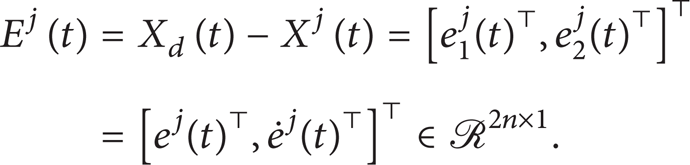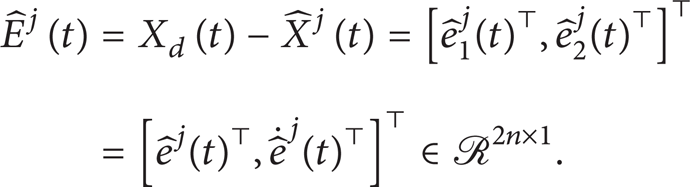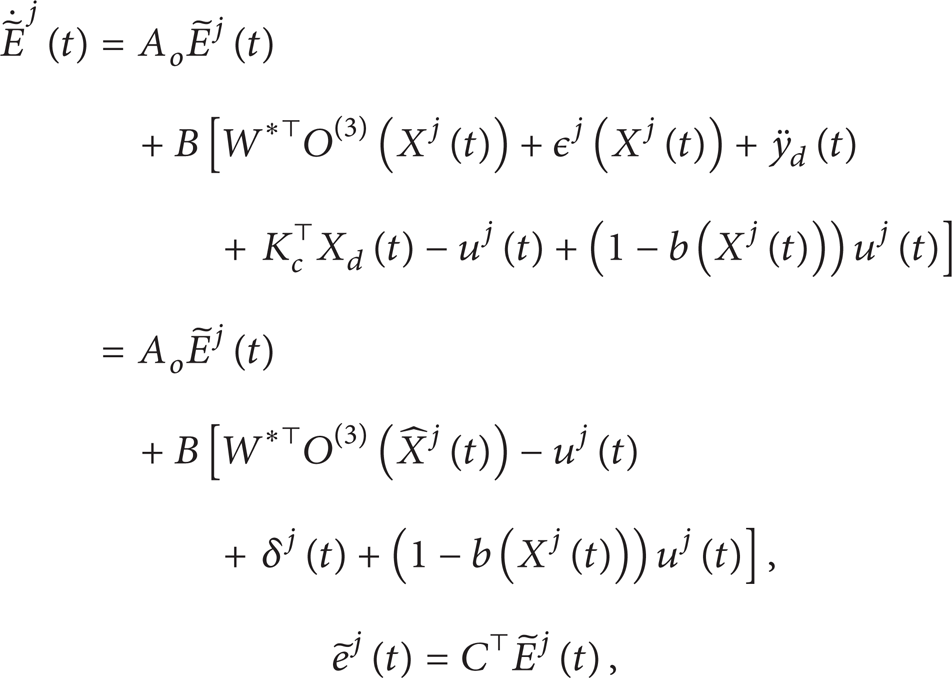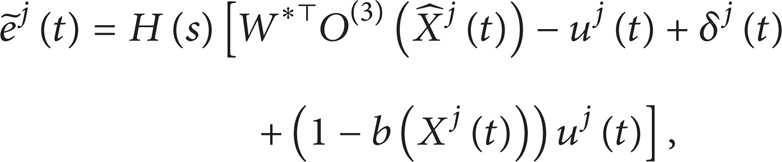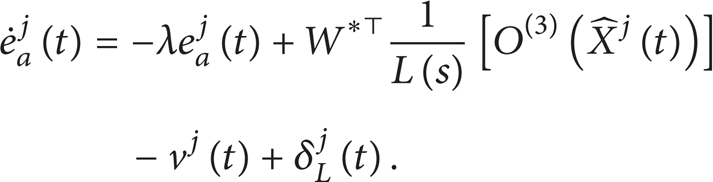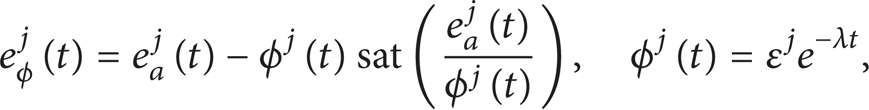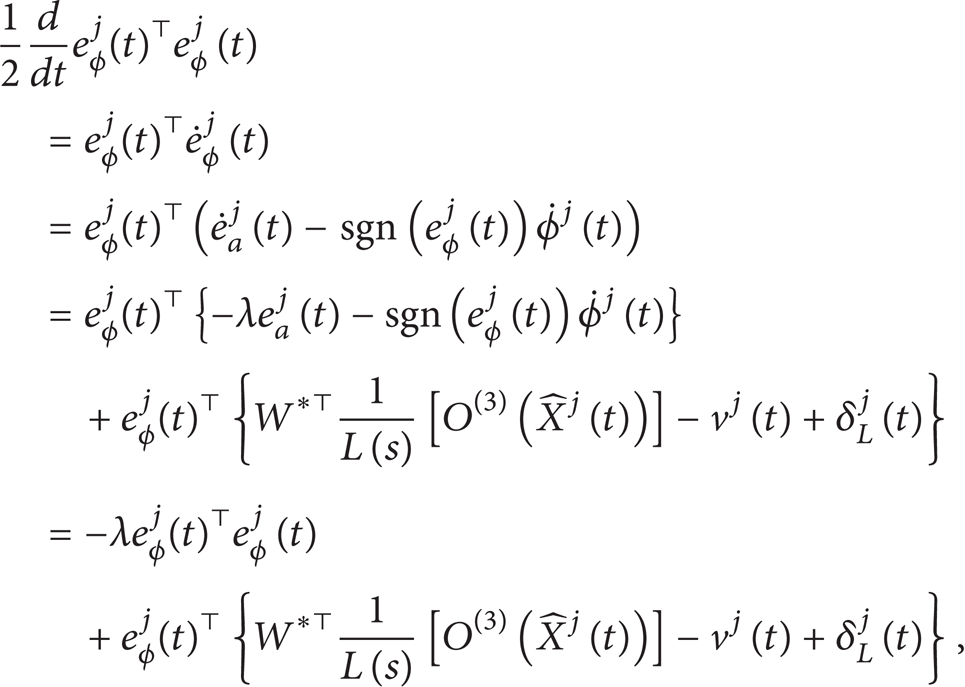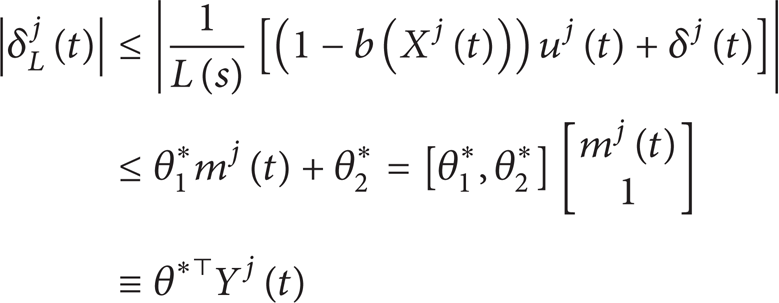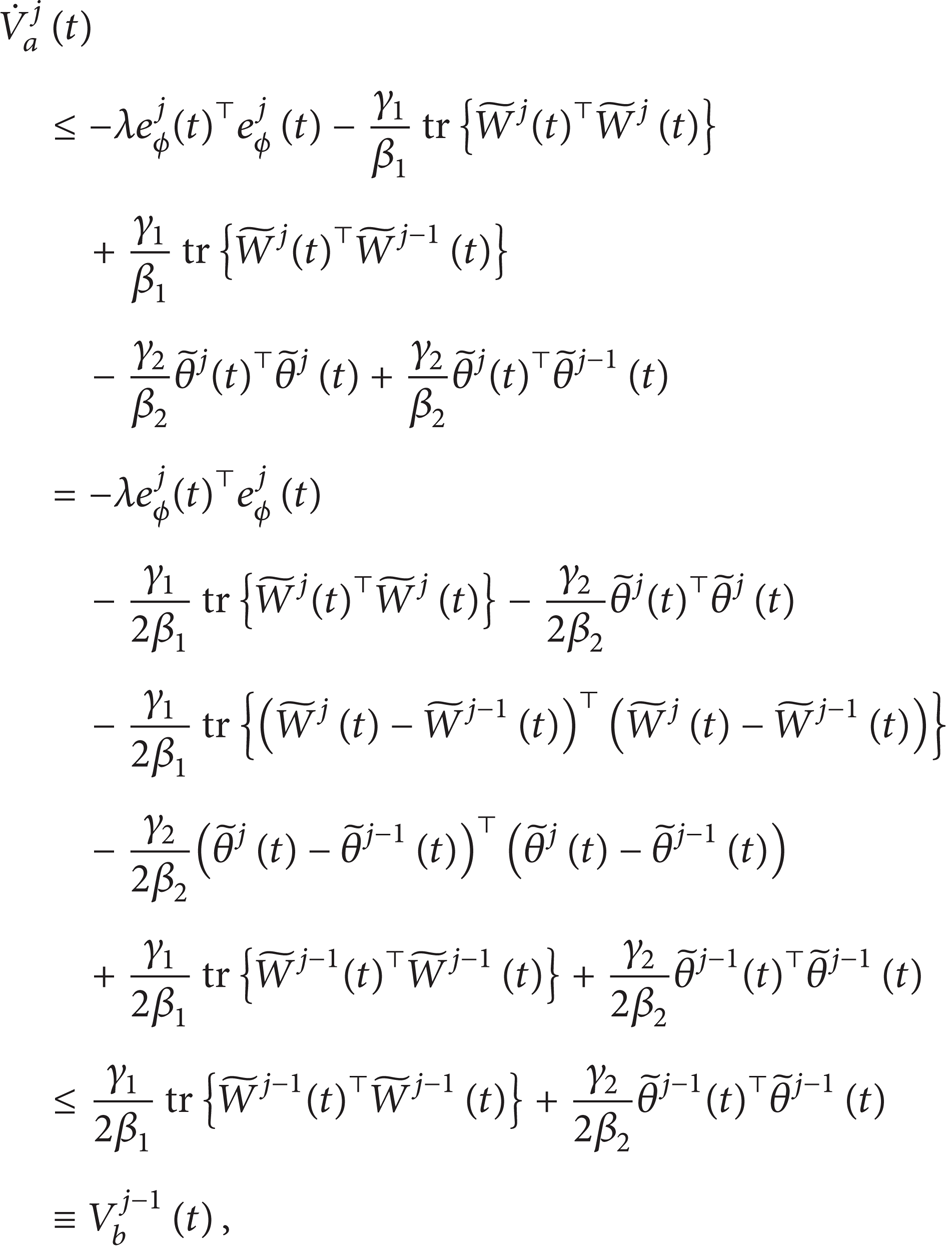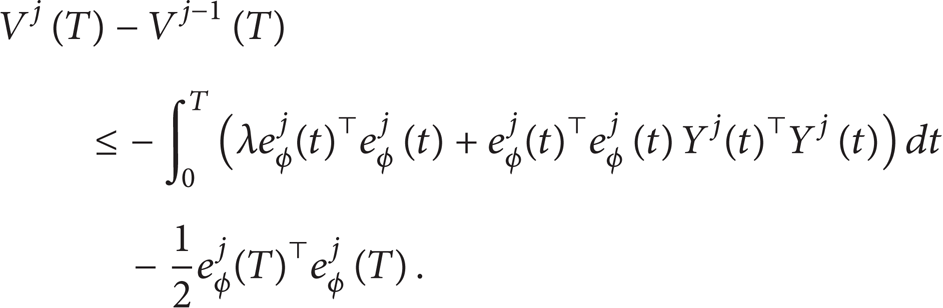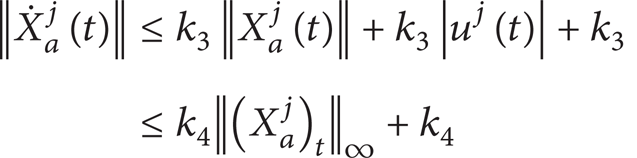An observer-based adaptive iterative learning control using a filtered fuzzy neural network is proposed for repetitive tracking control of robotic systems. A state tracking error observer is introduced to design the iterative learning controller using only the measurement of joint position. We first derive an observation error model based on the state tracking error observer. Then, by introducing some auxiliary signals, the iterative learning controller is proposed based on the use of an averaging filter. The main control force consists of a filtered fuzzy neural network used to approximate for unknown system nonlinearity, a robust learning term used to compensate for uncertainty, and a stabilization term used to guarantee the boundedness of internal signals. The adaptive laws combining time domain and iteration domain adaptation are presented to ensure the convergence of learning error. We show that all the adjustable parameters as well as internal signals remain bounded for all iterations. The norm of output tracking error will asymptotically converge to a tunable residual set as iteration goes to infinity.
