
Abstract
Distributed video coding presents a viable solution for power-constrained multimedia communication. However, its relatively low coding efficiency compared to the conventional video coding schemes remains a challenging issue. The rate-distortion performance of distributed video coding is highly dependent on the quality of side information generated at the decoder and various techniques have been proposed to improve the side information quality in block-based and frame-based distributed video coding architectures. In this paper, a robust spatiotemporal joint bilateral upsampling based side information generation method is proposed. The proposed side information generation method is based on a block-based low-complexity distributed video coding architecture with adaptive block coding mode classification. A partially reconstructed Wyner-Ziv (WZ) frame with skip and key blocks is downsampled and spatiotemporal error concealment and joint bilateral upsampling are used to generate the side information. Simulation results show that the proposed method improves the quality of side information significantly while keeping low computational complexity.
1. Introduction
Video coding technology has played a key role in the explosion of the current multimedia society. The success of the widespread deployment of digital video applications and services is largely built on the predictive video coding paradigm where the encoder exploits the video redundancy and irrelevancy. This type of video coding is well suited for broadcasting or one-to-many video transmission systems where video is encoded once and decoded many times. However, in resource-constrained environments, a low-complexity encoder is necessary at the expense of a high-complexity decoder while still maintaining a high coding efficiency.
Distributed video coding (DVC) has emerged as a new video compression paradigm for video applications with resource-constrained devices because it enables low-complexity encoding and is naturally robust against transmission errors. Over the past decade, several practical implementations of DVC have been proposed including the Stanford codec [1], PRISM codec [2], and DISCOVER codec [3]. However, current DVC architectures still have several technical limitations that prevent their widespread use in real-world applications. In particular, there is still a significant gap in terms of compression efficiency between the current DVC solutions and conventional predictive video coding techniques.
Since the coding efficiency is highly affected by the quality of SI in DVC, lots of efforts have been made to improve the quality of SI [4–18]. Popular SI generation techniques exploit spatial correlation within the same frame and/or temporal correlation between the consecutive frames [4–6]. Recently, optical flow based methods [7, 8], hash information generated at the encoder [9–11], or multiresolution based techniques [12–18] have been introduced to improve the SI quality. However, most of these methods have high complexity and long decoding time due to a feedback-based architecture.
In this paper, we propose a novel SI generation scheme based on spatiotemporal joint bilateral upsampling (STJBU), which is simple and applicable to any block-based DVC architecture. The proposed method consists of three steps: (1) downsampling of a partially reconstructed WZ frame, (2) SI generation for the WZ blocks in the downsampled WZ frame, and (3) upsampling of the WZ frame using the proposed STJBU algorithm.
The rest of the paper is organized as follows. We review related work on SI generation in DVC in Section 2. In Section 3, the low-complexity DVC (LC-DVC) [19] architecture is briefly introduced which is the basis for the proposed SI generation technique. Then the proposed STJBU based SI generation method is explained in Section 4. Simulation results are presented in Section 5 and the conclusion of the paper is given in Section 6.
2. Related Work
In the past few years, various approaches have been proposed to improve the performance of DVC. The main issues restricting the use of current DVC architectures in practical applications are its low coding efficiency, high decoding latency, and the presence of a feedback channel. In particular, since the coding efficiency is highly affected by the SI quality in DVC, extensive research has been performed to improve the quality of SI.
A multiple motion hypotheses pixel-based temporal interpolation method is proposed in [4], where global and local motion estimation is incorporated. This work has been extended to an adaptive pixel-based temporal interpolation scheme [5] which can adaptively switch between spatial interpolation and forward/backward temporal extrapolation for SI generation. Similarly, a mode decision scheme is presented in [6] to determine the interpolation mode for each block by combining forward and backward motion vectors. Recently, the optical flow algorithm has been exploited for SI generation to compensate for the weaknesses of block-based methods. An optical flow based SI generation algorithm is proposed in [7] which improves the SI quality by obtaining more accurate motion vectors. A similar method proposed in [8] uses optical flow to improve the SI quality and block clustering to increase local adaptivity in the noise modeling. In general, the complex motion estimation process used in these methods incurs high computational complexity and long decoding time.
