
Abstract
Wireless sensor networks (WSNs) have limited energy and transmission capacity, so data compression techniques have extensive applications. A sensor node with multiple sensing units is called a multimodal or multivariate node. For multivariate stream on a sensor node, some data streams are elected as the base functions according to the correlation coefficient matrix, and the other streams from the same node can be expressed in relation to one of these base functions using linear regression. By designing an incremental algorithm for computing regression coefficients, a multivariate data compression scheme based on self-adaptive regression with infinite norm error bound for WSNs is proposed. According to error bounds and compression incomes, the self-adaption means that the proposed algorithms make decisions automatically to transmit raw data or regression coefficients, and to select the number of data involved in regression. The algorithms in the scheme can simultaneously explore the temporal and multivariate correlations among the sensory data. Theoretically and experimentally, it is concluded that the proposed algorithms can effectively exploit the correlations on the same sensor node and achieve significant reduction in data transmission. Furthermore, the algorithms perform consistently well even when multivariate stream data correlations are less obvious or non-stationary.
1. Introduction
Wireless sensor networks (WSNs) can monitor, sense, and collect the data of various environments or monitored objects in an area. And the data are eventually sent to the target users [1]. WSNs have wide range of potential applications including home area and smart grid [2]. Each sensor node in WSN has limited battery power supply, and the used batteries are hard to recharge and replace. It is infeasible that a large number of nodes directly transmit the collected raw data to the base station or sink due to limited bandwidth and battery capacity. Wireless communication consumes most of the power. The literature [3] shows that the power consumed by transmitting the 1-bit data over a 100-meter distance can support to execute 3000 CPU instructions. The literature [4] also points out that the power consumption of the data transmission is much higher than that of data processing. Transmitting a 1-bit data via radio medium is at least 480 times the power consumption used for executing one “addition” operation. Approximately, 70% of the total power is consumed in data transmission. How to effectively reduce the amount of data within the WSN in order to extend the network lifetime is an important issue. Sensor energy can be saved via mechanisms at different layers of the WSN protocol stack [5–8], such as energy efficient routing [9] and battery saving media access control [10], where there are plenty of existing work. L. Zhang and Y. Zhang [11] presented an energy-efficient packet forwarding protocol in wireless sensor networks, considering channel awareness and geographic information. The perspective of this paper is from the application layer by introducing effective data compression.
Sensor nodes use the data sensing units to collect raw data and then transmit the data processed through the data processing units to reduce the amount of data to be transmitted. Generally, there are two types of processing methods [12]: data aggregation and data approximation. Aggregate functions process the sampled data using some forms of simple statistics such as maximum, minimum, and average. It is an effective mean to reduce the volume of data. However, it just provides simple coarse statistical information while potentially hiding some interesting local varieties of the data. Data approximation can be regarded as a model-based data processing method. When data feeds exhibit a large degree of redundancy, approximation is a less intrusive form of data reduction in which the underlying data feed is replaced by an approximate signal tailored to the application needs. It is only required to transmit the parameters of the distributed model built for the sensor data collected from WSN. Thereby, the amount of transmitted data is greatly reduced, resulting in network energy being saved, and thus the network lifetime is being prolonged. In terms of the way they are applied, there are four major categories for data approximation: probabilistic model [13, 14], time series analysis model [15–17], data mining model [18], and data compression model [19–24].
The paper is based on the following three facts which also show the application scenario. (1) Multivariate correlation exists. With the development of the wireless communication and microelectronics technology, wireless sensor node equipped with several sensing units has become popular. Such node can simultaneously monitor several types of data, such as sound intensity, acceleration, temperature, humidity, light intensity, and video, in which certain correlation universally exists. In this paper, the data collected by different sensing units in the same sensor node are referred to as multivariate data or multiattribute data, and the correlation among these different data type is called multivariate correlation or multiattribute correlation. (2) Spatial correlation does not exist. Most distributed compression algorithms are based on the assumption that nodes have spatial correlations with other nodes. This introduces large implementation cost. In real life, people often hope to use as small number of sensor nodes to monitor as wide an area as possible in order to reduce investment cost. As a result, these nodes are placed far away from each other, leading to no or little of unstable spatial correlation. In this case, it is a better choice that the algorithm is designed to run independently on each node. (3) Error is bounded. Influencing by noise, node failure, unreliable wireless communication, power constraints, and other factors, it exists certain error in acquisition, processing, and transmission processes of sensor data. The sensor data has a certain degree of uncertainty. If the user does not need very accurate results, by sacrificing the data precision, he can achieve the purpose of reducing the data amount of communication. Our study is devoted to minimize the volume of the transmitted data in the error bound predefined by the user.