1. Introduction
Due to the repeatability of operation for robotic systems, it is suitable to perform the control task by using the technique of iterative learning control (ILC) for a repetitive tracking control problem. ILC is basically a non-model-based learning approach which is very effective in dealing with repetitive control tasks [1–5]. Initially, PID-type ILC algorithms which required a certain a priori knowledge of robot dynamics were developed for robot manipulators based on the contraction mapping theory [6–9]. In D-type, PD-type, or PID-type ILC, the acceleration errors of joint variables are required to construct the learning controller. However, the acceleration measurement is unfortunately not realizable in practice and becomes the major disadvantage of D-type ILC. On the other hand, P-type ILC uses only the velocity errors of joint variables for the design of updated learning function. Although the requirement of acceleration measurement is removed, more strict conditions on the robot manipulators are needed for technical analysis. In general, it is hard to apply the traditional PID-type ILC for repetitive tracking control of robot manipulator using only joint position measurement.
Recently, adaptive iterative learning control (AILC) has been widely studied in the research field of the ILC. One of the most attractive advantages of AILC scheme is the capability to deal with the issues of large initial resetting error, large input disturbance, and iteration-varying desired trajectory. In the past decade, the AILC schemes have been utilized for repeated tracking control of robotic systems [10–14], or a class of nonlinear systems [15, 16]. In order to relax the restrict Lipschitz condition on the plant's nonlinearity, the Lyapunov-like approach instead of contraction mapping theory is applied in AILC to analyze the stability and convergence. If the system nonlinearties are unknown, the fuzzy systems or neural networks were often introduced to approximate the nonliearties and provide the basis functions for the design of AILC [17–19]. However, both PID-type ILCs and AILCs require at least the joint velocities to develop the AILC algorithms. If only the measurement of joint positions is available, an observer is one of the possible choice to design the AILC. In [20], an observer-based ILC for a time-varying nonlinear system was proposed to overcome the unmeasurable states. Although an observer-based ILC system can guarantee that the tracking error will converge to zero, the initial resetting errors at each iteration were not considered. In [21], an observer-based ILC scheme was proposed for a class of nonlinear systems with unknown parametric uncertainties. The Lyapunov-Krasovskii-like composite energy function was applied to analyze the closed-loop stability and learning performance. Nevertheless, the plant nonlinearities must be linearly parameterizable. In [22], a framework for ILC by using an observer to estimate the controlled variable was presented. However, it was necessary to assume that the ILC input converges to a bounded signal. In [23], the observer-based ILC with evolutionary programming algorithm was proposed for MIMO nonlinear systems. The evolutionary programming was applied to search for the optimal and feasible learning gain to speed up the convergence of the ILC and the tracking error will converge to zero via successive learning. But the AILC was developed for MIMO nonlinear plants with nonlinearities satisfying Lipschitz continuous condition. In [24], an observer-based AILC was developed for a class of nonlinear systems with unknown time-varying parameters and unknown time-varying delays. The linear matrix inequality (LMI) approach was used to design the nonlinear state observer. By constructing a Lyapunov-Krasovskii-like composite energy function, the boundedness of the internal signals and the convergence of tracking error can be proved. However, it was assumed that the plant nonlinearities satisfy Lipschitz continuous condition and the unknown system parameters must be linear with respect to some known nonlinear vector-valued functions. In [25], a velocity-observer-based ILC for trajectory tracking of rigid robot manipulators with external disturbances without using the velocity measurement was proposed. However, the inertia matrix of the robotic systems needed to satisfy Lipschitz continuous condition and the initial resetting errors at each iteration were assumed to be zero. Besides, the disturbances were assumed to be repetitive and the velocities were assumed to be bounded.
In order to relax the condition of measurement for joint velocity and without the requirement of Lipschitz condition on the robot unknown nonlinearity and the zero initial resetting errors at each iteration, a new observer-based adaptive iterative learning controller using a new filtered fuzzy neural network (filtered-FNN) is proposed for repetitive tracing control of robotic systems in this paper. A state tracking error observer is firstly presented to deal with the problem that only joint positions are available. Based on this observer, a state tracking error model including a filtered-FNN approximation term can be derived by using an interesting s-domain transfer function technique which is usually utilized in the area of traditional model reference adaptive control [26]. An averaging filter is then proposed to solve the implementation problem of the controller. Under the derived error model, a fuzzy neural learning component is designed to approximate the unknown nonlinearities by a filtered-FNN using state estimation vector as the network input, a robust learning component is constructed to compensate for the uncertainties from approximation error and state estimation error, and a stabilization component is used to guarantee the boundedness of internal signals. The main features of this iterative learning controller and its contributions relative to the related works are summarized as follows.
Compared with most of the works using adaptive iterative learning control for robotic systems or nonlinear systems, this paper can design a realizable adaptive iterative learning controller using only joint position measurement. In other words, it is not necessary to measure the states for the controller design.
A new design approach is introduced to derive the error model so that a filtered-FNN can be applied for compensation of the unknown system nonlinearities. The filtered-FNN can be treated as a dynamic version of traditional FNN which plays an important role in this proposed adaptive iterative learning controller.
Compared with the fuzzy system or neural-network-based adaptive iterative learning controller using state measurement [17–19], the stability analysis becomes more difficult since the boundedness of output tracking error cannot guarantee the boundedness of input signal. A new analysis to prove the regularity of internal signals is successfully derived in this paper so that we ensure the boundedness of all the adjustable parameters and internal signals during the learning process. Furthermore, we guarantee that the norm of output tracking error will asymptotically converge to a tunable residual set which depends on the design parameters if iteration number is large enough.
This paper is organized as follows. In Section 2, a problem formulation is given. The error model between system output and desired output is derived in Section 3. Based on the derived error model, the filtered-FNN-based AILC using observer design is presented in Section 4. Analysis of closed-loop Section 6. The detailed description of the proposed filtered FNN is given in the Appendix.
In the subsequent discussions, the following notations will be used.
denotes the absolute value of a scalar or the Euclidean or any other consistent norm of a vector or matrix.
Lpe[0,T] denotes the set of Lebesgue measurable (or piecewise continuous) real-valued (vector) functions with
denotes the truncated L∞ norm of the argument function or vector [26].
denotes the H∞ norm of the transfer function G(s).
G(s)[u(t)] denotes the filtered version of u(t) with any proper or strictly proper transfer function G(s).
