
Abstract
We present a detailed study on the RSS-based location techniques in wireless sensor networks (WSN). There are two aspects in this paper. On the one hand, the accurate RSSI received from nodes is the premise of accurate location. Firstly, the distribution trend of RSSI is analyzed in this experiment and determined the loss model of signal propagation by processing experimental data. Secondly, in order to determine the distance between receiving nodes and sending nodes, Gaussian fitting is used to process specific RSSI at different distance. Moreover, the piecewise linear interpolation is introduced to calculate the distance of any RSSI. On the other hand, firstly, the RSSI vector similarity degree (R-VSD) is used to choose anchor nodes. Secondly, we designed a new localization algorithm which is based on the quadrilateral location unit by using more accurate RSSI and range. Particularly, there are two localization mechanisms in our study. In addition, the generalized inverse is introduced to solve the coordinates of nodes. At last, location error of the new algorithm is about 17.6% by simulation experiment.
1. Introduction
Localization is certainly needed for robots to efficiently carry out given tasks such as cleaning, serving, and guiding. It is a challenging research topic in mobile robot which has received much attention [1]. Moving around without location for robots is the same as walking with closed eyes for people [2]. They do not know where they are and which direction they should move to. Under this background, reliable and efficient localization is still a critical issue for mobile robots. Research on localizing mobile robots has come to prominence in wireless sensor network over the last years [3].
To a large extent, WSN has changed the current situation that people get information by the traditional way, such as their sense of touch, sight, and smell. WSN has become a new formula of technology to get data. Wherever in the field of national security or national economy building, WSN has been applied widely [4]. In a variety of applications in WSN, only if the location information of the node itself is combined with the information which is captured and collected from sensor nodes “the location of the incident” can be illustrated accurately and the region of target monitoring is reflected truly. Obviously, the location information of the node is the premise of sensor nodes that are perceived and collected data. It is imprecise and lacking practical significance that there is only perception data of nodes and there is not the perception of location information which signed the source of perception data [5]. Therefore, it is important to locate the node in WSN, so the location technology also is becoming an essential function and a critical supporting technology in WSN [6]. In terms of the collection of network data and event monitoring, the location information of nodes is important. In the field of remote sensing, it is significant to track and monitor. It is contributed to compare composited route and optimize communication task and improve composited routing table [7]. Some domestic scholars also research on deep discussions of localization in WSN [8, 9]. Unknown nodes and anchor nodes are two important parts of location system. In addition, in terms of choosing anchor nodes, some researchers pay attention to research on RSSI-similarity degree [10].
There are two existing formulas of methods of node localization in WSN by measuring distance or angle information between nodes in the location process and not measuring information: the method is based on range location (Range-based) and without range location (Range-free) [11]; the information of range or angle between communication nodes is obtained; it is the premise of the former method to locate nodes; the latter method is not needed to measure range information between nodes directly; it is estimated coordinates of nodes just by getting information of communication hops between nodes or network connectivity. There are common ranging methods as follows: TOA ranging method [9, 11], TDOA ranging method [11], AOA ranging [12], and RSSI ranging method [13].
Range is the premise of location; precise range is the assurance of accurate location. Only a certain number of reference nodes (anchor nodes) are combined with effective localization algorithm if they ensured feasible location task, lots of equipment is included in the process; they are arranged before and are able to communicate. At the same time, in the place of receiving nodes, information of signal strength and angle between nodes is needed to measure and convert it into distance information. With the help of geometric or mathematical relationships we can carry out the location task after achieving information of distance or orientation between nodes. In typical location algorithms, the method of Range-based mainly included trilateral location and triangulation location and maximum likelihood location; Range-free mainly included centroid location, convex programming location, and DV-Hop location method.
The principle of Hop count [12] ranging method is based on hop counts between anchor nodes and unknown node and the product of distance of mean hop in the network to determine their distance. Information of hop count is obtained as follows: anchor nodes send a packet which included lots of information such as its location information to the network, if receiving nodes received the packet, it will add one hop to itself and retransmission, until the unknown node receives this packet; at this time, the minimum hop (the shortest path) is regarded as the hop count between anchor nodes and the unknown node. This range method requires the uniform distribution of nodes in the network; it can ensure that the distance of mean hop in the network better reflected the layout of nodes and achieved higher ranging precision.
The coordinate of the unknown node is estimated by the trilateral location method; it has got good effect [14].
In [15], the value of nodes localization is achieved by the steepest descent algorithm which is a modified algorithm of maximum likelihood estimation method; moreover, the location accuracy and smaller computational cost can be obtained from the steepest descent algorithm which has obvious effect. In [16], the maximum likelihood estimation and the Kalman filtering are composited; it has a double effect on node prelocation and tracking, and it also has higher location accuracy.
The location principle of centroid localization is as follows: the unknown node sends broadcast messages to the network for determining its location information; after anchor nodes received broadcast messages, they sent response of information of its own location to the unknown node; the center of mass in this graphic is regarded as the estimation coordinate of the unknown node [17, 18], which is formed by anchor nodes.
In [19], Approximate Point In triangulation Test (APIT) is mentioned. It is a concrete application of centroid localization method; the location principle is as follows: there are any three anchor nodes that composed one triangle; there is a collection formed by all triangles which included the unknown node; the coordinate of the unknown node is determined by determining the center of mass of graphic which is composed of all triangles of the collection.
Centroid algorithm is the most popular algorithm in many location methods in WSN, because the easy operation and the characteristics of few errors are included in the algorithm. Yedavalli and Krishnamachari has put forward sequence of location algorithm [20] (SBL, Sequence-based Localization); Liu et al. has put forward a new SBL algorithm; it combined SBL with three orthocenter algorithm [21]; it is a concrete instance of centroid localization method; it achieved good localization accuracy, but it is needed to improve on boundary node location or ideal environment.
The location principle of convex programming location method [22] (convex optimization) is that the whole network is regarded as a model of convex collection by using the network connectivity; it is through the way of bound combination and plans to determine the possible region within the unknown node and estimate coordinates.
In [23], researchers have analyzed location methods of DV-Hop and DV-distance; the experimental result has shown that the location accuracy can achieve 20% when the network connectivity is 9 and the proportion of anchor nodes is 10%, but the location accuracy is declining evidently along with the increasing range error. Zhang and Wu have put forward a modified location algorithm [24] which is based on the estimation of mean hop distance and location correction; it has solved the situation that the distance of mean hop cannot reflect the real distance, which is estimated by the single anchor node in the network. The result of experiment has shown that mean error of the modified algorithm is reduced about 8.8497% and 14.457%; it has achieved better location accuracy.
In this paper, a novel location algorithm based on RSSI vector similarity degree is presented and a location system is designed, which is applied to locate sensor nodes indoor. Our proposed contributions are as follows.
The Gaussian fitting has optimized the value of RSSI at different distance. The linear interpolation is used to decrease the calculation of RSSI; it is according to the relation between different RSSI and distance. The vector similar degree is helpful in choosing anchor nodes. The generalized inverse is solved to estimate the coordinate of unknown node by equations. The location system is able to work well indoor when the mobile node is dynamic.
2. Ranging Method of RSSI-Based
Received signal strength indicator (RSSI) indicated the energy loss in the process of signal transmission; the RSSI value is associated with the size of signal attenuation. In the process of signal transmission, the smaller the RSSI value the less the attenuation. Usually, the RSSI ranging [25] is based on the experience model or theory model. The RSSI ranging of model-based experience has shown that an offline database is built between few RSSI values of nodes which are known location information and their distance of signal propagation; in the process of nodes location, the stored data in the database is constantly compared to implement nodes location. The RSSI ranging model-based theory implemented nodes localization by determining the environmental parameters in the loss model of signal propagation and plugging the RSSI value which is received from receiving nodes into the model, so as to estimate distance between nodes. There is a key of former method; lots of measuring work of off-line in the region is required; in addition, the location accuracy is limited by the number of nodes and measuring workload. The core of the latter method lied in researching on critical parameters of the model detail by the accurate measuring of RSSI value; hardware conditions and actual environment can be better reflected; in addition, location accuracy and improved location performance can be enhanced.
Common methods of RSSI ranging are as follows, which are based on the theory model: the path loss model of free space propagation [26] and the block model of logarithmic normal [26] (Shadowing model), and so forth.
The path loss model of free space propagation is an ideal transmission case, it is known that there is an infinite vacuum around antenna, the signal transmission energy is only related to transmission distance, there is a linear relationship between the signal transmission energy and transmission distance, this model has no effect on obstacles and scattered reflection, and so forth. The path loss model [26] is as follows:

However, the application environment of wireless sensor signal is not in a free space, but in the actual environment such as industrial sites or indoor buildings; it needs to consider shade and absorbance by obstacles and the interference of scattered reflection, and so forth. The attenuation characteristic of channels in the long distance is following the lognormal distribution; it is commonly used by the block model of logarithmic normal; the path loss model is as follows:
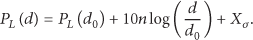
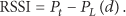


We take the reference distance



2.1. RSSI Ranging Method Based on Gaussian Fitting
As shown in Shadowing model, there is a corresponding relationship between wireless signal propagation loss and transmission distance in the actual test environment. It means that according to the received information of signal strength the distance between sending nodes and receiving nodes can be obtained. However, the conclusion of experiment cannot rely on one time of measurement task, but on the basis of a large number of test data. So, in terms of the same node and the same distance, received signal strengths are taking many times of measures. On the basis of measurement, the distribution trend of RSSI in the test environment is analyzed and interference data and error data are eliminated; the most representative signal strength value at specific distance is obtained; signal strength is regarded as the basis of distance estimation at this place.
2.1.1. Experimental Environment
The location system is included the hardware platform and software platform. Hardware platform included anchor nodes and unknown node, gateway control equipment. The measurement is worked on the perception platform of SensorRF107H2 0, the sensing platform is designed by the wireless gateway which owned the core of high-performance microcontroller and in 32-bit ARM, and it included advanced designing tools of software and hardware such as online emulators when users develop, debug, and test software. Anchor nodes and unknown node are composed of modules of CC2530 of the system of ZigBee which is included TI.
2.1.2. Acquisition of RSSI Data
Signal strength indicator (RSSI) is read from the register RSSI_VAI in the data packets which are received from sensor receiving nodes, a sensor node is set and regarded as a receiving device at intervals of 1 m, RSSI data is measured more than 400 times at every place, and each sensor node is received and recorded its signal strength value. Receiving nodes only can receive few signal strength values beyond 25 m; parts of signal value are not detected, because the RSSI value of characterization signal attenuation is included in data packets, so it is meaningless to keep measuring. In this paper, the range of RSSI ranging is kept 0~25 m. For example, the distance between sending node and receiving node is taken 5 m and 10 m, respectively, we have made statistics for collecting RSSI value and chosen more than 400 times of measurement to be a sample and got the characteristics picture of RSSI, and they are as in Figures 1 and 2.

RSSI experimental data of node at d = 5 m.

RSSI experimental data of node at d = 10 m.
Figures 1 and 2 can be seen, with the passage of time; although RSSI generally presented obvious nonstationary characteristics, the RSSI value in certain distance are always fluctuated up and down between the constant real RSSI value, the closer distance from emission node, and the frequenter change of measurement value; on the contrary, the farther the distance from emission node, the gentler the change.
2.1.3. Shadowing Model
In order to exactly describe the actual measurement environment and ensure the accuracy of RSSI ranging, the parameters of signal propagation model are needed to define. A indicated the received signal strength value when the reference distance is
The determination of parameter A is as follows.
The determination of parameter n is as follows.
Environment factor n indicated, along with the increasing distance, the speed of signal loss in the process of actual transmission. They are satisfied with the following relationship:
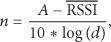
The value of n.

The mean value n can be obtained as follows:


2.1.4. The Distribution Trend of RSSI and Gaussian Fitting
In order to analyze the distribution trend of RSSI, many groups of RSSI data are integrated and analyzed and drew four groups of probability density curves when RSSI is, respectively, 117 DBM, 89 DBM, 61 DBM, and 25 DBM; the results are as in Figures 3, 4, 5, and 6.

First group of RSSI probability density.

