
Abstract
Foreground detection plays an important role in the traffic surveillance applications, especially in urban intersections. Background subtraction is an efficient approach to segment the background and foreground with static cameras from video sensor networks. But when modelling the background, most statistical techniques adjust the learning rate only based on the changes from video sequences, which is a crucial parameter controlling the updating speed. This causes a slow adaptation to sudden environmental changes. For example, a stopped car fuses into background before moving again, and it lowers the segmentation performance. This paper proposes an efficient way to address the problem by accounting for the physical world signal in traffic junctions. It assigns an adaptive learning rate to each pixel by integrating traffic light signal obtained from sensor networks. Combined with abundant physical world signals, background subtraction method is able to adapt itself to the outside world changes instantly. We test our approach in real urban traffic intersection; experimental results show that the new method increases the accuracy of detection and has a promising future.
1. Introduction
Intelligent video surveillance, aiming at making traffic more intelligent and decreasing the amount of vehicle accidents, is a well-studied subject area with both existing application systems and new approaches still being developed. Among this area, detecting objects at the intersection is one of the most significant focuses in typical intelligent transportation systems (ITS) applications and the basis of high-level processing. In the most real intersections, a single camera is not enough to monitor the whole scenario. Video sensor network provides a large-scale, redundant, of video streams to observe the intersections [1, 2]. Because some of video-based traffic monitoring systems include high-level description of both cars and their behaviours, continuous tracking result is significant to the high-level processing. Background subtraction is a widely used technique for foreground detection which compares an observed image with an estimated background image that does not contain any objects of interest. But before using this method, several parameters have to be determined. Among these arguments, the learning rate is more critical to the performance. If the rate is large, the slow or stopped vehicles will fuse into background quickly just as Figure 1 describes. But if we set the rate at a small value, the background will not be updated in time. In particular, in a traffic junction scene, vehicles always encounter congestion and stop-and-go when there is a red light. At this time, a reasonable learning rate becomes more significant. Usually, the majorities of current methods adjust learning rate only relying on the changes from video sequences. This causes very often the method to be unable to adapt itself with the outside world changes instantly. And when the traffic light is red, it mainly leads the tracking of vehicles to be interrupted. Once the light turns green, the cars move again and new tracking of them is constructed. In summary, it has a bad effect on the continuous tracking of foreground objects and reduces the accuracy of some high-level understanding methods, such as [3, 4]. Unlike previous methods, this paper focuses on how to adjust learning rate according to the real-time and accurate physical world signals from other sensors. And this technique guarantees the continuous tracking of vehicles in traffic junction.

