
Abstract
The nonexistence of an end-to-end path poses great challenges to directly adapting the traditional routing algorithms for Internet and mobile ad hoc networks (MANETs) to mobile opportunistic networks (MONs). In this paper, we try to improve the routing performance by resorting to an efficient data item selection mechanism that takes the bandwidth and connection duration time into consideration. For the purpose of evaluation, a specific data item selection mechanism for a probability-based routing is devised, which is formally defined as an optimal decision-making problem and solved by the dynamic programming technique. The simulation results show that our data item selection mechanism greatly reduces the number of aborted transmissions thus enhancing the routing performance in aspects of delivery probability, average latency, and overhead ratio.
1. Introduction
Recent years have seen the development of mobile devices such as smartphones, laptops, and tablet PCs, which makes it easier for people to contact and share data with each other in a cheap way. Many researchers use the term “mobile opportunistic networks (MONs)” to describe this special kind of delay-tolerant network (DTN), in which mobile users move around and communicate with each other via their carried short-distance wireless communication devices. Since MONs experience intermittent connectivity incurred by the mobility of users, routing is a mainly concerning and challenging problem [1]. In traditional data networks such as Internet, there are usually some assumptions of the network model, for example, the existence of at least one end-to-end path between source-destination pairs. Any arbitrary link connecting two nodes is assumed to be bidirectional supporting symmetric data rates with low error probability and latency. In addition, the power of each node is considered to be sufficient and thus irrelative to the node throughput. Messages are buffered in intermediate nodes (e.g., routers) and further forwarded to the next-hop relay or successfully received by the destination. In this case, each message is not expected to occupy the buffer of nodes for a long period of time. However, all the above assumptions usually fail in the context of DTNs. A part of applications in DTNs stresses the delivery ratio while being tolerant of an acceptable end-to-end latency, which is known as the “delay-tolerant” property. For further popularizing these kinds of applications, we have to reconsider the widely used network architecture so as to relax the assumption based by the traditional TCP/IP, that the end-to-end connectivity always exists [2].
There are many research achievements of the routing problem in DTNs, which highly improve the performance in the network scenarios like MONs. Most of them focused on exploiting the strategies for choosing relay node(s) during the routing process [3–5], while few literatures [6–8] considered the effect of data item selection on the routing performance. However, the combination of long-term storage and the message replication performed by many DTN routing protocols imposes a high bandwidth and storage overhead on wireless nodes [9]. Moreover, the data units disseminated in this context, called bundles, are self-contained. What is more, the application-level data units can often be large [10]. As a result, the nodes' buffer, in this context, usually works at a full load status. Similarly, the available bandwidth for a certain connection is likely to be insufficient to have all the buffered messages forwarded. Consequently, regardless of the specific routing algorithm used, it is important to have efficient scheduling policies to decide which message(s) should be chosen to exchange with another encountered node when bandwidth and connection duration are limited.
In this paper, we try to improve the classical probability routing protocol PRoPHET [11] from this point. By defining the concept of “Transmission Profit,” we introduce the “Optimal Throughput-Aware Probabilistic Routing,” which is consequently modeled as an optimal decision-making problem and is solved by the dynamic programming technique. Based on this model, a data item selection mechanism for PRoPHET is devised in this paper. The data item selection mechanism in this paper applies to the network scenarios with the two following characteristics.
The average throughput of the connection between each pair of nodes is far smaller than the size of messages in their buffer. The energy consumption for each transmission may not be ignored, which highlights the importance of every successful relay operation.
For example, a transmission operation for a message would fail when the available throughput of the used connection is smaller than the size of this message. However, a solution to this problem is to send a message of which the size is not exceeding the connection throughput, thus avoiding the waste of the transmission opportunity. To say the least, even if the throughput of the connection is sufficient for sending either of the messages, the whole profit we gain for each transmission (e.g., the delivery probability or the end-to-end latency) would be distinctive when different messages are selected to send. From this perspective, an efficient data item selection mechanism is expected to be employed in challenged network scenarios.
