
Abstract
Data collection in wireless sensor networks (WSNs) can become extremely expensive in terms of power consumption if all measurements have to be fetched. However, since multiple applications do not require data from all nodes but to compute a function over a smaller data set, much of the available data on the network can be considered irrelevant and not worthy of spending energy. In this context, in-network filtering schemes can be used to forward only relevant data towards a sink node for processing purposes. In this work, we propose and evaluate two schemes that can drive this filtering process. Both of them are based on the integration of metaheuristics and learning algorithms inspired by nature. In particular, we consider the computation of the maximum function as case study for these schemes. We investigate the trade-off between communications costs, which are directly associated with power consumption, and error costs due to fetching not all relevant data. We show by simulation that communication costs can be significantly reduced with respect to traditional schemes while keeping the computation error bounded.
1. Introduction
A wireless sensor network (WSN) consists of a set of small and low cost sensor nodes connected by wireless links, which can be deployed to obtain information about physical phenomena such as heat, light, noise, radiation, and chemical emissions. Typically, sensor readings are sent to a collector node (i.e., sink) using multihop forwarding, according to a data delivery model [1–3]. However, sensor nodes can have limited sensing, processing, and communication capabilities due to energy constraints resulting from battery operation. Hence, energy efficiency is a key issue in the design of systems based on this technology, where data communication can typically be considered the most energy demanding task.
Besides forwarding packets, WSN nodes are typically allowed to process in transit data available on the payload of these packets. Data can be aggregated or filtered (i.e., discarded) in order to decrease the amount of packets traveling through the network; thus, saving energy by reducing communication costs [4]. While data aggregation, which aims at fusing redundant data, has been thoroughly investigated [5], data filtering has received much less attention. In particular, the computation of type-sensitive and type-threshold functions [6, 7] can significantly benefit from in-network filtering schemes. The former requires to know a minimum fraction of arguments for the function value to be determined. Examples include average, median, histogram, and majority. The latter depends only on element-wise maximum (minimum) of the histogram and a threshold vector. Instances of these functions are maximum, minimum, range, bottom-n, and top-n. Intuitively, the value of a type-sensitive function can be accurately determined if a large fraction of the arguments are known, whereas the value of a type-threshold function can be determined by a smaller amount of arguments. Consequently, type-threshold function can potentially be computed with low communication costs.
A major issue in type-threshold function computation is how to select a set of arguments (i.e., node readings) for the function value to be accurately determined. The most naive solution is to consider all arguments, thus all network data without any kind of filtering. This guarantees the accuracy of the computed function value but involves querying all nodes and forwarding all readings to a sink for computation, which can demand a huge communication effort as the network size increases. Ideally, there exist a minimal set of nodes which can return the actual function value, but this set is unknown a priori. Since functions are typically computed over time, a learning scheme could be used to select a set of arguments that can provide with high probability the function value. If so, only a limited number of nodes can actually be queried for data, which can reduce the message count required to compute the given function. In this way, it is possible to implement low-latency one-shot computation schemes by issuing a single query at regular intervals that fetches relevant data only.
In this work, we consider the problem of filtering inside the network, those arguments not actually required to compute a type-threshold function. To this end, only the set of arguments which can be used to determine the function value at the sink node are selected. Indeed, this selection constitutes a precomputation of the function value for type-threshold functions, which can be performed inside the network in order to save energy. The network can provide the best argument candidates for a given function to a sink, which can then process these data to obtain the function value. For the maximum (minimum) function computation, just the argument with maximum (minimum) value could be provided, while, for the range case, all arguments belonging to the range. However, in general, we may provide (i) a larger set, which can result in a high communication cost but no computation error, or (ii) a smaller set, which results in a computation error. A trade-off between cost and error is thus present in solutions addressing this problem.
Type-threshold functions can be divided into two categories based on how the threshold level is defined. Fixed-threshold functions define a threshold which is known a priori and can be embedded on the query as a constant value. Nodes only read this threshold to determine whether their readings are relevant or not. The range and isocontour functions are good example of this category. On the other hand, dynamic-threshold defines a threshold which is embedded on the query as a variable value. Nodes can not only read but also update this threshold. Among the functions belonging to this category, the maximum function is the most interesting example as it can be used to implement other functions such as minimum, top-n, and bottom-n. Besides, the maximum function is typically required in several WSN applications. In this work, we focus on filtering schemes which can be used for computing the maximum function.
Dynamic-threshold functions require filtering schemes that can adapt and learn from the network. To this end, we propose to integrate computational intelligence techniques (CI) on nodes. CI is a set of nature-inspired computational methodologies to address complex problems of the real world to which traditional methodologies are ineffective or infeasible. In this work, these techniques are used to provide nodes with two filtering rules, as shown in Figure 1. The first one, namely, self-filtering rule, determines whether a reading constitutes a relevant argument to the function. The second rule, namely, neighbor-filtering rule, determines if neighbor nodes can have relevant arguments or not. In other words, if neighbor data are assumed irrelevant, the query message (containing the function) is only forwarded with some (low) probability. These rules are not static (i.e., preconfigured) but built on the fly by means of learning mechanisms.

