
Abstract
Automated Planning has been successfully used in many domains like robotics or transportation logistics. However, building an action model is a difficult and time-consuming task even for domain experts. This paper presents a system,
1. Introduction
Activity recognition (AR) systems have been widely used in the past to detect activities of daily living (ADL) [1], but most of the literature describes approaches that detect the whole activity like in [2–6]. In order to provide assistance for the user to complete an activity or task, it would be desirable to detect the subtasks or actions (e.g., opening/closing cabinets) that compose an activity (e.g., preparing an omelette) and the effects that these actions have (omelette cooked). So, recognizing such actions and their effects while a user tries to accomplish a task could be used to check if the user is completing the task correctly. This way, a correct sequence of actions can be generated to accomplish the task successfully. In order to generate the sequence of actions, Automated Planning (AP) tools could be used, but they require to have an action model. Such model could be generated by experts manually, but usually this is a time-consuming and error-prone process.
Hence, the goal of this work is to build a system capable of guiding users while they are completing an activity. The system will be able to recognize, from sensor time series, the actions performed by a user while completing the activity, and the states of the system produced by those actions. Using that information, the proposed system generates a user action model represented as a STRIPS (Stanford Research Institute Problem Solver) planning domain in the standard language PDDL (Planning Domain Definition Language) [7]. Then, the generated planning domain will be used by an automated planner to generate plans (sequences of actions) to accomplish a task. These plans can be used to provide assistance to people in daily activities.
This paper describes a system, called
In order to automatically generate the planning action model, the preconditions and effects of each action have to be learned from sensor readings. For that reason, the segmentation of the time series is a key issue since the typical method used, the temporal sliding windows, may overlap several actions. Instead, this work employs a method based on events which was first used in [9]. The events produced by changes in the environment, like the actions do, are used to split the sensor time series. A segmentation method based on events may produce better results for generating planning action models than a method based on fixed-length sliding-windows as it is shown in [9]. Once the sensors time series were segmented, two different models to recognize actions were compared employing different features in order to obtain the best classifier. We used six different machine learning algorithms in the experiments. The best model was then used to generate the sequences of actions employed to build the action model in PDDL.
The main contribution of this paper is the creation of a system capable of the following: first, recognizing user actions; second, automatically generating user action models, represented as a STRIPS planning domain in PDDL, using the recognized actions and the states of the sensors between the actions; finally, assisting users by providing a sequence of actions to accomplish a goal. In this work, an user action model is defined as a representation of the actions that user performs. Planning action models are user action models represented as a planning domain in PDDL.
The rest of the paper is organized as follows. In Section 2 a brief introduction to Automated Planning is given and in Section 3 the
2. Automated Planning
Since the main objective of this paper is to learn a planning domain, this work focused on classical Automated Planning (AP) (more specifically in STRIPS planning). A STRIPS planning task can be defined as a tuple
On the other hand, AR systems try to infer the plan that a user performs from sensor raw data. So, this work tries to narrow the gap between AP and AR by building AP domains using real sensor data with AR methods. Our system tries to automatically learn the preconditions, adds and deletes of each action using AR in order to build a planning action model.
Figure 1 shows an example of one action learned in PDDL. It describes the action pick-up(param1,param2) which has two parameters. It only has one precondition, in(param2,param1). Its effects are that in(param2,param1) is no longer true and holding(param1) becomes true. Actions in the PDDL language are parametrized while most current planners instantiate the actions with problem objects to obtain the set of instantiated actions A. The learning system learns the parametrized version, because it is more general and applicable to all problems in a given domain.

Example of an action learned by the AMLA module.
