
Abstract
With the rapid evolution of the smart home environment, the demand for natural language processing (NLP) applications on information appliances is increasing. However, it is not easy to embed NLP-based applications in information appliances because most information appliances have hardware constraints such as small memory, limited battery capacity, and restricted processing power. In this paper, we propose a lightweight morphological analysis model, which provides the first step module of NLP for many languages. To overcome hardware constraints, the proposed model modifies a well-known left-longest-match-preference (LLMP) model and simplifies a conventional hidden Markov model (HMM). In the experiments, the proposed model exhibited good performance (a response time of 0.0195 sec per sentence, a memory usage of 1.85 MB, a precision of 92%, and a recall rate of 90%) in terms of the various evaluation measures. On the basis of these experiments, we conclude that the proposed model is suitable for natural language interfaces of information appliances with many hardware limitations because it requires less memory and consumes less battery power.
1. Introduction
A smart home is a home in which all systems work together to make residents’ lives better with more control. In smart homes, household appliances are being rapidly evolved into information appliances (e.g., smartphones and personal digital assistants (PDAs)), which are usable for the purposes of computing, telecommunicating, reproducing, and presenting encoded information in myriad forms and applications. The information appliances will play important roles in the improvement of the quality of life, safety, and security as well as the communication possibilities with the outside world [1]. Therefore, future information appliances will interact with residents via social networking services (SNS) such as Twitter (http://www.twitter.com/), Facebook (http://www.facebook.com/), and Line (http://line.me/en/) [2, 3], as shown in Figure 1.

Scenarios of smart home services via social networking.
To implement such interactions via social networking, information appliances need to be enabled to a Web server or a gateway. Recent approaches have shown methods to embed Web servers directly in resource-constrained devices [2]. As shown in Figure 1, some information appliances in which embedded Web servers will be registered as users’ friends. Then, the registered information appliances will execute various commands that are received from users via social networking services. To realize such smart homes, information appliances should understand users’ natural language commands which are in the form of short text messages (e.g., tweets and recognized speech inputs) [2]. Natural language processing (NLP) techniques can be used to convert a natural language into a formal language that information appliances can understand [4], as shown in Figure 2.