The major contribution of the paper lies in the following aspects. This paper designs the algorithms considering the temporal and multivariate correlations of the data and also taking into account the case when the multivariate correlation is unstable, but without considering the spatial correlation of the data. Our algorithms run in each sensor node collecting a number of data streams. This paper proposes a self-adaptive regression-based multivariate data compression algorithm with error bound (denoted as AR-MWCEB) and implements it in C. According to the predetermined error bounds, AR-MWCEB makes decision automatically to transmit raw data or regression coefficients and to select the number of data involved in each regression. The results of simulation experiments show that the algorithm can reduce the amount of transmitted data and has better real-time performance than the benchmark algorithms.
The rest of the paper is organized as follows. Section 2 describes the related work, which is followed by the introduction of some preliminary knowledge and the problem formulation in Section 3. Section 4 presents the proposed compression scheme, base selection algorithm, and incremental calculation of regression coefficient. A self-adaptive regression-based multivariate data compression algorithm with error bound is detailed in Section 5. After the presentation of the intensive simulation results and performance analysis in Section 6, the paper is concluded in Section 7.
2. Related Work
Multivariate streams measured from one sensor node are correlated. The same is often true in other domain. Deligiannakis et al. [12] pointed out that the scatter diagram with indexes of industry and insurance from the New York stock market as the x-axis and y-axis coordinates, respectively, appears to be an approximated straight line. Each original time series is not linear, but he proposed a SBR algorithm using the base signal as an independent variable and the regression model to piecewise approximate other series. The values of the base signal are extracted from the real measurements and maintained dynamically as data changes. When the multivariate correlation measured by a sensor node is larger, this algorithm is better. But SBR algorithm does not consider the problem of error bound, and it just compresses data in the maximum degree under satisfying the condition of data compression. It may lead to two problems: (1) the algorithm is terminated before the error margin reaches its predetermined requirement; (2) the data is still continuously compressed when the error has met the requirement.
For the data generated by the single sensor node, the RACE algorithm [19] proposes a Haar wavelet compression algorithm with adaptive bit rate. It can output CBR (constant bit rate) or LBR (limited bit rate) streams by selecting the significant wavelet coefficients based on a threshold. RACE runs on a single node. In spite of reducing the transmission of redundant data by eliminating the temporal correlation, it does not consider the spatial correlation among neighboring nodes or multiattribute correlation in the same node. Ciancio et al. [20] study a distributed wavelet compression algorithm, which exchanges information among neighboring nodes and distributes the discovered spatial correlation of the sensor network data before the data are transmitted to the sink node. Although the algorithm has greatly reduced the transmission of redundant data, however, information exchange among nodes would result in some cost, such as power consumption and network delay, which needs further quantitative analysis in theory.
The literature [21] designs a new algorithm based on multiattribute correlation. The algorithm can effectively reduce spatial, temporal, and multivariate correlations, but there are two problems limiting its performance. (1) All the raw data of each node in a cluster must be sent directly to the cluster head and must be processed in the cluster head. The data with different attributes but from different nodes are not differentiated, but rather they are abstracted into a column of the processed data matrix. (2) Before sending data, the cluster head must call data preprocessing algorithm to analyze and find out the attribute pairs between which the correlation is large. In this processing, the estimated attribute data are fitted using the least square method. Our previous algorithms proposed in [22] run independently in each of the sensor nodes, and no collaboration exists between nodes. It uses the single data stream wavelet compression algorithm with error bound (SWCEB) to do wavelet decomposition to the maximum level resulting in full elimination of the temporal correlation of the data to satisfy the error bound in the coefficient selection. Meanwhile, it eliminates multiattribute correlations and uses the regression-based multiple data streams wavelet compression algorithm with error bound (MWCEB), in which the regression intervals are continuously bisected if needed to ensure that the error is bounded. The binary partition is arbitrary, so this paper will try to self-adaptively determine the number of data involved in each regression calculation.
