
Abstract
A vector quantizer is a system for encoding the original data to reduce the bits needed for communication and storage saving while maintaining the necessary fidelity of the data. Signal processing over distributed network has received a lot of attention in recent years, due to the rapid development of sensor network. Gathering data to a central processing node is usually infeasible for sensor network due to limited communication resource and power. As a kind of data compression methods, vector quantization is an appealing technique for distributed network signal processing. In this paper, we develop two distributed vector quantization algorithms based on the Linde-Buzo-Gray (LBG) algorithm and the self-organization map (SOM). In our algorithms, each node processes the local data and transmits the local processing results to its neighbors. Each node then fuses the information from the neighbors. Our algorithms remarkably reduce the communication complexity compared with traditional algorithms processing all the distributed data in one central fusion node. Simulation results show that both of the proposed distributed algorithms have good performance.
1. Introduction
Vector quantization is one of data compression methods, encoding information by fewer bits than the original representation to reduce the communication and storage burdens, while maintaining the necessary fidelity of the data. A vector quantizer is a system of mapping input vectors into corresponding reproduction vectors drawn from a finite reproduction alphabet. There are two kinds of vector quantization algorithms. If each input is encoded using a certain rule that is independent of previous inputs or outputs, the vector quantization algorithm is classified as a memoryless method, like the LBG algorithm and tree-searched vector quantization [1–3]. Another kind of algorithms are called feedback vector quantization algorithms, incorporating memory into quantizer in choosing different codebooks for each input, like the vector predictive quantization [4, 5]. In this paper, we consider the memoryless ones.
In sensor network, sensors are distributed over a wide-range area. The data collected by different sensors are often different because sensors are at different locations under different environments. So information from all sensors is needed to obtain the overall data structure. Each sensor is a small device with limited power. To process data, traditional signal processing algorithms need all data available at a central processor, which is infeasible for distributed sensor network because the sensors cannot afford large data communication to gather all the data to one fusion node. Therefore, distributed algorithms, which need less communication, are needed in signal processing over sensor network. In recent years, many distributed algorithms are proposed, such as the distributed estimation algorithms [6–10], distributed detection algorithms [11, 12], and distributed clustering algorithms [13–15]. These distributed algorithms deal with the information extraction from spatially distributed nodes and fulfill the processing task based on the local computations and information from the nodes' neighbors. Nodes only transmit necessary parameters to their nearest neighbors instead of gathering the whole data set to one fusion node, so as to reduce the communication complexity and provide better flexibility and robustness to node/link failures. Applications of distributed signal processing algorithms in environmental monitoring, military surveillance, and source localization and extraction have been promoted in recent years [16–19].
In this paper, we consider distributed vector quantization. When using a sensor network as an exploratory infrastructure, we need to transmit and store the data collected by sensors. With a well-designed vector quantizer, fewer bits are needed for the communication and storage. Vector quantization will be certainly beneficial for the following data processing. Therefore, for distributed sensor network, vector quantization is needed. The goal of this paper is to design distributed vector quantization algorithms, which do not need to transmit all the data to a fusion center. LBG [20] and SOM [21] algorithms are two of the most popular methods among the vector quantization algorithms. These two methods are both basic algorithms and many modified algorithms based on LBG and SOM are proposed to achieve better performance. Based on the basic methods, LBG and SOM, here we present two distributed vector quantization algorithms, distributed LBG algorithm, and distributed SOM algorithm. Other modified algorithms based on traditional LBG and SOM can be easily extended to distributed version by applying our distributed process.
The rest of this paper is organized as follows. In Section 2, we briefly introduce the vector quantization problem and describe the distributed vector quantization problem. Our distributed LBG algorithm is presented in Section 3 and distributed SOM in Section 4. We present the numerical experimental results in Section 5. Finally, we draw conclusions in Section 6.
2. Preliminary Knowledge
2.1. Traditional Vector Quantization
Mathematically, an N-level k-dimensional vector quantizer is a mapping, q, from each k-dimensional input vector,


