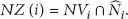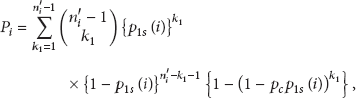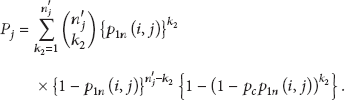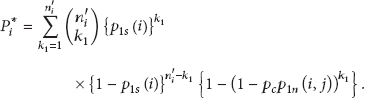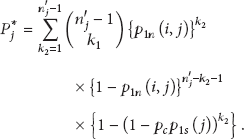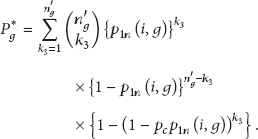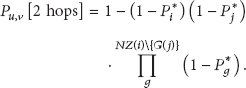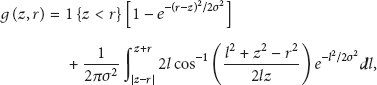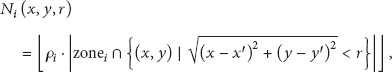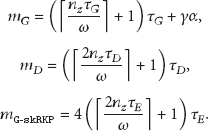Limited capabilities of tiny sensor node make it difficult to build a secure wireless sensor network. To cope with this problem, location-aware key predistribution schemes have been studied but without considering irregularity of real sensing fields. They were designed for ideal sensing fields divided into uniform regular polygons but false is the real sensing field, where we face irregular obstacles, undulations, and boundaries. In this paper, we tackle this problem from practical sense and first introduce the general deployment model, comparable to the previous uniform deployment model. To construct a secure WSN in the general deployment model, we present a new framework called GenDep, which consists of two phases: group placement and key management. In the group placement phase, we find an optimal position for sensor groups so that both connectivity and global coverage are satisfied for secure communications. In the key management phase, we devise a new structure called extended groups to partition the whole deployment area into irregular subareas. GenDep can build secure and flexible WSNs by using the existing key predistribution schemes even designed in the uniform deployment model. To ensure practicality of GenDep, we also conduct rigorous analysis and simulation in this paper.
1. Introduction
Wireless sensor networks (WSNs) play an important role in mission critical applications, such as military systems, healthcare services, and industrial systems. In such applications, security is a crucial requirement. Unfortunately, it is quite challenging to construct secure WSNs because tiny sensor nodes are very constrained in the capacity of computation, communications, storage, and power management. In particular, key management, which is the most fundamental part of security mechanisms, must be considered in the design phase of WSN with regard to the limited capabilities of tiny sensor nodes.
Since Eschenauer and Gligor have introduced the first proposal [1], a variety of approaches have been studied for secure key management based on the key predistribution concept [2–7]. Among them, location-aware key management schemes [5–7] were remarkable in their efficiency in terms of computation and communication costs (Section 2.1). Indeed, the efficiency came from the preknowledge of the location that helps sensor nodes share secret keys effectively with their (likely) adjacent nodes. However, previous approaches are unrealistic. (1) The previous deployment models assumed a sensing field to be a flat area that is dividable into uniform, regular grids. Such a uniform deployment model is, however, far from the real sensing field, which is actually not uniform in its geographical features and so highly inefficient. (2) The previous location-aware key management schemes are not applicable to a general deployment model, which covers various geographic features in the real sensing field. Their target application is so limited; nonuniform density was not allowed for placing the sensor nodes (Section 2.2).
To cope with these problems in this paper, we first present the general deployment model for WSNs and then propose a new location-aware key management framework called GenDep so as to be effective in that model. We can summarize our contribution as follows.
We present the general deployment model (Section 3). We address that the conventional uniform models are unrealistic because geographical features are irregular in the real world. The general deployment model relaxes the constraints of sensing fields and implements the conceptual WSNs to be practical.
On the general deployment model, we construct the new framework called GenDep that actually enables practical location-aware key management. GenDep consists of two phases. First, in the group placement phase (Section 4), we find optimal positions of sensor groups by fulfilling the requirements of WSN applications and geographical features. After placing groups of sensor nodes, we partition a whole sensing field into a number of nonuniform polygons, called zones. Second, in the key management phase (Section 5), we can employ the existing key predistribution schemes (even designed in the uniform deployment model) for our general deployment model. To do so, we devise a new structure of extended groups, each of which consists of a pair of adjacent zones. The extended groups are organized for every pair of zones; thus they overlap each other and connect all neighbors. We treat every extended group as an independent group. Therefore, we can employ any key predistribution scheme for each extended group.
We evaluate GenDep via numerical analyses and simulations (Section 6). In particular, the numerical analyses handle connectivity, security, and storage overhead of sensor nodes with general probability distributions.
