
Abstract
Due to the importance of power dissipation in the wireless sensor networks and embedded systems, real-time scheduling has been studied in terms of various optimization problems. Real-time tasks that synchronize to enforce mutually exclusive access to the shared resources could be blocked by lower priority tasks. While dynamic voltage scaling (DVS) is known to reduce dynamic power consumption, it causes increased blocking time due to lower priority tasks that prolong the interval over which a computation is carried out. Additionally, processor slowdown to increase execution time implies greater leakage energy consumption. In this paper, a leakage-controlled method is proposed, which decreases both priority inversion and power consumption. Based on priority ceiling protocol (PCP) and a graph reduction technique, this method can decrease more energy consumption and avoid priority inversion for real-time tasks.
1. Introduction
Power consumption of IC devices can be briefly classified into (1) static power consumption which consists of the power used when the transistor is not in the switching process and (2) dynamic power consumption which consists of the power used to charge the load capacitance and logic states of the device. In the last two decades, complementary metal-oxide semiconductor (CMOS) has emerged as a dominant technology due to its low static power dissipation. Leakage power in CMOS circuits is due to subthreshold current that flows through the transistors and contributes to a significant portion of the total power consumption. Figure 1 illustrates the trend at lower nodes that leakage power becomes almost comparable to active power. For 90 nm and below technologies, leakage is the main factor which dominates over the dynamic power and contributes to almost or more than 50% of total power dissipation.
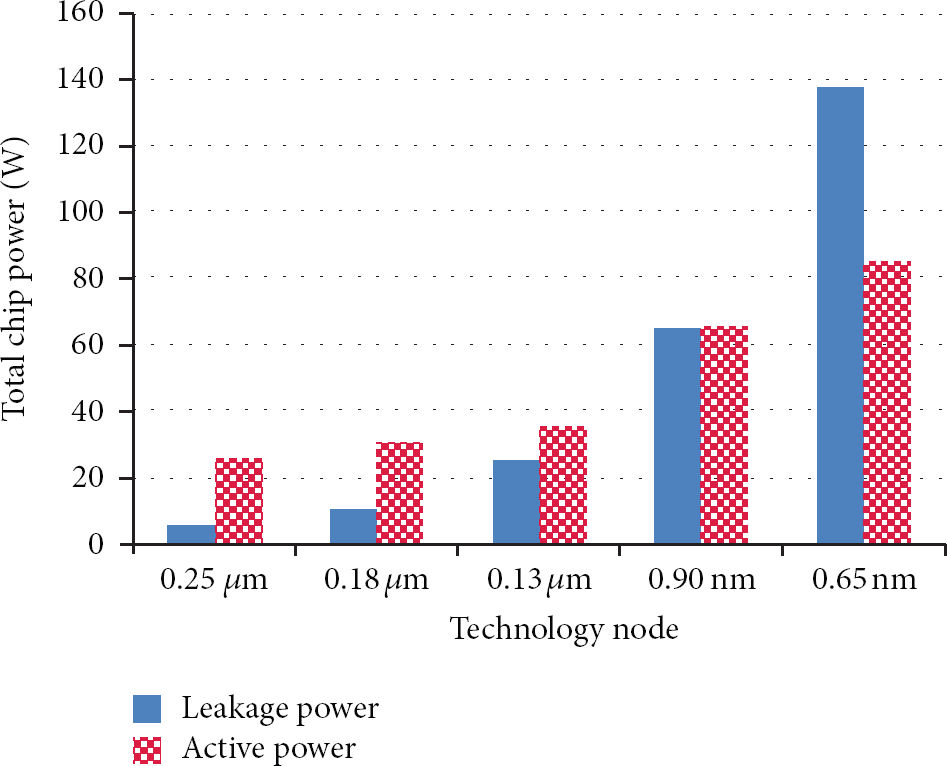
There have been multiple techniques used in the past to reduce the power dissipation of embedded systems and have been implemented successfully through the different levels of design abstraction. At the system level, there are two primary ways to reduce power consumption: processor slowdown and shutdown. Slowdown techniques such as dynamic voltage scaling (DVS) are preferred due to the assumptions of low leakage power dissipation and quadratic dependence of power on voltage level. However, energy savings based on DVS come at the cost of increased execution time, which implies greater leakage power consumption. With the repaid increase in device leakage power due to the scaling down of technology nodes, the leakage power has been a major concern in the system design. Device scheduling is the key factor to have the best tradeoff between the power and characteristics such as resource sharing and system utilization.