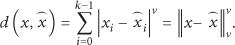
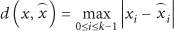
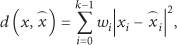
2.2. Distributed Quantization Problem over Sensor Network
When it comes to a large-scale network, we need a distributed vector quantization algorithm as the traditional vector quantization algorithm is infeasible due to the difficulty of gathering all the data to a central processor. We consider the distributed quantization problem over a sensor network. The graphical representation of distributed vector quantization problem is shown in Figure 1. Each node collects its own input vectors and the goal of distributed vector quantization is to obtain the overall reproduction alphabet. The network is a connected graph with no isolated node. Each node collects its own data which may be unbalanced so that the data of one node cannot reflect the data structure of all the data of the network. We assume that each node can only communicate with its one-hop neighbors and the message delivery is reliable with little time delay. We consider an N-level k-dimensional vector quantizer over sensor network. Let J denote the number of nodes in the network, let

The graphical representation of distributed vector quantization problem.
3. Distributed LBG Algorithm
3.1. LBG Algorithm
Here, we make a brief description of the well-known LBG algorithm [20]. The LBG algorithm aims to find the reproduction alphabet and the corresponding partition to minimize the expected distortion. The LBG algorithm is realized by a three-step loop. Given the initial reproduction alphabet For each input vector x, find the nearest reproduction vector If the total distortion between the input vectors and their corresponding reproduction vectors of the mth iteration, For each partition Replace m by
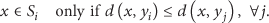

In step-1, we choose the minimum distortion reproduction vector for each input. By this step, we get the optimum partition for the current reproduction alphabet as (6). In step-2, we check the ending condition. Alternatively, we can check whether the partitions between two iterations are changed because the same partitions mean
3.2. Distributed LBG Algorithm
The traditional LBG requires that all data are available in a central processor and can be accessed in their entirety during each iteration. When the data are distributed over the network and the communication ability of the sensor network is limited, we need a new distributed algorithm to solve the distributed vector quantization problem. Here, we put forward our distributed LBG algorithm. In brief, each node, in our algorithm, executes several inner loops of a modified traditional LBG and then transmits the local results, the reproduction alphabet and the corresponding partition counts denoted as
At the beginning of our distributed LBG algorithm, we generate the initial reproduction alphabet

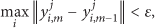
A summary of the distributed LBG algorithm is given as follows.
Initialization. Local data
Computation. Node j in iteration m of outer loop does:
Execute p inner loops of the three-step-loops of traditional LBG algorithm on local data Send local results of node j, Update the reproduction alphabet If
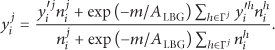
Termination. Algorithm ends when no message exchange is done in the network. We then compute the global reproduction alphabet by an average of local results weighted by partition counts.
3.3. Communication Complexity Analysis
In this section, we estimate the communication complexity of distributed LBG algorithm. According to our algorithm stated above, each node in the network needs to send each neighbor a copy of local results consisting of the reproduction alphabet and partition counts in each iteration of outer loops. Let q denote
3.4. Computation Complexity Analysis
In this section, we present the computation complexity analysis of traditional LBG and distributed LBG. For each iteration in traditional LBG, we find the nearest reproduction vector for each input data and calculate the centroid of each partition. The computation complexity for finding the nearest reproduction vector is
4. Distributed SOM Algorithm
4.1. SOM Algorithm
The self-organizing map (SOM) is a type of artificial neural network and is trained using unsupervised learning [21, 22]. A SOM network has N output nodes and one weight for each output node, where N is the number of vector patterns. The weights have the same size as the input vectors and self-organize their values in order to reflect the vector patterns. At the beginning, the weights are initialized to small random values. For a randomly chosen input vector

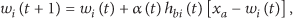

4.2. Distributed SOM Algorithm
Like the traditional LBG, the traditional SOM needs all the data available in one node, which is not feasible for distributed data. To deal with the distributed vector quantization problem, here we present the distributed SOM algorithm. As initialization, we generate the initial weights and threshold ϵ for all nodes. Distributed SOM algorithm is also an inner-outer loop algorithm. Outer loop consists of two parts, self-organizing part and fusion part. For iteration m of the outer loop, node j executes the algorithm as follows.
Self-organizing part is the inner loop of our distributed SOM algorithm and is similar to traditional SOM, adjusting the local weights using local input vectors. In addition to traditional SOM, we record and denote the matching counts as
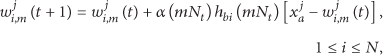
At the beginning of fusion part, each node sends its local results,
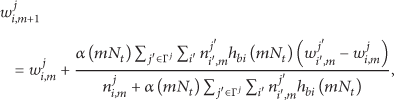