Example of natural language processing in smart home interactions.
As shown in Figure 2, a morphological analyzer segments an input sentence into a sequence of words and annotates the segmented words with part-of-speech (POS) tags. In inflective languages, the major goal of the segmentation process is to find roots of words (e.g., hours = hour+s/plural-noun). In noninflective languages such as Chinese, the major goal of the segmentation process is to correctly split a compound word in a sequence of morphemes (e.g., 美  人 = 美
人 = 美 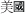 (America) + 人(people)). A named entity recognizer groups some words into meaningful units (e.g., temperature and time). A semantic and speech act analyzer generates a machine-readable semantic form (e.g., set (temperature = 25, time = 14:30)) and identifies user's intention that is implied in an input sentence (e.g., request). As shown in the NLP steps, the initial step in the development of NLP-based applications is to implement a high-performance morphological analyzer (i.e., a morpheme segmentation and part-of-speech (POS) tagging system). However, this implementation is not easy because many information appliances have limited input and output capabilities, limited bandwidth, limited memory, limited battery capacity, and restricted processing power. These hardware limitations make it difficult to use the well-known morphological analysis models that require complex computations on a large amount of training data. Although many high-performance information appliances are developed at present, lightweight morphological analyzers are still needed to efficiently realize high-level NLP applications because high-level linguistic models (e.g., named entity recognition, semantic analysis, speech act analysis, and so on) require large memory and high-performance processor. To resolve this problem, we propose a morpheme segmentation and POS tagging model that combines a rule-based method with a statistical method. The current version of the proposed system operates in Korean, but we believe that changing the language will not be a difficult task because the system simply uses a combination of widely used language-independent NLP techniques such as a longest-matching method and a hidden Markov model (HMM).
(America) + 人(people)). A named entity recognizer groups some words into meaningful units (e.g., temperature and time). A semantic and speech act analyzer generates a machine-readable semantic form (e.g., set (temperature = 25, time = 14:30)) and identifies user's intention that is implied in an input sentence (e.g., request). As shown in the NLP steps, the initial step in the development of NLP-based applications is to implement a high-performance morphological analyzer (i.e., a morpheme segmentation and part-of-speech (POS) tagging system). However, this implementation is not easy because many information appliances have limited input and output capabilities, limited bandwidth, limited memory, limited battery capacity, and restricted processing power. These hardware limitations make it difficult to use the well-known morphological analysis models that require complex computations on a large amount of training data. Although many high-performance information appliances are developed at present, lightweight morphological analyzers are still needed to efficiently realize high-level NLP applications because high-level linguistic models (e.g., named entity recognition, semantic analysis, speech act analysis, and so on) require large memory and high-performance processor. To resolve this problem, we propose a morpheme segmentation and POS tagging model that combines a rule-based method with a statistical method. The current version of the proposed system operates in Korean, but we believe that changing the language will not be a difficult task because the system simply uses a combination of widely used language-independent NLP techniques such as a longest-matching method and a hidden Markov model (HMM).
This paper is organized as follows. In Section 2, we review the previous work on morpheme segmentation and POS tagging systems. In Section 3, we present a hybrid system for morpheme segmentation and POS tagging in information appliances with restricted resources. In Section 4, we report the result of our experiments. Finally, we draw conclusions in Section 5.
2. Related Works
Morpheme segmentation and POS tagging have been widely studied by many researchers [5–8]. Previous morpheme segmentation methods can be classified into two groups: rule-based models [9–12] and tabular parsing models [13]. Since the rule-based models are based on stemming [9, 10] or longest matching [11, 12], they are widely used for analytic languages (i.e., isolating languages) with low morpheme-per-word ratios (e.g., Chinese and English). Although rule-based models are simple and exhibit decent performance, they are not appropriate for synthetic languages (i.e., agglutinative languages) with high morpheme-per-word ratios (e.g., Korean, Japanese, and Turkish) because various linguistic problems occur in separating a word into a sequence of morphemes. Therefore, tabular parsing models are widely used for the Korean language, although they require complex computations to identify all possible morpheme candidates. However, it is impractical to use these tabular parsing models in information appliances, which typically have restricted processing power. To resolve this problem, we propose an efficient morpheme segmentation method based on modified longest-match-preference rules.
The initial approaches to POS tagging were based on rule-based models. Karlsson [14] applied constraint grammars (the grammar formalism was specified as a list of linguistic constraints) to POS tagging. Some researchers dealt with POS tagging as a part of syntactic analysis using rules that had been handcrafted on the basis of knowledge of morphology and intuition [15, 16]. Although these rule-based models are simple and clear, they have some drawbacks. First, they require handcrafted linguistic knowledge, which is considerably costly to construct and maintain. Second, they cannot effectively handle unknown word patterns because they use lexical levels of predefined patterns. Approaches that are designed to resolve these problems are mainly based on statistical models. The HMM is a representative model of statistical POS tagging for many languages [17]. To improve performance, some researchers have tried to apply effective smoothing methods or language-dependent characteristics to a conventional HMM [17, 18]. Because these statistical models can automatically obtain the necessary information for POS tagging, they do not require the construction and maintenance of linguistic knowledge. In addition, they are generally more robust to unknown word patterns than to the rule-based models. However, in information appliances with a small main memory, it is impractical to use these statistical models because they have large memory requirements. Conditional random fields (CRFs) and maximum entropy Markov models (MEMMs) are good frameworks that use contextual features for building probabilistic models to segment and label sequence data [19]. However, the strength of these discriminative models cannot help being restricted in information appliances with restricted processing power because they generally require more complex computations than an HMM for parameter estimations and probability calculations. Kudo et al. [20] proposed a compact CRF-based model in POS tagging of Japanese. Although Kudo's model showed good performances, it still requires larger memory capacity than an HMM-based model because it uses additional n-gram features in order to increase performances. In the experiments on automatic word spacing which are performed in a commercial mobile phone with a XSCALE PXA270 CPU, 51.26 MB memory, and Windows Mobile 5.0, a CRF-based model was 2.11 times slower in response speed and 77.61 times larger in memory usage than an HMM-based model. To resolve these problems, we proposed a modified hidden Markov model that requires much less memory for loading statistical information.
3. Lightweight Morphological Analysis and POS Tagging
3.1. Modified Left-Longest-Match-Preference Method for Morpheme Segmentation
In English, a word is a spacing unit, but in Korean, an eojeol that consists of one or more morphemes comprises a spacing unit. Therefore, for morphological analysis of Korean sentences, eojeol's should be first segmented into several morphemes. In this paper, we refer to an eojeol as a word for convenience because an eojeol plays the similar role as a word in the English language. To aid the readability of the examples, we use Romanized Korean characters called Hangeul and insert hyphen symbols between Korean characters called eumjeol's. The segmented morphemes can then be recovered into their lemma forms (i.e., lexical roots). To perform these processes in information appliances, we propose a method based on modified left-longest-match-preference (LLMP) rules. The conventional LLMP model scans an input word from left to right and matches the input word against each key in a morpheme dictionary. Then, it returns a lemma form of the longest-matched key and continues to scan the remainder of the input word. If a lemma has various POSs, the LLMP model assigns the most frequent POS to the lemma. Owing to the characteristic of longest matching, the conventional LLMP model cannot find all morpheme candidates in an input word, as shown in Figure 3.

