
Abstract
The underwater wireless sensor network (UWSN) is a state-of-the-art approach to exploring potential information and resources in the aquatic environment. However, underwater communication has unique features, such as long propagation delay, low bandwidth capacity, high bit error rates, and mobility, memory, and battery limitations. In this paper, we propose a round-based clustering scheme that can overcome the UWSN's confines mainly by resolving the transmission of redundant data in the network—one of the significant factors that reduces network lifetime. Our proposed scheme works in rounds, with each round consisting of four main phases: initialization, cluster-head selection, clustering, and data aggregation. Suitable mechanisms are chosen to apply in each round. By dealing with most of the redundant data, our proposed clustering scheme better reduces network consumption, thus increasing network throughput. Moreover, the minimum percentage of received data at the sink/base station is guaranteed.
1. Introduction
A wireless sensor network (WSN) is composed of a large number of tiny sensor devices equipped with a small battery, a tiny microprocessor, a radio transceiver, and a set of transducers [1, 2]. These tiny sensor devices continuously sense the environment, detect events, process data, and communicate with each other. A wide range of applications have been developed using WSNs, such as environment monitoring (e.g., habitats in forests, moisture levels in agriculture land, and noise levels in urban areas), traffic and vehicular monitoring, health care systems, and target tracking for the military [1–3].
In the last decade, the aquatic environment has motivated intensive research because of its potential information and resources. Interested researchers aim to monitor underwater environments for various applications, such as oceanographic data collection, disaster prevention, undersea exploration, and surveillance applications [4–6]. The underwater wireless sensor network (UWSN) is a state-of-the-art approach to reach those goals. However, UWSNs face many challenges due to the communication differences between UWSNs and terrestrial WSNs. For example, one major drawback of an acoustic wave is that the speed of the sound is far slower (approximately 1500 m/s) than that of the radio wave (3 × 108 m/s), and thus the difference in their propagation speed is huge. Furthermore, sensor nodes in UWSNs move with the water's current; the low bandwidth capacity in kilohertz results in high bit error rates; there are limitations on, and difficulty with, recharging batteries and so on [6–9]. Hence, designing a UWSN that saves energy consumption and prolongs the network's lifetime has become a major concern.
The cluster structure makes a network look smaller and more stable from the perspective of each mobile terminal [10]. Moreover, the cluster structure is a promising method to reduce network's energy consumption, which has recently received much attention when deploying a network in an aquatic environment. The cluster-based concept divides the network into groups of nodes (or clusters) and defines a mechanism by which all clusters connect to each other [8, 11–20]. There are various ways of doing research on network clustering, such as how to optimize cluster size [13], how to select a cluster-head [11, 14, 15], how to communicate among nodes and among clusters [11, 13, 16, 17], and how to aggregate data in the cluster [18–20].
Data aggregation is the technique under which the WSN attempts to collect the sensed data from the sensors and transmit them to the base station (BS) or the sink. The main role of data aggregation is to not only eliminate redundant data received from sensor nodes, but also reduce the number of transmissions to the BS/sink [12, 18]. Aggregation of data using similarity functions can minimize data redundancy and reduce the size of data packets to be sent to the BS/sink [18]. This subsequently reduces traffic load and prolongs network lifetime.
In this paper, we consider all layers forming the network. Also, we propose an idea for a clustering scheme in which the cluster-head can be reselected and clusters can be reconstructed due to the changes in network conditions like energy consumption, network movement, and so forth. Reclustering not only retains the best cluster structure, but also prolongs the network lifetime. A combination of clustering and data aggregation with a similarity function is the best way to reduce overall network consumption, increase network throughput, and achieve data accuracy. Through simulation results, we show that our proposed round-based clustering scheme can achieve better throughput and energy consumption than clustering without data aggregation. Also, a minimum percentage of received data at the BS/sink is guaranteed.