The rest of this paper is organized as follows. In Section 2 we introduce the system model and the routing model. In Section 3 we formally define the key problem. The improved protocol with the data item selection is given in Section 4. In Section 5 we analyze the simulation result. Section 6 reports on previous similar work. We conclude the paper and discuss future work in Section 7.
2. Preliminary
The mathematical notations are listed in Table 1. In our model, we use a discrete timeline that is divided into many small time slots of which the length is defined as a unit time. We denote the whole nodes set as
Mathematical notations.

PRoPHET routing algorithm records history of encounters and transitivity, and the utility metric is based on an encounter probability with the transitivity. PRoPHET estimates a probabilistic metric called delivery predictability, 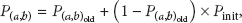
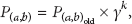
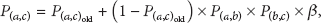
3. Problem Formalization
In this section, we give the details of our proposed data item selection scheme.
3.1. Objective
The objective is to maximize the delivery probability of each message to the destination. In MONs, each node routes the message in a “store-carry-forward” way. We can choose to always forward the message to the node with higher meeting probability to its destination. However, this simple strategy does not take the throughput issue into consideration, which is highly relative to the bandwidth and the connection duration time. Since the bandwidth and the connection duration time between each pair of nodes are limited, the forward sequence of messages in the queue has great effect on the routing performance. Assume that
If the message is forwarded to 
Thus we have the following definition.
Definition 1 (transmission profit).
The transmission profit 
The value of variable
Definition 2 (optimal throughput-aware probabilistic routing).
The optimal probabilistic routing always tries to maximally improve the delivery probability for each message to the destination, by taking the estimated bandwidth of current connection into consideration; that is, each node
For example, as shown in Table 2, there are five messages in the buffer of
Five messages in

3.2. Estimating the Available Throughput
Consider the following definition.
Definition 3 (throughput of connection).
Given a connection duration time t between two nodes and the bandwidth B (KB/unit) of the connection between them, the throughput 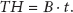
Since we assume that the bandwidth B of the connection is known in advance, the remaining task of estimating the throughput is to get the connection duration time t. We can use the following equation to estimate the duration time for the next upcoming connection between 
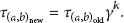
In each time unit, the node checks the status of the connection between 
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12)
An example is shown in Figure 1. The connection between 

An example of the bandwidth estimation process.
3.3. Formalization
We first show that the routing problem can be viewed as a 0-1 knapsack problem, and then we give the formalization of our routing problem.
Theorem 4.
The optimal bandwidth-aware probabilistic routing problem can be formalized to be an optimal decision-making problem and, furthermore, can be viewed as a 0-1 knapsack problem.
Proof.
If viewing the estimated throughput
Theorem 4 shows that the routing problem is an optimal decision-making
Definition 5 (formalization of routing problem).
Assume that the optimal bandwidth-aware probabilistic routing problem is an optimal decision-making problem; that is,

4. Improved Routing Protocol with Data Item Selection
In this section, we give the detailed information about the improved routing protocol. The key problem of routing is formalized in Section 3. We first apply dynamic programming to the data item selection problem. Then we illustrate how to maintain the needed information during the entire routing process. Finally we show the entire procedure of our improved routing protocol.
4.1. Solving the Optimal Decision Problem
The scheme to solve the optimal decision-making problem is stated in Algorithm 2. The calculating process is shown in Lines 1–5. And the process of solution construction is stated in Lines 6–19.
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16)
Overviewing the example through this paper, the value of corresponding ζ and the size of messages are shown in Table 2. In Section 3.2 the estimated throughput for the connection between
Calculation process using dynamic programming.

4.2. Protocol Description
Now we focus on the routing protocol. The same as that in PRoPHET, first of all we need to maintain a table recording the meeting probability. Besides, since the estimation of connection throughput is based on the connection duration time, we also need to let each node record the variables
The routing information table.

