
Abstract
This paper proposes an adaptive iterative learning control strategy integrated with saturation-based robust control for uncertain robot system in presence of modelling uncertainties, unknown parameter, and external disturbance under alignment condition. An important merit is that it achieves adaptive switching of gain matrix both in conventional PD-type feedforward control and robust adaptive control in the iteration domain simultaneously. The analysis of convergence of proposed control law is based on Lyapunov's direct method under alignment initial condition. Simulation results demonstrate the faster learning rate and better robust performance with proposed algorithm by comparing with other existing robust controllers. The actual experiment on three-DOF robot manipulator shows its better practical effectiveness.
1. Introduction
The wide application of robot in repetitive manufacturing processes has produced a need for increasing research in robotic control techniques, especially trajectory tracking control. For trajectories that repeat themselves, a very successful approach is to learn the feedforward signals for subsequent trials by iteratively updating them based on the error accumulated in previous trials [1–5]. As a result, for systems making repetitive movements, like robotic systems, iterative learning control (ILC) is a good choice for feedforward control design.
ILC is a learning control technique for systems making repetitive movements. In each trial, a feedforward is computed based on measurements of the error in the previous trials, such that the error converges to a small value. Additionally, it does not require a prior knowledge of system dynamics. Owing to its simplicity and effectiveness, ILC has been considered to be a good alternative in many areas and applications.
From the beginning, ILC has been mainly applied to improve the tracking accuracy of robot. Arimoto et al. [1], Guglielmo and Sadegh [6], and Elci et al. [7] proposed a series of learning laws that are proportional to the error in the previous iteration, containing error derivative and error integral (PID-type ILC) with respect to time under no requirement for explicit model information. Although the computation style is simple and straightforward, the learning speed is largely limited owing to the singleness of control, meaning that the state signal needs several iterations to converge to zero. Additionally, with respect to practical robotic systems, many uncertainties resulting from dynamics, inner or external disturbances, and structural or unstructured parameters largely reduce system's tracking accuracy and the learning speed of control law. Therefore, more sophisticated and intelligent ILC methods are required for increasing complex systems. Seo et al. [8] and Tayebi and Chien [9, 10] gave different adaptive iterative learning (AILC) strategies for nonlinear systems. Choi and Lee [11] proposed another AILC for robotic system, where the parameter was estimated in the time domain. Yang et al. [12] proposed an adaptive robust iteration learning control for uncertain robotic systems based on sign function, while the larger fluctuation of gain of sign function affects convergence speed. Ouyang et al. [13] proposed a learning law based adaptive switching PD control strategy in the iteration domain. In addition, Tayebi et al. [14] designed a feedback controller by using the Youla parameterization and μ-synthesis approach to solve the robust performance condition. However, the aforementioned works have one thing in common in the assumption of initial condition, which requires perfect resetting or repositioning at the beginning of each iteration.
Alignment condition is a novel method for avoiding the influence in tracking performance resulting from the inconformity of initial condition for each trial [15–20]. Under alignment condition, the initial state of current iteration depends on the final state of previous iteration without considering the assumption of initial state tracking error [15–17]. A series of alignment condition-based ILC control strategies have been proposed for applying to nonlinear systems [18–20].
In this paper, the trajectory tracking control problem for robot manipulator systems is considered under alignment condition. The factors of modelling uncertainties of unknown parameter and external disturbances are explicitly addressed in control design and stability analysis. Robust adaptive control method is further merged with ILC strategy to form a new control method, robust adaptive ILC, in which the iterative learning law is used to cope with the impact arising from parametric uncertainties and model uncertainties. The control scheme is composed of three parts: a PD-type error feedback control, parameter adaptation, and disturbance compensation. It is shown that, by blending ILC with adaptive control, the resultant control scheme is able to accommodate model errors and external disturbances effectively. The system convergence is guaranteed during the whole iteration process. Compared with existing results, the major contributions of this paper can be briefly summarized as follows. (1) To enhance the control performance, the robot manipulator dynamic model is attached with model uncertainties and uncertain external disturbances. (2) The resultant robust adaptive ILC scheme is designed, without precise model information, under alignment at initial condition by replacing the traditional identical initial condition, which requires perfect resetting or repositioning at each iteration beginning.
The rest of this paper is organized as follows. In Section 2, the dynamic model of n degree-of-freedom uncertain robot manipulator is described. In Section 3, the robust adaptive ILC strategy for robotic system is proposed. Furthermore, both position and velocity tracking stability are established systematically by using Lyapunov analysis under alignment initial condition. With simulation and experimental results in Section 4, the effectiveness and robustness of the proposed control law are verified. Moreover, the practical effectiveness of proposed law is fully verified on the actual 3-DOF robot manipulator. Conclusion is then made in Section 5.
2. Problem Formulation
Consider n DOF robotic system with uncertain external disturbances; the dynamic equation can be expressed as follows:

where t ∈ [0, T] denotes the time index. The subscript k ∈ Z+ denotes the iteration number. The singles q
k
(t),
In this paper, the robot manipulators should have the following common robot properties.
Property 1. For any D(q k ) ∈ Rn × n, D(q k ) is symmetric, bounded, and positive definite matrix.
Property 2. For any q
k
,
Property 3. At the kth iteration, for q
k
,

Additionally, in developing the controller, dynamics (1) is assumed to satisfy the following identical initialization condition.
Assumption 1. The desired trajectory, containing position and velocity trajectories q
d
(t) and
Assumption 2. The desired trajectories are spatially closed, achievable, and twice differentiable, meaning that q
d
(0) = q
d
(T),
According to the paper, our main objective is to find an appropriate control input τ
k
(t), guaranteeing q
k
(t) and
Remark 3. Assumption 1 makes the task assigned for controller design feasible. Assumption 2 not only satisfies the repeatable control environment but also removes the conventional assumption of initial resetting conditions, which is an initial issue before iteration research.
3. Robust Adaptive ILC Design
At the beginning, we have the following definitions.
Definition 4. The generalized error is
Definition 5. The saturation function satisfies

Consider τ k (t) as the control input for kth iteration; from (1), we obtain

where
Linearizing (4) along the desired trajectories q
d
and
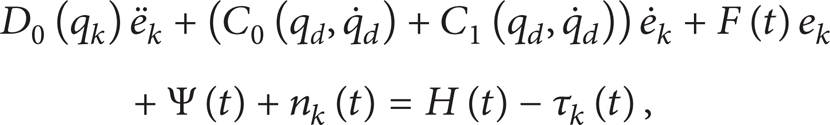
where
For the robot system (1) with uncertain parameters and external disturbances, a robust adaptive iterative learning controller is proposed under alignment condition as follows:

where K
pk
∈ Rn × n and K
dk
∈ Rn × n are known positive definite diagonal matrixes, satisfying K
pk
= φ
k
(t) Kp0 and K
dk
= φ
k
(t)Kp0, where φ
k
(t) is a monotonic increasing function with respect to iteration k. ρ is a positive appropriate constant.
The convergence analysis of the proposed learning control scheme is carried out under alignment condition and unknown external disturbances, which is summarized in the following theorem.
Theorem 6. Consider system (1) with Properties 1–3 and Assumptions 1 and 2 under control law as (4); the external state signals will converge to zero as k tends to infinity over a finite-time interval [0, T]; that is, limk → ∞q
k
(t) = q
d
(t),
Proof. Let us consider the following Lyapunov function:

where
Now we define the two parts of the right side of (7) as V k 1(t) and V k 2(t), respectively.
Part 1. The Difference of V k 1(t). For V k 1(t), from (4), we obtain
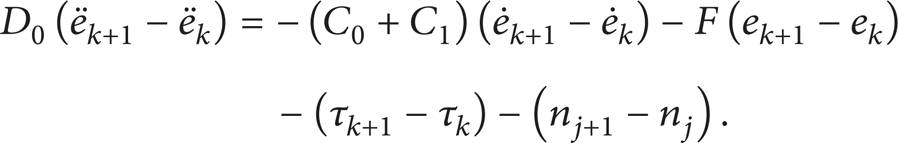
Then based on (8)

Define K p = λK d ; hence

where w = C0 + C1 − λD0.
Assuming ∥n k ∥, then, differentiating V k 1(t) with respect to time t at the kth iteration, we have

Applying the partial integration, we get

Substituting (12) into (11), we have

because of φ(k + 1) > φ(k), where W1 = − e−ρtΔγ k T D0Δγ k −ρ∫0 t e−ρtΔγ k T D0Δγ k dτ.
Substituting