2. Background and Problem
2.1. Related Work
Sensor Node Placement. Previous studies on the node placement have focused on how to place a sensor node at an optimal location individually. Meguerdichian et al. addressed the coverage problem in WSN [8]. They calculated the maximum breach path and the maximum service path of nodes to find a position that maximizes coverage. In [9], Zou and Chakrabarty introduced a greedy algorithm called virtual force algorithm (VFA). VFA assumes targets have virtual attractive forces and obstacles have virtual repulsive forces. Sensor nodes can find their position under the influence of the forces. Zou and Chakrabarty [10] also proposed setting a virtual backbone from active nodes to improve coverage and connectivity in ad hoc networks. Takahara et al. [11] evaluated the coverage of sensors deployed in the grid pattern for uniform and normal errors. Wang et al. [12] proposed a deployment strategy when sensors are deployed in Gaussian distribution without concerns on the connectivity. Recently, interesting researches have been carried out to enhance coverage in mixed WSNs, which has the heterogeneous setting of static and mobile nodes. Ghosh and Das presented a good survey on the coverage and connectivity issues in [13]. Static sensor nodes are arranged to maximize the coverage (blanket/barrier coverage of [13]) and mobile sensor nodes move carefully to fill the coverage holes (sweep coverage). Lambrou and Panayiotou proposed collaborative scheme to improve coverage in mixed sensor networks [14, 15]. In particular, considering the tradeoff between coverage and energy consumption (communication), they pursue an autonomous sensor system to improve coverage effectively by mobile sensor nodes. Emphasizing the role of mobile sensor nodes for coverage, Das and Roy presented an algorithm to maximize coverage with continuous movement of sensor nodes in [16]. The proposed algorithm lets the mobile sensor nodes cover the sensing field fully within a fixed time. Mahboubi et al. employ Voronoi polygons in [17] to find the coverage holes. Each sensor node has its Voronoi polygon that is derived by relative position to adjacent nodes. Thus the difference between the sensing area and the Voronoi polygon can show the effectiveness of coverage. The authors proposed node-based and vertex-based strategies to relocate sensor nodes. He et al. presented curve-based deployment for barrier coverage in [18]. They modeled sensor nodes along curved lines to enhance the suboptimal coverage of line-based coverage. To sum up, the previous researches focused on placing individual sensor nodes effectively and achieved their goal. However, in large-scale WSNs, where sensors are deployed in groups, we have to take into account group placement. In that sense, GenDep focuses on placing sensor groups rather than individual sensor nodes.
Key Management in Wireless Sensor Networks. In [1], Eschenauer and Gligor proposed a random key predistribution (RKP) scheme for WSNs. A randomly selected sub-key pool is preinstalled to each node before deployment. Chan et al. enhanced RKP (q-composite RKP, qRKP). qRKP achieves better resilience by restricting the minimum number of shared keys to connect. They also proposed the random-pairwise key scheme (RP) in [19], where RP selects a random pair and gives a pairwise key. In [3], Du et al. proposed a structured key-pool RKP scheme (skRKP) by adding randomness to the Blom scheme [20]. If two sensors share a key space, they can generate a key through shared key matrix. The location-aware schemes enhance key managements in WSN. They partition a whole sensing field into fixed square areas, called “grid.” We classify it as grid deployment. Du et al. proposed the location-aware RKP, where sensors share a key pool with other sensors in the same and adjacent grids only. Liu and Ning proposed a similar approach using bivariate polynomials [6]. In the grid-group key predistribution scheme (GGD) [5], Huang et al. employ skRKP to connect nodes in the same grid but RP to connect nodes in adjacent grids. Fanian et al. applied a mixed key from polynomial-based and random key predistribution schemes to WSNs in [21]. Grid-based predeployment knowledge on location is used to preinstall the hybrid keys to sensor nodes. Our previous work improves the connectivity in key management with perfect resilience via the key offering method [22].
2.2. Problems
Previous location-aware approaches [2, 3, 5, 6] assume the uniform deployment model, where a sensing field is a flat area with a uniform geographical feature. In real world, however, a target sensing field is nonuniform. We hardly meet the ideal sensing field that fits to the uniform deployment model. Furthermore, the real-world field has irregular geographical features. The WSN applications also have different sensing interests. Of course we can apply the uniform deployment model to the real-world field by force but it must be extremely inefficient.
Figure 1 shows an example of the real-world sensing field. Suppose that we would like to install WSN for a plain field only (not on the mountain and lake). We cannot make an optimal design to partition the sensing field with grids. To provide a practical WSN for real-world sensing fields, we should be able to divide the sensing field into any polygons like the dotted lines.
An example of the sensing field in the real world.
3. GenDep Overview
In this section, we overview the proposed method, GenDep, which is a novel location-aware key management scheme in the general deployment model. The detailed explanations on GenDep will be given in later sections, Sections 4 and 5.
3.1. General Deployment Model
Large-scale WSNs benefit from group-based deployment, that is, placing sensors by the unit of a group [23], for their scalability. Since sensor groups should be placed in a fixed pattern, however, the uniform deployment model is not appropriate for large-scale WSNs in the real world. To cope with this impracticality, we present the general deployment model. Any form of deployment area can be used for group-based deployment by dividing it into nonuniform subareas, which the existing uniform deployment model cannot support. The general deployment model relaxes the constraints and resolves this problem. Unfortunately, the previous location-aware key management schemes have been considered in the uniform model only, and so they are not quite workable in the general model. It is desirable to develop a new location-aware key management method in the general deployment model.
3.2. GenDep Framework
The new method proposed in this paper is called GenDep. In the general deployment model, GenDep divides and assigns subareas in irregular form to sensor groups and performs location-aware key management effectively.
Figure 2 illustrates the basic procedure of GenDep. Given the information of a sensing field and application requirements in the general deployment model, we firstly define the sensing requirements, which imply the required density of sensors at a particular point. We then apply GenDep in two phases as follows.
Phase 1: in this phase, we make a group placement plan by finding optimal positions of “sensor groups.” We first set reference points according to the sensing requirements and then set deployment points of sensor groups based on the reference points. Finally, we adjust the planned location and distribution of sensor groups so as to enhance the intergroup connectivity.
Phase 2: in this phase, we preinstall key sets and conduct location-based key establishment in the general deployment model. We first build group structures incorporating zones and extended groups. Second, we preinstall key sets to every sensor node so as to deploy sensor groups to the target sensing field according to the group placement plan. Finally, after the real deployment, all the sensor nodes conduct pairwise key establishment.