Many previous works have addressed DVS based on performance requirements to minimize the dynamic power consumption [1–13]. While techniques to optimize the total static and dynamic power consumption have been proposed, they are still based on the ideal system environment without considering resource synchronization problem. Recently, researchers have started exploring energy-efficient scheduling with the considerations of leakage current [4–6, 14–16]. To reduce the leakage power, a system might be turned off (to enter a dormant mode) when not used. For periodic real-time tasks, Jejurikar et al. [6] and Lee et al. [14] proposed energy-efficient scheduling on a uniprocessor by procrastination scheduling to decide when to turn off the system. Jejurikar and Gupta [5, 15] further considered real-time tasks that might complete earlier than its worst-case execution time (WCET) by extending the algorithms presented in [6]. For DVS processor with aperiodic real-time tasks, Irani et al. [4] proposed a 3-approximation algorithm to minimize leakage current on the uniprocessor with continuous available speeds. It guarantees to derive a solution with the energy consumption at most three times energy consumption of an optimal solution. For aperiodic real-time tasks without DVS, Baptiste [17] developed an algorithm that minimized the energy consumption resulting from the leakage current and the overhead to turn on/off the system. In the periodic real-time task systems, Quan et al. [13] and Niu and Quan [16] proposed a leakage-aware method that expands all the jobs in the hyperperiod of the given tasks and calculates their latest starting time on the fly. The computation overheads produced by their algorithms might be too much to be applied in an online scheduling. In addition to considering the leakage current of the processor, leakage power consumption produced by system devices was also considered in [18] as well as their preemption control [9]. The objectives of the above methods are proposed to reduce the system power and do not consider other advantages or purposes of leakage-aware techniques. For example, one can shut down a processor before the beginning of a lower priority task that intents to lock a shared resource required earlier by a higher priority task.
Work-demanded analysis has been extensively investigated in real-time systems in which sporadic tasks are jointly scheduled with periodic tasks [3, 7–9, 11, 12, 15, 21]. The purpose of work-demanded analysis is to improve the response times of aperiodic tasks or to increase their acceptance ratio. It also benefits the power-saving on both DVS and leakage-aware methods. Pillai and Shin [12] proposed a cycle-conserving rate-monotonic (ccRM) scheduling scheme that contains offline and online algorithms. The offline algorithm computes the worst-case response time of each task and derives the maximum speed needed to meet all task deadlines. It recomputes the task utilization by comparing the actual time for completed tasks with WCET schedule. In other words, when a task completes early, they have to compare the used actual processor cycles to a precomputed worst-case execution time schedule. This WCET schedule is also called canonical schedule [22] whose length could be the least common multiplier of task periods. ccRM is a conservative method, as it only considers possible slack time before the next task arrival (NTA) of current job. Gruian proposed a DVS method for offline task stretching and online slack distribution [3]. The offline part of this method consists of two separate techniques. One focuses on the intratask stochastic voltage scheduling that employs a task-execution length probability function. The second technique computes stretching factors by using a response time analysis. It is similar to Pillar and Shin's offline technique, but instead of adopting a stretching factor for all tasks before NTA, Gruian assigns different stretching factor to the individual task within the longest task period. Kim et al. [8] proposed a greedy online algorithm called the low-power work-demand analysis (lpWDA) that derives slack from low-priority tasks, as opposed to the method in [3, 12] that gains slack time from high-priority tasks. This algorithm also balances the gap in voltage levels between high-priority and low-priority tasks. Its analysis interval limited by the longest of task periods is longer than NTA. Thus, lpWDA gains more energy saving than the previous rate-monotonic (RM) DVS schemes applying NTA. Therefore, these slack reclamation methods are applicable not only to increase energy-saving and schedulability but also to the new methods on different scheduling criteria. For example, slack time can also be applied to avoid priority inversion incurred by task synchronization.