It is worth mentioning that both multiple data streams (the data streams collected by a cluster head from all other nodes in the cluster) [23] and multiattribute data stream (the data streams collected by the single sensor node having multiple sensing units) can be effectively compressed by our proposed AR-MWCEB scheme. Furthermore, after the multiple data streams being processed by the cluster head, its spatial correlation is reduced, and after the multiattribute data stream is being processed in the multimodal node, its multivariate correlation is also reduced. This paper focuses on reducing the multivariate correlation of multiattribute data stream, but the result can also improve the performance of DLRDG [23].
Sadler and Martonosi [24] propose a lossless compression algorithm for sensor nodes in WSNs, called S-LZW. They discuss some design problems in detail about implementation, adaptability improvement, customizing compression techniques, and so on. Research on lossless data compression in WSNs is still in its early stage with very few published papers.
3. Preliminaries and Problem Statement
Many monitoring data collected by sensor nodes such as temperature, humidity, light, and vibration always slightly varies within a continuous time, and most of successive data are the same or similar. When these successive data are decomposed by wavelet transform, the majority of the energy is concentrated in the low-frequency coefficients. High-frequency coefficients are 0 or close to 0. Even if the monitored object changes abnormally, which causes unusual fluctuations of sensor data, the multiresolution characteristic of the wavelet transform can ease the impact of these unusual fluctuations on the overall data. It maintains values of some detail components as approximately 0. Compressing (discarding) the detail components with value 0 does not affect the data reconstruction; compressing the nonzero detail components would affect the data accuracy. The more detail components are compressed, the higher the compression ratio of the data is, but the larger the caused data error is. Therefore, under the premise of guarantee of error bound, detail components should be compressed maximally.
The distributed wavelet compression algorithm for the sensor networks is designed to complete the task by multiple nodes together. In this algorithm, the wavelet transform is calculated dispersedly in each node, and the wavelet coefficients are also dispersed at each node. Thereby, the amount of calculation for each node is small. The performance of using two-level wavelet transform is slightly better than that of using single-level transform, because the second level of the wavelet transform can better eliminate the correlation, in spite of increasing the additional energy consumption and time delay. Communication overhead and time delay are increased constantly with increasing the level of wavelet decomposition; thus, the distributed compression algorithm cannot always rely on increasing the wavelet decomposition level to improve its performance. Our algorithm runs independently on each sensor node, there is no collaboration among nodes; therefore, wavelet transform can decomposes the data with the maximum level to eliminate the temporal correlation of enough data.
Garofalakis and Gibbons [25] firstly proposed a wavelet-based compression technique with error guarantees of data reconstruction by introducing probabilistic wavelet synopses. Based on the error tree from the literatures [25, 26], a single-attribute data wavelet compression algorithm with error bound named SWCEB is proposed by us in the literature [22]. It includes four steps: wavelet decomposition, coefficient selection, quantization, and entropy coding. In the step of coefficient selection, it guarantees to satisfy the error bound. And it eliminates the temporal correlation in a single data stream through Haar wavelet transform. Furthermore, literature [22] proposes a multiattribute data compression algorithm with error bound named MWCEB, which is based on regression and divided into three steps:
selecting some attributes as the base attributes according to the correlation coefficient matrix of multiattribute sampling data; using SWCEB algorithm to compress the base attributes data; describing other nonbase attributes data by linear regression coefficients of one of the base attributes.
