
Abstract
TDMA protocols are recognized to save energy consumption by avoiding unnecessary idle listening and communication collision. As sensor nodes are usually equipped with limited resource supply, they are thus desirable to improve network capacity and energy efficiency by adopting TDMA scheduling for wireless sensor networks (WSNs). This paper proposes a TDMA scheduling approach, which reuses time slots among sensor nodes, for WSNs. Specifically, with the idea of consecutive slots assignment, our approach can reduce both the time and energy cost of establishing nodes' schedule. Furthermore, the energy of node's switching is also reduced. To avoid the transmission of a node's result interference to all irrelevant receivers within its interference range, we develop a slot negotiation mechanism for slot assignment. We perform extensive simulations in NS-2 to evaluate our proposed approach. The results show that our approach outperforms existing TDMA scheduling in terms of time and energy overhead.
1. Introduction
Wireless sensor networks (WSNs) are used to gather information in a variety of periodic data collection applications, such as environment sensing, structural health monitoring, and military surveillance [1]. In these applications, sensor nodes are usually self-organized to form a data collection tree. In such a multihop network, node not only periodically generates data but also relies data for other node to the sink. Therefore, each node serves as collector and router in the data gathering applications.
As nodes are equipped with limited energy supply, it is desirable to reduce the energy consumption by avoiding unnecessary idle listening and reducing the number of node's switching at the same time. TDMA protocol can reduce energy consumption by assigning time slots to nodes in the network. Nodes wakeup at their assigned time slots for data receiving and transmission and then enter into sleep mode for saving energy until the next assigned time slot. In a sensor network, it is necessary to improve network performance, such as data collection time and energy efficiency, by executing data transmission in parallel for nodes at the same slots. However, it has been proven that such a improvement is difficult to achieve, due to several constraints of WSNs, for example, energy and wireless interference [2–4].
The scheduling protocol based on TDMA (i.e., TDMA scheduling) [5] fortunately turns to be an efficient approach to realize the concurrent data transmission for nodes in WSNs. The intention behind TDMA scheduling is the idea of time slots reuse among nodes. The time slots reuse, however, is hard to implement, especially in an effective way. Many TDMA scheduling approaches [6–11] have been proposed. In these approaches, the nodes are scheduled under the protocol interference model and the nodes' slots are propagated to two-hop neighbors to eliminate wireless interference occurring in concurrent data transmission. With the scheduling generated by the existing approaches, a packet, however, may be lost because of communication collision, which is caused by the incorrect slot reuse between the receiver and its two-hop neighbors [6, 8, 9, 12]. A possible solution is that each node propagates its slot assignment to three-hop or more neighbors at the expense of extra energy cost [13, 14]. Other TDMA scheduling approaches which take the physical interference into account have been proposed in [15, 16]. The slots will be assigned to a node if the node's signal-to-interference-plus-noise-ratio (SINR) meets
In this paper, we propose a TDMA scheduling with well-designed slots negotiation and consecutive slots assignment mechanisms. Furthermore, our approach adopts a local time synchronization mechanism to remove the impact of clock drift. In our approach, each node's schedule consists of slots which are used to data collection and time synchronization, respectively. Slots are assigned to nodes in the initial phase. Once all nodes establish their schedules, they receive and transmit data according to their schedules in each data collection cycle. In summary, our approach improves the network performance from the following schemes.
Our slot negotiation mechanism can reduce communication collision when nodes assign time slots to themselves in the network initialization period, which makes our approach achieve high packet receiving ratio and energy efficiency. Our consecutive slots assignment mechanism can reduce the cost of establishing nodes' schedule. Furthermore, our approach saves energy by decreasing the times of node's state switching, for example, from sleep state to transmission state.
We evaluate the performance of our approach with extensive simulation experiments in NS2. The simulation results show that, compared with existing TDMA scheduling approach, our proposed approach achieves much higher packet receiving ratio and energy efficiency. The results also demonstrate that our approach can reduce the cost of establishing nodes' schedules by assigning consecutive slots to nodes.
The rest of the paper is organized as follows. We discuss related work in Section 2. Our approach is elaborated in Section 3. In Section 4, we present the evaluation results. Section 5 concludes this paper.
2. Related Work
Many TDMA scheduling approaches have been proposed for data collection in wireless sensor networks. The distributed coloring method has been proposed in [8, 19–22]. When nodes are assigned colors with the distributed coloring method, each node assigns itself with the minimum color number so that the whole network can minimize the number of colors. In [12, 19, 23], node picks up a color by running a lottery game. In [6, 8], node can color itself only when it receives the token from its parent node in the data collection tree. For most of these algorithms, however, slot may not be fully utilized because nodes can only be active at their assigned time slots that are related to their color. In addition, it is a complicated problem to assign slots based on nodes' coloring in a many-to-one communication pattern. In another proposed method, nodes assign collision-free slots based on the k-hop slot information exchange [13, 14, 24]. This method allows two or more nodes to assign slots concurrently. However, the huge message overhead, due to slots information exchange among nodes, results in unacceptable energy consumption.
