
Abstract
The sensing data of nodes is generally correlated in dense wireless sensor networks, and the active node selection problem aims at selecting a minimum number of nodes to provide required data services within error threshold so as to efficiently extend the network lifetime. In this paper, we firstly propose a new Cover Sets Balance (CSB) algorithm to choose a set of active nodes with the partially ordered tuple (data coverage range, residual energy). Then, we introduce a new Correlated Node Set Computing (CNSC) algorithm to find the correlated node set for a given node. Finally, we propose a High Residual Energy First (HREF) node selection algorithm to further reduce the number of active nodes. Extensive experiments demonstrate that HREF significantly reduces the number of active nodes, and CSB and HREF effectively increase the lifetime of wireless sensor networks compared with related works.
1. Introduction
A wireless sensor network consists of spatially sensor nodes which are generally self-organized and connected by wireless communications [1]. Today such networks are used in many industrial and consumer applications, such as traffic data collection, vehicular monitoring and control, security surveillance, and smart homes. Each sensor node is equipped with a sensing device which can detect the environmental condition. The nodes are also powered by limited batteries and it is difficult or impossible to replace them in some special environments. It is why energy efficiency is always the most important criterion for such networks. One important approach to extend the network lifetime is to reduce the number of required packet transmissions in the network [2–5], such as clustering [6–11], in-network data aggregation [12–18], and approximate data collection [19, 20]. In these scenarios, all nodes in the network are considered active and the data are gathered from all nodes during the collecting process.
However, it is not an efficient way to collect all raw data from each node in some special applications which aim to collect information originated from the environment, such as temperature, humidity, and pressure. In these applications, it is fully tolerant if the final collected information is just within error threshold. The sensing data of each node is generally a noise version of the observed phenomenon and there is a deviation among them due to distance, location, or node sensitivity. Nodes are generally correlated if they are observing the same physical phenomena. Correlations between nodes are described in some simple ways such as the maximum or minimum value between nodes [21]. In this paper, correlation occurs if the sensing data of simple node can be obtained from the other nodes. Accordingly, a subset of active nodes can be selected to provide the required sensing service within error threshold, and the rest nodes can go to sleep and preserve energy. In this way, the active node selection strategy with correlation optimization not only prolongs the network lifetime, but also helps to solve other issues in dense wireless sensor networks [22], such as lower network throughput, serious node conflict, and excessive packet transmissions.
How to describe the correlation among the sensing data quantitatively is the key issue when achieving an efficient active node selection strategy. The distance function is generally considered as an important model to formulate the data similarity between nodes because the sensitivity is sometime related to the distance between the source and sensing device. Here we adopt Manhattan distance between sensing data as error metric [22]. Based on the observation that the sensing data are similar to each other if they are close enough, Kotidis [23] proposes Snapshot query in which only selected active nodes report their sensing data, and sensing data of one-hop nodes is computed by active nodes. Liu et al. [24] propose an EEDC algorithm which divides the nodes into disjoint cliques based on spatial correlation so that the nodes in the same clique have similar sensing data and can communicate directly with each other. Hung et al. [22] propose a DCglobal algorithm to determine a set of active nodes with high energy levels and wide data coverage ranges.
Figures 1(a) and 1(b) show the selected nodes with EEDC and DCglobal for a given wireless sensor network, where each circle denotes one node (the sensing data value is marked above the circle). The edge between a pair of nodes denotes that they can communicate directly with each other. Here we assume that Manhattan distance is used as the similarity function and the error threshold is 0.5. The selected active nodes are marked with black solid circle. The selected active node set with EEDC is

An example to demonstrate different algorithms. (a) EEDC, (b) DCglobal, (c) CSB, and (d) HREF.
The concept of data coverage range is firstly introduced to describe the correlation among nodes and defined as a node set in which the distance between each element and the given node is within the error threshold [22]. In fact, it is a simple extension of one-hop data coverage [23]. Another issue of [22] is the efficiency of proposed node selection algorithm. The partially ordered tuple (residual energy, data coverage range) is used to select an active node set, which ensures that the selected nodes always have high reserved energy, but the number of selected active nodes is not minimized.