Procedure of GenDep.
4. Group Placement (Phase 1)
The group-based deployment phase consists of three steps: (1) setup reference points, (2) setup deployment points, and (3) adjust distributions. Notations section summarizes the notations to be used in this paper.
4.1. Step 1: Setup Reference Points
In this step, we set reference points according to the sensing requirements. First of all, we represent a target sensing field as a two-dimensional Cartesian plane and place reference points , as illustrated in Figure 3(a). The reference points are the points that hold sensing requirements at their position and are placed by following the uniform distribution. Note that they are not actual deployment points but only used for deriving local sensing requirements based on the prior knowledge about the terrain and WSN application.
Three steps of the group placement scheme. (All sensor groups are modeled as the Gaussian distribution with .)
From [9, 10, 12, 24], we generalize the sensing requirements for the general deployment model. It is required that an event taking place at a certain reference point should be detected by at least numbers of sensor nodes with the probability of . Hence, the sensing requirements are defined at a specific point and parametrized as follows:
: detection probability of a sensor desired at ,
: number of sensors required to detect an event at .
We then combine these parameters to the sensor density desired at , . First we compute the area of the sensing region where a sensor node can detect an event with higher probability than . We assume probabilistic sensing model, in which the detection probability decays exponentially as the power of distance. When we suppose d is the distance of a sensor from an event, would be the detection probability of the sensor, where α is a positive parameter that represents the physical characteristics of the sensor node and it is determined by the sensor type [9, 12]. Hence a sensor can detect an event taking place within with higher probability than and the area of the sensing region is when we assume sensors are omnidirectional. In other words, an event at can be detected by sensors located in the sensing region of with the probability of . also requires at least number of sensors to be located in the sensing region. Thus,
However, is a goal of density to achieve when deploying sensor nodes. When placing sensor nodes as a group, it is likely that there exists a gap between the goal and the actual density of sensor nodes at . We represent the gap, , as follows:
where is the total number of sensor groups and is the density of sensor nodes belonging to sensor group, at . Let us defer the explanation of to Section 6.2.4.
Figure 3(a) shows an initial state of when the target sensing field is covered by 25 reference points. With , is derived from the sensing requirements given to the reference point , that is, and . Since no sensor groups are deployed yet, is the same as for now.
4.2. Step 2: Setup Deployment Points
The goal of this step is to set deployment points of sensor groups on the positions that would minimize the sum of all , that is, . We first perform initial placement and then adjust the position of the deployment points.
Initial Placement. We conduct the initial deployment as shown in Algorithm 1. Algorithm 1 finds a reference point of highest and assigns an unassigned sensor group at the point iteratively. Since represents the gap between and the sensor density of assigned sensor groups, the value of keeps being updated during the process. As a result, we obtain the set B of assigned deployment points of sensor groups.
Algorithm 1: Initial placement: initial placement for unassigned sensor groups.
Input: A set of sensor groups and a set
of tuples of a reference point and its
for every reference point
Output: A set of deployment points assigned to sensor groups
fordo
Find a reference point of highest in W.
.
Add to B.
Update s in W.
end
returnB
We will improve the result of initial placement in the following steps. We first adjust positions in B to minimize the sum of . And then we determine an optimal position (in Step 3) with regard to the intergroup connectivity.
Position Adjustment. We present a new algorithm, pVFA, which adjusts the assigned deployment position of sensor groups to find more suitable position for achieving the goal. pVFA is an iterative, subgradient method. In an iteration of pVFA, every sensor group calculates a gradient that would decrease the sum of all . The gradient is represented as an Euclidean vector (direction and magnitude) in the target sensing field. Sensor groups move along their gradients by a unit step at the end of an iteration.
More specifically, Algorithm 2 explains the detailed process. Let be attractive force on a group from a reference point . A reference point attracts sensor groups with the power of ; that is, . The gradient of , , is the sum of attractive power from all the reference points, . A sensor group, , updates its assigned deployment point as by applying its gradient, where is a unit step for distance. The iteration is repeated until the average of gradients goes below a threshold .
Algorithm 2: Position adjustment: adjustment of initial position of sensor groups.
Input: A set of deployment points assigned to sensor groups
Output: A set of deployment points after position adjustment
repeat
fordo
Calculate an attractive force, , from .
Derive the gradient of : .
Update its position as of B
Update s in W.
end
Copy B to .
until
return
Figure 3(b) shows the results of this step. The circles indicate the effective region of sensor groups (which we will describe in the next step). The initial deployment determines the gray circles while the black circles indicate the position of sensor groups after the position adjustment. We show the gradient as a vector in arrow. As a result, we could obtain the intermediate deployment points of sensor groups and we will finalize the optimal deployment points in the next step.
4.3. Step 3: Adjust Distributions
The result of the previous step could have satisfied the sensing requirements (initially given by the general deployment model) but may have isolated groups having no well-connected adjacent groups because of missing the intergroup connectivity. To avoid such a case, we adjust the assigned deployment point and distribution of sensor groups before accomplishing the group placement plan.
The requirement for achieving “well-connectedness” in the intergroup connectivity is to have an effective, reasonable number of interconnections for two adjacent sensor groups. Thus, we count interconnections between sensor nodes, both of which are effective members in their own sensor groups only. To do so, we first define an effective region of a sensor group as the area covered by an effective number (we set the effective number as 80 percent of the number of sensor nodes in a group) of sensor nodes in that group. And we then set the minimum number of interconnections for two sensor groups to become a connected component.