Though power-aware real-time scheduling problems are well studied, relatively few works of them considered task synchronization problems. Most embedded real-time applications have to share the resources such as I/O devices or database and mutually exclusive access to these shared objects. Concurrent access to shared data may result in data inconsistency. Mechanisms that force tasks to execute in a certain order so that data consistency is maintained are known as synchronization protocols. If a lower priority job has access to a resource, a higher priority job requesting the resource is blocked and can miss its deadline. Therefore, real-time task synchronization is developed to achieve data consistency with as little loss in schedulability as possible. Priority ceiling protocol (PCP) [23, 24] is a synchronization protocol for shared resources to avoid deadlock and unbounded priority inversion due to wrong nesting of critical sections. In PCP, each resource is assigned a priority ceiling, which is a priority equal to the highest priority of any task which may lock the resource. PCP has the interesting and very useful property that no task can be blocked for longer than the duration of the longest critical section of any lower-priority task. The recent related work is an extension of PCP in frequency inheritance. Zang and Chanson [25] proposed a dual-speed (DS) algorithm: one is for the execution of a task when it is not blocked, and the other is adopted to execute the task in the critical section when it is blocked. Jejurikar and Gupta [26] compute two slowdown factors, which can be classified into static slowdown, computed offline based on task properties, and dynamic slowdown, computed using online task execution information. Chen and Kuo [2] proposed a DVS method using frequency locking concept which can be used to render energy-efficient to the existing real-time task synchronization protocols. However, DVS may decelerate the blocking tasks in the critical section and receive additional priority inversion which increases the difficulties of predictability of the schedule.
In this paper, we propose a blocking-aware task synchronization method, which decreases both priority inversion and energy-consumption of the processor. Graph theories have been applied in the scheduling which transforms an existing resource allocation graph (bipartite graph) to a weighted-directed graph (WDG). Our idea is based on PCP and available slack time in the schedule. We use WDG to analyze and present the available slack time, preemption points, and the lengths of priority inversions. The timing and its duration for switching processor status can be computed by traversing the WDG in which lower-priority tasks have intention to lock on some resources. The proposed method can utilize the existing work-demanded analysis methods such as lpWDA [8] and Gruian's methods [3] to squeeze additional slack time from lower priority tasks so as to further decrease priority inversion.