Decision rules at each sensor node.
Nodes implement these simple rules iteratively resulting in a complex network behavior, where the network evolves from a nonfiltering state to a filtering one by means of independent decisions made by its nodes. In particular, our work considers two different approaches to implement the neighbor-filtering rule. The first scheme is based on the simulated annealing (SA) concept and centralizes network learning at the sink node to update a global query forwarding policy which fetches data from relevant areas. Instead, the second strategy distributes learning on network nodes in order to locally update the query dissemination policy at each node. This is achieved by means of the ant colony optimization (ACO) algorithm which is a bioinspired scheme based on the behaviour of ants seeking a path between their colony and a source of food. In our context, relevant data seeks a path to the sink node. When implemented over time, these schemes can learn from the network and dynamically provide a set of arguments that offers good performance in terms of communication cost and computation error.
This paper significantly extends our previous analysis reported in [8, 9], providing a much deeper discussion of the proposed schemes as well as new results. Besides, both schemes are compared to identify benefits and limitations, which can determine the best application scenario for each proposal. The main contributions of this work are as follows.
A detailed description of how filtering schemes can be used in the context of in-network computation is presented. General approaches as well as particular solutions are discussed. Proposed schemes are described in terms of forwarding and learning processes, which helps to analyze its behavior and compare their performance. Different simulation scenarios are evaluated, thus enhancing result analysis and strengthening conclusions.
The rest of the paper is organized as follows. Section 2 briefly discusses related work on in-network computation with special focus on query mechanisms. Section 3 formalizes the problem we consider in this work and introduces the concept of filtering as an efficient solution. Section 4 describes the general network model and the behavior of nodes. Forwarding and learning algorithms used to implement neighbor-filtering rules are explained in Section 5. Section 6 discusses main results obtained by simulation. Finally, Section 7 concludes the work.
2. Related Work
In-network computation of symmetric functions in multihop random WSNs has been discussed broadly in [6, 7]. In particular, the use of gossip-based algorithms has been identified as suitable solutions when both robustness and fault tolerance are required. These schemes have mainly considered type-sensitive functions (i.e., average) [10, 11] which are computed through data aggregation. However, a different approach can be considered for type-threshold functions, which actually require data searching rather than aggregation. In this sense, data aggregation techniques can be used to reduce the communication costs in WSN applications where a large amount of data needs to be sent from source nodes to a sink one (i.e, in many-to-one data flows) [2]. However, in case of type-threshold functions, where often only few nodes can possess arguments for computing a given function, these techniques can be inefficient. For this reason and because nodes with relevant readings are unknown a priori, our problem is more related to data search/discovery problems than to data collection ones.
Several query processing schemes for WSNs have been proposed in the literature, which can be classified from the point of view of both the required infrastructure and the query dissemination mechanism. The former can be infrastructure-based (such as tree, clustering, etc.) [12, 13] or infrastructure-free (i.e., unstructured) [13–15]. The latter can be walk-based [13–15], random walk-based [16], flooding-based [17, 18], and gradient-based [17]. In this sense, unstructured- and gradient-based schemes are the best option in case of type-threshold function computation due to the low overhead of unstructured mechanisms and the information gain concept of gradient-based strategies for query dissemination. The concept of using fingerprint gradients to direct query dissemination to nodes detecting events was proposed in [17]. This strategy is based on the fact that every physical event produces a fingerprint in the environment which results in a natural information gradient in the proximity of the phenomenon.
Most query processing schemes used in WSNs are based on one-phase pull diffusion [19] and rely on the network infrastructure for query propagation and data collection, which enables in-network processing for data reduction [14] (i.e., data aggregation). First, the sink node disseminates once an interest described as a function computation task. Besides, this query sets up backward paths from each sensor node to the sink. Afterwards, sensor nodes with relevant data for this function can either send data to the sink for computing the function value in a centralized way or distributively compute the function inside the network to deliver to the sink the final result. This last process can be repeated after a period of time to update the function value at the sink. However, since WSNs can be considered unreliable networks where nodes are prone to failure, these schemes can suffer from topology changes which can break up backward paths.
In this work, we focus on type-threshold function computation problems using one-shot on-demand query-based schemes. These types of schemes are much more robust to network changes since queries are disseminated each time the function is to be computed; thus backward paths are set up on-demand after each query. Note that this scheme, at first glance, might seem to demand high communication costs; however, if query dissemination can be combined with both gradient-based routing strategies for data searching and in-network filtering schemes query communication costs can be reduced. In this sense, each node, based on simple rules, participates in this process by filtering irrelevant readings as well as neighbor nodes not necessary for the function computation. As a consequence, the query area can be reduced iteratively, and the query dissemination can be directed only to those nodes which can give the best arguments for the function computation.
Our first proposed scheme drives the query dissemination process using a simulated annealing (SA) metaheuristic. Kirkpatrick et al. [20] proposed the SA algorithm to deal with traveling salesman and component placement problems. SA is a nature-based probabilistic metaheuristic for the global optimization problem of locating a good approximation to the global optimum of a given function in a large search space. Due to the distributed nature of WSNs, algorithms such as SA can be implemented in parallel fashion [17, 21], in order to compute type-threshold functions in the network. Our second proposed scheme is based on computational intelligence, in particular, bioinspired mechanisms. Kulkarni et al. [22] proposed reinforcement learning (RL) and swarm intelligence (SI) as the best options in WSNs from the point of view of computational and memory requirements, flexibility, and optimality. RL is biologically inspired and acquires its knowledge by actively exploring its environment [23]. In the last years, communication and networking technologies are increasingly considered to integrate bioinspired strategies as robust and efficient solutions [24].
A current branch of swarm intelligence focuses on ant colony optimization (ACO) and pheromone-based mechanisms. In this sense, pheromone-based routing strategies mimic the behavior of ant colonies when searching for food. Upon finding food sources, ants return to their colony laying down pheromone trails. Other ants tend to follow these paths and to reinforce them releasing more pheromone. Over time, pheromone tends to evaporate to erase unused paths. Most pheromone-based strategies for WSNs address routing and aggregation problems [25, 26]. To the best of our knowledge, the problem of in-network filtering for computing type-threshold functions using bioinspired schemes in WSNs has not yet been treated.
3. Problem Formulation
Most WSN applications are required to compute a function over sensed data (i.e., measurements). We can formalize this as computing a function
Let
The computation of a function

