
Abstract
Video sensor networking technologies have developed very rapidly in the last ten years. In this paper, a cross-based framework strategy for cost aggregation is presented for the depth map estimation based on video sensor networks. We formulate the process as a local regression problem consisting of two main steps with a pair of video sensors. The first step is to calculate estimates for a set of points within a shape-adaptive local support region. The second step is to aggregate the matching cost for the gradient-based weight of the support region at the outmost pixel. The proposed algorithm achieves strong results in an efficient manner using the two main steps. We have achieved improvement of up to 6.9%, 8.4%, and 8.3%, when compared with adaptive support weight (ASW) algorithm. Comparing to cross-based algorithm, the proposed algorithm gives 2.0%, 1.3%, and 1.0% in terms of nonocclusion, all, and discontinuities, respectively.
1. Introduction
Wireless sensor networks (WSN) have drawn the attention of the research community in the last few years, driven by a wealth of theoretical and practical applications [1, 2]. Recently, as rapid improvements and miniaturization in hardware, a single embedded device can be equipped with audio and visual information collection modules [3]. The availability of low-cost hardware is like enabling the development of wireless multimedia sensor networks (WMSNs), that is, networks of resource-constrained wireless devices that can retrieve multimedia content such as video and audio streams, still images, and scalar sensor data from the environment [4–7].
There are many algorithms for developing WMSNs applications [8–12]. In [8], Chi et al. have studied the problem of compression of video surveillance sequences collected by a wireless sensor network. In particular, they have proposed a low-complexity coding framework based on change detection and JPEG-like compression of regions of interest, along with a suitable low-complexity change detection algorithm. Huang et al. have proposed a robot wireless sensor network that can enhance multimedia surveillance and provide the foundation for strategies based on multi-modal sensor integration [9].
In [10], DeBardelaben have investigated techniques that can be applied at each layer of the network protocol stack to produce clandestine, power-efficient wireless microsensor network implementations. Also, a smart camera network has been demondtrated for providing extensive coverage of a large virtual public space, a train station populated by autonomously self-animating virtual pedestrians [11, 12].
Figure 1 shows that several adjacent sensors may have overlapping sensing areas, due to the field of view of the cameras in the sensors. Since the overlapped image region contains information about the alignment of the image, we are able to make an approach for stereoscopic view generation (depth estimation) with a pair of neighboring camera senors. This kind of work can give more plentiful information for object recognition and tracking strategies.