To address these problems, we introduce several new concepts, that is, cover set, active node, and covered node, and propose a new Cover Sets Balance algorithm (CSB) to choose a set of active nodes with wide data coverage range and high energy level by using the partially ordered tuple (data coverage range, residual energy) and build the corresponding cover set in sequence to ensure the selected active nodes have high residual energy. In this way, the set of final selection nodes generally owns larger residual energy and smaller size, which helps to extend the network lifetime. Figure 1(b) demonstrates the set
In the following we show some nodes can be further removed from the selected active node set with CSB. As shown in Figure 1(c), the sensing data of We propose a Cover Sets Balance algorithm (CSB) to select a set of active nodes with wide data coverage ranges and high energy levels. In each active node selection step, we use the partially ordered tuple (data coverage range, residual energy) to find an initial active node set and then balance the size of the cover sets in order to replace low-energy nodes. We propose a Correlated Node Set Computing algorithm (CNSC) to calculate the correlated node set with minimum set size and maximum geometric mean of residual energy of each node in the sensor network by following the observation that some nodes selected by CSB can be further removed. We propose a High Residual Energy First algorithm (HREF) to reduce the number of active nodes selected with CSB by removing nodes which can be computed by correlated node sets.
The rest of this paper is organized as follows. In Section 2, we describe the system model. Section 3 introduces CSB and HREF algorithms. The theoretical analysis of the algorithms is proposed in Section 4. In Section 5, we describe the simulation results and performance analysis. Section 6 presents the related works and Section 7 is conclusion.
2. System Model
A wireless sensor network generally consists of a set of stationary nodes
The nodes are equipped with unreplaceable or unrechargeable batteries. The reserved energy for node i at time t is denoted by
The notations used in this work are listed as the following:
n: Number of nodes in the network ε: One given error threshold r: Transmission radius Interval: Interval to reselect a new active node set.
The correlation among sensing data especially in a dense wireless sensor network is helpful to extend the network lifetime. Some researchers studied the correlation between nodes and provided some models [25]. Among all these models, it is common to adopt distance function, such as Manhattan distance
The sensing data of
Definition 1 (data coverage range (DCR)).
Given an error threshold ε in the sensor network, the data coverage range
For the example in Figure 1(b),
Definition 2 (active node set (ANS) and active node).
Given a sensor network
For the example in Figure 1(c),
Definition 3 (cover set (CS) and covered node).
Given a sensor network
For the example in Figure 1(c),
Sensor data is affected by the events in monitored region, and the influence of each event on a sensor is inversely proportional to their distance. Here we assume that correlation occurs among all active nodes in the sensor network.
Definition 4 (correlated node set (
)).
Given a sensor network
For the example in Figure 1(d),
Definition 5 (CNS computing problem).
Given a sensor network
Note that we adopt the geometric average of the residual energy in the correlated node set by following the observation that the average geometric averaging gives higher results for lower variations in the data values for a given data set with a fixed arithmetic [26].
Definition 6 (active node selection problem).
Given a sensor network
The active node selection problem is to find the active node set during each epoch and aim at maximizing the network lifetime. The problem is proven to be NP-hard by mapping it to the set covering problem or minimum dominating set problem [26–28]. In this paper, we design two heuristic algorithms, namely, CSB and HREF for this problem.
3. Heuristic Algorithms
3.1. CSB Algorithm
Most related works use the concept of data coverage range combined with energy to solve the active node selection problem. In this section we illustrate the Cover Sets Balance algorithm (CSB) based on the idea of data coverage range.
In data collection process, only active nodes are required to provide perception service, and the rest nodes are closed to preserve energy. An intuitive approach for the node selection process is to use the partially ordered tuple (data coverage range, residual energy) [23]. Another approach is to use partially ordered tuple (residual energy, data coverage range) to select active nodes with higher residual energy [22]. However, the number of selected nodes is generally larger than the former approach, which means that more energy consumption is necessary when providing perception service during the given epoch. Obviously, we need a balance between the two metrics, that is, the data coverage range and residual energy.
The basic idea of Cover Sets Balance (CSB) algorithm is described as the following: (1) generate an initial active node set and the corresponding cover sets through the previous data coverage range priority strategy; (2) replace active nodes with high-energy candidates. Note that the candidates must cover all nodes within the same cover set. For example, in Figure 1(b),
We adopt a cover set balance strategy to balance the set size by moving nodes from larger cover sets to smaller ones. The initial cover sets are sequenced in descending order of the set size, and then we check nodes in one cover set and try to move them to another with smaller size. This process continues until all sets are checked and finally they are balanced. This strategy is helpful to increase the number of candidate nodes with higher residual energy by cutting down the maximal deviation of each cover set in the balance progress.
