
Abstract
Though there are a number of benefits associated with cellular manufacturing systems, its implementation (identification of part families and corresponding machine groups) for real life problems is still a challenging task. To handle the complexity of optimizing multiple objectives and larger size of the problem, most of the researchers in the past two decades or so have focused on developing genetic algorithm (GA) based techniques. Recently this trend has shifted from standard GA to hybrid GA (HGA) based approaches in the quest for greater effectiveness as far as convergence on to the optimum solution is concerned. In order to prove the point, that HGAs possess better convergence abilities than standard GAs, a methodology, initially based on standard GA and later on hybridized with a local search heuristic (LSH), has been developed during this research. Computational experience shows that HGA maintains its accuracy level with increase in problem size, whereas standard GA looses its effectiveness as the problem size grows.
1. Introduction and Literature Review
The current manufacturing systems are facing a number of challenges in the form of globalization, shrinking product life cycles, variable demand patterns, more customized products, and ever decreasing “time to market.” These challenges can be tackled through effective and reliable manufacturing systems that can reduce the manufacturing cost and meet the manufacturing requirements timely and effectively, thus helping the manufacturer to compete with his competitors. Implementation of cellular manufacturing systems (CMS) can help the modern day manufacturers to face these challenges efficiently all in terms of cost, quality, and availability.
CMS is based on the philosophy of group technology (GT) which means similar tasks should be grouped together and handled in a similar fashion. According to Hyde [1] “GT is a technique for manufacturing small to medium lot size batches of parts of similar processes, of somewhat dissimilar materials, geometry, and size, which are produced in a committed small cell of machines which have been grouped together physically, specifically tooled, and scheduled as a unit.” Mitrofanov [2], Ranson [3], and Burbidge [4] provided guidelines for implementing GT in a cost effective and efficient manner without investing hugely in new equipment. According to Askin and Standridge [5], GT is a philosophy in which production of similar products is performed in a similar fashion. GT is mainly focused on the grouping of parts or products into specific cells based on similarities in their production requirement. At shop floor, the term traditionally used for the description of such systems is “cellular manufacturing (CM).” “(CM) is the formation of independent groups of functionally dissimilar machines and workstation types, located together on the floor, dedicated to the manufacture of a family of similar parts or products” (Irani, [6]). Singh [7] reported a number of benefits such as reduced setup time and throughput, increased worker satisfaction, and product quality.
In spite of so many benefits, implementation of CM (identification of part families and corresponding machine groups) is a challenging task. This is the reason that this problem has been extensively researched around the world for the last 60 years or so. A number of techniques have been reported in literature for solving the CMS design problem. Some widely known methods include classification and coding, array based clustering, similarity coefficient, mathematical programming, and artificial intelligence (AI) based algorithms.
Classification and coding technique is based on assigning numerical codes to different design and manufacturing attributes of a part and then grouping of parts is carried out on the basis of these codes. Mitrofanov [2] and Opitz [44] have put in a great deal of effort in developing this technique. Generally it is considered as a complex and hugely time consuming technique.
Array based clustering is considered as one of the simplest CMS design techniques. It uses machine part incident matrix in the form of 0's and 1's as input and provide results in block diagonalized shape. McAuley [45], Carrie [41], and Miltenburg and Zhang [46] used clustering techniques in their models. In similarity coefficient approach similarity among parts is developed based on their design and manufacturing attributes and on the basis of these similarities grouping is carried out. Lozano et al. [47] and Yin and Yasuda [48] used similarity coefficient approach in their models.
Mathematical programming based approaches possess the potential of solving the CMS design problem optimally and this is the reason that such approaches have been extensively used to solve the cell formation problem. According to Mungawattana [49], “Obtaining optimal solution for the mathematical programming approaches can be infeasible due to combinatorial complexity of the CMS design problem.” Chen & Heragu [50], Won [51], and Akturk and Turkcan [52] used mathematical programming based approaches in their models.
In the last two decade or so, AI based approaches have been extensively used to solve the cell formation problem (CFP). The main reason is their ability to handle large size problems and convergence to optimum solutions within the physically possible time. The widely known techniques of AI are (i) artificial neural network (ANN) (Kao and Moon [53]), (ii) fuzzy logic (FZ) (Susanto et al. [54]), (iii) simulated annealing (SA) (Tavakkoli-Moghaddam et al. [55]), and (iv) genetic algorithm (gA) Gupta et al. [56], Gravel et al. [57], Zhao and Wu [58], and Uddin and Shanker [59].
According to Ghosh et al. [60], among all the AI based techniques, GA is considered to be the most competent algorithm in handling the CMS design problem. Earlier, similar views were given by Mungawattana [49]. A large number of researchers used GA to solve the CFP such as Venugopal and Narendran [61], Joines et al. [62], Gravel et al. [57], Mak and Wong [63], Zhao and Wu [58], Wu et al. [64], Chu and Tsai [10], and Chan et al. [65].
Since GA is considered as an effective tool for the optimization of CFP therefore it remained the focus of prime interest of researchers in the early 90's. As the manufacturing systems became more and more complex with the passage of time, the researchers’ interest abstracted towards the development of multiobjective models. This increased the complexity of the CFP, thus requiring higher computational effort, time, and accuracy. To achieve these objectives and to enhance the convergence capabilities of GA, the focus of researchers shifted from standard GA to HGA based methodologies. A number of such approaches are listed in Table 1.
List of researchers who use hybrid genetic techniques.