MWCEB algorithm can guarantee the satisfaction of error bound by increasing the number of base attributes. However, in the worst case, it degenerates into the SWCEB algorithm without taking advantage of multiattribute correlation. Another way to reduce error for MWCEB algorithm is to reduce the number of data involved in the regression calculation, that is, to carry out piecewise linear regression. As MWCEB algorithm arbitrarily divides the regression intervals equally without considering the data correlation, its processing parameters required manual intervention, and its regression performance is not ideal.
Within the framework of the above processing procedure, this paper tries to self-adaptively determine the number of data involved in the regression calculation each time to guarantee that the error is bounded. If successive data is a dramatic change, it is difficult to use a linear regression model to describe the nonbase attribute. Thus, the self-adaptive piecewise linear regression which automatically determines the data number involved in the regression calculation each time or direct transmission of the raw sampling data is selected automatically.
Assuming the data buffer size of a sensor node is M, the collected data is denoted as
Definition 1 (normalization of the sampling data).
Definition 2 (normalization error).
Definition 3 (∞-norm average error).
Definition 4 (the correlation coefficient matrix).
M times samples
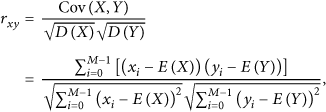
Definition 5 (the best correlation of attribute
for the base attributes set).
Suppose that N attributes streams

Definition 6 (the expected income of adding candidate attribute
to the base attributes set).
The N attributes are divided into the base attributes set BaseSet and the candidate attributes set CandSet. If attribute

4. Base Selection and Coefficient Incremental Calculation for Regression
4.1. Base Selection and Linear Regression
Suppose that a sensor node has N sensing units, and the collected attribute is
Step 1.
Using our base selection algorithm proposed in [22], classify all attributes into several groups
Each group
Step 2.
Run the SWCEB algorithm on M sampling data of the base attribute X. After wavelet decomposition, set some wavelet coefficients to 0 in the case of error bound. The local reconstructed data by wavelet transform is directly used as the base signal X of the regression. As a result, it avoids to spread the base reconstruction error to other nonbase attributes, and the reconstructed base signal is more regular and more suitable for use as a base than the original one.
Step 3.
Regress the nonbase attributes on the base attribute from the group in which the nonbase attributes locate, and transmit the calculated regression coefficients. The raw data of the nonbase attributes is no longer required to be transmitted.
The implementation of Step 3 is analyzed below in details. When the estimation of nonbase attribute Y is


Then,

4.2. Incremental Calculation for Regression
Now, we will introduce how to use self-adaptive regression to make decisions automatically to transmit raw data or regression coefficients, and how to automatically obtain the number of the data involved in each regression calculation. The number of data in each regression is set to some power of 2 for convenience. If the regression results satisfy the error bound, the start number start and the count number length of the data participating in the regression should be transmitted, as well as the regression coefficients a and b. If
Through analyzing the equations of calculating the regression coefficients a and b, it is found that the regression coefficients can be incrementally calculated. Define a data structure as in Algorithm 1.
(1) (2) double sum_x; (3) double sum_xx; (4) double sum_xy; (5) double sum_y; (6) }COEFF; (7) COEFF coeff, firsthalf_coeff, *pcoeff;
Algorithm 1:
The AuxCalc is an auxiliary function used by the incremental regression, which is implemented as in Algorithm 2.
(1) (2) (3) (4) (5) pcoeff ->sum_x=0; (6) pcoeff->sum_xx=0; (7) pcoeff->sum_xy=0; (8) pcoeff->sum_y=0; (9) (10) pcoeff->sum_x += X[i]; (11) pcoeff->sum_xx += X[i]*X[i]; (12) pcoeff->sum_xy += X[i]*Y[i]; (13) pcoeff->sum_y += Y[i]; } (14)
When the regression results satisfy the error bound condition, the number of regressed data length is doubled repeatedly for exploring the maximum length. Known by analysis of (6), when length is increased to 2 times of the raw one, the calculated coeff in the previous regression calculation can still be effectively used. Therefore, they can be saved as a static variable or global variable firsthalf_coeff for the use in the next regression calculation. In addition, assignment operators for the variables of COEFF type can be implemented by the addition and assignment of each corresponding fields.