The remainder of this paper is organized as follows. Section 2 explains our system model. The motivations and basic idea on the task synchronization method are proposed in Section 3. Section 4 describes the proposed algorithm and its example. We present the performance evaluation in Section 5. Section 6 gives conclusions and their future work.
2. System Model
2.1. Task Model
This paper studies periodic real-time tasks that are independent during the runtime. Let 𝒯 be the set of input periodic tasks and n denotes the number of tasks. Each task
2.2. Power Model
All tasks are scheduled on a single processor which supports two modes: dormant mode and active mode. When the processor is switched to the dormant mode, the power-consumption of the processor is assumed
2.3. Resource Access Model
We assume that semaphores are used for task synchronization. All tasks are assumed to be preemptive, while the access to the nonpreemptive shared resources must be serialized. Therefore, a task can be blocked by lower priority tasks. When a task has been granted access to a shared resource, it is said to be executing in its critical section [24]. The kth critical section of task
3. Motivating Example
Suppose that we have three jobs At time At time At time At time At time At time At time At time At time
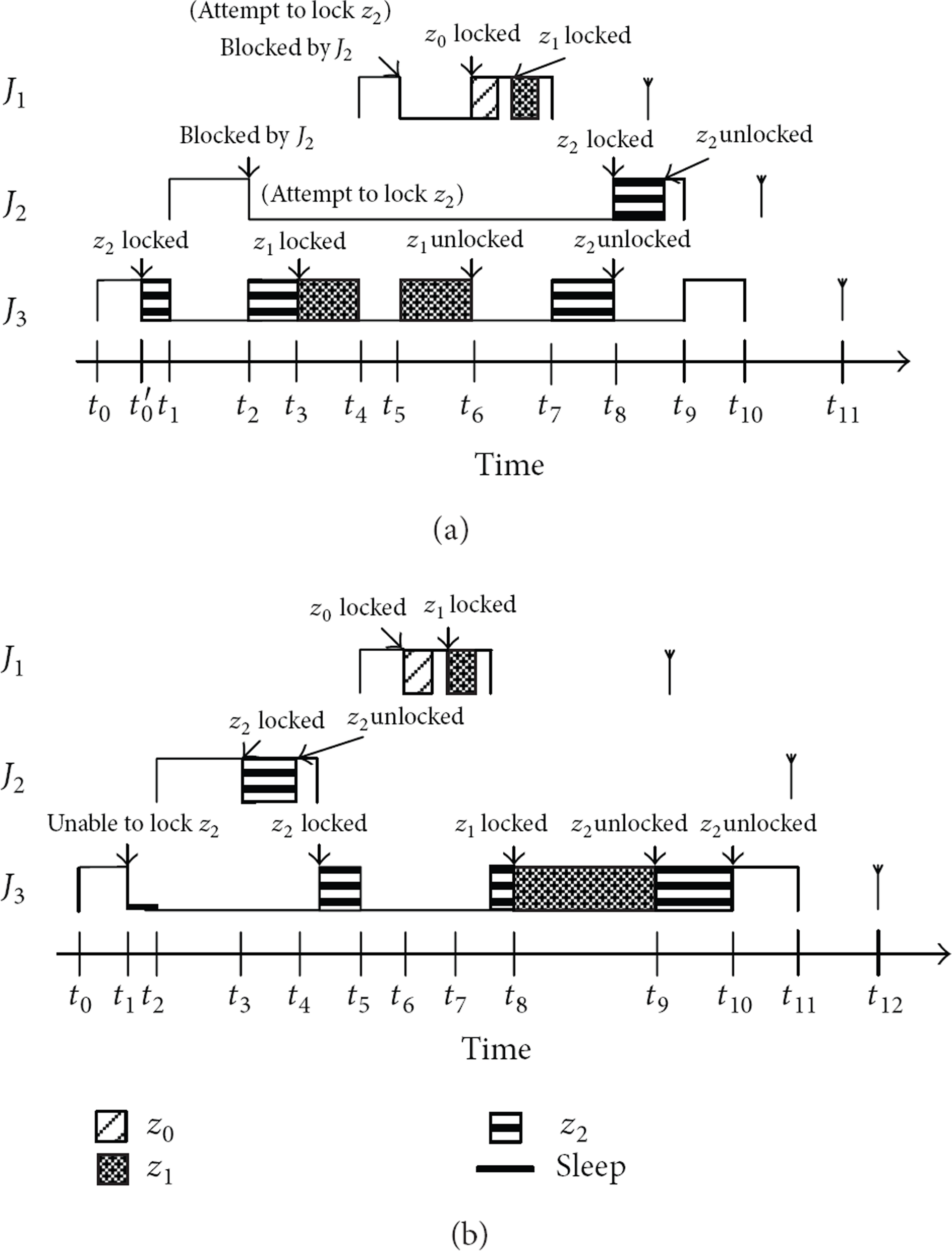
The task synchronization of (a) primitive PCP and (b) latency locking method.
The blocking intervals introduced by primitive PCP are [
This study is motivated by the significant priority inversion that is incurred from task synchronization. When the available static slack time (unused time in the WCET schedule) or dynamic slack (occurred in the early-completed task) is larger than break-even time, the lower-priority task intent to lock a semaphore can be postponed until the start time of a higher-priority task. A practical approach is to postpone the task execution by switching processor to dormant mode. During the sleeping time, system still has awareness of the arrival of other jobs and awakes processor at proper time. The example in Figure 2(b) postpones the request of lower-priority task intent to lock a semaphore. At time
Example illustrating the computation of blocking times.