2. Problem Formulation
In this paper, we consider an uncertain robotic system with n rigid bodies which can perform a given task repeatedly over a finite time interval [0,T] as follows:
where j∈Z/+ denotes the index of iteration number and t∈[0,T] denotes the time index. The signals qj(t), , are, respectively, the generalized joint position, joint velocity, and joint acceleration vectors. D(qj(t))∈ℛn × n is the inertia matrix, is the centripetal plus Coriolis force matrix, are the gravitational plus frictional forces, and uj ∈ ℛn × 1 is the joint torque vector. It is noted the inertia matrix D(qj(t)) is assumed to be positive definite and bounded for all t∈[0,T] and iteration j≥1 as
where m1,m2>0 and In × n is an n × n identity matrix. Since the inverse of inertia matrix exists for all joint variables, the dynamic formulation of the robotic system can be written as follows:
Let and b(qj(t)) = D−1(qj(t))∈ℛn × n and choose the output variable as yj(t) = qj(t)∈ℛn × 1, state variable as , then we have
or equivalently in the following state-space form:
where
Here, 0<b(Xj(t)) ≤ m1−1In × n. In this paper, we assume that only joint position yj(t) = qj(t) is measurable for controller design. Let the signals qd(t), , be, respectively, the desired generalized joint position, joint velocity, and joint acceleration vectors; the desired state trajectory can be defined as . Now, given a specified desired output trajectory yd(t), t∈[0,T] and an initial desired output yd(0)≠yj(0) for all j≥1, the control objective for the robotic systems executing a repeatable task is to force the output yj(t) to follow yd(t) as close as possible.
3. Derivations of Error Model and Controller
3.1. Derive the Error Model
Define an output tracking error as ej(t) = yd(t)-yj(t) and state tracking errors as e1j(t) = yd(t)-yj(t), . It is assumed that the initial output tracking error vector at each iteration is not necessarily zero, small, and fixed but satisfies for a known positive constants ɛj since the joint position vector yj(t) is measurable. Let the state tracking error vector be defined as
Then we can derive as follows:
where Kc = [k2cI,k1cI]⊤ ∈ ℛ2n × n is a feedback gain matrix such that the characteristic polynomial of Ac = A-BKc⊤ is Hurwitz. Therefore, the tracking error dynamics will satisfy
where . Note that the state tracking error vector Ej(t) in the tracking error dynamics (10) is not assumed to be available for measurement. Hence, it is necessary to construct a state estimation vector for estimation of the state vector. In order to construct a state estimation vector, we first define an output tracking error estimation vector as . Then the state tracking error estimation vector can be defined as
The state tracking error observer is designed as
where Ko = [k1oI,k2oI]⊤ ∈ ℛ2n × n is the observer gain vector such that the characteristic polynomial of Ao = Ac-KoC⊤ is Hurwitz. Define an output observation error vector as . Then the state observation error vector can be defined as
By using (10) and (12), we have the following observation error dynamics:
Note that . Based on the universal approximation theorem, we know that the nonlinear function h(Xj(t)) can be approximated by a traditional FNN [19] Wj(t)⊤O(3)(Xj(t)). Here O(3)(Xj(t))∈ℛM × 1 is the basis function vector with M being the number of rule nodes and Wj(t)∈ℛM × n is the weight matrix of the output layer. According to the universal approximation theorem, there will exist an optimal weight matrix W* such that h(Xj(t)) = W*⊤O(3)(Xj(t)) + ϵ(Xj(t)), where ϵ(Xj(t)) is the approximation error satisfying |ϵ(Xj(t))| ≤ ϵ* in a certain compact set. This implies that (14) can be rewritten as
where is the lumped uncertainty term which includes the difference between FNN networks with input using state Xj(t) and estimated state and the network approximation error. It is easily proven that the lumped uncertainty term satisfies |δj(t)| ≤ δ*. However, it is noted that the value of the unknown constant δ* might be large.
To see how to design the iterative learning controller uj(t) to achieve the control objective, we now adopt the mixed use of a time signal and a Laplace transfer function to obtain the explicit expression of in (15) in time domain with a filtered version as follows:
where . The observer gain vector Ko = [k1oIn × n,k2oIn × n]⊤ is chosen such that with ℓ(s) = s + λ and L(s) being any Hurwitz polynomial of order 1. Then (16) can be rewritten as
where .
3.2. Construct Some Useful Signals
According to the filtered version of output tracking error model (17), we define an augmented signal with filtered version as
where vj(t) is an auxiliary input to be designed later. Then, design an auxiliary error signal as
The initial condition eaj(0) will satisfy . Substituting (17) and (18) into (19), we can find that
It is noted that we apply the Laplace operation to derive the tracking error model (20) for technical analysis later as that used in the traditional model reference adaptive control [26]. The equivalent time-domain state space representation of (20) is
In order to overcome the uncertainty from initial output tracking error, a dead-zone signal eϕj(t) is introduced as follows:
where and
and ϕj(t) is the width of boundary layer. Note that ϕj(t) is designed to decrease along time axis with the initial condition chosen as ϕj(0) = ɛj for jth iteration and 0<ɛje– λT ≤ ϕj(t) ≤ ɛj, ∀t∈[0,T],j≥1. According to (22), it is easy to show that eϕj(0) = 0, ∀j≥1. Now let us differentiate as follows:
where is the typical signum function vector. In the following, we will show that the uncertainty term δLj(t) in (17) can be bounded in a linearly parameterized form if the following normalization signal mj(t) [27] is utilized
where δ1,δ2>0 and δ1<δ1*. Here δ1* is the least positive constant such that 1/L(s – δ1*) is a stable system. In practical, δ1 can be chosen as small as possible. Note that 1-b(Xj(t)) and δj(t) are bounded and is a strictly proper stable transfer function. Hence, according to the definition of δL(t) and by using Lemma 3.1 in [27], we can prove that
for some positive constants θ1*,θ2*.