The final step of the CSB algorithm is to replace the selected active nodes with candidates by order of reserved energy. In this way, we finally build an active node set with the same size as its initial version but higher residual energy, which is helpful to extend the network lifetime.
The CSB algorithm can be divided into three processes and pseudocodes are shown in Algorithm 1.
Input: G = (V, E),
ɛ
, X = Output: ANS, CS. (1) //Initialization_Process ( ) (2) Calculate DCR = {DCR1, DCR2, …, (3) Set the state of all nodes as Un-Covered; (4) Sort nodes into sequence with partially ordered tuple (5) ANS ←∅, CS ←∅; (6) (7) ANS ← (8) (9) (10) (11) (12) //Cover_Set_Balance_Process ( ) (13) Sort CS into a sequence with decreasing order of the set size; (14) (15) Sort nodes in (16) (17) find out all k which satisfies (18) (19) (20) (21) //Node_Replace_Process ( ) (22) (23) (24) if (25) (26) select a node m from all candidates of i with maximal residual energy (27) ANS ← ANS + (28)
The Initialization_Process is used to build a primary active node set and corresponding cover sets. The basic steps are described as follows. There are two different states for each node in the network, namely, Primary-Covered and Un-Covered, which are used to mark whether it is within the cover set of one node in the active node set. The states for all nodes are initialized as Un-Covered (Line 3). Then we sort nodes with partially ordered tuple (data coverage range, residual energy) and initialize the active node set as empty set (Line 4-5). Finally, we check nodes in sequence with state as Un-Covered, and add them into the active node set if the required conditions are satisfied (Line 6–11).
The Cover_Set_Balance_Process aims at balancing the size of cover sets generated with the Initialization_Process. Firstly, the cover sets are ordered and checked accordingly to their set size (Line 13). Secondarily, nodes in a given cover set
The Node_Replace_Process focuses on nodes exchange by replacing the low-energy active nodes with high-residual-energy candidates. All feasible candidate nodes of i are checked (Line 23–25), and we select the one (marked as m) with maximal residual energy among all these candidates (Line 26). Finally, the active node set is updated as well as the cover set for node m (Line 27).
The CSB algorithm follows the idea of replacing the active nodes with candidates with higher residual energy. However, it has the same number of active nodes compared with the approach which only uses the partially ordered tuple (data coverage range, residual energy). In the following we introduce a new HREF algorithm to further reduce the number of active nodes based on CNSC algorithm.
3.2. HREF Algorithm
We first introduce an algorithm for the CNS computing problem and then propose a High Residual Energy First node selection algorithm (HREF) for the active node selection problem.
3.2.1. CNSC Algorithm
The CNS computing problem is to find one subset
To reduce the time complexity, we assume each

Here we demonstrate an example to illustrate the two basic operations. Let
In the following we illustrate the CNS computing process for Consider the sensing data 36.5 of consider the sensing data 34.5 of consider the sensing data 36.9 of
The deviation between 35.3 and the sensing data of nodes in set
Algorithm 2 provides the pseudocodes for CNSC algorithm.
Input: ANS, ɛ, CS = Output: ANS. (1) (2) (3) (4) placed them in node_vector; (5) (6) (7) (8) (9) (10) (11) Dset = Dset + {the kth node in node_vector}, temp = temp – (12) (13) (14) if ( (15) (16) (17)
3.2.2. HREF Algorithm
For a given
Input: G = (V, E),
ɛ
, Output: ANS. (1) Run CSB algorithm to obtain the initial ANS and CS; (2) Run CNSC algorithm to obtain CNS; (3) Mark all nodes in ANS as Un-Completed; (4) Sort CNS with increasing order of their set size; (5) (6) (7) ANS ← ANS − (8) (9) (10)
In Line 3, an active node set is generated with respect to the concept of data coverage range and corresponding correlated node set in ANS. Then we mark all active nodes as Un-Completed. There are two different states for each node in the active node set, namely, Completed and Un-Completed. In Line 4, we sort CNS with ascending order of their set size. In Line 5–10, we check whether if an active node can be removed from ANS and mark each node in
4. Theoretical Analysis
Theorem 7.
The CSB and HREF algorithms correctly generate an active node set for a given wireless sensor network even in case that there are message losses.
Proof.
The cases with CSB and HREF are described as follows.