4. Latency Locking PCP
In this study, PCP is extended with the concept of latency locking, referred to as LL-PCP. The idea is to perform preanalysis of possible priority inversion and available slack time in the schedule. LL-PCP derives the best timing and duration for switching processor to dormant mode and thus reduces priority inversion. To understand and control the sequence of intent to lock resources, tasks are organized as a weighted directed graph (WDG) reduced from the resource allocation bipartite graph in [28]. In the bipartite graph, each indirect edge is labeled with the time required to access the resources. Let
Step 1.
For any pair of vertices
Step 2.
For any pair of vertices
Step 3.
In WDG, for any pair of vertices with multiple arcs, eliminate the dotted arcs having the same blocking time as that of one of their solid arcs.
Different from the bipartite graph, each vertex in the WDG corresponds to a task but resource. A task
Input: a set of task T, a set of resources R.
(Offline part)
(1) Reduce bipartite graph to WDG (T, A); (2) Compute the value of I ( a (
(Online part)
(3) Identify a set of tasks priority task (4) Update the value of REW ( arc a( (5) Construct a set (6) Compute the static available slack each job in (7) Compare each value of the arcs in (8) Construct an arc set (9) Search for an arc a( maximum value of REW( (10) switch the processor to dormant mode until time
(11) Switching the processor to end of the interval;
(12) Schedule the highest priority job in the ready queue; On early-completion of a job at time t; (13) Compute dynamic slack time due to early completion;

Graph reduction from (a) bipartite graph to (b) WDG.
Definition 1 (expected sleeping interval, ESI).
In order to prevent job 

Definition 2 (reduction of priority inversion time, RPI).
The expected reduction of priority inversion time due to the processor sleeping in the 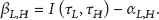
According to (1), (2), and (3), we define a reward function for each arc in WDG.
Definition 3.
A reward function for each arc in WDG is defined as

The reward for an arc referred to the reduction of priority inversion time if the processor is switched to sleep during the interval
By updating the information of arcs in WDG during runtime, we can traverse the vertices of WDG by following the current job and make decisions on switching the processor to active or dormant mode. Additionally, the values of ESI can be updated on the fly according to the dynamic slack time due to early completion of a job. Also, the arcs corresponding to the unused resources due to early completion can be removed from this job vertex.
5. Experimental Results
To evaluate the effectiveness of the proposed scheduling method, we implemented the following techniques and derived their energy consumption.
Primitive PCP: all tasks are executed at maximum speed and use PCP for accessing the shared resources [23]. P-PCP: all tasks are scheduled using procrastination technique under fixed priority [5]. DVS-PCP: all tasks are scheduled according to the RM-DVS scheduling based on the slowdown factor proposed in [26]. LL-PCP: all tasks are scheduled according to the proposed method.
We use the processor power model in [5] and consider energy overhead of shutdown required by on-chip cache. With an energy cost of 13 nJ [15] per memory write, the cost of flushing the data cache is computed as 85 uJ. On wakeup, we assume a cost of 98uJ total energy overhead. Additionally, we assume that cache energy overhead to actual charging of circuit logic requires 300 uJ, and the total cost is
In Figure 4, the comparison of the energy consumption of the techniques is as a function of the number of task, and the energy consumption of all techniques is normalized to LL-PCP. As the number of task increases, primitive PCP starts consuming more energy than other methods. When the number of tasks is greater than four, DVS-PCP starts consuming more energy due to the dominance of leakage and speed switching. The leakage is derived from frequent priority inversion due to increased resource contentions. We see that the LL-PCP results in an up to an additional 4.5% gains over DVS-PCP when the number of tasks is not less than 10.
