
Abstract
Possibilistic c-means clustering algorithm (PCM) has emerged as an important technique for pattern recognition and data analysis. Owning to the existence of many missing values, PCM is difficult to produce a good clustering result in real time. The paper proposes a distributed weighted possibillistic c-means clustering algorithm (DWPCM), which works in three steps. First the paper applies the partial distance strategy to PCM (PDPCM) for calculating the distance between any two objects in the incomplete data set. Further, a weighted PDPCM algorithm (WPCM) is designed to reduce the corruption of missing values by assigning low weight values to incomplete data objects. Finally, to improve the cluster speed of WPCM, the cloud computing technology is used to optimize the WPCM algorithm by designing the distributed weighted possibilistic c-means clustering algorithm (DWPCM) based on MapReduce. The experimental results demonstrate that the proposed algorithms can produce an appropriate partition efficiently for incomplete big sensor data.
1. Introduction
Recent years have witnessed the deployments of sensor networks for many critical applications such as Internet of Things (IoT) [1, 2], environment monitoring [3], and target detection [4, 5]. With the rapid advent of various sensor networks, more and more mobile devices, such as smart phones and RFID, can sense and collect a huge number of sensor data. For example, data sampled from millions of sensors deployed sensor networks for environment monitoring can exceed hundreds of terabytes data every day. We are moving toward the era of big sensor data which requires efficiently advanced data analysis and mining tools [6].
As an important data mining tool, the possibilistic c-means cluster algorithm (PCM) has emerged as an important technique for pattern recognition and data analysis, proposed by Krishnapuram and Keller [7]. Many PCM variants have been proposed after standard PCM for improving the performance of the original PCM algorithm. Zhang and Leung applied the fuzzy method to PCM for an improved PCM algorithm, which enhances the robustness of the possibilistic approach [8]. In 2011, Yang and Lai proposed a robust merging approach and created the automatic merging possibilistic clustering method to obtain the number of classes automatically. However, this algorithm could not always obtain the most reasonable number of clusters [9]. Pal proposed FPCM and PFCM, which is a combined way of doing PCM with FCM, avoiding the coincidental cluster [10, 11]. In 2008, Xie et al. proposed an enhanced possibilistic c-means clustering algorithm, which partitioned the dataset into the main cluster and the assisted cluster to avoid producing the coincidental cluster [12].
PCM can be extensively used in big sensor data analysis and mining. However, in big sensor data, many data sets suffer from incompleteness; that is, a data set X can contain vectors that miss one or more of the attribute values [13]. PCM could not succeed completely in clustering such incomplete data sets in real time. On the one hand, PCM could not calculate the distance between two objects in incomplete data sets. Meanwhile the accuracy of PCM is easily corrupted by incomplete objects. On the other hand, PCM is difficult to satisfy the real-time requirement of clustering incomplete big sensor data due to the huge amount of data.
The paper proposes a distributed weighted possibilistic c-means algorithm (DWPCM) for clustering incomplete big sensor data. First, the paper applies the partial distance strategy (PDS) [14] to PCM (PDPCM) for calculating the distance between two objects in incomplete data set using all available attribute values. Further, a weighted PDPCM algorithm (WPCM) is designed to reduce the corruption of missing values. In WPCM, a novel method for determining weight values is presented. Finally, the cloud computing technology is used to optimize the WPCM algorithm by designing the distributed weighted possibilistic c-means algorithm (DWPCM) based on MapReduce, which aims at improving the cluster speed of WPCM.
To evaluate the performance of the proposed algorithms, we implement the proposed methods on two real big sensor data sets. The experimental results demonstrate that the proposed algorithms can produce an appropriate partition efficiently for incomplete big sensor data.
The rest of this paper is structured as follows. Section 2 resumes some related research on possibilistic c-means clustering algorithms and the cluster algorithms based on cloud computing. Section 3 depicts the WPCM algorithm and Section 4 describes the DWPCM algorithm based on MapReduce. The performance evaluation is illustrated in Section 5. The paper is concluded in Section 6.
2. Related Work
2.1. Possibilistic c-Means Algorithms
PCM partitions an m-dimensional dataset
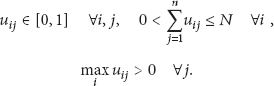
PCM minimizes the following objective function [7]:

In (2),
Solving the minimization problem (2) yields membership functions of the form
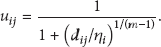
The cluster centers are updated using

The procedure of PCM can be described as follows.
Step 1.
Choose m, c, and
Step 2.
Update cluster centers using (4).
Step 3.
Estimate

Step 4.
Update membership matrix U using (3).
Step 5.
If
PCM is rational and it has a meaningful interpretation. What is more important is that PCM is robust, because a noisy object would belong to the clusters with small memberships, and consequently it cannot corrupt the resulting clusters significantly [8].
In the PCM algorithm, each object is considered equally important in the clustering solution. The weighted PCM (wPCM) model introduces weights to define the relative importance of each object in the clustering solution [15, 16]. Assume that
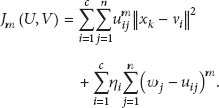
In order to find clusters with nonspherical shapes, kernel-based PCM algorithms are proposed, which mapped original data into higher dimensional feature space [17]. Given a kernel function k, the kernel PCM algorithm (kPCM) minimizes the following objective function:

Even though these methods are performed well in the cluster process, they cannot succeed completely in clustering incomplete big sensor data because of the corruption of missing values. The paper proposed a weighted PCM algorithm (WPCM), which applies the partial distance to PCM for calculating the distance between two objects in incomplete data set and then assigns low weight values to incomplete data object for reducing the corruption of missing values.
2.2. Cluster Algorithms Based on Cloud Computing
Cloud computing has emerged as a significant technology to deal with big data in time by leveraging vast amounts of computing resources available on demand with low resource usage cost [18, 19]. As the key technology of cloud computing, MapReduce [20] is a highly efficient distributed programming model for large-scale data sets in parallel computing.
Many cluster algorithms based on MapReduce have been proposed to improve the cluster efficiency. For example, Zhao [21] proposed parallel k-means algorithm based on MapReduce to cluster massive data fast. Similar algorithms include MapReduce-kCenter algorithm and MapReduce-kMedian algorithm, which used iterative sampling technology to get good performance for clustering very large data [22, 23]. Another example is hierarchical clustering algorithm based on cloud computing, in which MapReduce is used to optimize the hierarchical clustering algorithm for processing large-scale data [24, 25]. Well-known cluster algorithms based on MapReduce, such as HDBSCAN [26] and MR-DBSCAN [27], reduce I/O access frequency and spatial complexity for speeding up the density clustering. For affinity propagation clustering algorithm, published in science magazine proposed by Frey and Dueck [28], Lu et al. [29] proposed a distributed AP clustering algorithm based on MapReduce (DisAP), which includes three MapReduce stages and achieved high performance on both scalability and accuracy. In 2012, Yang et al. [30] presented a MapReduce-based MST text clustering algorithm, which used cloud computing technology to improve the performance of the graph clustering. Yu and Dai [31] proposed a parallel fuzzy c-means algorithm based on MapReduce for improving the standard fuzzy c-means algorithm. Other parallel clustering algorithms based on cloud computing can be found in [32–34].
Even though these algorithms perform their job well, they all focus on crisp clustering. The paper uses cloud computing technology to accelerate the cluster speed of WPCM by designing a distributed WPCM algorithm (DWPCM) based on MapReduce to produce the possibilistic clustering for big data in real time.
3. Weighted PCM Algorithm
3.1. PCM Based on Partial Distance for Clustering Incomplete Data
In this subsection, the paper applies partial distance to PCM for clustering incomplete data set. Partial distance is used to calculate the distance between an object
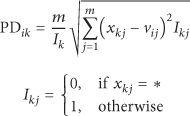

