
Abstract
This paper presents a sensor random deployment scheme to monitor 2-dimensional areas for constraining applications while providing a mathematical control of the coverage quality it allows. In addition, useful techniques to detect and repair sensor failures are also added to provide system robustness based on this scheme. In particular, mathematical formulas are developed to express the probability of complete coverage when the environment characteristics are varying, taking into account the deployment parameters. Moreover, a methodology is presented to adapt this scheme to the need of various WSN-based monitoring applications. A simulation is also performed to show the efficiency of the developed strategy, highlight some of its features, and assess its impact on the lifetime of the monitoring system it serves.
1. Introduction: Need for Failure Detection and Repairing
With evolving sensor technologies, a growing number of sensors can be installed to architecture for the management and control of systems monitoring 2D areas. As the monitoring applications utilize the sensor data for alarming and decision, it is essential that (a) the data acquired by the sensors are accurate and reliable; (b) the sensing coverage quality is maximized at any time; and (c) the sensors are acting properly. One can notice, in particular, that sensor faults become more frequent compared to the architecture's lifetime and that the deployment techniques affect deeply the quality coverage of WSN.
The deployment strategies for WSNs providing area monitoring can be classified into three categories, namely, the static nodes placement with controlled deployment, the static nodes placement with random deployment, and the dynamic nodes placement with random deployment [1]. When it comes to the continuous monitoring of 2-dimensional areas (2D areas), all these techniques experience numerous drawbacks, either for their feasibility and the availability they provide or for the control they offer and the sensor lifetime they allow.
In particular, while the deployment strategies in the first class give optimal and guaranteed qualities of coverage in areas easy to access [2], these strategies fail hardly in accessible areas, since the sensors cannot be placed in positions chosen to ensure full coverage of the monitored area. On the other hand, the static node placement with the random deployment schemes operates by assuming that sensors are spread randomly in the monitored area [3, 4]. These schemes do not ensure total sensing coverage and radio connectivity to report all collected events, because the distribution of the sensors may not be uniform in the given area.
Strategies in the third class allow dynamic node placement with random deployment [5, 6], assuming that the deployed sensors are able to move within the monitored area. They mainly proceed through two steps. In the first step, the sensors are randomly spread in the monitored area. During the second step, the deficiency of coverage quality is compensated by commanding the sensors to move and change their positions to ensure the required quality of coverage. Monitoring applications using such strategies experience two major drawbacks. First, the node motion may cost a lot of energy. Second, the sensors may not be able to move properly to their new positions because of the nature of the monitored area and the obstacle irregularities they may face.
On the other hand, efficient monitoring systems should be able to address different constraints. In particular, they should provide (a) total sensing coverage of the monitored area or at least a large part of it, if the supported application is satisfied with it; (b) a wireless sensor network capable of relaying any detected event to the central station(s) in a real time manner; (c) the optimization of the energy consumption to provide longer sensor lifetime and reduce cost operation; and (d) the detection and repair sensor failures to keep the area continuously and properly covered.
In actual fact, a faulty sensor cannot perform its monitoring function properly, but, as an alternative, it may provide false information and induce erroneous decision, thus making the system unreliable or overconsuming energy [7]. Therefore, it is necessary to detect such failures and adapt the network to the new situation by running correcting actions such as sensor replacement. When the system is redundant, removing a failing sensor will not result in a loss of accuracy. However, if that is not the case or when the WSN has to operate for long time, a technique is needed for detecting, isolating and replacing/correcting a faulty sensor.
In this paper, a multistep method is proposed to deploy sensors and detect, isolate, and repair the sensors in the network when they get faulty. The main contribution of this paper is 4-fold.
First, it builds a dropping scheme, from air, for example, capable of providing tight control on the landing positions of the deployed sensors based on a landing pattern taking into consideration the characteristics of dropping environment and the sensor transporter. Second, a mathematical model is developed to control the sensing coverage quality and the quality of network communication provided by the deployed WSN, using deployed data relaying nodes. Third, it builds a monitoring scheme for the energy depletion control and the management of failures of the deployed sensors while allowing fault predictions using rule-based strategies. Fourth, it builds mechanisms to replace (or repair) faulty sensors and increase the network availability and lifetime using the proposed deployment scheme.
In particular, the provided model and techniques allow planning the WSN design in a way that increases the probability of network connectivity by controlling a set of parameters including, but not limited to, the dropping point locations, the number of deployed data relaying nodes and their range, the dropping altitude, and the errors associated with the variation of the landing patterns.
The remaining part of this paper is organized a follows. Section 2 develops the proposed deployment scheme of WSN for 2D area monitoring applications, in its static form. Section 3 extends the mathematical model to integrate the variation of the parameters involving the environments and the sensor transporter. Section 4 discusses techniques for the detection and prediction of sensor faults. Section 5 discusses different uses of the proposed deployment scheme and gives rule-based strategies for the prediction. Section 6 discusses techniques for faulty sensor replacement. Section 7 develops a numerical simulation of a system based on the proposed scheme. Section 8 concludes this paper.
2. Controlled Random Sensor Deployment for Area Monitoring
Assume that a WSN is to deploy in a 2D area to monitor the occurrence of some events. Assume also that the WSN has a hierarchical structure, in the sense that it has three layers. The first layer is formed by basic sensor nodes (SNs). The role of a SN is to detect the occurrence of prespecified events that help in monitoring a given area and to report the collected data to near nodes in the second layer (eventually through other SNs).
The second layer is formed by communication nodes (CNs) acting as cluster heads for the SNs in the first layer and routing those sensor's reports to the nearest (sink) node in the third layer, as called analysis nodes (ANs). The ANs are responsible for (a) message analysis and prediction needed by the application served by the WSN; (b) sensor fault detection and localization; and (c) the energy management of all sensors in the WSN.
For the sake of coverage efficiency, the layer two nodes should constitute all the time a connected network. In the following two subsections, we define the major mathematical model to deploy sensors and determine their landing positions within the area to monitor and the deployment scheme, when the environment parameters do not vary during deployment. In addition, we assume that the nodes in layers 1 and 2 are dropped from air following a deployment pattern that we will formally define.
2.1. Deployment Patterns for Sensors
We define a sensor deployment pattern (SDP) as a 5-tuple
We assume in the following that n is sufficiently small or that parameters