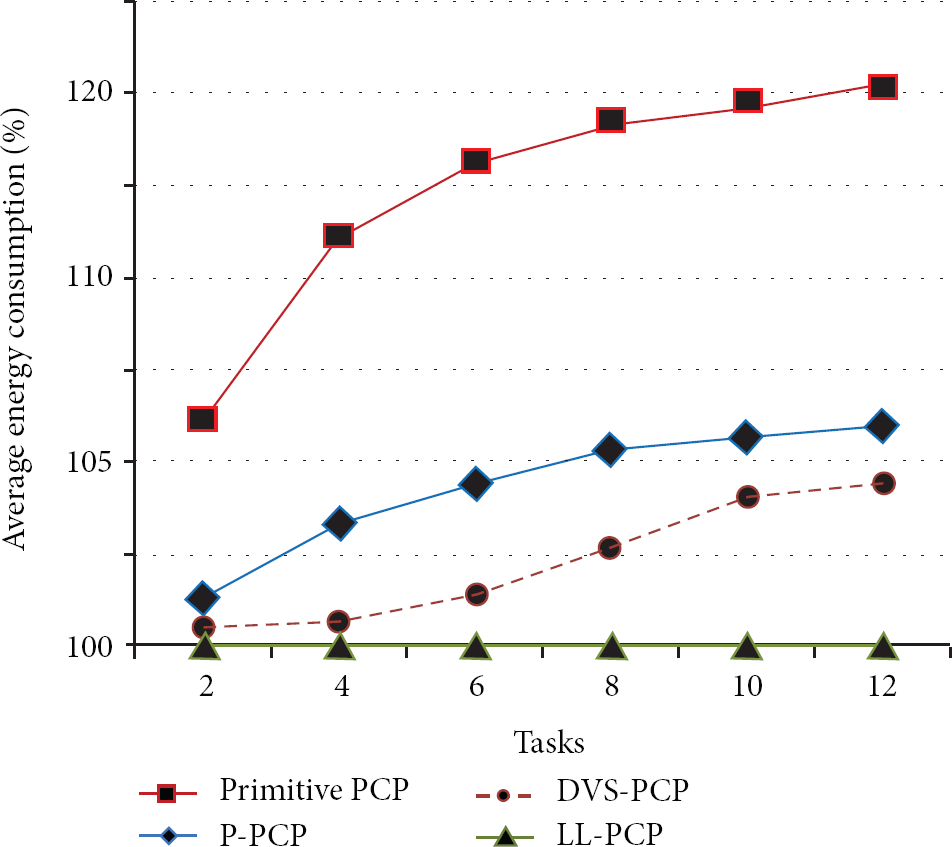
Comparison of energy consumption in the different number of tasks, utilization = 50%.
In Figure 5, the energy consumption of the techniques is as a function of the processor utilization at maximum speed. When the processor utilization increases, DVS technique starts consuming more energy. As the processor utilization is low, DVS-PCP presents significant energy savings. There are idle intervals in these techniques and could be utilized by applying dynamic reclamation methods [3, 8, 12] for more energy gains. These idle intervals can be used for processor shutdown to compare the benefits of our procrastination scheme. Both P-PCP and LL-PCP are procrastination scheme and their energy consumptions outperform that of preemptive PCP through shutdown. Additionally, P-PCP and LL-PCP are not sensitive to the change in processor utilization because they are leakage-aware methods. We see that LL-PCP leads to up to 6% energy gains over P-PCP and an average of 5% energy savings compared to DVS-PCP.

Comparison of energy consumption in the different processor utilization, 6 tasks.
Figure 6 shows the comparison of the length of priority inversion normalized to LL-PCP, as a function of the number of tasks. In consideration of task synchronization, priority inversions directly affect the feasibility of real-time scheduling because they usually postpone actual finish time of higher-priority tasks and would result in deadline misses. When the number of tasks increases, primitive PCP, P-PCP, and DVS-PCP result in increasing priority inversion longer than that of LL-PCP. The main reason is that the number of increases of nonpreemptive resources and access conflictions among the tasks would produce additional short idle periods and switching time that also hamper timely completion of the tasks. LL-PCP reduces an additional 4.8% priority inversion over DVS-PCP at 12 tasks in each task set.
