
Abstract
An autonomous robot in an outdoor environment needs to recognize the surrounding environment to move to a desired location safely; that is, a map is needed to classify/perceive the terrain. This paper proposes a method that enables a robot to classify a terrain in various outdoor environments using terrain information that it recognizes without the assistance of a user; then, it creates a three-dimensional (3D) semantic map. The proposed self-supervised learning system stores data on the appearance of the ground data using image features extracted by observing the movement of humans and vehicles while the robot is stopped. It learns about the surrounding environment using a support vector machine with the stored data, which is divided into terrains where people or vehicles have moved and other regions. This makes it possible to learn which terrain an object can travel on using a self-supervised learning and image-processing methods. Then the robot can recognize the current environment and simultaneously build a 3D map using the RGB-D iterative closest point algorithm with a RGB-D sensor (Kinect). To complete the 3D semantic map, it adds semantic terrain information to the map.
1. Introduction
As seen in the Defense Advanced Research Projects Agency (DARPA) Grand Challenge, USA, robotics has progressed markedly from industrial robots that perform only given tasks to autonomous mobile robots that determine how to travel to a target. For robots to operate more intelligently, research on mobile robots needs to consider the following: (1) how to recognize certain objects, humans, or specific patterns; (2) simultaneous localization and mapping (SLAM) [1]; and (3) navigation to a specific destination. When an autonomous robot needs to reach a destination, the most important basic process before moving is for it to assess the safety of the surrounding environment and find a safe path for movement [2]. This process could incorporate global positioning system (GPS) and mapping technology, but a GPS system is not accurate enough to identify an exact position, and maps do not include all objects, especially moving objects. Therefore, a moving robot must be able to recognize the surrounding environment. One recognition method is terrain classification, in which a robot uses sensor responses to recognize the surrounding environment and determine possible safe pathways. This paper presents a method by which a robot equipped with a vision sensor can stop and classify terrain using self-supervised learning system and identify roads and sidewalks from passing vehicles and humans. Then it introduces the method used to create a three-dimensional (3D) map using a red/green/blue-depth (RGB-D) sensor (Kinect) and to add terrain information to create a 3D semantic map.
Figure 1(a) shows the environment of interest for this paper. It is an urban environment with a road for vehicles and a sidewalk for people. Figure 1(b) is the expected 3D semantic map after adding semantic information to the dense map.

(a) Example of an urban environment with a road, sidewalk, and buildings. (b) Example of a 3D semantic map (blue region: road; green region: sidewalk; red region: obstacles).
The remainder of this paper is organized as follows. We summarize related work in Section 2 and introduce the terrain-classification method and learning method for distinguishing between road and sidewalk through observations using a camera sensor in Section 3. Section 4 introduces the RGB-D iterative closest point (ICP) method, which uses a RGB-D sensor to make a 3D dense map and to develop a 3D semantic map by integrating the results of Section 3. Experimental results showing the effectiveness of the proposed method are presented in Section 5 and the conclusions and future research are presented in Section 6.
2. Related Works
2.1. Terrain Classification
During the past year, several studies have proposed methods for terrain classification. One study developed a method that involved searching for possible obstacles using a stereo camera, eliminating candidates based on texture and color clues, and then modeling terrain after obstacles had been defined [3]. Another study focused on avoiding trees in a forest; it used a stereo camera to recognize trees and classify terrain to find a safe pathway [4]. Other studies used a vibrating sensor to classify terrain that had already been traveled, based on various vibration frequencies [5].
However, these techniques only work in specific environments. Robots need to be able to learn about unknown terrain. Some studies have focused on supervised learning that requires human intervention when a robot reaches an unknown area. Due to the limitations of supervised learning, many researchers are now working on self-supervised or unsupervised techniques, in which a robot can learn about an environment on its own, without any human supervision.
One recent study developed a technique in which a robot can calculate the depth of a ground plane using a depth map generated by a stereo camera and can classify and learn about the ground and obstacles within 12 m. Based on these data, it can recognize very distant regions, as far as 30–40 m [6]. Another study developed an unsupervised learning method that deletes incorrect detections about a wide variety of terrain types (e.g., trees, rocks, tall grass, bushes, and logs) while the robot navigates and collects data [7]. Yet another study involved self-supervised classification using two classifiers: an offline classifier that used vibration frequencies to provide the other classifier, an online and visual classifier, with labels for various observed terrains. This allowed the visual classifier to learn about, and recognize, new environments [8].
However, some of these methods require more than one sensor; some use stereo cameras or vibrating sensors with monocular cameras, and most assume either that the robot is facing a flat plane through which it can navigate or that the robot will learn about the terrain after it navigates through it.
2.2. 3D Map Building
The construction of 3D maps using various sensors has been studied, including range scanners [9], stereo cameras [10], and single cameras. The biggest problem in constructing a 3D map is the alignment of captured images. To process 3D laser data, the ICP algorithm is widely used [9]. This algorithm finds a rigid transformation of the optimal distance between a point on the frame and each other point on the frame repeatedly. A passive stereo image system can extract depth data for features through the paired images. The feature points may be combined via optimization similar to the iterative process of the first ICP. Then, additional algorithms such as the random sample consensus (RANSAC) algorithm can be used to solve the problem of consistency [10].
Recent research on creating 3D maps has obtained depth information for each pixel using a sensor that simultaneously extracts a color depth image and a general video, such as by combining Kinect with a time-of-flight (TOF) camera [11]. Kim et al. [12] built a 3D map using a fixed TOF camera that had a frame unrelated to the order of time. In contrast, Henry et al. [11] proposed a 3D map-building method that used a freely moving RGB-D sensor and information on time, shape, and appearance simultaneously.
3. Self-Supervised Terrain Classification
The proposed method is based on a self-supervised framework. The robot observes moving objects and determines their movement along roads and sidewalks. From these data it extracts image data (e.g., patch) about the terrain and classifies it as one of three classes (road, sidewalk, or background). This framework consists of three parts: detection and tracking of moving objects, recognition of paths taken by moving objects, and learning the terrain patches that were extracted from the paths taken by moving objects and classifying the environment.
The proposed method has two classifiers. One is for classifying moving objects; this is offline and supervised learning. The other is for classifying terrain; this is self-supervised learning, and it also learns image patches, based on labels generated by the object classifier. Both classifiers are Support Vector Machines (SVM) as proposed by Vapnik [13] and both use only visual features.
3.1. Detection and Tracking of Moving Objects
For this study, we assumed that only humans and vehicles move in the outdoor environment. Thus, moving objects are defined in two classes: human and vehicle. Background subtraction is used to detect moving objects; this involves a mixture of adaptive Gaussians [14]. The system tracks objects based on their size and location. Figure 2 shows the results of detection, classification, and tracking of moving objects.

