
Abstract
The problem of missing data in multiway arrays (i.e., tensors) is common in many fields such as bibliographic data analysis, image processing, and computer vision. We consider the problems of approximating a tensor by another tensor with low multilinear rank in the presence of missing data and possibly reconstructing it (i.e., tensor completion). In this paper, we propose a weighted Tucker model which models only the known elements for capturing the latent structure of the data and reconstructing the missing elements. To treat the nonuniqueness of the proposed weighted Tucker model, a novel gradient descent algorithm based on a Grassmann manifold, which is termed Tucker weighted optimization (Tucker-Wopt), is proposed for guaranteeing the global convergence to a local minimum of the problem. Based on extensive experiments, Tucker-Wopt is shown to successfully reconstruct tensors with noise and up to 95% missing data. Furthermore, the experiments on traffic flow volume data demonstrate the usefulness of our algorithm on real-world application.
1. Introduction
Missing data can be recognized as the problem that occurs in the data collection process. This problem is of considerable practical interest. Recently, it has been shown that data often have more than two modes of variation and are therefore represented as multiway arrays (i.e., tensors). For example, in internet network traffic flows analysis, the network traffic flows can be modeled as a fourth-order tensor with source IP, destination IP, port number, and time [1, 2]. If a sequence of traffic flows is missing, how can we recover them from the underlying information? Other examples include bibliographic data analysis [1, 2], image in-painting [3, 4], video in-painting [5], and data analysis [6]. Thus, it is necessary to develop a tool for reconstructing efficiently the tensors with missing data.
The low rank approximation or completion problem on matrix is studied in science and engineering to estimate missing values, such as computer vision, machine learning, and signal processing. Ruhe [7] proposed the low rank matrix approximation with missing data while considering the underlying decomposition factors. Srebro and Jaakkola [8] formulate the problem using singular value decomposition. Golub and Van Loan [9] proposed a manifold optimization approach based on truncated singular value decomposition (T-SVD) for matrix completion due to the nonuniqueness of the T-SVD, and the implementation of the algorithm was described in [10]. Ma et al. [11] applied fixed point and Bregman iterative method, and Cai et al. [12] proposed a singular value thresholding algorithm to solve the rank minimization problem.
Instead of flattening multiway arrays into matrices and using techniques for matrix, tensor-based methods can preserve the multiway nature of the data and extract the underlying factors in each mode of a higher-order tensor. The methods consist of two main types of methods: methods based on tensor decomposition and methods based on trace norm.
In this paper, we focus on low multilinear rank approximation of tensors with missing data based on Tucker decomposition [13], since Tucker decomposition is more general than CP and CP can be regarded as a special case of Tucker decomposition. Our goal is to capture the global structure of the data via a Tucker model in the presence of missing entries and recover them. In the two-way case, that is, the matrix case, the rank is a powerful tool to capture the global information. However, the properties of tensor ranks are quite different from matrix. There is no straightforward algorithm to determine the rank of a given tensor [14], and tensor rank is difficult to minimize in general since it is a nonconvex function (it is also a nonconvex function for matrix rank). Fortunately, a tensor can also be represented by Tucker model [13], whose rank can be represented by multilinear tensor rank (comparing with CP-rank, the definitions refer to Section 3). Therefore, the multilinear rank can be used for exploiting the global information instead of the CP-rank of a given tensor in low multilinear rank approximation problem.
Considering the missing tensor entries and noise in the observed elements, we formulate the low multilinear rank approximation problem as