Most of these approaches have produced some incredible results. Apparently this effectiveness seems to be because of the hybrid nature of these strategies, thus suggesting that HGAs have better convergence abilities than standard GAs. This has been generally reported in literature by a number of researchers but exact quantification of the difference has been rarely carried out. Therefore, this was the basic motive of this research to quantifiably verify this difference. For this purpose a methodology initially based on standard GA is developed during this research and a number of benchmark problems are solved. Later on the approach is converted into an HGA by combining it with a local search heuristic (LSH) and solving the same benchmark problems again using the similar parameters. A comparison of the result shows that HGA easily outperforms the standard GA.
2. CFP
The CFP can generally be divided into two subproblems. Identification of part families followed by grouping of corresponding machines into cells with the aim of reducing intercellular moves and increasing the within cell machine utilization. In some techniques these two subproblems are solved sequentially whereas in some they are handled simultaneously. The approach developed during this research is a simultaneous one. It uses information about the total number of parts and machines in the system, the total number of cells in which the system is required to be divided into and machine part incidence matrix (MPIM) in 1-0 form of size M × P (M = Total Machines, P = Total Parts) as inputs. Grouping efficacy (GE) has been chosen as the objective function (performance factor) as it possesses the ability of minimizing intercellular moves and at the same time maximizing the within cell machine utilization. The output of the approach is the block diagonalized form of the MPIM identifying different part families and their respective machine groups.
3. Model
A mathematical model for the above mentioned problem is developed based on the following considerations:
maximizing GE is to be the objective function;
each cell is to be assigned at least one machine and one part

subject to
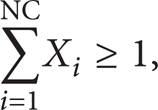
where NC = Total number of Cells, X i = Total 1's in Cell “i,” i = 1,…, NC, and E = Total number of 1's in MPIM
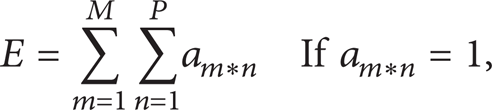
where a = Any entry in the machine part incidence matrix (it can be either 0 or 1), M = Total number of Machines, P = Total number of Parts, m = 1,…, M (Total number of Machines), n = 1,…, P (Total number of Parts), Evoids = Total number of 0's inside the cells (Block Diagonals)