There are two parts of our entire protocol. The information exchange protocol is shown in Algorithm 3 and the data transmission protocol is shown in Algorithm 4.
In each time unit (1) (3) call Algorithm 1 to update (4) (5) broadcast the request for (6) (7) forward (8) (9) (10) call Algorithm 4 (11)
In Algorithm 3, the primary task is to update the needed information for timely routing and then to exchange it with neighbor nodes. The updating process is stated in Lines 1–4, where the equation in PRoPHET and our updating algorithm are used. In Line 5 the request for
In Algorithm 4, the current node
5. Simulation
The results are evaluated by the ONE simulator [12]. We firstly adopt the real experimental trace of the Cambridge-iMote dataset, since it is one of the most extensive and widely exploited data traces. This trace includes Bluetooth sightings by groups of users carrying small devices (iMotes) for two months in various locations that we expected many people to visit. Mobile users in this experiment mainly consisted of students from Cambridge University who were asked to carry these iMotes with them at all times for the duration of the experiment. Then we perform the evaluation based on the Helsinki City Scenario, a widely used synthetic mobility model. The simulation is grouped into the following categories: (1) varying buffer size in Cambridge-iMote real trace; (2) varying message time-to-live in Cambridge-iMote real trace; (3) varying buffer size in Helsinki City Model; (4) varying message time-to-live in Helsinki City Model. We compare five different routing protocols based on delivery ratio, overhead ratio, and average latency.
5.1. Simulation in Cambridge-iMote Real Trace
We conduct the simulations by generating 3,300 messages for randomly selected source nodes and by executing the above-mentioned algorithms to forward these messages to their destinations, while recording the delivery ratio, average latency, and average hop count. In simulations on evaluating all these metrics, we set the simulation time as 25%, 50%, 75%, and 100% of the entire time of the dataset. Figure 2 shows the simulation results on varying buffer size, with the message TTL constant at 300 minutes. In Figure 3, we show the simulation results on varying the message TTL, with the node buffer size constant at 50 M. The other settings of the simulation are listed in Table 5.
Simulation settings of Cambridge-iMote trace.


[Cambridge-iMote] Buffer size versus overhead with different percentage of simulation time.

[Cambridge-iMote] Message time-to-live versus overhead with different percentage of simulation time.
Regarding all the figures in Figure 2, the results show that our improved throughput-aware routing significantly outperforms PRoPHET and Epidemic routing in delivery ratio and average latency and reduces the overhead to an extent. Though the delivery performance between MaxProp and our scheme varies a little, our proposed routing outperforms MaxProp in either of the remaining two criteria. More specifically, from Figures 2(a), 2(d), 2(g), and 2(j), we can see that the effect on the improvement of delivery performance increases with the simulation time prolonged. As shown in the second column of Figure 2, the improved throughput-aware routing has a comparably lower latency than PRoPHET. By referring to the third column of Figure 2, our proposed routing has greater improvement on overhead ratio with the simulation time set longer. From all the subfigures, we can see that the throughput-aware routing has the overall best performance among all the five protocols.
Regarding all the figures in Figure 3, the results show that our proposed routing significantly outperforms the other two protocols in delivery and overhead, while having a slight improvement on average latency. With the simulation time prolonged, the influence of our proposed scheme has greater improvement on all of the three metrics. However, we do not see much improvement on the average latency. From all the subfigures in Figure 3, our proposed routing has a relatively better performance than Epidemic, PRoPHET, and EncounterBased routing. Compared with MaxProp, our proposed routing performs much better when the whole simulation time is short, which indicates that the proposed routing reaches the best status more quickly in real network scenarios.