Firstly, we prove that the sink node obtains all sensing data of the nodes in Closed state through the selected active node set. At the beginning of CSB and HREF, all nodes are active nodes. The state that whether one node is closed or not depending on the condition whether the sensing data can be fused by the corresponding correlated node set. In these algorithms, the node is removed from the active node set only in case the condition is satisfied. Thus it is sure that all sensing data can be obtained from nodes in ANS calculated via CSB and HREF. Secondly, we prove that CSB and HREF correctly generate an active node set even in case that there are message losses. Note that our algorithms aim at shutting down certain nodes if they can be fused by other active nodes, which means that these nodes keep active if the above condition is not satisfied. It is obvious that the message losses never reduce the number of active nodes, and thus CSB and HREF correctly generate an active node set correctly in case of message losses.
Theorem 8.
The active node set size with CSB is at most
Proof.
The active node selection problem with respect to the concept of data coverage range is essentially a set covering problems [27]. We regard the problem of selecting a smallest size of active node set as the problem of selecting the minimum size of subset in set-covering issue [22]. Similar to the greedy approximation algorithm of set covering problem, CSB also takes the greedy strategy to maximize the size of data coverage range for each new added active node. Let δ be the size of selected active node set with number of nodes
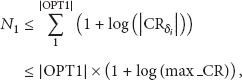
Due to
Theorem 9.
The time complexity of CSB is
Proof.
The CSB algorithm is divided into three processes as mentioned.
In the Initialization_Process, it is easy to know that the time complexity of obtaining all node's data coverage range is
In the Cover_Set_Balance_Process, the time complexity for each covered node to find the active node is
In the Node_Replace_Process, the progress of selecting the optimized candidate active node and replacing the low-energy node is carried out simultaneously, and the time complexity is
So the time complexity of CSB is
Theorem 10.
The size of the active node set with HREF is at most
Proof.
We adopt a greedy strategy HREF to solve the active node selection problem. The HREF is divided into two phrases: the first step is the CSB algorithm and the second phrase is to further reduce the number of active nodes selected by CSB.
Assume that the size of active node set with CSB is m. According to [28], the optimized number of active nodes has upper bound as
Theorem 11.
The time complexity of HREF is
Proof.
The time complexity of HREF includes three different phases: the first step runs the CSB algorithm, the second step runs the CNSC algorithm, and the third step shuts down certain nodes. The time complexity for the first step is discussed above as
5. Simulation Results and Analysis
In this section, we demonstrate detailed simulation experiments to evaluate the actual performance of the above algorithms. Note that this paper focuses on the active node selection problem by exploiting correlations among nodes but has no concern with the aggregation operators or probabilistic models. We compare the proposed CSB and HREF algorithms with the DClocal, DCglobal [22], EEDC [24], and Snapshot [28] by running them in the same networks as well as the same parameters for the environment.
Here we adopt two main metrics for the algorithm performance, namely, the number of active nodes and the network lifetime. The number of active nodes is an important measurement since data coverage basically aims at minimizing the number of active nodes. We compare the related algorithms via this metric for a given data collection epoch. Meanwhile, the active node selection problem aims at maximizing the network lifetime, and thus network lifetime is adopted as the other metric for the performance comparison.
In this section, we first introduce the simulation environment, then compare the algorithms via the number of active nodes with different parameters, such as network size, error threshold, and number of events, and finally we compare them by the metric of network lifetime with different parameters as well as interval for each epoch.
5.1. Simulation Environment Setup
We adopt MATLAB as the platform tool which is popularly used in the simulation of wireless sensor networks. The network is set up by placing
We adopt the approach of generating synthetic sensor data on the monitored region. In the synthetic data set, h events are randomly generated as

In this paper we focus on the node selection process and its impact on the network lifetime, while the routing/path selection are both ignored. Readers are guided to other works for details about these issues [29–31]. The default values for the simulation parameters are listed in Table 1.
Default values for the simulation parameters.

5.2. Comparison of Number of Active Nodes
In this part, we compare the performance of our algorithms with related works by various parameters, including network size, error threshold, and the number of events.