From (8a) and (8b), partial distance makes full use of attribute information of both complete data and incomplete data to calculate the distance between two objects.
The PCM algorithm based on partial distance (PDPCM) is obtained by making two modifications of PCM: (1) calculating

This algorithm enjoys all the standard convergence properties of PCM because it is an instance of alternating optimization [7].
For an m-dimensional incomplete data set, the procedure of the PCM algorithm for clustering incomplete data based on partial distance can be described as follows.
Step 1.
Choose m, c, and
Step 2.
Update cluster centers using (9).
Step 3.
Estimate
Step 4.
Update membership matrix U using (3).
Step 5.
If
3.2. Weighted PCM Algorithm
Even though the PCM algorithm based on partial distance given earlier can cluster incomplete data sets, it is difficult to produce a good partition due to the effect of incomplete objects. The paper proposes a weighted PCM algorithm (WPCM), which assigns low weight values to incomplete objects for reducing the corruption of incomplete objects on the cluster process.
To minimize the objective function, WPCM updates the membership values and clusters centers using the following equation:
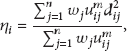
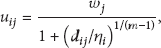

The

Equation (13) can detect the outlier effectively. However, it cannot reduce the effect of incomplete objects on the cluster process. The paper redefines the weights in

The steps of the WPCM algorithm are outlined as follows.
Step 1.
Choose m, c,and
Step 2.
Calculate the weight values using (14).
Step 3.
Estimate
Step 4.
Update membership matrix U using (11).
Step 5.
Update the cluster centers V using (12).
Step 6.
If
3.3. Time Complexity
In this subsection, we discuss the time complexity of WPCM. All operations are counted as unit costs. We do not assume time economies that might be realized by special programming tricks or properties of the equations involved. We use the following notation in our discussion:
i is the number of iterations of WPCM over the full data set; n is the number of data objects; f is the number of dimensions; c is the number of clusters.
From the cluster process of the WPCM algorithm, the time complexity of this algorithm is dominated by Steps 4 and 5. The calculation of membership matrix using (14) requires
4. Distributed Weighted PCM Algorithm Based on MapReduce
In Section 3, we propose a weighted PCM algorithm based on partial distance, which can cluster incomplete data effectively. However, WPCM has a low efficiency for clustering incomplete big sensor data owning to the huge number of data and its high time complexity.
To accelerate the cluster speed of WPCM, the paper proposes a distributed WPCM algorithm (DWPCM) based on MapReduce in this section.
From the steps of WPCM, there are two major operations: calculating the degree of membership
In the map phase, the Map function is designed to calculate the degree of membership
To reduce the communication cost of the distributed algorithm, the paper partitions the membership matrix into p blocks by columns, each block with
In order to update cluster centers in parallel, two parameters,

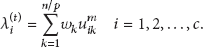
Finally, the Map function outputs
In the reduce phase, the Reduce function is designed to calculate the clustering centers
The input of the Reduce function is a

Similar to Section 3.3, we discuss the time complexity of DWPCM now. The notation used in our discussion is the same as that in Section 3.3. The time complexity of DWPCM is approximately
5. Experiments
In order to evaluate the efficiency and effectiveness of the proposed algorithms, we perform the algorithms on the two real data sets. The experimental setup and dataset are described first, followed by the results.
5.1. Experimental Setup and Dataset
The experimental environment consists of 20 computers as cloud computing nodes, each of which has an Intel Core i7 processor with 3.2 GHz speed, 8 GB RAM, and a 2 TB hard drive.
We apply the algorithms on two real data sets in the experiments. The first data set is an extension of “Gas Sensor Array Drift Dataset at Different Concentrations Data Set” which is available in UCI Machine Learning Repository [35, 36]. This data set contains 3 × 109 objects with 129 numerical attributes, called eGSAD. The second data set consists of 2 × 1010 objects sampled from the smart WSN lab, called sWSN, whose size is about 1 TB. The parameters used for the proposed algorithms are
We first artificially create missing values in the data sets for simulating incomplete data sets and then cluster them using the proposed algorithms. The performance of the proposed algorithms is evaluated by comparing their cluster results to the result of PCM for clustering original data sets from both the efficiency and effectiveness points of view. While the efficiency concerns the time required to cluster the data sets, the effectiveness is related to the cluster accuracy.
Since the cluster performance depends on the amount of missing values, we artificially create six kinds of missing ratios, which are 1%, 3%, 5%, 10%, 15%, and 20% objects with missing values. For every missing ratio, we generate 5 different incomplete data sets for Gisette and sWSN. Specifically, any two data sets can have different missing values for every missing ratio.
5.2. Experimental Results on Cluster Accuracy
In order to assess the effectiveness of WPCM, two well-known evaluation criteria,
The first evaluation criterion,