5.2. Simulation in Helsinki City Scenario
In Helsinki City Scenario [12], the nodes are assumed to be users with mobile phones or similar devices, using Bluetooth interface at 250 KBps bandwidth and 10 m transmission range. In this case, the initial free buffer size of each node is set to be small, which ranges from 5 M to 55 M. There are six trams following predefined routes, and there is an extra high-speed interface at 10 MBps bandwidth and 1000 m transmission range for the communication between trams. Two-thirds of the remaining nodes are pedestrians and one-third is cars. The speed of cars is set to be 1050 km/h and the speed of trams 2536 km/h, with the pause time of 10120 s and 1030 s, respectively. Both pedestrians and cars randomly choose their destinations on the map and move along the shortest path. The parameters settings are listed in Table 6.
Simulation settings of Helsinki City Scenario.
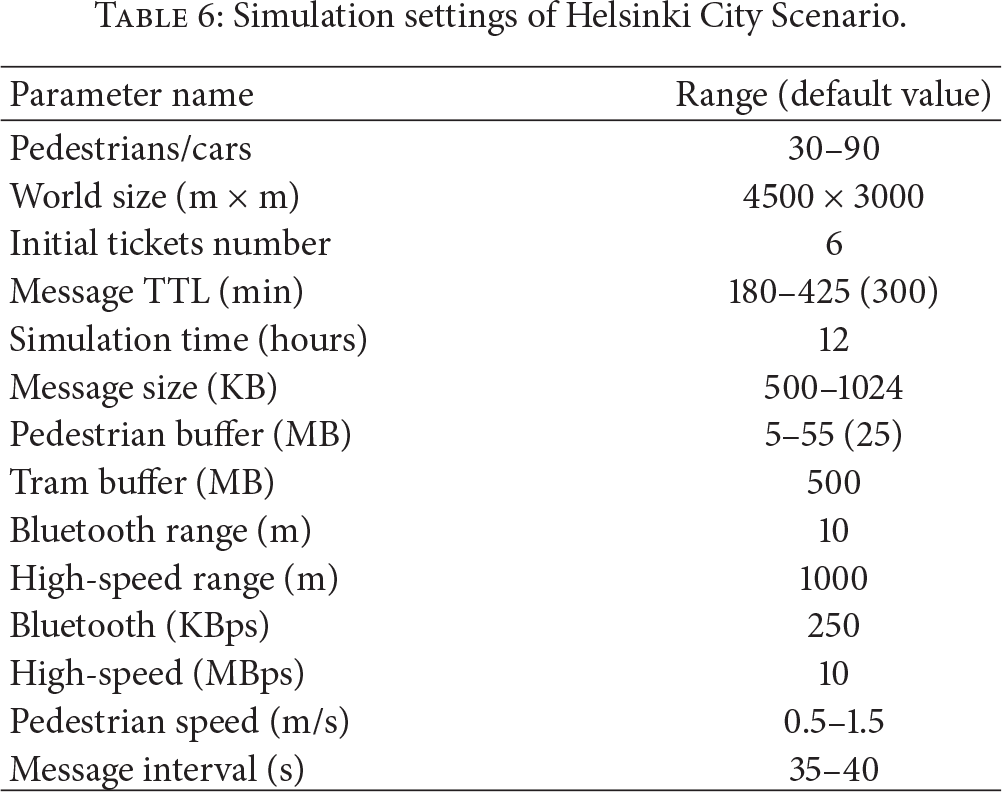
Regarding all the figures in Figure 4, the results show that our improved throughput-aware routing significantly outperforms EncounterBased, PRoPHET, and Epidemic routing in delivery ratio. With the number of active pedestrians and cars increasing, MaxProp routing gradually outperforms the others in all the three criteria. But when there are not enough active pedestrians and cars in the network, the performance of MaxProp routing is almost the same as PRoPHET. In this case, our proposed scheme significantly outperforms the others in all the three criteria. More specifically, from Figures 4(a), 4(d), and 4(g), we can see that the effect on the improvement of delivery performance increases with the number of pedestrians/cars. As shown in the second column of Figure 4, the improved throughput-aware routing has almost the same latency as PRoPHET. By referring to the third column of Figure 4, our proposed routing has greater improvement on overhead ratio. From all the subfigures, we can see that the throughput-aware routing has the overall best performance when the number of nodes in the network is set to be relatively small.