Detection, classification, and tracking of moving objects ((a) the result of background subtraction, (b) the result of object classification (blue square: human, green: vehicle) and tracking based on size and location).
3.2. Object Classification
To identify whether a detected object is human or vehicle, the SVM selects an object classifier. Data about the object's edge are used for a feature vector. This classifier also provides information about what class of terrain is involved.
(
1) Classifier. The first SVM in this system classifies objects as either human or vehicle. This binary classification can be expressed as (1) where the classification function is


(
2) Features. The feature vector for the object classifier is a global edge histogram of the object's region [19, 20]; this is shown in (3) and also consists of responses from four orientations and other data:

3.3. Data Association and Path Extraction
To extract human and vehicle movement paths (see Figure 3), the system saves data about objects


Path extraction about moving objects and lines shows its path (blue: human, green: vehicles).
Here, K is the number of total objects that are detected as moving object; our system defines the bottom-left of the image as zero in the image coordinates. Algorithm 1 shows the entire process of data collection and association about a moving object.
(1) Observe the object that is moving ( (2) Confirm whether the presently detected object every object (2a) If the object update data of (2b) If the object Thus, the total number of detection objects K increases to (3) Check whether K is a multiple of β. (3a) If it is, do path extraction. (3b) If it is not, keep observing until K becomes the next multiples of
Algorithm 1 (
We can use data about moving objects
Sidewalk map: A map that includes the total paths of human movement Road map: A map that includes the total paths of vehicle movement Input: All detect object Goal: Find all paths on which humans and vehicles move (Sidewalk: S, Road: R) (0) Initialize S, R, Sidewalk map and Road map (1) for (2) if (3) (4) for (5) (6) end for (7) if (8) for (9) Draw a line from (10) end for (11) else (12) for (13) Draw a line from (14) end for (15) else (16) (17) end for (18) for all pixels of Sidewalk and Road map do (19) if Sidewalk (20) if Road (21) end for
In Algorithm 2, lines (2), (3), (15), and (16) show how observed objects are defined as useful or not, based on the assumption that the object is observed over a certain number of iterative frames
Additionally, we use maps, which are one-channel image spaces, to save object's movements and conduct random sampling for patches based on path data generated from maps. If we used raw position data instead of path data, patch sampling would be very dependent on the object's location, rather than random, because objects appear at similar locations in an image when it is located over the camera's focal length. We can solve this problem by drawing lines onto maps and using these to generate path data. The elements of both path data should be more than
3.4. Terrain Data Extraction
Terrain data about sidewalks and roads are randomly extracted from each path S and R.
Then to extract nonpathway regions (cf., in this study, these regions were defined as backgrounds) not only means that
And eth cluster of backgrounds candidates is selected as backgrounds data; that is,
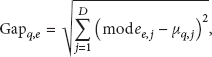