Distributed camera sensors around a sink in WMSN.
To make stereoscopic view generation (depth estimation), many different approaches have been taken towards solving the stereo correspondence problem and great progress has been made within the field during the last decade. Dense stereo matching forms the basis for extraction of a three-dimensional scene structure and involves the identification of, for every pixel in one image, the corresponding pixel in another image [13].
Because individual pixel values are not unique and as corresponding pixels may not have the same values in different views, searching for correspondence at the level of individual pixels produces questionable results. To overcome this problem, local stereo matching algorithms generally aggregate similarities in the areas around each pixel with the implied assumption that all pixels in area have the same depth.
Several algorithms have been proposed in attempts to solve the problem of optimizing the size of the region. Kanade and Okutomi [14] presented a method selecting a window adaptively by evaluating the local variations in both the intensity and the initial disparities. They used a statistical model to represent the uncertainty in the disparity of points over a given window. Veksler [15] proposed an algorithm to choose an appropriate window shape by optimizing over the class of compact windows. A compact window class was achieved via the minimum ratio cycle algorithm. However the selected shapes produced by the methods of Kanade and Okutomi and Veksler are both constrained to a rectangle.
To overcome the mentioned constraints, Okutomi et al. [16] determined regions by recovering precise object edges and obtaining smooth surfaces using multiple stereo pairs and multiple windowing. Yoon and Kweon [17] adjusted the support weight of pixels in a given support window based on the color similarity and the geometric proximity in order to reduce image ambiguity. However, their algorithm consumes a huge amount of memory and has high computationally complexity due to storage of center pixel-dependent support weights. To overcome the computational complexity, Richardt et al. [18] introduced a real-time stereo matching technique based on a reformulation of Yoon's adaptive support weight algorithm.
Zhang et al. [19] proposed a cross local support aggregation algorithm that uses color similarities and connectivity constraints to construct a shape-adaptive full support region on the fly, merging horizontal segments of the crosses in the vertical neighborhood. However the problem of finding the optimal support region and aggregating the matching costs still remains.
We propose a cross-based gradient weight cost aggregation algorithm to find the optimal support region. After constructing a support region, we aggregate matching costs over the support region using gradient-based weights in the outermost pixel of the support region.
Section 2 describes our proposed algorithm in detail, with observations. We verify the performance of the proposed algorithm in Section 3, and conclusions are presented in Section 4.
2. The Proposed Algorithm
Our proposed algorithm is based on the following assumptions:
The final assumption is that the gradient magnitude has a constant bandwidth within the object boundaries. Because each object has different bandwidth of edge magnitude in the boundary, we have aggregated matching costs by weighting factor as edge magnitude to distinguish different depth levels.
Figure 2 shows the overall procedure of proposed algorithm to estimate the depth map. We focus on the cost aggregation step using matching cost after the calculated matching cost initialization.
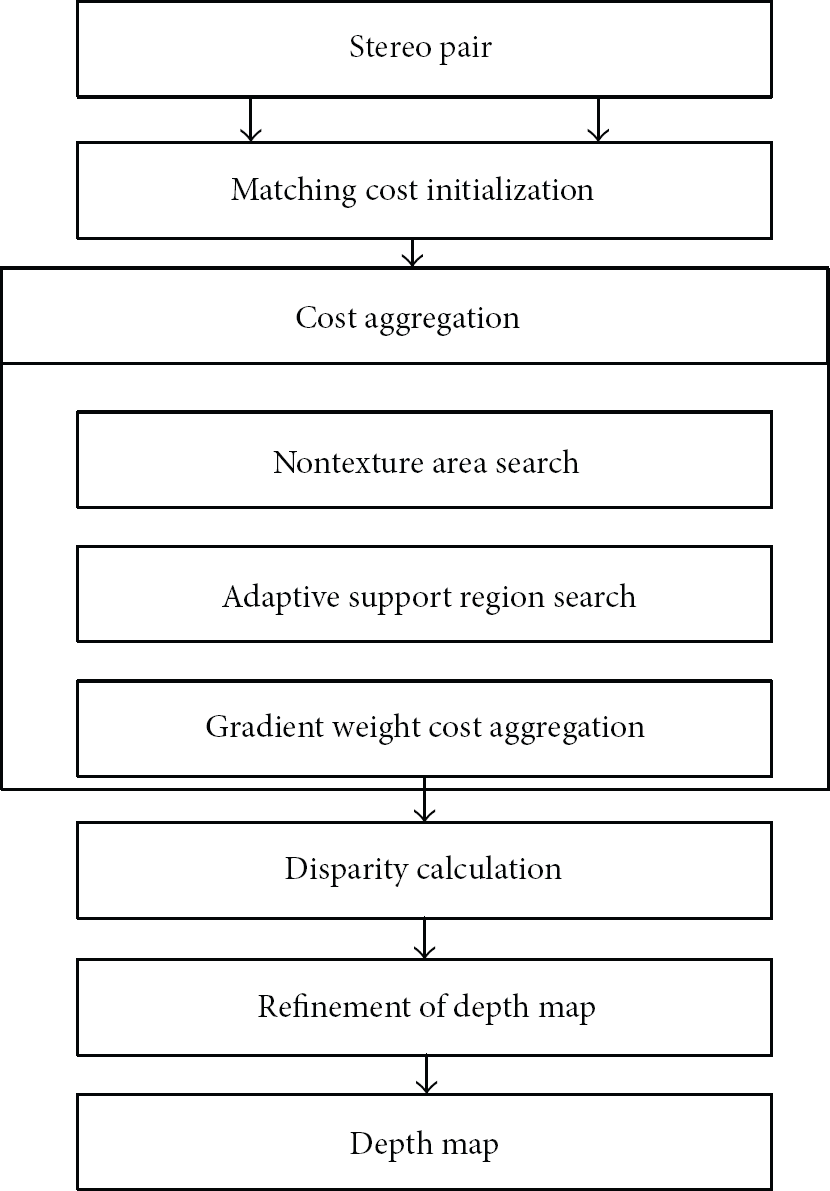
A flowchart of the proposed algorithm.
The proposed cross-based gradient weight cost aggregation algorithm consists of a few stages. First, for each pixel p, a set of four varying support arm lengths is determined for on the image. Before a constructing support region, this step searches the nontexture area in order to limit the support region. Figure 3(a) shows the limited arm lengths