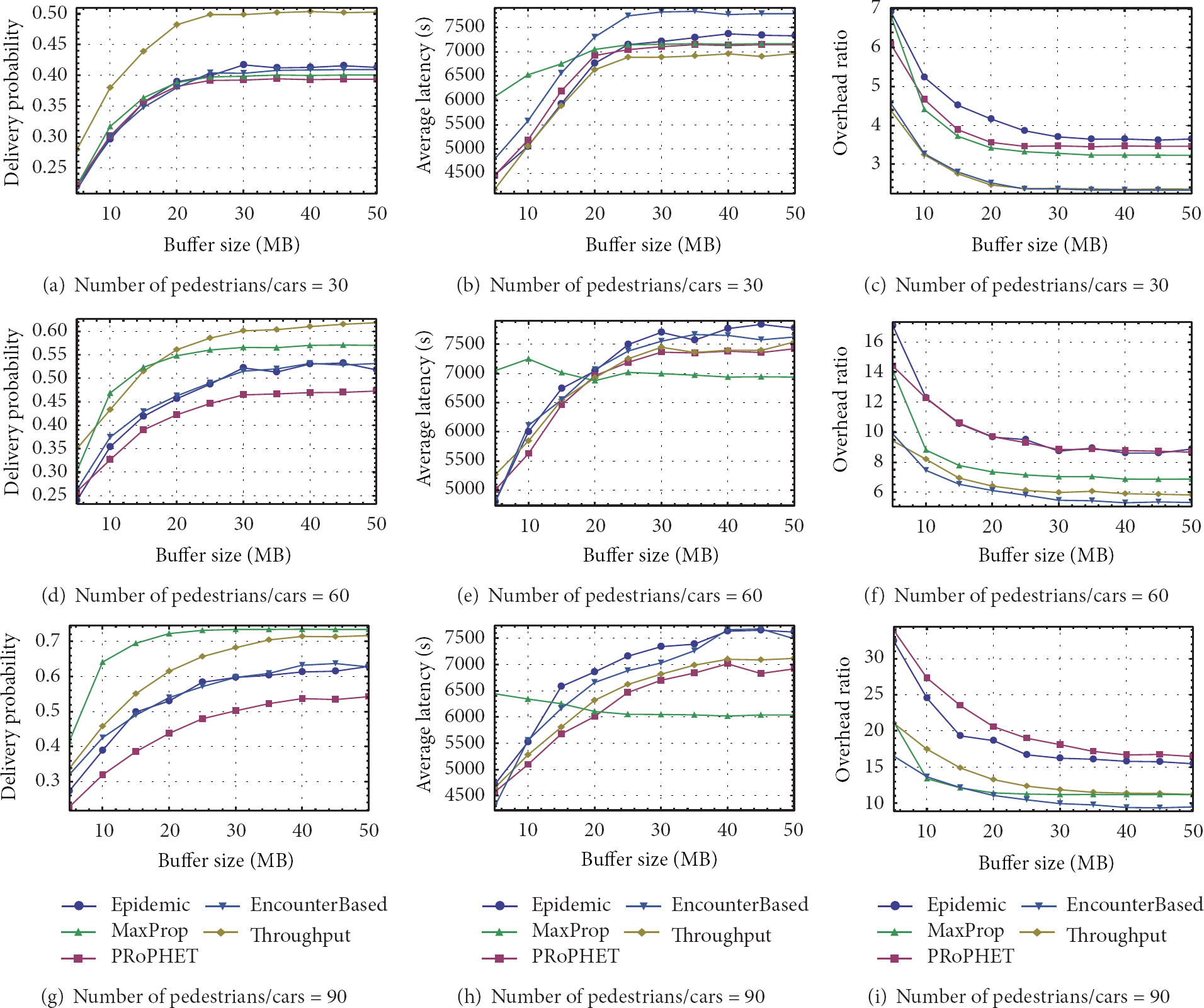
[Helsinki City Scenario] Buffer size versus overhead with different number of nodes.