3. ASRA-AMLA System Description
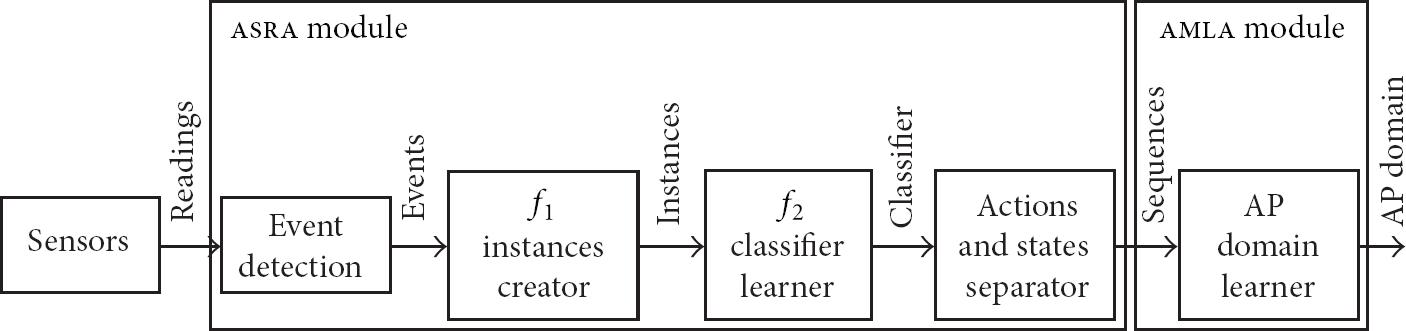
Architecture of
3.1. asra : Action and States Recognition Algorithm
The objective of
Once the sensors are able to detect the effects of the actions through the states, the
When the user performs an action, it produces some changes in the environment and those changes may generate none or several changes in the sensor readings. For example, when a user picks an object up, the object changes its location. Thus, a RFID sensor placed near the hand of the user may change its reading from not detecting anything to detecting the object. We are interested in detecting those kinds of changes in the sensor readings since they are connected with the effects of the action pick-up. An event is defined as any change in the readings of any sensor. For example, when the user opens a cabinet, a RFID detects the cabinet and generates an event. Also, the magnetic sensor changes its value from closed to open.
The events are used for the segmentation of the sensor time series to extract the actions and states. When an event is detected, the system recognizes the action to which it belongs and its effects. If the action produces more than one effect, it may also produce more than one event. Also, one event may be produced by more than one action, even for actions we are not interested in.
For magnetic sensors or RFIDs, the events are easy to define since they provide discrete values. For both sensors, all the changes in the values of the readings they report will be considered as an event. For cameras, the detection of the events is not so direct since they provide richer information, and such information may not be discrete. They are used to detect the state of some appliances (on and off) and objects (e.g., cracked for an egg) and the location of some objects (e.g., fry-pan on the burner). So, cameras will report in every frame the state of the appliances that they are monitoring, the objects that they can detect, and the state of those objects. Hence, the changes in the location or state of any object detected by the cameras are considered as an event.
Once the events have been defined, the next step is to build a classifier that predicts the action the user has performed. The action recognition task is formally defined as follows. Suppose the goal is to learn a recognition function f, such that being S a set of N sensors, and A the set of actions performed by an agent, f determines the action that the agent performs from the current and past sensor readings. That is, the objective is to learn the function
The function
After learning the action classifier, the states recognition is performed. When activities are recognized, sensors readings are segmented in pieces of data called temporal windows. These temporal windows do not usually match a complete activity from the beginning to the end of the activity. Instead, they normally split an activity into pieces that contain data that belongs to some parts of the activity. Actions have the same problem. Thus, in order to recognize complete actions, we assign to each temporal window an action. Next, we group consecutive temporal windows classified as the same action as an entire action. Then, the states between two different entire actions are the states extracted by the system.
Algorithm 1 shows how
As an example, suppose the user performs three consecutive actions,
3.2. amla : Action Model Learning Algorithm
This module builds an AP domain from the sequences generated by the
Example of types and predicates used.

Also, some standard assumptions are made. First, it is assumed that actions are deterministic. That means that it is considered that the actions are going to have always the same effects. Second, it is assumed that the preconditions are conjunctive; all the preconditions have to be true for the action to be executed. Also, a threshold (error rate) is used to eliminate the sensors' noise. This threshold indicates a minimum percentage of times that a predicate has to appear before/after an action to be used for building the corresponding action model. The goal is to learn the preconditions and effects (adds and deletes) of the actions. This threshold allows us to deal with situations in which the action fails (i.e., the effects are not correct); or the sensors fail (i.e., the preconditions or effects are not correct).