Now using the partial integration, we get

Substituting (15) into (14), we have

where
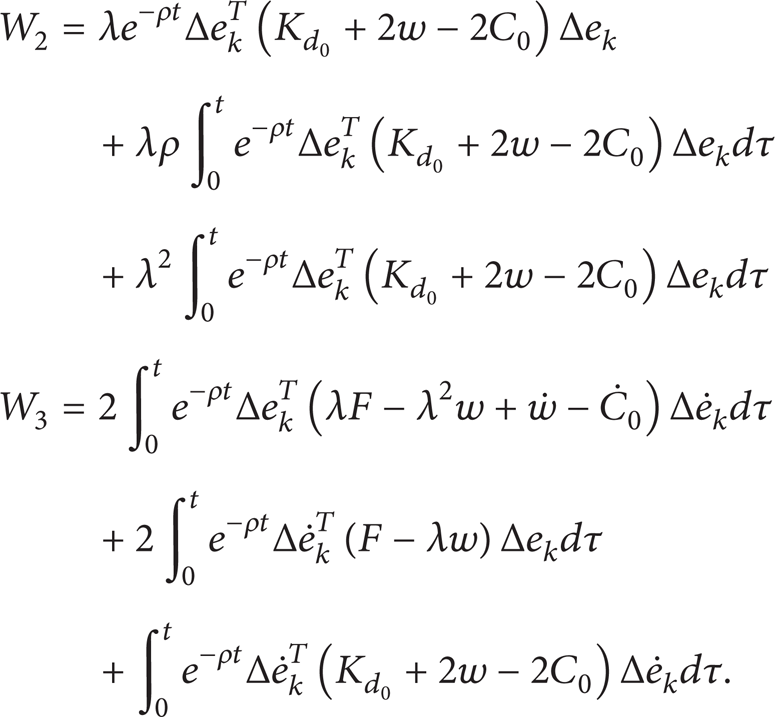
Using Cauchy-Schwarz inequality, we achieve

where λmin1 and λmin2 are the minimum eigenvalue.
Let us define 2λmin1λmin2 ≥ P = ∥F − λw∥max; hence

Based on W1, W2, W3, and W4, the nonpositivity of ΔV k 1 is guaranteed.
Part 2. The Difference of V k 2(t). For ΔV k 2(t), using the learning control law (6), we can obtain

Based on (16) and (20), the difference of E k (t) can be shown as follows:

According to Barbalat Lemma, we can easily obtain the uniform convergence of γ
k
(t) which leads to the fact that the external position tracking error e
k
(t) and velocity tracking error
Remark 7. Note that, in practice, the iteration number will not approach infinity; thus we can predefine a tracking error bound in the simulation, so that the iterative learning can be ceased timely as the tracking error reaches the bound. In this work, the bound is defined that the maximum position tracking error norm satisfies ∥e k (t)∥max ≤ 5 × 10−3 for any iteration.
4. Simulation
Let us consider a two-DOF robot manipulator described by (1) to verify the proposed algorithm. The matrix D(q
k
) = [d
ij
]2×2 is given by d11 = m1lc12 + m2(l12 + l22 + 2l1l2 cos q2), d12 = d21 = m2(l22 + l1l2 cos q2), and d22 = m2l22. The matrix
In the simulation, the desired reference trajectories are given as q1d = sin(3t) and q2d = cos (3t). The iteration cycle is T = 2π/3. The external repetitive perturbation d1 = 0.5sin(2t)*rank(k); nonrepetitive perturbation d2 = 0.1(1 − e−2t)*rank(k). In the controller of (4), Kp0 = Kd0 = 5I2×2, λ = 5, and ρ = λ2, where Ii × i is an i × i identity matrix. At the initial iteration, the joint position and joint velocity are, respectively, designed as q0(0) = [0, 1]
T
and
The simulation results are shown in Figures 1–5. From Figures 1 and 2, we can conclude that the trajectory converges to the desired trajectory at first or second iteration with the proposed control law. The tracking error decreases monotonically with the iteration number. Moreover, the error in first iteration decreases more sharply than other iterations. The stability and tracking performance have been improved largely.