Effective Region and Interconnections. We model sensor nodes deployed in a sensor group by omnidirectional probabilistic distributions, for example, Gaussian distribution. Hence the effective region is a circular region whose radius we calculate from the inverse cumulative distribution (CDF) [25] of the probabilistic distribution. CDF of the distribution of a sensor group returns the portion of member nodes for a given region of the sensor group; thus the inverse CDF provides an area (or a radius) that holds the given portion of sensor nodes. For example, we calculate the radius of the effective region as , where is the inverse CDF. We then regard interconnections of sensor nodes located in intersection of the effective regions of two adjacent sensor groups as effective interconnections. Let and , respectively, denote the number of sensor nodes from and in the intersection region between and .
Minimum Number of Interconnections. To become a connected component, a sensor group must have such a minimum degree of graph as , where C is a tunable radio transmission range parameter ( will increase the global connectedness to be close to 1) [26] and is the number of sensor nodes in a sensor group. Similarly, two sensor groups must have a minimum degree of graph, . Therefore, we define a set of well-connected neighbor groups, , for group :
where is the probability that two nodes of different groups can be connected. It indicates that two nodes are within each other's communication range and also share keys because only sensor nodes sharing the same key can communicate with each other [5]. Finally, to avoid the case that isolated groups exist, the following condition should be satisfied:
pVFA with an Extending Option. We improve the intergroup connectivity of the isolated sensor groups by extending their effective regions. For this purpose, we employ pVFA with an extending option. Algorithm 3 shows the process of this step. First we compute the effective region, denoted by , of a group and calculate intergroup connections between every pair of neighboring sensor groups, which have overlapped effective region in common. We then identify the isolated groups by using the condition of (4). When extending the effective region, we control the parameter of probability distribution of the sensor group. Here we suppose that we model the probability distribution as the two-dimensional Gaussian distribution. Thus we increase the standard deviation (std), , of by multiplying , which is a unit step for std. During extending the effective region, we can improve the connectivity but we could also experience the lower density of sensor nodes in the sensor group at the same time. It may bring back . Thus pVFA also adjusts the position by applying the algorithm PositionAdjustment of Algorithm 2. This process is repeated until there is no isolated group and the average magnitude of the gradient is below . The result is a deployment plan for a given sensing field. The deployment plan indicates the position of sensor groups (i.e., deployment points) and its distribution parameter (i.e., std).
Algorithm 3: Final adjustment: adjustment of position and distribution for intergroup connectivity.
Input: A set of deployment points after position adjustment
Output: Deployment plan: a set of
deployment points and distribution for each sensor group
repeat
foreachdo Compute the effective region of ,
for, do
Calculate inter-group connections between and
end
Identify isolated groups as I
fordo
end
Apply PositionAdjustment
untiland
returnK
In Figure 3(c), the gray circle and the black circle indicate the effective region, respectively, before and after the adjustment. We could observe that isolated groups have extended their effective regions while several groups have moved to minimize in Figure 3(c). Compared with the result of Step 2, the fraction of connected groups has been significantly improved from 0.455 to 1.0 at the cost of , of which the average increased from 0.0043 to 0.0132.
5. Key Management (Phase 2)
In this section, we describe the key management phase of GenDep. On the basis of the result of the group placement phase, we preinstall key sets to sensors for establishing pairwise keys in the key management phase. To do so, we describe building group structures in Step 1, preinstalling key sets to sensors in Step 2, and establishing pairwise keys in Step 3 (after deployment).
5.1. Step 1: Build Group Structures
In order to provide the location awareness to the key management schemes, we need to define a zone for a group. The key management schemes assume zones are nonoverlapped; thus we divide the sensing field into zones by using the Voronoi decomposition method [27], where a Voronoi cell for a seed point is a region consisting of points that are closer to the seed point than other seed points.
By employing the deployment points of groups as the seed points, we define a zone for the group is the Voronoi cell based on its deployment point, . Let denote a set of groups sharing Voronoi edges with the group . Then we could define a set of neighbor groups, , as follows:
Figure 4(a) is an example of the zones based on the deployment points of Figure 3. The sensing field was partitioned into 11 zones. Every zone has different shapes and different neighbors. In order to explain the subsequent process more clearly, we use the field of Figure 4(b) that consists of various polygons, that is, irregular zones.
Voronoi decomposition and deployment plan.
After partitioning zones, every pair of two neighboring zone groups is merged to be an extended group, EG. A group belongs to as many EGs as the number of its neighbor groups.
Algorithm 4 explains the process for setting the neighbor sensor group and assigning extended groups. All the assigned EGs are in E. In addition, Figure 5 illustrates an example of multiple EGs (i.e., 5 EGs) overlapped on the group . Note that EGs could intrinsically support location awareness because of binding a pair of adjacent zones.
Algorithm 4: Build structure: define the neighbor groups and build a set of extended groups of every pair of neighboring sensor groups.
Input: A set Q of sensor groups, a set of well-connected sensor groups of
, and a set of the sensor groups sharing a Voronoi edge with
Output: A set of extended groups.
foreachdo
fordo
ifEGthen
end
end
end
returnE
Group structures for group . (Note that denotes the extended group of and .)
5.2. Step 2: Preinstall Key Sets
In this step, we assign key predistribution schemes to EGs and preinstall key sets to be used for key establishment. Before preinstall keys to sensor nodes, we select a key predistribution scheme suitable for each EG. Because each EG is an independent space, we could assign not only homogeneous but also heterogeneous key predistribution schemes to EGs. It is clear that heterogeneous schemes could only affect their own EGs. For example, a compromised sensor node may only contaminate sensors in its local EG. When selecting key predistribution schemes, we could flexibly approach them by considering their distinct features in terms of node-capture resilience, storage overhead, and computational complexity. We could prioritize one of those features in each EG. For instance, we could select RP for prioritizing the perfect resilience against node capture attacks or RKP for higher connectivity. No key predistribution scheme is a panacea.