A TDMA scheduling based on the physical interference has been proposed in [15, 16]. Taking the physical interference into consideration will lead to a better scheduling with spatial reuse. Brar et al. [15] present a distributed algorithm which uses a global primitive to exchange schedule information among nodes, to provide guaranteed collision-free slot assignment. A PHY-aware distributed algorithm for wireless ad hoc networks is proposed in [16]. The authors use the optimal stopping theory to balance the tradeoff between network throughput and the overhead of channel probing. However, the real-time calculation of external interference is prohibited for resource constrained sensor nodes.
Some works aim at improving energy efficiency for data collection with TDMA scheduling [7, 25–29]. Zhao and Tang [7] propose an energy-efficient TDMA schedule to accommodate periodic data collection with dynamic traffic patterns. The energy consumption self-adapts to the node's traffic load produced in traffic pattern when node has a consecutive slots assignment. However, this schedule cannot achieve high energy conservation if nodes have inconsecutive slots assignment. TRAMA [25] is an energy-efficient scheduling protocol that uses distributed election scheme to assign slots to nodes. Nodes use a hash function to determine their priorities among contending neighbors. The drawback of this hashing based method is that the priority for a node is only effective in a specific slot, and thus frequent node switching due to priority changes is needed. Dynamically adjusting the node's duty cycle when the network changes is an effective method to reduce the energy consumption. In [26], nodes can reduce energy consumption through maintaining a low duty cycle during their lifetime. Only part of nodes are scheduled in each data collection cycle. This method, however, is not suitable for periodical data collection applications. Another work in [27] uses the similar method to minimize the energy consumption. They first construct multiple connected dominating sets (CDS) for the network and then propose a heuristic algorithm to find an optimal combination of CDSs. But, the proposed algorithm is not practically applicable to wireless sensor networks, since it requires sink to compute schedule and disseminate schedule to node.
To reduce the cost of establishing nodes' schedules is an important objective for TDMA scheduling. In [30], a constant time scheduling policy is developed for ad hoc networks. However, this policy has not considered the energy efficiency. In [31], two low-complexity randomized scheduling algorithms based on the random access technique are developed for wireless networks. They achieve the low overhead implementation at the cost of performance loss on network capacity. Sanghavi et al. [32] propose a scheduling algorithm which can achieve any required fraction of wireless capacity region in arbitrary wireless networks with low overhead. The algorithm only considers the one-hop interference model that is not proper in the practical WSNs.
3. TDMA Scheduling with Consecutive Slots Assignment
3.1. Overview
Our approach consists of two phases: the network initialization phase for establishing the nodes' schedules and data collection cycles. Figure 1 shows the order of two phases.
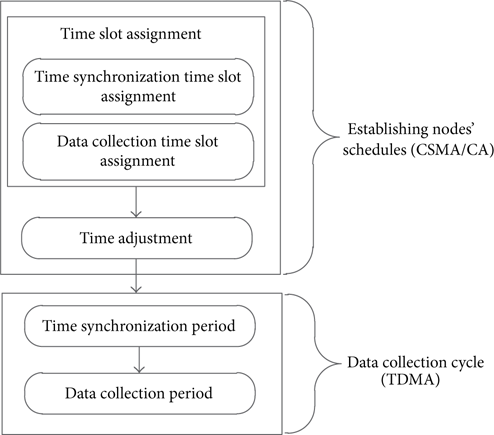
The order of two phases.
Note that nodes maintain their schedules during their lifetime, so that the network initialization phase occurs only once for all nodes. In the first phase, nodes exchange their slots information using CSMA/CA. All nodes are in wake-up status during this phase. Our approach uses a token-passing scheme to control slots assignment process. Node executes slots assignment only when it holds a token and meanwhile its buffer is not empty. After network initialization is finished, all nodes perform data collection tasks according to their schedules. The data is delivery to the sink periodically.
Figure 2 shows the node's schedule structure. Each node's schedule includes a set of slots that represent the active time of the node. Note that the node's slots are not always contiguous in time. In our approach, the first part (SYN) is used for time synchronization. Nodes perform time synchronization using their corresponding slots. It is worthy to point out that sink only has the slot for sending the synchronization packet and the node that has no children only has slot for receiving the synchronization packet. At the data collection (DC) part, nodes switch to the receiving mode in their received slots and to send mode in their transmission slots for transmitting data. Otherwise, they switch to the sleep mode for saving energy. When nodes finish all data activities in a data collection cycle, they will keep in sleep mode until they wake up again in the next data collection cycle.

The structure of the node's schedule. The node's schedule consists of three parts: time synchronization (SYN), data collection (DC), and sleep period (SLEEP).
In this paper, we assume that all nodes in the network already form a data collection tree, in which nodes send their data to sink. To our best knowledge, many well-designed routing protocols [33–35] can be used to build the data collection tree.
3.2. Establishing Nodes' Schedules
The establishing of nodes' schedules aims at assigning slots to nodes for time synchronization and data collection. Our approach uses the depth-first-search (DFS) technique for slot assignment. Since DFS could be used to limit the number of slots assigned to each node, our approach avoids the slots assignment that exceeds the limitation of maximum consecutive slots. In this work, we define maximum consecutive slots as the maximum number of slots that could be assigned to each node when it executes slot allocation. For clarity, Notations shows some notations used in this paper. Note that CT is set when node is initialized and its value is customized by the user according to the application requirements.