Using the fundamental principle of dynamics, one can see that the motion of a sensor dropped from position
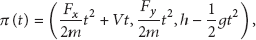



Landing area.
Assume that the sensors have a sensing range equal to

Proposition 1.
Let n sensors have a deployment pattern defined by
Moreover, if

Proof.
Using (4), one can deduce that the landing point of the n sensors is given by

On the other hand, one can see that the sensing ranges of two neighboring sensorsj and


Example of sensor deployment.
When
2.2. Front-Sense Scheme
Using the result achieved in the previous subsection, we can define a deployment scheme, called frontier sensor (Front-Sense) deployment scheme, that is capable of providing total sensing coverage of a 2D area to monitor, using a connected 3-layer hierarchical WSN. To explain this, we assume, for the sake of simplicity, that the area to monitor is a rectangle and that the sensing deployment patterns operate under the same wind and flight conditions. More varying conditions can be easily considered.
The Front-Sense scheme is a 3-step process operating as follows.
Step 1 (decomposing the rectangle into landing pattern-based zones).
Assume that the length and the width of the rectangular area to monitor are equal to A and B, respectively, and that its south west vertex is (0, 0, 0). Let us partition it into strips of length A and width
Step 2 (determining the sensor deployment pattern for every strip).
Let us assume that the sensor carrier is able drop the sensors from altitude h. Since the strips have equal lengths in the rectangle, the deployment patterns to deploy sensors in every strip will differ only on the droppings point to guarantee full sensing coverage of the rectangle. Let
The expressions are easy to set since the strips of odd order are similar, while the strips of even order are similar. Thus, the total number of dropped sensors is equal to the number of strips
Step 3 (computing the landing positions of sensors to deploy).
The landing positions of the first sensors in the first strip and the second strip are given, respectively, by



To monitor areas with general forms, we first construct the smallest rectangle containing the given area. Then, we can decompose the rectangle into strips with the width considered in Step 1. The strips are then shortened to the right size by considering the intersection between the area and the strips. The deduced strips have variable lengths. This makes the deployment patterns assigned to each strip different in the number of sensors they handle and the landing points. Step 1 in Front-Sense scheme can be modified accordingly, and the number of sensors is deduced for every strip. Figure 3 depicts an example of area coverage area by five strips.

Example of covered area.
3. Coping with Environment Variations
Several assumptions have been made in the previous sections to make Front-Sense scheme presentation and explanation easy to understand. Assumptions have mainly included the airplane velocity, the dropping altitude, the wind intensity, the area form, and the geographic features of the area. In the following, we address these issues under two hypotheses: low variation and modeled variation.
3.1. Adapting the Scheme to Slow Variations: Pattern Management
To cope with the variation of the wind speed, one can choose to measure more often the wind speed and deploy the sensors in a strip using as many sensor deployment patterns as possible, in the sense that the number of sensors in a pattern is fixed based on an estimated period of invariability of the wind speed. To implement this, let us assume that the wind speed statistics show that if the wind measurement is made at an instant
One can notice, however, that using multiple patterns per strip would make the width of the strip slightly vary from one pattern to another. This should be taken into consideration when proceeding with the next strip by placing appropriately this strip. In addition, adapting properly the control imposed by the inequality
To cope with the dropping altitude, area flatness, and area vegetation (i.e., the variation of h), we can assume that the variation h is negligible in a given time interval
Consequently, the landing positions can be adapted appropriately, assuming that the geography of the area to monitor is not so abrupt. Upon the occurrence of sudden changes in the geography of the area, the recomputation of the pattern may be triggered.
On the other hand, one can be convinced that to cope with the wind speed variation, a technique similar to the one used for h can be implemented, provided that this variation is limited in time and intensity.
3.2. Coping with Fast Variable Parameters
We consider in this subsection only the case where the wind intensity is varying under a uniform model. Assume now that n sensors are to be dropped, from air, using the following sensor deployment pattern:
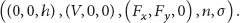





