
Abstract
Nonuniform node deployment makes the cluster-based routing protocol less efficient in wireless sensor networks (WSNs). Energy aware distributed clustering (EADC) is one of the cluster-based routing protocols proposed for networks with nonuniform node distribution, which can effectively balance the energy consumption among the nodes. However, due to the nonuniform node distribution, there is a redundancy in sensed and transmitted data in dense area. This unnecessary energy consumption is not considered in EADC. Therefore, in this paper, a new algorithm called scheduled activity EADC (SA-EADC) is proposed. SA-EADC exploits the redundant nodes and turns them off for the current round. The redundant nodes are scheduled based on their residual energy to work alternatively. The results show that SA-EADC significantly decreases the energy consumption and extends the network lifetime without degradation in coverage and sensing reliability of the network.
1. Introduction
Wireless sensor networks (WSNs) consist of a hundred to a thousand sensor nodes, which measure a property from the environment as well as processing and transmitting the collected data to the base station (BS) [1]. However, they have many constraints, because the sensor nodes have limited capabilities. Since the energy resources of the sensor nodes are limited and nonrechargeable, energy efficiency is a very critical issue in the design of the network topology, which affects the network lifetime significantly. Hence, the main concern in designing protocols is how to reduce the energy consumption and extend the network lifetime [2].
It has been proved by many researchers that among different categories of routing protocols based on the network architecture, cluster-based (hierarchical) routing protocols are more energy efficient and increase the scalability as well as lifetime of the network [3–5]. Clustering schemes divide the field into multiple clusters, where each cluster is controlled by a cluster head (CH) with the purpose of gathering data from cluster members (CM). CHs act as the local BS for their own clusters. After gathering data and performing data aggregation to omit the redundant data, the data are transmitted to the BS [6–8].
Networks with nonuniform node distribution make the cluster-based routing protocols less efficient [9, 10]. The nonuniform node deployment makes the energy consumption of the nodes more imbalanced [9]. Furthermore, as the density of the sensor nodes varies in each region due to nonuniform node distribution, in dense area the sensed and transmitted data are extremely correlated and redundant. In random and nonuniform node distribution, there may exist some redundant sensor nodes whose coverage areas are completely covered by their neighbor nodes. These redundant sensor nodes can be identified and scheduled to be activated alternatively in order to prolong the network lifetime [11].
Energy aware distributed clustering (EADC) [9] is one of the protocols proposed for networks with nonuniform node distribution, which can effectively balance the energy consumption among the nodes. However, the unnecessary energy consumption of redundant nodes is not considered in EADC. Therefore, in this paper, a scheduled activity energy aware distributed clustering (SA-EADC) is proposed based on EADC, which exploits the redundant nodes and turns them off. The redundant nodes are scheduled based on their residual energy to work alternatively. The proposed algorithm maintains the original sensing coverage and guarantees a certain redundancy. Consequently, SA-EADC avoids unnecessary redundant sensing and transmission of data, which reduces the overall energy consumption and extends the lifetime of the network.
The rest of the paper is organized as follows. Section 2 covers the related works in this area. Section 3 introduces the network model of our algorithm. Section 4 explains the used redundancy check method and activity-scheduling algorithm in SA-EADC. Section 5 presents SA-EADC in detail. Section 6 analyzes the properties of the proposed protocol. Section 7 describes the simulation and the analysis of the obtained results. Finally, the paper is concluded in Section 8.
2. Related Work
In this section, first some typical energy efficient clustering protocols are discussed. Afterwards, the sensor node scheduling algorithms are analyzed, which focuses on exploiting the redundant nodes and scheduling their activity.
2.1. Energy Efficient Clustering Protocols
Low energy adaptive clustering hierarchy (LEACH) [5] is a fundamental clustering algorithm, in which the sensor nodes independently elect themselves as the CH. The CHs are responsible to gather the data from their CMs, perform data aggregation to omit the redundant data, and transmit data to the BS using single hop communication. The nodes are selected as the CHs in turn with the purpose of evenly distributing energy expenditure in the network. Despite of being simple, the remaining energy of nodes is not considered as a parameter in CH selection. Moreover, it is not suitable for the large size networks. Thus, several cluster-based routing protocols were proposed so as to tackle the limitations of LEACH and improve its performance [13–15].
