
Abstract
Transient faults appear unpredictablly and frequently in networked control systems (NCSs), which directly affect the safety of system. However, they can not be accurately identified due to various kinds of causes, so the detection of them needs more systematic and comprehensive system knowledge. Hence, a hierarchical and systematic detection approach based on function, behavior, and structure (FBS) models is proposed in this paper. The FBS models are established according to systematic knowledge of NCSs. And the transient faults are excavated in node level and system level, in which parameter match and model-based detections are employed. Moreover, the key implementation aspects of the proposed approach in NCSs are detailed on parameterization of FBS models, criteria, and feature parameters of faults, fault monitoring, fault detection, and real-time scheduling considering fault detection. At last, a simulation platform of a networked control liquid mixer system is described by Architecture Analysis and Design Language (AADL), and a transient fault is injected before the sample task in the node for fault detection. The simulation results show that the faults are exposed in the gradual detection hierarchies and the effectiveness of the detection scheme is quite promising.
1. Introduction
Networked control systems are widely applied in modern industrial fields, such as aerospace, automotive and transportation [1, 2]. And to improve system safety, the detection and handling of transient faults are concerned because of their hazards [3–7]. However, the transient fault is hard to be detected and located due to their unpredictable nature and short duration. Transient faults are widely various due to diverse design flaws and environmental interference [8–11], and they occur in anywhere and anytime in the system with a higher rate than permanent faults [12]. And transient faults always remain active for a short period of time and eventually disappear without any apparent intervention [13]. With the increasing system scale and complexity of NCSs, transient faults are unavoidable even though many fault-tolerant methods are considered. For these reasons, transient fault handling is challengeable and imperative for establishing safety control system.
Currently, transient fault detection approaches mainly focus on the models from the knowledge of control mechanism and communication or pure embedded realization platform but not systematic system knowledge for NCSs. Some literatures focus on modeling NCSs from the knowledge of control mechanism and communication. Ahmadi et al. [14] modeled NCS considering network time delay, from which the bound of system stability was discussed for fault detection. Xie et al. [15] modeled NCS considering packet dropout and drew the maxim dropout for fault detection. Zhang et al. [16] modeled the communication task scheduling as system models and conducted the fault detection. The works mentioned above implement the fault detection on account of single or more parameters. Considering that the networked control system is software-intensive, the transient fault detection in NCS needs a systematic approach containing the fault detection in embedded realization platforms. For detecting fault in embedded systems, Pinello et al. [17] discussed the execution platform faults and proposed a fault-detection and tolerance approach, Li and Hong [18] discussed the control flow and data flow model for fault detection in a space control system, and Bernardi et al. [19] discussed the fault detection in a software-implemented approach. Some traditional fault detection architectures (i.e., FTA and CCS) focused on how to detect the source of fault. But considering with the short duration of transient fault and online detection requirements, the sources of transient faults in NCSs are hard to be located and the fault will be detected by subsequent fault propagation effects. At all, to detect the transient faults in NCSs, a novel approach is required considering entire system knowledge. Some literatures have explored this research. To model the system based on entire system knowledge, Chittaro et al. [20] proposed a multimodeling approach with teleological, functional, behavioral, and structural knowledge. Functional and behavioral knowledge are used for fault detection in an intelligent and autonomous system [21], and in [22] entire system knowledge is considered in a system supervisory framework.
In our work, the entire system knowledge is used for system modeling of NCSs and the detection of transient faults is implemented considering the system control and the system realization. As similar to system modeling concepts in [22], we use intentions and means as the knowledge for modeling NCSs, which runs through the conceptual design and the system realization. The intentions contain system functions, and the means contain system structure and behaviors. Function reflects the desired system goals, and it will be achieved by the behaviors of the system. The structure reflects the system realization and it supports the system behaviors. A FBS model covers the system models of NCSs. For fault detection, hierarchical detection is established from node-level to system-level. Node-level detection aims at the faults occurring at the nodes, and the system-level detection concentrates on communication fault, control fault, and fault propagation. Without focusing on locating fault source, the fault propagation effect traces are used to arrange the probes for system monitoring. AADL [23] and its supporting suites are employed to describe the system models. By injecting transient faults and tracking system running, the effects caused by the faults can be identified by parameter matching and model-based detection.
This paper is intended to describe systematic transient fault detection in NCSs. The main contribution is that we proposed a modeling approach based on entire knowledge of NCSs and a transient fault detection approach considering system realization. And to verify the transient fault detection approach, a unified platform based on AADL which reflects the system models is recommended. The remainder of this paper is organized as follows. We analyze the requirements of transient fault detection in NCSs in Section 2. And then we introduce the knowledge for establishing FBS models of NCSs in Section 3. Next, the detailed transient fault detection approach is expatiated in Section 4. Moreover, the implementation of the proposal is explicated in Section 5. A case study is specified on a simulation platform described by AADL and the simulation results are demonstrated in Section 6. Finally, the conclusion and future works are discussed in Section 7.
2. Requirement Analysis of Transient Fault Detection for NCSs
In this section, we first introduce the characteristics of NCSs. And then the transient faults in the system and their causes are inspected. At last, the key issues of the transient fault detection are discussed.
2.1. Characteristics of NCSs
Networked control systems are distributed control systems in which sensors, actuators, controller, plant, and other devices are interconnected by communication networks [24]. A classical architecture of NCS is shown in Figure 1. The architecture contains two parts—plant and a control system based on communication network.