Second group of RSSI probability density.
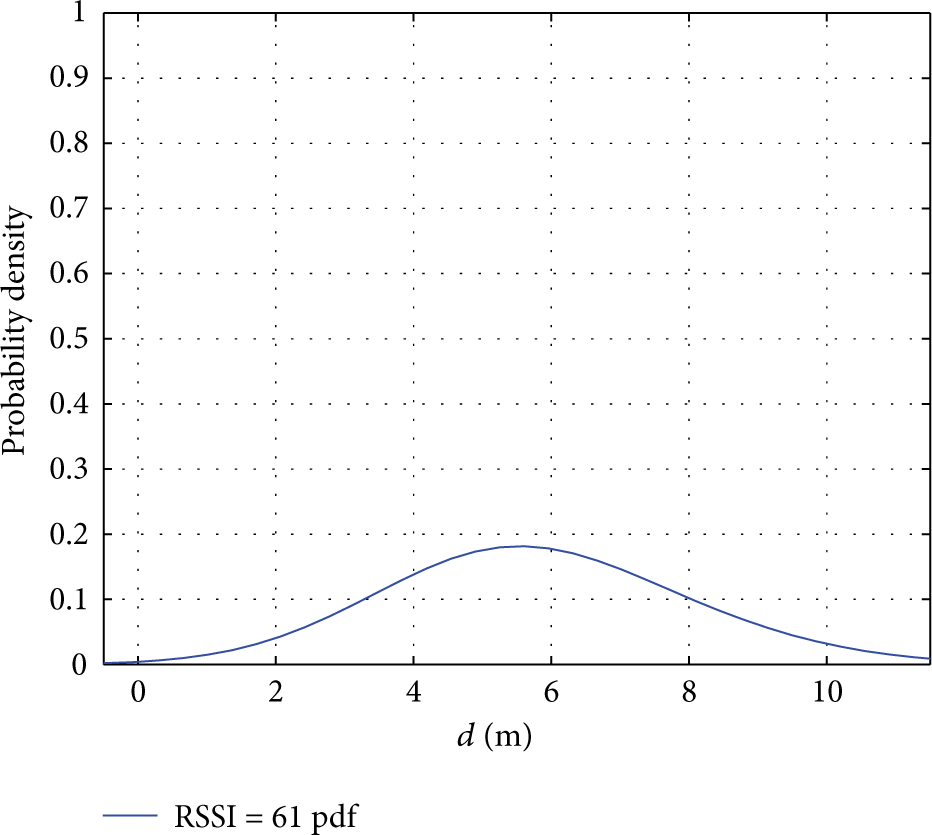
Third group of RSSI probability density.
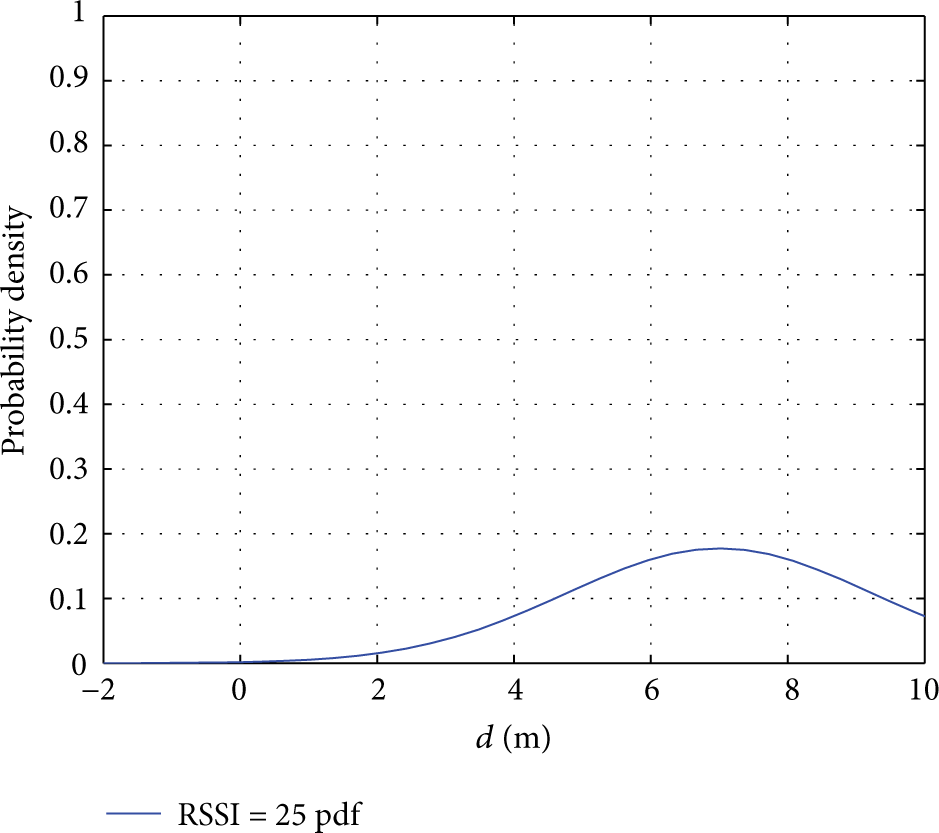
Fourth group of RSSI probability density.
It can be seen from Figures 3, 4, 5, and 6 of RSSI probability density that the distribution of RSSI value of the real measurement presented a probability distribution; there are some characteristics are as follows.
Concentration. The peak of the curve (the mean location) is located in the central.
Basic Symmetry. Two sides of curves are basic symmetry and ends of the curve are closed to horizontal axis. The centre of curves is based on mean value.
Volatility. The trends of two sides of curves are declined gradually at the place of mean value.
Some scholars also research on the kind of distribution of RSSI [27–29]; they think RSSI value approximately followed normal distributions as a whole. According to the experimental data and probability density in this paper, it can be seen that there is a similarity between actual measured probability density of RSSI and normal distribution [30]. So Gaussian fitting is used to fit RSSI value in experiment and probability error and invalid data are eliminated, the peak value of probability is found, the estimating distance is extracted, which is closer to the real distance, and the process is prived an experiment basis to get accurate location.
If RSSI data is closed to normal distribution, the peak of normal distribution will be the place of the greatest probability density, and the RSSI value is most likely the corresponding distance. So the Gaussian fitting [31] is used to fit the original RSSI data by looking for the peak of probability density; it is aimed at reducing the interference that small probability events have an effect on the overall measurement process. In order to improve the precision of RSSI ranging, the least square [32] is used to fit curves of probability density of RSSI.

There is an assumed fitting function between 

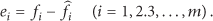




Figure 7 has shown the probability density of fitting when RSSI = 117 DBM. Since then, the RSSI value at the highest peak of curve is regarded as the signal strength value (distance 1 m). Similarly, in terms of any RSSI value, the distance is regarded as the basis of distance estimation, which is correspondent to the peak of probability density.

The gauss curve fitting when RSSI = 117.
The Gaussian fitting function protoformula is as follows:


2.2. Ranging Method Based on Interpolation
400 groups of RSSI data are taken at intervals of permanent distance; in Figure 8, the blue line is the real measurement value of RSSI in different distance; it can be seen that, with the increasing distance, different distance of RSSI overall has shown the trend of exponential attenuation, but there is a certain fluctuation which is influenced on interference factors around. The green line is the fitting value of RSSI in different distance.

The trend of curves of RSSI value between experiment and fitting.
Due to the fact that the trend of RSSI value is in accord with the distribution characteristics of indexes, the least squares are also used to fit the indexes function between the relation of RSSI-d, 0.0001237 and 128.2 are presented in this formula when the range of RSSI value is taken from 117 DBM to RSSI = 61 DBM, and there is a formula of fitting curve as follows:
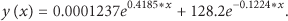
It is known that the real RSSI value is close to Gaussian distribution at different distance by analyzing the above section; the place of larger distribution density of RSSI is most likely to be the distance between receiving nodes and projection nodes. As shown in Figure 9, the corresponding RSSI value is measured at intervals of 1 m and the distribution of probability density is analyzed. The probability density curves when RSSI = 117 DBM and RSSI = 61 DBM are drawn, respectively, in the diagram. But it is uncertain that the not-measured RSSI value is at the distance of 1.5 m and 2.5 m; similarly, in terms of a given RSSI value, the distance between sending nodes and receiving nodes is uncertain. To this end, the interpolation mode is built according to the measured probability distribution of RSSI value; the distance between nodes is estimated according to the received RSSI value.

The curve of probability density when RSSI = 117 and RSSI = 61 DBM.
The Gaussian fitting is used to fit the probability distribution of RSSI. There is a fitting function as follows:

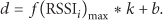



The linear interpolation.
If it is known that
In this experiment, in the range of 0~25 m, all mean values of signal strength and standard deviation are indicated as follows:


The contrast of range error between RSSI-d interpolation model and Shadowing model.