In the SI generation method proposed in [9], seed blocks are selected first and these blocks are used for motion estimation of the other blocks. Extra information for WZ blocks was transmitted in [10] to help the block matching process at the decoder. Another method called frame-hash uses a highly compressed WZ frame with zero motion vectors to improve the quality of SI [11]. However, the performance of the hash-based DVC schemes is highly dependent on the accuracy of the rate allocation mechanism. An alternative method is to use multiple resolutions in encoding WZ frames. Recently, several SI generation methods based on a mixed-resolution (MR) DVC architecture have been proposed [12–18]. In the MR-DVC architecture, the SI quality is improved by exploiting the spatial relationship between the original frames and the scaled ones.
Spatial low-pass filtering is used in image processing to replace a pixel by a uniform or weighted average of its neighboring pixels. An edge preserving bilateral filter was originally proposed in [20] to alleviate the drawback of spatial low-pass filtering when it is performed over discontinuous regions. It takes into account both the geometric closeness of pixels and their photometric similarity. This noniterative filter smooths images while preserving edges by means of a nonlinear combination of nearby pixel values. Joint bilateral filter proposed in [21] extends the bilateral filter to two correlated images. It filters one image with weights generated using the other image. An alternative joint edge-preserving filter, the guided filter, has been proposed in [22] where the guided filter is derived from a local linear model and can perform filtering in constant time. In [23], the joint bilateral filter has been further extended on image pairs with different resolutions, namely, the joint bilateral upsampling. In [24], a multiresolution bilateral filtering is proposed where the bilateral filter is combined with wavelet thresholding to provide an image denoising framework. The joint bilateral filtering has been successfully applied in a variety of image processing and computer vision applications such as photo enhancement and stereo matching [25].
3. Architecture of Low-Complexity DVC
A simple and unidirectional LC-DVC architecture is proposed in [19]. In the encoder of LC-DVC, an incoming frame is adaptively classified as a key or a WZ frame. The key frame is encoded using the H.264/AVC encoder in intramode. The WZ frames are divided into 4 × 4 nonoverlapping blocks and the blocks are further classified into skip, key, and WZ blocks. The classification map resulting from the block classification process is compressed using arithmetic coding and sent to the decoder. The skip blocks are not transmitted and can be reconstructed at the decoder with help of the previous frame. The key blocks are encoded using H.264/AVC in intramode. The WZ blocks are transformed, quantized, and the bit planes are extracted and encoded using BCH codes.
At the decoder, the key frames are decoded using the H.264/AVC decoder. For a WZ frame, the key blocks are decoded first and then the skip blocks are copied from colocated blocks in the previous frame according to the classification map. As it is shown in Figure 1, a partially reconstructed WZ frame which contains the key and skips blocks is generated. Then, the SI for the WZ blocks is generated by using the proposed method which can be applied to any block-based DVC architecture.

An example of a partially reconstructed WZ frame.
4. Proposed SI Generation Algorithm
The procedure of the proposed SI generation method is shown in Figure 2 and can be divided into 3 steps: (1) downsampling of a partially reconstructed WZ frame, (2) SI generation in the downsampled partially reconstructed WZ frame, and (3) upsampling of the error-concealed WZ frame using the proposed STJBU algorithm.

Flowchart of the proposed SI generation scheme.
4.1. Downsampling of the Partially Reconstructed WZ Frame
In order to reduce the computational complexity in spatiotemporal SI generation methods, the partially reconstructed WZ frame is first downsampled. Downsampling has been used in various image or video compression applications to improve the compression efficiency while reducing the computational complexity [26–30]. The simplest downsampling method is to retain only every Mth sample to create a lower resolution signal in downsampling by a factor of M. However, this simple downsampling method causes aliasing in the resulting downsampled signal. In this paper, four different downsampling methods are used.