According to the selected key predistribution schemes, we preinstall key sets to sensor nodes. Algorithm 5 shows the procedure. First we assign unique identifiers, and , to each sensor node and each EG, respectively. For each EG, we generate a key pool, , according to the selected key predistribution scheme for the EG. From the key pool, we select a key set and install it on a sensor node of the EG. The method for generating a key pool GenerateKeyPool and selecting a key set from the key pool SelectKeysFrom is dependent on the selected key predistribution scheme.
Algorithm 5: Preinstall: preinstall a key set for each sensor node.
Input: A set E of extended groups
foreach a sensor node, udo
SetNewIdentifier
end
foreachEGdo
SetNewIdentifier
←GenerateKeyPool
for a sensor node, do
s←SelectKeysFrom
InstallKeySet
end
end
5.3. Step 3: Establish Pairwise Keys
Finally, we could deploy sensor nodes into the sensing field. After deployment, the sensor nodes will then establish pairwise keys by themselves. The procedure to establish pairwise keys is as follows.
Key Discovery. Each sensor node broadcasts its ID, , and key list whereas the key list is composed of the identifiers of its keys, . Sensor nodes could exchange them with their neighbors and compare the lists for key establishment.
Pairwise Key Establishment. If a sensor node finds a neighbor node sharing the same key, then it sends a connection request to the neighbor. By using the key agreement method of [3], the two adjacent nodes can generate a pairwise key in a secure way.
Path Key Establishment. If there remain neighbors not yet connected, the sensor node broadcasts the IDs of the disconnected neighbors to the connected neighbors, so that the connected neighbors could help them to establish pairwise keys. This step is repeated until the sensor node connects to all the neighbors and cannot find newly connectable nodes.
6. Performance Evaluation
In this section, we analyze the performance of GenDep. We compare our method to the previous location-aware key management schemes based on the fixed deployment model, such as GGD [5] and skRKP [2].
6.1. System Model for Evaluation
We assume the following.
The number of sensor nodes () is 100 in a single group.
To compare the result with the previous schemes fair, we set each zone to be formed as a square: .
GenDep uses three configurations for key predistribution schemes: G-skRKP, G-COMB, and G-RP. For G-skRKP and G-RP, we select skRKP and RP as key predistribution schemes, respectively. In G-COMB, a combination of RKP and RP is applied; among 4 EGs of a group, 2 EGs use RKP and the other 2 EGs employ RP. The key pool size of the RKP scheme is 4880 to keep the faction of communication compromised under 0.4 until 50% nodes are compromised [1].
In order to keep the same level of key storage and to preserve the λ-secure property (for resilience against compromised sensor nodes, the key distribution schemes using the secret key matrix of the Blom scheme, such as GGD and skRKP [2, 5], have an upper bound on the ratio of the number of sensor nodes and the size of secret matrix; this is called λ-secure property; please refer to [3] for the λ-secure property) [3], for all the schemes but , , and for GGD, skRKP-D, and G-skRKP, respectively. The analysis of key storage is described in Section 6.5. Additionally, we set the parameters for GGD as and based on [5].
6.2. Key Graph Connectivity
Let be the probability that two sensor nodes in and share at least one common key. It is assumed that a sensor node of randomly picks different keys for from a key pool of size M. Then, the is
Likewise, let be the probability that two sensor nodes in the same share at least one common key. The sensor nodes in the same group have all their EGs in common. They can be connected unless they do not share any key in their EGs, which are . For each that they share, the key graph connecting probability is . Thus,
If a single key predistribution scheme is applied to all EGs of , is calculated as
since the number of shared EGs of the two sensor nodes in the same group is . Appendix A shows the probabilities, and , on the instantiations of key predistribution schemes in GenDep.
A sensor node can be connected to neighbors directly (1 hop) or through relaying of other neighbor nodes (more than 1 hop). For simplicity and clarity, we consider 2 hops at maximum. Let be the number of sensors of within the communication range R from a position . We assume a sensor node u in at . For the sensor node u, we take as the number of reachable neighbor nodes in (the number of sensor nodes within the communication range except itself) and as the number of reachable neighbor nodes in , where and .
6.2.1. Key Graph Connectivity within the Same Group
Suppose that a sensor node u connects to another sensor node v in the same group , . We represent the probability that two nodes are connected, , as
where the probability of the 1-hop connection, , is equal to . When we calculate the probability of the 2-hop connection, , we take account of two cases of relaying: by a node in the same group or another node in a neighbor group. Let us denote by and the probabilities that the sensor nodes, u and v, are connected via a node in and , respectively. The two nodes can be connected in any of these cases. Hence,
We calculate and by developing the binomial probability distribution (the development of the binomial probability distribution for the key graph connecting probability is inspired by [28]). We compute as follows:
where the part is the binomial probability distribution that represents that u is connected to sensor nodes out of neighbors (the number of reachable neighbor nodes except v) and u is connected to one of sensor nodes by . The term, , represents the probability that at least one of the sensor nodes is connected to v. Note that is the probability that any two sensor nodes are within the communication range of each other. If the communication range is circle-shaped and of equal radius, then is 0.5865 regardless of R according to [28]. Likewise, we calculate as
Equation (12) represents that u is connected to v via one of sensor nodes in . Since the sensor nodes belong to , the connecting probability between them and u or v is . Finally, we get (13) by joining (9), (10), (11), and (12).