where

Tucker decomposition is not unique. Consider the three-way Tucker decomposition in (1). Let
A consequence of the property is that the solutions of f w are not isolated. Thus, numerical methods might have difficulties converging to a solution [15]. That is, (1) does not have an isolated local minimum, which severely degrades the performance of standard optimization algorithms.
Considering the existing nonuniqueness problem of the Tucker decomposition, a novel method is proposed based on Grassmann manifold to minimize the weighted function in (1). The proposed method is termed as Tucker weighted optimization (Tucker-Wopt). Let the subspace spanned by the columns of
The proposed Tucker-Wopt is related to the work in [10, 16], in which a manifold optimization approach based on T-SVD was proposed. The differences between the two methods are that (1) we extend the matrix case to tensor case by laying out the theoretical foundations and then build an efficient algorithm by using nonlinear optimization technique on Grassmann manifold and (2) that we focus on low multilinear rank approximation problem with missing data which is different and more complex than the matrix case. Another related work is CP-Wopt proposed by Kolda and Bader [14], which is also a first-order optimization method. However, we focus on the most general tensor decomposition (i.e., Tucker) and optimize the problem on Grassmann manifold for ensuring the uniqueness of the final solution. Our method is also different from the method based on Tucker decomposition presented in [17, 18], where the presented method is used for comparing with low rank tensor completion (LRTC), and their objective function does not consider the existed noise and the uniqueness of the optimal solution and is optimized by block coordinate descent method (BCD).
The proposed algorithm Tucker-Wopt is tested on both simulated data and real traffic volume data. Experiments show that Tucker-Wopt outperforms the traditional imputing-based methods especially when the ratio of missing data is high and the data sets are corrupted by noise. Tucker-Wopt is able to reconstruct the low multilinear rank tensor efficiently even when the ratio of missing data is up to 95%. Experiments on traffic flow volume data demonstrate the usefulness of our algorithm in real-world application.
This paper is organized as follows. Section 2 overviews related work of the existing tensor-based methods for missing data and the traditional methods for missing traffic volume data. Section 3 introduces the notation used in the paper. The proposed algorithm is described in Section 4. Numerical results on both simulated and real data are given in Section 5. Conclusions and possible future work are in Section 6.
2. Related Work
2.1. Existing Tensor-Based Methods for Missing Data
To estimate the missing entries in a low rank tensor, tensor completion methods which try to minimize the tensor rank have been proposed [17–20]. Liu et al. proposed tensor completion based on trace norm, optimizing the objective function by block coordinate descent algorithm (BCD) [19] and alternating direction method of multipliers (ADMM) [17, 18]. Gandy et al. [20] built the objective function based on multi-n rank instead of trace norm, optimizing the objective function by ADMM.
For the methods based on tensor decomposition, CANDECOMP/paraFAC (CP) [21] decomposition and Tucker decomposition [13] are the two most widely used decomposition models. Smoliński et al. [22] proposed EM-Tucker3 method which incorporates EM in alternating least squares (ALS) procedure to estimate missing elements based on Tucker decomposition. Nevertheless, as the amount of missing data increases, the performance of the algorithm may suffer since the initialization and the intermediate models used to impute the missing values will increase the risk of converging to a less optimal solution. Tomasi and Bro [23] developed an INDADAC (Incomplete Data paraFAC) procedure that uses the Levenberg-Marquardt version of GN for fitting the CP model for data with missing values. The method is a second-order optimization and a first-order method has been developed called CP-WOPT [24] with the goal of scaling to larger problem sizes. CP-WOPT is always faster than the best alternative approach based on second-order optimization (INDAFAC) and even faster than EM-ALS with high percentage of missing data. However, just as Acar et al. [24] pointed, CP-WOPT could not fulfill the case of data with different structure for each mode. It may be possible to perform better using a more flexible model such as the Tucker model.
2.2. Existing Methods for Missing Traffic Volume Data
The spatial and temporal correlations of traffic volume data are critical for imputing the missing traffic volume data. The traditional methods involve the techniques such as historical (neighboring) imputation methods [25] and spline (including linear)/regression imputation methods [26]. These methods model the traffic data as vector pattern, which can cover few spatial-temporal information. Then spatial/temporal correlations are used to impute missing traffic data when few data are missing. Recently, the development of imputation techniques is moving on a statistically principled track. Bayesian Principal Component Analysis (BPCA) algorithm and Probabilistic Principal Component Analysis (PPCA) [27] model the traffic data as matrix pattern, which can cover more spatial-temporal information than vector pattern, and impute the missing traffic data from the whole matrix based on spatial-temporal correlations. These methods have been proved to be more effective with higher accuracy than the traditional imputation methods for missing traffic volume data.
As mentioned above, traditional methods mostly only exploit part of correlations, such as historical or temporal neighboring correlations. And the statistically principled methods usually utilize the temporal correlations of traffic data from day to day. In fact, there are many correlations existing in traffic volume. For example, the traffic data temporal correlations contain the relations from day to day, hour to hour, and so forth. In addition, the spatial correlations exist in the adjacent detectors data. However, these correlations are not explored fully or simultaneously in previous imputing methods. Considering the situation, the missing traffic volume data is solved by the tensor-based methods in this paper.
3. Notation
This work partially adopts the notation in Acar et al. [24] and Ishteva [15]. Throughout this paper, third-order tensors are denoted by calligraphic letters (𝒜, ℬ,…), matrices by boldface capitals (
The elements of a third-order tensor are referred to by three indices. The mode-1 vectors of the tensor are defined to be its columns and the mode-2 vectors are its rows. In general, the mode-n vectors (n = 1, 2, 3,…, N) are obtained by varying the nth index, while keeping the other indices fixed. The number of linearly independent mode-n vectors is called mode-n rank. It is a generalization of column and row ranks of a matrix. Different from matrix rank, mode-n ranks are not equal to each other in general.
The mode-n products
where 1⩽i n ⩽I n , 1⩽j n ⩽J n .
An N-way tensor can be rearranged as a matrix; this is called matricization, also known as unfolding or flattening. The mode-n matricization of a tensor

where 1⩽i1⩽I1, 1⩽i2⩽I2, and 1⩽i3⩽I3.
Given two tensors 𝒜 and ℬ of the same size I1 × I2 × I3, their Hadamard (elementwise) product is denoted by 𝒜*ℬ and defined as

and the scalar product of 𝒜 and ℬ is defined as

For a tensor 𝒜 of size I1 × I2 × I3, its norm is

Let 𝒜𝒲 be the I1 × I2 × I3 observed tensor that stores all the observed values, such that