Figure 5 shows a similar result as in Figure 4 which is that, when the number of nodes is relatively small, our proposed routing outperforms the other four protocols in delivery and overhead and has a slight improvement on average latency. From all the subfigures in Figure 3, our proposed routing performs better than its original edition PRoPHET, which reflects that the same relay node choosing strategy with different data item selection mechanism has totally variant performance. In all, when the nodes are relatively abundant, that is, the density of nodes is large in the network, we prefer to choose MaxProp. On the other hand, our proposed scheme has a comparable improvement on the PRoPHET routing thus making it suitable to work in the network with relatively low density of nodes.
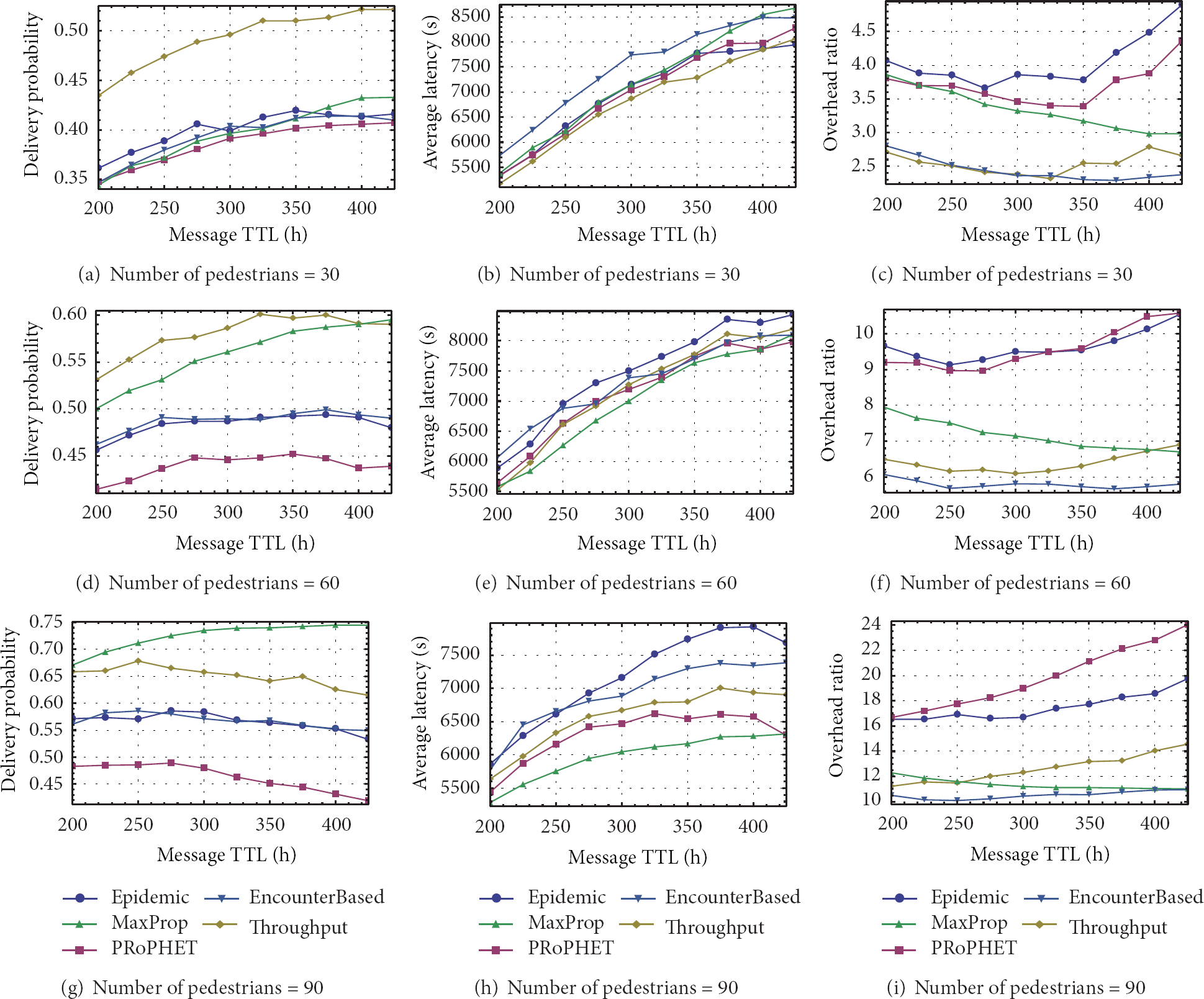
[Helsinki City Scenario] Message time-to-live versus overhead with different number of nodes.
