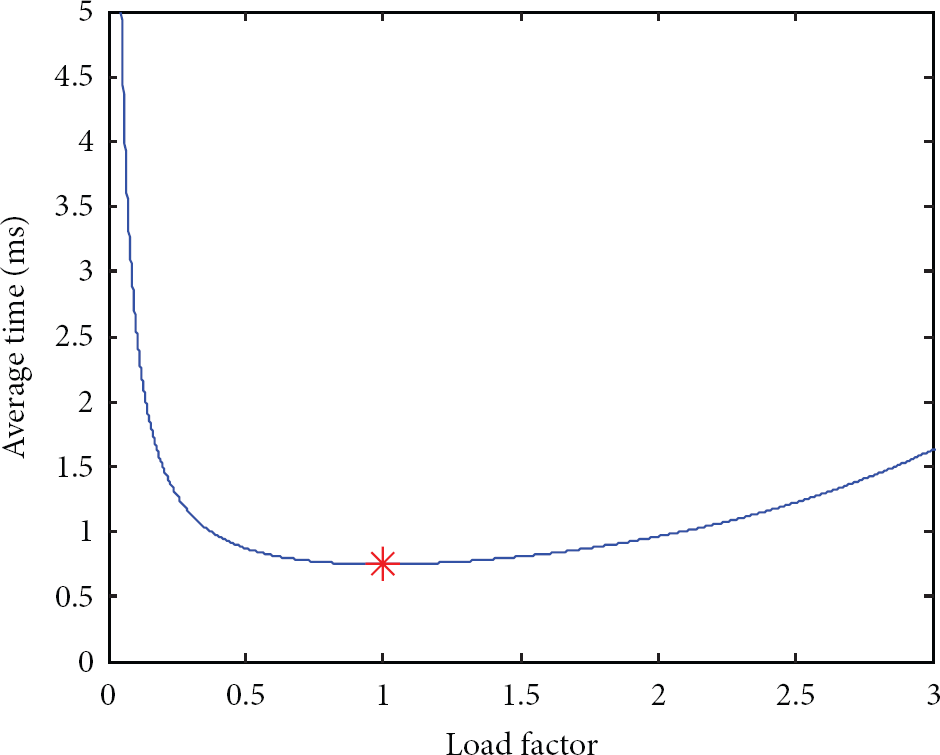
Average time of ECMTI for verifying the presence of one tag with respect to the load factor ρ.
In (10), we obtain the minimum average time
4.4. Discussion
4.4.1. False Positive of Bloom Filter
In the first phase of CMTI and ECMTI, a tag which is not in the wanted set
Assume that a hash function selects each array position with equal probability. If M is the number of bits in the array and V is the number of hash functions, then the probability that a certain bit is not set to “1” by a certain hash function during the insertion of an element is
Now we test membership of an element that is not in the set. The probability of all of them being “1,” namely, the error rate, is