Function computation processes.
The self-filtering rule is straightforward as it only requires evaluating the local data against a threshold available on the query message. However, as discussed on Section 1, fixed and dynamic thresholds can be considered. Fixed thresholds [27, 28] are used for searching readings within a specific range of values, while dynamic ones, for readings without a predefined range. Fixed thresholds can be implemented locally by each node despite the actual readings available at other nodes, while dynamic ones depend on these readings to update the threshold values [29]. The canonical example for a dynamic threshold is the maximum function where, given an initial threshold, all nodes whose readings are above the threshold update it on the query message. In this way, the threshold tends to increase as the query message is disseminated through the network. In general, we will consider for our analysis the case of the maximum (minimum) function since it makes use of dynamic thresholds; however, the analysis can also be extended to fixed ones.
Among both rules, the second one (neighbor-filtering) is the most challenging as it requires learning towards which directions relevant data are present. Since data can change over time, this process needs to be robust enough to track changes that can lead to considering new nodes and/or discarding existing ones. Thus, solutions to the problem of computing
4. Network and Data Models
We consider a WSN composed of sensor nodes uniformly distributed over a square area, where communication range r and node density ρ are constant. In this sense, the more the sensor nodes in the network, the greater the area covered by the network. We assume the broadcast protocol model for wireless communication, where a node transmits information to all nodes in its communication range. In this sense, a node i can successfully transmit a packet to another node j if
Information sources (i.e., events) are modeled as uniformly distributed functions following a diffusion law with the distance; that is,

In this context, a sink node, located at the center of the network, requires computing a specific function over time by injecting queries to the network. These queries are routed through the network to fetch relevant data
In the downstream direction, the query message is first broadcasted by the sink node to all its neighbors who, after processing the query, can decide to forward it to their neighbors, and so on. Even if nodes can receive the same query multiple times, they can at most forward it once. The query message contains an identification
In the upstream direction, selected nodes (i.e., not filtered) sent a reply message back to the sink containing their readings. This enhances the self-filtering process when considering dynamic thresholds as preselected nodes in the downstream direction could be filtered in the upstream one. Even if each reply message is broadcasted, it is delivered to only one upstream node; thus, replies are routed back to the sink node through a single path. The broadcast mechanism helps to disable preselected nodes near the response path.
5. In-Network Filtering Schemes
Upon receiving either a query message or a reply one, nodes implement self-filtering in both directions. This is done comparing their readings with either thresholds in (downstream) query messages or arguments in (upstream) reply ones. Note that self-filtering does not introduce computation errors but can increase the communication cost due to the required message exchange to filter nodes with actually no relevant data. On the contrary, neighbor-filtering, which decides on whether it is worth broadcasting a query to neighbors, can introduce computation errors but tends to decrease the communication cost by avoiding querying nodes which may have useless data.
In this section, we describe two schemes for implementing the neighbor-filtering process. The first one considers that sensors nodes do not keep any state of previous filtering decisions; thus, it is referred to as stateless filtering. However, the sink node can learn from the information obtained from the network and modify the filtering rule over time by embedding some state information in the query messages that can be used to fetch only relevant data at a lower communication cost. Instead, in the second scheme, named stateful filtering, nodes maintain information about previous decisions while the sink node always keeps the same filtering rule. Both schemes can be described by (i) a downstream forwarding algorithm which implements the neighbor-filtering rule to route the query message through the network and (ii) an upstream learning process which actually adapts the dynamics of the neighbor-filtering rule in time.
5.1. Stateless Filtering
This scheme implements a version of the simulated annealing (SA) metaheuristic [20]. SA has the ability to explore beyond those areas where no relevant data are available due to its stochastic behavior. Since each query can be broadcasted to more than one node, this results in a natural parallelization of the algorithm as it can generate multiple forks of the same algorithm. The resulting algorithm is also known as Parallel Adaptive Simulated Annealing (PASA) [8]. Because PASA scheme is query-driven, it is conformed by two sequential phases, downstream forwarding and upstream learning. Both phases conform a computation iteration. The first one is used to forward the query to the sensor nodes following a one-to-many data flow model. The second one, instead, is implemented to send the arguments from selected nodes with relevant readings to the sink, following a one- or many-to-one data flow model, depending on the number of events in the network. These phases are detailed in the following subsections.
Downstream Forwarding. Each node can forward each query at most once in each computation iteration, in order to save as much energy as possible. The query message includes a T value, which represents the temperature of the algorithm, and the best found value (threshold) in the path followed by the query. Both parameters can be modified by each forwarding node. As a consequence, queries in the same iteration can have different T and threshold values depending on the sequence of broadcasts. A node having relevant data is configured to answer the query after a period of time and always broadcasts the query with the updated threshold to all its neighbors (Figure 3 top). Given that

(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26)

Downstream forwarding of the stateless scheme.
In the response process, single-path routing is implemented in order to reduce the communication cost, such as in [31]. Each selected node in PASA scheme uses the path of the first query arrival (lower latency path) to report arguments to the sink. Since PASA iteratively implements query and response phases, it can maintain an updated view of the network state. This allows dealing with nodes that can fail previous to an iteration. In case of a failure within an iteration, a simple self-healing strategy has been included to deal with this problem, which is discussed in detail in Section 6.4.
Upstream Learning. For a large value of

Performance of stateless scheme for different
Therefore, it is necessary to find an optimal
This learning process is sketched in Figure 5. Even if nodes are scattered over an area A as illustrated, a first query iteration reaches nodes on area B. Nodes on (A-B) area were not queried since relevant data was not found nearby and the value of P became too small. On the second iteration, the initial

Iterative filtering with space reduction from A to E.
A description of logarithmic and linear cooling processes is sketched in Figure 6 in case of max function computation. The sink node is indicated as s node and a node selected to report its argument to the sink as n node. Query messages embed both the current T and threshold values. After i iterations,

Cooling strategies used in stateless scheme.