From Table 2, it can be seen that Shadowing model and RSSI-d interpolation model can obtain corresponding distance by speculating the RSSI value; they achieved the ranging effect. But from the ranging error, it can be known that mean range errors of RSSI-d interpolation model are less than Shadowing model; it is benefit from linear interpolation of short distance.
3. The Location Algorithm Based on R-VSD
Along with growing demands of applications, there are many kinds of methods, but every method has its merits. At present, the research on indoor location technology in wireless is relatively concentrated on signal-based RF [35], there are various technologies in wireless network, such as ultra wideband (UWB), Wi-Fi (IEEE 802.11), Bluetooth, and radio frequency identification (RFID). If researchers consider hardware conditions of location and signal resources and location accuracy, the method based on the received signal strength indicator (RSSI) [21] is widely used in all of location methods. Existing localization algorithms [23] can also obtain good location effect, but the researching is not completed on the part of edge nodes; in addition, there is a problem of large location errors which are caused by the pending location nodes that are outside of the unit. On account of the above problems, an improved localization algorithm RSSI-based with vector similarity is proposed. In the process of location, the method of R-VSD is used to choose optimal anchor nodes; the new location algorithm is used to estimate coordinates of unknown nodes.
3.1. The RSSI Vector Similarity Degree
In order to describe the similar degree between the RSSI vector of unknown nodes and the RSSI vector of reference sample points, the new indicator, similar degrees of RSSI vector is built; reference sample points which are nearest to the unknown node accurately can be found.
Definition 1.
If a node can receive radio signal from n anchor nodes, the received RSSI value can set a vector collection as follows:

RSSI value of the vector collection 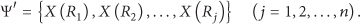
The RSSI vector which is formed by n anchor nodes and m reference sample points is as follows:


Definition 2.
There are two different vectors 
Definition 3.
There are two RSSI vectors.


According to Definition 3, the vector similarity is satisfied with the following relations:
the smaller the



The algorithm flow chart.
In Figure 11, firstly, there are a number of Un unknown nodes and the number of n anchor nodes is distributed in the region of pending. Secondly, unknown nodes received RSSI which are sent and created the RSSI vector table which is arranged by descending sort. Thirdly, the top four anchor nodes are taken to determine the quadrilateral location unit. Fourthly, the unknown node p is judged whether it is inside of the quadrilateral location unit or not. If it is inside of the quadrilateral location unit, the internal location arithmetic is implemented; on the contrary, the external location arithmetic is implemented. Finally, the number of unknown nodes in the range of Un should be judged before estimation coordinates of unknown nodes are calculated. Otherwise, the unknown node had to judge that whether it is inside of the quadrilateral location unit or not.
The time consuming of points collection and vector table are both
In this paper, in terms of the triangle location unit S, which has shown the initial area, three median lines are divided into four small triangles for the original triangle; there is a triangle called a median triangle, which is formed by three median lines; the areas of four triangle are
3.2. The Location Algorithm Based on the Quadrilateral Location Unit
There are four anchor nodes regarded as reference anchor nodes, which are the closest to the unknown node. The quadrilateral is regarded as the location region, which is formed by these four anchor nodes. The unknown node is determined whether inside of the quadrilateral or outside of the quadrilateral by the relation of area constraint. Under this section, these problems are solved: how to select reference sample point if it is inside of quadrilateral; if it is outside of the quadrangle, how to determine the coordinate of the unknown node in the case of making location error as small as possible.
3.2.1. The Determination of the Location Unit
Theorem 4.
The midpoint of the each edge of the triangle is taken; the new three midpoint points and three top points of the original triangle are regarded as reference sample points; there is uniqueness of the RSSI vector which is formed by the RSSI value of sample points which are received from all anchor nodes.
Proof (by reduction).
As shown in Figure 12, it is assumed that there are different coordinates of two different nodes P1 and P2, but they have the same RSSI vector with same dimension and value (the numbers of anchor nodes are 3, the dimension of vector is 3), ∵ There is the same RSSI vector with same dimension and valuefor P1 and P2 ⇒ By Shadowing model, there is a same distance vector with same dimension and value for P1 and P2. ⇒There is the same distance from P1 or P2 to any same anchor nodes. ∴ There is the following equation:
There is a unique solution for the coordinate of P1 by above formula (43) and formula (44).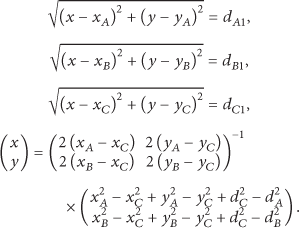
There is a known assumption that

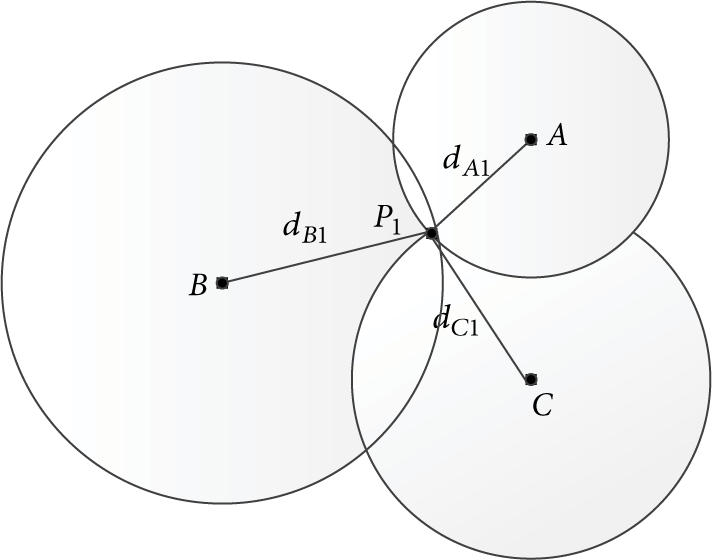
A set of RSSI vector is uniquely correspondent to the coordinates of node.
According to Theorem 4, there is uniqueness for every vector of reference sample points in subsequent localization algorithm.
3.2.2. The Main Idea of the Localization Algorithm
As shown in Figure 13, P1 and P2 are indicated unknown nodes, A, B, C, and D are indicated reference anchor nodes which are the closest to P1 and P2, and the quadrilateral indicated the location unit, which is surrounded by A, B, C, and D. AC and BD indicated two diagonals of the quadrilateral ABCD and O indicated diagonals intersection (coordinates can be obtained); it is regarded as the new reference sample point.

Unknown nodes of P1 and P2 for locating.
By the following relation of area constraint, the location of unknown node can be determined roughly as

By Algorithm 1 of two location system, the location of unknown node can be determined.
The input: These reference anchor nodes A, B, C, D, which are the closest to of a set There are number Un unknown nodes are distributed in the region of locating. The output: The unknown node P is inside of the location unit or external. Step 1. FOR Step 2. IF Step 3. RUN InternA //The algorithm of location mechanism that P is inside of graphics. Step 4. ELSE Step 5. RUN ExternA //The algorithm of location mechanism that P is outside of graphics. Step 6. ENDIF Step 7. ENDFOR
3.2.3. The Location Mechanism of the Unknown Node Is inside of the Location Unit
As shown in Figure 14, if the unknown node is inside of ABCD, some operations will be taken to reduce the location unit as follows.