4. Tucker-Wopt Algorithm
In this section, we will present the Tucker-Wopt algorithm for the low multilinear rank approximation problem of tensors with missing data. For simplicity, we only consider third-order tensors. The generalization to tensors of order higher than three is feasible.
4.1. Cost Function
Let 𝒜 be a real-valued tensor of size I1 × I2 × I3. From function (1), the low multilinear rank approximation problem of tensors with missing data can be formulated as
Here,
4.2. Gradient Descent on the Grassmann Manifold
Because

where
In fact, M = St(R1, I1)/O
R
1
× St(R2, I2)/O
R
2
× St(R3, I3)/O
R
3
is the product quotient manifold of the product Stiefel manifolds
Theorem 1. The relationship between gradient of F(
where

and shew(
The detailed proof of Theorem 1 is presented in the Appendix of this paper.
Let 𝒮0 be the minimum point; the function (10) can be represented as

The function (14) is equivalent to

where ℬ = 𝒲*𝒜 and 𝒞 = 𝒲*(𝒮0×1

The gradient of the function

Combining (12) and (13), a closed-form expression for the gradient of F(
In the following, we use a compact representation
4.3. Optimization on Manifold
Minimizing F(
HOSVD [29, 30] is a generalization of the singular value decomposition (SVD) [9] which can give the best low rank approximation of a matrix. However, truncation of HOSVD results in a suboptimal solution of the best low multilinear rank approximation problem. But it can serve as a good starting point for iterative gradient descent algorithm.
Apply the HOSVD on the observed tensor 𝒜𝒲

for a so-called core-tensor
For any step size τ, it is shown in Armijo [31] that this algorithm converges to a stationary point. The algorithm stops when the fit error
The pseudocode of the Tucker-Wopt algorithm is given in Algorithm 1. In step 1, the initial mode matrix (

Tucker-Wopt.

