
Abstract
Location awareness plays an indispensable role in a wide variety of application domains such as environment monitoring and vehicle tracking. In this paper we focus on the localization of mobile users in sparse mobile networks which exist in many practical scenarios where users are distributed over a vast area. The unique characteristics of sparse mobile networks present several challenges for accurate localization, such as constant movement and little information from anchors. By analyzing five large datasets of real users traces with entropy analysis from five sites, we make an important observation that there are strong patterns with user mobility. Motivated by this observation, we propose a localization approach called EMP by exploiting mobility patterns of users for localization in sparse mobile networks. EMP implements a range-free distributed algorithm, with which each user collaboratively estimates its current location by fusing two localization sources, that is, network connectivity with other nodes and mobility patterns. With trace driven simulations, we demonstrate that EMP significantly improves the localization accuracy, comparing with other existing localization approaches.
1. Introduction
Location awareness plays an indispensable role in a wide variety of domains, such as environment monitoring and vehicle tracking. In this paper we focus on the localization of mobile users or devices in sparse mobile networks which exist in many practical scenarios where the users or devices are distributed over a vast area. The localization approach based on the global positioning system (GPS) suffers several limitations. First, GPS may fail in indoor environments or urban areas where urban canyons exist. Second, GPS receivers are power consuming and can easily drain power driven devices.
The unique characteristics of sparse mobile networks present several challenges for accurate localization. First, users are constantly changing their locations and localization should be performed in real time. Second, in a sparse network, anchors that have location information can be few for most of the time and thus localization should usually be performed under little information from anchors.
There has been extensive research on the localization problem [1–6]. Existing approaches could be classified into two categories: range-based and range-free. Examples for range-based approaches include Received Signal Strength (RSS) [7, 8], Angle of Arrival (AOA) [9], Time of Arrival (TOA) [10], and Time Difference of Arrival (TDOA) [11]. The performance of range-based approaches is highly dependent on the accuracy of range techniques, which could vary greatly in practical situations. For range-free approaches [4, 6, 12], mere communication connectivity is used for computing localizations of nodes. A high node density is an indispensable condition for range-free approaches. Unfortunately, the high density condition does not hold for sparse mobile networks.
By analyzing five large datasets of real users traces with entropy analysis from two university campuses (NCSU and KAIST), New York City, Disney World (Orlando), and North Carolina state fair [13, 14], we make an important observation that there is strong patterns with user mobility. More specifically, the future location of a user is highly dependent on the current location. In addition, a user intends to move around a few preferred locations.
Motivated by this observation, in this paper we propose a localization approach called EMP by exploiting mobility patterns of users for localization in sparse mobile networks. EMP implements a range-free distributed algorithm, with which each user collaboratively estimates its current location by fusing two localization sources, that is, network connectivity with other nodes and mobility patterns. Upon meeting another user, the location of that user is used to improve the location estimation of the user. At the same time, the mobility pattern of the user is exploited for helping refine its location estimation, and users are differentiated according to the degrees of their mobility patterns.
The technical contributions of the paper are listed as follows.
By analyzing the five real-world user traces with entropy analysis, we reveal that there exist strong patterns for user mobility. As a result, the mobility of a user is characterized by a Markov chain.
It is the first attempt, to the best of our knowledge, to estimate user locations by fusing network connectivity and mobility patterns.
With trace driven simulations, we demonstrate that EMP significantly improves the localization accuracy, comparing with other existing localization approaches, such as Locale [15].
The rest of the paper is organized as follows. In Section 2, we review related work. In Section 3, we give the system model and the problem statement. In Section 4, we introduce our localization algorithm in detail. Section 5 presents evaluation results. The conclusion is given in Section 6.
2. Related Work
A lot of methods have been proposed for localization. They could be classified into two categories: range-based localization and range-free localization. In this section, we review related work under the two categories.
2.1. Range-Based Localization
For range-based localization algorithms, techniques like triangulation or trilateration [16] are very popular, in which the physical distance among nodes is measured. These algorithms require some kinds of special hardware for measurements of distances [8, 17–20].
Received Signal Strength (RSS) [7, 8] is a distance measurement technology based on the relationship between RSS and distance. There are various models to map a RSS to the distance, for example, the free space model, two ray model, shadow fading, and so forth. In a practical situation, however, even if the nodes are from the same distance, their received signal strengths can be different because of the fading effect.
Angle of Arrival (AOA) [9] acts as a complementary measurement to estimate the direction of the received signal. Merely using the AOA technique, however, the localization accuracy is hard to guarantee. Moreover, the cost on the angle detection device is high.
Time of Arrival (TOA) [10] is a technique implemented on the Global Positioning System (GPS). With four or more GPS satellites, the localization accuracy could be guaranteed. Unfortunately, it suffers several limitations. First, GPS may fail in indoor environments or urban areas where urban canyons exist. Second, GPS receivers are power consuming and can easily drain power driven devices.
Time Difference of Arrival (TDOA) [11] is a multilateration technique based on the measurement of the difference in distance to two or more stations whose locations and the broadcast time of signal are both known. Like TOA, however, the implementation is costly.
2.2. Range-Free Localization
Besides range-based localization techniques, there are many range-free localization [2–4, 6, 12, 21–23], which rely on connectivity between different nodes.
Previously, the Centroid algorithm [24] estimates a node's location by simply calculating the center of all seed nodes around the node. Multidimensional Scaling (MDS) [6] is also such a kind of algorithms to solve the range-free localization. In MDS, the relative location of nodes could be calculated with the estimated distances of all pairs. Once the absolute locations of any three nodes, not in a line, are known, the location of the rest nodes could be calculated. After MDS, two extensions are introduced [22, 23]. Besides, MCL [1] is introduced with the consideration of finite movement speeds. The possible location of a node could be reduced from the possible location information provided by the seed nodes within two hops.
In [5], MCL is extended to enhance the localization performance. Obviously, to guarantee the localization accuracy, a large number of uniformly distributed seeds are necessary. That is, the density of nodes should be high enough to guarantee sufficient connectivity.
3. System Model and Problem Statement
3.1. System Model
We consider the localization of a set of mobile users moving within a given region. The set of mobile users are denoted by
Initially, at