Thus, in order to learn the preconditions of each operator, given a collection of predicates that represent the state before the action,
The threshold is also used for the effects in the same way as for the preconditions. To be part of the effects, a predicate has to appear in the effects a percentage of times greater than or equal to the threshold. So, in the previous example, a predicate has to be in the adds of a in at least 7 out of the 10 instances of the action to be part of it. The same is used for the deletes.
4. Experimental Setup and Results
In order to test the system, a dataset has been generated with the task of making an omelette and the actions that compose this activity. The actions are
The
Figure 3 shows three pictures. The first one in Figure 3(a) shows the kitchen where the user cooks. Figure 3(b) shows the view of one of the cameras. In this case, the camera focused on the sink and part of the kitchen top where some objects have been placed. Finally, Figure 3(c) shows the view of a camera focused on the cooktop. Also, this picture shows one of the RFID gloves used by the user and some objects with RFID tags.

(a) Kitchen; (b) sink and part of the kitchen top with some objects (c) cooktop, glove with the RFID reader and some objects with RFID tags.
We used the OpenCV library [13] to recognize the objects. First, our system removes the background using an initial photo. Then, part of the shadows of the objects are removed using the initial photo but darkened. Finally, color and shapes are used as features to recognize the objects and their states using a classifier. Each object has a different color to facilitate the recognition. Before recording the dataset, the computer vision system was trained taking photos of all the objects of the kitchen in many situations. In each photo, the background is removed and the color and shape are extracted using contours. This way, a classifier was generated. Some of algorithms provided by OpenCV were tested: Support Vector Machines (SVM) [14], k-nearest neighbor (Ibk) [15], and Random Forests (RF) [16]. The best results were achieved using SVM, which obtained a recognition rate of 98% of the objects. Inside some objects some ingredients can be found in different states: oil in the fry-pan, raw egg in the bowl, beaten egg in the bowl, beaten egg in the fry-pan, omelette in the fry-pan, and omelette on the plate. Different classifiers were developed to detect each of these situations. So, first, the system detects the object using the main classifier. If, for example, the fry-pan is detected, a second classifier is used to detect if the fry-pan is empty, with oil, with the beaten egg, or with the omelette. A third classifier was generated to detect the different states of the bowl. The recognition rates were 63% for the fry-pan classifier, and 71% for the bowl classifier. In order to avoid problems caused by occlusion, there is more than one camera focusing on the working surface. Also, no changes are reported by the cameras until detecting an object and its state. So, if the user hides an object during some seconds, the cameras will not report any information about that object, and the system will consider that the object is in the same location and state previous to be hidden. Cameras work together with the RFIDs, so, whenever an object is detected by a RFID, the cameras try to find that object. The system also searches for specific information in specific places (e.g., the eggs just can be fried in the fry-pan or beaten in the bowl). To determine the state of the appliances we use the area of the images where a display indicates the state of the appliance. Then, using the difference of the colors in that area of the images, the state is computed. Finally, the initial state of some elements is defined since the system does not have sensors to detect such information, like objects that are initially inside some cupboard or inside the fridge. In addition, we have attached some RFID tags to the cupboards, drawer, fridge and surfaces in order to have some information about the place where the user is.
We tested our system through the task of making an omelette. The task has been performed by two different users ten times each, from beginning to end. The task was performed by two users to avoid the possible bias caused by a single user. The task was performed ten times by each user in order to obtain enough instances of each action to test the models. Also, parts of the task have been recorded in order to get more instances of some of the actions that compose the task. For instance, beating the eggs and putting the mix in a fry-pan or picking an egg up from the fridge and cracking it.
4.1. asra : Experiment Description
In order to test the
The second experiment, called
We have included an attribute to indicate the index of the position that was changed by the previous event. So, the vector is similar to the one generated for the
After generating all the instances, we used the following classifiers to learn the model: PART [17], C4.5 [18], Ibk, SVM, RF, and a Bayesian Network (BN). We have used their implementation in the Weka toolkit [19]. These classifiers have been selected because they represent different machine learning strategies and cover a wide spectrum of learning techniques.