We here look back to the fusion updating formula of the distributed LBG algorithm. In fact, (8) can be rewritten as

Obviously, (17) shows that the fusion updating formula of the distributed LBG algorithm has similar form of the distributed SOM. The distributed LBG algorithm uses simplified neighbors kernel—one for best matching weight and zero elsewhere. Thus, the distributed LBG fusion formula is the simplified case of the distributed SOM fusion formula. In the two distributed algorithms, local results from other nodes are considered as one kind of inputs that represent the data structure of other nodes' data and the fusion is one kind of SOM learning. In fact, (15) can also be seen as an iterative algorithm for distributed average consensus [24] with attenuation. Each node updates its own parameter by adding a weighted and attenuated sum of the total difference between its neighbors' parameters and its own. We use these updating rules to fuse the local results of different nodes to obtain the global reproduction vectors.
The terminal condition of distributed SOM is the same as distributed LBG. After updating, we compare the difference between
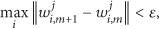
Initialization. Local data
Computation. Node j in iteration m of outer loop does
Set Record the best-matching counts Send local results of node j, Find the best-matching weight for each received weight and update the fusion weights
If


Termination. Algorithm ends when all nodes enter terminated state. The final weights are obtained by computing the average of local weights.
4.3. Communication Complexity Analysis
In this section, we estimate the communication complexity of the distributed SOM algorithm. Like what we do in the analysis of distributed LBG algorithm, let q denote
4.4. Computation Complexity Analysis
In this section, we present the computation complexity analysis of traditional SOM and distributed SOM. For each input vector in traditional SOM, we find the best matching weight in N weights and update all the N weights. Therefore, the computation complexity for one input vector is
5. Numerical Experiments
We study the behavior of distributed LBG algorithm and distributed SOM algorithm by simulation in this section. We first test our distributed algorithms under simple situation to observe the illustrative results. Then, tests of our algorithms under more complicated situation are also done to evaluate the performance in detail. In the following simulations, centralized LBG and centralized SOM, that is, traditional LBG and traditional SOM with input data gathered in one central processor, are denoted by c-LBG and c-SOM for short. Besides, nc-LBG and nc-SOM denote traditional algorithms carried out by each node with no-cooperation among nodes. Distributed LBG and distributed SOM are denoted by d-LBG and d-SOM.
In the simple situation, there are 10 nodes in the network and the input data are 2-dimensional, forming double-moon as showed in Figure 2. Each node has half inputs on one moon and half on the other. In other words, the inputs are balanced. Results of two different level quantizers, 8-level and 24-level, of the two distributed quantization algorithms are presented. Both of our distributed algorithms can obtain proper results under low and high level quantizer.

The illustrative results of our distributed algorithms. (a) Results of distributed LBG algorithm under low level quantizer. (b) Results of distributed LBG algorithm under high level quantizer. (c) Results of distributed SOM algorithm under low level quantizer. (d) Results of distributed SOM algorithm under high level quantizer.
In the complicated situation, much more detailed evaluation on the performance is presented. Here we first describe the simulation environment and the data generation. Then, we give the measure of performance of our vector quantization algorithms. At last, we present the results of our experiments.
5.1. Experiment Environment Setup
We test our distributed algorithms in networks consisting of 20 nodes. Nodes form a circle and each node is connected to two nearest nodes, respectively, in the left and right. Besides, two nonadjacent nodes are connected with a probability
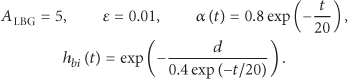
5.2. Data Generation
All the data used in our experiment are 2-dimensional data generated from a mixture of a square and two half-rings disturbed by uniform noise distributed over range