(a) shows several stopped vehicles during red light. (b) is the corresponding detection results. As time passed, some of the foreground objects disappeared gradually.
In this paper, we select the more common traffic light as the external signal to improve the results of foreground detection. Meanwhile, to divide input images into reasonable regions, road line detection result is used. Because the camera is static, road lines are just detected only once in the whole monitoring period. If the system receives a red light signal, it indicates that vehicles will slow down and stop after some frames. To avoid these interested vehicles blending in background and losing existed tracking, we decrease the learning rates of pixels in the red light region while the rates of other pixels remain unchanged. When the system receives a green light signal, it means that vehicles run through the intersection at normal speed and normal learning rates are selected. Experimental results show that this kind of environment information can greatly improve the results of the background subtraction and foreground detection.
We have done some work in improving the detection results by combining the video sequence and physical world information before, which is published in paper [5]. This paper is an expanded version of [5], which analyzes the method more in detail, sets more contrast experiments, and adds quantitative evaluation of experiments’ results. The remaining of this paper is organised as follows. In Section 2, a compact review of important developments and existing improvements about background subtraction and foreground detection are presented. We propose the proposed framework and outline three classical methods and illustrate how to use our approach to make these methods perform better in Section 3. Further explanations of our method in a practical application scenario are supplied in Section 4. Meanwhile, the contrast experiment results between precious methods and our method are presented. The last section is conclusion and future work.
2. Related Research
There has been numerous works devoted to the development of background subtraction for real-time video processing. Several surveys devoted to this topic can be found in [6, 7]. The statistical tools provide a good framework to model the background of a complex traffic scene and so many methods have been developed.
During these methods, Gaussians mixture model (GMM), first presented in [8], models the distribution of the values observed at each pixel by a weighted mixture of Gaussians. GMM is able to cope with the multimodal nature of many practical situations and leads to good results when there are repetitive background motions, such as leaves shaking or water rippling. By far, GMM is the most researched and applied method. Many enhanced algorithms [9] have been proposed all along these years. Reviews of them can be seen in literature [7, 10]. The weakness of GMM lies in its strong assumption that the background is more frequently visible than the foreground and that its variance is significantly lower. Also, the initialization of the model and estimation of the parameters are problematic and uncertain in different real-world environments. Therefore, traditional GMM-based methods with empirical value usually are not competent to good background subtraction results. To avoid the difficulty of finding an appropriate shape for the probability density function, nonparametric methods using kernel density estimation to model background distributions have been proposed. These methods build a histogram of background values for each pixel, by collecting values sampled from the pixels recent time window [11]. In [12], a Bayesian framework which incorporates multiple types of features for modelling complex backgrounds is proposed (we abbreviate the foreground detection method in [12] as FGD for short) and solves the sudden once-off background change effectively.
For all those background subtraction methods that have been mentioned above, they still have a common problem. That is how to select an adaptive learning rate. Explicitly, background modelling methods with a global empirical learning rate are significantly penalized. Over these years, a lot of research papers discussed the adaptive learning rate and proposed various solutions for tuning the learning rate based on local intensity changes [13, 14], different level feedbacks [15, 16], and so on. Based on GMM, [17] proposed a background subtraction method using a pixel-wise adaptive learning rate for object tracking. Unlike the traditional methods that use the same experiential “learning rate,” it assigns a learning rate to each pixel relying on two parameters; one is depending on the difference of pixel intensities between the background model and the current frame and the other is depending on the duration of the pixel being classified as a background pixel. In [18], the learning rates for the mean and the variance terms are decoupled and independent so as to avoid the saturation phenomenon and degeneracy problem. They use an adaptive learning rate to update the mean and a semiparametric model for the variance. The authors of [19] use the time gap between moving and stopped objects to train the background model and get adaptive parameters for urban traffic video. Considering the slow learning problem of GMM at the beginning phase, Kaewtrakulpong and Bowden improved the update mechanism in learning step and proposed the fast-learning Gaussian mixture model [20]. In [21], the enhanced Gaussian mixture model detects still objects from moving state and adjusts learning rate to improve the performance of detecting moving object detection with intermittent stops. The authors of [22] modulated the learning rate of background model based on scene activity. In [23], an updating method with adaptive learning rate (we abbreviate this method as GMMX for short) is proposed to accurately segment the objects that move slow or stop for a while during moving.
Even though many background subtraction approaches with adaptive learning rates were proposed and indeed improved the naive GMM, as mentioned above, they still have some limits and are not proper for foreground detection at the intersection. Especially, we find that many stopped cars gradually fuse into background and cannot be traced again with the previous methods. Firstly, most of these methods [14, 15, 17, 18, 21–23] perceive sudden change only based on the image information, such as illumination changes and background movements. Therefore, the accuracy of perception is difficult to be guaranteed. Secondly, statistical methods often need a period of time to affirm and learn new changes. During this period, it generates a lot of detecting mistakes. Thus, some instant adjustment mechanisms are significant. Thirdly, image processing for perception needs additional computing, which aggravates burden on the system real-time performance. The problems mentioned above motivate us to propose a new method to perceive environment changes and adjust the learning rate by integrating traffic light signal into video sensor networks.
3. Our Approach
To the best of our knowledge, there have not been any methods that utilize the traffic light signal to enhance the vision-based background subtraction at the intersection. This paper proposes to regard these similar physical world signals as the criteria to adjust background model parameters. There are several parameters in background modelling methods. Learning rate α which controls the updating speed of modelling is a more important parameter. The stopped foreground objects will not fuse into background by adjusting α according traffic light signal. Then, we use GMM [8], GMMX [23], and FGD [12] as experimental subjects and traffic light signals as external information. How these methods are enhanced by our approach is described elaborately in the following text. Note that our method can work with other existing background subtraction approaches applied in intersection scene as well.
3.1. The Proposed Framework
In Figure 2, it depicts the whole proposed framework of using traffic signal to enhance the vision-based background subtraction. Model initialization, the first step, assigns all parameters needed and initials the background model. Then, the system gets a new input image from the video sensor networks and simultaneously receives physical world signals. Next module adjusts learning rate according to the traffic light signals. The following step is background subtraction, which is the same as the previous methods. Then, it outputs the foreground detection results. Meanwhile, the system updates background model and waits for the next input image. The grey modules are newly added in the framework, which distinguish from previous methods.