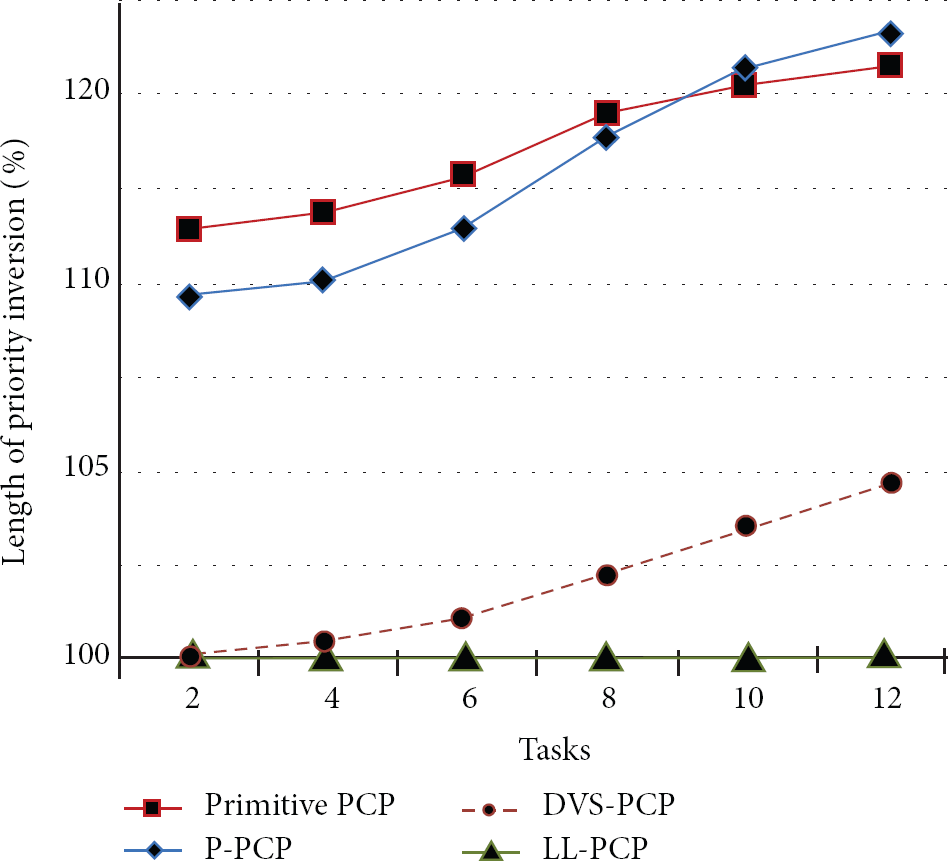
Comparison of priority inversion in the different number of tasks, utilization = 50%.
The comparison of the length of priority inversion of the techniques is shown in Figure 7, as a function of the processor utilization at maximum speed. As the processor utilization increases, preemptive PCP, P-PCP, and DVS-PCP result in less increasing priority inversion than that of LL-PCP. The reason is that, in accordance with (4), when the value of
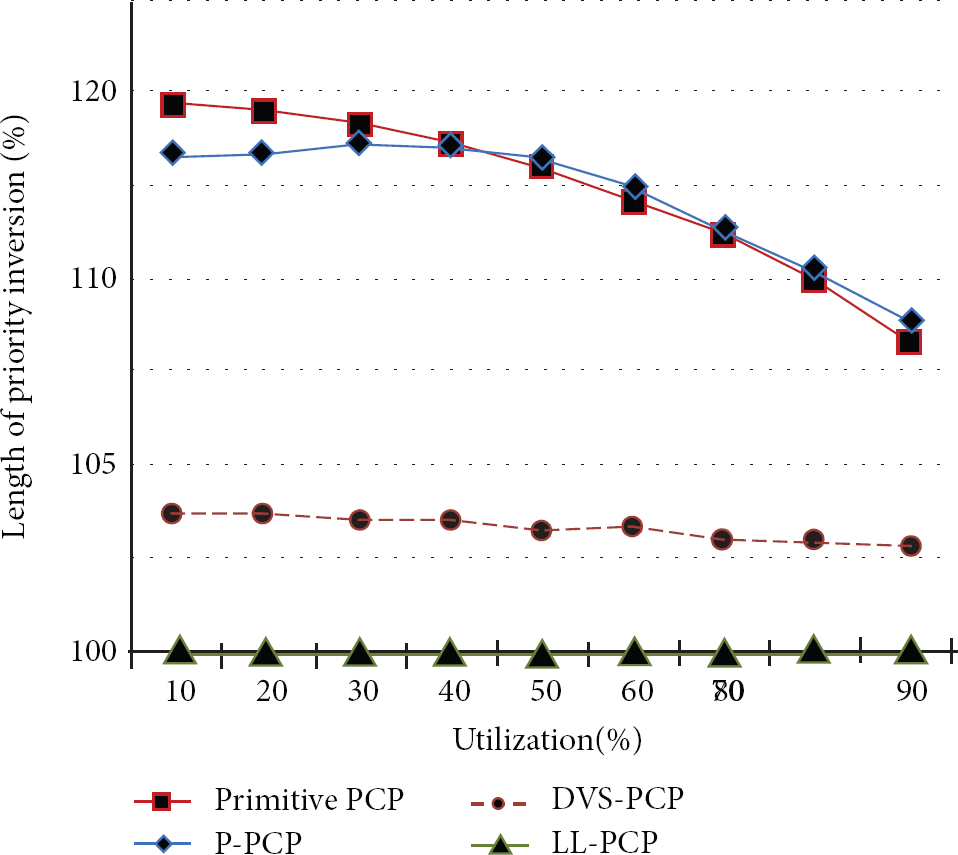
Comparison of priority inversion in the different processor utilization, 6 tasks.
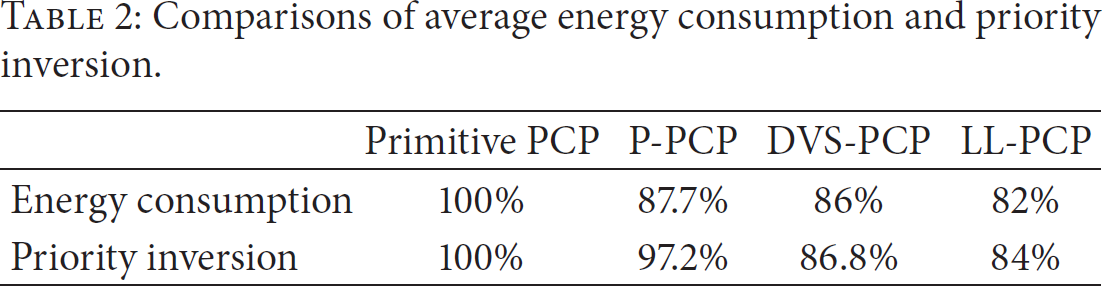
The average performance of the abovementioned methods is presented in Table 2 as the setting to the range of processor utilization and the number of tasks in each task set is [10%~90%] and 6, respectively. The proposed method still outperforms primitive PCP, P-PCP, and DVS-PCP with regard to both energy consumption and priority inversion.
Comparisons of average energy consumption and priority inversion.
The proposed method may have additional offline processing time comparing to other methods. With respect to time complexity, the proposed method takes
6. Conclusions
This paper reduces priority inversion of real-time task synchronization with speed/voltage switching overhead consideration. The objective is to minimize the priority inversion of a given task set and reduce the leakage energy, provided that the schedulability of tasks is guaranteed. By traversing the vertex in WDG, the scheduling decisions can be done efficiently during the runtime.
For further study, we shall explore the minimization issues of energy consumption on dynamic priority assignment, for example, the Earliest Deadline First Scheduling with Stack Resource Policy [28]. Future research and experiments in these areas may benefit several mobile system designs.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests with any financial organization regarding the experimental process and discussion in the paper.
Acknowledgment
The authors would like to thank the National Science Council of the Republic of China, Taiwan, for financially supporting this research under NSC 102-2221-E-025-003, NSC 102-2622-E-025-001-CC3, and NSC-101-2622-E-025-002-CC3.