Example of the wrong left longest match.
In Figure 3, the correct morpheme sequence of “jip-gwon-han (doing the seizure of power)” is “jip-gwon (seizure of power)/noun + ha (do)/verb_suffix + n (-ing)/ending” in this context. However, the conventional LLMP model only returns “jip-gwon (seizure of power)/noun + han (hate)/noun” because “han (hate)/noun” is a longer morpheme than “ha (do)/verb_suffix” and “n (-ing)/ending.” We refer to short morphemes that are covered by long morphemes as hidden morphemes. To increase the recall rate of morphological analysis by resolving this hidden morpheme problem, we modify the LLMP model by adding supplementary rules for finding hidden morphemes. To construct the supplementary rules, we first implemented a Korean morpheme segmentation system based on the LLMP model. Second, we annotated alarge Korean corpus using the morpheme segmentation system. By comparing the results of automatic annotation with the correct results of human annotation, we automatically collected the cases where a long morpheme should be divided into a set of shorter morphemes. Finally, we selected the top-n cases that most frequently occurred and represented each case using symbolic rules, as listed in Table 1. We refer to these symbolic rules as decomposition rules.
Subset of the decomposition rules.

By using the decomposition rules, the modified LLMP model adds hidden morphemes to the results obtained by the initial analysis, performed using a conventional LLMP model. For example, the modified LLMP model matches the longest-match morpheme “han (hate)” against “han (hate)” → “ha (do)/verb_suffix + n (-ing)/ending” and “han (hate)” → “ha (do)/adjective_suffix + n (-ing)/ending” in the decomposition rules. Then, it adds “ha (do)/verb_suffix + n (-ing)/ending” and “ha (do)/adjective_suffix + n (-ing)/ending” to the original morpheme sequence, as shown in Figure 4.

Processing example of the modified LLMP model.
3.2. Simplified HMM for POS Tagging
Let

In (1),
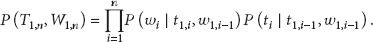
Equation (2) is simplified by making two assumptions: the current POS tag is dependent only upon the previous POS tag and the current word is only affected by its POS tag. Equation (3) is a well-known HMM model for POS tagging:

In (3),

Example of in-word HMMs based on the tabular parsing method.
In Figure 5, the gray rectangles represent the in-word HMMs based on the modified LLMP model. However, these in-word HMMs require more computing power, because they increase the complexity of POS tagging. To resolve this problem, we simplify the observation probability and the transition probability calculations based on the assumption that the first POS tag and the last POS tag provide important clues to syntactically connect words, as shown in
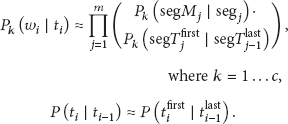
In (4),

Example of the simplified HMM based on the modified LLMP model.
As shown in Figure 6, the transition probability between “chong-20-nyeon-eul (for total of 20 years)” and “jip-gwon-han (doing the seizure of power)” is calculated based on grammatical possibilities between the POS tag “noun” of the first morpheme “jip-gwon” in the current word and the POS tag “postpositional_word” of the last morpheme “eul” in the previous word. The observation probability of the word “jip-gwon-han” is calculated as the maximum score among the following three probabilities:

In the above example, we can assign
4. Experiments
4.1. Data Sets and Experimental Settings
To evaluate the proposed model experimentally, we used the 21st Century Sejong Project's POS-tagged corpus [22]. Table 2 describes the Sejong POS-tagged corpus in brief.
Description of Sejong POS-tagged corpus.