The incremental calculation function of regression coefficients is described as in Algorithm 3.
(1) (2) Y[start.. start+length-1] (3) (4) (5) (6) (7) (8) (9) coeff+= firsthalf_coeff; } (10) firsthalf_coeff= coeff; (11) *a= (length*coeff.sum_xy - coeff.sum_x*coeff.sum_y)/(length*coeff.sum_xx - coeff.sum_x*coeff.sum_x); (12) *b= (coeff.sum_y - *a*coeff.sum_x)/length; // recursive form of (6) (13) *cnterr = 0; (14) double max_y=−32768, min_y = 32767; (15) (16) (17) (18) (19) (20)
5. A Self-Adaptive Regression-Based Multivariate Data Compression Algorithm with Error Bound
5.1. The Proposed Algorithm
The proposed self-adaptive regression-based multivariate data wavelet compression scheme with error bound is abbreviated to AR-MWCEB. Its basic idea is as follows. (1) Calculate the regression error of the first 8 being processed data in the buffer of a sensor node. (2) If the calculated regression error does not satisfy the predefined error bound, transmit directly these 8 raw data, or else, and recalculate the regression error after doubling the number of regressed data until that the maximum number of the regressed data with satisfaction of the predefined error bound is found in order to obtain the best compression performance. In this case, it only needs to transmit 4 data that described the regression process to represent one segment of the raw sampling data of the nonbase attribute. (3) repeat the above process starting from the first unprocessed data to the last one.
Assuming that the number of the regressed data is l and the error bound is satisfied, but the error bound is not satisfied when it is
The compression algorithm based on self-adaptive regression is described as in Algorithm 4.
(1) (2) the sampling data of related attributes X[0 ⋯ M−1], Y[0 ⋯ M−1], M is the number of buffer data in a sensor node; initially start is 0 and size is M. (3) reconstruct the raw sampling data satisfied the predefined regression error bound (4) (5) double a, b, old_a, old_b; (6) int counterror; (7) loop: (8) int startpos= start; (9) int count= 8; (10) (11) (12) (13) (14) Directly transmit the eight raw data Y[startpos ⋯ startpos+7] to the receiving sensor node; (15) startpos += 8; } (16) (17) Transmit the 4-tuples (old_a, old_b, startpos, count/2) for regression representation of count/2 data; (18) //the approximation of Y[startpos.. startpos+count/2-1] can be reconstructed by the 4-tuples in the receiving end (19) startpos += count/2; (20) count=8; } (21) } (22) (23) count*= 2; (24) old_a= a; (25) old_b= b; } (26) } // (27) (28) Transmit the 4-tuples (old_a, old_b, startpos, count/2) for regression representation of count/2 data; (29) start= startpos+ count/2; (30) size= M - start; (31) (32) //The above statement can also been expressed as: (33) } // (34)
5.2. Properties of the Algorithm
Property 1.
After transmitting the part of the data each time, the number of the remaining data shall be a multiple of 8.
Proof.
We assume that the size M of the data buffer in a sensor node is some power of 2. This assumption accords with the actual situation of the memory hardware, and it is also convenient for making wavelet transform on the base attribute in Step 2 of Section 4.2. The total number of data of each attribute in a buffer is usually some power of 2 and more than 210. Set it to
Property 2.
AdapRegressCompress algorithm complying with the aforementioned process is correct.
Proof.
When the condition of the while loop in line 10 of AdapRegressCompress algorithm is true, the codes within the loop body are executed. However, only one of three cases can be executed in each loop. The three cases are (1) if the conditions in both line 12 and line 13 are true, the block statement from lines 14 to 15 will be executed; (2) if the condition in line 12 is true but the condition in line 13 is false, the block statement from lines 17 to 20 will be executed; (3) if the condition in line 12 is false, the block statement from lines 23 to 25 will be executed.
The values of variables start and size are kept unchanged in the process of repeatedly executing the loop body. For each loop, if some data are transmitted, then the increment of variable startpos is 8 at least; if no data are transmitted, then the value of variable count is doubled. Thus, the while loop must be terminated after finite loops. Next, analyze the states of terminating the while loop by the three cases, respectively.