The division of the location unit when the unknown node is inside of graphics and the determination of sample points.
Step 1. Point P is judged whether in
Step 2. If point P is inside of any one triangle, three new reference sample points are obtained by taking the middle point of each edge of triangle.
Step 3. The similar degree for the RSSI vector of the unknown node P are compared with the top points of the original triangle and the RSSI vector of three new reference sample points (there are six RSSI vectors); the most similar reference sample points are found; namely, three reference sample points which are closest to P are E, G, D.
By analogy, above steps are repeated, reference sample points are obtained by looking for the midpoint of the location triangle constantly, which are the closest to the unknown node P, the microtriangle region which included the unknown node is narrowed, and Figure 14 has shown that midpoint P is locked in the region of
3.2.4. The Location Mechanism of Unknown Node Is outside of the Location Unit
If the unknown node is outside of the unit, as shown in Figure 15, the coordinates of the unknown node is determined by determining two triangles of copoint.
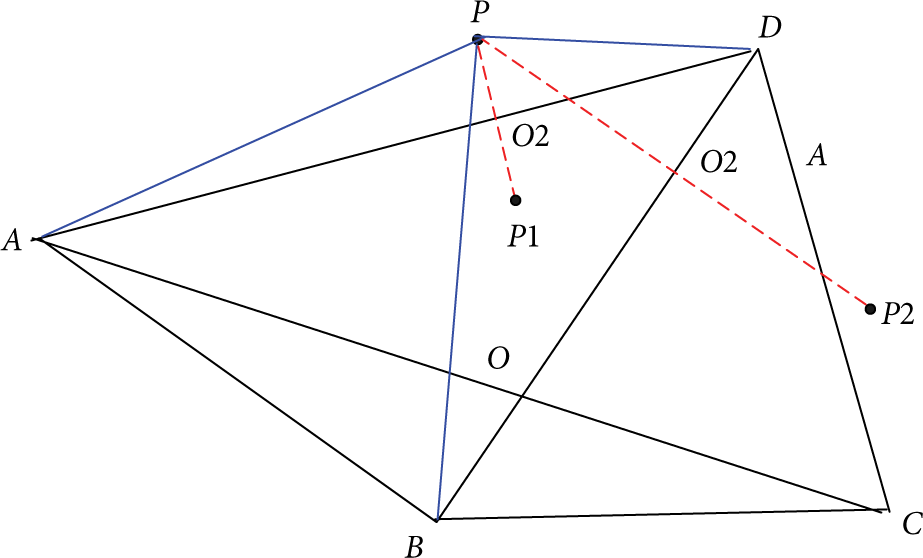
The unknown node is outside of the graph.
Main operations are as follows.
Step 1. Points D and A are found, which are first and second of the RSSI vector of the unknown node P; they are made of
Step 2. Points D and B are found, which are first and second of the RSSI vector of the unknown node P; they are made of
Step 3. Since the RSSI can be measured, the distance between points can be obtained by the signal attenuation model. Since three lengths of sides are known, the triangle area can be obtained. Since coordinates of two tops are known, the height from point P to its edge can be obtained by the area formulation
The coordinate of known node is obtained by the following equations:

By the same token, RSSI values of points D and B are chosen, which are first and third in RSSI vector.
Although this method is feasible, the rate of measurement error of RSSI on all directions may not be consistent in the process of distance measuring; it will be leaded to distance changes of the corresponding direction showing different conditions; at this time, the above method cannot get two public point of two triangles; namely, there is not public solution for simultaneous equations.
3.2.5. The Method of Generalized Inverse
As shown in Figure 16, there are random measurement errors of RSSI; the calculation result is not coincidence. Furthermore, there is not public solution for simultaneous equations. To this end, a complementary localization algorithm is designed when the node is outside of the location unit by using the generalized inverse [36].

The complementary localization algorithm used the generalized inverse.
If there is a solution of equations, the equation is regarded as the compatibility equations; on the contrary, it is the incompatible equation. In terms of the incompatible equations, there is no general solution. So in this section, the optimal and approximate solution of incompatible and insoluble equations is obtained by using the generalized inverse

Definition 5.
If the incompatible linear equation
G indicated a matrix,
Namely,
The coordinate of the unknown node is calculated according to anchor nodes of A, B, and D, and there are equations as follows:


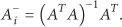
4. Results of Simulation Experiment and Real Experiment
4.1. The Result of Simulation Experiment
In order to simulate the real environment, the Shadowing model is used to convert RSSI value into its corresponding distance; ranging errors are setup to simulate the range environment. In this section, localization algorithm is simulated by the tool of MATLAB 7.0, 8 anchor nodes and 160 unknown nodes are taken in this experiment, all nodes are isomorphic, unknown nodes are random distributed in the rectangle area 10 × 10 m2 in the experiment environment, and anchor nodes are in the scope of the region that unknown nodes can be communicated (Figure 17).

The layout of anchor nodes and unknown nodes.
Figure 18 has shown that location error is obtained by simulation when anchor nodes numbers are 8, 16, 24, and 32. Along with the increasing numbers of anchor nodes, location errors are decreased gradually. Because the more the numbers of anchor nodes are in the locating area, the more the numbers of anchor nodes are nearest to the unknown node, the smaller quadrilateral area is formed by anchor nodes; namely, sample reference points are more closer to the unknown node.