The schematic plot of experimental data.
To mimic the real sensor network environment, we test our algorithms using unbalanced data. Considering the center of the square as the origin of the coordinates, we divide the coordinate plane into four quadrants,
5.3. Measure of Performance
We measure the performance of the quantization algorithms by the total distortion between each input vector and its corresponding reproduction vector. In this paper, we use the most common squared-error distortion for convenience. In addition to the results of our distributed LBG algorithm and distributed SOM algorithm, we also present the results of centralized LBG algorithm and centralized SOM algorithm, as well as the no-cooperation LBG algorithm and no-cooperation SOM algorithm. Obviously, centralized algorithms should perform best as the overall structure of data can be got at the cost of high communication complexity. We should be happy if the results of our distributed algorithms can approach that of the centralized algorithms, as we do not transmit the original input data. The no-cooperation distortion of a node is defined as the total distortion between all the input vectors and the individual quantization reproduction vectors of this node. Then, the overall no-cooperation distortion is the average of the distortion of all nodes.
In the numerical experiment, all the results are the average of independent 100 trails.
5.4. Result
To see the convergence process of the distributed algorithms, we present the distortion curves during outer loops of one typical trial in the balance case in Figure 4. As evident from the figure, the distortions of both distributed quantization algorithms decrease when algorithms carry on. Both algorithms converge after several outer loops. The distortion of distributed LBG is larger than that of distributed SOM. Moreover, the number of loops of distributed LBG is also larger than that of distributed SOM. What calls for attention is that the distortion curves during outer loops are just observed results. Whether the algorithms end or not depends on the max difference between the reproduction vectors of two sequential iterations of outer loop.

The evolution of the distortion of the distributed algorithms during outer loops.
5.4.1. The Influence of Unbalance
Here we present the performance of our distributed algorithms under different data unbalance conditions. Figure 5 shows the quantization distortion of distributed LBG algorithm (

Results of total distortion of quantization algorithms under different unbalance level. (a) The results when
As evident from the figure, the results of distributed LBG algorithm are quite stable under different unbalance levels. The increase in unbalance does not have an obvious effect on the distortion performance. However, for the distributed SOM algorithm, the increase in unbalance has significant effect on the distortion performance. The performance of the distributed SOM algorithm is better than that of the distributed LBG algorithm under low unbalanced condition but worse under high unbalanced condition. The performance of distributed SOM under unbalance level-0 is particularly good and quite close to that of centralized SOM algorithm. The results of no-cooperation LBG and SOM are heavily worse than those of the distributed algorithms, especially under high unbalance level. The results under different r values lead to the same conclusion.
As analyzed in Sections 3.3 and 4.3, the communication complexity of our distributed algorithms is directly related to the number of outer loops executed by the algorithms. Figure 6 shows the number of outer loops needed by our distributed algorithms under different unbalance levels. Higher unbalance increases the number of outer loops needed by the distributed LBG obviously but nearly has no influence on the distributed SOM. The numbers of outer loops of the distributed LBG are significantly larger than those of the distributed SOM under all unbalance level conditions. Different r values have little influence on the number of outer loops for both the distributed LBG and SOM algorithms.

The number of outer loops of quantization algorithms under different unbalanced conditions.
5.4.2. The Influence of Inner Loop Parameter p
In the distributed LBG algorithm, p inner loops of traditional LBG-steps are executed in each node before information communication. We are interested in the influence of inner loop parameter p. We check the distortion performance and outer loops of our distributed LBG algorithm with different parameter p under different unbalance levels. Figure 7 shows the distortion performances of

The total distortion of distributed LBG algorithm under different p values.
In both
Figure 8 shows the outer loops needed by distributed LBG algorithms under different p values. The loops needed when

The number of outer loops needed by distributed LBG algorithm under different p values.
5.4.3. The Influence of Inner Loop Parameter
In the distributed SOM algorithm,

The total distsortion of distributed SOM algorithm under different
From Figure 9, we can see that the distortion curve of
Figure 10 shows the outer loops needed by distributed SOM algorithm when