Since any node's velocity is finite

where

where
The whole region is divided into grids of equal size

The KAIST campus is divided into
The trajectory of a node can hence be represented as a series of grids that it travels:

We make three assumptions. First, mobile nodes are equipped with a low accuracy dead-reckoning tracking sensor device. Second, all users have access to their historical traces. The historical trace of a mobile user i is represented by
3.2. Problem Statement
The goal of our algorithm is to get the location of each mobile user at any time within a period of time of interest. The estimated locations of all mobile nodes are denoted by set

We define

where
Thus, our objective of localization of the mobile nodes is as follows:
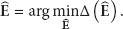
4. Design of EMP
4.1. Overview
EMP is a distributed algorithm designed for localization of nodes in highly sparse mobile networks. In EMP, each node estimates its location jointly based on its own track sensor devices (3D accelerometer, electronic compass, etc.), its own mobility pattern, and estimated locations of its encountered neighbors. As shown in Figure 2, EMP can be divided into three building blocks.
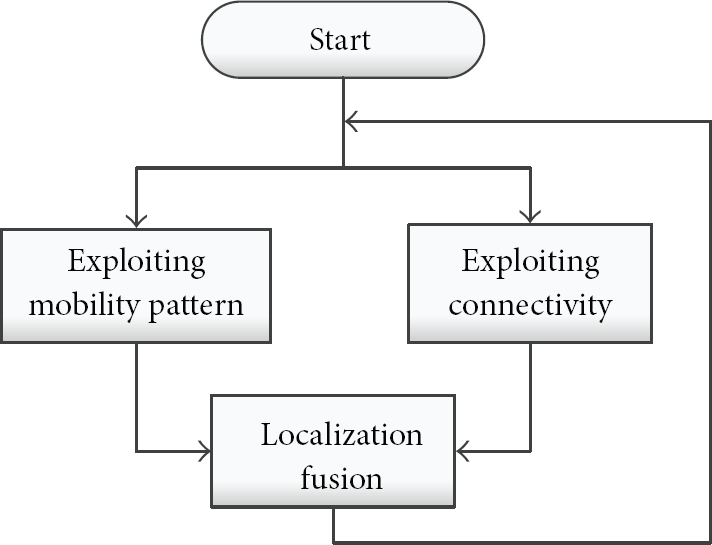
The three major building blocks of EMP and their relationship.
In Exploiting Mobility Pattern, we characterize the mobility pattern of a mobile node with a Markov chain, as introduced in Sections 4.2 and 4.3. In Exploiting Connectivity, the location of a node is consolidated by using the estimated location of an encountered node, as described in Section 4.4. In Localization Fusion, the two localization sources, that is, connectivity and mobility pattern, are fused to derive a better location estimation, as introduced in Section 4.5.
4.2. Characterizing Mobility Pattern
We first show that there are strong mobility patterns with user mobility. To this end, we analyze the real-world user traces from two university campuses (NCSU and KAIST), New York City, Disney World (Orlando), and North Carolina state fair [13, 14] through entropy analysis.
We denote the locations of the nodes as a variable:
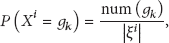
where
The marginal entropy can be calculated as
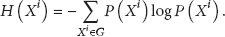
Similarly, the joint probability
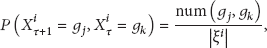
where