6.2.2. Key Graph Connectivity between Neighbor Groups
is the probability that a sensor node u in connects to another node v in , that is, a neighbor group of () with or without help from all neighbor nodes. Obviously, , but, in , three cases of 2-hop connections are possible: , , and .
First, , the probability of 2-hop connection by relaying of a sensor node in is
In (14), note that and , respectively, represent the probability that node u connects to neighbor nodes and the probability that neighbor nodes connect to node v. Second, is the probability of 2-hop connection by relaying of a sensor node in and is given as
Third, is the probability of 2-hop connection by the relay of a sensor node in neighbor groups except , which are . Hence, is
Joining (14), (15), (16), and (17), we represent as (19).
6.2.3. Numerical Results in Key Graph Connectivity
Figure 6 depicts and when and are the same. Table 1 shows the parameters, and , computed by the equations as referred to Appendix A. As illustrated in Figure 6, the connectivity of GGD is best at the same group but worst between the neighbor groups at the same time. The reason is that GGD employs different methods for the same and the neighbor groups. The connectivities at the same group are similar in G-skRKP, G-RP, and skRKP-D. But the connectivities between the neighbor groups are better than skRKP-D in G-skRKP and G-RP as illustrated in Figure 6(b). When we assume the number of neighbor nodes is 21, in Figure 6(a), the of G-RP is and lower than GGD and skRKP-D, respectively, but, in Figure 6(b), of G-RP is and higher than the two schemes. In other words, GenDep has slightly lower connectivity within the same group but far higher connectivity between the neighbor groups. In both cases of Figure 6, G-COMB achieves high connectivity. Furthermore, it is noteworthy that RP is a good choice as a key predistribution scheme because G-RP shows better performance than skRKP-D and G-skRKP. In addition, RP does not require complex computation in the key establishment and has better network resilience [22].
Local connectivity ( and ).
GGD
0.8857
0.01
skRKP-D
0.5338
0.0816
G-skRKP
0.4602
0.1429
G-RP
0.4779
0.15
G-COMB
0.62
0.33 (RKP), 0.08 (RP)
Key graph connectivity.
6.2.4. Discussion on Key Graph Connectivity according to Deployment Distribution
We model the deployment method for a sensor group as probabilistic distribution of sensor nodes. In this section, we take into consideration two kinds of probabilistic distributions: Gaussian and uniform distributions.
Gaussian Distribution. First, in the Gaussian distribution, sensor nodes are deployed in the 2-dimension (2D) Gaussian distribution from their deployment point. We denote by the cumulative density function (CDF) of the 2D Gaussian distribution within a circle whose center is located at the distance of z from the deployment point and its radius is r. More formally,
where σ is the standard deviation of the Gaussian distribution. Please refer to [29] about derivation of . Let us denote the position of the deployment point, , by using and . The number of nodes in at the point of within r is
Figure 7 depicts the probability of the key graph connectivity to nodes in any neighbor group, , from (0,0) to (100,100) where the deployment point is located at (50,50). Since the distribution of neighbor nodes determines the probability of the key graph connectivity, Figure 7 shows high connectivity along each direction to the deployment points of neighbor groups. Additionally, note that the shape of the zone in Figure 7(a) is a regular polygon, that is, a square, but that of Figure 7(b) is the irregular pentagon, which is the same shape to the zone G in Figure 4(b).
Uniform Distribution. Second, in the uniform distribution, the coverage area and density determine the number of neighbor nodes regardless of the deployment point. Let be the sensor node density of , which can be calculated by , where is the zone of . Hence, the number of sensor nodes within r in is
where is the area of the intersected region between and the communication range of the node located at . The intersected area can be calculated geometrically using the sensor coverage analysis such as [5].
6.3. Simulation
We perform simulation to validate our analysis result in more realistic situations. Our simulation follows the system setup of Sections 6.1 and 6.2.4 (, , ). In the simulation, we place nine sensor groups as shown in Figure 8. Each group is located from a given group distance. We ran simulation with varying distances between groups to check the number of connections to confirm the trends of key graph connectivity of our analysis in Section 6.2.3. In the simulation, we implemented GGD and G-skRKP, since the relative performance of G-skRKP to GGD is a good indicator for the trend of the analysis result.
Simulation setting. We place nine sensor groups and deploy sensor nodes in Gaussian distribution. (Please note that we use in this figure to show sensor groups more distinguishably but in the simulation to follow the settings of Sections 6.1 and 6.2.4.)
Figure 9 shows the result of the simulation. We change the distance between groups from 20 m to 50 m and count the total number of connections established within the two-hop key graph after deployment. Since sensor nodes are deployed randomly in Gaussian distribution, we ran simulation 30 times to get the average of the results. As expected, we can observe that the connectivity within the same group does not change by varying the distance in Figure 9(a). GGD has 18.8% more connections among sensor node within the same group than G-skRKP. As shown in Figure 9(b), however, G-skRKP always outperforms GGD by 338% in the number of connections among neighbor groups. Therefore, both results show the same trend as the result of the numerical analysis in Section 6.2.3 and G-skRKP can provide higher connectivity between groups.
Key graph connectivity in the simulation.
6.4. Security Analysis
The group structures in GenDep prevent the general deployment model from incurring additional security concerns. The security conditions for the key predistribution schemes, such as the λ-secure property, can also be applied easily.