Framework of the proposed background subtraction.
As wireless sensors become widely available and their costs come down, traffic control systems integrate with wireless sensor networks (WSN) in ITS [24]. Our method is designed to obtain traffic light signals from WSN. For convenience, we set the traffic light signal manually in experimenting. The learning rate is adjusted according to traffic light signal. When it is red, a little constant is selected. And once the light turns green, a normal one is applied. Here, the two values are all determined empirically. The following content specifically describes the improved methods.
3.2. Improved GMM Modelling
In the context of a traffic surveillance system, Friedman and Russell [25] proposed to model each background pixel using a mixture of three Gaussians corresponding to road, vehicle, and shadows. The maintenance is made by using an incremental EM algorithm for real-time consideration. Stauffer and Grimson [8] generalized this idea by modelling the recent history of the colour features of each pixel
The intensity in the RGB colour space of each pixel is selected as the feature to classify. The probability of observing the current pixel value is considered given by the following formula in the multidimensional case:


For computational reasons, Stauffer and Grimson [8] assumed that the RGB colour components are independent and have the same variances. So, the covariance matrix is of the form

The K Gaussians are sorted in descending following the ratio
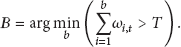
The others are regarded as foreground distribution. When the new frame comes at time

When a match is found with one of the K Gaussians, for the matched component, the update is done as follows:


When no match is found, the least probable distribution is replaced with a new one with initial parameters.
In our improved method, the learning rate is adaptively tuned in accordance with external physical world events. Once a new input image arrives, the system enquires traffic light to perceive environment changes and does some reasonable adjustments instantly to get the best effect. The learning rate is changed as follows:
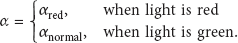
When light is green, α is selected as
3.3. Improved GMMX Modelling
The original GMM has many limitations, such as the number of Gaussians having to be predetermined, the need for good initializations, and the dependence of the results on the true distribution law which can be non-Gaussian and slow recovery from failures. To alleviate these disadvantages, numerous improvements have been proposed over the recent years. In this paper, we choose a method as the comparative experiment, which is abbreviated as GMMX [23] and has an outstanding performance on detecting temporarily stopped objects with adaptive learning rate.
The main contribution of paper [23] is a model number adaptive method to decrease the amount of computation and an updating method with adaptive learning rate to accurately segment the objects that move slow or stop for a while during moving (here we are only interested in the second method). The authors think the fixed learning rate causes the problem that moving objects stopping for a short time will rapidly be updated to the background model by the GMM. Thus, different learning rates should be assigned to different distributions. When a new match is found at time t, the learning rate
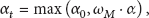
Traffic light signal is still able to be combined with GMMX by changing

3.4. Improved FGD Modelling
Li et al. proposed to classify background and foreground pixels under the Bayes decision theory [12]. Let

Using the Bayes decision rule, a pixel s is classified as background according to its feature vector
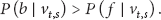
Note that the feature vectors associated with the pixel s are either from background or from foreground objects, and it follows that
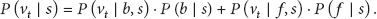
Substituting (11) and (13) into (12), it becomes

In this method, the colours of a pixel are chosen as the feature for stationary background, while the colour cooccurrences of interframe changes from the pixel are chosen as the feature for moving background. And a table of statistics for the possible principal features is established for each feature type at s, which is denoted as