Stateless scheme convergence (400 nodes, 10 events).
In this work, we apply a more robust decision rule of the temperature update policy at the sink node with respect to our previous work [8]. In our previous version on PASA, we considered that the sink node takes advantage of the number of responses
5.2. Stateful Filtering
As for the stateless case, the goal of stateful scheme is to route queries towards nodes with relevant data to obtain the arguments for the computation of a given function. However, instead of centralizing learning on the sink node as just discussed, we consider a different scheme where sensor nodes can learn in a distributed fashion from previous decisions. The proposed scheme, also known as Pheromone-based In-Network Processing (PhINP) [9], implements an iterative procedure based on path reinforcement which results in search space reduction. Path reinforcement is achieved following a pheromone-based strategy similar to that used in ant colonies when searching for food [32], thus resulting in a probabilistic query routing towards nodes with relevant readings. PhINP, like PASA scheme, is a query-driven scheme conformed by two sequential phases, downstream forwarding and upstream learning, which are described in the following subsections.
Downstream Forwarding. Like in PASA, the query message is first broadcasted by the sink node to all its neighbors who, after processing the query, can decide to forward it to their neighbors, and so on. Even if nodes can receive the same query multiple times, they can at most forward it once. The message content was detailed in Section 4. In this case, each node maintains a state referred to as pheromone level λ whose value can range between 0 and 1. Nodes periodically decrement the value of λ by a factor
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23)

Downstream forwarding of the stateful scheme.
Upstream Learning. Only nodes which have been either selected to answer the query or have forwarded a response message to the sink node increase their pheromone level by
(1) (2) (3) (4) (5) (6) (7) (8)
In this work, we improve further the downstream forwarding decision with respect to our previous versions [9, 33, 34] to increase its robustness to changes in the sensed field. This is implemented by always forwarding queries if relevant data are present (i.e.,
6. Simulation Results
The proposed schemes were evaluated in simulation environments developed in Omnet++ [35], where three metrics were analyzed to assess their performance under different scenarios: computation error, probability of success, and communication cost. Computation error represents the relative error resulting from the computed function at the sink and the actual optimal one. On the other hand, the probability of success represents the probability of computing the optimal value (i.e., zero relative error). In this sense, in case of computing the max function, this metric represents the probability of finding the node with the maximal reading in the network. Communication cost considers average number of nodes involved in forwarding both the query message (query cost) and the relevant readings to the sink (response cost). Note that the maximum query cost is equal to 1, which means that all nodes forwarded the query once (i.e., flooding). As each selected node sends its reading to the sink by a single path, this response cost is negligible with respect to the query cost. For this reason, we focus on the query communication cost only. Under the assumption that each sensor node can forward once the query in each iteration, the query cost can be also defined as the number of packets transmitted at each iteration. Note that this metric is closely related to the consumed energy in the network. The parameter set used in the simulations is shown in Table 1. We evaluate several aspects of the proposed schemes, in order to compare their performance and to determine the best application fields of each scheme. Our analysis includes the algorithm convergence, event analysis, the robustness to node failure, packet loss and dynamic events, and the capability of readaptation to event changes in the sensor network. Finally, a comparison between the proposed schemes is addressed. These aspects are described in detail in the following sections.
Simulation parameter setting.