We divided the POS-tagged corpus into training and test data, at a ratio of nine to one. We then performed a 10-fold cross-validation using the following evaluation measures: precision, recall rate, and F1-measure. In order to evaluate the usefulness of the proposed model in a real information appliance environment, we implemented it in a commercial mobile phone with a XSCALE PXA270 CPU, 51.26 MB memory, and Windows Mobile 5.0.
4.2. Experimental Results
The first experiment performed was intended to evaluate the changes in performance with the proposed model, based on the number of decomposition rules. We computed the average performance of the proposed model at various cutoff points in Figure 7.

F1-measure scores at various cutoff points.
In Figure 7, the more rules the proposed model had, the higher performance it obtained. However, we believe that the model incorporating top-40% rules is the most suitable for information appliances because the models having more rules require more processing time and larger working memories, while delivering limited performance improvement over models with smaller rule sets.
In the second experiment, we compared the performance of the proposed model with those that are representative of previous models, using the same training and testing data, as listed in Table 3.
Comparison of precision and recall rates.

In Table 3, “LLMP” is a morphological analyzer based on conventional LLMP rules. This morphological analyzer does not need additional POS tagging processes because it returns one morpheme sequence per word. “Tabular parsing + HMM” is a POS tagger based on an HMM that selects the most reasonable sequence among all possible morpheme candidates generated by the tabular parsing method. The system is one of state-of-the-art Korean morphological analyzers which show F1-measures of 94~95% [18]. “Modified LLMP + Simplified HMM” is the proposed POS tagger that selects the most probable sequence among a number of morpheme candidates generated by the modified LLMP model. As listed in Table 3, “Tabular parsing + HMM” exhibited the best performance in terms of all measures. However, the performance differences between the proposed model and the “Tabular parsing + HMM” model were much smaller than those between the proposed model and the “LLMP.” This fact reveals that the decomposition rules are very effective. On the other hand, the proposed model significantly outperformed the “LLMP.”
In the last experiment, we compared the memory usage and response time of the above models, as listed in Table 4.
Comparison of memory usage and response time.

As listed in Table 4, the proposed model used much less memory and required much less processing time than the “Tabular parsing + HMM” model. Let N denote the number of eomjeol's in an eojeol. In the scan procedure from left to right for matching an eojeol against each key in a morpheme dictionary, the tabular parsing model has the time complexity
4.3. Contribution to Distributed Sensor Networks
Smart home technology can be used in the following key areas in which various sensors should interact with each other in order to detect residents’ behaviors and protect against dangerous situations [3]:
safety area: intruder detection, burglar deception, fire detection, video surveillance, and so on;
comport area: temperature control, light control, windows control, and so on.
To realize this smart home environment, sensor network systems should gather information detected by sensors and should transmit the information to tablet terminals, gateways, or information appliances. If the sensor network systems adopt NLP techniques (i.e., NLP techniques are embedded in sensors or gateways), they will be able to more promptly detect various events and more accurately determine their actions against events. For example, if a keyword detector based on NLP techniques is embedded in a motion sensor (or CCTV), the sensor network system can generate necessary actions when the keywords like “money” and “give me” are included in the conversation between an intruder and a resident or when a resident shouts “fire” while fast moving. As a result, the proposed model can contribute to making sensor network systems better at understanding residents’ contexts.
5. Conclusions
We proposed a morpheme segmentation and POS tagging model for an information appliance. To reduce the number of morpheme candidates, the proposed model uses a method that expands the set of morpheme candidates generated by longest-match-preference rules, instead of using the well-known tabular parsing method. To reduce the computational cost and memory usage, the proposed model uses a method that simplifies an inner HMM, which is necessary in order to find the correct sequence of morphemes in a word. In the experiments, the proposed model exhibited good performance in terms of the various evaluation measures such as precision, recall rate, memory usage, and response time. On the basis of these experiments, we conclude that the proposed model is suitable for information appliances with many hardware limitations because it requires less memory and consumes less battery power.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research was supported by the IT R&D program of MOTIE/MSIP/KEIT [10041678, The Original Technology Development of Interactive Intelligent Personal Assistant Software for the Information Service on multiple domains]. This research was also supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (2013R1A1A4A01005074).