The conditional entropy could be calculated as follows:

More generally, the conditional entropy is denoted by
The CDFs of entropies of five real user traces are shown in Figure 3. We observe that the entropies of the users traces are very low. For comparison, we calculate the marginal entropy of a node moving in a random way within a
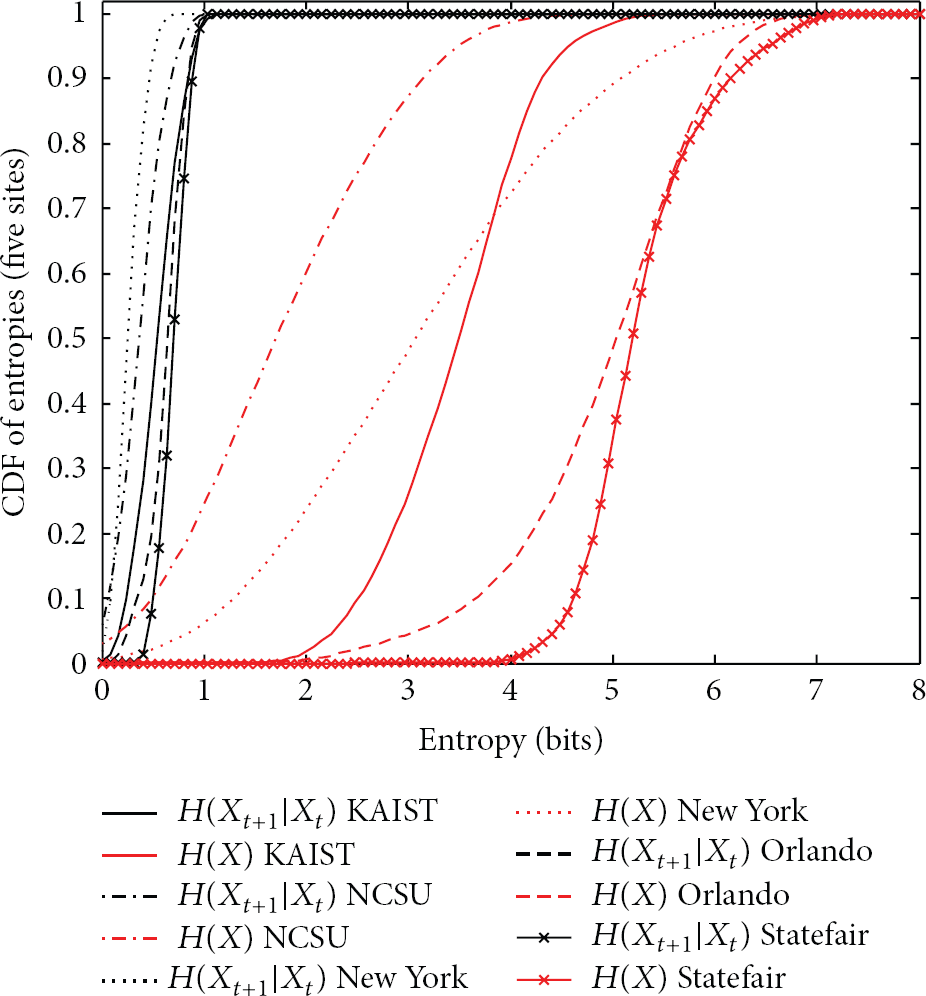
The CDF of the entropies from five real user traces: NCSU, KAIST, New York City, Orlando Disney World, and North Carolina State.
To determine the number of orders for the Markov chain model, we calculate the conditional mutual information as
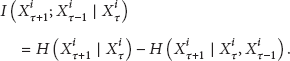
The result of
For implementing the first order Markov chain, the state transition matrix, denoted by Q, could be calculated by