Energy efficient heterogeneous clustered (EEHC) routing protocol proposed by Kumar et al. [16] considers a network with the nodes, which differ in their energy level. CH selection and cluster formation are performed in a distributed method. The CH selection phase is performed based on the residual energy of the nodes. Nevertheless, the intercluster communication phase is performed in single hop and the residual energy of the nodes is not considered in CH selection.
Energy-aware data gathering (EADEEG) [17] is another clustering routing protocol, which is able to achieve a good CH distribution. The CHs are selected according to the residual energy of the nodes and the average residual energy of their neighbors in EADEEG. In spite of improving the network lifetime, EADEGG suffers from the existence of “isolated points” [4].
Yu et al. [4] proposed energy aware distributed unequal clustering (EADUC) routing protocol in order to solve the mentioned problem in EADEGG. EADUC assumes a network with heterogeneous nodes, which are different in energy resources. Additionally, the clusters are constructed in unequal sizes in EADUC, in order to solve the “hotspot” problem. The hot spot problem is related to the early death of CH nodes, which are closed to the BS. Therefore, the clusters near to the BS have smaller size to save more energy for intercluster communication.
Arranging cluster sizes and transmission ranges (ACT) proposed by Lai et al. [7] is a novel clustering routing protocol. ACT separates the network topology into multiple levels. The sizes of the clusters are the same in each level and are different from other levels. In other words, the clusters near to the BS are the smallest, whereas the largest clusters are the farthest ones from the BS to overcome the problem of “hot spot.” Since ACT avoids reclustering in each round, a cluster maintenance phase was proposed. Cluster maintenance phase consists of CH rotation based on energy threshold and cross-level data transmission. The results show that ACT can significantly increase the network lifetime. However, it does not address the coverage problem [7]. In addition, although cluster sizes are arranged according to energy consumption, the location of the newly selected CH strays from the ideal ones. This issue makes the distribution of energy fluctuate [18].
Coverage preservation clustering protocol (CPCP) [19] is a clustering protocol in which the clusters are constructed based on a group of coverage-aware metrics [2]. It considers a network with nonuniform node distribution. The main concern of CPCP is coverage preservation and it uses good CH selection technique. However, the network lifetime and balancing energy expenditure are not noted in detail in CPCP [9].
2.2. Sensor Activity Scheduling Protocols
In [20], Cardei and Du proposed a method in order to preserve full coverage of the area, in which the sensor nodes are divided into disjoint cover sets. These cover sets are active alternatively. Each cover set contains adequate number of active sensor nodes, which are essential to cover the monitoring area, meanwhile the rest of the sensor nodes are turned off. While, the rest of the sensor nodes are turned off. However, this scheme is based on a centralized approach. Therefore, it requires global synchronization overhead; besides it is not scalable in the networks with large size.
In PEAS [21], the sensor nodes use a simple rule in order to decide about their activity. The sensor node will be active if it cannot find another active node in its probing range. Otherwise, it will return to the sleep mode. PEAS does not require the nodes to maintain the neighbor state and location information. Therefore, it reduces the complexity. However, it does not guarantee a complete coverage preservation of the environment [22].
Tian and Georganas in [22] proposed a scheduling scheme, in which the sensor nodes decide about their state in a distributed manner, based on the obtained coverage information from their neighbors. In this scheme, in order to avoid creation of “blind points” in the network, a random back-off time is introduced, before a node makes a decision about its status. The problem of “blind points” occurs when two sensor nodes, whose redundancy is dependent to each other, decide to be inactive simultaneously.
In CPCP clustering scheme [19], in order to check the redundancy, the grid approach is used. Although this method is a straightforward approach and it does not limit the sensing coverage model, it can be time consuming, storage expensive, and computation complicated [12]. Soro and Heinzelman introduced a delay in node activation based on the nodes current cost value in order to avoid “blind point” problem. Therefore, the nodes with less cost have a better chance to be inactive.
In BCA clustering scheme [10], in order to identify inactive nodes, each CH calculates the average number of nodes in a cluster. The number of inactive sensor nodes is equal to the difference of the nodes in a cluster from the average number of nodes. The CHs select the inactive nodes randomly and each selected sensor node determines whether to be inactive or not. Although it is a simple method, the full coverage is not guaranteed in this approach.