Random deployment on a strip.
Proposition 2.
Consider the above notations and assume that the communication range and sensing range of the n deployed sensors in S satisfy the following conditions:
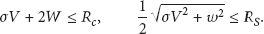
Proof.
We first notice that the condition on
Now, let us consider the intersection of the sensing range of sensors j and

The following result computes, in more general settings, the probability that the n sensors are able to sense and communicate.
Theorem 3.
Consider the above notations and assume that the communication range and sensing range of the n deployed sensors in S satisfy the following conditions:
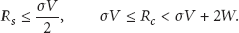
Then
the probability that the n sensors are able to communicate with each other is given by
the probability

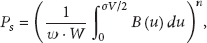
Proof.
To demonstrate the first statement of the theorem, we only need to consider that the probability
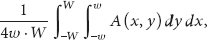
The connectivity of the sensors in the strip is then equal to
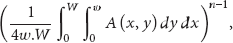
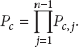
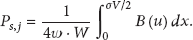

4. Sensor Failure Detection and Prediction
Amongst the challenges that WSN-based monitoring applications are facing, one can mention the quality of service (QoS) provided by the network and the lifetime of the network. The latter depends largely on the energy consumption of sensors composing the network. Most important concerns of QoS include (a) the quality and the amount of the information that can be collected and analyzed about the observed objects; (b) the detection of sensor faults and the tolerance of the monitoring system to these faults; and (c) the quick recovery from a fault. In fact, a sensor fault can be defined as a deviation from the expected model of the function the sensor is assumed to perform.
Faults can occur in different layers of WSN, but most commonly they occur at the physical layer, since sensors are most prone to malfunctioning and energy depletion. Major faults include calibration systematic faults, random faults from noise, energy exhaustion, and complete malfunctioning [8–10]. Calibration faults appear as drifts throughout the lifetime of a sensor node. Random noises induce random unwanted variations in the data reporting on the events detected by the sensors. Energy exhaustion occurs when batteries fail to provide the needed energy for detection and reporting.
4.1. Fault Classification
Sensor faults can be defined through two overlapping viewpoints: data-centric and system-centric faults [8]. Faults in the first category can be observed in readings through the effect they produce in data. Faults in the second point of view are observed with physical malfunction, environment conditions’ modifications, and inconsistencies of factors that are not expected to change throughout the lifetime of sensor.
The most common classes of sensors that have been used extensively in 2D area monitoring implement functions for the sensing of temperature, humidity, light, chemical elements, and mobile objects. Major features for these sensors include sensor location, environment characteristics, system features (e.g., calibration, detection range, reliability, and noise), and date features (e.g., statistical measures, gradients, and distance from other readings).
In the sequel, we only consider the data-centric viewpoint since one can assume, for sensor-based monitoring, that all the features revealing faults can be deduced from the reports transmitted to the sink for analysis. In particular we distinguish the following features/faults.
Temporal Gradients. We define a temporal gradient to be a rate of change, of a feature (or parameter), larger than expected over a short time window, despite what can be the value of the feature afterwards. In general, the determination of gradient is based on environmental context and models of the physical phenomenon to observe. It is a grouping of several data reports (or data samples) and not one isolated event. An example of gradient can be light intensity going through sudden and large changes.
Crossing Boundaries. A fault or the proximity of occurrence of a fault can be controlled by numerical metrics whose values are crossing a threshold. The crossing is typically an isolated sample or a sensor that significantly deviates from their expected temporal or spatial models. In particular, a temperature exceeding a high value for a point in a forest may reveal the occurrence of fire around that point. On the other hand, the level of remaining energy reported for a battery, powering a sensor, may show that the battery is running out of charge.
Zero Variations. Some faults can be defined as a series of data values (reported to the sink) that experiences zero or almost zero variation for a period of time greater than expected. Thus, a zero variation fault shows a constant value for a large amount of successive reported data. This value can be located outside, or within, the range of the expected values of the observed parameter. In particular, it can be either very high or very low.
High Noise. Noise is commonly expected in sensor data communication. Nonetheless, an abnormally high amount of noise may be an indication of a sensor problem. We define a noise fault to be sensor data exhibiting an unexpectedly high amount of variation. In fact, high noise may be due to a hardware failure or low energy batteries. Despite the noise, noisy data may still provide information regarding the phenomenon under monitoring.
Missing Data. A missing data requested by the monitoring protocol or a specific request sent by the sink may be a sign of fault. Moreover, missing periodic data for a relative period of time as expected can reveal a faulty sensor. Often, missing data is caused by the sensor generating the expected data of intermediate sensors in charge of relaying the data.
4.2. Fault Detection
Let us consider only the detection of sensor faults in WSN-based monitoring applications of 2D areas. Various works have addressed this issue assuming that a large set of hypotheses can be made on the sensor network and the data for sensor fault detection [9]. Among the major assumptions, we consider the following. First, all sensor data should be forwarded to a central node (or sink), where the event processing is performed. Second, all data received by the sink is not corrupted by any communication error. Third, no security attack is targeting the data flowing through the network, its components, or its sensors when fault is occurring.
We also consider the following two requirements to be fulfilled.
an event detected by a sensor will be detected in the near future, either by a neighboring sensor or by the same sensor. In the latter, the attached data should be different. sensors reporting an event should be appropriately identified and correctly localized and the localization errors are bounded.