After nodes initialization, sink generates a token for slot assignment. The token is passed to each node using DFS technique, and it is always passed to the child that has not received the token before and has the smallest node ID. When node receives the token, it first assigns slot
3.2.1. Slot Assignment
This section discusses the slot assignment for time synchronization and data collection. The flow chart is shown in Figure 3.

The flow chart of slot assignment.
(a) Slot for Time Synchronization. The slot
(b) Token Handling. Before node assigns slots for data transmission, it needs to handle the token as follows. It updates RCT according to (1), where

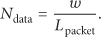
Baed on RCT, the token is handled by using following two rules.
Passing token to its child: if Holding the token and assigning transmit slot: if
Figure 4 illustrates the token passing and slots assignment.

Token passing and slot assignment. We assume that node has
(c) Slot for Data Transmission. After a node deals with the token, it should select the lowest slot number, which is not yet used by its interference nodes, as its slot
Step 1.
The node (requestor) propagates the assigned slot information to its one-hop neighbors by sending inform_slot packet. The inform_slot packet contains the assigned slot information: the destination address, the parent ID, the first slot number, the number of slots, and the level counter. This information is represented using a quintuple: ID, PID, SN, SUM, and LC. The consecutive slots (SN, SN + SUM − 1) are called slot interval. The one-hop neighbors then check PID. If the node's ID is PID (i.e., the node is the parent of requestor), it sends a reply packet to the requestor immediately, or else it switches into listening mode. The reply packet contains the following information: a flag (Flag), and a new slot number (NSN). Therefore, the reply indicates whether or not the slot is reused by the parent's interference nodes. Based on the parent's TL, RL, and UL, the Flag and NSN are set as follows. Note that UL includes the node's two-hop neighbors' slot information that is collected in the schedule exchange phase.
All slots in (SN, SN + SUM − 1) are not listed in the parent's TL, RL, and UL. The Flag and NSN are set as 1 and the requestor's first slot number (i.e., SN), respectively. The details of slot negotiation are shown in Figure 5(a). At least, one slot in (SN, SN + SUM – 1) is listed in the parent's TL, RL, and UL. The parent set Flag to 0, and NSN is set as the lowest slot number that is not listed in the parent's TL, RL, and UL. The details of slot negotiation are shown in Figure 5(b).

A timing diagram for slot negotiation between requestor s2 and parent s1 when the requestor tries to assign slot for data transmission.
Step 2.
When requestor receives the reply packet, it reply ack packet. According to the reply packet, the field in ack packet is set as follows.
The NSN is not listed in the requestor's TL, RL, and UL; the Flag and FSN are set as 1 and NSN, respectively. FSN is defined as the first slot number of consecutive time slots. The NSN is listed in the requestor's TL, RL, and UL. the Flag is set as 0, and FSN is set as the lowest slot number that is not listed in the requestor's TL, RL, and UL. Note that FSN should be larger than NSN.
Step 3.
When the one-hop neighbors of requestor receive the ack packet, they check the Flag and then know whether to execute schedule exchange. If
(d) Schedule Exchange. The schedule exchange is triggered when a node broadcasts its assigned slot(s) to its one-hop neighbors, and then each of these one-hop neighbors propagates the slot(s) information again to their one-hop neighbors (i.e., two-hop neighbors for the claimed node). Therefore, the assigned slot(s) information is propagated to all nodes within the node's interference range.
When a node receives the inform-slot packet in the slot assignment phase, the ack packet actually decides whether or not to perform schedule exchange. The schedule exchange is controlled by the level counter (LC) which indicates the status of packet propagation. If
After the schedule exchange finishes, the ancestors on the path to sink assign forward consecutive slots to transmit the data stored in their buffers. Note that the forward slot number must be larger than the received slot number. The slot assignment for data collection as described before is repeated until sink receives the inform_slot and executes schedule exchange. The slot assignment ends when the token is returned to sink and all nodes in the network finish their slot assignments.
3.2.2. Time Adjustment
When slot assignment is done, sink knows two important parameters on the nodes' schedules: the amount of slots for time synchronization (say
Hence, the start and end time for data collection can be calculated using (3). Consider

For nodes in the network, we use (4) to calculate the final start and end time of a slot. Consider
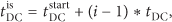

For the node's schedule, we use (6) to calculate the duration time of node's schedule. Consider

Our approach performs time adjustment after the slot assignment is finished. Initially, the sink generates a token for time adjustment. With the token passed to nodes using depth-first-search technique, each node adjusts the time arrangement of each phase, and meanwhile it obtains the duration of the whole schedule for data collection (i.e.,
3.3. Time Synchronization
Time synchronization is critical in TDMA-based scheduling because the nodes involved in the same slot must wake up at the right time to accomplish data exchange. In this work, our approach performs time synchronization locally, and parent only needs to be synchronized with its children in the assigned slots. The time synchronization works as follows.