3. Network Model
There are Nsensor nodes distributed in
The energy model used in SA-EADC is adopted from LEACH [5]. In order to transmit l bit message to the distance of d, the energy dissipates as follows:

For receiving l bit message, the radio dissipates energy as follows:

In addition, it is assumed that the energy consumptions due to data sensing and data aggregation are
4. Sensor Activity Scheduling
In order to schedule the sensor activity to preserve the complete coverage of area, the first question is to find out whether the area covered by the sensor node is covered completely by its active neighbors. It should be noted that the state of the nodes' neighbor has a significant impact on the redundancy of the node. A node may not be redundant anymore, if one of its active neighbors becomes inactive. The second question is to identify the order of sensor's activation and deactivation [12]. The following sections describe the redundancy check method and activity scheduling procedure used in SA-EADC.
4.1. Redundancy Check Method
SA_EADC utilizes the crossing coverage redundancy check method proposed by Xing et al. [23] in order to determine the redundant nodes, since it reduces the storage requirements and computation complexity [12].
If the sensing disks of two nodes intersect each other, then crossing points that are the intersection points on the perimeters of two disks will be created. As represented in Figure 1,
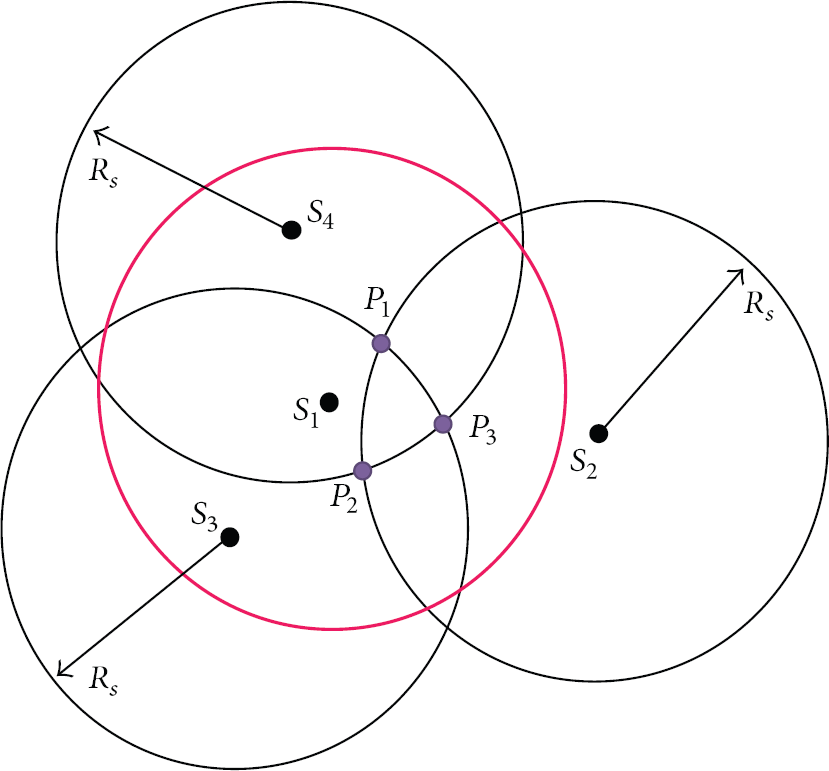
Crossing coverage redundancy check method [12].
4.2. Activity Scheduling Procedure
A fully distributed “self-inactivation” algorithm is proposed in order to determine the order of sensor's activation and deactivation and avoid creation of “blind points,” since the centralized algorithms are not scalable and need global synchronization overhead. The proposed algorithm avoids the problem of “blind points” by introducing the delay in the node deactivation based on the residual energy of the node. Therefore, the sensor nodes with higher remaining energy have a higher chance to be active in each round. The activity scheduling procedure of SA-EADC is discussed in detail in following section.
5. SA-EADC Algorithm
In this section, SA-EADC clustering algorithm is introduced in detail. Similar to EADC, the protocol contains an energy aware clustering algorithm (SA-EADC) and a cluster-based routing algorithm. SA-EADC adds a “sensor redundancy check and activation” phase to EADC. Thus, it makes even clusters. Furthermore, a subset of sensor nodes is selected to perform the sensing task while the redundant sensor nodes go to sleep mode for the current round. SA-EADC not only maintains the original coverage area, but also maintains a certain redundancy to guarantee the sensing reliability of the system. In the cluster-based routing algorithm, which is identical to [9], the energy consumption among the CHs is balanced. The description of the control messages used in the process of SA-EADC is shown in Table 1.