b = A variable used to count voids in a cell, M n = Number of Machines in cell “i,” P n = Number of Parts in cell “i,” and Ein = Total number of 1's inside the cells (Block Diagonals)
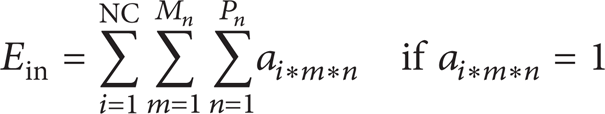
Eout = Total number of 1's outside the cells (Block Diagonal), Eout = E − Ein.
4. Methodology
The methodology developed during this research mainly consists of two steps. In the first step a standard GA based algorithm is developed. After getting it tested with a number of benchmark problems it is converted into an HGA by combining it with an LSH and testing it again with the same benchmark problems. The HGA methodology is shown in Figure 1.
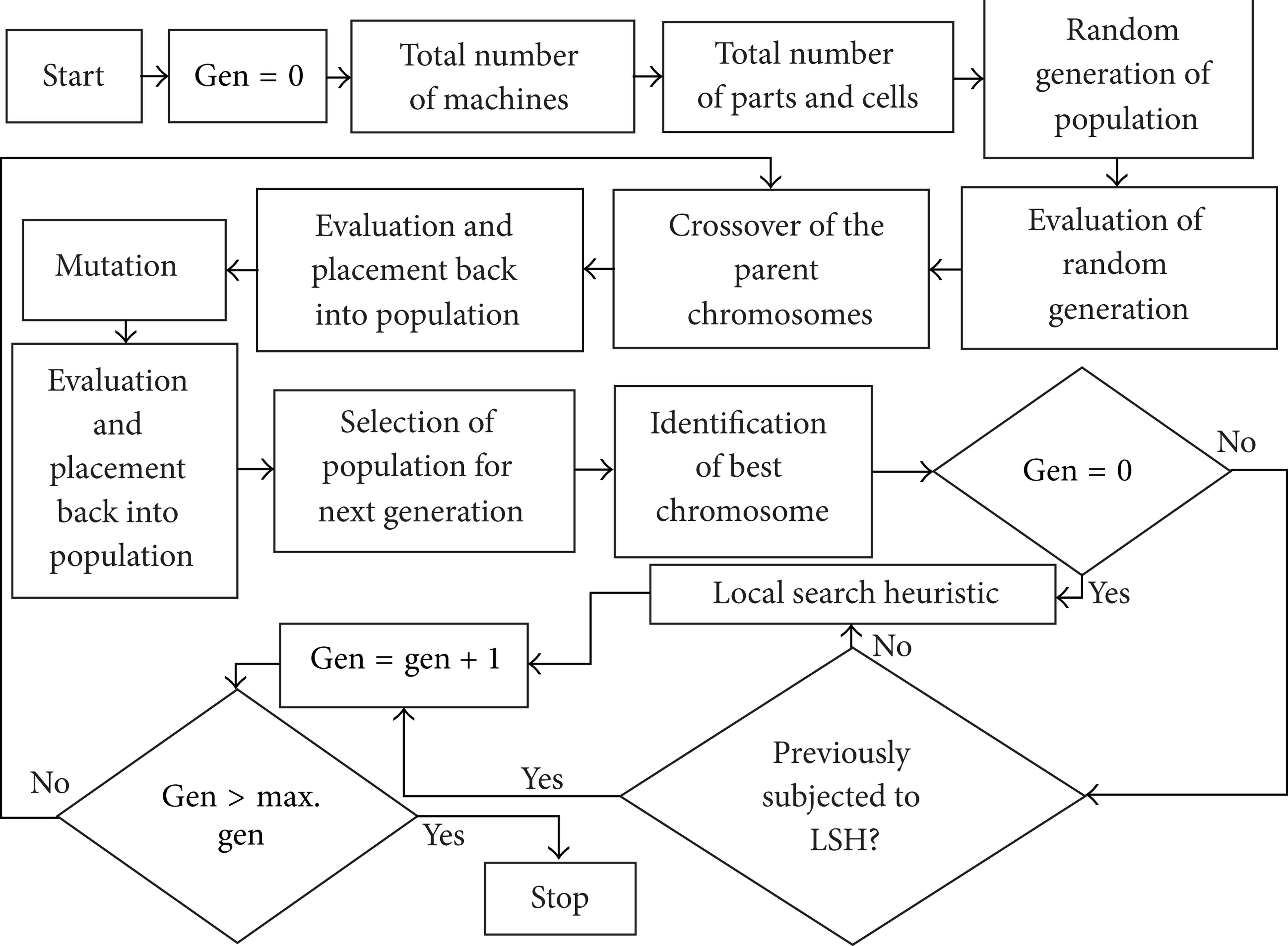
HGA methodology.
4.1. Genetic Algorithm (GA)
The idea of GA is based on Darwin's theory of evolution and was initially introduced by John Holland in 1975. It uses the principles of natural genetics and natural selection for searching out the optimum solution of a problem. The ability of GA to avoid local optimums has made it more attractive as far as combinatorial optimization problems are concerned.
GA starts with an initial population of randomly generated solutions and then by using the genetic operators of crossover, mutation, and selection, the continuous evolutionary improvement of the solutions is carried out till the time the optimum is achieved.
4.1.1. Representation
Representation is the first step in implementing GA to a problem. In this paper, integer based representation is used. The length of each chromosome in the population is equal to the sum of the total number of parts and total number of machines in the system. The location of each gene is associated with a machine or part whereas its value represents the cell number which that machine/part is assigned to. For example, if the total number of parts and machines are 7 and 5, respectively, and they are to be arranged in 2 cells then a chromosome can be represented as shown in Table 2.
Chromosome representation.