A classical architecture of NCSs.
With increasing application, NCSs are becoming more complex and the scales of them are becoming bigger and bigger. And to implement the control processes, more and more software is embedded in NCSs. All those cause the external interferences and the internal dysfunction to be unavoidable. Thus, fault detection and tolerance are the problems that could not be avoided for establishing a safety control system. As far as we know, transient fault occurs more frequently than permanent fault [11], and there exist some reasonable solutions to permanent fault. So here we focus on the detection of transient fault in NCSs.
2.2. Transient Faults in NCSs
Transient fault is a dominant type of fault in control systems [11], which occur with burstiness and randomness. They are caused by external interferences (i.e., EMI [25], attack [26], and high-energy particle [27]) and internal dysfunctions (design flaw [28], software bugs [29], etc.) which could not be predicted. High occurrence rate and unpredictability lead the transient faults in NCSs hard to be enumerated. Meanwhile, the complex realization of NCSs causes transient faults to be unavoidable; even reasonable fault tolerant control design is considered. On the other hand, a fault could be caused by many factors [30], that leads transient fault hard to be located and eliminated. In NCSs, the source of transient fault may propagate to affect the subsequent operations and brings in a new fault [31]. In the design of transient fault detection, not only traditional fault detection means but also the fault propagation needs to be considered.
2.3. Key Issues of Transient Fault Detection
Because of the natures mentioned above, the implementation of transient fault detection in NCSs generally contains the following issues.
Modeling of NCSs. NCSs is crossing process control, communication, and computer fields, so that single knowledge is insufficient for modeling. The organization of entire knowledge is still a challengeable problem. In the representation of system models, quantitative models are hard to be established and qualitative models are coarse for entire system knowledge. A reasonable combination of these two types of models will be envisaged. Hierarchical detection design. Most often, in the presence of transient fault, diverse phenomenon may be presented at different system levels, and the occurrence time and destructive effect are discrepant. The choices of abstraction hierarchies and faulty phenomenon have a significant impact on implementing real-time and low-cost detection. Real-time assurance. When a fault occurs, we hope it will be detected as soon as possible. And fault detection and system monitoring will bring additional tasks to NCSs. All those need to be taken into account in the implementation and previous scheduling design.
To establish a reasonable transient fault detection approach for NCSs, we use the FBS model for entire knowledge representation, which will be explicated in the next section.
3. Knowledge-Based FBS Models for Modeling NCSs
3.1. Knowledge for Modeling NCSs
System knowledge consists of four types to cover the intentions and the means. Teleological knowledge and functional knowledge are to represent the system intentions, and they can be reflected by functions which reveal the desired actions of the system. Each function is achieved by a group of behaviors which are drawn from the system behavioral knowledge. Behavioral knowledge is about possible behaviors in the system which describes how system or components can work and interact. Generally, variables and parameters are used to characterize the states and the laws which rule their transitions. Structural knowledge is about system topology which describes the constitution of the system and the connection among the components. One behavior is supported by one or more components. And a same behavior may be supported by different components in different system structure. The four aspects of knowledge cover from system design to system implementation. Moreover, they can be correlated systematically by the terms—“achieved by” or “support.” The models of NCSs could be constructed under this knowledge.
3.2. FBS Models of NCSs
Function models, behavior models, and structure models compose the FBS models. FBS models and their relationships are shown as Figure 2. Function models originate from the designer's intentions and the roles of components in the physical processes. Behavior models describe how components work and interact. Structure models describe the system topology and resources. The abstraction hierarchies are interrelated by “achieved by” and “achieves.” A fault occurs in some abstraction hierarchy and it influences the other one. For instance, a faulty behavior in the sensor node will make it lose the sensing function.