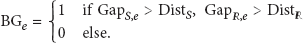
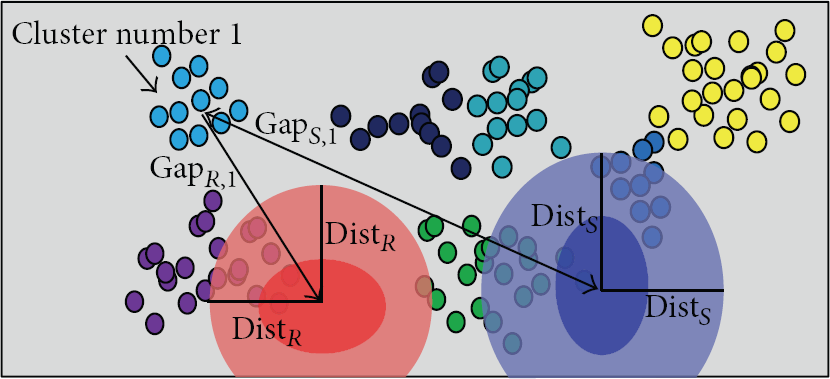
Example of 2D features clustering, and comparisons of clusters with sidewalks and roads data. Deep blue: a distribution of the sidewalk data, deep red: a distribution of the road data, small dots: candidates of the background; same color represents same cluster.
In this study, we assumed that distributions of extracted sidewalks and roads data were the Gaussian distributions. Thus, n in (6) is a multiple of the standard deviation that specifies the width of the interval (i.e.,
Figure 4 shows an example of 2D features clustering and notations.
The size of terrain data, that is, patch size, is set at
Figure 5 shows experiments about backgrounds candidates clustering in which clusters were selected as background or not.

(a) The result of clustering (small dots: candidates of the background; same color represents same cluster), (b) the result of terrain data extraction (red dots: background, blue dots: sidewalk, green dots: road, the others: excluded clusters of candidates from background class).
3.5. Terrain Classification
The terrain classifier learns terrain data generated using observed paths as a feature vector (see (8)) and determines where a robot can move within the surrounding environment as a self-supervised learning method. For a case with different numbers of training data, we can weigh each terrain class according to the number of data in its own class compared with the total number of data in all classes. The use of features and classifiers to classify image data into class labels has been popular in recent years [22].
( 1) Classifier. We defined terrain using three classes (sidewalk, road, and background) and used a multiclass SVM for terrain classification.
SVM systems were initially designed for binary classification, but two common methods allow SVM systems to classify more than two classes: one method involves combining numerous binary SVM systems. The other involves approaching a problem as an optimization problem and considers all data simultaneously.
We selected the former approach, specifically the one-against-one method. It constructs
(
2) Features. We used two visual features, color and texture, for the terrain classifier. We used RGB and Lab color spaces for color features; these have been proven as good features for scene classification [24] and we used a Global Edge Histogram for texture features. Equation (8) presents the visual feature vector used for the terrain classifier:

4. 3D Semantic Map Building
This paper constructs a 3D semantic map that shows regions where people or vehicles can move. To build the 3D map, it is necessary to determine the position of the sensor at every time point. It is possible to estimate the location with the sensor or to do so more precisely using multiple sensors. Normal position estimation can use the motion model of the robot and it is also possible to make use of GPS or an image process. We build the 3D map using the position of the robot estimated by matching the point cloud and features from the image and odometry data.
4.1. Ground Plane Estimation with Vertical Disparity Map
Using a learning environment based on the trajectories of passing vehicles and humans, it is still possible to classify some terrains incorrectly because their texture and color differ completely. For example, as shown in Figure 6(a), the sidewalk might be recognized as an obstacle because there are so many leaves with different colors and textures on it. However, we can assume that a sidewalk or road is in the same plane after obtaining the ground plane. Then, we solve this drawback by depending on the class that forms the principal of the plane.