Sensors deployed for monitoring applications using our deployment scheme comply with these requirements. In fact, events collected for the applications we consider are related to moving objects in a 2D area (e.g., fire in a forest and intruders of the frontier line). Collected events are time-stamped and include varying data (such as temperature or intruder position). Let us notice however that the location of a sensor is determined by the deployment pattern used to deploy it. The location is nothing but the center,
Let us now present the main two detection methods of sensor faults, as denoted by variance-based detection and profile-based detection. While the fist technique builds for resource consumption and predicts time of their exhaustion, the second handles the variance of a feature characterizing a given fault among the aforementioned list of faults. Both methods follow the same approach for fault detection: they first characterize the “normal” behavior of sensor reported data; then they identify the occurrence of significant deviations as faults and finally give some predictions on the related fault. However, for the sake of simplicity we consider only one type of fault for each method. In particular, we consider energy depletion and the temporal gradient.
Loss of Energy. Let n be an integer (equal to 3 or 4, in general). Let us assume that a sensor in the WSN has to send a message
The following section discusses the rules followed to monitor the energy consumption and the prediction of loss in the case of border surveillance.
Temporal Gradient. Let us assume selected a window N, a standard deviation σ, and threshold
Variation techniques have been developed to provide good estimation of the different parameters involved in the detection of faults [11]. While our method uses heuristics for detecting and identifying the fault types and exploits statistical correlations between sensor measurements to generate estimates for the sensed phenomenon based on the measurements of the same phenomenon at other sensors and reduce false positives, other techniques are time-series-analysis-based or learning-based [12] techniques.
5. Adapting the Front-Sense Scheme for Monitoring Uses
Various monitoring applications may benefit from the use of our deployment scheme. Among these applications, we consider in this section two special examples, namely, the border surveillance and wildfire sensing. We, first, present the architectural issues of the network that will be used for these applications. We will present the hierarchy of the network and the major functionalities.
The network is formed by three layers built on the following three types of node.
The sensor nodes (SNs) constitute the first hierarchical level. They are in charge of detecting the occurrence of an event of importance to the monitoring application. They also collaborate to relay the information gathered to the next layer in an optimized manner. SNs are assumed to know approximately their location information. The relaying nodes (RNs) constitute the second hierarchical layer of the network. The RNs main task is to collect the data gathered by the SNs and collaborate to relay it to the next layer. They may include intelligent functions to help in handling energy consumption, coverage estimation, and fault detection. The analysis nodes (ANs) form the third layer. Their function is to receive the events detected at first layer and correlate them, analyze and predict failures, operate object tracking, and coordinate actions.
5.1. Country Border Surveillance
A country border surveillance application monitors either an area on the country border or a borderline. This type of applications is becoming a serious concern due to the increase of the risks of illegal border crossings aiming at controlling unauthorized importation of goods or terrorism actions. Border surveillance can be performed using specialized WSNs appropriately deployed. Typically, WSNs within these applications are interconnected and have to report on any event related to crossings. For this, they should provide efficient monitoring and a certain coverage level of the 2D area (or line) of interest, since the coverage can be total (when the 2D area is completely sensed) or partial (when, for example, it is done through several thick lines in the 2D area), [13, 14].
The deployment scheme described in the previous sections can be used to provide total or partial coverage of cross-border actions, using sensor capable of detecting individual and animal motions. Indeed, total coverage of the network first and second layers in the 2D area can be realized using RDAM as operating according to Figure 2. A partial coverage can be achieved by guaranteeing the surveillance of several lines parallel to the border line. In both cases, the altitude and speed of the airplane, the wind speed, the sensing range, and the communication range of the nodes can be selected in way that the probability of total coverage can be as high as needed.
Rules to handle sensor faults in border surveillance handle mainly energy depletion, sensor location, and location of detected object. Rules include the following.
Energy Level Reporting Rule. Let
One should have
Energy Threshold Crossing Rule. If the reported level of energy
Replacement Rule. If the reported level of energy
Object Location Rule. Knowing the limited speed of the detected object and that the positions of the deployed sensors are known with reduced errors, then important variations of observed object positions reveal faulty positioning function on a sensor.
5.2. Wildfire Sensing
Monitoring the location and speed of advance of the fire front wave is a critical task to fight against wildfire and help in optimizing the allocation of firefighting resources while maintaining safety of the firefighters. A WSN-based fire monitoring system is a 2-area deployed fire alarm system that is able to remotely report the location of its components and the presence of a fire in their vicinity. Indeed, a wildfire can be monitored using multiple sensors that are able to detect smoke, carbon monoxide, methyl chloride, rapid temperature increases, windy speed, and other physical phenomena related to the occurrence and propagation of a fire. The use of sensors reduces the likelihood of false alarms without excessive complexity to the WSN. The data gathered is typically transmitted by radio in real time to firefighters equipped with radio receivers or to a sink, called the fire command center. The sensor can be dropped from air or be manually placed by firefighters over a predefined 2D area.