Description of control messages in SA-EADC.

5.1. SA-EADC Details
The clustering process of SA-EADC is divided into four phases: information collection phase with duration of
5.1.1. Information Collection Phase
The duration of this phase is defined as
Then each node starts to calculate the average residual energy of its neighbors 
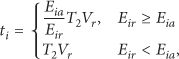
Receive Update neighborhood table NT Update active direct neighbor table ADNT
5.1.2. Cluster Head Competition Phase
Afterwards, SA-EADC starts the CH competition phase, whose duration is
NT Continue Broadcast
5.1.3. Sensor Redundancy Check and Activation Phase
As
Execute the crossing coverage algorithm Set Timer α Wait for Timer expiration Update active direct neighbor table ADNT Execute the crossing coverage algorithm Broadcast
5.1.4. Cluster Formation Phase
In this phase, all the active plain nodes select a CH, according to the received signal strength. Thus, they will select the nearest CH and send the “Join_Msg.” The CHs create a node-scheduling list based on the received “Join_Msg.” CHs create and send the “schedule_Msg” in order to identify the time of data transmission for the nodes and, in other times, they can be in the sleep mode. This issue will result in saving energy. Pseudocode 4 shows the pseudocode of cluster formation phase. At this point, the whole process of SA-EADC is done. The clusters consist of the nodes in Voronoi cell around the CHs.
Send Receive Broadcast
5.2. Cluster-Based Routing Algorithm
SA-EADC utilizes the cluster-based routing algorithm of EADC [9]. Similar to EADC, the CHs generated by EADC distribute uniformly over the network. Therefore, the size of clusters is equal. However, due to the nonuniform node distribution, clusters in the dense area have more members in comparison to the clusters in the sparse area. Hence, this issue results in imbalanced energy consumption of CHs. According to Yu et al. [9] the energy consumption in multihop communication is divided into intracluster energy consumption and intercluster energy consumption. The CHs consume energy due to receiving, aggregating and transmitting data from their CMs, which is called intracluster energy consumption. In addition, they consume energy due to forwarding data for their neighbor CHs, which is called intercluster energy consumption. Yu et al. [9] adjusted the ratio of two parts of energy consumption, in order to balance the energy consumption among the CHs. The CHs in sparse area forward more data packet to mitigate the imbalance intracluster energy consumption. Furthermore, the heterogeneity of the nodes is also taken into consideration. Thus, if the CHs with higher residual energy are chosen to take more forwarding task, the network lifetime will be better prolonged.
At the beginning of this phase, each CH broadcasts a “Route_MSG” message within the radius range 
Broadcast Receive Compute the value of Update cluster head neighborhood table CHNT Update MR
5.3. Data Transmission Phase
Data transmission phase is composed of intracluster communication and intercluster communication phase. These phases are discussed as follows.
5.3.1. Intracluster Communication Phase
CMs collect the data from the monitoring area and transmit the data in the allocated time slot to their CH directly.
5.3.2. Intercluster Communication Phase
CHs receive data from their members, perform data aggregation, and send the aggregated data to the next hop nodes. If a CH receives the data from other CHs, it will forward it to the next hop, without performing data aggregation. The topology of SA-EADC is shown in Figure 2.

Topology of SA-EADC.
6. Protocol Analysis
Theorem 1.
The overhead complexity of control messages in the network is
Proof.
In each clustering process, each node broadcasts a Node_Msg. Therefore, there are N Node_Msg. In each round, each active sensor node broadcasts a Join_Msg. Each CH broadcasts a Head_Msg, a Schedule_Msg, and a Route_Msg, while, each inactive node broadcasts a Sleep_Msg. Suppose the number of inactive sensor nodes and the number of generated CH are S and K, respectively. Therefore, the total number of control message in the whole network is
Theorem 2.
SA-EADC can set up the clustering topology in
Proof.
SA-EADC is a distributed clustering algorithm. Therefore, the time complexity of the whole network is constant and is equal to a single node
7. Performance Evaluation
A discrete event simulation (DES) in a purpose language C# was developed in order to perform the simulation. The simulations were conducted for two scenarios shown in Figure 3.