5. Experiments
The proposed Tucker-Wopt algorithm for missing tensor value estimation is implemented with MATLAB on a Windows Workstation with a Dual-Core Intel(R) Xeon (TM) 2.8 GHZ CPU and 1 GB RAM. In this section, the performances of proposed method are evaluated both on simulated and real-world traffic data and compared with previous tensor-based method, such as Tucker-EM and CP-Wopt, for missing data estimation.
5.1. Performances on Noiseless Synthetic Data
To evaluate the performance of missing data estimation on noiseless data, we use the generated 3-mode I1 × I2 × I3 test tensor 𝒜 with mode-n rank (r1, r2, r3) as the synthetic test data. To impose these rank conditions, 𝒮 is r1 × r2 × r3 core tensor with each entry being sampled independently from a standard Gaussian distribution 𝒩(0, 1).
To show the superiority of proposed method, Tucker-Wopt is compared to EM-Tucker3 (implemented in the N-way Toolbox for MATLAB, version 3.10 [32]). Both of the two algorithms are tested in two types of missing data: randomly missing and structured missing data by randomly missing fibers. For Tucker-Wopt and EM-Tucker3, the stopping condition
5.1.1. Results with Randomly Missing Elements
In the case of randomly missing elements, we consider the performances on moderate-sized problems of size 50 × 50 × 50 and 100 × 100 × 100. For both sizes, we set the mode-n rank of the tensor to (5, 5, 5) and the missing rate to 20%, 40%, 60%, 80%, 90%, and 95%. The weight tensor 𝒲 is a binary tensor such that exactly (m × I1 × I2 × I3) randomly selected missing elements are set to zero, where m ∈ (0, 1) defines the percentage of missing data. It is required that every slice of 𝒲 (in every direction) has at least one nonzero element, since the underlying Tucker model cannot be reconstructed. This is the generalization of the problem of coherence in the matrix completion problem that a matrix cannot be recovered if there is a whole missing row (or a column).