The other evaluation criterion,
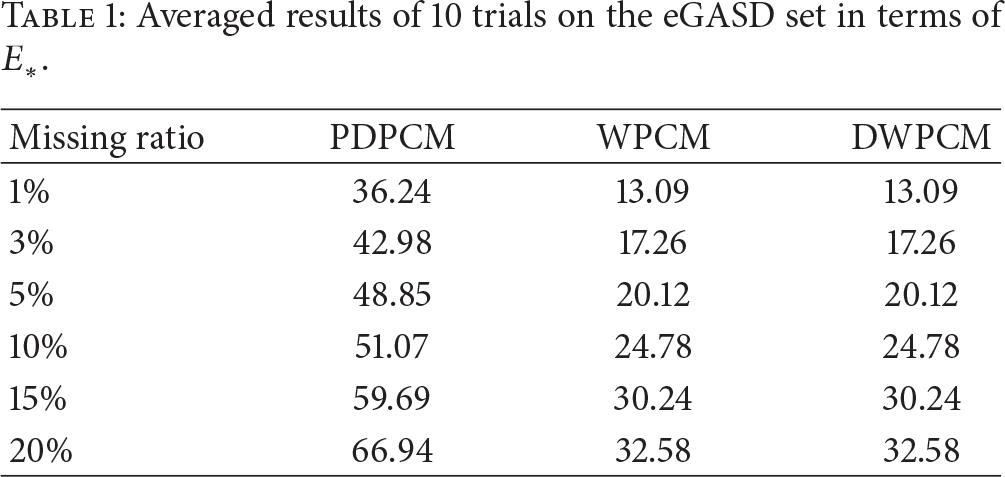
To eliminate the variation in the results from trial to trial, Tables 1 and 2 present the average values of
Averaged results of 10 trials on the eGASD set in terms of
Averaged results of 10 trials on the sWSN set in terms of

We present the cluster accuracy of PCM, PCM based on partial distance (PDPCM), WPCM, and DWPCM on the two data sets in terms of
From Tables 1 and 2, as the missing ratio increases, the average values of
To calculate the
Averaged results of 10 trials on eGASD in terms of ARI.

Averaged results of 10 trials on sWSN in terms of ARI.