3.3. Design the Filtered-FNN-Based Iterative Learning Controller
Based on the aforementioned derived error model and the useful signals, we now design uj(t) and vj(t) as follows:
Here is a filtered-FNN (see Appendix) used as an approximator to compensate for h(Xj(t)), is a robust learning term used to overcome the uncertainties due to function approximation error and the error induced by using state estimation, and eϕj(t)Yj(t)⊤Yj(t) is a stabilization term used to guarantee the boundedness of all the closed-loop signals. In this controller, Wj(t) is the weight matrix of the filtered-FNN and θj(t) is control parameter vector which are used to compensate for the unknown W* and θ*, respectively. Furthermore, F(τs) = (τs + 1)2 with τ>0 being a small constant. In the literature, 1/F(τs) is referred to as an averaging filter, which is obviously a low-pass filter whose bandwidth can be arbitrarily enlarged as τ approaches 0. If we define the parameter error as and and substitute (28) into (24), we have the following error dynamics for technical analysis later:
A set of stable adaptive laws is necessary to tune the control parameters. The adaptive laws combining time domain and iteration domain adaptation without knowledge of known bounds on optimal parameters or dead zone mechanism are proposed as follows:
with Wj(0) = Wj–1(T),θj(0) = θj–1(T) for j≥1, and 0<γ1,γ2<1, β1,β2>0. In these adaptive laws, γ1,γ2 and β1,β2 are defined as the weighting gains and adaptation gains, respectively. For the first iteration, we set W0(t) = W0 and θ0(t) = θ0 to be any constant matrix or vector, ∀t∈[0,T] and ∀j≥1. Equations (30) and (31) will become pure time-domain adaptive laws if γ1 = γ2 = 0, or pure iteration-domain adaptive laws if γ1 = γ2 = 1.
4. Analysis of Stability and Convergence
To prove the stability and convergence of the proposed learning system, we first give the following three lemmas.
Lemma 1. Consider the robotic system (2) performing a repetitive control task. If one applies the observer-based adaptive filtered-FNN iterative learning controller (18), (19), (22), (25), (27), and (28) with adaptation laws (30) and (31), then one guarantees that , and are bounded.
Proof. Choose a Lyapunov-like positive function as
and compute its derivative with respect to time t along (29), (30), and (31); then we have
Since and , Vaj(t) in (33) can be simplified by using (30) and (31) as
where we use the property of . Since and are bounded for all t∈[0,T] so that if j = 1, (34) can be rewritten as
Note that the initial value Va1(0) is bounded since eϕ1(0) = 0, and . Together with the result of (35), it readily implies Va1(t),eϕ1(t), . Since the filtered basis function vector is bounded for all j≥1, we conclude that ea1(t) (by (22)) ∈L∞e[0,T].
Lemma 2. Consider the problem setup in Lemma 1. The proposed observer-based adaptive filtered-FNN iterative learning controller guarantees that , and are bounded, for all j≥1 as well as and .
Proof. Define a positive function Vj(T) as
Using the technique of integration by parts, we have
The difference between Vj(T) and Vj–1(T) can be derived by the facts of and as follows:
where we use the property of . Substituting (39) into (38), it yields
Since V1(T) is bounded by Lemma 1 and Vj(T) is positive and monotonically decreasing, we conclude by the result of (40) that Vj(T) is bounded for all j≥1 and will converge as j approaches infinity to some limit value V(T) which is independent of j. The boundedness of Vj(T) also ensures the boundedness of and for all j≥1. On the other hand, (40) also implies
It follows that eϕj(T)⊤eϕj(T) are bounded for all j≥1. Furthermore, and .
Using the boundedness of and (or equivalently the boundedness of and for all j≥1 as shown in Lemma g2, boundedness of all internal signals for all j≥1 is now established in the following Lemma.
Lemma 3. Consider the problem setup in Lemma 1. The proposed observer-based adaptive filtered-FNN iterative learning controller ensures that all the internal signals are bounded; that is, eϕj(t), eaj(t), , yaj(t), , Ej(t), , Wj, θj(t), uj(t), , .
Since Vj(T), defined in (36), is bounded for all j≥1 according to Lemma 2, we conclude that is bounded for all j≥1. Furthermore, the initial value Vaj(0) is also bounded for all j≥1 due to Lemma 2. This readily implies from (44) that Vaj(t) and hence, eϕj(t), . Using the same argument given in Lemma 1, it can be easily shown that eaj(t)∈L∞e[0,T] for all j≥1.
However, the boundedness of Vaj(t), eϕj(t), , , eaj(t), and cannot guarantee the boundedness of Yj(t) (or equivalently mj(t)) and input uj(t). In order to show the boundedness of Yj(t) for all t∈[0,T], we first note that are established in (41). In addition, since . But the boundedness of eϕj(t) and only ensures that Yj(t) is bounded everywhere except on a set of measure zero. Now we adopt some techniques given in chapter 2 of [26]. Firstly, rewrite uj(t) in (27) as follows:
Since , and are bounded for t∈[0,T], and L(s)/F(τs), sL(s)/F(τs) are proper or strictly proper stable transfer functions, (45) implies that uj(t) will satisfy
for some k1,k2>0 by lemma 2.6 (output is bounded by truncated L∞ norm of input for a stable linear system) in [26]. Now we construct an extended dynamic equation by using (15) and (25) as follows:
Let Xaj(t) be the state vector of the extended dynamic equation (47). Taking norms on (47) will yield
for some k3,k4>0. This implies that Xaj(t) is regular [26] so that Xaj(t) and hence, can grow at most exponentially fast and no finite time escape during a finite time interval [0,T]. This condition guarantees a certain degree of smoothness of signal mj(t). Therefore, we show that Yj(t) is a certain degree of smooth signal. Together with the result of , we can now conclude that Yj(t)∈L∞e[0,T].
Due to , this also implies that vj(t)∈L∞e[0,T] (by (28)). Since eϕj(t), Wj(t), θj(t), , Yj(t)∈L∞e[0,T], we conclude that (by (30)), (by (31)) ∈L∞e[0,T]. Since vj(t)∈L∞e[0,T] and L(s)/F(τs) is a proper stable transfer function, this implies that uj(t)∈L∞e[0,T] (by (27)). Since vj(t),uj(t)∈L∞e[0,T], 1/L(s) and 1/ℓ(s) are strictly proper stable transfer functions, this implies that yaj(t)∈L∞e[0,T] (by (18)). As noted above, eaj(t),yaj(t)∈L∞e[0,T], we have (by (19)). Moreover, because Ac is a Hurwitz matrix and , this implies that (by (12)). Finally, since Ao are Hurwitz matrices and , we have (by (14)). Since , it implies Ej(t)∈L∞e[0,T] (by (13)). This completes the proof.
Based on Lemmas 1, 2, and 3, we now state the main result in the following theorem.
Theorem 4. Consider the system setup in Lemma 1. The proposed observer-based adaptive filtered-FNN iterative learning controller guarantees the tracking performance and system stability as follows:
, for all t∈[0,T].
, for all t∈[0,T].
, for all t∈[0,T] and for a constant k5>0.