The number of outer loops needed by distributed SOM algorithm under different
5.4.4. The Communication Complexity Performance
Here we present the communication complexity performance of our distributed algorithms. We check the performance of
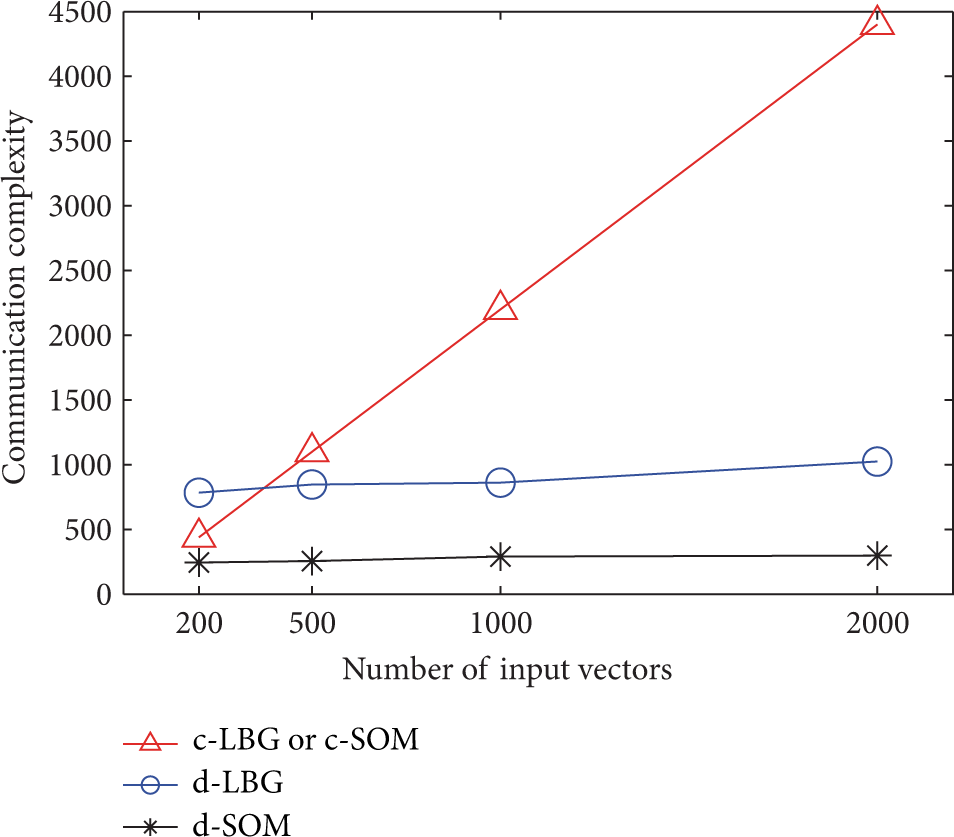
The communication complexity performance of distributed and traditional algorithms under different numbers of input vectors of each node.
5.4.5. The Computation Speed Performance
Here we present the computation speed performance of our distributed algorithms. The simulation is run by matlab 7.0 and using a PC with CPU of 2.1 GHz and 2 G RAM. We check the computing time (seconds) of different L,

The computation time of the distributed and traditional algorithms under different numbers of input vectors of each node. (a) The results of the distributed LBG and traditional LBG. (b) The results of the distributed SOM and traditional SOM.
6. Conclusion
In this paper, we consider vector quantization in the situation that data are distributed over network. Traditional vector quantization algorithms are not feasible for distributed data because they need all the data available in a central processor which results in heavy data communication burden. Thus, in this paper, we propose two distributed quantization algorithms to solve the distributed quantization problem without centralizing the data to one node. Our distributed algorithms work by local quantization and neighbor communication. Our experiments show that the distributed LBG algorithm has a stable distortion performance under different unbalance levels but costs more outer loops than the distributed SOM algorithm. The distortions of the distributed LBG are little affected by data of different unbalanced degree, while the outer loops needed increase obviously when the degree of unbalance increases. The distortion performances of the distributed SOM are significantly affected by the unbalance level and get larger obviously when unbalance level increase. The outer loops of distributed SOM are less than that of the distributed LBG and almost stay unchanged when the unbalance level increases. As a conclusion, the distributed LBG algorithm is more suitable for unbalanced condition while the distributed SOM algorithm is more suitable for balanced condition. Compared with the centralized algorithms which need all data available in one node, our distributed algorithms require less communication resource if there are large amount of data distributed over the sensor network. When the communication resource is severely limited, the distributed SOM algorithm is more preferred, since the number of outer loops (the times of communication) needed is small.
As our algorithms are based on basic vector quantization algorithms, we believe that some other centralized vector quantization algorithms can also be extended to distributed version using our distributed protocol. For example, we may develop distributed vector quantization based on information theory.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant nos. 61171153, 61201326, and 61101045), the Open Research Grants by Key Laboratory of Visual Media Intelligent Processing Technology of Zhejiang Province, the Zhejiang Provincial Natural Science Foundation of China (Grant no. LR12F01001), and the National Program for Special Support of Eminent Professionals.