Monitoring wildfire presents the problem of wide covered areas requiring the transmission of a large amount of information through the network with the risk of significant energy consumption and hence limiting the lifetime of the network. Particularly, energy is crucial for the wildfire sensing because of the complexity of maintenance of the sensors and the replacement of empty batteries due to the difficulty of access to these sensors, in general. Another problem needs to be tackled by these systems; it is the fading effect. Due to the presence of vegetation, this leads to important problems such as the shadowing phenomenon.
An efficient wildfire monitoring should propose an optimized design capable of providing energy conservation, consideration of the quality of transmission, and spatial localization techniques for choosing the routing protocol. A solution based on DRAM can be built using the aforementioned 3-layer architecture, where we assume that detection is not made on image processing to detect energy related faults [15].
Fault detection can be done using the aforementioned rules for the faults related to energy. A library of rules for reporting faults can be built on the available models developed for the evolution, propagation, of smoke and temperature. These rules use contradictions or repeated errors observed on the reported information by neighboring sensors. Examples of rules include the following rules dealing with temperature.
Irregular Variation of Temperature Rule. A sensor, ψ, detecting that the temperature has exceeded a threshold τ starts sending messages every δ seconds to report on the temperature and its neighbors are requested to report on the temperature in their vicinity. If the reported values are not coherent then sensor ψ is experiencing a fault. For this, coherence cases can be distinguished.
Regular Variation of Temperature Rule. A sensor, ψ, detecting that the temperature is increasing and has exceeded a value η lower than the sensor breaking temperature
6. Deployment-Based Repairing of Sensor Failures
In this section, we develop techniques using our deployment scheme to plan the replacement of faulty sensors or sensors on their way to a faulty state. In addition, we will discuss techniques allowing reactive actions to reduce the loss of coverage (sensing or communication) due to the occurrence of faults.
6.1. Proactive Sensor Replacement
Replacement of sensors for a given monitoring application based on DRAM is built using a 3-phase process in charge of (a) the detection of faulty sensors; (b) the prediction of the time of occurrence of faults; and (c) the computation of new deployment patterns and instant of sensor dropping. The detection of faults can be achieved through a library of rules, similar to those discussed previously, taking into account the nature of the activity to monitor and the models governing the evolution of fault related parameters.
The prediction of fault occurrence is performed based on two things, the collection of messages helping in analyzing the temporal evolution to fault and a theoretical model governing evolution of related parameters, if any. The generation of the first message is often triggered when a threshold is reached, while the following messages are sent, by the concerned sensor or by its neighbors, on a time-based or event-based manner.
Upon receipt of the messages, the sink node can configure the related model, if any, and adapt to the reality of the situation to deduce the time to live before the occurrence of the fault. The actions in this step have been discussed in the previous section in the case of energy loss and temperature evolution.
On the other hand, the computation of new deployment patterns and instant of sensor dropping can be operated as follows: let
Assume that the period of dropping is selected so that the altitude h (in The reference lending position of sensor k, The actual landing of sensor The actual landing of sensor k, The dropping of the p new sensors before a given time is generally linked to the predicted times of the sensors going to fail.
The feasibility of the above conditions is easy to address, since they involve very simple constraints.
6.2. Sensing Coverage Maintenance
It is clear that when a sensor goes down or is eliminated from the monitoring WSN supporting a 2D monitoring application, then the coverage quality is reduced, since a subarea of the 2D area under monitoring might not be sensed properly or some sensors might be disconnected.
To address these issues one can perform the following tasks.
Proactive Replacement. This task assumes that instant of failure of the sensors to replace can be predicted for a horizon h (in time units). Then, a replacement procedure can be triggered to complete replacement of a set of sensors going to fail before one of can become faulty. However, this task may trigger a large number of replacement procedures, when the area is large and time between successive faults is reduced (due to limited battery lifetime, for instance). In addition, it is clear that the time it takes to replace the failing sensing and the rate of failing sensors per unit of time may have an effect on the quality of lifetime improvement. To highlight this let us, first, discuss the definitions of lifetime.
Two common lifetime definitions can be found in the literature [16]. The first considers the time when the first sensor in the network fails (i.e., dies or is out of energy). The second lifetime definition considers the time at which a certain percentage of total nodes run out of energy. This lifetime definition is widely utilized in general purpose wireless sensor networks. These definitions apply well for sensors deployed in a region to monitor some physical phenomenon occurring anywhere in this area. One can easily be convinced that utilizing proactive replacement will increase significantly the lifetime wireless sensor network, since the first sensors to fail will be replaced before energy shortage.
Increase of Sensing Range Temporarily. This task is executed when abrupt faults occur and reduce significantly the probability of sensing coverage. This task implements a 2-step process. In the first step, the probability of coverage is recomputed and compared to a prespecified threshold. The second step takes place when the computed probability is lower than the threshold. In that case the sensors in the vicinity of the faulty node are commanded to increase temporarily their so that the new probability becomes higher than the threshold.
To show how the coverage is recomputed we consider the expression demonstrated in Theorem 3, where we assume only one faulty sensor. We then locate the terms involving the faulty sensor. We recompute them taking into consideration the remaining involved sensors. Then, we reinsert the modified terms to get the final result. The recomputation can be seen through Figure 5, which shows that the area close to the faulty sensor should be deleted in the computation of