4.1.1. Nearest Neighbor Downsampling
The intensity of a pixel in the downsampled image is the intensity of the nearest pixel in the original image as shown in (1):

4.1.2. Bilinear Downsampling
Bilinear downsampling considers the closest
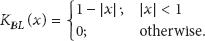
4.1.3. Bicubic Downsampling
The output pixel value after bicubic downsampling is a weighted sum of the pixels in the nearest

4.1.4. Lanczos Downsampling
The output pixel value of the downsampled image is obtained by using a convolution kernel given in the following:

4.2. SI Generation at a Lower Resolution
After the partially reconstructed WZ frame is downsampled, SI is generated for the WZ blocks by exploiting the spatial and temporal correlation. Within a low-delay DVC, the decoder cannot wait for the future frame to arrive before starting the SI generation process and so it must use only the previously reconstructed frame for temporal information. Since the proposed DVC method is block-based and it uses a unique block classification scheme, the decoder is ensured that every WZ block is surrounded by either a key or a skip block in its adjacent 4 neighbors. In this paper, we consider two different methods which are bilinear error concealment and inpainting for SI generation at a lower resolution.
4.2.1. Bilinear Interpolation
SI generation at decoder can be regarded as error concealment (EC) process where the WZ blocks have to be estimated using EC techniques. Among various spatial error concealment techniques [31–34], bilinear error concealment [31] is chosen to estimate the WZ blocks because it is simple but highly efficient.
Bilinear interpolation is a spatial error concealment method which uses the spatially adjacent blocks to recreate the missing pixels by a weighted averaging procedure. Let x and y represent the vertical and horizontal coordinates of the WZ block, where
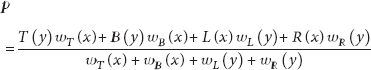

4.2.2. Region-Filling Inpainting
EC at the lower resolution frame can also be regarded as a hole-filling problem. Region-filling inpainting technique proposed in [35–37] fills holes within the image by propagating linear structure (also called isophotes) into the target region by diffusion. This interactive processing includes 3 steps, namely, patch priorities computation, texture and structure information propagation, and confidence value updating. The initial setting includes target region
4.3. Spatiotemporal Joint Bilateral Upsampling
After applying EC, the error concealed frame is upsampled using the proposed STJBU method. STJBU is an extension of joint bilateral upsampling (JBU) [24]. JBU is an extension of bilateral filtering [23] and it uses both a domain filter and a range filter to adaptively combine pixels based on both their geometric closeness and their photometric similarity. The difference between JBU and bilateral filtering is that the range filter in JBU is applied to a second guidance image.
In the proposed method, JBU cannot be applied directly because the target reference pixels used for the range filter are not available. In order to solve this problem, the temporal correlation between the consecutive frames is considered. The information in the previous frame is exploited to be used as the second guide image for the range filter. The collocated block in the previous frame is found by boundary matching and it is used as the reference block for the range filter. The scheme of STJBU is shown in Figure 3.

Proposed spatiotemporal joint bilateral upsampling (STJUB) scheme.
Given a previously decoded frame at high resolution

5. Simulation Results
To evaluate the performance of the proposed SI generation technique, we conducted experiments using four standard test sequences, Hall Monitor, Akiyo, Mother and Daughter, and Foreman of QCIF size (
5.1. Comparison of Different Downsampling Methods
First, we compare the performance of four different downsampling methods introduced in Section 4.1. For each test sequence, the first 50 frames are used for simulation. For the experiments, the frames are downsampled using different downsampling methods and then upsampled using the proposed STJBU. The resulting frames are compared to the original frame to calculate the peak-signal-to-noise ratio (PSNR). Table 1 shows the average PSNR value of the four test sequences when different downsampling methods are applied.