(a) A sidewalk with complex texture, such as fallen leaves. (b) The road plan estimated using a V-disparity map.
To estimate the plane, V-disparity is widely used to detect obstacles and the plane [25]. The horizontal axis of the V-disparity map indicates the depth, and the vertical axis is made by accumulating the pixels with the same depth along the horizontal axis of the depth data. A plane in the 3D world actually appears in the form of a line in the V-disparity map. Therefore, the extraction of a strong line from the V-disparity map represents the ground plane. Extraction of the ground plane is shown in Figure 6(b). The ground plane is determined using the voting method “Max Wins” to obtain the most votes from parts of the terrain class for planes. A value exceeding the plane in the column direction in a V-disparity map is an obstacle [26].
4.2. Map Building Using RGBD Iterative Closest Point
The ICP algorithm searches for the rigid transformation that minimizes the distance between the source point cloud,
In this paper, we apply the RGB-D ICP algorithm, which has the advantage of matching RGB-D data in two ways. The algorithm is described in Algorithm 3. It takes input source
(0) (1) (2) ( (3) (4) (5) (6) (7)
Lines (3) to (6) are the main loop of the ICP algorithm. The association
Figure 7 shows a 3D map created using the RGB-D ICP algorithm in an outdoor environment. This map will become a 3D semantic map when the results of terrain classification are added.

An example of a 3D map using the RGB-D ICP algorithm.
5. Experiments
5.1. Experimental Environment
We conducted experiments at four locations at Seongdong-gu, Seoul, Republic of Korea, and captured test datasets using a camera set at
The experiments involved a robot observing moving objects and learning about the surrounding terrain based on the paths of moving objects; the robot was motionless with the assumption that it was in an unknown location.
To extract a reasonable number of patches, test was conducted to classify terrain with various numbers of training data. Figure 8 presents the results.

Classification performance with various numbers of training data in whole dataset.
We evaluated the proposed method by comparing its results with those of supervised learning, which ensured correct labels using ground-true images. Both methods randomly extracted training data about each terrain (sidewalk: 200, road: 200, background: 400) based on Figure 9. To train the object classifier, which involves offline learning, about 1968 units of training data were obtained from NICTA [27] and UIUC [28]. Each class of object (i.e., humans and vehicles) had the same amount of data; the RBF kernel parameter γ, which was used for training, was

Experimental results. Columns present the results and processes of experiments in the whole dataset. (a) Experimental environments, (b) extraction of training patches based on paths after observing moving objects, (c) ground-true images for terrain classification (red: background, green: road, blue: sidewalk), (d) supervised terrain classifications based on ground-true image, (e) classification results of the proposed method.
5.2. Results of Self-Supervised Terrain Classification
In this study, self-supervised classification was compared to supervised classification, and classification error rates for both methods were compared with ground-true images. Table 1 lists the terrain classification error rates as mean and standard deviation in four datasets. Tests were conducted 10 times for extraction patches, training, and classification for each dataset.
Comparison of self-supervised classification and the supervised learning method.

Table 1 shows that the results of the proposed method were approximately 3–9% different to those of supervised classification. The biggest difference between supervised and proposed classification result was 11% in dataset 2. As shown in Figure 9, the most wrong classification appeared in boundaries between roads and sidewalks, because any human or vehicles did not pass through these regions and also those had different color and textures compared to sidewalk and road. This fact could be found in datasets 3, 4, and 1 which turned out the second, third, and fourth worse classification results. To sum up, the performance of the proposed method might be almost the same as the supervised method which was conducted by human interventions who expects the problem that critically happened at dataset 2, such as the boundary regions.
Figure 9 presents the experimental environments, extraction of patches for terrain classes based on the paths of moving objects, ground-true images of terrain, supervised terrain classification, and the results of the proposed method per dataset.
5.3. Results of 3D Map Building with Terrain Classification
After self-supervised learning by observing objects moving in the unknown environment, the robot moves around to build a 3D map with the RGB-D sensor. The result is shown in Figure 10. Finally, Figure 11 shows a 3D semantic map that includes the result of the terrain classification. Compared to Figure 10, the map was created by classifying terrain regions as road, sidewalk, and obstacles that the robot cannot move through, such as trees and buildings. However, the proposed terrain classification has a disadvantage in that the region between the sidewalk and road is classified as an obstacle that the robot cannot pass through.

(a) 3D map of the university, (b) RGB images of the same scene.

(a) The 3D semantic map. (b) Magnification of part of the 3D semantic map (red: obstacles; blue: road; green: sidewalk).
6. Conclusions
We proposed a self-supervised terrain classification framework in which a robot observes moving objects and learns about its environment based on the paths of the moving objects captured using a monocular camera. The results were similar (ca. 3–9% worse) to those of supervised terrain classification methods, which is sufficient for an autonomous robot to recognize its environment. In addition, we built a 3D dense map with a RGB-D sensor using the ICP algorithm. Finally, the 3D semantic map was created by adding the results of the terrain classification to the 3D map.
In future research, we will focus on better ways to extract background data, using a vanishing point or depth data and a total framework for navigation. We will also conduct tests in various environments, such as indoors and unstructured outdoor environments.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This research was supported by the 2014 Scientific Promotion Program funded by Jeju National University.