In the assigned slot, parent broadcasts its time information using SYN packet at first, and its children adjust their clock when they receive the SYN packet. Since a child only needs to be synchronized with its parent, time synchronization is simple, as the clock drift of nodes can be minimized by periodic time synchronization during each data collection cycle.
3.4. Example
We now illustrate our approach using the data collection tree shown in Figure 6. We assume that node produces one packet at an operation periodically. We also assume CT is 2.
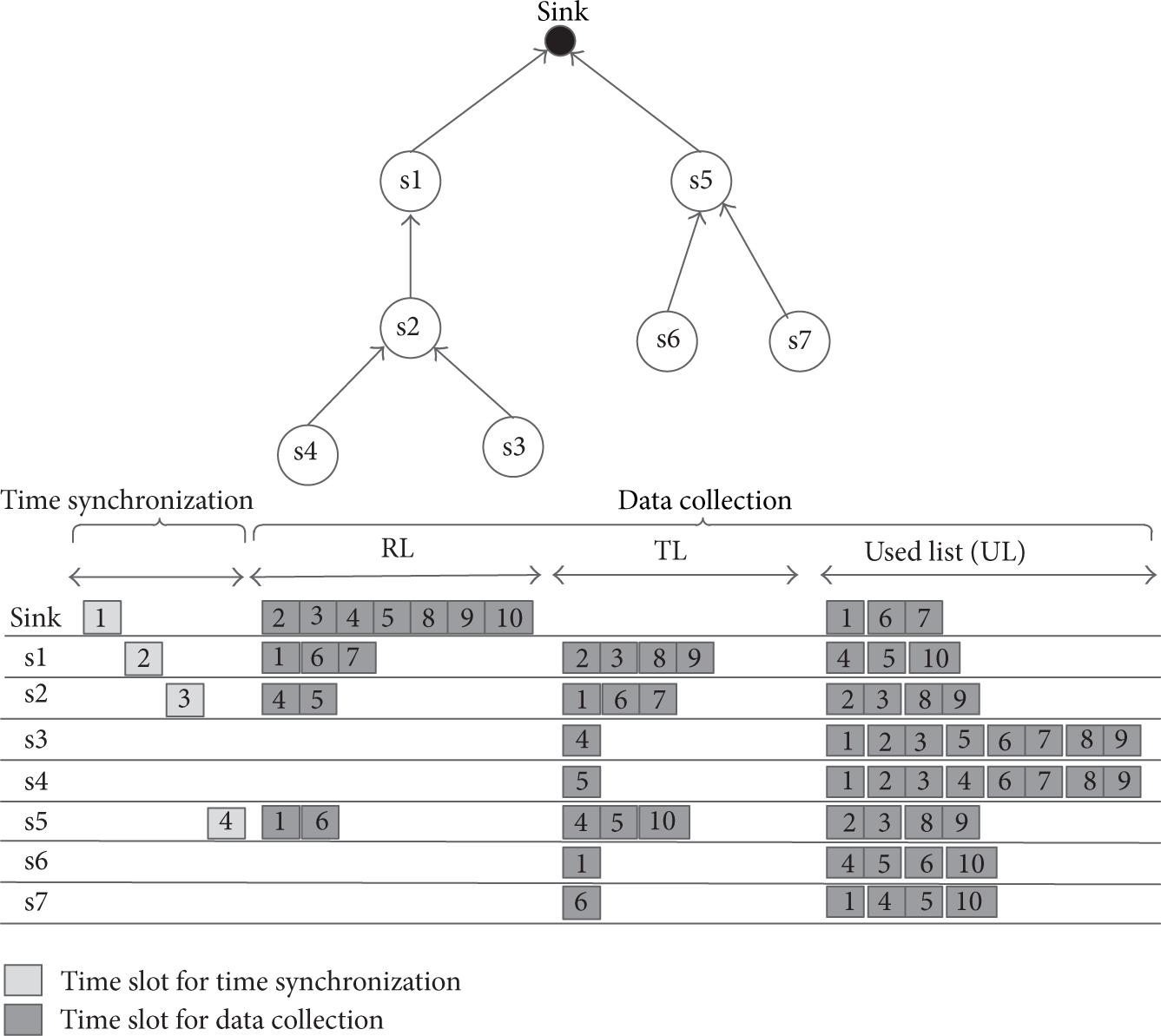
As an example of our approach, each node produces one packet at an operation periodically and the maximum consecutive slots assignment requirement (i.e., the node's buffer limitation) is two packets at one time.
Initially, the slot assignment token is generated by sink and it first passes token to the node s1. When s1 obtains, it first records the slot t1 for receiving time synchronization packet; s1 assigns slot t2 for sending its time synchronization packet because it has a child (i.e., s2). s1 then checks its parent's RCT that is piggybacking by token. Since s1 needs to reserve one slot for its own data produced in an operation, hence, the RCT is updated to 1. As
When s2 receives the token, it records slot t2 for receiving time synchronization packet and then assigns slot t3 for sending its time synchronization packet. According to RCT included in the token, s2 knows that parent's (i.e., s1) CT will reach 2 if it transmits one packet to s1. Therefore, s2 immediately claims slot (i.e., slot 1) for transmitting data and lists this slot in its TL after finishing the cooperation between s1 and s2. s2 and then propagates the slot to its two-hop neighbors using schedule exchange (Section 3.2.1).