The convergence rates of Tucker-Wopt for tensors of size 50 × 50 × 50 are reported in Figure 1, where the fit error
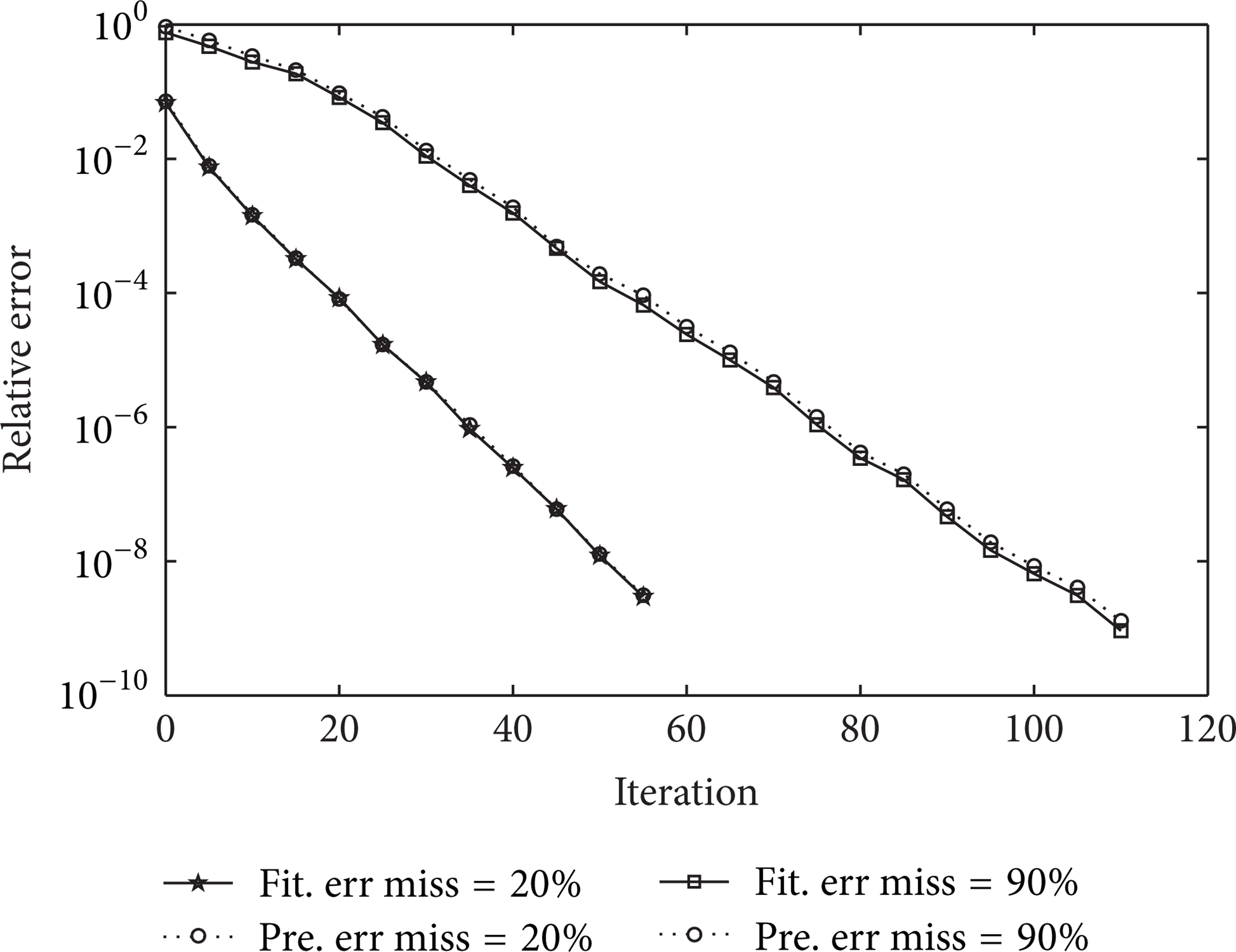
Prediction and real fit errors versus the number of iterations of the manifold optimization step for tensors of size 50 × 50 × 50 and mode-n rank (5, 5, 5) with different percentages of missing data: 20% and 90%.
Experimental results also show that EM-Tucker3 converges slower in the case of low missing data rate and does not converge in the case of high missing data rate, while the proposed Tucker-Wopt converges faster in all cases of data sets with different missing ratio. Figure 2 illustrates the convergence of Tucker-Wopt and that of EM-Tucker3 for the tensors of size 50 × 50 × 50, mode-n rank as (5, 5, 5), and 90% missing data.
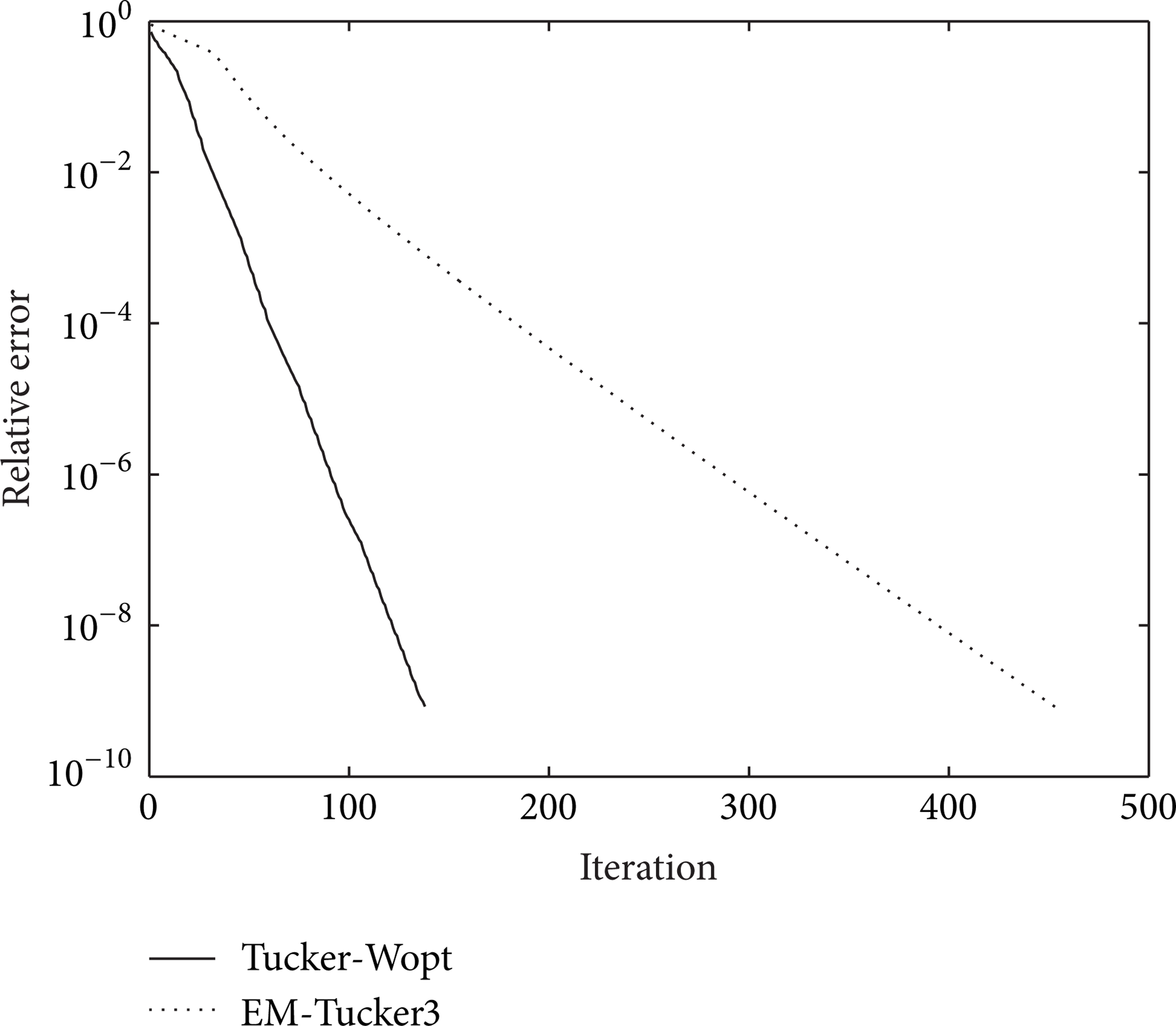
Comparison of the convergence of Tucker-Wopt and EM-Tucker3 for the problems of size of 50 × 50 × 50, mode-n rank as (5, 5, 5), and 90% randomly missing data.
Figure 3 demonstrates the relative error
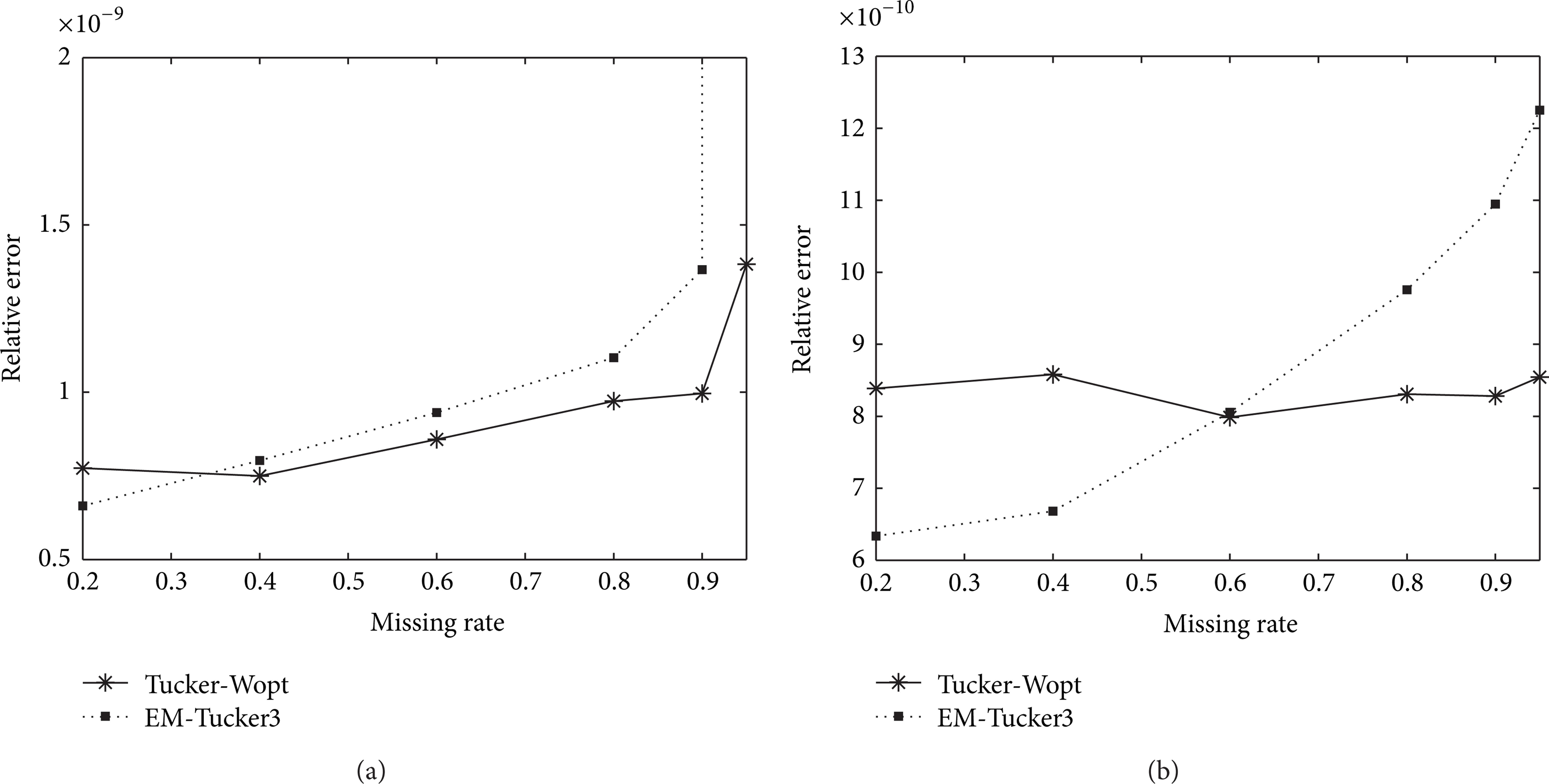
Comparison of relative error for 50 × 50 × 50 and 100 × 100 × 100 tensors in (a) and (b), respectively, where mode-n rank is set as (5, 5, 5) for randomly missing elements with different percentages of missing data.
The proposed method outperforms EM-Tucker3 in most cases; the reason might be that Tucker-Wopt can capture the global information of tensors and keep the overall structure of data sets. EM-Tucker3 is based on EM framework that exploits the local information of tensors only, and therefore the relative errors rise sharply with the increasing of missing data ratio.
5.1.2. Results with Structured Missing Data
The setup for experiments with structured missing data is similar to that for randomly missing data. Let