4.2. asra : Experimental Results
In summary, we have performed experiments to check the performance of the
Then, to build an AP domain we selected the best classifier according to the employed metric. Table 2 shows the kappa coefficient of every generated model and the time in seconds that took to classify all the instances of the dataset employing the models. The best model is marked in bold.
Kappa coefficient and time in seconds of the learning algorithms used in

As it can be seen, the differences between ObjectInvolved and SingleValues are not significant in most models. Results obtained by the ObjectInvolved experiment are more consistent, since all the results are over 0.90. So, focusing the data just on the objects involved in the last event permits the system a better recognition of actions in average, although the difference in the results achieved by most algorithms is very small. In any case, the model that obtained the best result, RF, is the one we selected to generate the action sequences used to build the planning action model. In addition, the chosen model is one of the fastest models tested, although it is not the fastest. It is important to consider the time performances because it can prevent the system to be used in real-time. In any case, the showed times belong to the classification of all the instances of the dataset. The classification time of a single instance is lower than 0.0001. So, all the models generated are fast enough to be used in the system.
4.3. amla : Experiment Description
After generating sequences of actions and states with
We applied a twofold cross-validation by dividing the dataset into two parts of equal size. We selected one part to generate the planning domain and used the other part to test the domain. In the testing part of the domain, we randomly selected 10 sequences of actions for each planning operator where the first action that need to be executed was the action to be tested. For example, we used a planning problem to check the action pick-up where there is an object in a working surface that has to be picked up to achieve the goal, to cook an omelette. So, first, the user has to pick-up the object and then use the rest of actions to achieve the goal. This way, the problems generated are different since the initial state of each problem is different. The problems employed to check the learned actions are sequences found in the part of the dataset used for testing.
The AP problems have been executed using a deterministic planner from the International Planning Competition (IPC).
In Section 4.4 the results are presented.
4.4. amla : Experimental Results
The best model for
Precision and the values of the threshold for which the operators are learned correctly by

Table 3 shows that not all the actions were learned correctly using the same threshold. Some actions like pick-up or beat admit the lowest value of 70%. However, put-away has the upper value of 50%. So, if we want our system to learn the first two actions, pick-up and beat, put-away is not learned correctly and vice versa. With a threshold between 75% and 70% all actions but one are learned correctly. That action is put-away. This action is the one that the user takes when placing something in the cabinets or drawers. This action is not learned correctly because the action is very similar to put-down. The action put-down is taken when the user leaves something on the kitchen top. So, the readings of the sensors are very similar and some of the events produced during the actions are identical. For that reason, the precision of the recognition of this action is one of the lowest. As we can see, transfer has even lower precision, though it can be learned correctly. This is due to the fact that the precision of transfer is affected mainly by sensor noise and sometimes it is captured correctly. However, the precision of put-away is affected by the fact that another action is very similar and both produce identical events which are classified in most of cases as put-down. So, with less precision, the threshold permits the system to absorb the sensor's noise and learn the action transfer. But also, to learn put-away correctly the threshold has to be lowered too much to allow
The results of the learning process change as the threshold is modified like in similar approaches [23, 24]. Using a different threshold for each activity solves the problem and permits us to learn the complete planning action model correctly. However, the drawback is that it requires to provide more inputs for the system to work and that is what we want to reduce.
Figure 4 shows an example of a plan generated by a domain created by

Example of a generated plan.
5. Related Work
Many systems can be found in the literature using different types of sensors and detecting very different types of activities like for example [2–6]. But just a few of them deal with what we are calling actions; subtasks that compose an activity or plan. In [25] Amft et al. split activities, that they call composite activities, into actions, that they call atomic activities. First, they recognize the actions through what they call detectors, similar to the “virtual sensor” in [11]. Every detector recognizes one of several actions and reports those actions as events of the system. The events are used to recognize every activity. In [26], the same authors also split activities in parts in a very similar way to [25]. In order to recognize the actions, [25, 26] use fixed length sliding windows. Instead, we use a segmentation method based on dynamic sliding windows [9] because it fits better to the purpose of recognizing actions and states.