As s1 is the parent of s2, it records slot 1 in its RL, whereas s3 and s4 list slot 1 in their ULs as shown in Figure 4. Again, s1, s3, and s4 broadcast slot information to their one-hop neighbors, and hence sink knows that slot 1 is used and then lists it in its UL. After the schedule exchange is completed, s2's parent, s1, will assign forward slots (i.e., slot 2 and 3) to forward two packets received from s2 and produced by itself.
When the token is passed to node s3, the RCT is set as 2 because both s1 and s2 do not have packets. However, since s3 has no children, it executes slot assignment immediately and then the token is returned to s2. When s2 receives the token from s3, the token is passed to s4 because its RCT is 1. The token-passing is replicated until all nodes receive the token. Note that node s6 can reuse slot 1 because slot 1 does is not used by its two-hop neighbors. Thus, in slot 1, s2 and s6 can send their data without collision, and s1 and s5 can receive data from their child in that slot. Similarly, slots 4 and 5 are reused by s3, s4, and s5.
When node s7 claims slot, it first tries to assign slot 2 and then broadcasts to its one-hop neighbors. However, its parent, s5, knows that slot 2 is used by its two-hop neighbors and it cannot receive data from s7 in slot 2 correctly; hence, s5 replies s7 and assigns a new slot 6 that is not listed in its RL, TL, and UL. s7 then confirms the s5's reply using ack packet. If slot 6 is listed in its RL, TL, and UL, it will try to assign another slot and start a new cooperative process. The cooperation between s5 and s7 is similar to Figure 5. When the token is returned to sink permanently, the slot assignment is finished.
Afterwards, the sink initiates the time adjustment phase by generating a new token. All nodes in the network adjust their time arrangement such as the start and end time of each phase according to the time information included in the new token. After the nodes' schedules are establish finally, nodes perform regular data collection tasks based on their schedules.
4. Performance Evaluation
We evaluate our approach named Coop and compare its performance against existing TDMA scheduling FlexiTP [6]. In FlexiTP, sink first generates a token for slot assignment in network initialization phase. The token passing is finished using the depth-first-search technique. Each time, the token is also passed to the child that has the smallest ID. When node assigns a slot, it first announces a slot that is not listed in its TL, RL, and UL and then propagates it to one- and two-hop neighbors. FlexiTP assumes that nodes only buffer one packet at any time, and thus each node has to assign forward slot immediately. Abundant of energy will be consumed due to frequent slot assignment.
We implemented the prototypes of the two approaches in network simulator (NS-2). Our simulation results are based on the mean value of various random network topologies with up to 300 nodes distributed uniformly over a 500 m × 500 m area in all experiments. The location of sink was fixed at the top-center of the network topology. In our experiments, each node produces one packet at an operation in a data collection cycle. The simulation parameters for all experiments were based on Mica2 Mote hardware [6, 36]. Table 1 presents these simulation parameters.
Simulation parameters in NS-2.

4.1. Impact of Network Scale
We first measured the time and energy cost of establishing nodes' schedules. These costs are one-off costs because nodes' schedules will be maintained throughout their lifetime. Figure 7(a) shows the average energy consumption for assigning the nodes' schedule. The energy cost per node is less than 0.6% of the node's initial energy for all network scale. For Coop, when nodes are assigned with no consecutive slots, they spent more energy on slot assignment than those under FlexiTP protocol, in which many control packets are transmitted due to the cooperation between children and its parent. However, the results on packet receiving ratio (PRR), which is calculated by (7) and explained in detail later, in Figure 8(a) show that the extra energy cost plays a tradeoff for PRR. When the the feature of consecutive slots assignment is on, the cost of Coop on energy and time is much lower than FlexiTP because the number of control packets and schedule exchanges is reduced in Coop. Figure 7(b) shows the time overhead, which shares the similar trend on time cost with the energy consumption shown in Figure 7(a).