MC: machine & Pr: part.
4.1.2. Fitness Evaluation
As GE possesses the ability of simultaneously minimizing intercellular moves and maximizing machine utilization in cells, therefore it is chosen as the fitness function for this problem. The fitness value is calculated with the help of (1).
4.1.3. Genetic Operators
For GA its operators are very important as they are the ones responsible for inducing the property of evolution in GA. This is the reason that ultimate level of care is required while selecting the type of an operator for a particular application.
Crossover. Crossover is the genetic operator in which two parent chromosomes are subjected to produce two new offspring. The type used during this research is a multipoint (two point) crossover technique. The first two chromosomes from the population are selected on the basis of their higher fitness value and allowed to take part in the crossover operation.
Two parent chromosomes are shown as MPA1 and MPA2:

A random number is generated for the machine portion (range: from 1 to number of machines). Let us suppose the number is 3. All the genes in the machine portion of Parent 1 from position 3 onwards are replaced with the genes of Parent 2. Similarly a random number is generated for the parts portion. Suppose that number is 4. Then the same process is repeated for the parts portion too. The two new children produced are as shown below:
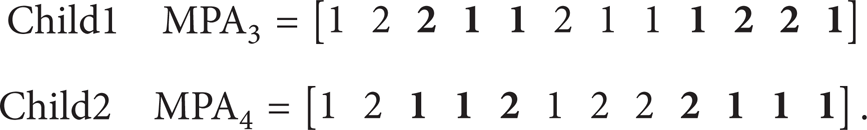
In case of better fitness values these children would replace the weakest solutions in the population. The code is developed in such a way that it would not include any illegal child into population. Illegal chromosome is that in which any cell number (between 1 and total number of cells) is missing in any of the portions (parts and machines). The crossover rate used in this research is 60%.
Mutation. Mutation is another important genetic operator which is used to impart diversity into the population, thus helping GA to avoid local optimums. The type used during this research is swap mutation.
In this type of mutation initially a solution is randomly selected. Then two genes (having different values) each in the parts’ and machines’ portion of the selected chromosome are randomly picked. After swapping their positions the solution is decoded and in case of having better fitness value it replaces the weakest solution in the population. The procedure is elaborated with the help of an example as follows.
Randomly selected solution and its genes:

After swapping the mutated chromosome:

The rate chosen for mutation is 5% of the total number of genes in the population.
4.1.4. Selection
The procedure of breeding new generations from the existing is called selection. There are a number of methods developed and used over the years by researchers, for example, Roulette Wheel selection criterion, Tournament selection, Stochastic Universal Sampling, and so forth. The approach used during this research is Stochastic Universal Sampling (SUS) as it is less biased towards the stronger solutions, thus maintaining the diversity of the population and helping GA to avoid local optimums.
4.2. Local Search Heuristic (LSH)
In order to improve the convergence abilities of GA it has been hybridized by combining it with an LSH. A detailed block diagram explaining the local improvement procedure applied to the best solution in each generation of GA is shown in Figure 2.

LSH methodology.
The uniqueness of this LSH is that unlike Tariq et al. [20] it only changes the cell numbers of those parts/machines which are ill placed that is, having more intercellular moves than the number of operations inside the cell. Such type of local improvement can definitely save time and computational effort.
5. Computational Results
In order to carry out a comparison between the standard GA and HGA, developed during this research, 22 benchmark problems have been solved by both the methodologies using similar crossover/mutation rates and population size. Initially both the algorithms were given a run for similar number of generations; that is, if HGA got the best solution for a problem in 5 generations then GA was also given a run for 5 generations. Once comparison on the similar number of generations was completed then GA was given a complete run for maximum number of generations (150) so that it should have sufficient opportunity to reach the optimum. In addition to these a comparison on the basis of CPU time (using Intel Core 2 Duo 2.66 GHz, having 4 GB RAM) has also been carried out and is given in Table 3 along with the results obtained in both the cases. They clearly show that HGA has outperformed the standard GA, both in terms of accuracy and speed.
Computational results.