5.2.1. Impact of Network Size
The network size is set from 100 to 500 with increment as 100, and the simulation result is demonstrated in Figure 2. It shows that the number of the selected active nodes ascends with the network size when the network size is smaller than 400. However, this trend is not obvious when the network size is large enough
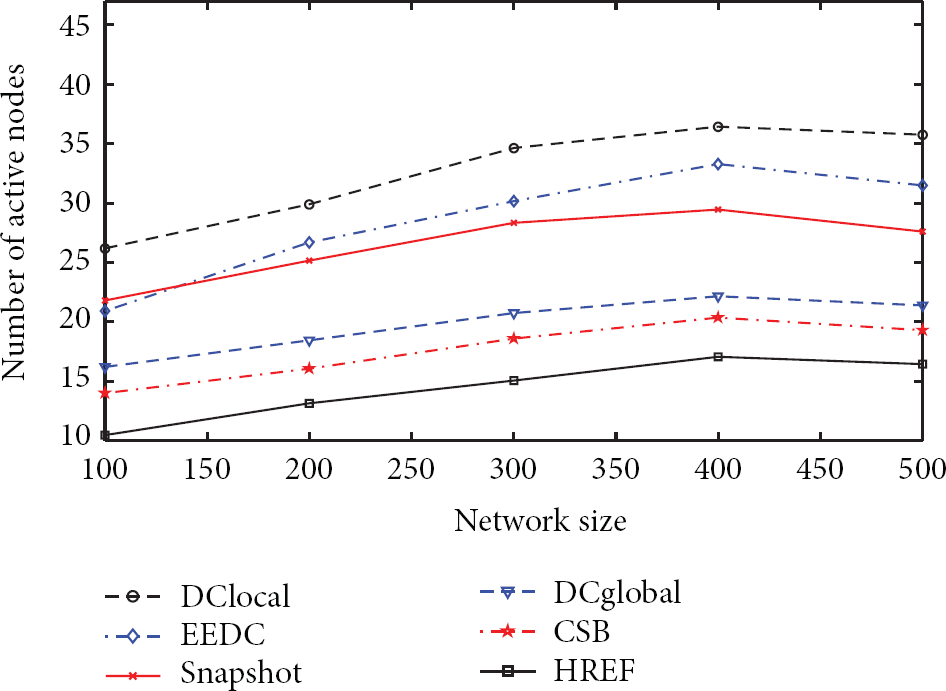
The impact of network size on the number of active nodes.
HREF always has better performance compared with CSB, as we can see from Figure 2. For example, the number of active nodes selected by HREF is only 80.91% of that by CSB in case that the network size is 300. It demonstrates that HREF is rather significant to reduce the active nodes by removing nodes which can be computed by the corresponding correlated node set with the help of CNSC algorithm.
In all cases, HREF and CSB have better performance compared with related algorithms, that is, EEDC, DCglobal, Snapshot, and DClocal. When
5.2.2. Impact of Error Threshold
The error threshold varies from 0.1 to 1.15 with increment as 0.15 in the simulations. As shown in Figure 3, the number of active nodes selected by HREF is lower than other algorithms in all cases. As the error threshold increases in the range of [0.1, 0.55], the number of active nodes decreases significantly. However, it is not obvious in the case that the error threshold is larger than 0.7. Hence, it is helpful to reduce the number of active nodes if a larger error threshold is tolerant in some applications.

The impact of error threshold on the number of active nodes.
5.2.3. Impact of the Number of Events
The number of events varies from 5 to 40 with increment as 5 and the simulation result is demonstrated in Figure 4. It shows that the number of selected active nodes is independent of the number of events by using the data computing Formula (2). It can be seen that HREF and CSB have better performance compared with related algorithms regardless of the number of events.

The impact of the number of events on the number of active nodes.
5.3. Comparison of Network Lifetime
There are variations of measurement for network lifetime [27], such as the first node to die, the number of alive nodes, and the fraction of alive nodes. The measurement with the first node to die is not a good measure metric in practical applications, especially in the dense-deployed wireless sensor networks. This is because the redundancy among correlated nodes is helpful to illuminate the defect of single-node failure. The definition based on fraction of alive nodes regards that the network is alive when the fraction of surviving nodes remains above a given threshold [32]. The network lifetime is defined in this paper as the time period during which the fraction of alive nodes remains above a given threshold and they are also connected.
To measure the network lifetime, we have to determine the relay nodes forwarding the sensing data from active nodes by constructing a minimum Steiner tree [33]. The nodes selected by the minimum Steiner tree construction step are called Steiner nodes. Note that the relay nodes do not need to sense data. In the following experiments, we compared the network lifetime of our algorithms to related algorithms in various environmental parameters.