For each feature vector


Also, traffic light signal is added in FGD just as GMM in Figure 2. The external signals are mainly used to adjust feature learning rate
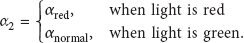
When the light is red, a little constant is set to avoid the stopped cars vanishing quickly. Once the signal changes,
4. Experiment Results
In order to make the experiment more convincing, we record the video at a real traffic junction, where there is a traffic light. Then, we run the programs of GMM, GMMX, FGD, and their enhanced versions, collect, and analyse the executive outcomes.
4.1. Data and Qualitative Results
The test video, which consists of 2752 frames of
The detailed selection of important parameters is as follows. In GMM, we choose
In Figure 3, the first row is four original frames selected randomly from the test video sequence, which are frames 2122, 2256, 2381, and 2417, respectively. These pictures show us five cars that slow down and stop successively. Then, the images below are the detection results of three initial approaches and their enhanced versions. We can see that the enhanced methods are successful to keep the stopped vehicles in the detection results, while the outputs of previous methods show that the cars in front of every image have fused into background. Our approach obviously improves the effect of detection.

(1)–(4) are four original frames selected randomly from the test video when the light is red. These images show us five cars that slow down and stop successively. The other images are the foreground detection results of three original methods and corresponding improved methods. (a)–(d) are the results of GMM, while (e)–(h) are the results of improved GMM. (i)–(l) are the results of GMMX, while (m)–(p) are the results of improved GMMX. (q)–(t) are the results of FGD, and the images of the last row are the results of improved FGD.
4.2. Quantitative Evaluation
In the evaluation, we choose 12 frames from the segment of the test video, during which the light is red and lasts about 25 seconds. In other words, a frame is selected in every 2 seconds. We use these images to analyse the performance of our method.
Three terms are used in the quantitative evaluation: false positive (FP) is the number of background pixels that are wrongly marked as foreground; false negative (FN) is the number of foreground pixels that are wrongly marked as background; total error (TE) is the sum of FP and FN. We calculate these terms for each image according to the corresponding hand-segmented ground truth. FN, FP, and TE of every approach are the sum of four frames of FN, FP, and TE.
Figure 4 illustrates overall performance on the selected twelve frames for the three previous methods and their improvements. The total error of the improved versions is less than the previous ones. In particular, the new approach reduces FN vastly, which means that the stopped cars would not disappear before the light turns into green. So, the tracking of foreground objects will not be interrupted, which supplies a solid foundation for many high-level images processing. But it is a pity that FP increases a little and it is our next problem to be solved.

Overall performance of the selected twelve frames for the three previous methods and their improvements.
In Figure 5, FN of different methods is listed according to the frame number. The horizontal axis is the frame number, while the vertical axis is the FN value (the number of foreground pixels that are wrongly marked as background). And different colours represent different methods. From Figure 5, we can see that FN of previous methods increases rapidly, which means that the foreground objects disappear from the detection results, while FN of the improved ones stays in a low quantity. This phenomenon is more obvious in latter period of red light.

The horizontal axis is the frame number, while the vertical axis is the FN value (the number of foreground pixels that are wrongly marked as background). Different colour represents different method.
In summary, we conclude that our method can effectively improve the accuracy and reliability of foreground segmentation. Meanwhile, various background modelling methods are able to benefit from physical world signals.
5. Conclusions
We present a novel method that utilises traffic light signal to enhance the performance of background subtraction, while existing methods use only image information to model and update the reference background. Then, this paper records elaborately the experimental process and results. By contrast with FN, FP, and TE of the previous methods, such as GMM, GMMX, and FGD, the responding enhanced versions obviously have a better performance. It demonstrates that background subtraction methods based on traffic light signal may have a bright future. Considering that different pixels have different characteristics of changes in colour, it is better to set different and more reasonable learning rates based on these signals for each pixel rather than some constants for all pixels, which is our future research focus. Meanwhile, in order to combine the background modelling methods with physical world signals more closely, we will think over more relations between model parameters and these signals to get a better effect.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the fund of the State Key Laboratory of Software Development Environment (Grant no. SKLSDE-2012ZX-01) and the Fundamental Research Funds for the Central Universities.