4.3. Exploiting Mobility Pattern
This building block estimates the location of a mobile node by exploiting the mobility pattern of a mobile user. After modeling the movement of a mobile node with the first order Markov chain, the estimate of its location can be obtained:
initially:
after one step:
after k steps:
Note π is the location estimate of the mobile node within the field. For the illustration purpose, we divide a field into

The process of state transition for exploiting mobility patterns.
Clearly, the technique for estimating the location of a mobile node performs well if the mobility pattern of the node is strong. In practice, however, the mobility patterns of some nodes may not be strong. Thus, merely exploiting mobility patterns is insufficient for accurate localization.
4.4. Exploiting Connectivity
This building block aims to estimate the location of a mobile node by exploiting connectivity between nodes. The main idea of this building block is inspired by LOCALE [15] which is a distributed technique for using connectivity for localization of mobile nodes. In this subsection, we first introduce how to represent a location with the location estimate (mean) and the certainty (variance) and then describe how to exchange node's location information with its encountered neighbors.
4.4.1. Location Representation
In probability theory, the central limit theorem (CLT) states that, given certain conditions, the mean of a sufficiently large number of independent random variables, each with finite mean and variance, is approximately Normal distributed. Based on the CLT, we use the location estimate (mean), denoted by E, and the certainty (covariance), denoted by C, to represent the current location of a node.
In the 2-dimensional case, the probability density function of location estimation is



where E denotes the true location and the parameter C denotes the certainty. We can see that only two parameters, C for certainty and
When a node moves through a long period of disconnection, it estimates the location by some low accuracy dead-reckoning tracking devices. The devices are influenced by a great deal of factors, for example, battery condition, wind, temperature, and so forth. The location estimation during this period also follows the Normal distribution. Since the movement covariance matrix is oriented in the moving direction denoted by θ, ρ in

Before the combination of the old estimation distribution

The covariance matrix in the common coordinate could be calculated by the rotation of the local coordinate:
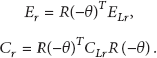
We could calculate the new distribution simply by

Finally, the new location estimation distribution is calculated simply by the linear combination of the old estimation distribution
4.4.2. Exchanging Location Information with Encountered Nodes
As mentioned before, our algorithm is distributed, where the coordinates of the individual mobile nodes are different from each other, shown in Figure 5. To solve this problem, the coordinate transition process is necessary before the process of merging the location estimation from the neighbor nodes.
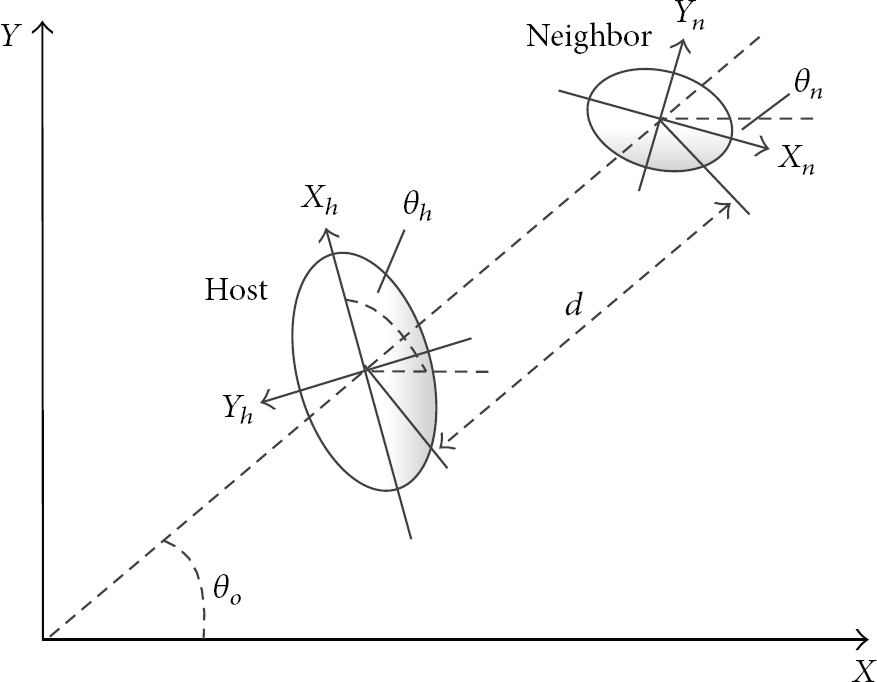
The representation of the host and neighbor nodes with different coordinates.
The operation process of exchanging location information with encountered nodes is shown in Figure 6.