6. Related Works
In [8], Zhu et al. proposed a routing algorithm taking full advantage of predicted probabilistic vehicular trajectories by which the packet delivery probability was theoretically derived. This paper demonstrates that predicted trajectories do help data delivery in vehicular networks. One of the most classical probabilistic routing schemes is probabilistic routing protocol using history of encounters and transitivity (PRoPHET) [11]. In PRoPHET, the utility metric is based on an encounter probability with the transitivity property. For example, given that
Reference [13] presents two multicopy forwarding protocols, called optimal opportunistic forwarding (OOF) and OOF-, which maximize the expected delivery rate and minimize the expected delay, respectively, while requiring that the number of forwarding operations of per message does not exceed a certain threshold. Reference [14] applies the evolutionary games to noncooperative forwarding control in MDTNs, of which the main focus is on mechanisms to rule the participation of the relays in the delivery of messages in DTNs. Reference [15] provides a reliable data delivery scheme for mobile sensor networks with an enhanced delaying technique. Nodes estimate connectivity and expect interencounter time with sink nodes. Connectivity is estimated based on ratio of past and present connections. When the connectivity is unreliable, nodes delay the transmission for the remaining interencounter duration or per-hop lifetime. Reference [16] theoretically proves that considering both factors leads to higher throughput than considering only contact frequency. And, to fully exploit a social network for high throughput and low routing delay, the authors propose a social network oriented routing protocol for DTNs, in which a duration utility-based metric is utilized for evaluating the most suitable the relay node for each message.
In [4], the authors find that it is wise to wait till much better opportunities arise to minimize the communication cost without degrading the delivery ratio and latency. Consequently a universal scheme, named E-Scheme, is proposed to improve routing on the delivery probability metric. In [3], the authors propose a distributed optimal community-aware opportunistic routing (CAOR) algorithm, where a reverse Dijkstra algorithm is devised so as to compute the minimum expected delivery delays of nodes, thus acheving the optimal opportunistic routing performance. By proposing a home-aware community model, whereby turning an MON into a network that only includes community homes, the computational cost and maintenance cost of contact information are greatly reduced.
7. Conclusion
In this paper, we try to improve the routing performance by resorting to an efficient data item selection mechanism in MONs. Our motivation is that, due to the fact that the bandwidth and contact duration time of each connection are highly constrained, a routing protocol would perform very differently with various data selection strategies. By defining the concept of “Transmission Profit,” the concept of “Optimal Throughput-Aware Probabilistic Routing” is introduced, which is consequently modeled as a dynamic programming problem. Then a data item selection algorithm for PRoPHET is devised in this paper. The simulation results show that our data item selection mechanism greatly reduces the number of aborted transmissions thus enhancing the routing performance in aspects of delivery probability, average latency, and overhead ratio. Besides, it is possible to apply the proposed scheme in improving other metrics by redefining the “Transmission Profit.” Our future work will be focused on evaluating the improvement of the data item selection mechanism on various routing protocols.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research was supported in part by Foundation Research Project of Qingdao Science and Technology Plan under Grant no. 12-1-4-2-(14)-jch and Natural Science Foundation of Shandong Province under Grant no. ZR2013FQ022.