Scenario 1: 100 nodes are deployed over an area of Scenario 2: 100 nodes are deployed over an area of
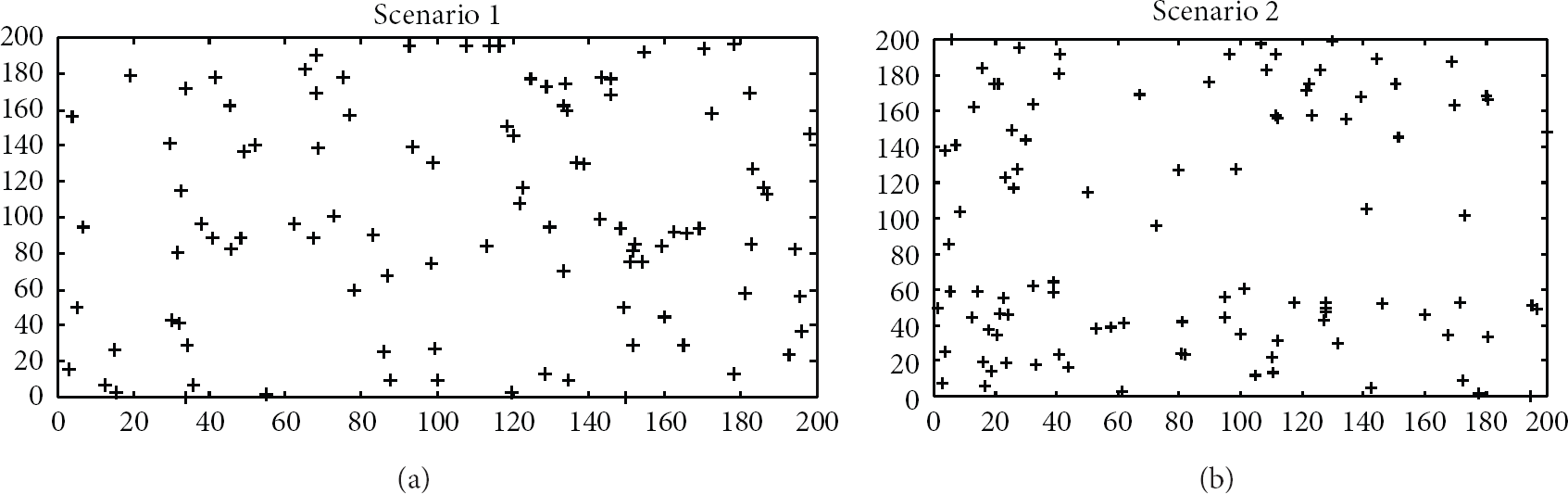
Network topology in two scenarios [9].
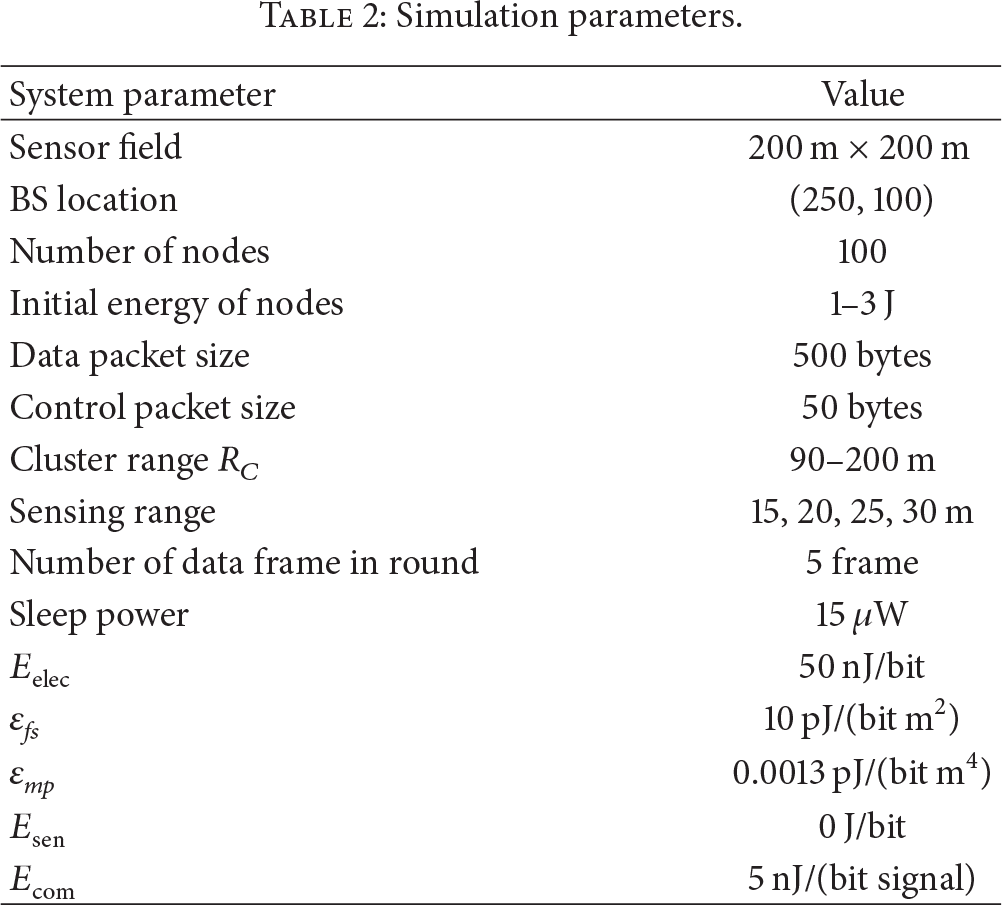
Every simulation result is the average of 100 independent experiments. The parameters of the simulation are listed in Table 2.
Simulation parameters.
The performance of SA-EADC protocol is evaluated in two parts. The first is to evaluate the algorithm in terms of maintaining the sensing coverage and sensing reliability. The second is to study and analyze the effectiveness of the proposed clustering algorithm in terms of energy saving and network lifetime for the two stated scenarios. In addition, in order to investigate the effect of the sensing range on the different performance metrics, the sensing range was set between 15 and 30 m.
7.1. Coverage Preservation Evaluation
In this subsection, the performance of the SA-EADC based on its capability of preserving sensing coverage, remaining sensing reliability, and number of the inactive sensor nodes is evaluated in the two selected scenarios.
According to Tian and Georganas [22], in order to calculate the sensing coverage, the environment is divided into
7.1.1. Sensing Coverage
SA-EADC was run with sensing range

Network sensing coverage in scenario 1 and scenario 2.
7.1.2. Sensing Degree
In this section, the original sensing degree as well as the obtained sensing degree are calculated and compared in both scenarios. The space is still divided into