FBS models and their relationships.
The function is a characteristic action or activity that needs to be performed to achieve a desired objective. Its realization relies on services provided by the physical components which constitute the system. Each function is achieved by the behaviors revealed in the functional modules. For NCS, the functions can be roughly divided into two categories, namely, communication and control. Furthermore, they can be subdivided into sensing, decision-making, actuating and communicating. Function models of NCS can be quantized by a set of services and their quality, for example, quality of communication and quality of control.
Behaviors describe all the possible potential operations of components in NCS, which can be represented as a sequence of states and transitions. Generally, the behaviors in NCS are expressed as a verb, that is, send, receive, calculate, and rotate, and each behavior can be refined [32] according to the granularity of structural representation. Finite state machine (FSM) [33, 34] is used to describe the states and transitions formally. In our research a behavior is formally represented by a tuple as {Node_ID, Beh_ID, Beh_FSM}. Node_ID denotes the node the behavior carries out, Beh_ID reveals the specific behavior in behavior models, and Beh_FSM is to represent the states and transitions in the behavior.
Structure models describe the resources in the system and their statuses and compositional relationships, which are divided into two level abstractions. In system-level, node is the element. Total number of the nodes and the connection statuses need to be considered. And in node-level, task is thought as the basic element. The execution statuses and the occurring sequences of them are used to represent the node.
To establish the FBS models, the intention will be stated explicitly first, and then the functions need to be listed from the control and communication aspects to support the intention. On the other side, the structure of the system is represented by the nodes and the tasks in node according to the realization, and the behaviors showing on the structures need to be listed in detail. At last, the behaviors and the functions need to be associated with the supporting relationships. The FBS models of NCSs are shown in Figure 3 in which only the system-level structure is considered.

FBS models of NCSs.
4. FBS Model Based Hierarchical Transient Fault Detection
FBS models contain the functional, behavioral, and structural information of NCSs which are exactly used to deduce the fault effects for fault detection. When the information violates the specification, a fault can be identified. In this section a fault detection approach consists of parameter matching and model-based detection is explained.
4.1. Hierarchical Transient Fault Detection Approach
The occurrence of transient faults in NCSs is unpredictable. The detection generally depends on their propagation effects. The effects can be presented as different features in FBS models. Some of them can be explored by simple parameter match, such as threshold and change rate. And the others need to be discovered through a complicated derivation (timing model, schedule, etc.). These features exist hierarchically in the FBS models, and a low-level fault could propagate into a high-level fault if not tolerated. The detection of transient faults in NCSs will be implemented by a hierarchical scheme in which the faults in the nodes and the system are fully covered.
A hierarchical scheme for the detection of transient faults in NCSs is shown in Figure 4. It consists of node-level detection and system-level detection. Parameter match is applied to inspect the characteristic features and the model-based detections are employed to excavate the undetected faults. System level models especially are employed to detect the undetected and propagable faults in node level.