We can determine M and V by the required false positive probability. When the number of activated tags which are not in the wanted category is large due to the false positive probability, we can handle it by using the Bloom filter again to reduce the wrong activated tags.
4.4.2. Impact of Imperfect Channel
The presence of channel noise can cause false positives and false negatives. For example, we assume a missing tag is mapped to a singleton slot. The expected singleton slot will actually be empty. However, due to channel noise, a false positive may occur if the RFID reader receives high noise which is mistaken for a tag response. Occasional false positives do not cause too much influence because a categorized missing tag identification protocol can be executed periodically. Thus, a missing tag which is not identified due to a false positive in this round will be identified in a later round.
A false negative occurs when a tag replies with a short response, but the transmission is corrupted by channel error. In this case, the RFID reader can not receive the response and the tag is mistaken for a missing tag. False negatives can also happen in ID transmission. When the RFID reader transmits a tag ID to verify the tag, channel error corrupts the transmission and consequently the tag does not respond. Therefore, the RFID reader takes it for a missing tag which actually exists. The false negatives can be easily handled by doing extra verification step. For example, the RFID reader transmits the potential missing tags’ IDs to verify their absence. If no response is sent back from the tag, then the RFID reader can confidently ensure their absence.
When tags are moved in or out of the system during protocol execution, false positives and false negatives may also happen. They can be handled by the approaches mentioned above. However, in order to reduce the false events caused by normal inventory operations, we should minimize the execution time. This is the place where our protocols significantly improve. In the next section, we will demonstrate through simulations.
5. Evaluation
In the previous sections, we have elaborated the design details and parameter analysis of our protocols. In this section, we first evaluate our protocols’ performance and then we compare them with the state-of-the-art method in the missing tags identification.
5.1. Simulation Results
We have performed extensive simulations to observe the performance of the proposed protocols. Based on the specification of the Philips I-Code system [32], we set the simulation parameters. Any two consecutive transmissions (from the reader to tags or vice versa) are separated by a waiting time. Thus, a one-bit slot for a tag to respond is 0.4 ms, which includes a waiting time before the transmission. And a 96-bit slot that carriers a tag ID or a vector segment is 2.4 ms, also including a waiting time. Those transmission rates give an approximate bitrate of 40 kbps.
According to the discussion in Section 4.4, we first investigate the optimal parameter settings of Bloom filter. In the simulation, we assume the required false positive rate is 0.01. Figure 7(a) illustrates the execution time in the first phase with varied V from 1 to 10. It shows that when

The investigation with different Bloom filter parameters: (a) the execution time with varied V from 1 to 10; (b) the execution time with varied false positive rate from 1% to 5%.
Based on the above parameter settings, we evaluate the average time for identifying a tag of EMTI and CMETI, respectively. According to the different number of tags in the wanted category, we all perform 300 simulations to get an average time for identifying a tag. Figure 8 shows the comparison of the practical average time and the theoretical average time for identifying a tag. The results are within a certain range of the theoretical average time.

The average time for identifying a tag: (a) the average time for identifying a tag of CMTI with varied
Based on the above results, we perform simulations of our three protocols. We set

The execution time comparison of three protocols: (a) the execution time with varied
5.2. Performance Comparison
We compare our three protocols with P-MTI [15], which is the state-of-the-art technology in the missing tag identification. P-MTI uses
Table 2 presents the execution times of the protocols. We vary
The execution time with respect to

Meanwhile, we evaluate the time of identifying the first missing tag based on different number of missing tags. This is an important function for categorized RFID systems that require a quick answer on whether the wanted category of tags is complete or not. We set
The time to identify the first missing tag with

From Table 3, we get that the identification times of P-MTI (100%) and P-MTI (20%) are two constants since they require the RFID reader to accomplish all
6. Conclusion
In this paper, we study the problem of identifying the missing tags in categorized RFID systems. The solution to the problem is of practical importance for many applications. In order to keep normal operations unaffected, we should minimize the execution time of the protocol for identifying the missing tags of the wanted category. We propose three protocols with progressive time efficiencies. We utilize the Bloom filter as a tool to activate all tags in the wanted category which keeps the tags in the monitoring range from all participating in the protocol. Meanwhile, we further use method to change empty slots and collision slots into singleton slots that improve the utilization of the frame. We do extensive simulations to evaluate the performance of our protocols. The results demonstrate that our three protocols outperform other possible solutions originated from existing approaches.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
Project was supported by The General Object of National Natural Science Foundation (no. 61371062), Youth Science Foundation Project of National Natural Science Foundation (no. 61303207), Ministry of Education in 2012 Colleges and Universities by the Specialized Research Fund for the Doctoral Program of Joint Funding Subject (no. 20121402120020), Shanxi Province Science and Technology Development Project, Industrial Parts (no. 20120321024-01), Shanxi International Science and Technology Cooperation Project (no. 2012081031), Science and Technology Activities Project of Study Abroad Returnees in Shanxi Province in 2012 (funded by Shanxi Province Human Resources and Social Security Hall), and Research Project supported by Shanxi Scholarship Council of China (no. 2013-032).