In order to further elaborate the difference, results of the tested problems are plotted on graphs as shown in Figures 3, 4, and 5.
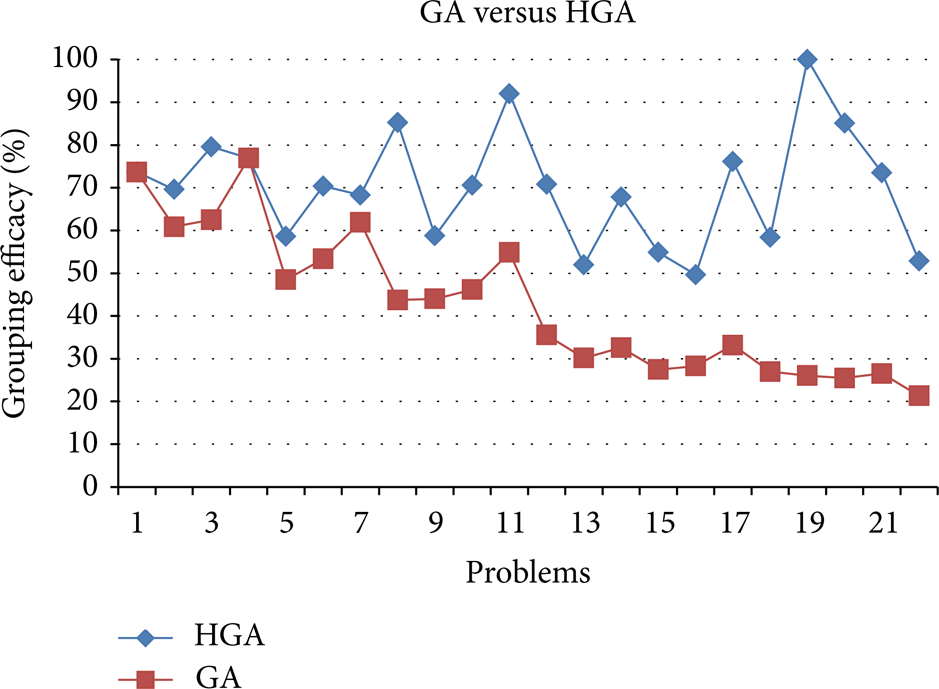
Comparison of GA with HGA (similar number of generations).

Comparison of GA with HGA (GA given maximum number of generations).