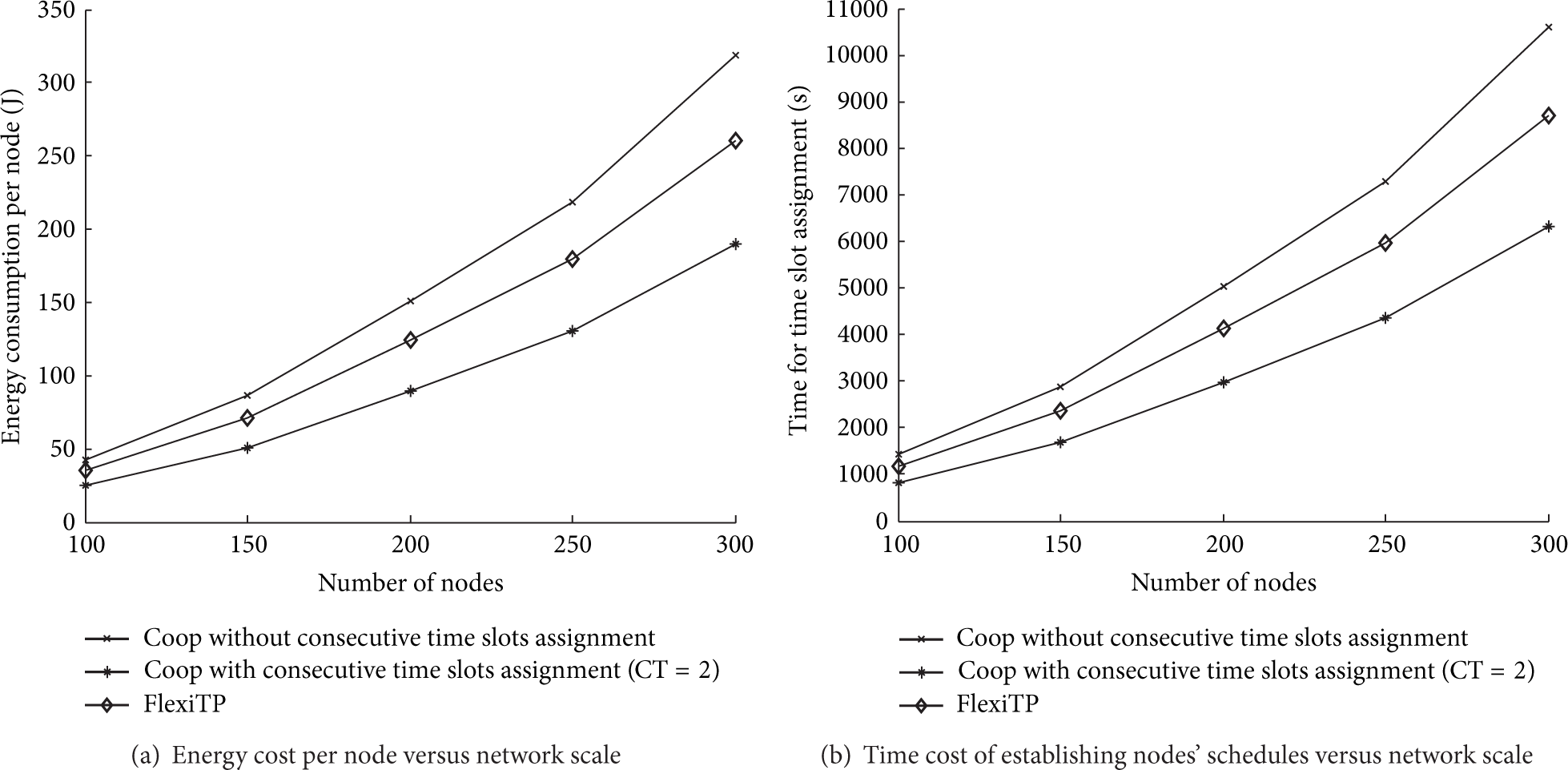
The time and energy cost of establishing nodes' schedules. We refer to the maximum consecutive slots requirement as CT.

The packet receiving ratio and throughput versus network scale.
For data gathering applications, a large number of data need to be sent to sink periodically. The scheduling approach can reduce the duration time of data collection by reusing slot among nodes. On the other hand, data would be received by sink as soon as possible. In this paper, we use (7) to calculate the packet receiving ratio (PRR). Consider


Figure 8(b) shows the throughput performance. We can draw a conclusion that Coop achieves better throughput than FlexiTP. The reason for this is that Coop has better packet receiving ratio (i.e., higher p) than FlexiTP.
In the most cases, sensor nodes have constrained energy supply. We measured the maximum energy consumption that involves network lifetime when the first node in the network dies in a data collection cycle. Furthermore, in order to evaluate the energy efficiency of data collection for each scheduling approach, we use (9) to calculate the energy consumption for data transmission. Consider

Figure 9(a) shows the maximum energy consumption. As shown in the figure, when the feature of consecutive slots assignment is on, nodes can gather at least one packet before executing slot assignment; hence, the consecutive slots are assigned to nodes and reduce the number of node state switching. The energy spent on node state switching is thus saved. As FlexiTP protocol has lower PRR than Coop, nodes consumed lower energy on packet transmission than Coop.

The maximum and average energy consumption for data collection versus network scale.
In Figure 9(b), we show the energy consumption for data transmission. The result shows that the Coop's energy consumption for a bit is lower than FlexiTP about 30 μJ and we attribute this to the Coop's high packet delivery ratio.
4.2. Impact of Consecutive Slots Assignment
In this simulation, we studied the impact of maximum consecutive slots (CT) for the performance of Coop. We varied the CT from 1 to 5 and then measured PRR, energy consumption, and cost for establishing the nodes' schedules under three different networks scales, that is, networks with 100, 200, and 300 nodes, respectively. The results are based on the mean value of different random network topologies.