Position trajectories of q1 and q2 for 10 iterations.
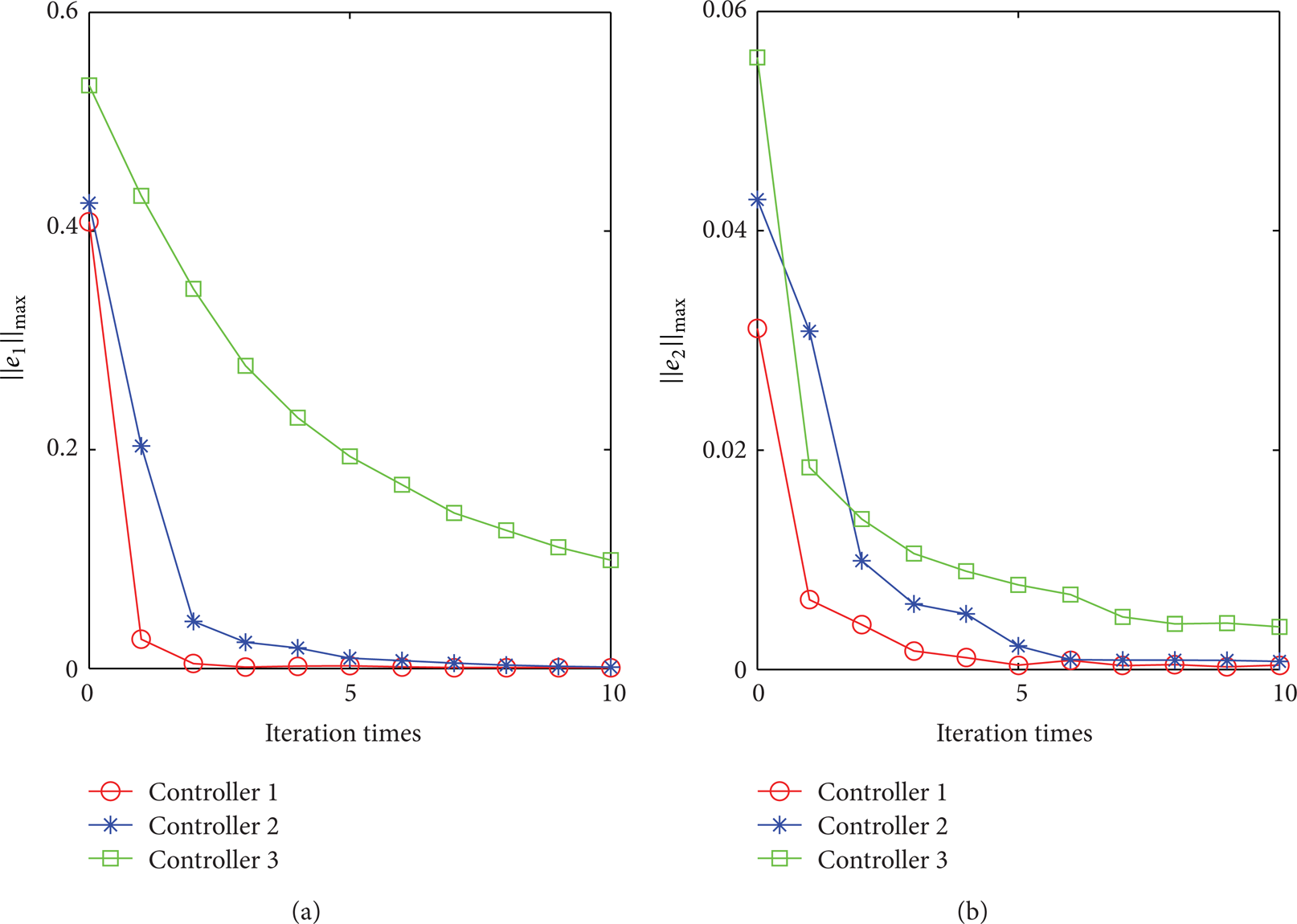
Comparison results in convergence of maximum position tracking error norm ∥e∥max controlled by three controllers.
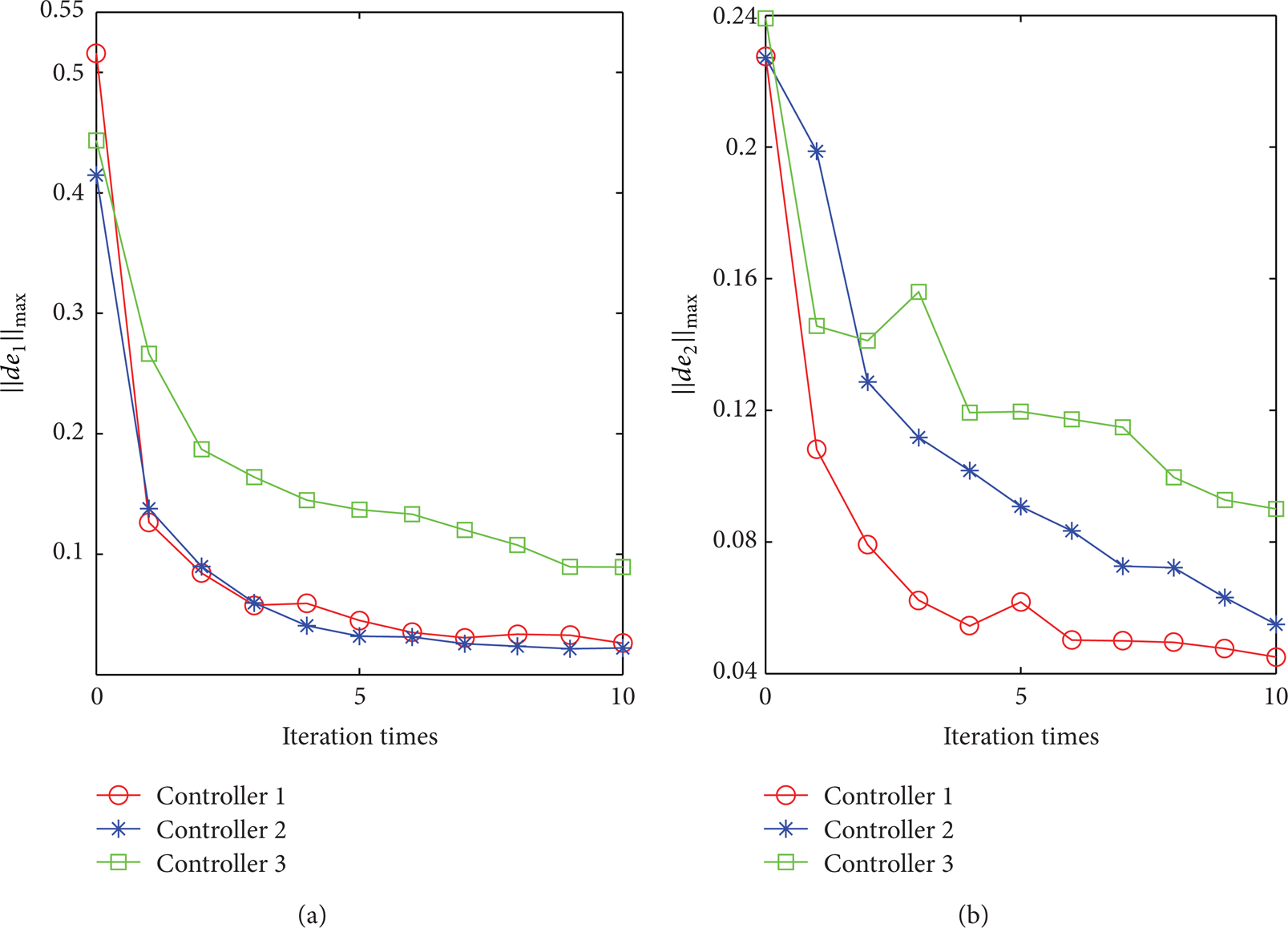
Comparison results in convergence of maximum velocity tracking error norm ∥de∥max controlled by three controllers.