Comparison of GA with HGA (CPU time).
The results tabulated in Table 3 and plotted in Figures 3 and 4 show a definite pattern. As the problem size grows the convergence of standard GA on to optimum strays even further especially in the case for similar number of generations as HGA. This behavior, widening in gap of GE for larger problems, is somewhat reduced when GA is given a run for maximum number of generations. On the other hand the results of HGA are consistent and for every problem it returns the best result reported in literature so far (with the constraint on the number of cells). This clearly proves that HGA has better convergence abilities than standard GA.
In addition to the above another comparison on the basis of CPU time is also carried out as shown in Table 3 and Figure 5. Here also, an interesting situation can be witnessed. In case of similar number of generations GA is completing its run quickly but the accuracy is very low as compared to HGA.
In case of maximum number of generations the accuracy of GA has slightly improved but at the cost of CPU time which is even larger than HGA for most of the benchmark problems. So finally it can be concluded that for NP-hard combinatorial optimization problems, HGA based methodologies can prove to be more effective as they tend to reduce the dependence of GA on its parameters in addition to increasing its level of accuracy.
6. Statistical Analysis
The difference in performance, presented in Table 3 and Figure 3, of both the approaches is statistically validated as well. To carry out statistical validation it is necessary to first verify whether the data is normal or not. For this purpose Anderson-Darling and Lilliefors tests are used during this research. The normality tests show that the results of both the methadologies are normal as shown in Table 4. The normality of the data can also be clearly visualized in the graph shown in Figure 6.
Test for normality of the data.
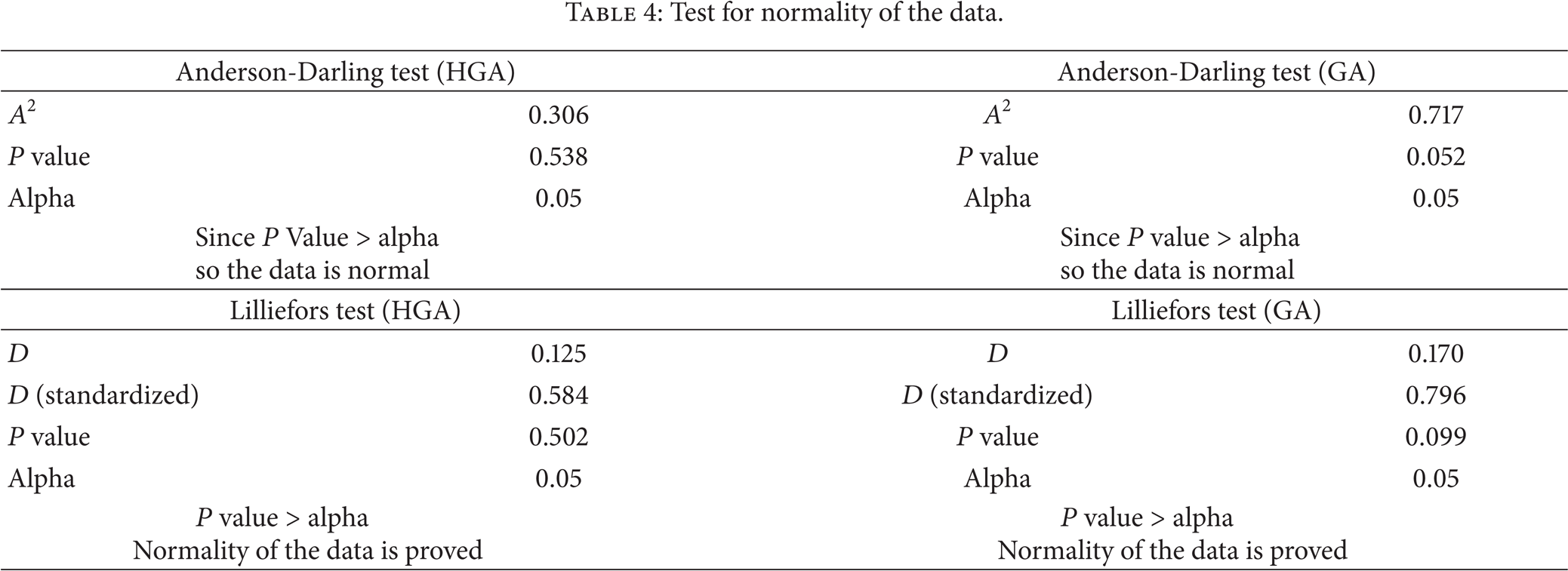

Normality test.
After the normality check, paired t-test is applied to the results of both methodologies by using 95% confidence interval (CI). The value of t-stat is 6.90, which shows that both the methodologies are not performing similarly. The performance of HGA (Mean = 70.21 and St. Dev. = 13.29) is much better than GA (Mean = 42.72 and St. Dev. = 16.78). The results of paired t-test are shown in Table 5.
Paired t-test for HGA versus GA.

95% CI for mean difference: (19.20, 35.76).
t-test of mean difference = 0 (vs not = 0): t-value = 6.90, P value = 0.000.
7. Conclusion
The initial aim of this paper was to assess and compare the convergence abilities of standard GA and HGA. For this purpose, initially a standard GA was developed for the CFP and used to solve a reasonable number of benchmark problems. Later on the same standard GA was hybridized by combining it with an LSH and solving the same benchmark problems again. A comparison of the computational results, based on first giving GA a run for similar number of generations as HGA and then maximum number of generations, shows that HGA has better convergence abilities than standard GA in both the situations as it returned optimum result for each one of the tested problems. The percentage solution gap between the results grows with the increase in problem size, thus proving a point that HGA maintains its accuracy whereas standard GA strays even further. This behavior has been further verified statistically as well.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.