Figure 10 depicts the network resilience against node capture attacks for the same size of key sets, , and the local connectivity, . We refer to [3, 19] and Appendix B for the equations of the network resilience. In Figure 10, skRKP shows the strong resistance to the node capture attacks when is only restricted under 100, that is, satisfying the λ-secure property. However, RP can achieve the perfect resilience against the node capture attacks. Note that the network resilience of qRKP is worse than RKP due to the small size of and key pool. Therefore, we exclude the qRKP scheme in the performance comparison. In case that nodes store a relatively smaller number of keys for an EG, the RKP scheme is better to be selected for security and connectivity than the qRKP scheme.
Network resilience of the key predistribution schemes (, ).
6.5. Storage Overhead
The size of the key storage required to preinstall key sets in a sensor node is dependent on the key predistribution schemes. Let be the size of the key storage for the EGof a sensor node. The total storage for a node can be computed as . The security conditions of the key predistribution scheme may restrict the lower bound of . In that sense, for the Blom-based schemes in GenDep, the security parameter λ is calculated as . That is, the selected key space in GenDep, , should be half of τ that other Blom-based schemes use in order to keep the same value of . Thus, for an EG with skRKP is
In case that skRKP is assigned to all EGs, for example, G-skRKP, . Table 2 shows the key storage overhead on various configurations for this case. Based on the configurations of [3, 5] (, , , 64-bit key), the required key storage for GenDep is under a few kilobytes for both cases of (rectangular zone) and (hexagonal zone). Even in the cases of hexagonal zone, 128-bit key, and , the key storage is under 12 kbytes. Since MICAz sensor nodes have a 128 kbyte program memory and a 512 kbyte secondary memory [30], the required key storage is small enough to be installed to the memory of sensor nodes.
Required key storage.
L
ω
Key size (bits)
Storage (bytes)
L
ω
Key size
Storage
4
50
7
1
64
512
6
50
7
1
64
768
4
100
7
1
64
960
6
100
7
1
64
1440
4
200
7
1
64
1888
6
200
7
1
64
2832
4
50
7
1
128
1024
6
50
7
1
128
1536
4
100
7
1
128
1920
6
100
7
1
128
2880
4
200
7
1
128
3776
6
200
7
1
128
5664
4
50
7
2
64
1920
6
50
7
2
64
2880
4
100
7
2
64
3776
6
100
7
2
64
5664
4
200
7
2
64
7424
6
200
7
2
64
11136
Let , , , , and be the required storages to store keys for GGD, skRKP-D, G-skRKP, G-COMB, and G-RP, respectively. In skRKP-D, each key pool is shared among neighbor zones in proportion to a or b. In other words, due to the λ-secure property, we cannot deploy more than nodes. Hence, for GGD and for skRKP-D using the condition in [2]. From these conditions, the required key storage for the schemes is
From (24), the parameters of the system model in Section 6.1 are determined to achieve the same level of key storage, and . Since G-RP and G-COMB do not require the security conditions on m, we set the .
7. Conclusion
In this paper, we proposed GenDep, the novel framework for location-aware key management in WSNs regarding the general deployment model. Due to the notion of generalized location awareness, GenDep can apparently provide a practical advantage. The WSN can be deployed without losing its security in the real world where nonuniform geographical features exist. In GenDep, the group placement phase is operated to find optimal deployment positions of sensor groups. In the following key management phase, a whole deployment area is partitioned into a number of different smaller zones based on the deployment points of sensor groups. Subsequently, we build a new group structure to cover all sensor nodes deployed in neighboring zones. Using the group structures, we can render the benefit of location awareness to the existing key predistribution schemes. We proved the superior performance of key predistribution schemes when applied to GenDep, compared to their raw deployment. We also showed that it is possible to achieve the same level of security even in the irregular deployment area due to our generalized location awareness.
The generalized location awareness approach is promising for various practical applications, not limited to WSNs. For WSNs, GenDep enables their deployment to unforeseen circumstances. Thus GenDep is also applicable to three-dimensional (3D) sensor deployment, such as sensors in intelligent buildings. Secure key management for a group of any scattered devices can adopt GenDep as well, for example, RF readers in department stores and remote consoles in cafes and restaurants. We believe it would be promising to scrutinize more applications in the future study.
Footnotes
Appendices
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT & Future Planning (nos. 2012R1A1A1044693 and 2012R1A1B3000965).
References
1.
EschenauerL.GligorV. D.A key-management scheme for distributed sensor networksProceedings of the 9th ACM Conference on Computer and Communications Security (CCS '02)November 2002Washington, DC, USAACM Press41472-s2.0-0038341106
2.
DuW.DengJ.HanY. S.VarshneyP. K.A key predistribution scheme for sensor networks using deployment knowledgeIEEE Transactions on Dependable and Secure Computing20063162772-s2.0-3284445941410.1109/TDSC.2006.2
3.
DuW.DengJ.HanY. S.VarshneyP. K.KatzJ.KhaliliA.A pairwise key predistribution scheme for wireless sensor networksACM Transactions on Information and System Security2005822282582-s2.0-2324446718210.1145/1065545.1065548
4.
di PietroR.ManciniL. V.MeiA.Random key-assignment for secure wireless sensor networksProceedings of the 1st ACM Workshop on Security of Ad Hoc and Sensor Networks (SASN '03)October 2003Fairfax, Va, USAACM Press62712-s2.0-4544301464
5.
HuangD.MehtaM.MedhiD.HarnL.Location-aware key management scheme for wireless sensor networksProceedings of the 2nd ACM Workshop on Security of Ad Hoc and Sensor Networks (SASN '04)October 2004Washington, DC, USAACM Press29422-s2.0-14844314204
6.