Experimental test facility of three-DOF robot manipulator.

Experiments on actual robot manipulator controlled by proposed strategy.
In order to further verify the robustness of the proposed control algorithm, Figures 2 and 3 show the comparison results with other two types of control law, where Controller 1 represents the proposed RA-ILC controller, Controller 2 denotes a class of robust ILC controllers based on sign-function (proposed in [12]), and Controller 3 stands for the conventional PD-type ILC controller with no robust adaptive part. It can be seen that the proposed control law owns a more obvious advantage on tracking error magnitude and convergence speed. Note that the adaptivity perform active on various uncertainties and disturbances applied to Controllers 1 and 2.
For more deeply verifying the practical effectiveness of the proposed control algorithm, an actual experiment on three-DOF robot manipulator is shown in Figure 4 and Figure 5. In the experiment, the robot manipulator is required to finish a series of moving action, including movement to the given position and high precision trajectory tracking (angle, circle, broken line, etc.).
5. Conclusion
In this paper, a robust adaptive ILC under alignment condition for n DOF robot systems with uncertainties in modelling, external perturbation, and parameter is exploited. Based on the properties of robot systems and assumptions about the boundary of reference trajectory, the uniform asymptotical convergence of both position tracking error and velocity tracking error is guaranteed using Lyapunov's direct method with compensation for the uncertainties under alignment condition in the iteration domain. Particularly, substituting alignment condition for traditional initial condition assumption makes the proposed control scheme more practical and effective. By comparing the simulation results shown in Figures 1–3 and actual experiments on three-DOF robot manipulator as shown in Figure 4 and Figure 5, it is illustrated that the proposed control algorithm achieves strong robustness and effectiveness relatively.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Footnotes
Acknowledgments
This work is supported by the Natural Science Foundation of China (no. 61175031), the Science Foundation of Ministry of Education of China (no. 110204004), and the National High Technology Research and Development Program of China (863 Program) (no. 2012AA041402).