Once a system is able to detect actions, there are some AP systems able to learn action models. An example is OBSERVER [27] which takes as input a sequence of states and the actions that generated those changes in the states. Using that information OBSERVER is able to build action models for deterministic domains. Others build action models in noisy domains [23]. They use the initial state and goals and the sequence of actions that changes the initial state into a goal state.
A relevant work is the one presented in [28] where partially observable planning domains were learned. In their case, they only learn the actions effects, that are the transition rules among states. They build on their previous work [29] where the method was only applied to fully observable domains. Their system used deictic coding to generate a compact vector representation of the world state and learned action effects as a classification problem. In [30], the authors present a system that also just learned the effects of actions in deterministic partially observable domains.
The LOCM system [31] automatically induces action schema from sets of example plans. It does not have to be given any information about predicates, initial goals, or intermediate state descriptions. The example plans are a sound sequence of actions. LOCM exploited the assumption that actions change the state of objects, and require objects to be in a certain state before the actions can be executed. Planning traces are the input of LOCM, where each action is identified by its name and the objects that are affected or are necessarily present but not affected by the action execution.
Opmaker2 [32, 33] takes as inputs a domain ontology and a solution to a problem and automatically constructs operator schema and planning heuristics from the training session. It requires only one example of each operator schema that it learns and an ontology of objects and classes (called a partial domain model) as input. Opmaker2 is an extension of the earlier Opmaker system [34].
The systems presented need the sequence of actions executed and that information must be precise to work properly. In our case, that information is provided by an AR system, so it may contain errors. So, the system we propose is able to deal with the sensors' noise like in [23, 28] but also with the errors generated by the AR system and it is capable of generating an action model.
Hoey et al. in [11] present the only work available capable of learning a human action model from sensors. They map the actions and the states directly from the sensors, except for what they called “virtual sensor.” This “virtual sensor” uses an AR method to recognize one of the actions, pouring. Once they have mapped the actions and the states, they build a Partially Observable Markov Decision Process (POMDP) to assist people. Our system is similar but we generate action models based on AP domains instead of a POMDP. A POMDP does not scale well in general and the modification of the domain is more complicated than in the AP domains. Using AP permits us to exploit the generality and power of AP algorithms. Also, the way the action model is learned is very different.
6. Conclusions
In this paper, we present a system for building AP domains from raw sensor data. The AP domains generated can be used, along with a planner, to find a sequence of actions that can be used to assist people in the environment where it was built. The system called
In the process of building the system, a working environment was created in a kitchen. Two persons performed a task, making a omelette, in the kitchen, and a sensor network recorded the data produced by the users performing the task. An AP domain was modeled to assist people in the task. However, using just one threshold does not permit to learn the entire domain. To model the AP domain successfully, more than one threshold has to be used. An alternative method would be to improve the sensor network in order to recognize better the actions. Anyway, the action that is not learned correctly does not prevent the system from guiding a person in the learned task because it is used to insert objects inside the furniture.
The sensor network used has some limitations. The user must use RFID gloves in order to recognize the object that he(she) picks up. Also, different objects cannot have similar colors. Both limitations could be solved using accelerometers like in [11, 25] to detect the object that is being used. That way, the system could infer the actions performed by each object as well as its locations and state.
The system is easily extendible. In order to include more recipes or actions, the sensorial system has to be extended to recognize the new actions and to detect the effects that the new actions would produce. That way, the new actions would be learned and included in the planning action model.
As future work, it is planned to learn the entire system automatically using unsupervised methods or semisupervised methods. This would minimize the information provided to the system to generate models. Also, the system will be extended to include more tasks and to use the AP domain not just to assist people but to recognize the actions that the user performs as in [8].
Footnotes
Acknowledgment
This work has been partially sponsored by the Ministry of Education and Science Project nos. TIN2011-27652-C03-02, TIN2008-06701-C03-03, and TIN2012-38079-C03-02.