The operation process of exchanging location information with encountered nodes.
In Step 1, we transform the location estimation by rotating the local coordinate to the common coordinate by

In Step 2, the host location estimation could generate a y uncertainty component in the y-axis.
In Step 3, the location uncertainty of the neighbor also influences the y uncertainty component in the y-axis. We add them to the observation component, too.
In Step 4, in the x-axis, the x uncertainty from the neighbor is also added to the x uncertainty component. In the previous operation we have already transformed the coordinate into the relative one, so ρ in
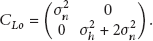
When the host and the neighbor node are in the communication range, the distance between them is a random variable. Here we assume that it is a uniform distribution in the 2-dimensional field. Thus, the distance

In Step 5, with the help of the observation from the neighbor node, the observed

In Step 6, the node localization accuracy could be improved by merging the host node location information and the transformed location information from the neighbor node. Due to the subjective (tracking sensor devices) and objective (environment factor) influence, the nodes location certainties (C) are different from each other. Therefore, we combine the estimation with respect to their certainties (C) acting as the weight.
The merged certainty is calculated by

The merged estimation is calculated by

where the factor K is defined as
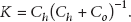
Then we need to rotate the new location to the local coordinate by

where

We can find that the uncertainty of the merged estimation becomes lower as a result of merging the host node location information and the transformed location information from the neighbor. The main principle of Step 6 is as follows. When two nodes can communicate with each other, the physical distance between the two nodes is smaller than the communication range which is a limited value. Before the host node encounters the neighbor node, its uncertainty of location can be large because of the communicative errors of the internal tracking sensor. When encountering the neighbor, its uncertainty can be largely reduced by referring to the location of the neighbor and the limited communication range. The proposed operations in Step 6 are based on this intuition.
4.5. Localization Fusion
This building block fuses the estimated location by exploiting connectivity and the estimated location by exploiting mobility patterns. So far, we have derived two different kinds of location estimation distributions which are very different from each other. The location estimate from exploiting mobility pattern is a discrete location distribution, while the location estimate from exploiting connectivity is continuous. We transform the continuous location into a discrete one by a sampling method.
Previously, we use function

After sampling,

The quantized values are the midpoints of the quantization regions.
After this process, two quantized discrete location estimation distributions are ready to be fused. In order to fuse those two kinds of location estimates, we utilize the median percent area error (MPAE) proposed in [15]. As shown in Figure 7, the MPAE is defined as the area of the smallest circle that includes

where C is defined as the grid number within the MPAE in the circle which contains

The distribution of estimated locations, marked with the median percent area error in the red dash circle.
With two distributions,

After the fusion process, the host's
5. Performance Evaluation
5.1. Methodology and Simulation Setup
To evaluate the performance of EMP, we perform evaluation with simulations with two real user traces from the KAIST campus and New York City. The trace datasets are recorded as follows. GPS receivers record the current positions of users every
We divide the time of the traces into two segments: one is from the morning to the afternoon, which contains almost
We use the mean absolute error (MAE) as our performance metric, which has been widely used by localization algorithms:
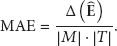
We compare EMP with the following schemes.
LOCALE [15]: it is designed for localization in sparse mobile networks, which utilizes the location information from neighbor nodes when they are within the communication range. The big difference of our EMP from LOCALE is that LOCALE does not consider the inherent mobility patterns of users at all.
Tracking Sensor (
5.2. Comparison over Time
We first examine a typical run of the localization schemes. Figures 8 and 9 report the comparison of EMP, LOCALE, and