5.3.1. Impact of Network Size
The network size is set from 100 to 500 with increment as 100, and the simulation result is demonstrated in Figure 5. It shows that the network lifetime increases along with the network size increasing. This is reasonable because the number of selected nodes might be independent on the network size. When there is enough data redundancy among the sensing data, more redundant nodes are used to extend the network lifetime, as shown in Section 5.2.1, HREF and CSB have better performance compared with related algorithms regardless of network size. Especially, our algorithm works better when the network size is larger than 200.

The impact of network size on the network lifetime.
The HREF has significant improvement on the network lifetime compared with CSB too. For example, the lifetime has about 18.19% increment compared with CSB in case that the network size is 300. It is reasonable since we adopt not only node reduction but also node replacement strategies which are rather helpful to enlarge the network lifetime.
5.3.2. Impact of Error Threshold
The error threshold varies from 0.1 to 1.15 with increment as 0.15 in the simulations. As shown in Figure 6, the network lifetime increases along with the error threshold increasing. HREF and CSB have better performance compared with the related algorithms, that is, EEDC and DCglobal. CSB has a better performance compared with DCglobal especially when the error threshold is larger than 0.4. The network lifetime of HREF algorithm is longer than the other algorithms in all cases.

The impact of error threshold on the network lifetime.
5.3.3. Impact of Interval
The value of interval varies from 20 to 160 with increment as 20 in the simulations. In Figure 7, the network lifetime increases along with the interval when it is smaller than 80. However, this trend slows down when interval is large than 80. It means that it benefits to extend the network lifetime if a larger interval is tolerant in some applications. In addition, HREF and CSB have better performance compared with related algorithms regardless of the interval.

The impact of interval on the network lifetime.
5.3.4. Impact of Fraction of Alive Nodes
The fraction of alive nodes varies from 0.6 to 1 with increment as 0.05 in the simulations. In Figure 8, the network lifetime decreases along with the fraction of alive nodes increasing. The HREF has better performance compared with related algorithms. The network lifetime of CSB is longer than that of DCglobal when the fraction of alive nodes is smaller than 0.95. However the case changes when the fraction of alive nodes is larger than 0.95. This is because CSB balances between the data coverage range priority and the energy priority. As the data coverage range priority prefers to select nodes with larger data coverage ranges, these nodes with lower energy might be selected as well, which results in rapid node failure and a dying network. The similar conclusion is drawn in Section 3.1. However, as the measurement of the first node to die is not suitable measure metric for network lifetime evaluation in practical applications, the CSB is still better than DCglobal in this case.
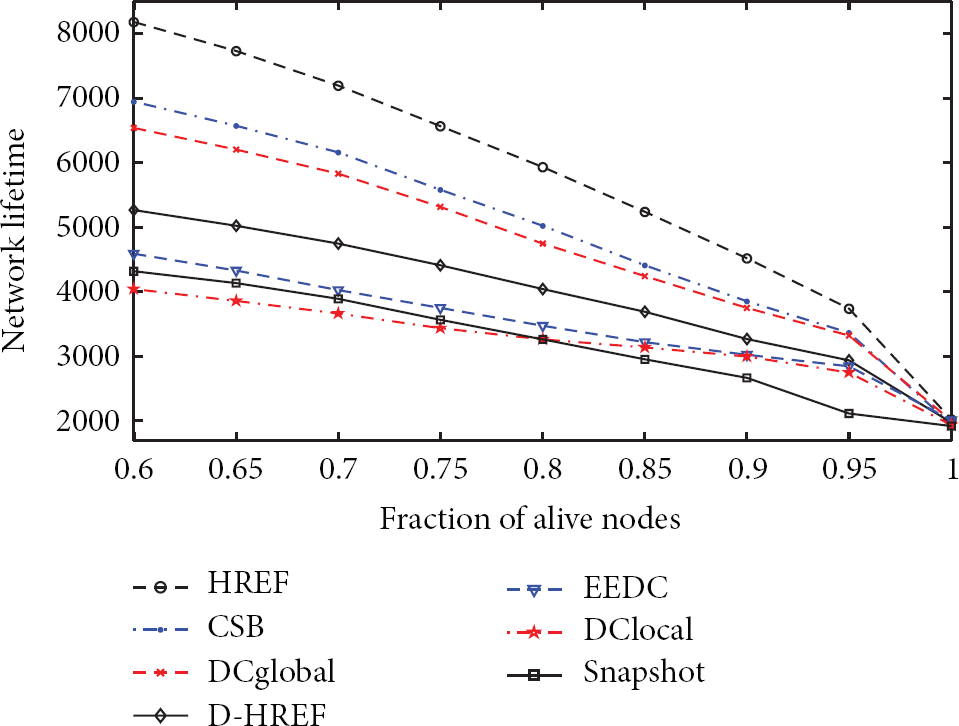
The impact of the fraction of alive nodes on the network lifetime.