Fault detection framework based on FBS models.

State transition diagram of the behavior “send.”
4.2. Node-Level Transient Fault Detection
Transient faults on node level present as false states or state transitions of task behaviors, control data error, exceeding the threshold of communication load and CPU utilization, and false states of node resources (components). These faults emerge as deviation of the characteristic feature parameters of the system models on different abstraction level. Some of them can be identified by parameter match, but some of them need to be excavated by diverse models. The node-level detection consists of node-level parameter match and model based detection.
During the parameter match, the monitoring data from the probes are compared with the correlative data in a database which contains the symptoms of node-level transient faults that can be enumerated in advance from the experiential knowledge. If the mismatch is discovered, the fault will be reported to the fault manager.
The behaviors in each node are expressed by the models, that is, FSM models and timing models. The detection of this type of faults depends on the rules of the models. Meanwhile, some detection relies on not only the parameters but also the rules of the models. In model-based detection, the violations of the rules are the criterion for the identifications of faults. For example, when the monitoring data input, the output of the model, is out of the specified domain, then a violation appears.
4.3. System-Level Transient Fault Detection
Transient faults on system level are presented as the errors of external characteristics of the plant and the control system. System error of the plant is defined as the mismatching between the desired value and the observed value of the outputs of plant and the state variables of the observations. The error of the control system is defined as the degraded performance of control system, for example, some tasks cannot be scheduled because of the suddenly increasing network loads. Some parameters are used to represent the system errors, that is, the output of the plant, the communication time, the network bandwidth, and the utilization.
In system level parameter match, the monitoring system characteristic data from the probes, such as QoC and QoS, are used to compare with the correlative data in a database which reflects the symptoms of node-level transient faults that can be enumerated in advance from the experiential knowledge for transient fault detection. If mismatch is discovered, the fault will be reported to the fault manager. In another side, the undetected and propagable faults from the nodes will be excavated based on the system level models, that is, computing models for delay and control models for the plant. All the fault messages will be reported to the fault manager.
5. Implementations of Hierarchical Transient Fault Detection in NCSs
The detection of transient faults is conducted based on the observable parameters in the knowledge representation of NCSs. In this section the FBS models are parameterized to depict the measurable parameters in NCSs firstly, which coverage the resources, FSMs, and flags. And then the fault judgments in NCSs are provided to ascertain the criterion of fault. Next, the implementation of the monitors and the detectors is specified in detail. At last, we discuss the task schedule for real-time assurance considering the increasing tasks and loads due to the inserted fault detection.
5.1. Parameterized FBS Model Representations of NCSs
Structure models consist of the resources, such as hardware and software, and their statuses and relationships. On system level, each node is identified by the only Node_ID. And a tuple {node(i), {related_node(j)}, status}
Behavior models contain communication models, scheduling models, node task executing models, and plant operating models. These models are formally described based on extended finite state machines (EFSM) [35]. An EFSM is a 6-element tuple (S,