Comparison of different downsampling methods.
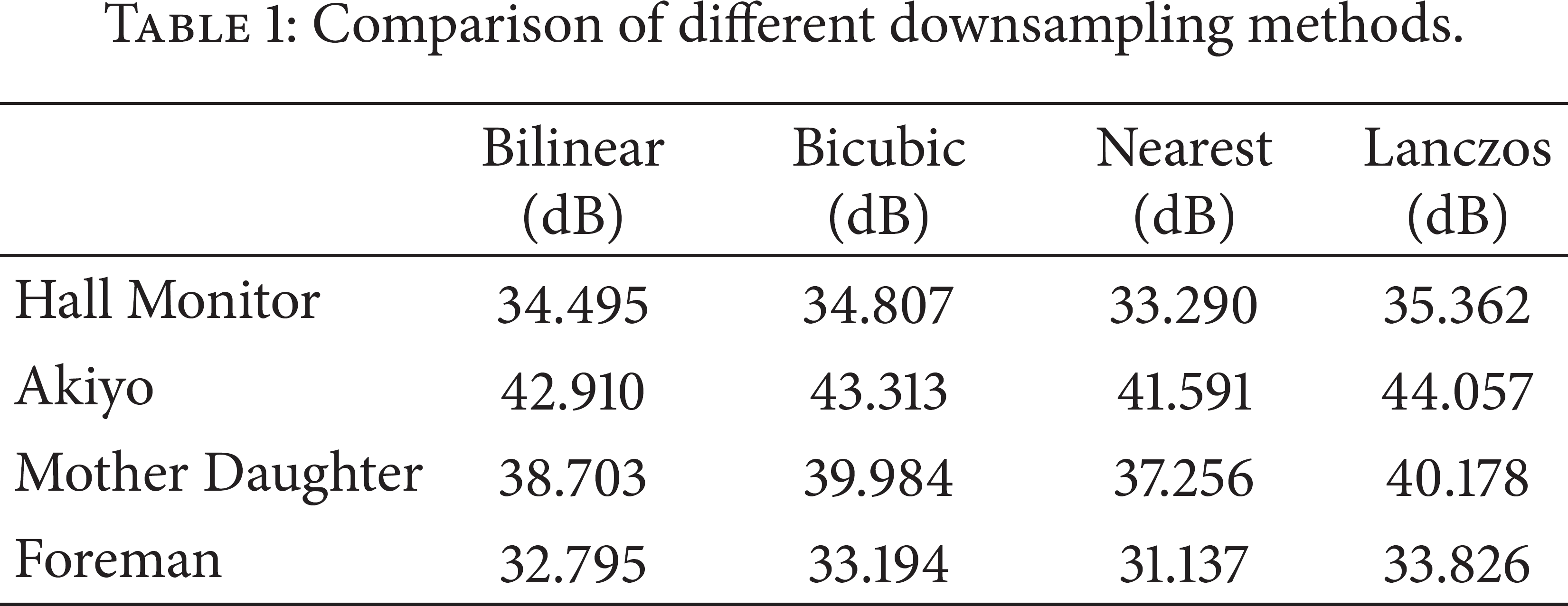
As shown in Table 1, the nearest neighbor downsampling algorithm has the lowest computational complexity but it produces the lowest quality. The Lanczos algorithm is much more complex than the other methods but gives the best quality. The processing time of the Lanczos algorithm is almost 10 times higher than the other methods. Bilinear and bicubic downsampling algorithms have lower computational complexity with acceptable output quality. By considering the trade-off between the performance and the processing speed, bilinear downsampling is chosen to downsample the partially reconstructed WZ frames.
5.2. Comparison of the Reconstructed WZ Frame Quality
This section compares the visual quality of the SI generated by the proposed method with that of the hybrid spatiotemporal error concealment [19]. Akiyo and Hall Monitor sequences were encoded and decoded using the LC-DVC architecture setting the QPISlice value to 30. For the experiments, we use two different EC techniques along with STJBU. In the following sections, we refer to different techniques as defined in Table 2.