Coverage probability-related areas.
This technique, however, adds complexity to the coverage control, introduces some irregularities to mathematical model controlling the deployment, and may impact the lifetime of the wireless sensor network since the unbalanced distribution of ranges often causes the problem of energy hole, which may induce energy exhaustion of the sensor nodes in the hole region faster than the nodes in other regions [17, 18]. On the other hand, one can agree that the replacement strategy along with a good balance between the time needed to replace failing sensors and the horizon of prediction would compensate such a possible reduction.
7. Simulation
In this section we show the performance of our system by discussing the variation of the radio and sensing coverage probability, in a first step, and by discussing the impact of the replacement strategy, in a second step.
7.1. Radio and Sensing Range Modeling and Simulation
With no loss of generality, we only consider a monitored domain reduced to a thick strip, as depicted by Figure 6. The strip is overlapped by three zones (or squares) where three sensors can land after they are dropped from air. A sensor is assumed to land on discrete positions (separated by δ meters). The parameters
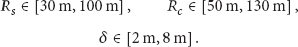
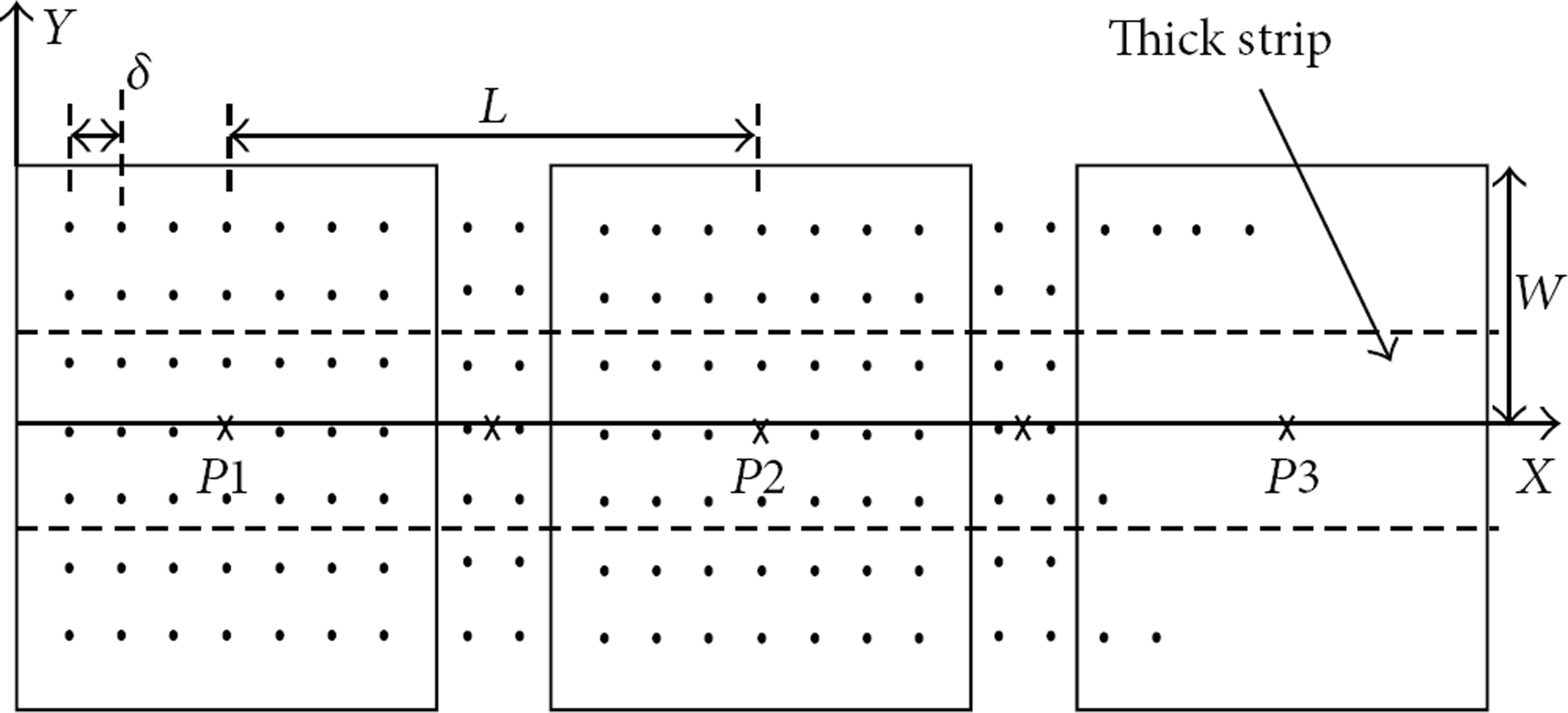
Simulation model.
The simulation is performed as follows: each sensor is dropped randomly on the discrete positions in the related square. The probabilities of sensing and radio coverage are then computed. The drop operation is repeated multiple times and the average probabilities are computed. The resulting values of the mean values are plotted by varying
Figure 7 shows the variation of the probability of radio connectivity for different values of