Let δ and k6 be the positive constants such that the transition matrix Φ(t) of Ac satisfies |Φ(t)| ≤ k6e−δt. Then there exists a positive constant k7 such that , for all t∈[0,T].
, for all t∈[0,T].
Proof. (T1) Since eϕj(t)⊤eϕj(t)∈L∞e[0,T] and for all j≥1. These facts imply that eϕj(t)⊤eϕj(t) is uniformly continuous over [0,T] for all j≥1. On the other hand, eϕj(t)⊤eϕj(t) satisfies due to the result of Lemma 2. We can now conclude, by using similar argument for Barbalat's lemma (e.g., Lemma 3.2.6 in [28]), that for all t∈[0,T].
(T2) According to the definition of eϕj(t) in (22), we can derive the bound of
for all t∈[0,T].
(T3) Substituting (27) into (18), we can find that eaj(t) actually satisfies
Since vj(t) is bounded and the H∞ norm of and , we can conclude that
(T5) Finally, we investigate the tracking performance in the final iteration when (T1), (T2), (T3), and (T4) of this theorem are achieved. Since , we have
As iteration goes to infinity,
for t∈[0,T]. This completes the proof.
Remark 5. In Theorem 4, we show that the output learning error ej(t) will converge to a residual set as the number of iterations approaches infinity. In general, the size of the residual set can be tuned by two design parameters. The first one λ is the decay rate of the boundary layer ϕj(t) = ɛje – λt which will be chosen as large as possible. The second one τ is the filter parameter of the averaging filter 1/F(τs) = 1/(τs + 1)2 which will be chosen as small as possible. To guarantee a satisfied learning performance, we will usually choose a larger λ and smaller τ. Furthermore, if there is no initial output error, that is, ɛj = 0, the output learning error will converge to a residual set whose level of magnitude depends on τ only.
5. Simulation Example
In this section, a computer simulation is conducted to demonstrate the learning effect of the proposed observer based adaptive filtered-FNN iterative learning controller. Here we consider a two-link planar robotic system [29] with the dynamic equation of
where , , D22 = m2lc22 + I2, and h = m2l1lc2sin(q2j(t)). Here mi,Ii,li, and lci represent mass, inertia, length of link i, and the distance from the previous joint to the center of mass of link i, respectively.
In this simulation, we set m1 = 10 kg, m2 = 5 kg, l1 = 1 m, l2 = 0.5 m, lc1 = 0.5 m, lc2 = 0.25 m, I1 = 0.83 kg-m2, and I2 = 0.3 kg-m2. The control objective is to let qj(t) = [q1j(t),q2j(t)]⊤ track the desired trajectory as close as possible over a finite time interval [0,15] when only the angular position qj(t) is measurable. The design steps are summarized as follows.
Specify the observer and feedback gain vectors Ko = [k1oI2×2,k2oI2×2]⊤ = [16I2×2, 9I2×2]⊤ ∈ ℛ4×2, Kc = [k2cI2×2,k1cI2×2]⊤ = [4I2×2, 4I2×2]⊤ ∈ ℛ4×2, respectively, such that the matrices Ac = A-BKc⊤ and Ao = Ac-KoC⊤ are Hurwitz.
Design the tracking error observer as in (12) to obtain , and the state estimation vector .
Select with ℓ(s) = s + λ = s + 10 and L(s) = s + 10. Then, define an augmented signal with filtered version as , an auxiliary error signal as , and a dead-zone signal with ϕj(t) = ɛje – λt = ɛje – 10t. The normalization signal is given as with δ1 = δ2 = 0.01.
Construct the membership functions for . Then, solve the filtered basis function vector . The filtered-FNN with input is given as . Since the working domain of the desired trajectory is within the interval [−1, 1], we choose the centers as m = [m1,m2,m3,m4] with mi = [mi1,mi2,mi3,mi4,mi5] = [−1, −0.5, 0, 0.5, 1], i = 1, 2, 3, 4 and variances as σ=[σ1,σ2,σ3,σ4] with σi = [σi1,σi2,σi3,σi4,σi5] = [0.25, 0.25, 0.25, 0.25, 0.25], i = 1, 2, 3, 4 to cover this interval, respectively. In addition, we set the control parameter θ0(t) = θ0 = 0.1 at the first iteration for all t∈[0, 15]. It is noted that the initial values of the consequent parameters W0(t) can be roughly estimated if the nonlinear function h(Xj(t)) of the robotic system is partially known. However, we often arbitrarily choose this initial parameters.
Design the observer-based adaptive filtered-FNN iterative learning controller as uj(t) = (L(s)/F(τs))[vj(t)] where . The averaging filter is designed with τ = 0.0001.
Finally, the adaptation algorithms (30) and (31) are adopted to update the filtered-FNN parameters and control parameters with γ1 = γ2 = 0.5, β1 = β2 = 500.