Figure 4 presents results for data sets of size 50 × 50 × 50 and 100 × 100 × 100 with missing fibers, respectively. Similar to the case of randomly missing elements, the relative error increases with the percentage of missing data. However, one notable difference is that the relative errors for structured missing data are in general greater than those for randomly missing data with comparable amounts of randomly missing elements. Also, in the case of randomly missing data, the Tucker-Wopt can recover the missing data up to 95% missing rate, while, in the case of structured missing data, it can recover the miss data up to 90%. This indicates that problems with structured missing data are more difficult than those with randomly missing elements.
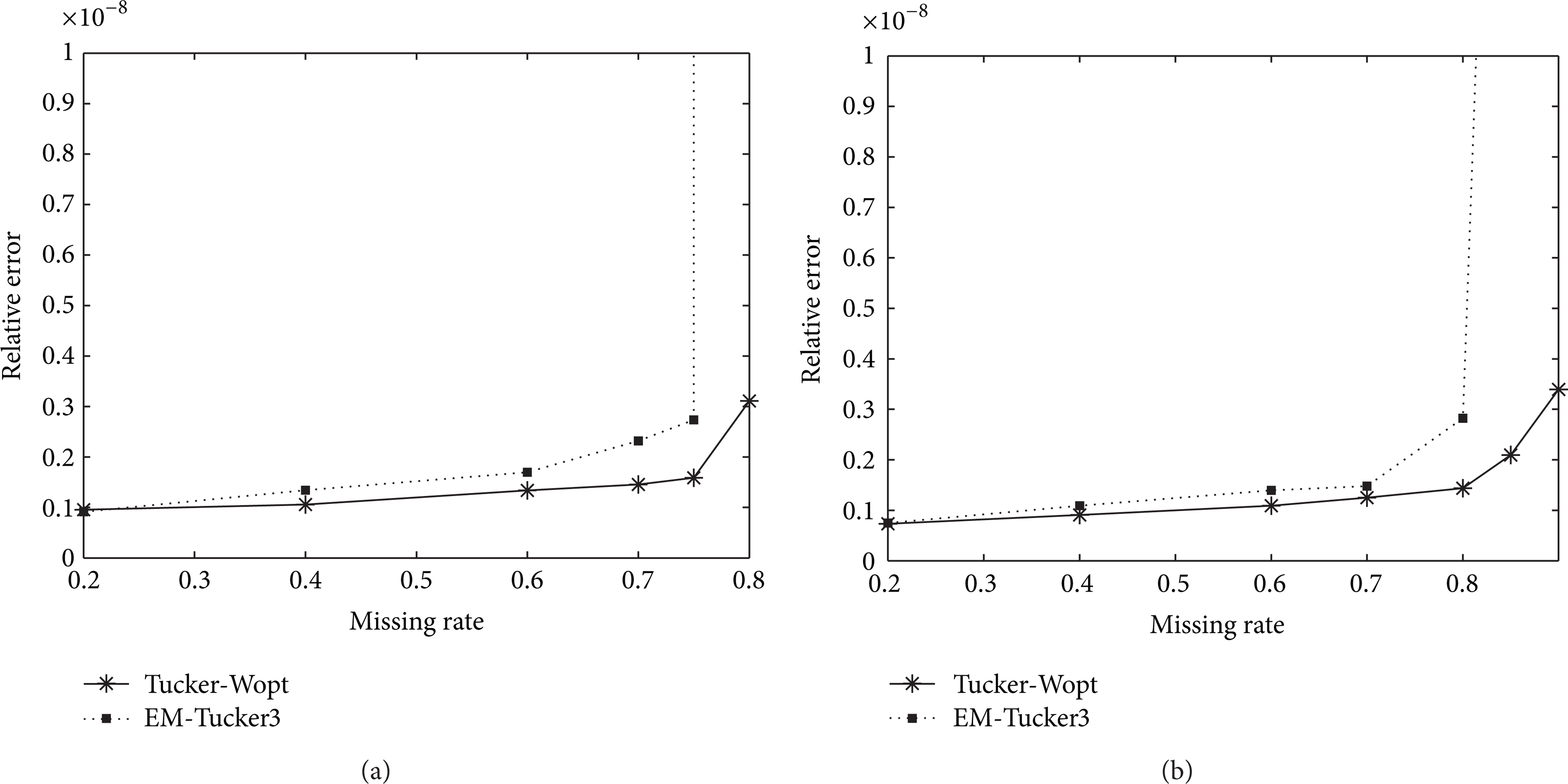
Comparison of relative error for structured missing data on 50 × 50 × 50 (a) and 100 × 100 × 100 (b) tensors, respectively, where mode-n rank is (5, 5, 5).
5.2. Performances on Noisy Observations
For the case with noisy observations, we also compare Tucker-Wopt with EM-Tucker3. To speed up the convergence, the iteration procedure is stopped when the difference of the fit error between adjacent iterations gets down to a threshold (set to 10−8). Other setups are the same as noiseless observations.
The proposed algorithm is tested on tensors of size 50 × 50 × 50, and, furthermore, it is tested with regularization with λ = 0.003 × (1 − m), where m is the missing rate of tensors. The value of λ used in this paper is based on our experience. Tensors are generated as above but corrupted by additive noise. The noises are independently and identically distributed according to a Gaussian distribution 𝒩(0, 1). Again, the mode-n rank of tensors is set to (5, 5, 5) and the missing rate is set from 20% to 90% with interval of 10%.
Figure 5 plots the relative errors of Tucker and EM-Tucker3 with noise. Similar to the problems without noise, both Tucker-Wopt with regularization and Tucker-Wopt without regularization outperform EM-Tucker3. For noisy data, the Tucker-Wopt with regularization performs better than the Tucker-Wopt without regularization.