The remainder of the paper is structured as follows. In Section 2, we review some related research about network clustering, cluster-head selection methods, cluster communications, and data aggregation in cluster-based networks. In Section 3, we describe in detail the proposed clustering scheme. Our simulations results are shown in Section 4. Finally, Section 5 concludes our paper and highlights the future work.
2. Related Research
For a cluster-head selection method, one study proposed a dependable clustering protocol to provide a cluster hierarchy survivable against cluster-head failure [11]. In that paper, the clustering protocol tries to select a primary cluster-head and a backup cluster-head for each cluster member during clustering. The authors believe that the cluster member can quickly switch over to the backup cluster-head when its primary cluster-head is not working for some reason. Another study proposed an energy-efficient cluster-head selection scheme by considering the nodes’ energy and distributed positions [14]. The proposed method is based on analysis of energy consumption under the LEACH protocol in the underwater channel. The main idea of this method is to select cluster-heads from nodes with more energy and that are more evenly distributed. Their simulation results illustrated that network lifetime is prolonged by using their proposed cluster-head selection scheme. However, the sensor network is assumed to be a static network, which rarely happens in underwater environments.
Data aggregation in UWSNs has also received a lot of attention from researchers. One objective is to propose a data aggregation algorithm that achieves energy savings, increases network lifetime, and reduces the amount of bandwidth [12]. In [12], the authors considered forming clusters, electing cluster-heads, and applying an averaging technique for data aggregation. Also, they made a comparison between networks with aggregation and without aggregation. In another study, the authors suggested using similarity functions for data aggregation in cluster-based UWSNs [18]. In that research, the similarity functions are applied to the aggregator nodes/cluster-head for data comparison. Those aggregator nodes/cluster-heads are responsible for gathering data, comparing similarities between the sets of sensed data from neighbor nodes, and then transmitting the result to the BS/sink nodes. They proved through simulation results that similarity functions, such as Euclidean distance and cosine distance, can help to construct an efficient underwater network by reducing packet size and minimizing data redundancy. In that paper, however, the authors assumed the network is already clustered, and they focused only on applying the similarity functions to the cluster-heads or aggregators.
Another study mainly worked on communications in an ad hoc underwater acoustic network [13]. The proposed network was grouped into multiclusters and justified the use of time-division multiple access (TDMA) and code-division multiple access (CDMA) within it. According to that proposed scheme, in-cluster communication is achieved through TDMA and intercluster communication is done with CDMA. Network performance is examined through measures of connectivity, successful transmission rate, average delay, and energy consumption. Simulation analysis was used to obtain optimal cluster size and transmission power for a network with a given density of vehicles [13].
3. A Proposed Round-Based Clustering Scheme
A cluster-based network is a network partitioned into nonoverlapping clusters. Each cluster consists of one cluster-head and several cluster members. Cluster members eventually sense the surrounding environment and then transmit information to their cluster-head. The main role of the cluster-head is to collect sensed data from the member nodes, aggregate the collected data, and transmit them to the BS/sink.
This section provides the complete description of our proposed clustering scheme, which works in rounds. Each round consists of four phases, as shown in Figure 1: the initialization phase, the cluster-head selection phase, the clustering phase, and the data aggregation phase. In the initialization phase, the BS/sink nodes and sensor nodes are deployed to the area, and the sink nodes start to set up the time for the round. Cluster-heads are selected in the second phase. During this phase, information about residual energy, position, and distance to the BS/sink node is gathered. In the clustering phase, clusters are formed for each cluster-head and its members. Then, in the last phase, data is aggregated and transmitted to the BS/sink by the cluster-heads. Each phase is briefly discussed in Figure 1.