6.1. Convergence
Since the stateless and stateful schemes learn in time, it is expected that their metrics will experience some variations during first iterations. In case of the stateless scheme, it needs to converge to a
In the stateless scheme, the sink node sets a high
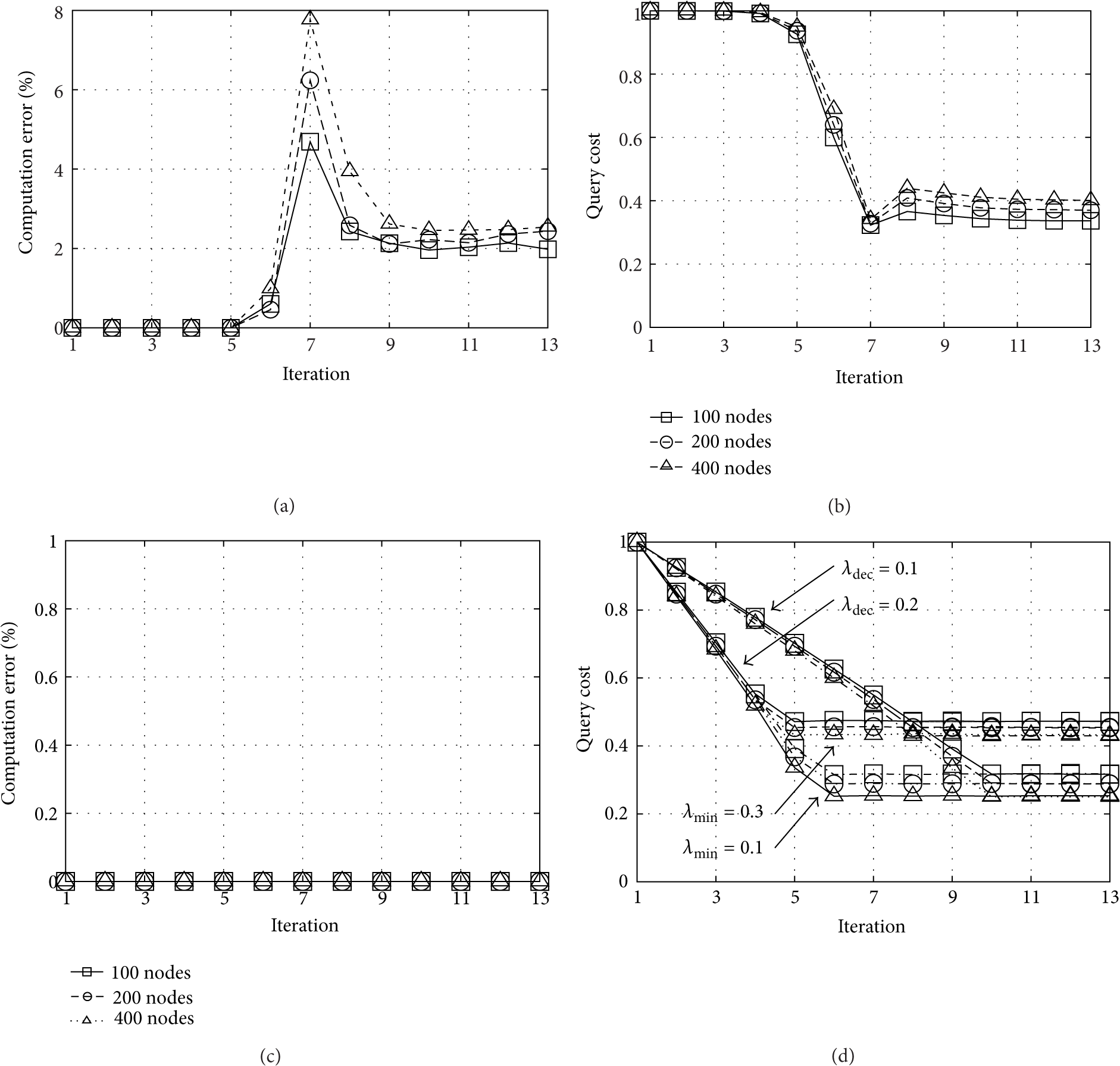
Convergence: stateless ((a), (b)) and stateful ((c), (d)) schemes.
On the other hand, since the stateful scheme also floods the network in the first iteration, the computation error remains null in the following iterations, considering no major data changes in the sensed field. Under these conditions, the convergence of the algorithm can be analyzed as it tries to decrease the query cost while keeping the error null (i.e., retrieving the same relevant data) as shown in Figures 9(c) and 9(d). Indeed, the first iteration has always a cost equal to 1 as every node forwards the query once. After each iteration, paths to nodes with relevant data are reinforced based on local pheromone levels, and the probability P of using other paths is reduced, minimizing the communication cost. Each node's behaviour is described by 4 fixed parameters (
From simulations we can see that the query cost for the stateless scheme can be decreased to more than 50% with respect to flooding while still keeping the error bounded to less than 2.5% with the considered scenario. Note that the stateful scheme can improve the communication cost with respect to stateless one by using lower