The relation between the number of anchor nodes and location error.
In order to describe the effection of ranging error and the trend of ranging error, we have drawn a picture of the relationship between location error and ranging error. In Figure 19, the increasing trends of anchor nodes are increased from 8 to 32, and the changing of the location error is changed.
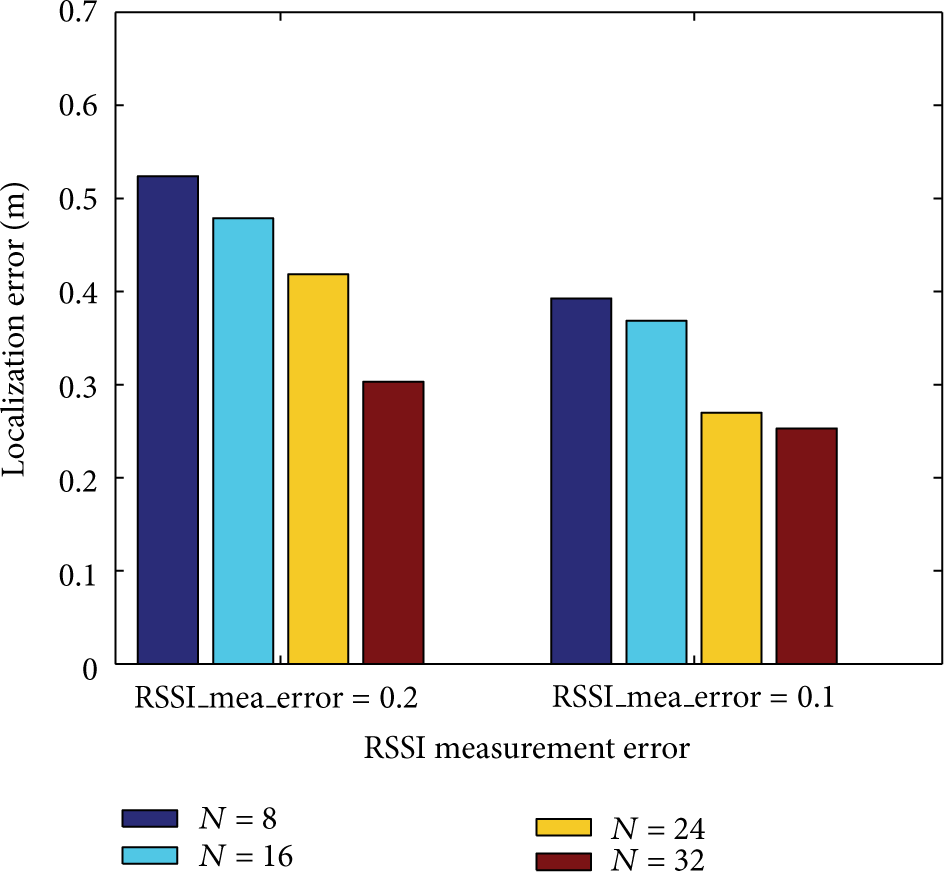
The relation between RSSI ranging error and location error.
At the same time, under the condition that the total number of unknown nodes is invariable at UN = 160, Figure 19 has shown the simulation result when RSSI ranging errors are 0.1 and 0.2, which are obtained by the method of average calculation, and it also means that the percentages of RSSI ranging error are 10% and 20%. According to Figure 19, when the number of anchor nodes is unchanged, the bigger the RSSI ranging error, the larger the location error; at the same time, when the RSSI ranging error is constant, the more the number of anchor nodes, the smaller the location error. It is also suggested that location error based on RSSI is not only dependent on the localization algorithm, but also dependent on the accuracy of ranging analysis of RSSI [10].
There is a relation analysis between the number of anchor nodes and location error and RSSI range error in Figure 19, in the real measurement environment. The measurement errors of RSSI at all directions are not consistent; the generalized inverse is used to solve the problem that there is not public solution of equations which is formed by the external location unit. The picture of location error is shown from Figures 20, 21, 22, and 23; the colorful lines indicated the mean location error when RSSI ranging errors are 0.05, 0.1, and 0.2, according to these figures, the mean location error = 0.2 is regarded as the better mean value, along with the increasing number of anchor nodes; location error has shown a decreasing trend on the whole; in addition, the final location error of the random ranging error is almost constant with the final location error of the constant ranging error before, but it is practical in application.

The number of anchor nodes is 8.
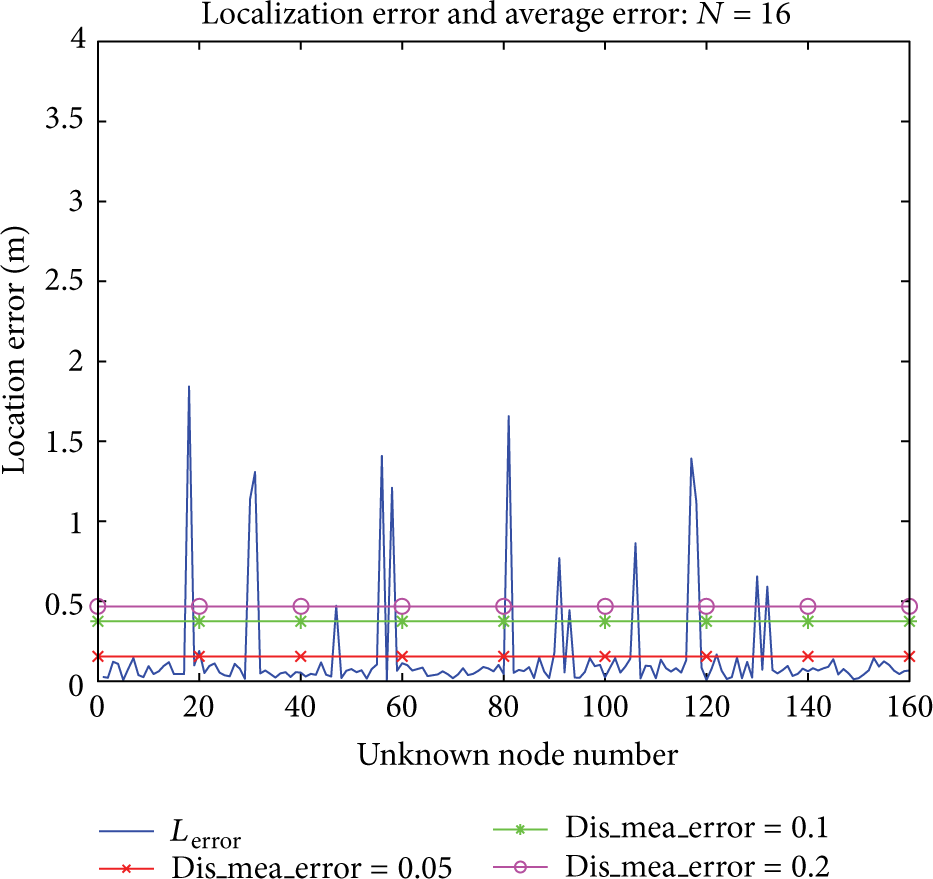
The number of anchor nodes is 16.

The number of anchor nodes is 24.
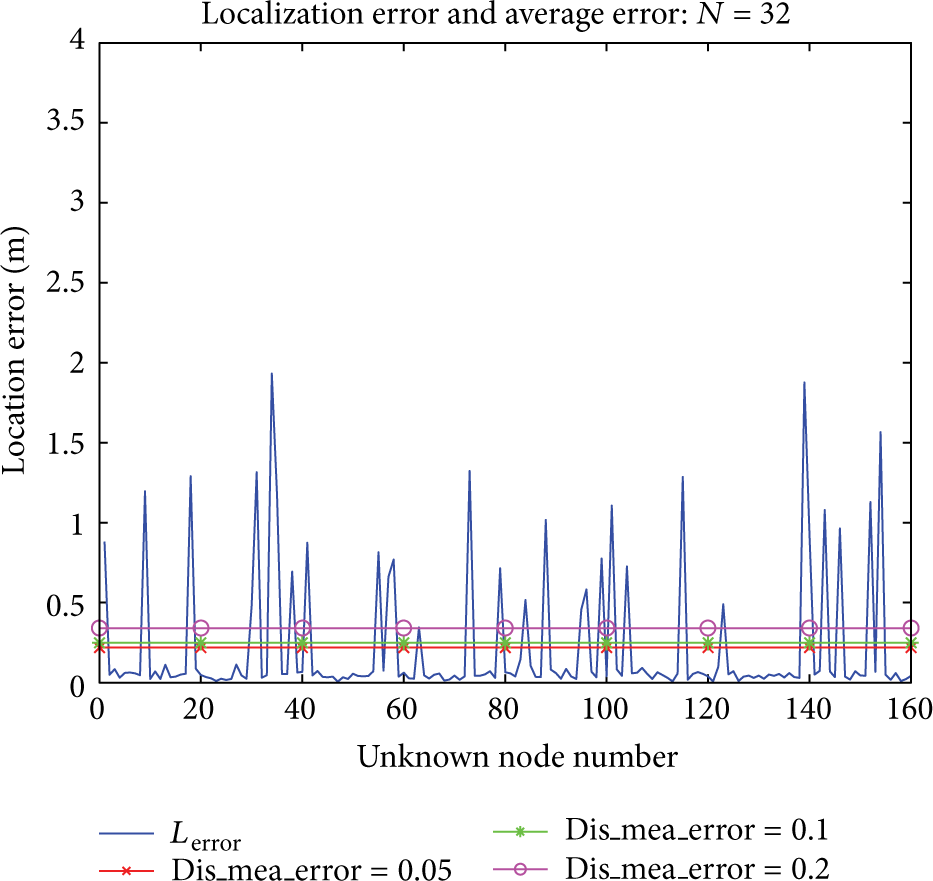
The number of anchor nodes is 32.
In Table 3, there is a comparative relationship of the number of reference sample points required when each unknown node is required to locate between localization algorithm and localization algorithm of FTLM model. According to Table 3, it can be seen that this algorithm needed less reference sample points when the microarea of positing is the same one; moreover, less amount of calculation is needed. The iteration location by reducing the area is convergent.
The relationship of the number of reference sample points between localization algorithm in this paper and localization algorithm of LTFM model.