Figure 5 shows the percentage of the deployed area that can be monitored with different sensing degrees in Scenario 1. As it is illustrated, the original sensing degree is varied from 1 to 9, from 1 to 11, from 1 to 12, and from 1 to 15 when the sensing range is 15, 20, 25, and 30, respectively. Whereas, the obtained sensing degree is always varied from 1 to 5, which shows that SA-EADC controls the redundancy and sensing degree of the network effectively. Similarly, Figure 6 illustrates that in Scenario 2 the sensing degree is varied from 1 to 9, from 1 to 11, from 1 to 16, and from 1 to 21 when the sensing range is 15, 20, 25, and 30, respectively, while, the obtained sensing degree is always varied from 1 to 6. Although SA-EADC turns off the redundant nodes, it still controls the redundancy and sensing degree of the network.

Different sensing degree of network in scenario 1.

Different sensing degree of network in scenario 2.
7.1.3. Inactive Sensor Nodes
In this section, the impact of sensing range and deployed node number over the number of inactive sensor nodes is investigated. In order to show the effect of varying sensing range on the number of inactive sensor nodes, in both scenarios,

Number of inactive nodes in each scenario.
Additionally, in order to investigate the effect of sensing range and node density on the number of inactive sensor nodes, the node density is changed by varying the sensing range from 15 to 30 m and the deployed node number from 100 to 250 in the same

Number of inactive nodes versus node density.
7.2. Energy Consumption Evaluation
In this section, the ability of SA-EADC in terms of energy saving is evaluated for the two mentioned scenarios. Therefore, in order to perform this evaluation, the network lifetime and average energy consumption of the nodes per round are selected as the performance metrics.