If the while loop is terminated after execution of line 15. The number of remaining data is a multiple of 8 according to Property 1. After executing statement 15, only 8 data are processed. Now, the loop condition is no longer satisfied; it has shown that only 8 data are left before this loop, and this loop happens to deal with all data. At this time, startpos equals to M. The algorithm ends. If the while loop is terminated after execution of line 20. Denote startpos, count as startpos1, count1 and startpos2, and count2 before and after this loop, respectively. Because count1 ≠8, then count1 16. So startpos1 + count1 = startpos1 + count1/2 +count1/2 = startpos2 + count1/2 startpos2 + 8 = startpos2 + count2. As the condition startpos1 + count1 ≤start + size is true when statement 17 is executed, then startpos2 + count2 ≤start + size, and this loop must be executed once after executing statement 20; that is, the while loop cannot be terminated by the second case. If the while loop is terminated after execution of line 25. Lines 27 to 33 deal with the third case. At this time, the first count/2 data can be represented by regression model, and only 4 tuples need to be transmitted. With the statement 29 and 30, the starting position and the number of the remaining data are calculated. If there are still some remainder data unprocessed, the above process can be repeated by the goto statement in line 32. A more intuitive expression is to recursively invoke this algorithm, namely, the statement 31.
5.3. Complexity Analysis of the Algorithm
The body of AdapRegressCompress algorithm mainly includes a while loop. In addition to the while loop, statement 11 and statement 31 are the two most time-consuming operations. Similar to the extreme cases of the three terminations of the while loop in previous correctness analysis, the average performance of AdapRegressCompress falls into the range among these extreme cases.
(1) When the linear correlation between the M data and the data of the base attribute is small, 8 raw data must be transmitted each time resulting in no compression. Each raw data is just used one time (i.e., in statement 11) according to AuxCalc. The time complexity is the least. The while loop from statements 10 to 26 must be executed
(2) Set

Illustration of data segments involved in regression.
As shown in Figure 1(b), when calculation with the first half part of the processed data in each time satisfies the error bound, but with the whole data does not, its compression performance is better than that of the left subgraph. The number of data used by AuxCalc is
(3) When all the M data are satisfied the regression error bound, the compression performance is best. Each data is simply used once in AuxCalc, its time complexity is the smallest. The while loop with statements 10 to 26 must be executed
6. Experiments
The used dataset is provided by Samuel Madden et al. (http://db.csail.mit.edu/labdata/labdata.html), containing more than 2.30 million data collected by 54 Mica2Dot nodes at the same time. Each Mica2Dot node collects four kinds of attribute data: temperature, humidity, light intensity, and voltage, denoted as attributes no. 0, no. 1, no. 2, and no. 3, respectively.
Each real number such as sampling data, wavelet coefficient, regression coefficient, which is stored in Micaz nodes, needs 2 bytes for storage. 2 bytes are enough for storing an integer such as start number start and the count number length of data. The number of samples in a sensor node buffer is usually no more than
Data compression performance can be measured with space savings rate, defined as the reduced data amount by compression to the raw data amount. Suppose that a node's buffer can store M times sampling data, it may send raw data directly or run regression calculation several times for the sake of bounded error. The processed part of data in each linear regression is called a segment. In the following experiments, the normalized error bound for the selected base attribute is set to 0.01, the normalized error bound for the temperature (attribute no. 0) is 0.07; that for the voltage (attribute no. 3) is 0.19.
6.1. Stationary Multivariate Correlation
The correlation degree of the attributes in the experimental dataset can be learned by calculating their correlation coefficient matrix. It can be seen from the experimental results that the multivariate correlation decreases with the increase in the number of sampling data in a buffer. However, if the samples in a buffer are too few, the proposed algorithm cannot take full advantage of the temporal and multivariate correlations. When the data used for the base selection is the same as the being transmitted ones, the multivariate correlation can be recognized as being stationary.