When the location area is 10 × 10 m2, the comparison of location error between the new algorithm and the sequence three-orthocenter method and the sequence location method and three other center methods is shown, respectively, in Figure 24.

The comparison between algorithms.
Visibly, along with the decreasing number of anchor nodes, location error of these methods will be increased, because the more the number of anchor nodes, the more the times that original location area is divided into different formulas of smaller area, unknown node is more closer to anchor nodes, the more accurate location; Figure 24 has shown that location error of three-orthocenter method is more than five times than new location algorithm when the anchor node number is 8, because the new location algorithm continuously narrowed the area which included the unknown node by the scale of 1/4 in the process of location; thus the actual location of the original node can be better restored; in this paper, the location error of the new location algorithm is almost constant with the sequence three-orthocenter method and the sequence location method when the anchor node number is 32, because the numbers of location sequence of sequence three-orthocenter method and sequence location method are already increased to 462273 when the anchor node number is increased to 32; the area is quite small, which included the unknown node, but, obviously, lots of measurements should be taken; a great amount of calculation and sequence alignment should be made; at this point, the 16 reference sample points are needed to compare with each unknown node in the new location algorithm; the location error is lower than three-orthocenter method; the superiority is shown.
In this simulation experiment, four anchor nodes and four unknown nodes are set up in the region 3 × 3 m2. The mean absolute ranging error of nodes is obtained as 0.27 m; the percentage of location error is about 17.6% by the calculation formula:
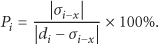
In Figure 25, black points indicated anchor nodes which are settled before, red points indicated the real coordinates of unknown nodes (they are ranged by tools), and blue triangle indicated estimated coordinates of unknown nodes by the new location algorithm.

The result of location.
The location error is not only related to the location algorithm but also related to RSSI range and the number of anchors nodes. There is an emulational result of location error of these unknown nodes shown as in Table 4.
Location error of unknown nodes.

4.2. The Result of Real Experiment
In this experiment, the latticed experiment environment is designed; there are some nodes in it. Because the place of this experiment is in laboratory, the location grid 20 × 20 m2 is set; 4 × 4 m2 is just a part of the location grid. In order to choose anchor nodes with better performance, the amount of calculation is needed to decrease; four anchor nodes and one known node are placed in the location grid 4 × 4 m2.
In addition, the unknown node is moved at different places. First of all, RSSI values of four nodes in multiple directions are measured, respectively; there is a result that RSSI values of nodes in each direction are basic stability when they are individual, so nodes are required to be immobilized. Secondly, the range models of nodes in different directions are determined, we found that location errors are unreal by calculating, so we measured the RSSI value of four nodes in the range of 1 m and 4 m, respectively, and the total RSSI value of are more than 2000 groups. Thirdly, the statistic of the probability of each RSSI value is obtained by using the tool of Matlab; we selected the optimal value by using the Gaussian fitting. Finally we built the ranging model by introducing
In terms of the station that the increasing anchor nodes in the experiment, the range model of this node should be created. Firstly, because interference factors are inevitable indoor, there are different RSSI value of anchor nodes in a different direction. Secondly, the new ranging model of node is needed to build. There are 20 groups of RSSI value of four nodes in the range of 1 m and 4 m, respectively, in Table 5.
20 groups of value of signal strength.

The number of nodes and distance of nodes and the probability of each RSSI value are measured in the experiment. For example, there are parts of information from Tables 6, 7, 8, and 9.
The measured data of number 1 node.

The measured data of number 2 node.

The measured data of number 3 node.

The measured data of number 4 node.

The optimal value is selected by using the Gaussian fitting. Figures 26, 27, 28, 29, 30, 31, 32, and 33 have shown curves of Gaussian fitting of four nodes when their distances are 1 m and 4 m.

The fitting curve of number 1 node when distance is 1 m.

The fitting curve of number 1 node when distance is 4 m.

The fitting curve of number 2 node when distance is 1 m.

The fitting curve of number 2 node when distance is 4 m.

The fitting curve of number 3 node when distance is 1 m.

The fitting curve of number 3 node when distance is 4 m.

The fitting curve of number 4 node when distance is 1 m.
The fitting curve of number 4 node when distance is 4 m.
The piecewise linear interpolation for RSSI-d curve is used to ensure the ranging precision. There are four range models of four nodes as in Table 10.
Range models of nodes.