EFSM = (S, s0, E, f, O, V) (1) States (S) = {WAITED, TRANSMITTED, RESENT, FAULT-REPORT}. (2) Initial State (s0) = {WAITED} (3) Events (E) Events = {REQ, ACK, SEND, RST, TIMEOUT}. (4) Transition Function (f) = {described in the state transition diagram in Figure 5} (5) Output Signals (O) = {Transmitted (message), Return Error (error message), Re-Transimitted (message)}. (6) Variables (V) REXMT: Retransmission Timer TIMEWAIT: Time-wait Timer
Every function can be represented by a phrase, that is, data acquisition and valve open calculation. They can be characterized by functional flags, QoC parameters, and QoS parameters. Generally, the functions in NCS are classified according to the requirements such as “to acquire the monitoring data and send them to the controller,” “to collect the monitoring data and make control strategies,” and “to receive the strategies and affect the control inputs of the plant.” A functional flag which is valued by correctness or fault is to assess whether the function is met. QoS is to evaluate the communication and QoC is to estimate the effect of control strategies. QoS parameters contain collective latency, collective packet loss, collective bandwidth, and information throughput. If these parameters exceed the thresholds, a fault may happen. QoC parameters contain the real-time performance of the control strategy and the predicted and measured control errors of the objects. And the functional structure integrity of whole system is also a critical factor, which is used to reveal that the system is under close-loop control by a series of functional flags.
5.2. Judgments of Transient Faults in NCSs
The transient fault judgments depend on the observable attributions of the faults. The transient faults in NCSs are characterized on system level and node level. System-level fault symptoms contain nonschedulability of the communication loads, incorrect QoS of network, non-real-time capability of the control strategies, imperfection of the functional structure, and uncontrollability of the system under the controller. And node level fault symptoms contain nonschedulability of the tasks in each node platform, output error of the plant (i.e., temperature, current, angle, etc.), incorrect state transitions (violations of the transmission rules), unexpected working states during operation (full CPU utilization, insufficient memory usage, etc.), and variables exceeding the predefined thresholds (collected data variables, such as outputs, observable transmitting state variables in nodes, and plant).
Actually, the detection of transient faults is to identify the violations of the state transitions and the unaccepted errors of the variables. Generally, the fault symptoms appear not only on node level but also on system level. Therefore, these feature parameters of faults can be obtained on different levels.
5.3. Two Level Monitors
The monitors in the system are categorized as system level monitor and node level monitor as shown in Figure 6. QoS monitor is deployed in master nodes, in which the time stamps, sequence and number of the messages are used to acquire the collective latency and the collective packet loss and a message sender in slave nodes and a collective bandwidth tester and an information throughput tester in master node are employed to measure the bandwidth and throughput. QoC monitors measure the whole time of the sampling, processing and actuating and communicating in a control period. Schedule monitor gets the flag of the communication scheduler, and functional integrity monitor supervises the connectivity of the nodes and the correctness of the node functions. And control performance monitors measure the output errors of the control objects by comparing the predicted value with the measured value.