Moreover, the stateless scheme tends to introduce more errors than the stateful one. However, the latter requires good synchronization of the setting parameters due to its distributed nature. In the stateless scheme, this condition is relaxed since the sink node configures and sends the cooling policy into the query.
6.2. Event Analysis
In this case, we evaluate the performance of the stateless and stateful schemes for different fields, that is, from the point of view of data distribution in the network. In this sense, we define the event-sensor-rate metric (esr), which is the relationship between data sources and sensor nodes presented in the network. In this sense, if we have n sensor nodes and e events (i.e., sources of information), the
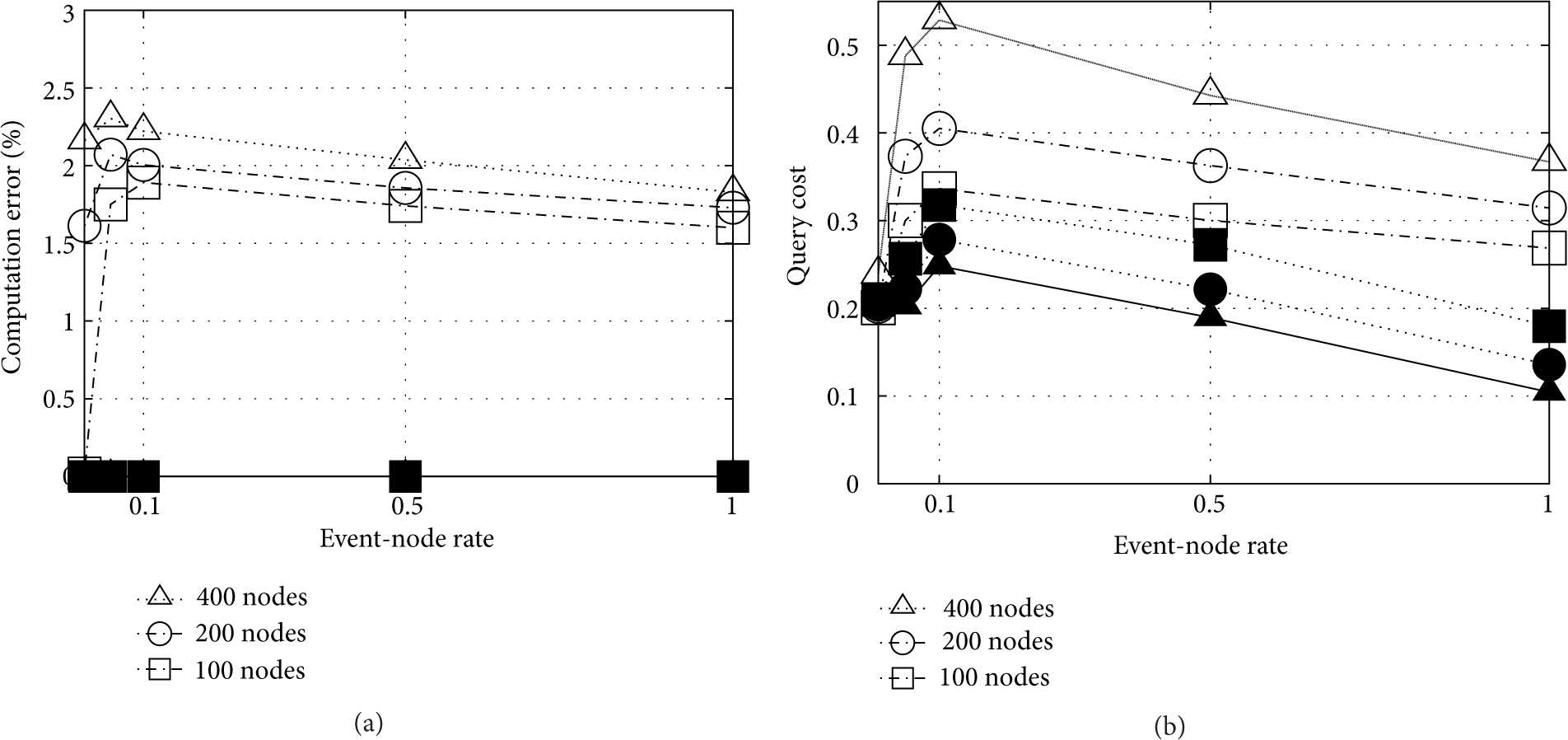
Event detection. Stateless (white) and stateful (black).
6.3. One-Event Detection
In this case, the capacity to detect an event randomly located in the network is analyzed. Note that this analysis is a particular case (
Capacity to detect a randomly deployed event.
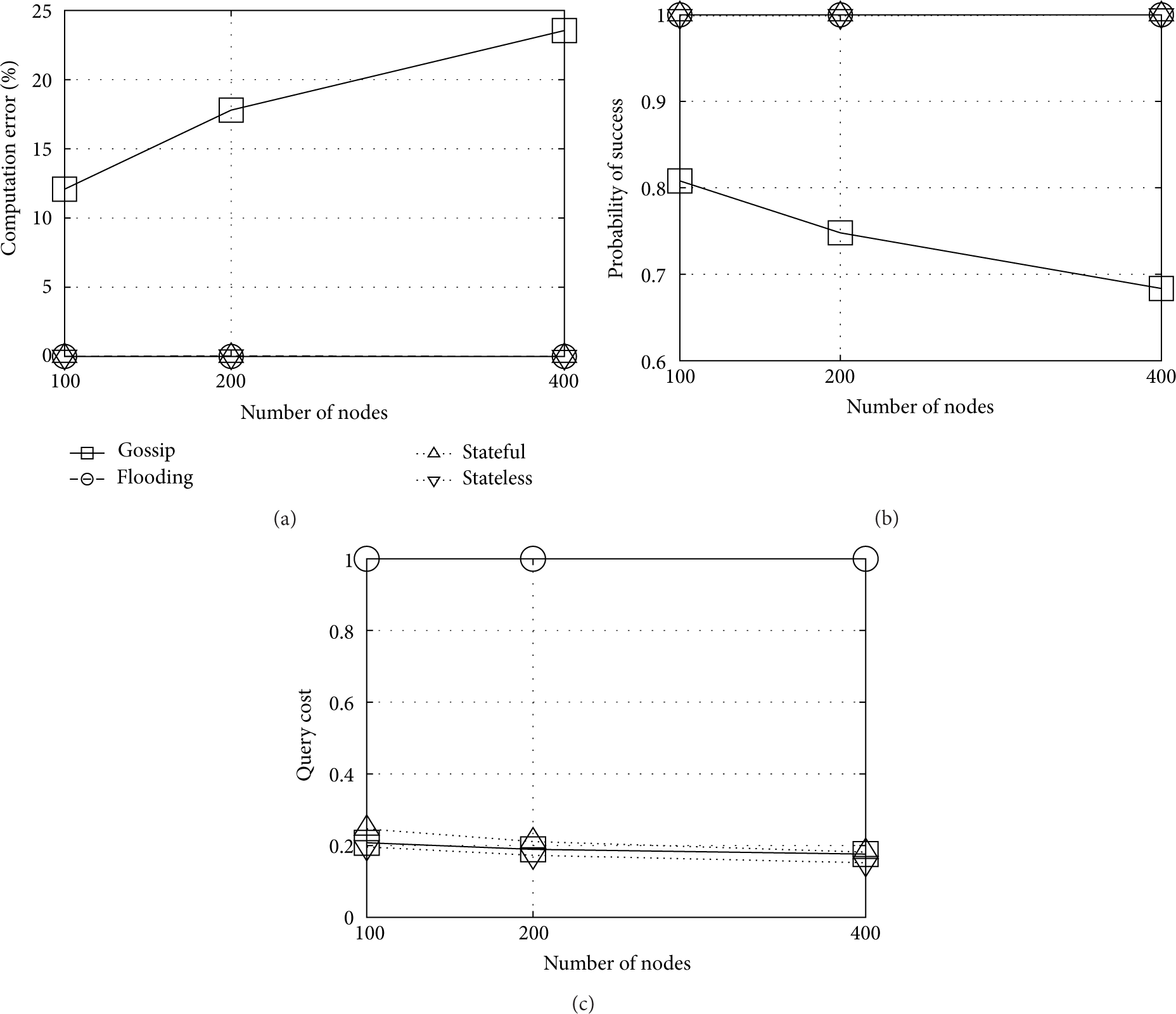
6.4. Robustness to Node Failure
Once the stateless and stateful schemes have converged after few iterations, it becomes critical for them to still work under faulty conditions. According to this, we consider the case of nodes with some failure probability. Figure 12 shows the performance of both schemes for different probabilities of node failure as the network size increases. To simplify the analysis, we suppose that the sensed field is static, thus, the sensed values do not change over time.