The used dataset consists of the initial
For the above case 1, set

Compressing no. 0 attribute data based on no. 1 using AR-MWCEB.
Compressing no. 3 attribute data based on no. 1 using AR-MWCEB.
The experimental results have showed that (1) the space savings rate of the AR-MWCEB algorithm is improved with the increase of the normalized error bound. When the normalized error is 0.191, the space savings rate of RACE algorithm is only 87.5% [19]. For the same error bound, the space savings rate of RACE algorithm is always less than that of AR-MWCEB algorithm. (2) To obtain higher space savings rate, PMC-MEAN algorithm [27] should accumulate the processed data in each time as many as possible without exceeding the buffer size of a node. With the number of the samples increasing, multivariate correlation will be weakened so that the absolute error bound increases. However, the AR-MWCEB algorithm determines self-adaptively the number of data involved in the regression by the error bound, and then it can search regression segments in a bigger interval to achieve better compression performance. (3) With respect to the amplitude of attribute no. 3, it has many large high-frequency noises; thus the compression performance is not good for the case of small error bound. (4) When the predefined error bound is small, MWCEB may degenerate into the SWCEB without taking advantage of multivariate correlation, and AR-MWCEB solves this problem.
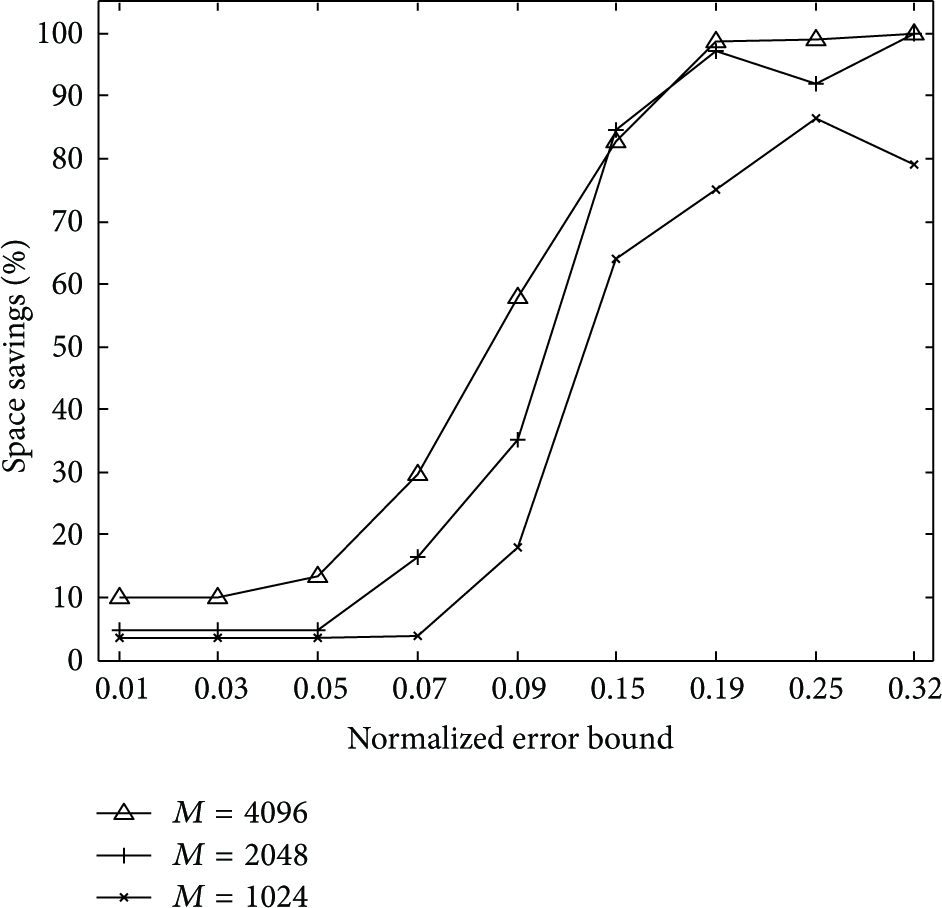
Figure 4 shows the comparison of the reconstructed temperature data with the raw sampling ones, where

Reconstruction by adaptive regression (no. 0 based on no. 1).