Different SI generation methods being compared.

The simulation results shown in Figure 4 illustrate the visual quality of WZ frames obtained by different methods for the Akiyo sequence. As can be seen in Figure 4, the proposed methods produce WZ frames with higher PSNR compared to the ones obtained by the hybrid EC [19]. Specifically, Proposed 1 (inpainting + STJBU) achieves better performance than Proposed 2 (BI + STJBU) because image inpainting is more effective than simple BI in error concealment, while it increases the computational complexity. However, since image inpainting is applied to a lower resolution image, the proposed method maintains low computational complexity.

Comparison of visual quality of the SI generated by different methods: (a) partially reconstructed 12th frame (WZ frame) of Akiyo sequence, (b) hybrid EC; PSNR = 43.259 dB. (c) Proposed 2; PSNR = 42.726 dB. (d) Proposed 1; PSNR = 44.602 dB.
5.3. Comparison of the Rate-Distortion Performance in SI Generation
Next, we encode the first 150 frames of Akiyo, Mother and Daughter, Hall Monitor, and Foreman sequences at various bitrates and compare the RD performances of the proposed methods with that of DISCOVER [38], H.264/AVC intramode, LC-DVC [19], and a recent proposed selective data pruning (SDP)-DVC [39]. It should be noted that DISCOVER uses bidirectional motion estimation for SI generation and uses a feedback channel. Therefore, DISCOVER achieves higher rate-distortion performance than block-based DVC without a feedback channel for high motion sequence but incurs prohibitively long delay.