Figure 10 shows the experiment results of the time and energy cost when nodes have different CT. Both average energy consumption and time overhead are reduced when we increase the CT. However, two features of network lead to these costs falling finally limited with the increase of CT: the first feature is network topology; the other feature is that nodes in the network self-organize into a data collection tree in the network initialization phase, and hence each node in the tree has a fixed subtree rooted at the node. As the CT increases, each node can assign enough consecutive slots at a time to gather all packets that are sent by its descendant, and hence the gain of time and energy cost falling is reduced, and these costs finally trend to a constant when the gain is very small. We measured the reliability of data transmission. As shown in Figure 11(a), the packet receiving ratio is reduced with the increasing of CT. The reason is that packets are lost due to continuous communication collision in the consecutive slots. However, Coop still outperforms TlexiTP on packet delivery. We also show the throughput in Figure 11(b). The throughput was calculated using (8). Even though PRR is decreased with the increasing of CT, Coop still has larger throughput than FlexiTP. The possible reason for this is that the throughput derived by (8) is mainly determined by the packet receiving ratio when there is little difference on the duration of data collection in the same network.
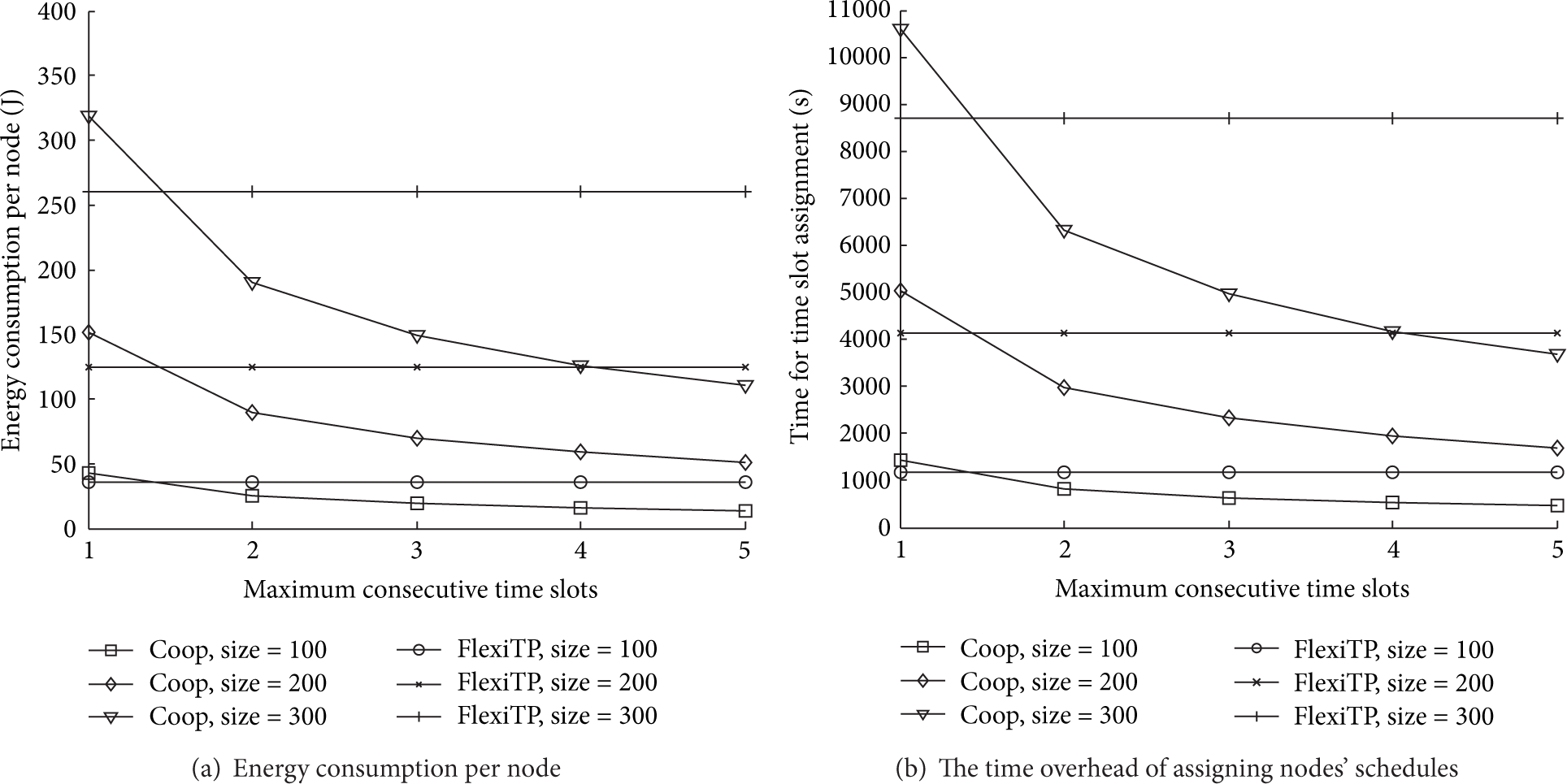
The average energy consumption and time overhead versus maximum consecutive slots requirement.