Reconstruction by adaptive regression (no. 3 based on no. 1).
6.2. Nonstationary Multivariate Correlation
When the correlation coefficient matrix varies with time, each attribute may be reallocated into a group and may act as a new role by using the base selection algorithm in terms of new correlation coefficient matrix every once in a while. In literature [21], before sending data each time, the cluster head had to call preprocessing algorithm to analyze and find the attributes with large correlations, so the overhead was large. This problem also occurred in our previous proposed MWCEB algorithm [22]. But the AR-MWCEB algorithm has been greatly improved by using the base selection algorithm to obtain the information about correlations between attributes. It can avoid considering the change of the correlation coefficient matrix and can regroup the attributes in a long time interval. Although the number of the samples involved in regression calculation is automatically determined to ensure that the error is bounded, the time-varying multivariate correlation may lead to worse compression performance. When the data used for the base selection is not the same as the being transmitted ones, the multivariate correlation can be recognized as being nonstationary.
Equally dividing the first 8K times samples of the dataset into 8 segments and calculating the corresponding 8 correlation coefficient matrixes, it is easy to find that these matrices change over time. Next experiments are conducted on transmission of the first 8K times sampling data, where the base selection is based on the beginning 1K sampling data, and attributes no. 0 and no. 3 are determined to take attribute no. 1 as the base signal by the correlation analysis. The attribute correlation is no longer analyzed in a long time. The compression performances of AR-MWCEB algorithm at different time are analyzed when M is 1K, 2K, and 4K, respectively, and are listed in Tables 1 and 2. The used normalized error bound for the temperature (attribute no. 0) is 0.07; the normalized error bound of the voltage (attribute no. 3) is 0.19.
AR-MWCEB's performances on compression of no. 0 attribute data.

AR-MWCEB's performances on compression of no. 3 attribute data.

The experiments have shown that (1) since the attribute correlation is reduced with the increase of M, MWCEB algorithm can only divide the sampling data into equal segments, while AR-MWCEB algorithm can self-adaptively segment the data resulting in a smaller error. (2) The attributes are grouped and located roles by the data firstly filling the node buffer. Although the correlation coefficient matrix may change with time, the compression performance of AR-MWCEB algorithm is slightly impacted by the time-varying multivariate correlation. (3) The compression performance is also affected by the distribution of the sampling data. The amplitudes of attribute no. 0 change greatly, and it has few high-frequency noises. For attribute no. 3, its amplitudes change slightly, but it has many large high-frequency noises. Thus, the default error bound for attribute no. 0 is set to a low value, while for attribute no. 3 it is of a larger value.
7. Conclusions
Aiming at effectively compressing the sampling data from the sensor networks node, between which the spatial correlation is nonexistent or nonstationary, this paper proposed a self-adaptive regression-based multivariate data compression scheme with error bound. The algorithms can run independently on each node. Determined by the predefined error bound and compression income, our algorithms can automatically select to transmit the raw data or the regression coefficients and explore the optimal number of the data involved in each regression. The compression performances of the proposed algorithms are also effective when multivariate correlations are reduced or nonstationary. The proposed algorithm is applicable for processing linear multivariate data by researching on using the linear relationship between base and nonbase attributes to represent the compressed results of nonbase attributes.
It is worthy of further research as to how to use a less complicated method to represent the nonlinearity between the base and nonbase attributes. In addition, for the model-based data collection in WSN, how to construct a model with dynamic evolution over time is also going to be our future work.
Footnotes
Acknowledgments
The work in this paper was partly funded by UK EPSRC Project DANCER (EP/K002643/1), EU FP7 Project MONICA (GA-2011-295222), the Science and Technology Planning Project of Hunan Province of China (Grant no. 2011SK3081), the Scientific Research Fund of Hunan Provincial Education Department (Grant no. 12B003), and the National Natural Science Foundation of China (Grant no. 61202439).