LiuD.NingP.Location-based pairwise key establishments for static sensor networksProceedings of the 1st ACM Workshop on Security of Ad Hoc and Sensor Networks (SASN '03)October 2003Fairfax, Va, USAACM Press72822-s2.0-4544293215
7.
ZhangY.LiuW.LouW.FangY.Location-based compromise-tolerant security mechanisms for wireless sensor networksIEEE Journal on Selected Areas in Communications20062422472602-s2.0-3314447683710.1109/JSAC.2005.861382
8.
MeguerdichianS.KoushanfarF.PotkonjakM.SrivastavaM. B.Coverage problems in wireless ad-hoc sensor networks3Proceedings of the 20th Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM '01)April 2001Anchorage, Alaska, USA138013872-s2.0-0034997317
9.
ZouY.ChakrabartyK.Sensor deployment and target localization in distributed sensor networksACM Transactions on Embedded Computing Systems200431619110.1145/972627.972631
10.
ZouY.ChakrabartyK.A distributed coverage- and connectivity-centric technique for selecting active nodes in wireless sensor networksIEEE Transactions on Computers20055489789912-s2.0-2414450110110.1109/TC.2005.123
11.
TakaharaG.XuK.HassaneinH.How resilient is grid-based WSN coverage to deployment errors?Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC '07)March 2007Kowloon, China287228772-s2.0-3634899667410.1109/WCNC.2007.532
12.
WangY.-C.HuC.-C.TsengY.-C.Efficient placement and dispatch of sensors in a wireless sensor networkIEEE Transactions on Mobile Computing2008722622742-s2.0-3754904473610.1109/TMC.2007.70708
13.
GhoshA.DasS. K.Coverage and connectivity issues in wireless sensor networks: a surveyPervasive and Mobile Computing2008433033342-s2.0-4354909852910.1016/j.pmcj.2008.02.001
14.
LambrouT.PanayiotouC.Collaborative area monitoring using wireless sensor networks with stationary and mobile nodes [Ph.D. dissertation]University of Cyprus
15.
LambrouT.PanayiotouC.Collaborative path planning for event search and exploration in mixed sensor networksThe International Journal of Robotics Research201332121424143710.1177/0278364913498909
16.
DasT.RoyS.Coordination based motion control in mobile wireless sensor networkProceedings of the International Conference on Electronic Systems, Signal Processing and Computing Technologies (ICESC '14)January 2014Nagpur, India23123610.1109/ICESC.2014.45
17.
MahboubiH.MoezziK.AghdamA. G.Sayrafian-PourK.MarbukhV.Distributed deployment algorithms for improved coverage in a network of wireless mobile sensorsIEEE Transactions on Industrial Informatics201410116317410.1109/TII.2013.2280095
18.
HeS.GongX.ZhangJ.ChenJ.SunY.Barrier coverage in wireless sensor networks: from lined-based to curve-based deploymentProceedings of the IEEE Conference on Computer Communications (INFOCOM '13)April 2013Turin, Italy47047410.1109/INFCOM.2013.6566817
19.
ChanH.PerrigA.SongD.Random key predistribution schemes for sensor networksProceedings of the IEEE Symposium on Security And Privacy (SP '03)May 2003Berkeley, Calif, USA1972132-s2.0-0038487088
20.
BlomR.An optimal class of symmetric key generation systemsAdvances in Cryptology: Proceedings of EUROCRYPT 84. A Workshop on the Theory and Application of Cryptographic Techniques1985New York, NY, USASpringer335338
21.
FanianA.BerenjkoubM.SaidiH.GulliverT. A.A hybrid key establishment protocol for large scale wireless sensor networksProceedings of the IEEE Wireless Communications and Networking Conference (WCNC '10)April 2010Sydney, Australia162-s2.0-7795504119310.1109/WCNC.2010.5506121
22.
KwonT.LeeJ.SongJ.Location-based pairwise key predistribution for wireless sensor networksIEEE Transactions on Wireless Communications2009811543654422-s2.0-7074909637010.1109/TWC.2009.090183
23.
LeeJ.KwonT.SongJ.Group connectivity model for industrial wireless sensor networksIEEE Transactions on Industrial Electronics2010575183518442-s2.0-7795117758310.1109/TIE.2009.2033089
24.
ZouY.ChakrabartyK.Uncertainty-aware and coverage-oriented deployment for sensor networksJournal of Parallel and Distributed Computing20046477887982-s2.0-1084427566210.1016/j.jpdc.2004.03.019
25.
SeshadriV.The Inverse Gaussian Distribution: Statistical Theory and Applications1999Springer
26.
XueF.KumarP. R.The number of neighbors needed for connectivity of wireless networksWireless Networks20041021691812-s2.0-104228903110.1023/B:WINE.0000013081.09837.c0
27.
AurenhammerF.Voronoi diagrams—a survey of a fundamental geometric data structureACM Computing Surveys199123334540510.1145/116873.116880
28.
HuangD.MehtaM.van de LiefvoortA.MedhiD.Modeling pairwise key establishment for random key predistribution in large-scale sensor networksIEEE/ACM Transactions on Networking2007155120412152-s2.0-3454839159310.1109/TNET.2007.896259
29.
DuW.DengJ.HanY. S.ChenS.VarshneyP. K.A key management scheme for wireless sensor networks using deployment knowledge1Proceedings of the 23th AnnualJoint Conference of the IEEE Computer and Communications Societies (INFOCOM '04)March 20045865972-s2.0-8344262333
30.
MEMSIC wireless moudules (formerly, micaz was a product of crossbow technology, inc.)http://www.memsic.com/