There are real coordinates of nodes. There is part of measurement data in Table 11.
Coordinates of unknown nodes.
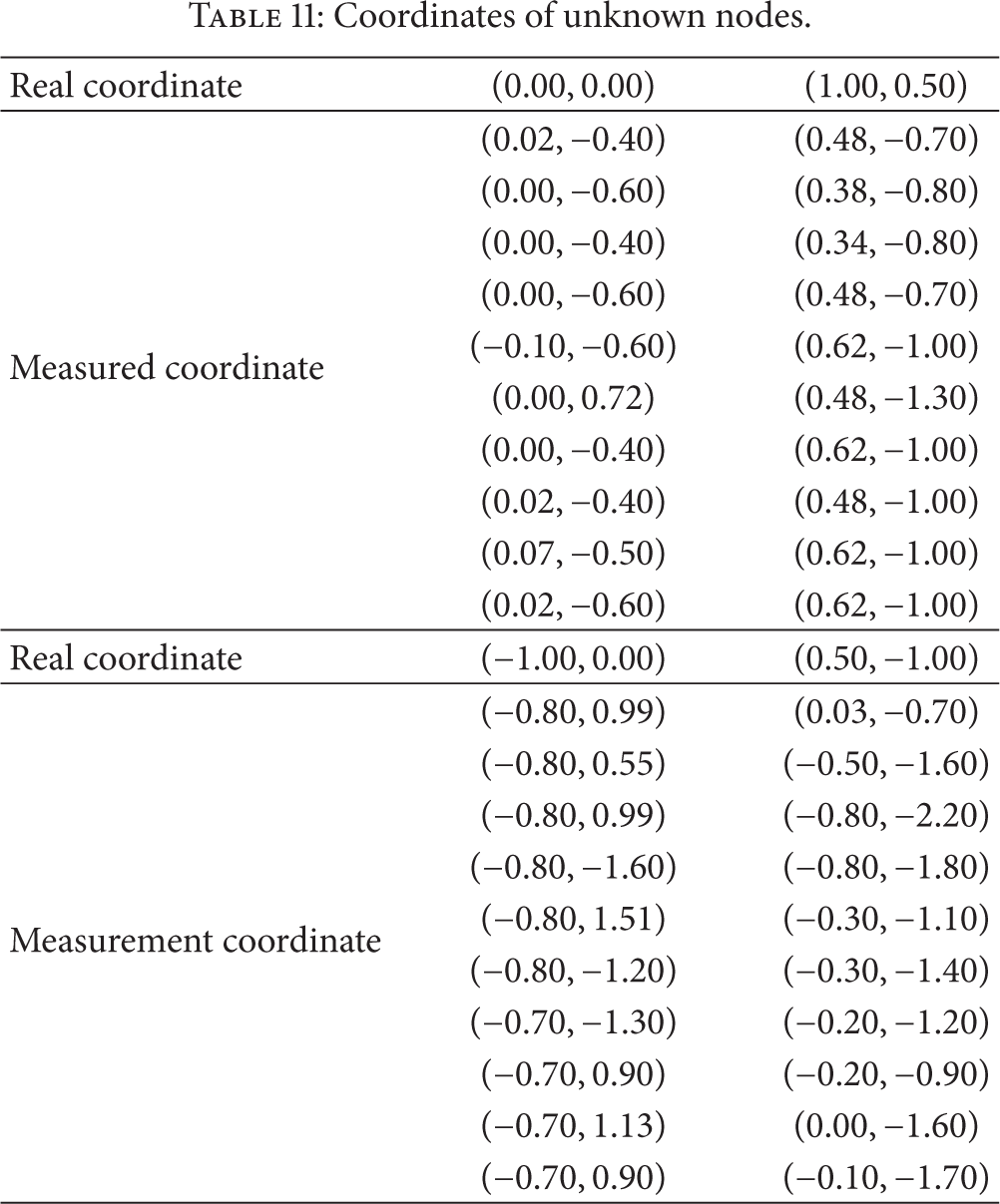
Through times of measurement of the unknown node, the smallest location error is regarded as the ideal date which is obtained from the noninterfering environment. For the first time, the smallest location error is 0.4 m in the actual coordinates of node; for the second time, the smallest location error is 1.31 m; for the third time, the smallest location error is 0.59 m; for the fourth time, the smallest location error is 0.48 m (see Table 12).
Coordinates of four nodes.

In Table 9, since interference factors are inevitable indoor, there are different RSSI values of anchor nodes in different direction. Their ranging models are based on different nodes. There are different results of mean location error.
In Figure 34, black squares indicated fixed anchor nodes in the experiments, yellow dots indicated actual coordinates of unknown nodes, and blue triangle points indicated estimation coordinates of unknown nodes which are obtained by the new location algorithm. In each experiment, the mean location error is about 1 m. Four yellow dots indicated movement results; there are four times of movement for the unknown node; the experiment is regarded as a dynamic test.

The effect of location.
4.3. The Simulated Application of the Location Algorithm
4.3.1. The Design of Location System
The location system is applied at home and location area is set as 4 × 4 m2. Four anchor nodes are It is selected in the location region. A RFID tag is carried with robot which is regarded as the unknown node. In addition, the location system is set as a server and a transmission PC and a router (see Figure 35). Firstly, anchor nodes send strength signal to the robot which can be received and sent signal. Secondly, the server received signal information from the robot and processed these data. Thirdly, mobile terminal gets processed data from server by router. Finally, information of mobile robot is displayed in the interface of mobile terminal. Particularly, the card reader is set at the door; it is a caution of the mobile robot when the robot is outside of the location region.

The schematic diagram of the location system.
4.3.2. The Design of Mobile Terminal
This system can be applied to prevent children lost indoor; accounting that the children's speed of movement is relatively much slower than parents, the process of implement is regarded as a lower level dynamic environment. The system is able to work well when child moves into room.
There are some pictures of experiment displayed in the interface of mobile terminal. In Figure 36, the application is set at home, so the background of the interface is the picture of home, and the black point indicated the mobile robot.
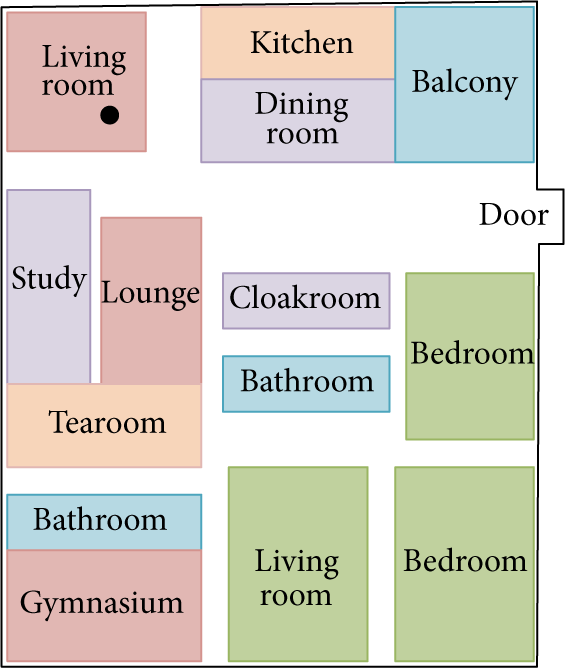
The normal effect.
In Figure 37, it is shown that there is an alarm's tooltip in the picture; it indicated that the RFID tag is read by card reader; namely, the mobile robot is outside of home. Particularly, this system designed the alarm's music with the alarm's function.

The alarm's effect.
5. Conclusion
In this paper, we studied on the location technology of RSSI-based in WSN. In order to get accurate RSSI value and simulate the real experimental environment, there is a large amount of experimental data. In the process of location, we determined the related parameters of the Shadowing model and analyzed the RSSI value at the specific distance by the Gaussian fitting; in addition, not only we built the RSSI-based interpolation model of node, but also we analyzed the influence of the number of nodes. In terms of the new location algorithm, we proposed the location mechanism; it is used to estimate that the unknown node is internal or external. Moreover, we proposed the concept of vector similar degree; it is helpful to choose anchor nodes. Particularly, the generalized inverse is solved to estimate the coordinate of unknown node by equations. Simulation and experiment results show that our approach outperforms existing approaches in terms of location accuracy, and our location system is applied to locate the robot quite well.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The authors would like to thank the Chongqing Natural Science Foundation under Grant no. cstc2012jjA40038 and the Science and Technology Research Project of Chongqing Municipal Education Commission of China. The work presented in this paper was supported in part by the Ministry of Industry and Information Technology of China for the special funds of Development of the Internet of Things (2012-583).