Lossy network. Stateless (white) and stateful (black).
As expected, the stateful scheme, although has lower computation error in the network size range analyzed, is more susceptible to failure of nodes than the stateless scheme. The reason behind this is that the stateful one tends to maintain a single path (i.e., pheromone trail) for the query dissemination between sink and each of the nodes that provide relevant arguments to compute the function at the sink. In this sense, the failure of a forwarding node is critical, since this can affect the computation of a function. As we will see, this behavior of the stateful scheme to distributively form paths can be relaxed, as the width of paths is a function of the

Downstream forwarding: stateless (a) and stateful (b) schemes and upstream forwarding (c) after convergence.
In order to increase the robustness of the proposed schemes to node failures, a simple self-healing mechanism is implemented to avoid loss of information. In this sense, each node sending information in upstream forwarding, based on reinforcement learning by active hearing, can notice if the transmitted packet was forwarded by its one-hop neighbor towards the sink. The same mechanism is followed by intermediate forwarding nodes in the path. When a sending node realizes that its one-hop destination neighbor does not forward the response packet (see Figure 14(a)), it sends the same response to the following neighbor of its neighbor's vector as depicted in Figure 14(b). In this respect, as seen above, the neighbor's vector is constructed by each sensor node in each query iteration. This is an ordered array in which the
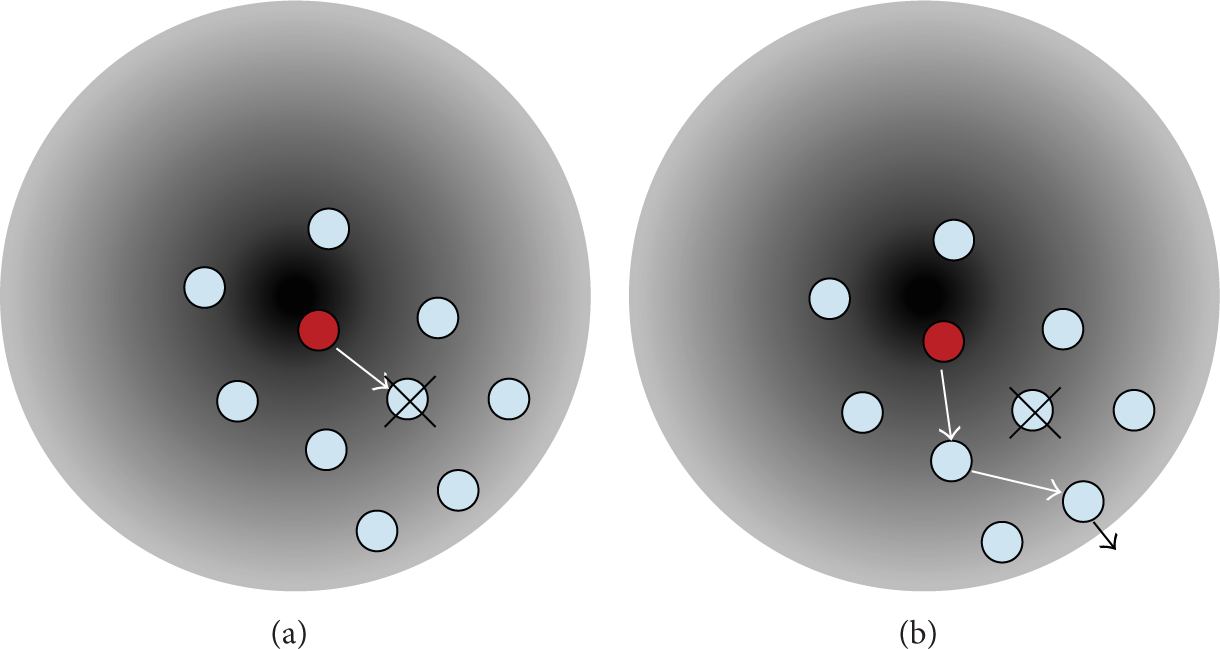
Self-healing mechanism to deal with node failures.
6.5. Robustness to Loss of Packets
In this case, the robustness of the stateless and stateful schemes to packet loss is analyzed. The same scenario and parameters setting as in the case of node failure analysis are considered. Results are shown in Figure 15. As expected, the stateful scheme is more sensible to packet loss than the stateless one, since it is able to conform paths using fewer query forwarding nodes.