Categories of monitors for transient fault detection.
On node level, there are four types of monitors: communication monitor records the states and the state transitions of the communication behaviors; task schedule monitor gets the flag of the task scheduler; resource monitor supervises the hardware platform running statuses (i.e., CPU utilization and memory usage); function monitor records the states and the state transitions of the task executing behaviors in which the function is defined as a correct execution process.
The QoS monitors are waked up if the QoC parameters are abnormal. And the schedule monitors are working when the task or load is changed. And the other monitors work once at every control period. Obviously, a part of the monitoring data can be processed at the slave node for fault detection, and the others can be processed at the master node. Therefore, hierarchical detections are wanted to carry out fast and systematic fault detection.
5.4. Hierarchical Fault Detector
Fault detectors consist of two types of detectors. Node-level detector is deployed in each single node, and system-level detector is arranged in master node. In the detectors, anomaly detection [36] is employed to identify the faults. Feature parameters and diverse models with constraints are specified in a database declared previously. Some of the monitoring variables are directly compared with the feature parameters to find the feature exceeding the threshold, and the others are inspected by the models to discover the nonconforming patterns as anomalies. The architecture of the detector is shown in Figure 7.

Architecture of the detectors.
Three types of monitoring data are addressed at the node-level detectors, such as node resources, node behaviors, and node running statuses. On the other hand, the data from system level monitors are processed by the system level detector. All the detectors are driven by the events from the corresponding monitor.
5.5. Scheduling for Real-Time Fault Detection
Data monitoring and fault detection increase the node tasks and the communication loads, which may influence the real-time performance of the control system. In master-slave manner control networks, the partition of the time slots for each slave node is flexible according to the schedule mechanism, in which the increasing communication loads and tasks in node are considered. In a multitasking system, we divide the tasks in the system into four types: initial tasks for control Task_init, sub control tasks Task_ctrl, communication for control Task_com, and others Task_other. Meanwhile, a control period is divided into three stages as sensing, processing, and actuating. A global system task schedule scheme is shown in Figure 8. Different nodes are dispatched with different tasks for the implementation for the close loop control. For example, a sensor node may execute initialization, communication, and control tasks. The control tasks specially contain monitoring and fault detection. In each node, the other time slots for the other services are scheduled by some well-known algorithms, that is, RM [37], and EDF [38–40].
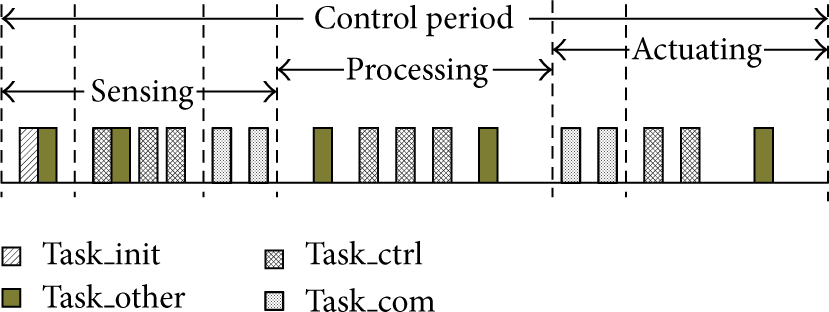
Global system task schedule.
In each communication stage, all the communication tasks in each relevant node can be scheduled by the algorithms mentioned above. In the slave node, the fault report will be treated as a sole task. In such a manner, the node level faults are detected by the local detectors in the dispatched task stage instantly and the detection of the system level faults are achieved in a certain time, which ensures the real-time control of the system.
6. Case Study
In this section, a networked control liquid mixer system (NCLM) is described for the verification of the proposed fault detection approach. FBS models of the NCLM are built up for the analysis of fault detection, and the simulation is conducted based on AADL suites.
6.1. Networked Control Liquid Mixer System
The networked control liquid mixer system is shown in Figure 9. A tank is used to hold liquid for a certain chemical reaction, and the temperature needs to be kept at 60°C within a margin of error (

Networked control liquid mixer system.
The flow rates

Each subfunction is supported by the behaviors of the nodes. The detailed specification of the function models of NCLM is shown in Table 1. Two functions and five subfunctions are used to portray the intention of the realized control system, and a series of node behaviors are listed. SF1, SF3, and SF5 are subject to F1, and SF2 and SF4 are subject to F2.
Function models of NCLM system.

Different behaviors may co-exist in one node, and each of them has different impact on the subfunctions. For example, B (TSN, sample) and B (TSN, send) are produced by the same node TSN, but one is to obtain the temperature of the plant and the other is to send this data to the controller. The behaviors of NCLM system are supported by the realized control system, which is rendered as the node behaviors, such as send, receive, schedule, and sample. And they are classified into three categories, which are shown in Table 2.
Behavior models of realized control system.

The structure models of NCLM contain global node resources, node tasks, CPU state and memory size, and QoS and QoC (real-time performance). The global node resources are denoted by {(CCN, all, connectivity), (VCN, CCN, connectivity), (VON, CCN, connectivity), (FLMN, CCN, connectivity), (TSN, CCN, connectivity), (FON, CCN, connectivity)}. Node tasks are listed as
The function and the behavior are associated with each other according to the supporting relationships, while different tasks in the nodes are linked to different behaviors. By detecting the violations of the specified FBS models, the transient faults will be exposed.
6.2. Simulation Based on AADL Tool Suites
The simulation platform of the NCLM system is described by AADL in Open Source AADL Tool Environment [42]. The architecture of the NCLM system is shown in Figure 10. Seven AADL processes are used to model the six nodes in the realized control system and the plant. The six nodes are connected by CAN network. The plant is linked with the sensor nodes and actuator nodes through the IO bus.