Cross-based gradient weight aggregation processes: (a) region search to limit arm length, (b) construction of support region, and (c) aggregation of matching cost over support region.
Second, an upright cross with four arms is constructed for each pixel. Figure 3(b) shows construction of the support region. For a given pixel, the left arm stops when it finds an endpoint pixel

where

where
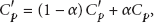
where
The second condition can also be defined as

where
A following step is to aggregate matching costs over the constructed support region. Figure 3(c) shows the aggregation process. We assume the gradient magnitude has a constant bandwidth in the object boundaries. Based on this assumption, our algorithm aggregates the matching cost, which is a given gradient as the weight of the support region at the outermost pixel (yellow block in Figure 3(c)). Aggregation cost is expressed as

where
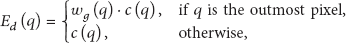
where

where

where
The proposed gradient-based weight has a value in the range
Based on the response of the edge in the object, we designed an adaptive weighting scheme for cost matching. The proposed weighting scheme is based on uncertainty of the edge feature. As the edge becomes stronger, the contribution of the given pixel becomes dominant. Otherwise, the contribution will be decreased in the aggregation stage.
With the proposed gradient-based weight, the proposed algorithm produces a more accurate depth map in the aggregation step for application of wireless video sensor networks.
The overall procedure of the proposed algorithm is summarized as follows (in Figure 2).
First, before constructing support regions, we determined size of support region to find much more homogeneous region.
Support regions are constructed based on the assumption that the same depth level has similar color. To improve the performance, we have to collect the matching costs in the same depth level.
Finally, we have aggregated matching cost over the constructed support region based on the response of the edge in the object. The goal of aggregation step is to collect matching costs of depth levels. To find the correct depth level, we constructed the support region in the same depth area using color similarity and aggregated matching costs weighted by response of edge over support region to reduce disturbance in the object boundary.
3. Results and Discussion
To verify the performance of the proposed algorithm, we tested our system using the Middlebury benchmark [20]. Middlebury defined three measures for evaluating performance, including nonocclusion, all, and discontinuities. The quantitative measure is the percentage of bad pixels in subsets of estimated disparity map, which is defined as

The parameters given in Table 1 have been kept constant for all the datasets. T is the threshold value for checking on non-texture area. τ is the threshold value to compare the color similarity between pixels. Finally, ρ is the threshold value to get a weighting factor. This threshold has been set from average magnitude of edge in all datasets. These parameters have been selected through experiments. Before analyzing our proposed method, we used a Census transform cost measure to initialize the cost volume [21]. Census transform has good performance on images with exposure and light changes.
Parameter settings.

After performing the aggregation step, we used the WTA (winner-take-all) [13] local optimization technique to calculate disparity map.
Figure 4 shows the quantitative performance. We evaluated results by comparing between the ASW algorithm [18] and the cross-based algorithm [19]. We achieved improvements of up to 6.9%, 8.4%, and 8.3% compared with ASW algorithm and improvements of 2.0%, 1.3%, and 1.0% compared with Cross-based algorithm in terms of nonocclusion, all, and discontinuities, respectively.

Errors over the Tsukuba, Venus, Cones, and Teddy test image pairs in quantitative measures.
The proposed method produced an accurate disparity map, as shown in Figure 5. Figure 5(a) shows the ground truth image of the tested venus image. In particular, depth discontinuities were well preserved comparing to the ground truth image. On the other hand, the other methods failed to preserve depth discontinuities. With the proposed algorithm, we can observe that the defects of inside of near objects can be avoided efficiently.

Partial boundary regions in venus image: (a) the ground truth, (b) ASW, (c) cross-based, and (d) the proposed algorithm.
Table 2 shows the Middlebury ranking of the proposed algorithm. Although the Middlebury ranking is low in terms of the overall procedure, we have improved the performance of the aggregation step which is based on the response of edge comparing with other aggregation algorithms. Our key idea is that we design the weight as each magnitude of edge in the object boundary and construct a support region using color similarity in the homogeneous region to improve accuracy, in the aggregation step. In terms of the overall stereo matching procedure, the improvement may be smaller than that of just considering an aggregation step.
Middlebury rank of the proposed algorithm and implemented other algorithms (TH < 1).

From the above results, the average rank has been improved by using the proposed algorithm. From this result, we would like to address that the proposed algorithm has enough contribution in the aggregation step.
4. Conclusions
We have proposed a cross-based gradient weight cost aggregation algorithm for efficient depth map estimation of WMSNs. We constructed an adaptive shape support region and aggregate matching costs by efficiently using gradient-based weight within the support region with a pair of neighboring camera sensors. Using the proposed feature and our algorithm, we verified promising results compared with the other aggregation algorithms.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported by the agency specific research program of MSIP, Republic of Korea (Development of Multi-Sensor Platform Technology for Context Cognitive Smart Car).