Four phases of proposed clustering scheme.
Notation section at the end of the paper summarizes the notations that we use throughout this paper.
3.1. Initialization Phase
In this phase, the BS/sink nodes start a new round by setting up a round time (

A request message containing a timestamp,
3.2. Cluster-Head Selection Phase
The cluster-head is selected through a process of self-selection by the sensor nodes. Sensor nodes that receive a request message from the sink nodes will take the maximum transmission range,
Unlike LEACH that select a cluster-head from nodes with more energy and that are more evenly distributed, in our cluster-head selection mechanism, a sensor node must have the highest residual energy along with the shortest distance to its sink to become a cluster-head, as shown in (2). These conditions make sure that cluster-heads are the node with maximum transmission power to communicate to its cluster members as well as help to increase the data accuracy that transmit to the BS/sink nodes

Algorithm 1 explains how our cluster-head selection phase works.
A node receive a msg { If the receive msg is Hello msg { Create a priority table to store Hello msg's information Compare among nodes’ information If a node has the most energy and is closest to the sink node { Node elects itself to become CH by broadcasting Invite msg to others } Else { Wait for Invite msg from CH node } } }
Algorithm 1
One disadvantage of the broadcasting technique is collisions caused by the transmission of so many messages in the network. Hence, we apply a random timer to each sensor node to delay broadcasting. This means that each sensor node starts a random timer every time it wants to broadcast a message and then broadcasts the message when that timer expires. The reservation-based MACA (R-MACA) protocols [21] are also applied to the medium access control (MAC) layer in order to prevent data collisions through short term scheduling in UWSNs. The collision avoidance feature of the R-MACA protocol replies mostly on time measurements that find the optimal duration for network communications. There were three measured time values such as waiting time, reservation time, and delay time. Each time measurement has its own function to help the protocol in achieving the better performance; for example, the delay time was proposed for avoiding data collision. In order to start a new data transmission, any sender node must wait for a delay time (
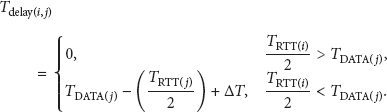
3.3. Clustering Phase
Clustering is a process of grouping sensor nodes. The clustering process is initiated by sending an invitation message from a cluster-head. The cluster-head sends the invitation message to all of its neighbor nodes within the maximum transmission range,

The time needed for a node to join a cluster is also included in the reply-to-join message. The clustering time is updated in each cluster-head. It is the total time that member nodes took to join a cluster, as updated by

3.4. Data Aggregation Phase
One way of addressing the energy savings is by reducing the number of transmissions when the network is monitoring the aquatic environment. Also, transmitting redundant information needs to be taken into consideration, because sensor nodes monitor the environment most of the time. To address those issues, the cluster-heads invoke a data aggregation mechanism to aggregate and transmit data to their sink node. In this phase, we implement a method of data aggregation with a similarity function (Euclidean distance) in the cluster-heads [18]. A cluster-head gathers sensed data from its cluster members and stores them as a vector (a set of data) in order of node identification. When a new vector is collected, the two vectors are compared by using a similarity function. If the two vectors are deemed to be similar, the cluster-head only sends one data set instead of both to the BS/sink. The idea has been proven to reduce data redundancy in the network.
The behavior of the cluster-head is illustrated in Algorithm 2.
Repeat A cluster-head gathers sensed data from cluster members and stores them as vector v (a set of data) Check if a new vector u is formed { Apply Euclidean distance to compare the two vectors If the vectors are very similar Send only v to the sink node Else Send both ( } Until a round finishes
Algorithm 2
3.5. Network Communications
Since all clusters are formed within a round, communication types such as intracluster communication (cluster-head to cluster members; cluster member to cluster member within a cluster) and intercluster communication (cluster-head to sink, cluster member to cluster members from two different clusters) are set up. We apply TDMA for intracluster communication and CDMA for intercluster communication. Communication between cluster-head and the BS/sink is achieved through a cooperative medium access control (MAC) scheduling scheme [21] for reliable data transmission.
As soon as an old round finishes and a new round starts, cluster-heads are reselected and clusters are reconstructed based on the state of the network, such as residual energy of all sensor nodes and network movement. There is also communication amongst nodes, so clusters are set up again due to the new construction of the network.
4. Simulation Results and Analysis
The performance of the proposed scheme was evaluated using simulation. We ran our simulations on QualNet5 simulator. Dimensions of the scenario are 1500 m × 1500 m. The scenario consists of 50 sensor nodes and 4 sink nodes deployed 200 m below sea level. Sensor nodes are deployed randomly, whereas the sink nodes are equidistant to one another. In order to replicate a shallow underwater environment, channel frequency and propagation speed were set at 35 KHz and 1500 m/s, respectively. The energy consumption parameters were set according to the UWM100 LinkQuest Underwater Acoustic Modem [22]. Communications between cluster-heads and BS/sink used a cooperative MAC scheduling scheme [21]—a handshake approach proven to provide reliable data transmission. In addition, intracluster communications and intercluster communications were set with TDMA and CDMA, respectively. All sensor nodes operated with a data rate in the LinkQuest UWM100 equal to 7 Kbps. Transmission power of the sink nodes was 30 dBm (around 544 m) while the transmission range of common sensor nodes depended on a random value between 100 m and 200 m. All the sensor nodes use the same AODV routing protocol. The time for each simulation run was 30 minutes.
4.1. Simulation Results and Analysis
Throughput of the network is shown in Figure 2, where the red line indicates the throughput per node with data aggregation, and the blue line indicates the results without data aggregation. The help of phases in our clustering scheme and the use of a random timer generated in each sensor node eliminate message collisions. Hence, the throughput per node with data aggregation is higher than with no data aggregation. However, at 2.4 bps of offered load, throughput with nonaggregation is better than that with aggregation. The first reason for the bad result can be explained in that we used a random timer to delay broadcasting for each sensor node. However, collisions will happen if the random values of the nodes are similar. Another reason is that collisions occurred at the CH/aggregator because it received too many messages from neighboring nodes.