5.3.5. Impact of Number of Events
The number of events varies from 5 to 40 with increment as 5 and the simulation result is demonstrated in Figure 9. It shows that network lifetime is independent of the number of events. However, HREF and CSB have better performance compared with related algorithms regardless of the number of events.
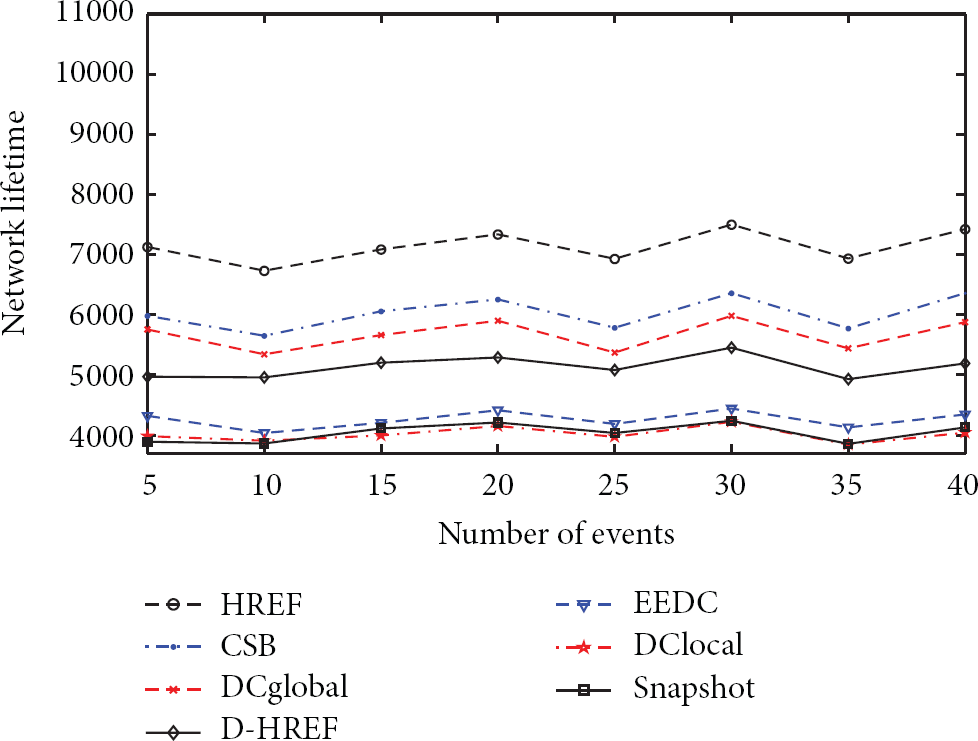
The impact of the number of events on the network lifetime.
6. Related Works
Energy efficiency is a critical design consideration in battery powered and densely deployed wireless sensor networks, which can be achieved by minimizing the number of messages transmitted during the data collection process. Related works include clustering, network coding, in-network data aggregation, and approximate data collection.
Clustering is proven to be an effective approach to provide better data aggregation and scalability for large wireless sensor network [6–11]. Recently, Aslam et al. [7] propose a novel multicriterion optimization technique based on energy-efficient clustering approach. This method takes multiple individual metrics as inputs in the cluster head selection process and simultaneously optimizes the energy efficiency of each individual node as well as the overall system. Karaboga et al. [8] propose an energy-efficient clustering mechanism based on artificial bee colony algorithm to prolong the network lifetime. The simulation results show that the artificial bee colony algorithm based clustering approach can be applied to routing protocols successfully. Naeimi et al. [9] classify routing protocols according to their different objectives and methods by addressing both the shortcomings and the strength of clustering process on each stage of cluster head selection, cluster formation, data aggregation, and data communication and summarized them into categories. Moreover, Lloret et al. demonstrated in [10] that cluster-based mechanisms allow multiple types of network topologies in order to have the most efficient network. Lehasini et al. [11] used clusters to improve the network coverage.