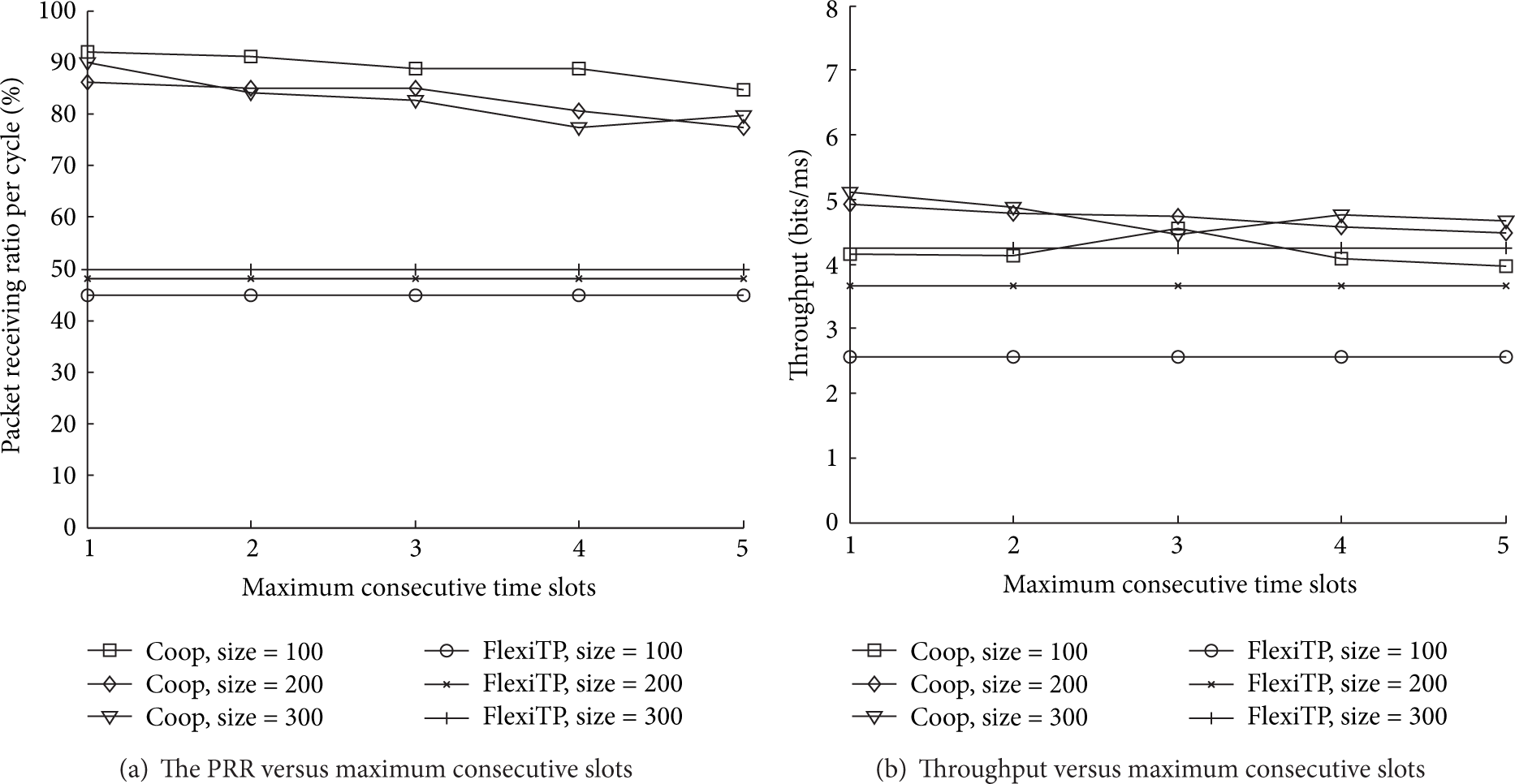
The PRR and throughput versus maximum consecutive slots.
We also measured the maximum energy consumption as shown in Figure 12(a). The result shows that the energy consumption spent on the node state switching is reduced because more consecutive slots are assigned to nodes when a node has larger CT. In addition, the energy for data transmission as shown in Figure 12(b) has no obvious change with the increasing of CT. According to (9), the reason could be that the total energy consumption for data collection and the volume of data transmission are increased with the network scale, and meanwhile the PRR only has small changes.

The energy consumption versus maximum consecutive slots.
5. Conclusion
Wireless sensor networks have limited hardware resource, such as energy, bandwidth, and memory. This paper proposes an efficient TDMA scheduling approach to improve packet receiving ratio yet with acceptable energy and time cost. Our approach uses slot negotiation mechanism to implement slot reuse under the protocol interference model. The slot negotiation produces low communication cost because it only occurs on each link. Furthermore, our approach assigns consecutive slots to nodes so that the time and energy cost are reduced. Our approach also integrates a local time synchronization mechanism to minimize clock drift among nodes. The simulation results show that our approach achieves high packet receiving ratio and energy efficiency and meanwhile decreases the time and energy cost by increasing the number of consecutive slots. In our future work, we would like to develop an efficient schedule adjustment strategy to deal with data transmission fault and network dynamic.
Footnotes
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.