Throughput of network (bits/s).
Figure 3 shows the energy consumed in the network, both with and without data aggregation. The red line indicates the energy consumption of the overall network with data aggregation, and the blue line indicates the results without data aggregation. In this proposed scheme, energy is saved at each phase of the clustering scheme. For example, only sink nodes are allowed to function during the initial phase. Also, data aggregation with a similarity function can save energy by reducing the number of transmissions from cluster-heads to the BS/sink. Hence, a clustered network with data aggregation consumes less energy than a clustered network without data aggregation.

Energy consumption of network (mJ).
The graph in Figure 4 shows the percentage of data received at the BS/sink. In this test, we established two scenarios: the first consists of 50 sensor nodes and 4 BS/sink nodes (indicated by the green line) and the second consists of 30 sensor nodes and 4 BS/sink nodes (indicated by the red line). Generally, we can see that the percentage of data sent to the BS/sink nodes in the first scenario is better than the second. The main reason is that the dense network may generate more data collisions than the dispersed network. The number of rounds does not have a significant effect on the results because the nodes are evenly distributed around cluster-heads. Except for a situation of around 90 rounds, the result of the first scenario is worse than the second. When many rounds are generated in a sparse network, the time given for one round to finish is divided into smaller segments. So the data cannot be transmitted, or it will be dropped during transmission, causing a loss of information. In this case, the data-received ratio of the second scenario is higher. In a dense network, sensor nodes may be unevenly distributed in the clusters. In the best case, a cluster with a small number of member nodes will deliver most of the data to the BS/sink. Also, a cluster that has more member nodes, in some situations, will successfully deliver a lot of data to the BS/sink. However, in most cases, the results from a sparse network are better than those from a dense network. The major purpose of this experiment is to prove the data guaranty at the BS/sink of our round-based clustering scheme

Percentage of data received at BS/sink.
5. Conclusion and Future Works
In this paper, we have proposed a promised clustering scheme to deal with data redundancy. The proposed scheme is made up of rounds, with each round consisting of four main phases. The cluster-heads are chosen through a self-selection process based on residual energy and distance to the BS/sink. Clusters are formed by the member nodes themselves. Data aggregation with Euclidean distance is applied in the cluster-heads in order to reduce data redundancy. Intracluster and intercluster communications are set up each time the new clusters are formed. We demonstrated with simulation results that our proposed scheme achieves high-throughput network and low energy consumption. Also, a minimum percentage of received data at the BS/sink is guaranteed.
In future work, we intend to improve on the accuracy of the data, the network size, and the network deployments in which our proposed clustering scheme can prove advantageous. Besides, we also will work more deeply on node mobility, number of clusters, and size of each cluster in order to decide what kind of cluster (big, medium, or small) should be performed to achieve the best performance.
Footnotes
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.