Comparison of relative error for noisy observation on 50 × 50 × 50 tensor, where mode-n rank is (5, 5, 5).
5.3. Compare with CP-WOPT
CP and Tucker decomposition are the two most well-known tensor decompositions, and, in fact, the former is a special case of the latter. Thus, for illustrating the generalization of Tucker-Wopt, we compare it with the CP-WOPT.
CP-WOPT [24] is implemented by the Tensor Toolbox [33]. Nonlinear conjugate gradient (NCG) is used with Hestenes-Stiefel updates [34] and the Moré-Thuente line search [35] provided in the Poblano Toolbox [36]. See Acar et al. [24] for more details.
The experimental parameters are set as follows. For Tucker-Wopt and CP-WOPT, the stopping condition which is the relative change of the function value F in (13) is set to 10−8, and the maximum number of iterations is set to 1000. Specially, in CP-WOPT, the tolerance on the 2-norm of the gradient divided by the number of entries in the gradient is set to 10−8.
Both algorithms are compared on 50 × 50 × 50 and 100 × 100 × 100 tensors. They are investigated with 20%, 40%, 60%, 80%, and 90% missing data. In CP-WOPT, similar to Acar et al. [24], the size of tensor is I × J × K and the number of factors is R. We generate factor matrices
Figure 6 shows the relative error of different missing ratios for Tucker-Wopt and CP-WOPT on 50 × 50 × 50 and 100 × 100 × 100 tensors, respectively. All the results are averaged over 10 runs. Results show that Tucker-Wopt is not only suitable for the special Tucker model (i.e., CP) but it performs better than CP-WOPT.
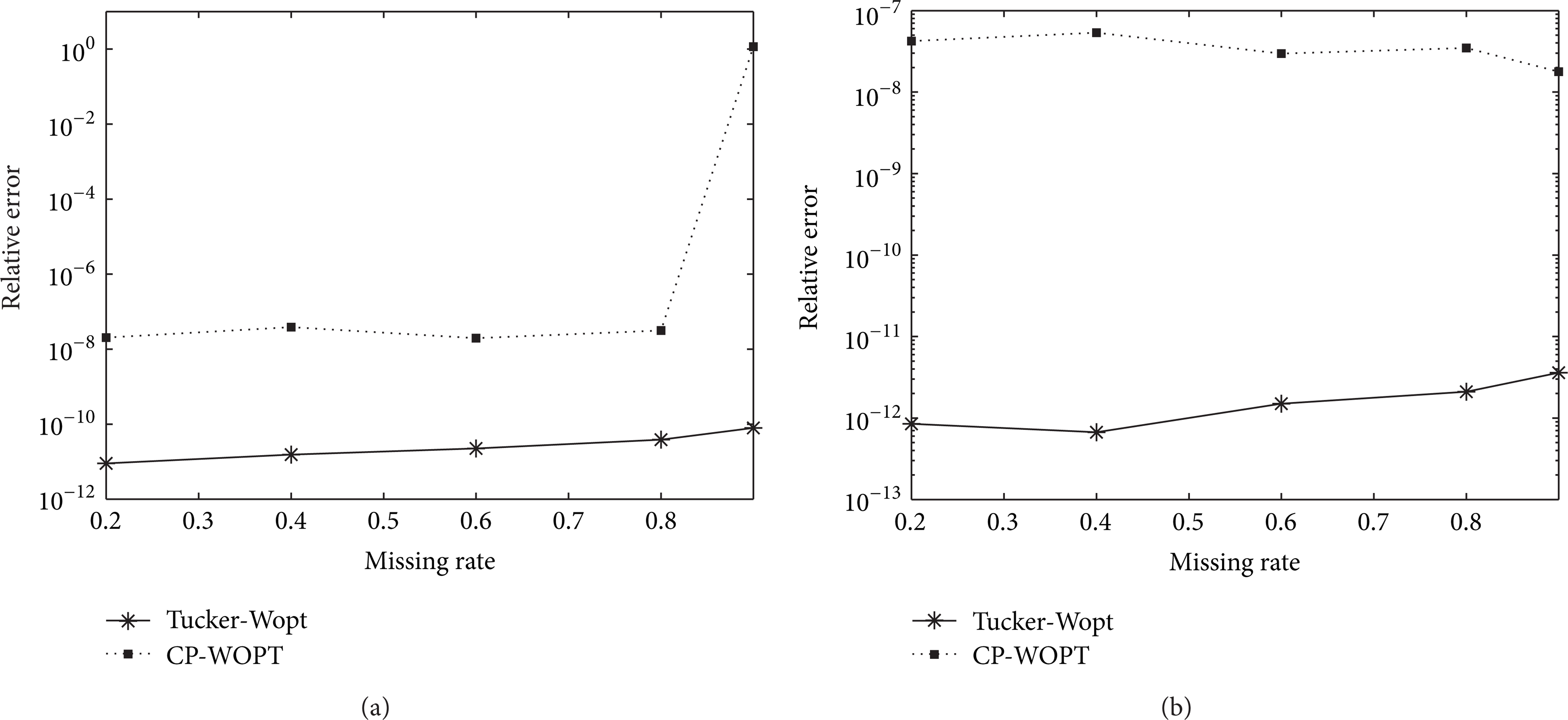
Comparison of relative error of Tucker-WOPT and CP-WOPT on 50 × 50 × 50 (a) and 100 × 100 × 100 (b) CP model with different missing ratios, respectively.
5.4. Traffic Flow Volume Data
Besides test on synthetic data, the proposed method is also applied to real-world missing traffic volume data estimation. Traffic volume data is important for appropriate traffic control strategies. However, some data are usually missed due to various reasons, such as the loss of data package during transmission in intelligent transportation systems (ITS) or detector malfunction [27]. An assumption is adopted that the traffic flows through the same loop have a high similarity form day to day [25]. With this assumption, the traffic flow volume data can be considered as low rank data. Then the missing traffic volume can be completed by our proposed method.
The traffic flow volume data at a site in Sacramento County downloaded from PeMS database (http://pems.dot.ca.gov/) are used for test. We use 16-days traffic flow data on one link which are recorded every 5 minutes and construct the data as a tensor of size 16 × 24 × 12, namely, 16 days, 24 hours, and 12 intervals per hour. Then the data is preprocessed as a Tucker model with multilinear rank (2, 2, 2).
Figure 7 illustrates the relative errors for different missing rates. Here, the definition of model error [24] is adopted for 2-component CP model as