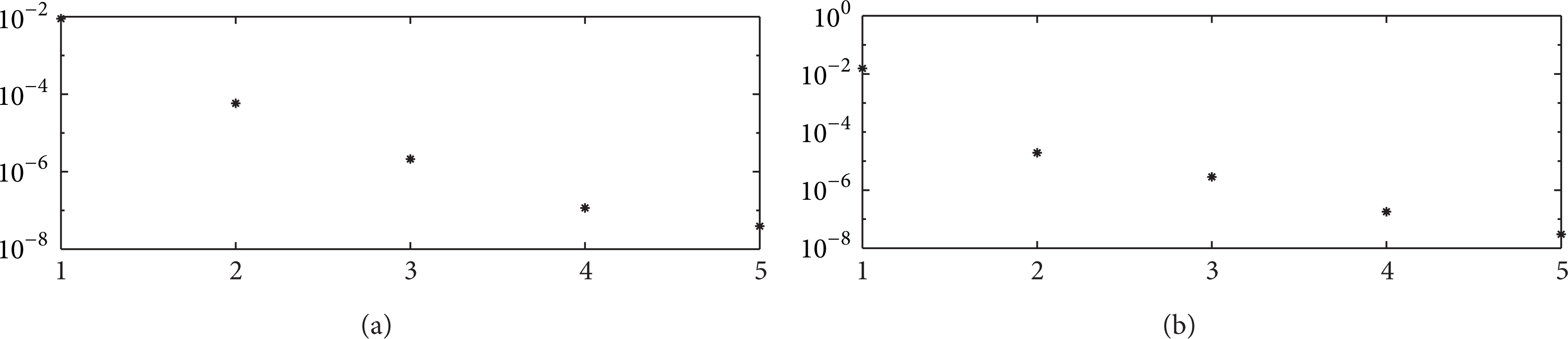
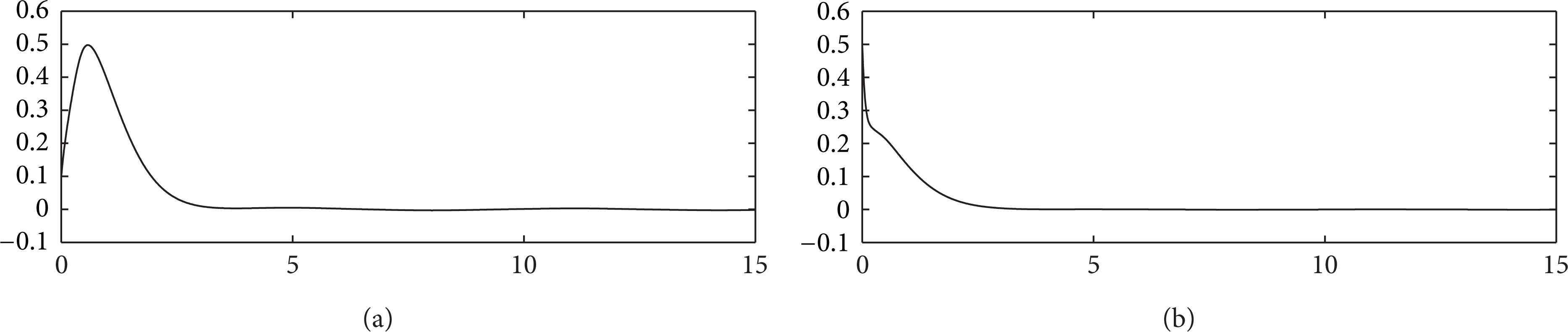
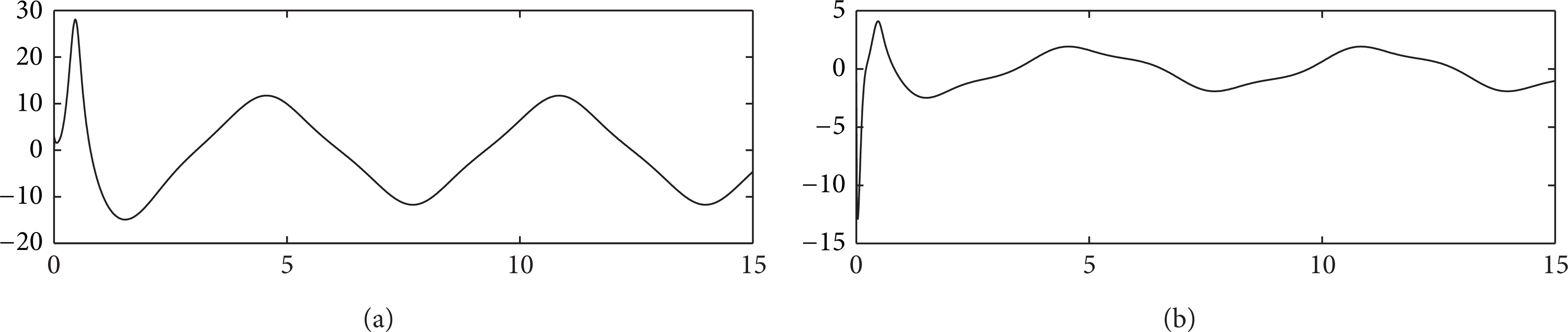
In order to show the robustness to the varying initial output tracking error, we first assume the initial joint position vector of the two-link planar robotic system taking the following arbitrary values for the first five iterations: qj(0) = [q1j(0),q2j(0)]⊤ = [0.05, 0.3]⊤,[0.25, 0.8]⊤,[0.14, 0.6]⊤,[0.09, 0.4]⊤,[−0.1, 0.5]⊤. At the beginning of each iteration, the initial value of the boundary layer ϕj(t) is then chosen according to . For example, ϕ1(0) = 0.05,ϕ2(0) = 0.25,ϕ3(0) = 0.14,ϕ4(0) = 0.09, and ϕ5(0) = 0.1. To study the effect of learning performances, and versus iteration j are shown in Figures 1(a) and 1(b), respectively. It is clear that the asymptotic convergence proved in (T1) of Theorem 4 is achieved. Since the learning process is almost completed at the 5th iteration, we demonstrate the auxiliary errors ea, 15(t) and ea, 25(t) in Figures 2(a) and 2(b), respectively. The trajectories of ea, 15(t) and ea, 25(t) satisfy −0.5e–10t ≤ ea, 15(t) ≤ 0.5e–10t and −0.5e–10t ≤ ea, 25(t) ≤ 0.5e–10t, respectively. This clearly proves (T2) of Theorem 4. The output tracking errors e15(t) and e25(t) are shown in Figures 3(a) and 3(b) with satisfied performance even there exists varying initial output errors. The nice tracking performances at the 5th iteration between joint position vector qj(t) = [q1j(t),q2j(t)]⊤ and desired joint position vector qd(t) = [qd, 1(t),qd, 2(t)]⊤ are presented in Figures 4(a) and 4(b), respectively. Finally, the bounded learned control forces u15(t) and u25(t) are plotted in Figures 5(a) and 5(b), respectively.
(a) versus iteration j; (b) versus iteration j.
(a) ea, 15(t) (solid line) and ± ϕ5(t) (dotted lines) versus time t; (b) ea, 25(t) (solid line) and ± ϕ5(t) (dotted lines) versus time t.
(a) e15(t) versus time t; (b) e25(t) versus time t.
(a) q15(t) (solid line) and qd, 1(t) (dotted line) versus time t; (b) q25(t) (solid line) and qd, 2(t) (dotted line) versus time t.
(a) u15(t) versus time t; (b) u25(t) versus time t.
6. Conclusion
An observer-based adaptive filtered-FNN iterative learning controller for repeated tracking control of uncertain robotic systems is proposed in this paper. A tracking error observer is designed to estimate the unknown joint variables since only joint positions are assumed to be measurable. An error observation dynamic based on the tracking error observer is derived for the design of the iterative learning controller. The main control force is designed by using a technique of averaging filter and some auxiliary signals. In this main control force, a fuzzy neural learning component based on a filtered-FNN is used to approximate the unknown nonlinear function, a robust learning component is designed to compensate for the other uncertainties, and a stabilization term is applied to guarantee the boundedness of internal signals. The adaptive laws combining time domain and iteration domain adaptation for the network parameters and control parameters are proposed to ensure the stability and convergence of the learning system. A Lyapunov-like analysis has been developed to solve both boundedness of internal signals inside the closed-loop system and asymptotic convergence of learning error. It is shown that the output tracking error asymptotically converges to a tunable residual set whose level of magnitude can be tuned by design parameters as the iteration number increases.