Mean absolute error (m) versus time (for KAIST).
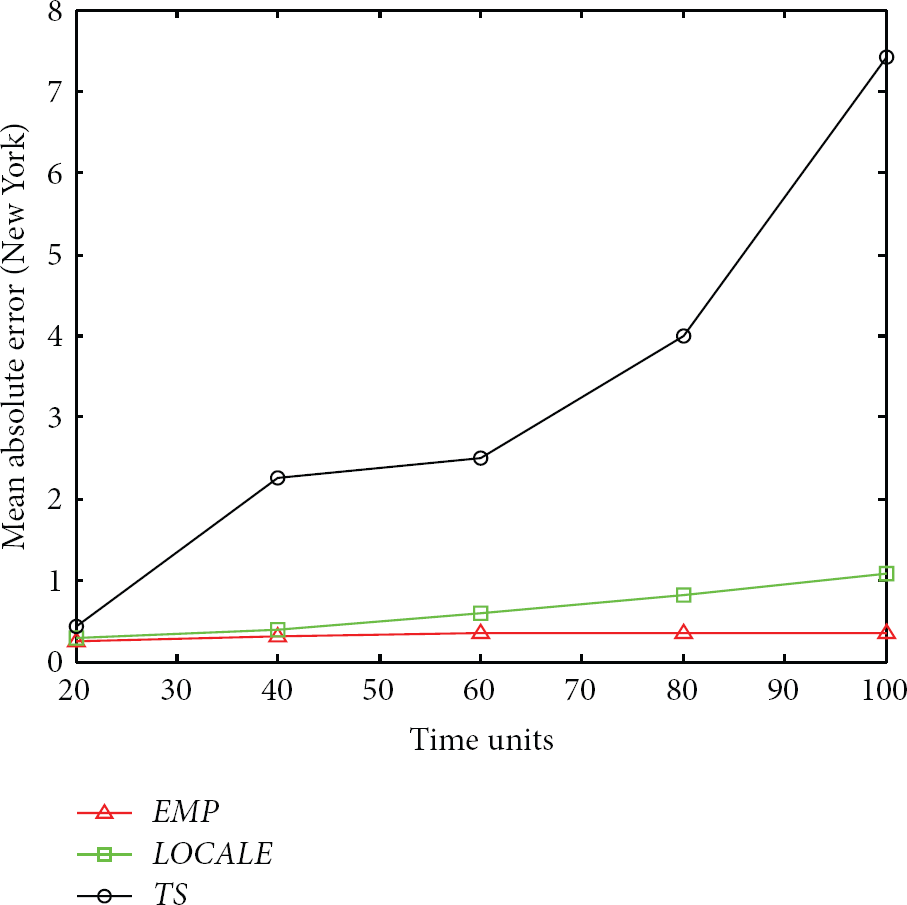
Mean absolute error (m) versus time (for the New York City).
We can see that the MAEs of the three schemes are initially almost the same. This is because the mobile nodes are initialized with an accurate starting location. When it comes to
5.3. Impact of Number of Nodes
We next investigate the impact of the node density on the localization performance. To examine the impact we vary the number of nodes from 10 to 66 for the KAIST trace and from
Figures 10 and 11 report the comparison of the three schemes as the number of nodes is varied for the two traces. We can find that the performance of

Mean absolute error (m) versus number of users (for KAIST).

Mean absolute error (m) versus number of users (for New York City).
5.4. Impact of Communication Range
We then investigate the impact of the communication range on the localization performance of the three schemes. Figures 12 and 13 show the impact of communication range γ on the location estimation for both traces from the KAIST campus and from the New York City, respectively.

Mean absolute error (m) versus communication range (for KAIST).

