
Abstract
One of the key issues for providing users user-customized or context-aware services is to automatically detect latent topics, users’ interests, and their changing patterns from large-scale social network information. Most of the current methods are devoted either to discovering static latent topics and users’ interests or to analyzing topic evolution only from intrafeatures of documents, namely, text content, without considering directly extrafeatures of documents such as authors. Moreover, they are applicable only to the case of single processor. To resolve these problems, we propose a dynamic users’ interest discovery model with distributed inference algorithm, named as Distributed Author-Topic over Time (D-AToT) model. The collapsed Gibbs sampling method following the main idea of MapReduce is also utilized for inferring model parameters. The proposed model can discover latent topics and users’ interests, and mine their changing patterns over time. Extensive experimental results on NIPS (Neural Information Processing Systems) dataset show that our D-AToT model is feasible and efficient.
1. Introduction
With a dynamic users’ interest discovery model, one can answer a range of important questions about the content of information uploaded or shared to social network service (SNS), such as which topics each user prefers, which users are similar to each other in terms of their interests, which users are likely to have written documents similar to an observed document, and who are influential users at different stages of topic evolution, and it also helps characterize users as pioneers, mainstream, or laggards in different subject areas.
Users’ interests have shown their increasing importance for the development of personalized web services and user-centric applications [1, 2]. Hence, users’ interest modeling has been attracting extensive attentions during the past few years, such as (a) Author-Topic (AT) model [3–5], (b) Author-Recipient-Topic (ART) model [6–8], Role-Author-Recipient-Topic (RART) model [6–8], and Author-Persona-Topic (APT) model [9], (c) Author-Interest-Topic (AIT) model [10] and Latent-Interest-Topic (LIT) model [11], and (d) Author-Conference-Topic (ACT) model [12].
In fact, when people enjoy SNS with their smart devices including phones and tablets, each user's interest is usually not static. However, the above models are devoted to discovering static latent topics and user's interests. Moreover, they are applicable only to the case of single processor. Of course, one can perform some post hoc or pre hoc analysis [4, 13] to discover changing patterns over time, but this misses the opportunity for time to improve topic discovery [14], and it is very difficult to align corresponding topics [15]. Currently, attention for dynamic models is mainly focused on analyzing topic evolution only from text content, such as Dynamic Topic Model (DTM) [16], continuous time DTM (cDTM) [17], and Topic over Time (ToT) [14].
This paper mainly focuses on the dynamic users’ interest discovery model, especially collapsed Gibbs sampling following the main idea of MapReduce [18]. Figure 1 gives a detailed illustration for discovering dynamic users’ interests. Our previous work [19, 20] is limited to inference algorithm on single-processor.

The illustration for discovering dynamic users’ interests.
The organization of the rest of this work is as follows. In Section 2, we firstly discuss two related generative models, Author-Topic (AT) model and Topic over Time (ToT) model, and then introduce in detail our proposed Author-Topic over Time (AToT) model. Sections 3 and 4 describe the collapse Gibbs sampling methods used for inferring the model parameters and distributed inference algorithm version, respectively. In Section 5, extensive experimental evaluations are conducted, and Section 6 concludes this work.
2. Generative Models for Documents
Before presenting our Author-Topic over Time (AToT) model, we first describe two related generative models: AT model and ToT model. The notation is summarized in Table 1.
Notation used in the generative models.

2.1. Author-Topic (AT) Model
Rosen-Zvi et al. [3–5] propose an Author-Topic (AT) model for extracting information about authors and topics from large text collections. Rosen-Zvi et al. model documents as if they were generated by a two-stage stochastic process. An author is represented by a probability distribution over topics, and each topic is represented as a probability distribution over words. The probability distribution over topics in a multiauthor paper is a mixture of the distributions associated with the authors.
The graphical model representations for AT model are shown in Figure 2. The AT model can be viewed as a generative process, which can be described as follows.
For each topic
draw a multinomial for each author
draw a multinomial for each word
draw an author assignment draw a topic assignment draw a word

The graphical model representation of the AT model.
2.2. Topic over Time (ToT) Model
Unlike other dynamic topic models that rely on Markov assumptions or discretization of time, each topic in Topic over Time (ToT) model [14] is associated with a continuous distribution over timestamps, and, for each generated document, the mixture distribution over topics is influenced by both word cooccurrences and the document's timestamp. Thus, the meaning of a particular topic can be relied upon as constant, but the topics’ occurrence and correlations change significantly over time.
The graphical model representations for ToT model are shown in Figure 3. The ToT is a generative model of timestamps and the words in the timestamped documents. The generative process can be described as follows.
For each topic
draw a multinomial from for each document
draw a multinomial for each word
draw a topic assignment draw a word draw a timestamp

The graphical model representation of the ToT model.
2.3. Author-Topic over Time (AToT) Model
The graphical model representations for AToT model are shown in Figure 4. The AToT model can be viewed as a generative process, which can be described as follows.
For each topic
draw a multinomial for each author
draw a multinomial for each word
draw an author assignment draw a topic assignment draw a word draw a timestamp

The graphical model representation of the AToT model.
From the above generative process, one can see that AToT model is parameterized as follows:
As a matter of fact, a paper is usually written by the first author and reprint author. If one wants to differentiate the contributions of the first author and reprint author from those of other coauthors, it is very easy for AToT model to set different weights for different authors. But since there are no criteria to guide the corresponding weights, we just set the equal weights for all coauthors in this work; that is to say,
3. Inference Algorithm
For inference, the task is to estimate the sets of the following unknown parameters in the AToT model:
In the Gibbs sampling procedure, we need to calculate the conditional distribution 
If one further manipulates the above (1), one can turn it into separated update equations for the topic and author of each token, suitable for random or systematic scan updates:


During parameter estimation, the algorithm keeps track of two large data structures: an 

As for 
With (2)–(6), Gibbs sampling algorithm for AToT model is summarized in Algorithm 1. The procedure itself uses only seven larger data structures, the count variables
// initialization zero all count variables, sample topic index sample author index // increment counts and sums // Gibbs sampling over burn-in period and sampling period // decrement counts and sums sample author index sample topic index // increment counts and sums update // different parameters read outs are averaged read out parameter set read out parameter set
4. Distributed Inference Algorithm
Our distributed inference algorithm, named as D-AToT, is inspired by AD-LDA algorithm [29, 30], following the main idea of the well-known distributed programming model, MapReduce [18]. The overall distributed architecture for AToT model is shown in Figure 5.

The overall distributed architecture for AToT model.
As stated in Figure 5, the master firstly distributes M training documents over P mappers, with nearly equal number
In each Gibbs sampling iteration, each mapper p updates 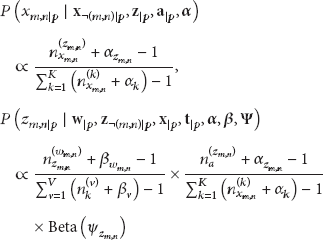
5. Experimental Results and Discussions
NIPS proceeding dataset is utilized to evaluate the performance of our model, which consists of the full text of the 13 years of proceedings from 1987 to 1999 Neural Information Processing Systems (NIPS) Conferences. The dataset contains 1,740 research papers and 2,037 unique authors. The distribution of the number of papers over year is shown in Table 2.
Distribution of number of papers over year in NIPS dataset.

In addition to downcasing and removing stop words and numbers, we also remove the words appearing less than five times in the corpus. After the preprocessing, the dataset contains 13,649 unique words and 2,301,375 word tokens in total. Each document's timestamp is determined by the year of the proceedings. In our experiments, K is fixed at 100 and the symmetric Dirichlet priors α and β are set at 0.5 and 0.1, respectively. Gibbs sampling is run for 2000 iterations.
5.1. Examples of Topic, Author Distributions, and Topic Evolution
Table 3 illustrates examples of 8 topics learned by AToT model. The topics are extracted from a single sample at the 2000th iteration of the Gibbs sampler. Each topic is illustrated with (1) the top 10 words most likely to be generated conditioned on the topic, (b) the top 10 authors which have the highest probability conditioned on the topic, and (c) histograms and fitted beta PDFs which show topics evolution patterns over time.
An illustration of 8 topics from a 100-topic solution for the NIPS collection. The titles are our own interpretation of the topics. Each topic is shown with the 10 words and authors that have the highest probability conditioned on that topic. Histograms show how the topics are distributed over time; the fitted beta PDFs is shown also.

5.2. Author Interest Evolution Analysis
In order to analyze further author interest evolution, it is interesting to calculate
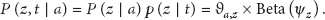

The distribution of number of publications and research interest evolution for Sejnowski_T.
From Figure 6(b), one can see that Sejnowski_T's research interest focused mainly on Topic 51 (Eye Recognition and Factor Analysis), Topic 37 (Neural Networks), and Topic 58 (Data Model and Learning Algorithm) but with different emphasis from 1987 to 1999. In the early phase (1989–1993), Sejnowski_T's research interest is only limited to Topic 51 and then extended to Topic 37 in 1994 and Topic 58 in 1996 with great research interest strength and finally back to Topic 51 after 1997. Anyway, Sejnowski_T did not change his main research direction, Topic 51, which is verified from his homepage again.
5.3. Predictive Power Analysis
Similar to [5], we further divide the NIPS papers into a training set 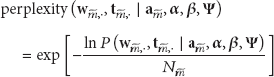
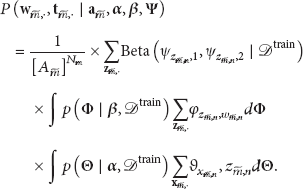
We approximate the integrals over

Perplexity of the 102 single-authored test documents.
6. Conclusions
With a dynamic users’ interest discovery model, one can answer many important questions about the content of information uploaded or shared to SNS. Based on our previous work, Author-Topic over Time (AToT) model [19], for documents using authors and topics with timestamps, this paper proposes a dynamic users’ interest discovery model with distributed inference algorithm following the main idea of MapReduce, named as Distributed AToT (D-AToT) model. The D-AToT model combines the merits of AT and ToT models. Specifically, it can automatically detect latent topics, users’ interests, and their changing patterns from large-scale social network information. The results on NIPS dataset show the increase of salient topics and more reasonable users’ interest changing patterns.
One can generalize the approach in the work to construct alternative dynamic models from other static users’ interest discovery models and ToT model with distributed inference algorithm. As a matter of fact, our work currently is limited to deal with the users and latent topics with timestamps in SNS. Though NIPS proceeding dataset is a benchmark data for academic social network, the D-AToT model ignores the links in SNS. In ongoing work, novel topic model, considering the links in SNS, will be constructed to identify the users with similar interests from social networks.
Footnotes
Appendix
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was funded partially by the Key Technologies R&D Program of Chinese 12th Five-Year Plan (2011–2015), Key Technologies Research on Large-Scale Semantic Calculation for Foreign STKOS, and Key Technologies Research on Data Mining from the Multiple Electric Vehicle Information Sources under Grant nos. 2011BAH10B04 and 2013BAG06B01, respectively.