Comparison of relative error for problems of real traffic flow volume data with different percentages of missing data.
It can be seen in Figure 7 that the relative error is around 0.14 for lower missing data rate, and, furthermore, it increases very slowly with the missing data rate; for example, it is around 0.147 for 80% missing rate. When the missing rate is less than 80%, Tucker-Wopt performs comparable to EM-Tucker3 and CP-WOPT. However, the relative error of CP-WOPT increases sharply when the missing rate is higher than 90%, while Tucker-Wopt still can recover the missing data with a relative error around 0.168. Our proposed algorithm is more robust for the traffic flow volume data than CP-WOPT with high missing data rate.
6. Conclusions
In this paper, we present a low multilinear rank tensor approximation based on Tucker model, named as Tucker-Wopt, in the presence of missing data. As the nonuniqueness of Tucker model, we propose a novel gradient decent method on Grassmann manifold which is for ensuring the global convergence of a local optimal solution.
Experimental results demonstrate that our proposed Tucker-Wopt algorithm is promising to missing tensor data estimation. Since the global information of tensors can be captured by Tucker-Wopt while the EM-Tucker3 just exploits the local information of data sets, Tucker-Wopt performs better than EM-Tucker3 in most cases and can fulfill the extreme case where the ratio of missing data is very high. Tucker-Wopt can reconstruct the Tucker model successfully with large amounts of missing data, for example, 95% missing elements for tensors of size 50 × 50 × 50, while EM-Tucker3 can only address the same problem with missing data lower than 90%. Additionally, our algorithm generally converges faster than EM-Tucker3 especially when the percentage of missing data is high.
Experiments on data sets contaminated by noise also illustrate the robustness of our proposed algorithm. We also consider the practical use of Tucker-Wopt algorithm for missing traffic flow volume data estimation. Experiments demonstrate the robustness of our algorithm even though the missing rate is high.
For future studies, we will consider the problem of computation time since we would like to apply the proposed algorithm to large scale problems.
Footnotes
Appendix
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (61271376, 61171118, and 91120010), the National Basic Research Program of China (973 Program: no. 2012CB725405), and Beijing Natural Science Foundation (4122067). The authors would like to thank Yong Li from Beijing University of Posts and Telecommunication and Bin Shen from Purdue University for fruitful discussions about parts of this paper.