Probability of connection versus
In addition, this shows that when
Figure 8 depicts the variation of the probability of radio coverage, with respect to the varying communication range

Variation of probability of connectivity with respect to
Figure 9 depicts the variation of the probability of sensing coverage for different values of

Probability of sensing coverage versus
Let us notice, finally, that the effect of the discretization step δ variations on the probability values in the simulation is not significant when δ is sufficiently small.
7.2. Impact on Network Lifetime
Let us now evaluate the effect of the sensors’ replacement strategy, proposed in Section 6.2, on the network lifetime and assume that the domain to monitor is a thick strip, containing two lines of sensor drawn along the length of strip. We assume that the lines are 3 Km long and that 30 sensors are deployed on each line uniformly (so that they form squares of side 100 m). Every second square of sensors is assumed to contain in its center a DRN to which the sensors of the square report. Thus, one can see that the points of the two lines are fully covered by the sensors.
While the two definitions of lifetime, discussed in Section 6.2, apply to WSN-based monitoring systems in general, we believe that these definitions do not apply to WSN-based border surveillance systems where the objective of surveillance is not only to locate the individuals crossing the border but also to track them until crossing completion. For this, we provide a third definition that considers the time of failure of the first set of sensors allowing the crossing of an intruder without being detected. Applied to our simulation model, this definition considers the time where the first pair of sensors occurring on different lines and facing each other fail (or get out of energy). Figure 10 depicts the variation of the network lifetime.
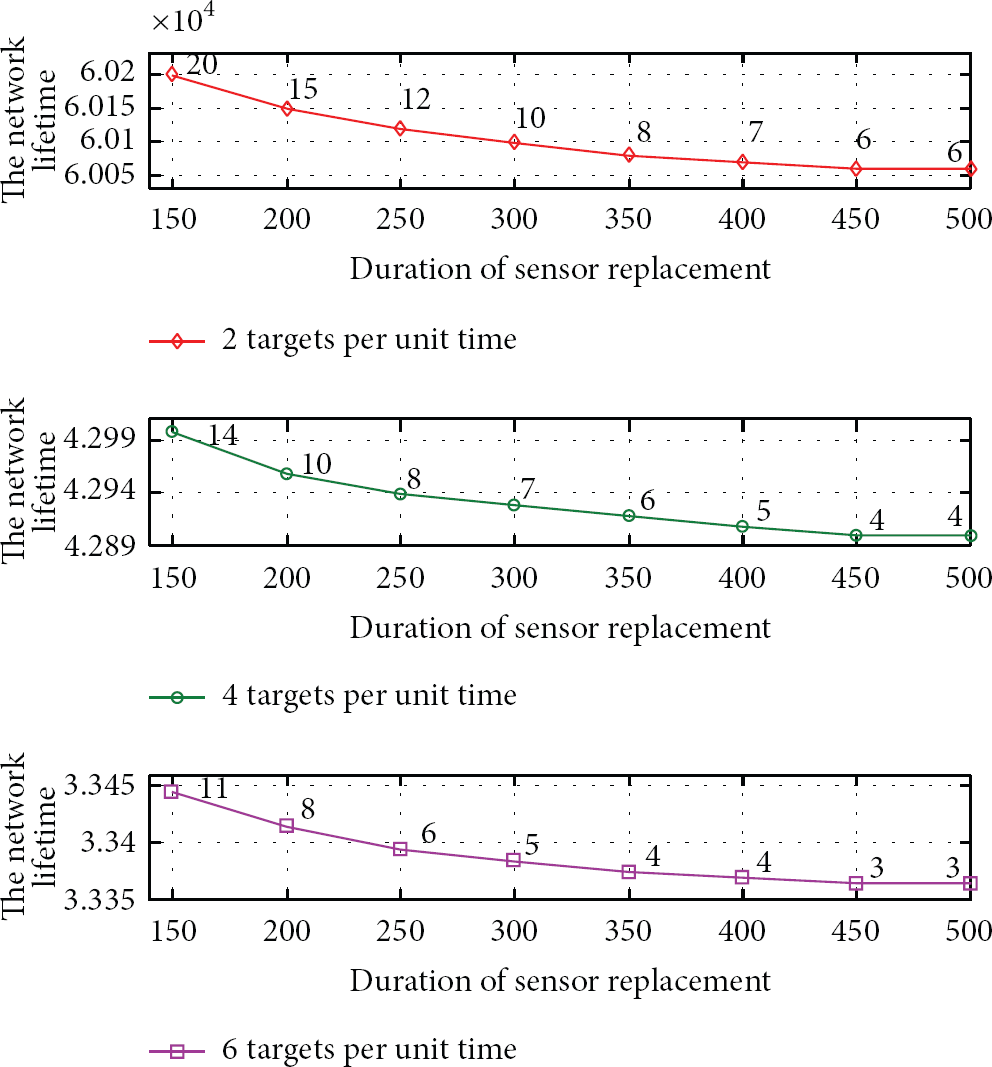
Effect of replacement on network lifetime.
To simulate the impact of the replacement strategy on sensors’ lifetime, we assumed the following two issues.
Lifetime modeling: when the sensor battery is fully charged, the sensor can send a maximum of 1000 packets to report detected events. Each sensor cannot send more than one packet per unit of time. Activity measuring: when not sending a message, the sensor performs normal functioning and consumes little energy. Normal activity during one time unit is assumed to be equal to 1/100 of the required energy to send a message reporting on crossing event.
During simulation two parameters have been varied to assess the impact.