Loss of packets. Stateless (white) and stateful (black).
6.6. Robustness to Dynamic Events
Even if the proposed schemes have shown to be robust enough to lossy networks, it becomes also crucial to analyze their behavior as the sensed field changes in time. For this purpose, we consider now a loss free network where all field sources (events) may change their positions. We are interested in evaluating if, after the schemes have converged to a given sensed field, they can adapt to a different one which has still some correlation with the original one. In this sense, a random position change is inserted to each event in the network, which is defined as a percentage of the communication range. The simulation considers the case of 10 events in the network, and the statistics are reported just after the change, that is, in the following iteration without considering readaptation as will be analyzed above for the stateful scheme. Results obtained for several position change values are shown in Figure 16. More clearly, if the communication range r of sensor nodes is fixed to 50 meters, a position change of 100% implies that each event in the network is randomly moved at most the same value of the communication range from its initial position. In this sense, a change of 20% has the effect that the node with the best reading to report to the sink (i.e., near to the event) could be the same; instead with a change of 200% the node with the best reading is usually another. Based on the simulation results, we can see that both schemes have similar tendencies as the percentage of position change of events is increased.
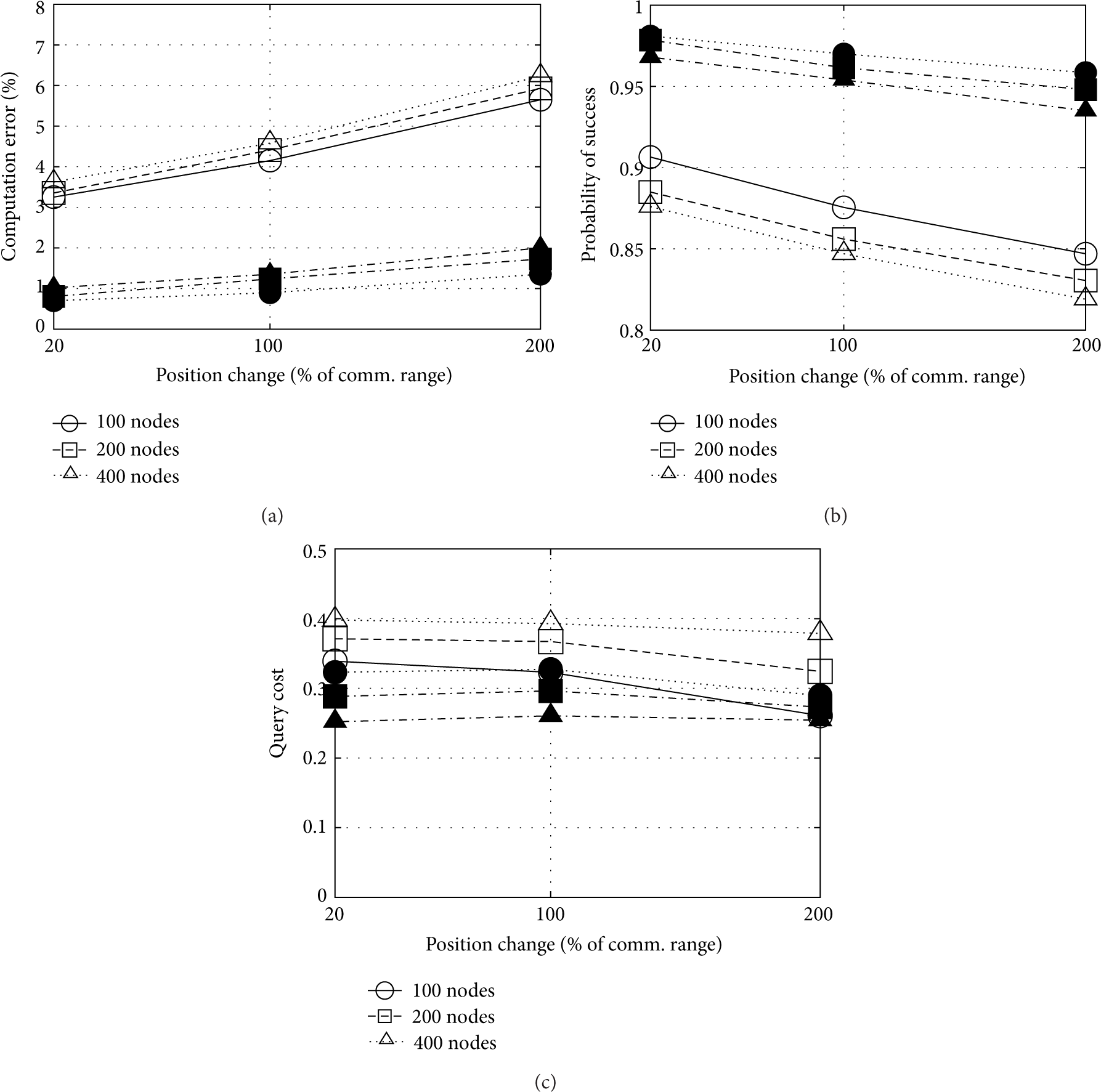
Dynamic events. Stateless (white) and stateful (black).
6.7. Readaptation Capability
As an extension of the previous analysis, in which we only report the metrics after applying the changes, we analyze the readaptation capability of the stateful scheme in several iterations after those changes. Recall that the stateless scheme does not have this readaptation feature due to the learning process followed by the centralized control of sink. As seen above, the configuration parameters

Readaptation capability. Stateful scheme.
6.8. Schemes Comparison
Based on the discussed results, we can notice that each scheme has its own scope; that is, each scheme is more efficient for a given scenario. We make this analysis considering that both schemes have already converged to a low-energy state. In this sense, the stateful scheme is more appropriate than the stateless one in scenarios with dynamic events. However, the stateless scheme is more robust to failure of sensor nodes due to the fact that the same query message more probably arrives to a node through multiple paths. In this sense, in the stateful scheme there is a trade-off between the communication cost and the robustness to node failure. If a low

Queried area. Stateful (a) and stateful (b).
A substantial difference between both schemes is the probability of exploration of sensor nodes (i.e., query forwarding) related to the neighbor-filtering rule. In the stateful scheme this probability is limited to a
Comparison of proposed schemes.

7. Conclusion
In this work, we analyzed the problem of in-network filtering to compute efficiently type-threshold functions in a WSN, minimizing both communication cost and computation error. In this context, in-network filtering schemes can be used to forward only relevant data towards a sink node for processing purposes as an alternative to data aggregation. To this end, two nature-inspired schemes were proposed that can drive this filtering process. The first one considered a stateless filtering scheme where the sink node implemented a learning algorithm to feed a decision rule based on the well-known simulated annealing search process. Instead, the second approach, dubbed stateful scheme, considered a distributed learning scheme inspired by the ant colony behavior where nodes kept a state to reinforce paths to the sink. We show by simulation that communication costs can be significantly reduced with respect to traditional schemes while keeping the computation error bounded.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is partially funded by Universidad Tecnológica Nacional, FONCyT IP-PRH Postgraduate Grant Program, SECYT-UNC Research Program, and CONICET Postgraduate Grant.