In-network data aggregation [12–18] is another approach to reduce the amount of data transmitted by the nodes and prolong the network lifetime. It performs data aggregation in network to reduce the amount of data transmission by constructing a routing tree. In [12, 13] we can find complete surveys on distributed database management techniques and data aggregation for wireless sensor networks. Al-Karaki et al. [14] present a Grid-based Routing and Aggregator Selection Scheme (GRASS), which achieves low-energy dissipation and low-latency without sacrificing quality. Seyin et al. [15] propose a localized and energy-efficient data aggregation tree approach called Localized Power-Efficient Data Aggregation Protocols (L-PEDAPs) for sensor networks. Gao et al. [16] jointly adopt the cooperative multiple-input-multiple-output and data-aggregation techniques to reduce the energy consumption per bit in wireless sensor network by reducing the amount of data for transmission and better using network resources through cooperative communication.
Approximate data collection is also an energy-efficient approach which is further divided into two subcategories. The first subcategory is approximate data collection via probabilistic models of sensing data collected from wireless sensor networks [19, 20]. Xua and Choi [19] propose a new class of Gaussian processes for resource-constrained mobile sensor networks and propose a distributed algorithm which achieves the field prediction by correctly fusing all observations. Min and Chung [20] present an approximate data gathering approach which utilizes temporal and spatial correlations for wireless sensor network and does not transmit the data to the sink if the data are accurately predicted. The second subcategory is approximate data gathering without probabilistic models. Kotidis [23] propose Snapshot queries for energy-efficient data acquisition in sensor networks. They constitute a network Snapshot through selecting a set of active nodes which is used to provide quick approximate answers to user queries and reducing the energy consumption substantially in wireless sensor network. Gupta et al. [28] design techniques that exploit data correlation among nodes to minimize communication costs incurred during data gathering in a wireless sensor network. They design distributed algorithms that can be implemented in an asynchronous communication model. They also design an exponential approximation algorithm that returns a solution within
In previous work, we have studied the minimum-latency data aggregation problem and proposed a new efficient scheme for it [34]. The basic idea is that we first build an aggregation tree by ordering nodes into layers and then we proposed a scheduling algorithm on the basis of the aggregation tree to determine the transmission time slots for all nodes in the network with collision avoiding. We have proved that the upper bound for data aggregation with our proposed scheme is bounded by
In previous work, we study the node selection problem with data accuracy guaranteed in service-oriented wireless sensor networks [36]. We exploit the spatial correlation between the service data and aim at selecting minimum number of nodes to provide services with data accuracy guaranteed. Firstly, we have formulated this problem into an integer nonlinear programming problem to illustrate its NP-hard property. Secondarily, we have proposed two heuristic algorithms, namely, Separate Selection Algorithm (SSA) and Combined Selection Algorithm (CSA). The SSA is designed to select nodes for each service in a separate way, and the CSA is designed to select nodes according to their contribution increment.
7. Conclusions
Due to the correlation and redundancy among the sensing data in wireless sensor networks, it is an important issue to develop an energy-efficient active node selection strategy, which not only improves the network lifetime but also is helpful to solve other problems, such as lower network throughput and serious node conflict in dense wireless sensor networks. In this paper, we concern with the active node selection issue and provided a formal definition for this problem. We propose the Cover Sets Balance (CSB) algorithm and High Residual Energy First nodes selection (HREF) algorithm aiming at extending the network lifetime of wireless sensor networks. We also propose a Correlated Node Set Computing (CNSC) algorithm to find the correlated node set for a given node. Experimental results on synthesized data sets show that HREF can significantly reduce the number of active nodes, and these algorithms are able to significantly extend the network lifetime compared with related works. In the future work, we are to further consider the temporal correlation among the sensing data and design an efficient node scheduling scheme with both spatial and temporal correlation.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Science Foundation of China under Grand nos. 61370210 and 61103175, Fujian Provincial Natural Science Foundation of China under Grant nos. 2011J01345, 2013J01232, and 2013J01229, and the Development Foundation of Educational Committee of Fujian Province under Grand no. 2012JA12027. It has also been partially supported by the “Ministerio de Ciencia e Innovación,” through the “Plan Nacional de I+D+i 2008–2011” in the “Subprograma de Proyectos de Investigación Fundamental,” Project TEC2011-27516, and by the Polytechnic University of Valencia, though the PAID-15-11 multidisciplinary Projects.