Rate-distortion (RD) performances of four test sequences are shown in Figures 5, 6, 7, and 8, respectively. Taking the Hall Monitor sequence as an example, it can be seen in Figure 7 that Proposed 1 gives the best RD performance, even better than the SDP-DVC [39]. However, the RD performance of Proposed 2 is lower than that of LC-DVC and DISCOVER. Both Proposed 1 and Proposed 2 perform better than H.264/AVC in intramode with an extremely simple encoder. BI based error concealment used in Proposed 2 enables a very simple encoder, but it reduces SI quality and RD performance.
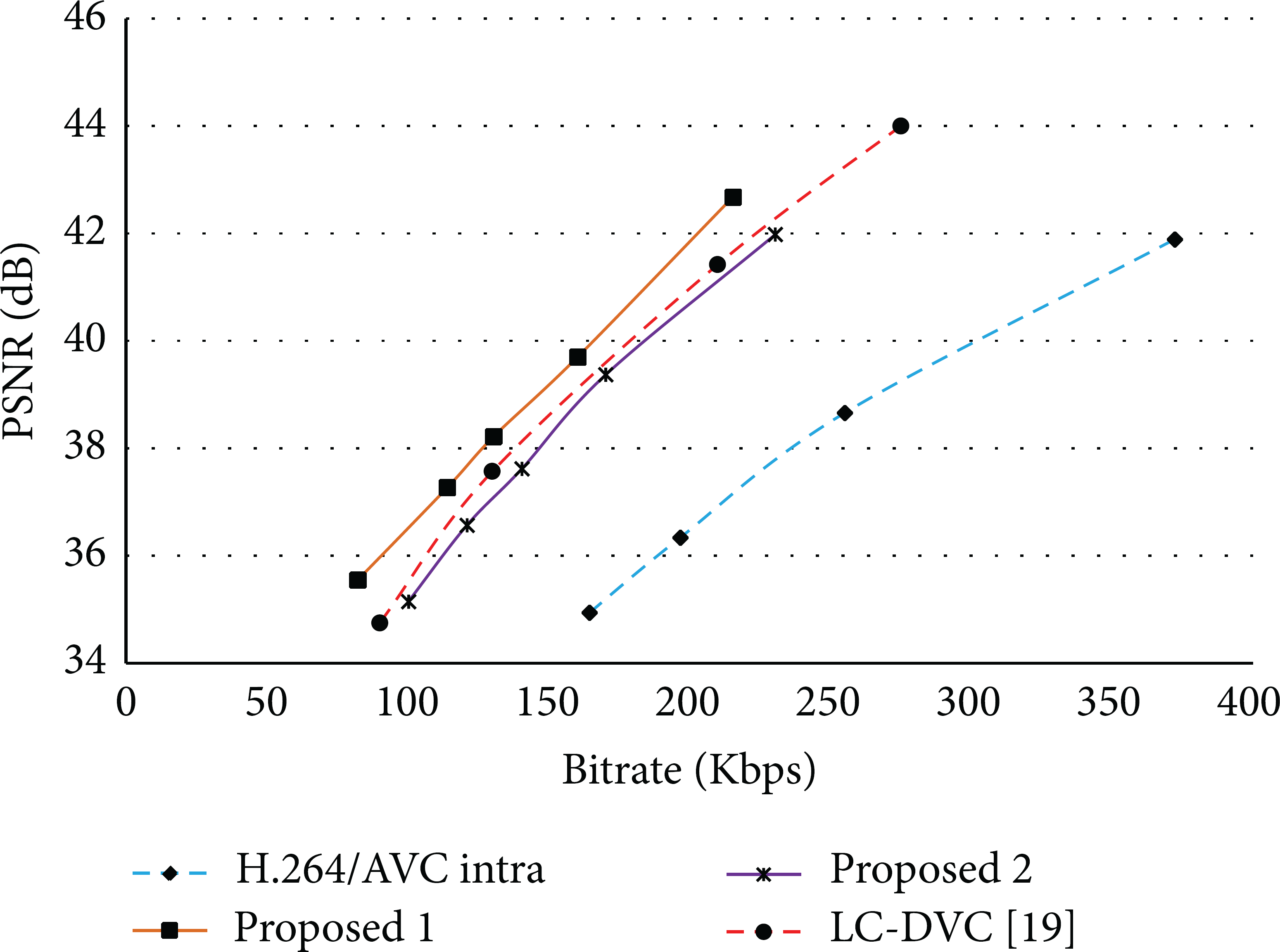
RD performance comparison for Akiyo sequence.

RD performance comparison for Mother and Daughter sequence.
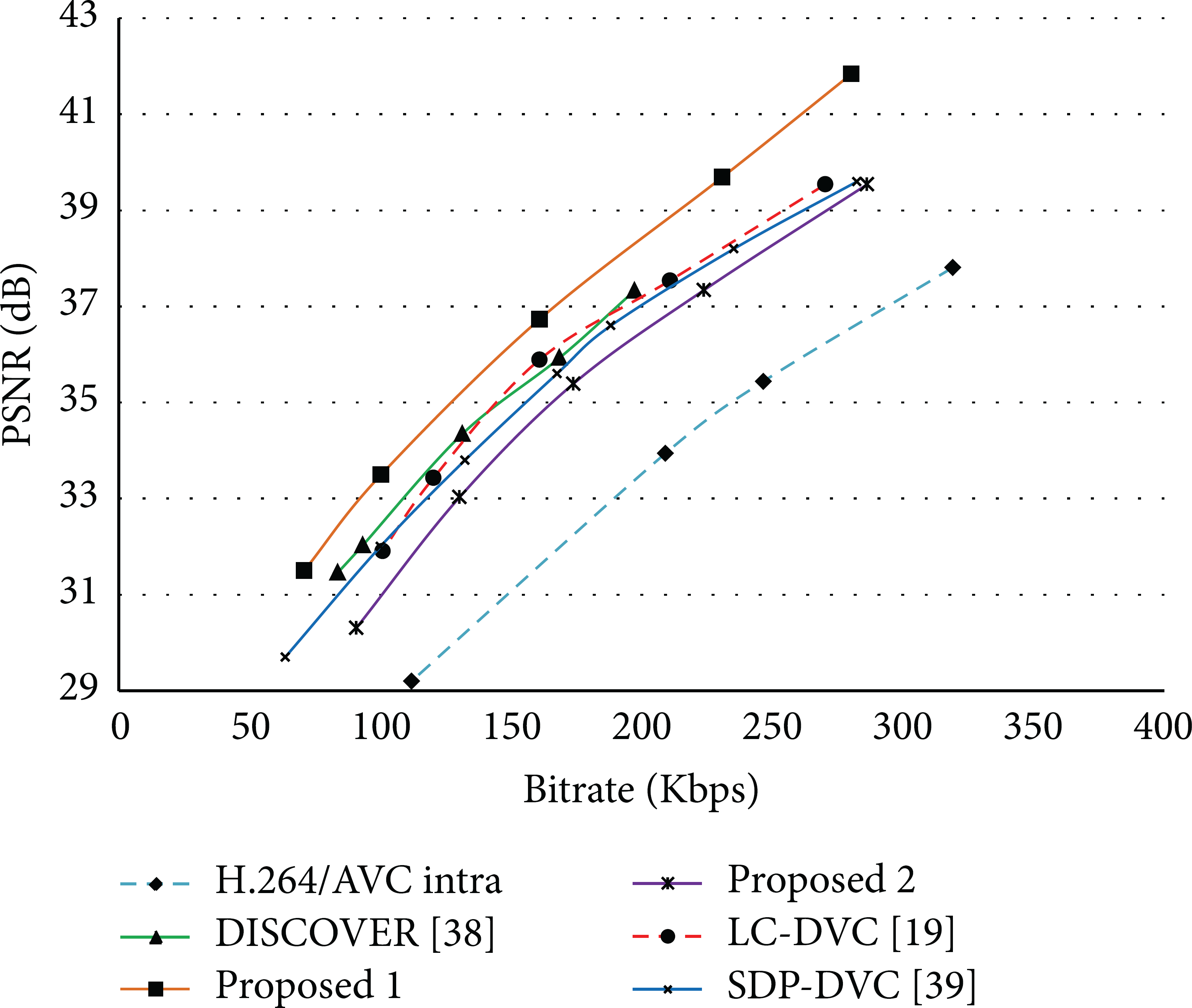
RD performance comparison for Hall Monitor sequence.

RD performance comparison of Foreman sequence.
As shown in Figure 8, the proposed method performs worse for higher motion sequences such as the Foreman sequence. However, it should be noted that DISCOVER uses bidirectional motion estimation for SI generation and uses a feedback channel. Therefore, the DISCOVER codec incurs extremely long decoding time and system delay. Since the proposed method is very simple, has low system delay, and does not require a feedback channel while producing a comparable rate-distortion performance to state-of-the-art DVC methods, it can be a promising solution for video applications in resource-limited environments.
6. Conclusion
In this paper, we present a robust STJBU-based SI generation method. The proposed method consists of 3 steps: (1) downsampling of a partially reconstructed WZ frame, (2) SI generation for the WZ blocks in the downsampled WZ frame, and (3) upsampling of the WZ frame using the proposed STJBU algorithm. Results show that the proposed method improves the visual quality of the SI by preserving the edges and improves the RD performance by more than 1 dB in comparison to other DVC architectures. The proposed SI generation method is simple and can be implemented into any exiting block-based DVC architecture. Moreover, with its low complexity and low latency, the proposed method can be a promising solution for video applications in resource-limited environments with a tight delay bound.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported by the Technology Development Program for Commercializing System Semiconductor funded by the Ministry of Trade, Industry and Energy (MOTIE, Korea). (No. 10041126, title: International Collaborative R&BD Project for System Semiconductor).