The replacement time: this is the time needed to deploy a sensor showing that it is getting out of energy. We varied the values taken by this parameter in the interval The number of targets crossing the monitored area: we considered three rates of targets attempting to cross the monitored area (from one side to the other). They are, respectively, equal to 2, 4, and 6 attempts per 10 time units.
We conducted simulations to measure the network lifetime and the number of replaced sensors to assess the effect of replacement strategy. The results of these simulations are represented in Figure 10.
Let us first notice that if the time to replace a sensor is lower than the time of shortage prediction, the simulation results show that the sensors are all the time replaced. That is why the plotted results start for replacement duration higher than 100 s. Two main observations can be made from the figure.
When the replacement time grows from 150 s to 500 s, the network lifetime decreases and the number of replaced sensors becomes smaller. In particular, the number of replaced sensors reaches 40% in the case where one attempt is performed every 10 time slots and the time to replace is 150 s. Indeed, when the time to replace increases, the probability of the sensor requesting replacement goes down before it is replaced gets higher. When more crossing attempts are performed per unit of time, the network lifetime gets smaller, for given value of the replacement time. In fact, when more attempts are performed, more sensors will report and more requests for replacement will be generated and the probability that a request is not answered will get more important.
Let us finally notice that if the number of sensing lines in the monitored area increases, then one can be convinced that the lifetime of the network will increase. This feature comes from the fact that more sensors (belonging to different lines) would go to energy shortage before an undetected path occurs.
8. Conclusion
This paper presents a sensor controlled random deployment scheme to monitor bounded 2-dimensional areas while providing mathematical formulations to control the sensor and radio coverage quality it allows. In addition, techniques to detect and repair sensor failures are added to provide system robustness for a large set of WSN-based applications and increase network lifetime. In particular, expressions are set up to define the probability of total coverage when the environment characteristics are varying while taking into consideration real deployment parameters. The cases of two applications, the border surveillance and the wildfire sensing, are considered in some details to show that the approach is generic and that strategies can be conducted and assessed.
Footnotes
Conflict of Interests
The author declares that there is no conflict of interests regarding the publication of this paper.