Footnotes
Appendix
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is supported by the National Science Council under Grants NSC102-2221-E-211-003 and NSC102-2221-E-211-011.
References
1.
MooreK. L. and Jian-XinX. U., “Special issue on iterative learning control,”International Journal of Control, vol. 73, no. 10, pp. 819–823, 2000.
2.
BristowD. A.TharayilM., and AlleyneA. G., “A survey of iterative learning control: a learning-based method for high-performance tracking control,”IEEE Control Systems Magazine, vol. 26, no. 3, pp. 96–114, 2006.
3.
AhnH.-S.ChenY. Q., and MooreK. L., “Iterative learning control: brief survey and categorization,”IEEE Transactions on Systems, Man and Cybernetics C, vol. 37, no. 6, pp. 1099–1121, 2007.
4.
WangY.GaoF., and DoyleF. J.III, “Survey on iterative learning control, repetitive control, and run-to-run control,”Journal of Process Control, vol. 19, no. 10, pp. 1589–1600, 2009.
5.
XuJ.-X., “A survey on iterative learning control for nonlinear systems,”International Journal of Control, vol. 84, no. 7, pp. 1275–1294, 2011.
6.
HorowitzR., “Learning control of robot manipulators,”Journal of Dynamic Systems, Measurement and Control, Transactions of the ASME, vol. 115, no. 2 B, pp. 402–411, 1993.
7.
WangD.SohY. C., and CheahC. C., “Robust motion and force control of constrained manipulators by learning,”Automatica, vol. 31, no. 2, pp. 257–262, 1995.
8.
ChienC.-J. and LiuJ.-S., “A P-type iterative learning controller for robust output tracking of nonlinear time-varying systems,”International Journal of Control, vol. 64, no. 2, pp. 319–334, 1996.
9.
BouakrifF., “D-type iterative learning control without resetting condition for robot manipulators,”Robotica, vol. 29, no. 7, pp. 975–980, 2011.
10.
TayebiA., “Adaptive iterative learning control for robot manipulators,”Automatica, vol. 40, no. 7, pp. 1195–1203, 2004.
11.
ChienC.-J. and TayebiA., “Further results on adaptive iterative learning control of robot manipulators,”Automatica, vol. 44, no. 3, pp. 830–837, 2008.
12.
JiaX.-G. and YuanZ.-Y., “Adaptive iterative learning control for robot manipulators,” in Proceedings of the IEEE International Conference on Intelligent Computing and Intelligent Systems (ICIS '10), pp. 139–142, Xiamen, China, October 2010.
13.
WeiJ.-M. and HuY.-A., “Adaptive iterative learning control for robot manipulators with initial resetting errors,”Applied Mechanics and Materials, vol. 130–134, pp. 265–269, 2012.
14.
NgoT.WangY.MaiT. L.GeJ.NguyenM. H., and WeiS. N., “An adaptive iterative learning control for robot manipulator in task space,”International Journal of Computers, Communications and Control, vol. 7, no. 3, pp. 510–521, 2012.
15.
TayebiA. and ChienC.-J., “A unified adaptive iterative learning control framework for uncertain nonlinear systems,”IEEE Transactions on Automatic Control, vol. 52, no. 10, pp. 1907–1913, 2007.
16.
ChenW.LiJ. M., and LiJ., “Practical adaptive iterative learning control framework based on robust adaptive approach,”Asian Journal of Control, vol. 13, no. 1, pp. 85–93, 2011.
17.
ChienC.-J., “A combined adaptive law for fuzzy iterative learning control of nonlinear systems with varying control tasks,”IEEE Transactions on Fuzzy Systems, vol. 16, no. 1, pp. 40–51, 2008.
18.
WangY.-C. and ChienC.-J., “Decentralized adaptive fuzzy neural iterative learning control for nonaffine nonlinear interconnected systems,”Asian Journal of Control, vol. 13, no. 1, pp. 94–106, 2011.
19.
WangY. C. and ChienC. J., “Repetitive tracking control of nonlinear systems using reinforcement fuzzy-neural adaptive iterative learning controller,”Applied Mathematics and Information Sciences, vol. 6, no. 3, pp. 473–481, 2012.
20.
TayebiA. and XuJ.-X., “Observer-based iterative learning control for a class of time-varying nonlinear systems,”IEEE Transactions on Circuits and Systems I, vol. 50, no. 3, pp. 452–455, 2003.
21.
XuJ.-X. and XuJ., “Observer based learning control for a class of nonlinear systems with time-varying parametric uncertainties,”IEEE Transactions on Automatic Control, vol. 49, no. 2, pp. 275–281, 2004.
22.
WallénJ.NorrlöfM., and GunnarssonS., “A framework for analysis of observer-based ILC,”Asian Journal of Control, vol. 13, no. 1, pp. 3–14, 2011.
23.
DuY.-Y.TsaiJ. S.-H.GuoS.-M.SuT.-J., and ChenC.-W., “Observer-based iterative learning control with evolutionary programming algorithm for MIMO nonlinear systems,”International Journal of Innovative Computing Information and Control, vol. 7, no. 3, pp. 1357–1374, 2011.
24.
ChenW.-S.LiR.-H., and LiJ., “Observer-based adaptive iterative learning control for nonlinear systems with time-varying delays,”International Journal of Automation and Computing, vol. 7, no. 4, pp. 438–446, 2010.
25.
BouakrifaF.BoukhetalabD., and BoudjemabF., “Velocity observer-based iterative learning control for robot manipulators,”International Journal of Systems Science, vol. 44, no. 2, pp. 214–222, 2013.
26.
AnnaswamyA. M. and NarendraK. S., Stable Adaptive Systems, Prentice-Hall, 1988.
27.
IoannouP. A. and TsakalisK. S., “A robust direct adaptive control,”IEEE Transactions on Automatic Control, vol. 31, no. 11, pp. 1033–1043, 1986.
28.
IoannouP. A. and SunJ., Robust Adaptive Control, Prentice Hall, Englewood Cliffs, NJ, USA.
29.
SlotineJ. J. and LiW., Applied Nonlinear Control, Prentice-Hall, Englewood Cliffs, NJ, USA.