7.2.1. Network Lifetime
The network lifetime is defined as the time (i.e., round) when 90 percent of the nodes are alive. In both scenarios, the cluster range (i.e.,
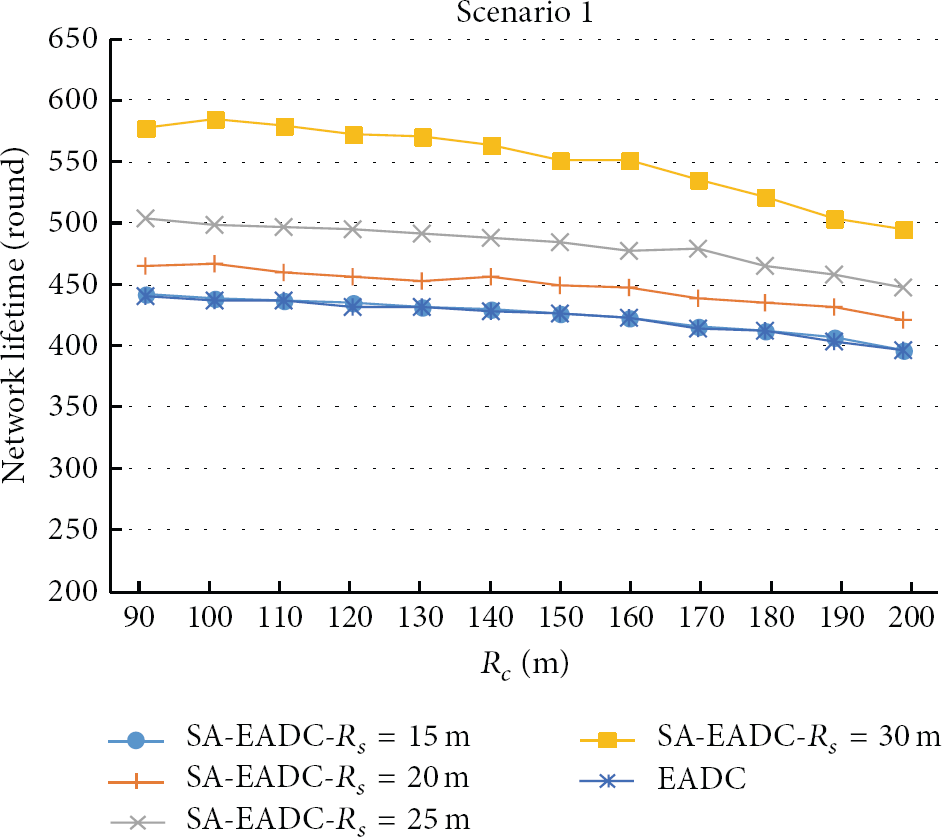
Network lifetime of scenario 1.

Network lifetime of scenario 2.
In Scenario 1, when the
Similarly, in Scenario 2, the network lifetime is increased slightly by 1.2% where
The reason of this appearance is that with the increase of
7.2.2. Energy Consumption
The energy consumption is defined as the average energy that the nodes consumed during the topology construction, data transmission, and sleep mode per round. Similar to the previous sections, in both scenarios the cluster range (i.e.,

Average energy dissipation per round in scenario 1.

Average energy dissipation per round in scenario 2.
As it is presented in these figures, the average energy consumption of the sensors in each round gradually increases with the increase of the
As can be seen in Scenario 1, the energy consumption of the nodes improves slightly by 3.07%, when the sensing range is set to 15 m. While, the sensing range is set to 20 m and 25 m, the energy consumption recovers by 13% and 20%, respectively, compared to EADC. Eventually, there is a significant improvement (i.e., 27%) in energy consumption when
Similarly, in Scenario 2, the energy consumption is decreased slightly by 6% when
This phenomenon occurs due to the following reason: the number of redundant nodes, which are eligible to go to sleep mode, increases with the increase of sensing range. Therefore, with the decrease of active node in each round, the sensor nodes save more energy. The results show that SA-EADC can effectively identify the redundant nodes and schedule them alternatively in a way that the energy consumption of the network decreases.
8. Conclusion
In this paper, a clustering algorithm, namely, SA-EADC, based on EADC for wireless sensor network with nonuniform node distribution is proposed. The SA-EADC identifies the redundant nodes, whose sensing coverage area also is covered completely by their direct neighbors and turns them off. It schedules these sensor nodes based on their residual energy to be activated alternatively. The analysis and simulation results show that the proposed algorithm can effectively identify the redundant nodes and schedule them to be active in a way that reduces the overall energy consumption. Therefore, it extends the network lifetime as well as maintains the original sensing coverage of the network.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.