From the results shown in Tables 3 and 4, WPCM produces better partitions than PDPCM for 6 different missing ratios of the two data sets in terms of ARI. DWPCM still produces the same result as WPCM based on ARI.
5.3. Experimental Results on Execution Time
We use execution time and scalability to evaluate the efficiency of DWPCM. The average execution time of PDPCM, WPCM, and DWPCM on the two data sets for different number of objects is shown in Figures 1 and 2.
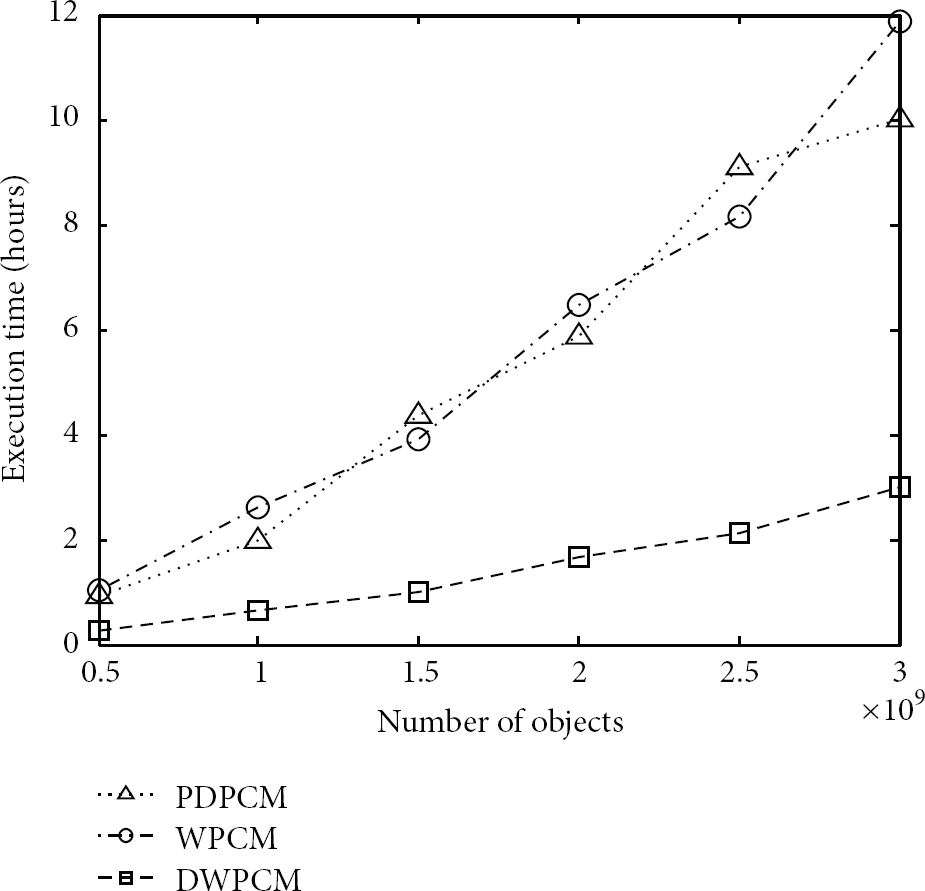
Average execution time on eGASD.

Average execution time on sWSN.
From Figures 1 and 2, even though the average execution time of the three algorithms increases with the number of objects increasing, DWPCM takes the least time of the three algorithms for the two data sets. Especially when the data set is very big, the execution time required by DKPCM is significantly less than the other two algorithms, which demonstrates that DWPCM performs most efficiently for clustering big sensor data.
In order to test the scalability of DWPCM, we perform the algorithm for clustering the two data sets in the different cloud computing platforms, in which there are 5 nodes, 10 nodes, 15 nodes, and 20 nodes, respectively. The result is shown in Figure 3.

Computation speed of DWPCM.
From Figure 3, the execution time of DWPCM for clustering the two data sets reduces gradually with the increasing number of data nodes in the cloud computing platform, which demonstrates that adding nodes can significantly improve the system capacity. Therefore, DWPCM has a good scalability, especially when the data set is big.
6. Conclusion and Future Work
The paper proposes a distributed weighted PCM algorithm for clustering incomplete big sensor data. The proposed algorithm applies partial distance strategy to PCM (PDPCM) for calculating the distance between any two objects in the incomplete data set. Further, based on PDPCM, the paper designs a weighted PCM algorithm (WPCM) to reduce the corruption of incomplete objects on the cluster process. Another unique property of the proposed algorithm is the use of the cloud computing technology. Cloud computing is used to optimize WPCM to provide a significant computation speed, which is very important for big sensor data real-time clustering and analysis.
The experiments demonstrate that WPCM produces a good cluster result based on both evaluation criteria, namely,
In the future research work, we will investigate a further improvement of DWPCM to improve the effectiveness and efficiency of clustering big sensor data with many missing values. Additionally, for many semistructured and unstructured data in big sensor data, our future research plans will modify DWPCM to cluster the two types of incomplete data into appropriate groups.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by Project U1301253 of NSFC and Project 201202032 of Liaoning Provincial Natural Science Foundation of China.