Mean absolute error (m) versus communication range (for New York City).
We can see that
5.5. Impact of Mobility Pattern
To study the impact of mobility pattern of users on the localization performance, we artificially generate the user traces based on the first order Markov chain. The conditional entropies of our generated traces vary from 0 to 2 bits, which is calculated as

Figure 14 compares EMP and LOCALE. We can find that, for small conditional entropies, EMP significantly outperforms LOCALE. As the conditional entropy becomes larger (i.e., the mobility pattern is not strong), the performance gap between the two schemes becomes smaller. This clearly indicates that EMP can effectively make use of mobility patterns of mobile nodes.
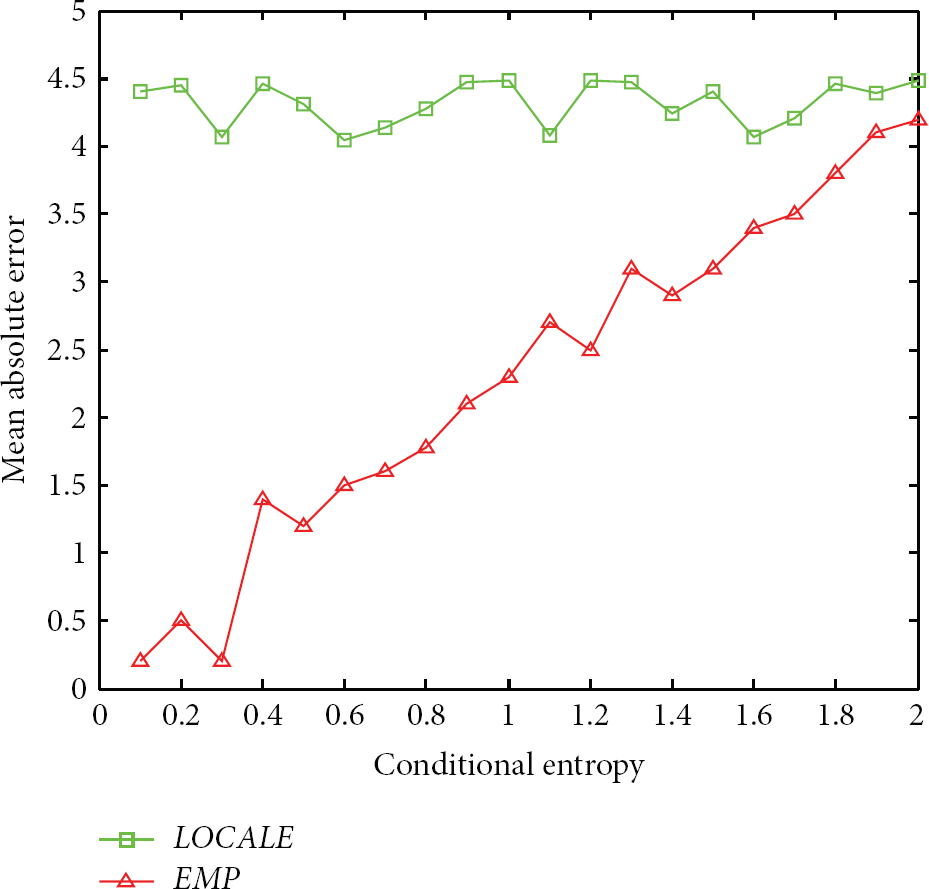
Mean absolute error versus conditional entropy.
6. Conclusion
Location information is valuable for many location-dependent application scenarios in mobile networks. The existing range-based localization is costly because of the hardware for range measurements, and the existing range-free localization requires a high node density. Unfortunately, the high density condition does not hold for sparse mobile networks. By analyzing five large datasets of real users traces with entropy analysis from two university campuses (NCSU and KAIST), New York City, Disney World (Orlando), and North Carolina state fair [13, 14], we have made an important observation that there are strong patterns with user mobility. With this observation, we have presented a localization approach called EMP by exploiting mobility patterns of users for localization of nodes in sparse mobile networks. EMP implements a ranging-free distributed algorithm, with which each user collaboratively estimates its current location by fusing two localization sources, that is, network connectivity and mobility patterns. Upon meeting another user, the location of that user is used to improve the location estimation of the user. At the same time, the mobility pattern of the user is exploited for helping refine its location estimation, and users are differentiated according to the degrees of their mobility patterns. Trace driven simulations show that EMP achieves significantly better localization performance than other existing approaches.
In our future work, we would like to incrementally implement our localization approach in mobile networks where the mobility of the users has strong mobility, for example, in university campuses. However, it should be noted that such an implementation would involve a large number of users. It takes time to accumulate the large number of users.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research is supported in part by 863 Program (2011AA010500 and 2013AA01A601) and Program for Changjiang Scholars and Innovative Research Team in Universities of China (IRT1158, PCSIRT).