Architecture of the described NCLM system.
The tasks in TSN nodes are described by AADL threads as shown in Figure 11. Three application tasks (TSNcomm, TSNfilt, and TSNsample), one initialization task (TSNsyn), and three fault detectors (TSNFD3T, TSNFD2T, and TSNFD1T) are stated. Considering the causal relationships of the tasks and real-time fault detection requirement, the tasks are scheduled as the sequence as “TSNsyn, TSNsample, TSNFD1T, TSNfilt, TSNFD2T, TSNcomm, TSNFD3T.” By a reasonable assessment, we know that the total execution time of the tasks is under 20 ms which satisfies the global schedule requirement. Besides the plant node, the other nodes are scheduled similarly. Because of the different control period specially, the tasks of the temperature control are dispatched into the idle slots of the level control.

Task dispatch in TSN.
In this simulation system, the temperature, liquid level and flows, and the opening degrees of the valves are selected as the fault features for fault detection. A lot of monitors in different nodes are preset for probing these variables, which are described in the fault detection tasks. And the suspected monitoring data and fault messages are clustered in the last detector before reporting to the system-level detector. Eighteen detectors are designed for the fault detection. The periodic scheduling table is shown in Figure 12. During each liquid level control period, interactive tasks are dispatched in pairs. When the tasks for temperature control are joined, the corresponding tasks appear in node CCN which are highlighted by the red circles. The other tasks for other services are not considered in this table, which will be arranged in the idle slots.

Schedule table for the tasks in NCLM system.
6.3. Experimental Results
To verify the detections of the transient faults in NCLM, a random transient liquid level fault at the sample task in FLMN node is injected once. The fault injection time is displayed in the corresponding window for monitoring the node as shown in Figure 13(a). At the fourth level control simulation period, a level fault occurred by which the level was changed to 1.152. The detector in this node immediately discovered this fault after the sample task by parameter match, and the change rate of the level is used to check the fault in the filter task, by which the fault will be exposed and the detection timing conformed to the sequence of the task schedule.

(a) Display of the nodes, (b) temperature comparison in normal operation and with fault injection, (c) level comparison in normal operation and with fault injection, and (d) flow comparison in normal operation and with fault injection.
In the upper right of the CCN window in Figure 13(a), the opening degree of valve
The flow for level control,
In all, the results show that the injected transient fault can be detected hierarchically by the proposed fault detection approach. The transient faults can propagate into the subsequential behaviors that make the goal lost, and the detection through the FBS models can be carried out according to their effects in different hierarchies.
7. Conclusion and Future Works
The detection of transient faults in NCSs depends on their effects on the system. FBS models can structurally represent the entire knowledge of NCSs, which are suitable for the detection of the transient faults. The structure models of NCSs consist of the resources in the system and their statuses and compositional relationships; the behavior models describe the possible potential operations as a series of EFSMs; and the function models reveal the goals of the realized system by the functions presented in the nodes and the subsystems which are parameterized by a specified functional state sets. Their mapping relationships show the feasible paths the fault propagates. Hierarchical transient fault detection employs parameter match and model based detection to identify the faults as many as possible. In the former the features are compared with their predefined scopes and in the latter diverse models are utilized to analyze the anomalies. The monitors and the detector inserted in the system increase the number of tasks, so task schedule in advance is exhibited. After validating the schedulability, AADL suites are used to describe the simulation platform of NCLM for the verification of the proposal. The results show that the transient faults can be exposed hierarchically.
Currently, the scheduling analysis of the bursted tasks can only be conducted offline and the proposal is only applied for the analysis of a simple control system. In the future, the online schedule analysis will be enhanced and the applications will be expanded to more complex industrial control systems.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported by the Natural Science Foundation of China (no. 61074145 and no. 61272204).